TL;DR#
Current deep learning approaches for precipitation nowcasting often produce blurry predictions due to pixel-wise loss functions like MSE. This limits their practical value for forecasters who need sharp, clear imagery. The paper addresses this issue by proposing a novel approach that focuses on the Fourier transform of the prediction.
The proposed Fourier Amplitude and Correlation Loss (FACL) consists of two new loss terms. The first term, Fourier Amplitude Loss (FAL), sharpens high-frequency details of the predicted image. The second term, Fourier Correlation Loss (FCL), preserves overall image structure. FACL significantly enhances the quality of the predictions, as measured by perceptual and meteorological metrics. The new loss function, FACL, consistently outperforms MSE across various models and datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the common problem of blurry predictions in precipitation nowcasting by introducing a novel loss function. This offers a significant improvement over traditional methods, leading to more accurate and visually appealing forecasts. The proposed method is also computationally efficient and model-agnostic, making it widely applicable. The research opens avenues for further investigation into spectral-based loss functions and the development of more robust perceptual metrics for evaluating spatiotemporal prediction models.
Visual Insights#
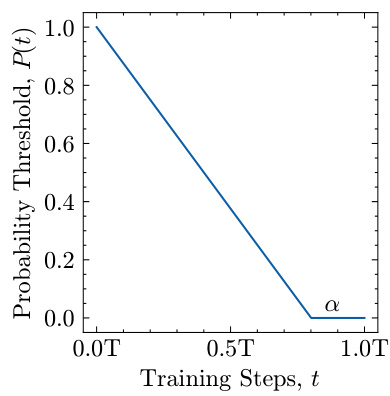
🔼 This figure shows the pre-defined probability threshold function P(t) used in the FACL loss function. The function linearly decreases from 1 to 0 over the training steps (t). The parameter α controls the point at which P(t) transitions from a declining value to 0, indicating the balance between the use of Fourier Amplitude Loss (FAL) and Fourier Correlation Loss (FCL) during training. This approach ensures that the model first learns the overall image structure with FCL before focusing on high-frequency details with FAL later in training.
read the caption
Figure 1: The pre-defined probability threshold function P(t) over training steps t with T total steps. α determines the ratio of the training steps where P(t) = 0.
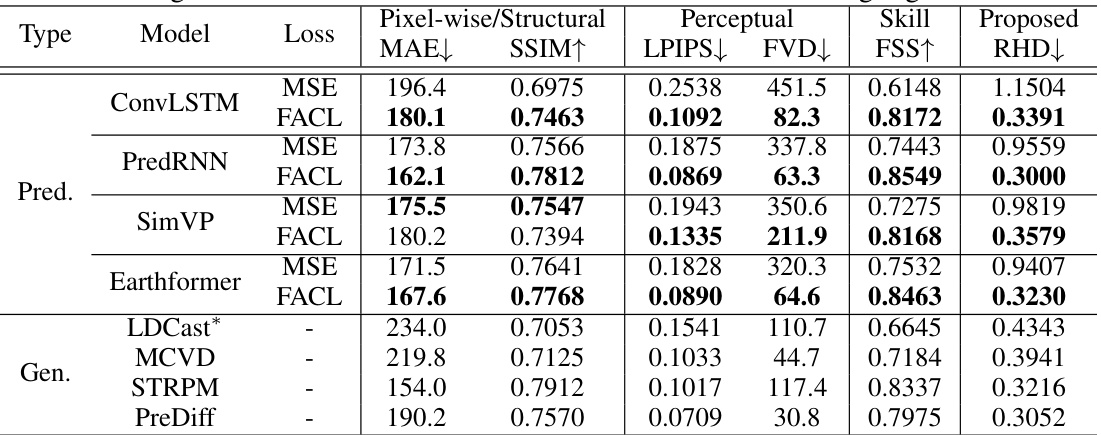
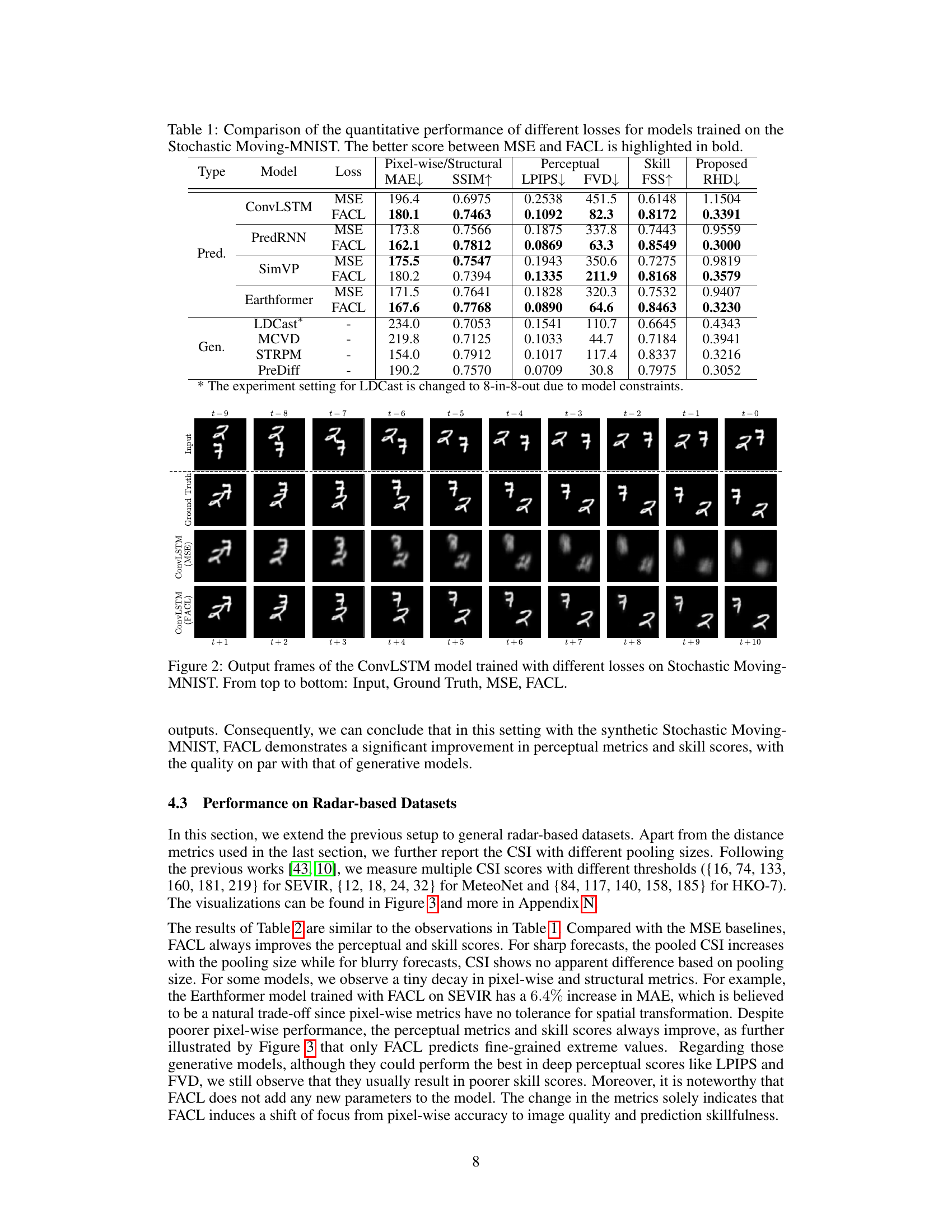
🔼 This table compares the performance of different loss functions (MSE and FACL) on various models (ConvLSTM, PredRNN, SimVP, Earthformer) trained using the Stochastic Moving-MNIST dataset. It shows quantitative results across different metrics categorized into pixel-wise/structural (MAE, SSIM), perceptual (LPIPS, FVD), skill (FSS, RHD), and a proposed metric (RHD). The best performing loss function for each model and metric is bolded, allowing for easy comparison of the effectiveness of FACL against the traditional MSE loss.
read the caption
Table 1: Comparison of the quantitative performance of different losses for models trained on the Stochastic Moving-MNIST. The better score between MSE and FACL is highlighted in bold.
