TL;DR#
Visual reinforcement learning (RL) agents often struggle to generalize to new environments with dynamic visual changes. This is mainly due to two issues: imbalanced saliency, where agents focus disproportionately on recent frames in a sequence, and observational overfitting, where agents fixate on irrelevant background features. Previous approaches using domain randomization and data augmentation have not fully addressed these issues, leading to subpar generalization performance in complex environments.
To overcome these limitations, the authors propose a simple yet effective framework called SimGRL. This framework introduces two key strategies: a feature-level frame stack that modifies the image encoder, helping agents focus on salient features across frames, and a shifted random overlay augmentation that makes agents robust to dynamic backgrounds. SimGRL demonstrates superior generalization capability on several benchmarks and sets a new state-of-the-art. The introduced Task-Identification (TID) metrics are also noteworthy, providing a new quantitative way to analyze the issues of imbalanced saliency and observational overfitting.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles a critical challenge in visual reinforcement learning: generalization under dynamic scene perturbations. It offers a simple yet effective framework (SimGRL) that achieves state-of-the-art results, making it highly relevant to researchers working on robust and adaptable AI agents. The introduction of new metrics for evaluating the ability of RL agents to discriminate salient regions also contributes to advancements in the field. The research opens avenues for developing more robust and generalized AI agents, applicable across domains.
Visual Insights#

🔼 This figure shows the average performance of SimGRL and other algorithms on six tasks in the DeepMind Control Suite generalization benchmark (DMControl-GB). SimGRL shows robust performance even in the challenging ‘Video Hard’ condition. Parts (b) and (c) illustrate two key problems that hinder generalization in visual reinforcement learning: imbalanced saliency (where the agent focuses disproportionately on recent frames) and observational overfitting (where the agent focuses on irrelevant background features).
read the caption
Figure 1: (a) Average performances on 6 tasks in DMControl-GB. In contrast to other methods with significant performance degradation in Video Hard, our proposed SimGRL demonstrates robust performance across all benchmarks. (b)-(c) Examples of two problematic phenomena that can cause overfitting in visual RL generalization. The background structures in the red boxes are correlated with the movement of the task object. s and Mp represent the stacked frames and attribution masks, respectively. Attribution masks in this figure were obtained using the critic trained by DrQ [40].

🔼 This table compares the performance of SimGRL against other state-of-the-art methods on six tasks within the DeepMind Control Suite-Generalization Benchmark (DMControl-GB) dataset. The results are presented separately for the ‘Video Easy’ and ‘Video Hard’ subsets, which vary in the level of background perturbation. The table shows average scores and standard deviations across five random seeds, offering a robust comparison. The Δ column quantifies SimGRL’s improvement over the second-best performing method for each task.
read the caption
Table 1: Generalization performance on video benchmarks from DMControl-GB [13]. We report the results on mean and standard deviation over 5 seeds. The scores of the comparison methods were taken from their respective papers, and in cases where the scores were unavailable, they were obtained through our implementation using the official codes. Δ indicates the difference with second best.
In-depth insights#
Visual RL Limits#
Visual reinforcement learning (RL) holds immense potential, but its application is currently hindered by several limitations. Data efficiency remains a major obstacle; training visual RL agents often necessitates massive datasets and significant computational resources. The high dimensionality of visual inputs exacerbates this, leading to overfitting and poor generalization to unseen environments. Imbalanced saliency, where agents disproportionately focus on certain visual features, further compromises performance and robustness. Addressing the partial observability inherent in many visual RL scenarios poses another challenge, impacting an agent’s ability to make informed decisions. Finally, the lack of strong theoretical guarantees surrounding the generalization ability of learned policies represents a key area for future research. Overcoming these limitations is crucial for realizing the full transformative potential of visual RL.
SimGRL Framework#
The SimGRL framework tackles the challenge of generalization in visual reinforcement learning (RL) under dynamic scene perturbations. It addresses two key issues: imbalanced saliency (where agents disproportionately focus on recent frames in a stack) and observational overfitting (where agents overemphasize irrelevant background features). SimGRL’s core innovation is a two-pronged approach: it employs a feature-level frame stack in the image encoder, processing frames individually at lower layers before stacking features, mitigating imbalanced saliency by enabling the network to learn spatially salient features in individual frames. In addition, it leverages a novel shifted random overlay augmentation technique which injects dynamic, task-irrelevant background changes during training, forcing the agent to learn robust representations less sensitive to observational overfitting. The results demonstrate that SimGRL achieves state-of-the-art performance on several benchmark environments, showcasing its effectiveness and simplicity.