In-depth insights#
FACL Loss Function#
The proposed Fourier Amplitude and Correlation Loss (FACL) function represents a novel approach to addressing the issue of blurry predictions in precipitation nowcasting models. FACL cleverly combines two loss terms: the Fourier Amplitude Loss (FAL) and the Fourier Correlation Loss (FCL). FAL sharpens predictions by regularizing the amplitude component of the Fourier transform of the model’s output, thus enhancing high-frequency details. Importantly, FCL compensates for the loss of phase information inherent in FAL by ensuring the overall image structure of predictions aligns with the ground truth, achieving a better balance between sharpness and accuracy. Unlike traditional L2 loss functions, FACL operates in the Fourier domain, providing a unique way to control image sharpness and structure simultaneously. This spectral approach proves effective in generating more realistic and skillful weather predictions, surpassing the performance of standard loss functions on multiple datasets. Furthermore, FACL’s model-agnostic nature and parameter-free design make it a versatile and efficient loss function applicable to diverse model architectures. The experimental results convincingly demonstrate the superiority of FACL in improving perceptual and meteorological skill scores while maintaining reasonable pixel-wise accuracy.
RHD Metric#
The paper introduces a novel metric, Regional Histogram Divergence (RHD), to address limitations of existing metrics in evaluating spatiotemporal predictions, particularly in precipitation nowcasting. RHD improves upon traditional pixel-wise metrics (MAE, MSE) by considering regional similarity and tolerance to small deformations, which are common in atmospheric phenomena. Unlike perceptual metrics (LPIPS, FVD), RHD avoids reliance on pre-trained models, making it less susceptible to domain bias. Unlike traditional skill scores (CSI, FSS), RHD offers finer-grained evaluation by utilizing histograms, enabling more precise assessment of the distribution of precipitation intensities within localized regions. This multi-faceted approach makes RHD a promising tool for comprehensively assessing the quality of precipitation nowcasting models, going beyond simple pixel-wise accuracy and capturing more nuanced aspects of perceptual and meteorological skill.
Generative Models#
Generative models have emerged as powerful tools in precipitation nowcasting, offering the potential to overcome limitations of traditional methods. Unlike traditional models which primarily focus on pixel-wise accuracy, leading to blurry predictions, generative models aim to capture the underlying probabilistic nature of weather patterns. This allows for the generation of more realistic and diverse forecast ensembles, which are highly valuable for improving decision-making in forecasting operations. However, generative models present challenges. They are often computationally expensive, requiring significant resources for training and inference. Furthermore, the inherent stochasticity of generative processes can introduce ambiguity and uncertainty into the forecasts, necessitating strategies for uncertainty quantification and ensemble analysis. The success of generative models hinges on choosing appropriate architectures and loss functions that effectively capture the spatiotemporal dynamics of precipitation. Despite these challenges, the ability of generative models to produce visually realistic and physically plausible precipitation forecasts makes them a promising avenue for future research and development in nowcasting.
Ablation Study#
An ablation study systematically removes components of a model or system to assess their individual contributions. In the context of a deep learning model for precipitation nowcasting, an ablation study might involve removing loss terms (e.g., Fourier Amplitude Loss, Fourier Correlation Loss) to evaluate their impact on forecast accuracy and sharpness. The results would reveal the relative importance of each component in achieving the desired model performance. A well-designed ablation study would compare the complete model to versions with individual components removed, providing quantitative evidence to support the design choices and highlight potential areas for improvement or simplification. It’s particularly important for this application because it shows which aspects are most critical for accurate forecasts and improves understanding of the model’s functionality. A thorough ablation study will also evaluate whether the removal of a component leads to an increase or decrease in model performance against different evaluation metrics. This provides further insights into the contribution of each element, facilitating a better understanding of their interactions. In this specific context, it helps determine the necessity and effectiveness of using Fourier transforms in the nowcasting process.
Future Work#
The authors acknowledge that their Fourier Amplitude and Correlation Loss (FACL) method, while demonstrating significant improvements in precipitation nowcasting, still has room for enhancement. Future work should focus on extending FACL’s applicability beyond the currently tested monotonic radar echo data to encompass more complex, multimodal datasets often found in medium-range forecasting scenarios. This would involve handling non-monotonic data and potentially incorporating additional data sources. Another important area for future investigation is the inclusion of mechanisms for improved temporal consistency within the predictions to avoid misalignments of features between frames. Additionally, exploring the method’s performance across a wider range of model architectures and datasets could be beneficial. Finally, a thorough analysis of FACL’s sensitivity to hyperparameters and its computational efficiency, particularly as dataset scales increase, would be a valuable contribution.
More visual insights#
More on figures

🔼 This figure shows the prediction results of the ConvLSTM model trained with MSE and FACL loss functions on the Stochastic Moving-MNIST dataset. The top row displays the input frames, the second row shows the ground truth, the third row shows the predictions using MSE loss, and the bottom row shows the predictions using the proposed FACL loss. The figure visually demonstrates the improved sharpness and quality of predictions achieved by using the FACL loss compared to the MSE loss.
read the caption
Figure 2: Output frames of the ConvLSTM model trained with different losses on Stochastic Moving-MNIST. From top to bottom: Input, Ground Truth, MSE, FACL.
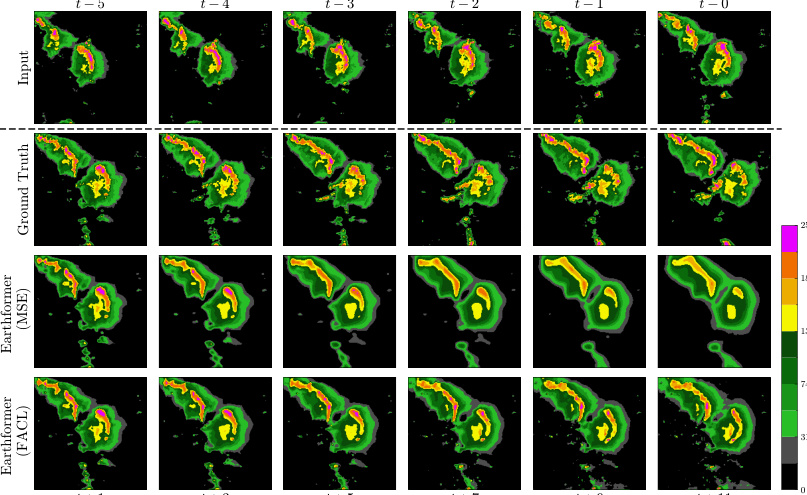
🔼 This figure shows the qualitative results of different models (ConvLSTM, PredRNN, SimVP, Earthformer) trained with MSE and FACL losses on the SEVIR dataset. The figure visually compares the input frames, ground truth, and model predictions for each model and loss function. The goal is to showcase the impact of the FACL loss on the sharpness and accuracy of precipitation nowcasting.
read the caption
Figure 12: Output frames of the experimented model trained with different losses on SEVIR.
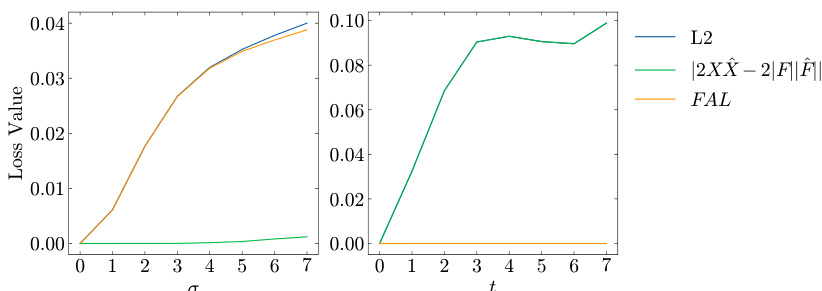
🔼 This figure shows the results of an experiment designed to study the behavior of the FAL loss function’s components under blurring and translation. The left panel shows the values of different loss terms as a function of σ (standard deviation of Gaussian blur). The right panel shows the values as a function of t (translation). The figure illustrates that FAL behaves similarly to standard L2 loss under blurring, but cancels out the L2 loss under translation.
read the caption
Figure 4: FAL loss terms over different values of (left) σ in blurring and (right) t in translation. In (right), L2 (the blue line) and |∑2XX − ∑2|F||F|| (the green line) mostly overlap.

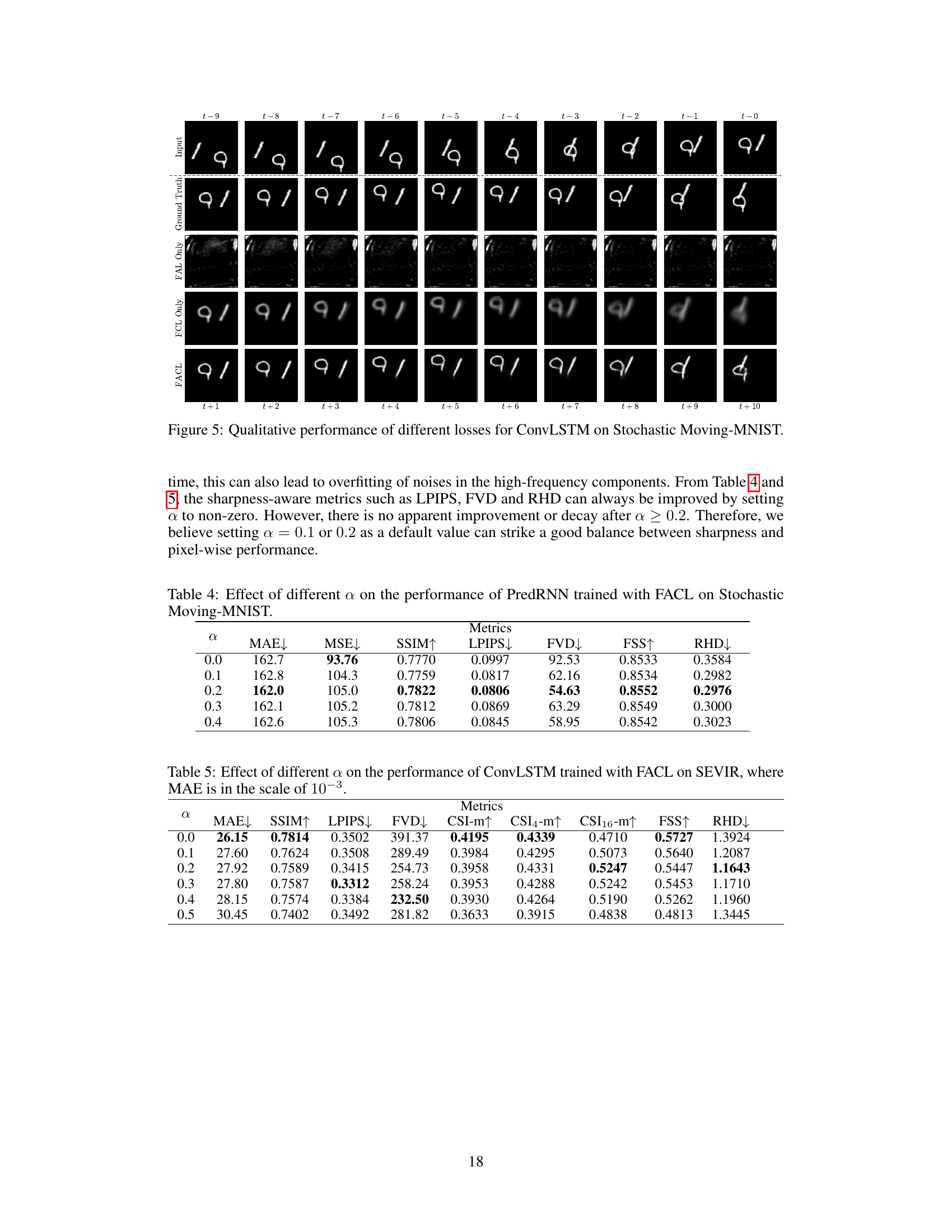
🔼 This figure compares the qualitative performance of different loss functions for the ConvLSTM model on the Stochastic Moving-MNIST dataset. It visually demonstrates the impact of using FAL only, FCL only, and the proposed FACL loss function compared to using MSE, as well as the ground truth. The results show that using only FAL leads to blurry predictions, FCL produces somewhat better results but is still blurry, and FACL yields the sharpest and most accurate results. This is a key result supporting the claims of the paper about the efficacy of the FACL loss function for improved image sharpness and detail preservation in prediction tasks.
read the caption
Figure 5: Qualitative performance of different losses for ConvLSTM on Stochastic Moving-MNIST.

🔼 This figure shows the qualitative results of different loss functions applied to the ConvLSTM model on the Stochastic Moving-MNIST dataset. It demonstrates the impact of the proposed Fourier Amplitude and Correlation Loss (FACL) compared to Mean Squared Error (MSE), FAL (Fourier Amplitude Loss) only, and FCL (Fourier Correlation Loss) only. The images visually illustrate how each loss function affects the model’s ability to predict the movement of digits, highlighting the improvement in sharpness and accuracy achieved by FACL.
read the caption
Figure 5: Qualitative performance of different losses for ConvLSTM on Stochastic Moving-MNIST.

🔼 The figure shows the qualitative results of applying different loss functions (FAL only, FCL only, and FACL) to the ConvLSTM model trained on the Stochastic Moving-MNIST dataset. Each row represents a different loss function, with the ground truth and input shown at the top. The results demonstrate that using only FAL results in blurry and inaccurate predictions, while FCL only achieves some structural similarity, but lacks detail. FACL, which combines both FAL and FCL, achieves the sharpest and most accurate predictions.
read the caption
Figure 5: Qualitative performance of different losses for ConvLSTM on Stochastic Moving-MNIST.