TID Metrics#
The proposed TID (Task-Identification) metrics offer a novel way to quantitatively evaluate the ability of a visual reinforcement learning (RL) agent to identify task-relevant objects within visual input. Instead of relying solely on overall performance metrics, TID directly assesses the model’s discrimination capability by analyzing attribution masks. This provides valuable insights into two key issues hindering visual RL generalization: imbalanced saliency and observational overfitting. The TID score measures the extent to which the model correctly identifies task object pixels across stacked frames. The TID variance assesses the model’s discriminative ability, indicating its consistency in focusing on relevant objects. By combining both the score and variance, TID provides a comprehensive evaluation. This granular analysis is particularly useful in situations where dynamic scene perturbations influence saliency, making it difficult to understand the cause of generalization failure with traditional metrics. Therefore, TID metrics are a crucial tool to understand and improve generalization performance in visual RL.
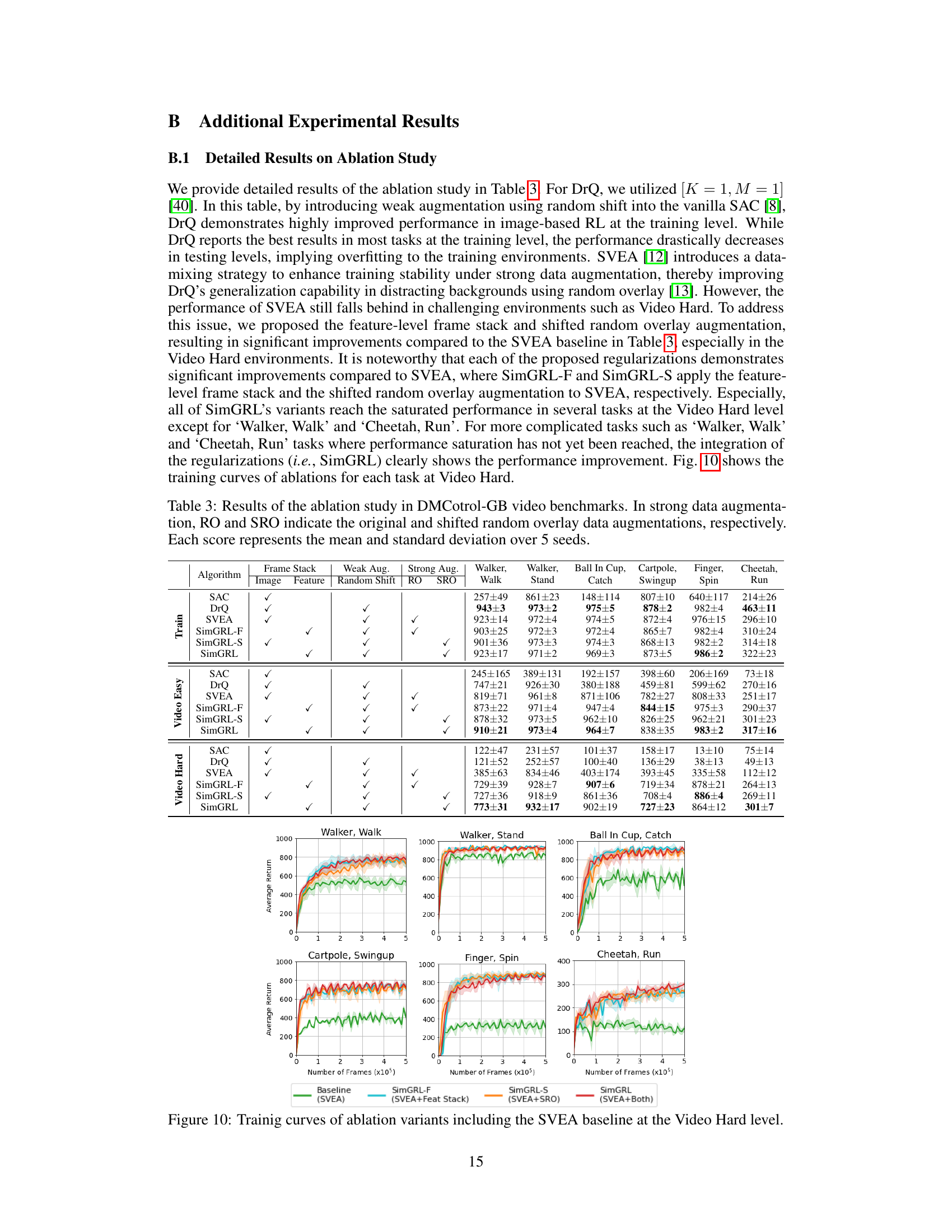
Ablation Study#
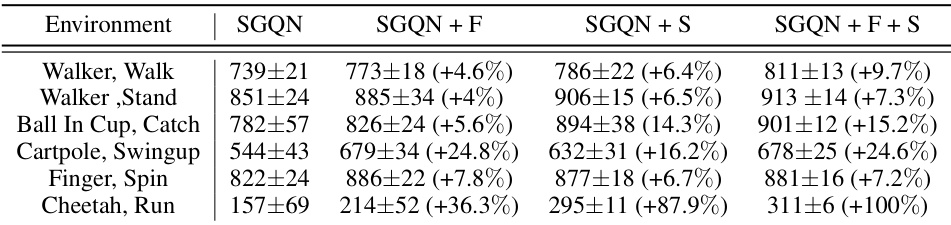
An ablation study systematically removes components of a model to assess their individual contributions. In a reinforcement learning (RL) context like this paper, this might involve removing different augmentation techniques (like shifted random overlays or random cropping) or architectural modifications (like feature-level frame stacking). The results would reveal the impact of each component on the model’s overall performance, specifically its generalization capabilities. A well-designed ablation study provides crucial insights into the model’s design choices, justifying why specific components were included. The absence of a particular component in the study and its impact on generalization is a key element of the analysis and should be discussed thoroughly. This allows for a deeper understanding of which components are most