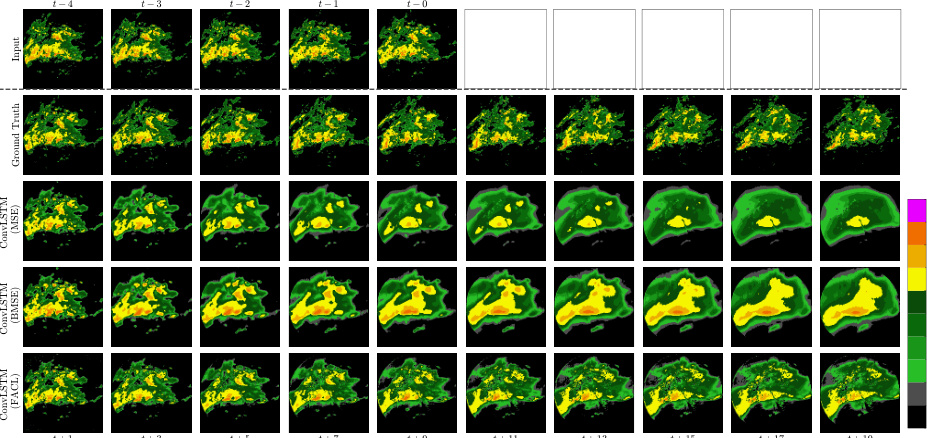
🔼 This figure shows the qualitative results of different models trained with MSE and FACL losses on the HKO-7 dataset. The models are ConvLSTM, PredRNN, SimVP, Earthformer, LDCast, and MCVD. The figure visually compares the model’s predictions to the ground truth for precipitation forecasting. It aims to demonstrate the impact of using FACL in improving the quality and realism of the predictions compared to the standard MSE loss. Specifically, it highlights the ability of FACL to generate sharper and more detailed precipitation patterns.
read the caption
Figure 14: Output frames of the experimented model trained with different losses on HKO-7.

🔼 This figure shows the qualitative results of three different video generative models (SVGLP, STRPM, and MCVD) trained with two different loss functions: MSE and FACL. Each model has two sets of outputs; one trained with MSE and the other trained with FACL. The figure demonstrates the visual differences in the generated video frames between the two loss functions, allowing for a visual comparison of the impact of FACL on the generated output quality. The results are discussed further in Table 11.
read the caption
Figure 9: Output frames of video generative models trained with different losses stated in Table 11 on Stochastic Moving-MNIST.

🔼 This figure visualizes the effects of different image transformations on a sample radar image. It shows the original image and transformed versions demonstrating Gaussian blur, translation, rotation, conditional brightening, and conditional darkening. These transformations are used in the paper to evaluate the robustness and sensitivity of different image similarity metrics.
read the caption
Figure 10. Visualization of different transformation techniques applied on the radar image.
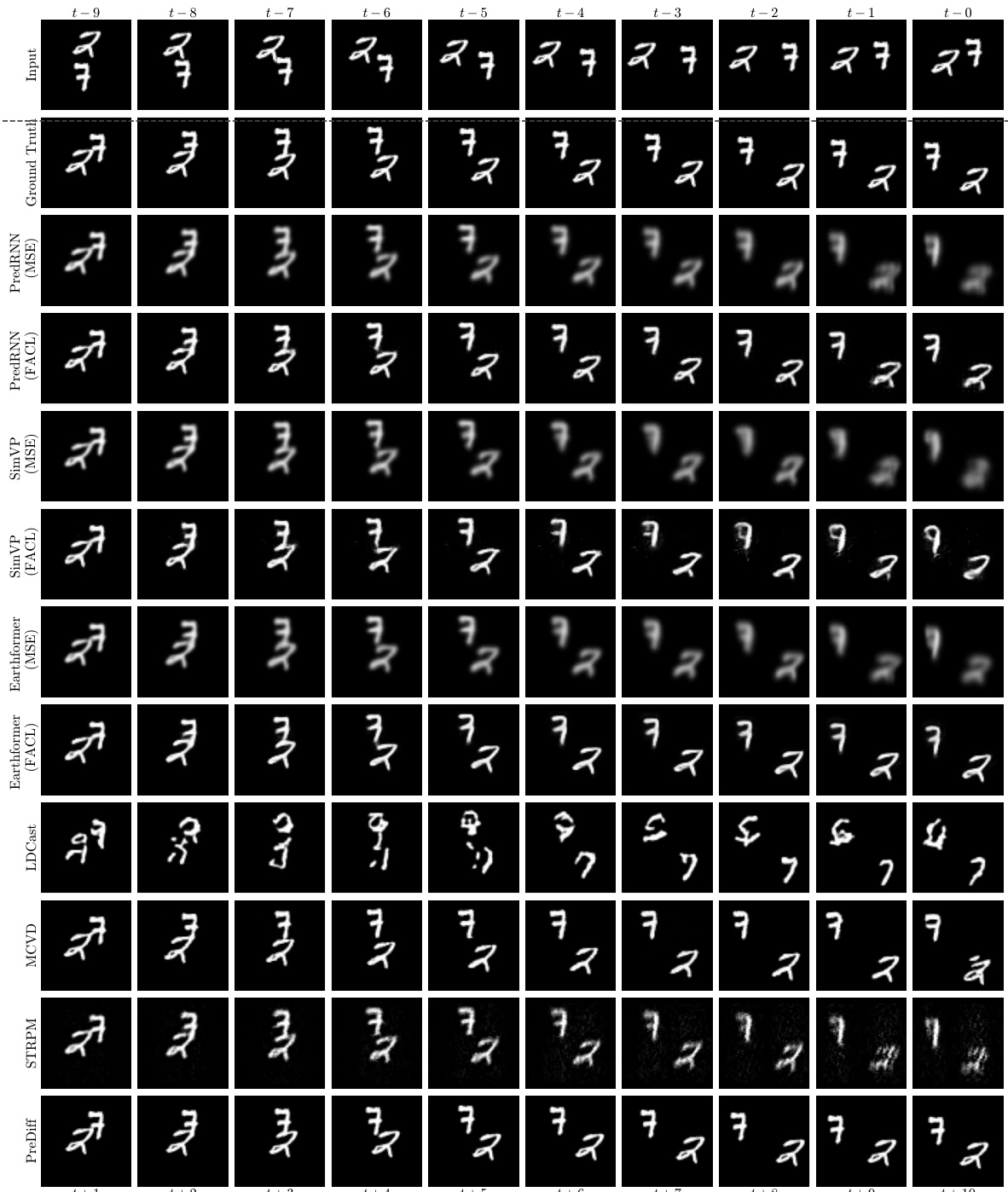
🔼 This figure shows the prediction results of different models (ConvLSTM, PredRNN, SimVP, Earthformer, LDCast, MCVD, STRPM, PreDiff) trained with either MSE or FACL loss on the Stochastic Moving-MNIST dataset. It demonstrates the visual differences in prediction quality, particularly regarding sharpness and detail, between the two loss functions. The extra frames for LDCast are generated using autoregressive inference. The figure is intended to showcase the effectiveness of FACL in generating sharper, more realistic predictions compared to MSE, especially in handling complex movements.
read the caption
Figure 11: Output frames of the experimented model trained with different losses on Stochastic Moving-MNIST. The extra frames of LDCast are generated with auto-regressive inference.
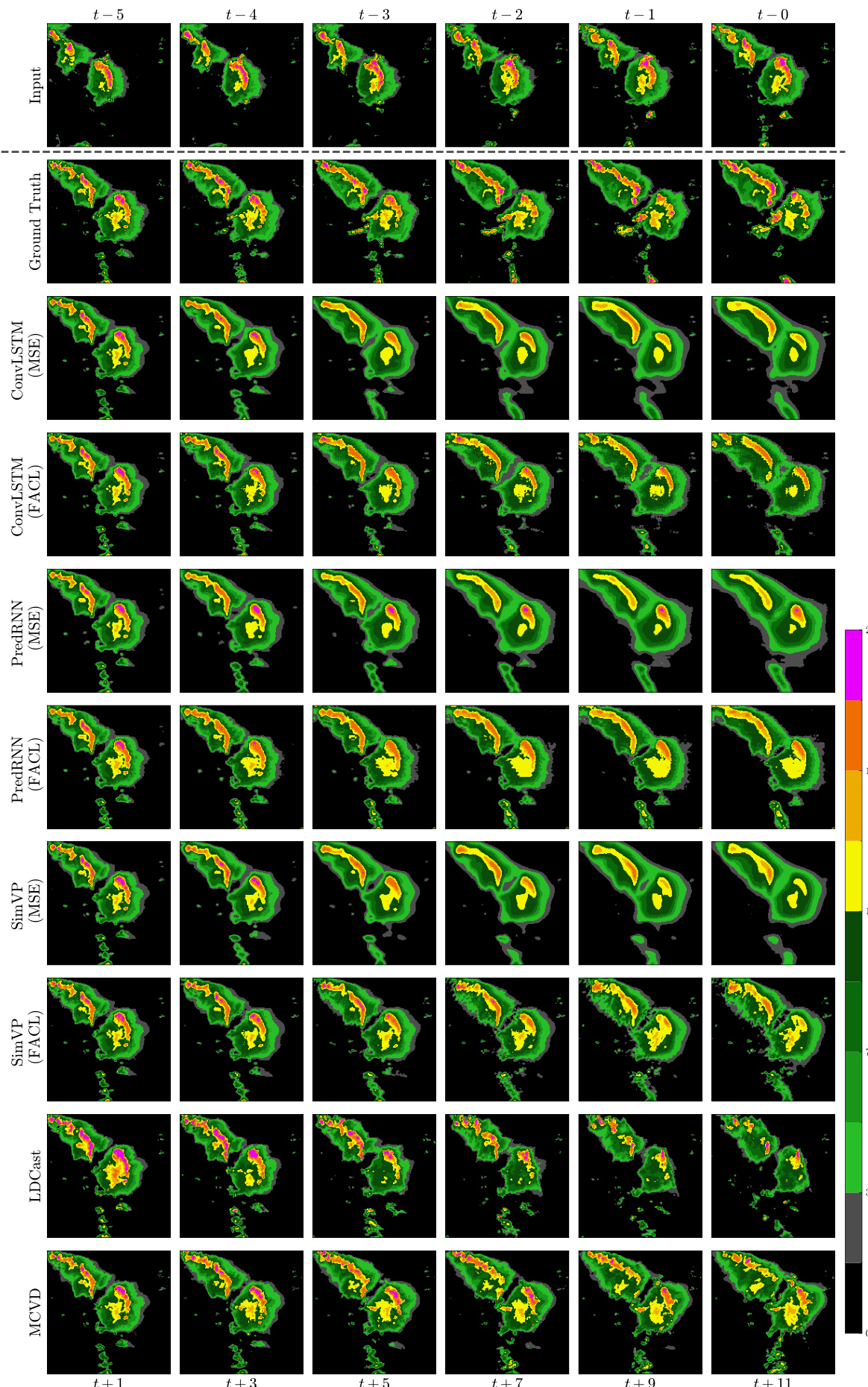
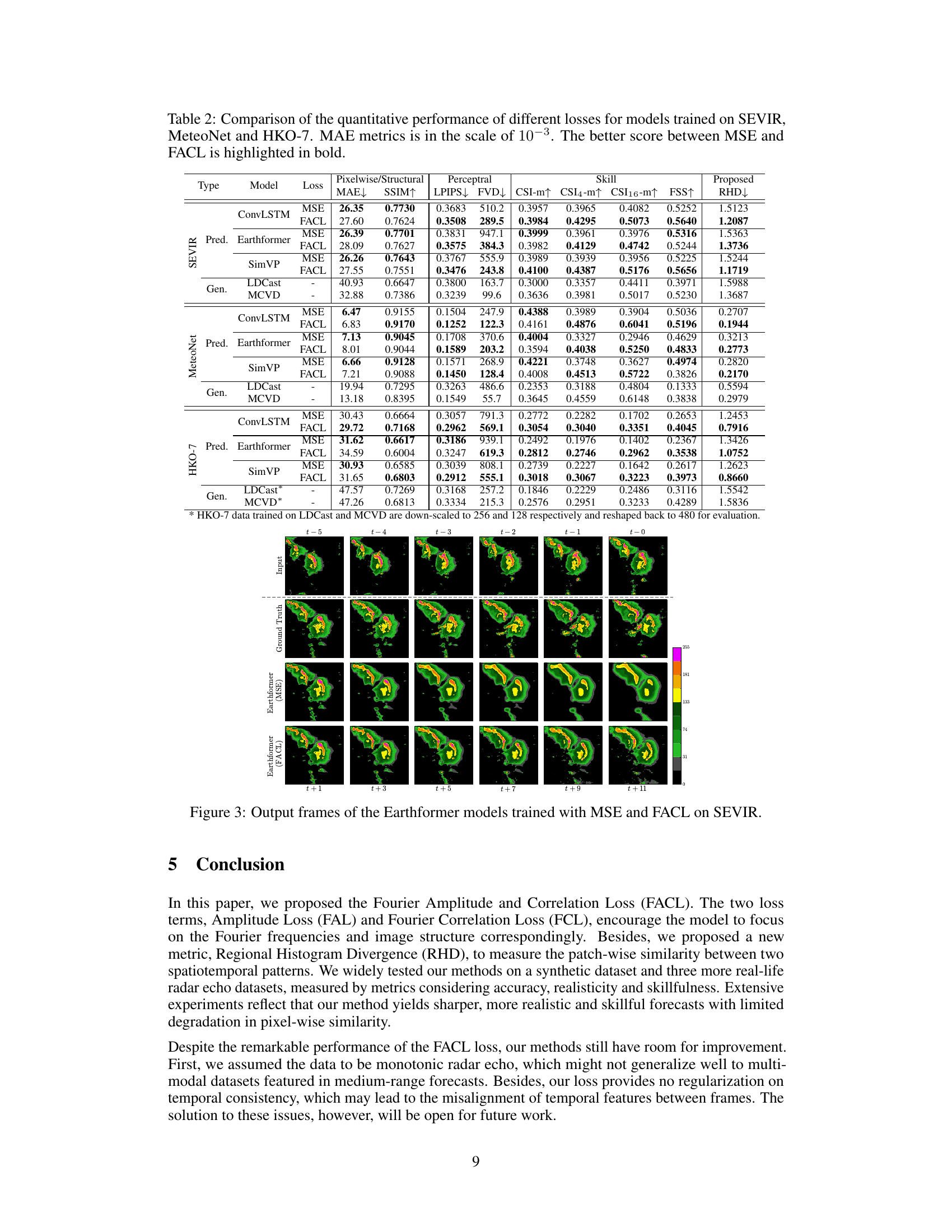
🔼 This figure shows the outputs of different models (ConvLSTM, PredRNN, SimVP, Earthformer, LDCast, MCVD) trained with MSE and FACL losses on the SEVIR dataset. Each row represents a different model, and each column represents a time step (from t=-5 to t=+11). The figure demonstrates the impact of using the Fourier Amplitude and Correlation Loss (FACL) on the prediction quality, showing how FACL generally produces sharper and more realistic precipitation forecasts compared to the standard MSE loss. The ground truth and input sequences are also shown for comparison.
read the caption
Figure 12: Output frames of the experimented model trained with different losses on SEVIR.

🔼 This figure visualizes the prediction results of different models (ConvLSTM, PredRNN, SimVP, Earthformer, LDCast, MCVD) trained with MSE and FACL losses on the SEVIR dataset. Each row represents a different model, and each column shows the model’s prediction for a specific time step. The input and ground truth are also shown for comparison. It demonstrates a qualitative comparison of the models’ performance in terms of precipitation nowcasting accuracy and visual quality. The FACL models generally produce sharper and more realistic-looking predictions.
read the caption
Figure 12: Output frames of the experimented model trained with different losses on SEVIR.

🔼 This figure shows the prediction results of different models (ConvLSTM, PredRNN, SimVP, Earthformer, LDCast, MCVD) trained with MSE and FACL losses on the SEVIR dataset. Each row represents a different model, and each column represents a time step in the forecast. The ground truth and input frames are also shown. The figure aims to visually compare the performance of MSE and FACL in terms of precipitation nowcasting accuracy and sharpness across different model architectures.
read the caption
Figure 12: Output frames of the experimented model trained with different losses on SEVIR.
More on tables
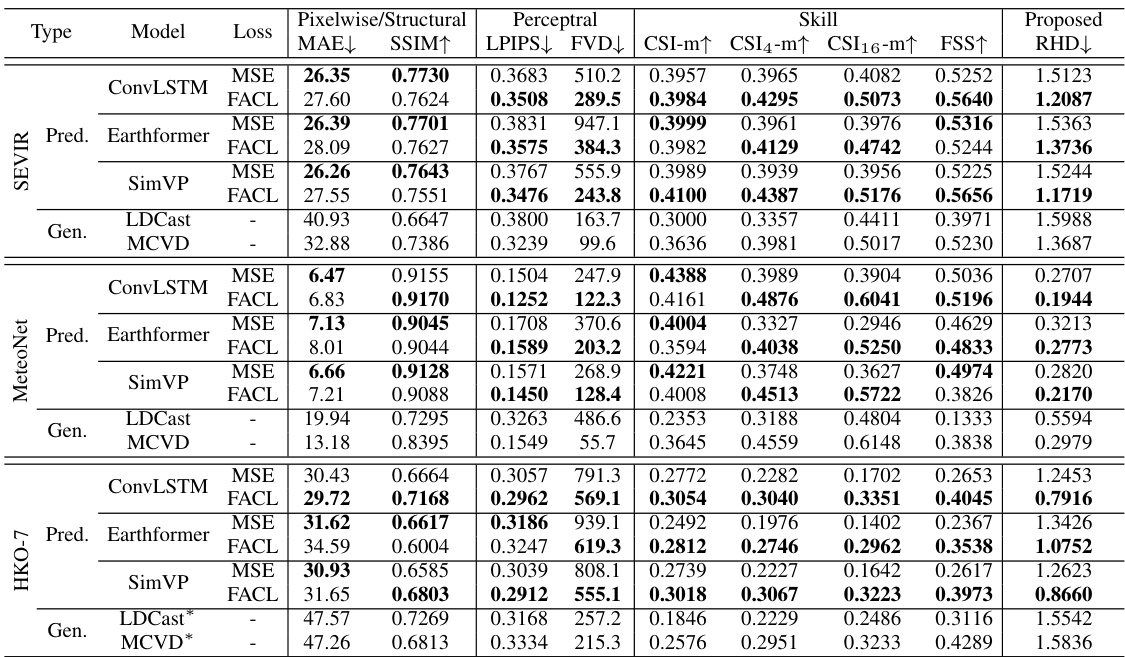
🔼 This table presents a comparison of different loss functions (MSE and FACL) on three different radar-based datasets (SEVIR, MeteoNet, and HKO-7) using various models. The metrics used to evaluate performance include pixel-wise metrics (MAE, SSIM), perceptual metrics (LPIPS, FVD), and meteorological skill scores (CSI, FSS, RHD). The table helps in understanding the impact of FACL on improving the quality and skillfulness of precipitation nowcasting.
read the caption
Table 2: Comparison of the quantitative performance of different losses for models trained on SEVIR, MeteoNet and HKO-7. MAE metrics is in the scale of 10-3. The better score between MSE and FACL is highlighted in bold.

🔼 This table presents the quantitative results of the ablation study performed on the ConvLSTM model trained on the Stochastic Moving-MNIST dataset. It compares the performance of three different loss functions: using only the Fourier Amplitude Loss (FAL), using only the Fourier Correlation Loss (FCL), and using the combined Fourier Amplitude and Correlation Loss (FACL). The metrics used to evaluate the performance include MAE, MSE, SSIM, LPIPS, FVD, FSS, and RHD. Lower values for MAE, MSE, LPIPS, FVD, and RHD indicate better performance, while higher values for SSIM and FSS indicate better performance.
read the caption
Table 3: Quantitative performance of different losses for ConvLSTM on Stochastic Moving-MNIST.
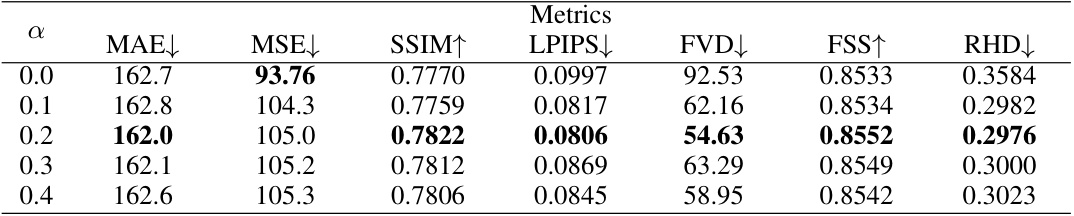
🔼 This table presents the ablation study of the hyperparameter α in the proposed FACL loss function. It shows the impact of varying α on multiple evaluation metrics (MAE, MSE, SSIM, LPIPS, FVD, FSS, RHD) for the PredRNN model trained on the Stochastic Moving-MNIST dataset. The results demonstrate how the random selection between FAL and FCL, controlled by α, affects the model’s performance in terms of pixel-wise accuracy, perceptual similarity, and meteorological skill scores. The optimal value of α balances sharpness and accuracy.
read the caption
Table 4: Effect of different α on the performance of PredRNN trained with FACL on Stochastic Moving-MNIST.
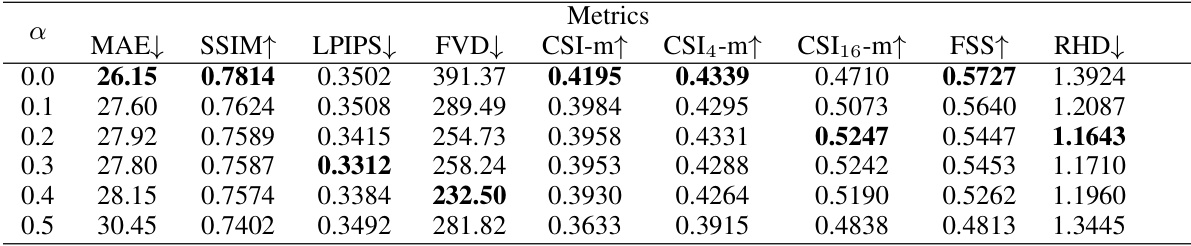
🔼 This table presents the quantitative performance results of the ConvLSTM model trained with the Fourier Amplitude and Correlation Loss (FACL) on the SEVIR dataset. It shows how different values of the hyperparameter α affect various metrics, including Mean Absolute Error (MAE), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), Fréchet Video Distance (FVD), Critical Success Index (CSI) with different pooling sizes (CSI-m, CSI4-m, CSI16-m), Fractional Skill Score (FSS), and Regional Histogram Divergence (RHD). The results illustrate the trade-off between sharpness and other aspects of prediction quality as α is varied.
read the caption
Table 5: Effect of different α on the performance of ConvLSTM trained with FACL on SEVIR, where MAE is in the scale of 10⁻³.
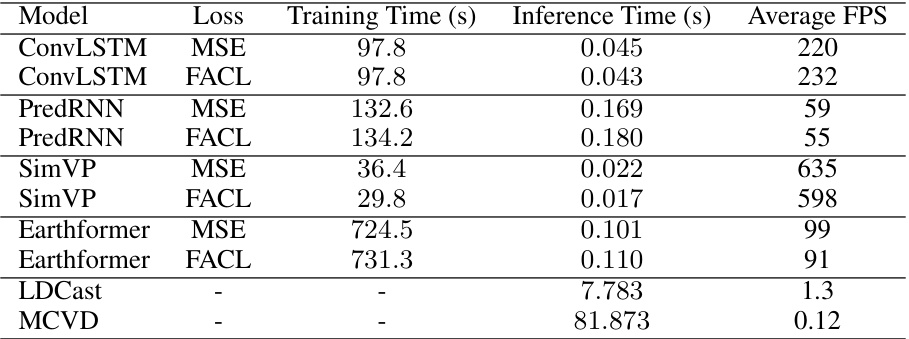
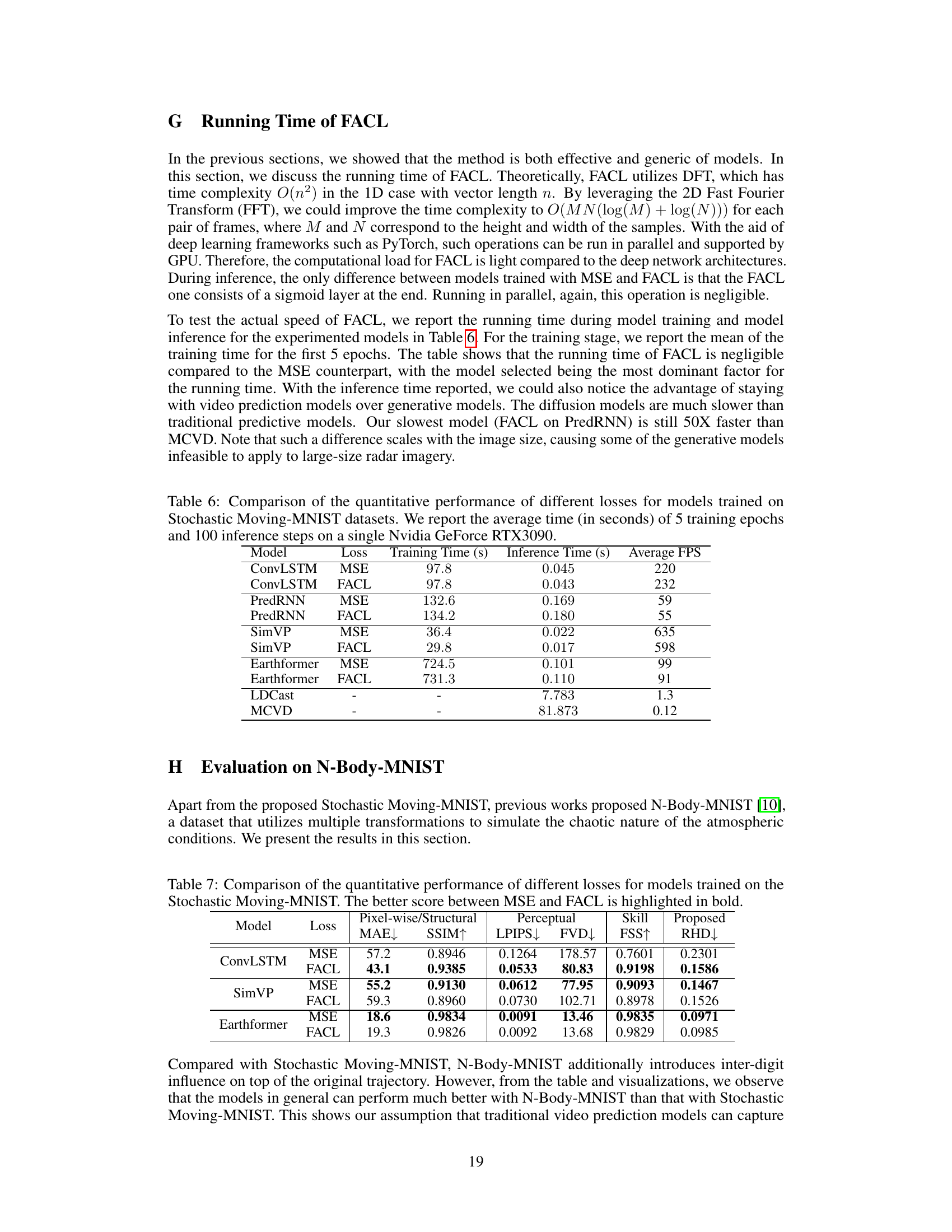
🔼 This table compares the training and inference time of different models (ConvLSTM, PredRNN, SimVP, Earthformer, LDCast, and MCVD) trained with either MSE or FACL loss. The experiments were conducted on a single Nvidia GeForce RTX 3090 GPU, and the results represent the average time taken for 5 training epochs and 100 inference steps.
read the caption
Table 6: Comparison of the quantitative performance of different losses for models trained on Stochastic Moving-MNIST datasets. We report the average time (in seconds) of 5 training epochs and 100 inference steps on a single Nvidia GeForce RTX3090.
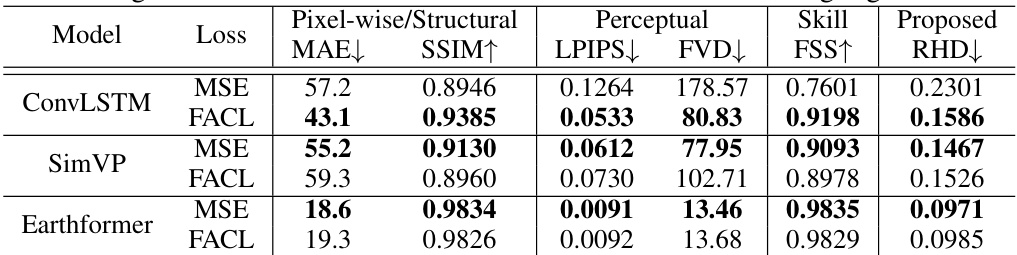
🔼 This table compares the performance of different loss functions (MSE and FACL) on various models (ConvLSTM, SimVP, Earthformer) trained on the Stochastic Moving-MNIST dataset. It evaluates pixel-wise metrics (MAE, SSIM), perceptual metrics (LPIPS, FVD), meteorological skill scores (FSS), and the proposed RHD metric. The bold values indicate the better performance between MSE and FACL for each model and metric.
read the caption
Table 7: Comparison of the quantitative performance of different losses for models trained on the Stochastic Moving-MNIST. The better score between MSE and FACL is highlighted in bold.
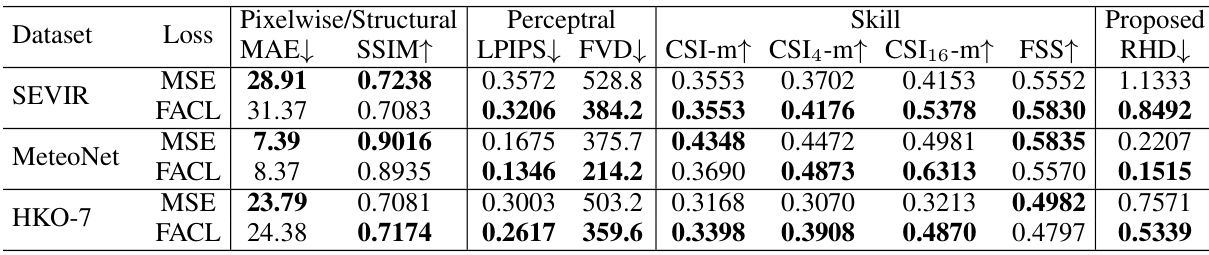
🔼 This table compares the performance of models trained with Mean Squared Error (MSE) loss and Fourier Amplitude and Correlation Loss (FACL) across three different radar-based datasets: SEVIR, MeteoNet, and HKO-7. It evaluates pixel-wise metrics (MAE, SSIM), perceptual metrics (LPIPS, FVD), meteorological skill scores (CSI with varying pooling sizes, FSS), and the proposed Regional Histogram Divergence (RHD). The best-performing loss (MSE or FACL) for each metric is indicated in bold. This allows for a comparison of the effectiveness of the proposed FACL loss against the standard MSE loss in various contexts.
read the caption
Table 2: Comparison of the quantitative performance of different losses for models trained on SEVIR, MeteoNet and HKO-7. MAE metrics is in the scale of 10-3. The better score between MSE and FACL is highlighted in bold.
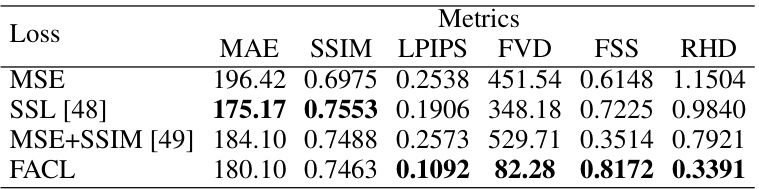
🔼 This table compares the performance of different loss functions (MSE, SSL, MSE+SSIM, and FACL) when training a ConvLSTM model on the Stochastic Moving-MNIST dataset. The metrics evaluated include MAE, SSIM, LPIPS, FVD, FSS, and RHD, providing a comprehensive assessment of the model’s performance in terms of pixel-wise accuracy, structural similarity, perceptual quality, and skillfulness. The results help determine which loss function best balances various aspects of performance for this specific model and dataset.
read the caption
Table 9: Comparison of the quantitative performance of different losses for ConvLSTM trained on Stochastic Moving-MNIST.

🔼 This table compares the performance of different loss functions (MSE and FACL) on three different radar-based datasets (SEVIR, MeteoNet, and HKO-7) across multiple models. The metrics used to evaluate performance include pixel-wise metrics (MAE, SSIM), perceptual metrics (LPIPS, FVD), and meteorological skill scores (CSI with different pooling sizes, FSS, RHD). The table highlights the better-performing loss function (MSE or FACL) for each metric and dataset combination.
read the caption
Table 2: Comparison of the quantitative performance of different losses for models trained on SEVIR, MeteoNet and HKO-7. MAE metrics is in the scale of 10-3. The better score between MSE and FACL is highlighted in bold.
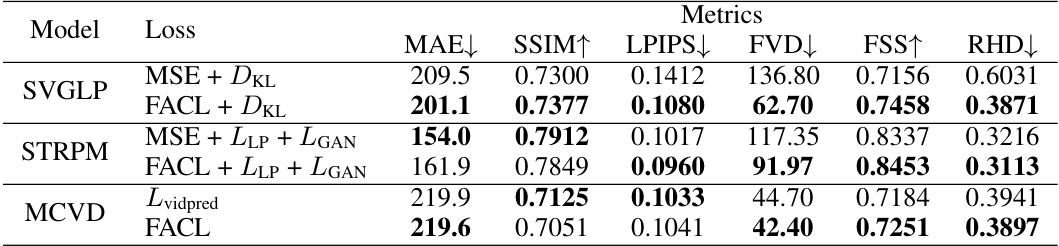
🔼 This table presents the quantitative results of three different generative models (SVGLP, STRPM, and MCVD) trained on the Stochastic Moving-MNIST dataset using two different loss functions: the original loss function of each model and the proposed Fourier Amplitude and Correlation Loss (FACL). The metrics used for comparison include Mean Absolute Error (MAE), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), Fréchet Video Distance (FVD), Fractional Skill Score (FSS), and Regional Histogram Divergence (RHD). The table shows the impact of replacing the original loss functions with FACL on the performance of the generative models.
read the caption
Table 11: Quantitative performance of SVGLP, STRPM and MCVD with different loss, trained on the Stochastic Moving-MNIST.

🔼 This table compares the performance of different metrics (MAE, MSE, SSIM, LPIPS, CSI-m, CSI4-m, CSI16-m, FSS, and RHD) across various image transformations (blurring, translation, rotation, brightening, and darkening). It highlights how each metric responds to different types of image alterations, showcasing their strengths and weaknesses. The best performing metric for each transformation is shown in bold, while the worst performing metric is underlined. This allows for a comparative analysis of the suitability of various metrics for evaluating the quality of nowcasting predictions under different error conditions.
read the caption
Table 12: The values of different metrics on different transformations, where MAE and MSE are in the scale of 10-3. The worst score for each metric under the tested distortions is underlined and the best score is in bold.

🔼 This table compares the performance of models trained using Mean Squared Error (MSE) loss and the proposed Fourier Amplitude and Correlation Loss (FACL) on the Stochastic Moving-MNIST dataset. It evaluates pixel-wise metrics (MAE, SSIM), perceptual metrics (LPIPS, FVD), and skill scores (FSS, RHD). The bold values indicate which loss function (MSE or FACL) performed better for each metric.
read the caption
Table 1: Comparison of the quantitative performance of different losses for models trained on the Stochastic Moving-MNIST. The better score between MSE and FACL is highlighted in bold.
Full paper#