effective for achieving robust and generalizable RL policies, aiding in future model improvements and refinement. The paper should explicitly state the baseline methodology used for comparison, which is then modified through the removal of specific components. This approach leads to a controlled and precise assessment of the contribution of each individual part and helps to understand how the components interact with each other. The ablation study should also include a discussion of any unexpected or counterintuitive results observed during the process; such insights can uncover new and potentially valuable information.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Extending SimGRL to more complex visual RL tasks beyond the DeepMind Control Suite is crucial to demonstrate its broader applicability and robustness. This could involve tasks with increased visual complexity, higher dimensionality, or requiring more sophisticated planning. Investigating alternative augmentation strategies alongside shifted random overlay might lead to further performance gains or robustness against diverse visual perturbations. A systematic evaluation of different augmentation techniques, perhaps guided by theoretical analysis, is warranted. The interplay between architectural modifications and data augmentations also deserves further study. For example, exploring other architectural changes to image encoders or other network components might complement or replace the proposed feature-level frame stack. Finally, developing more sophisticated metrics for evaluating generalization performance beyond the proposed TID metrics is essential to gain deeper insights into the nature of generalization in visual RL. This could include developing metrics that explicitly capture temporal dependencies, higher-level visual features, or the agent’s ability to extrapolate beyond previously seen visual patterns.
More visual insights#
More on figures

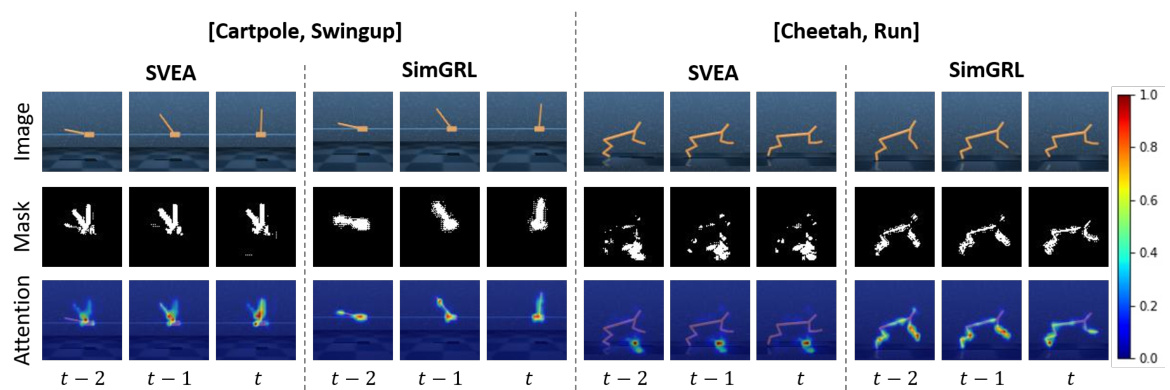
🔼 This figure shows examples of attribution masks and the corresponding masked frames for the ‘Cartpole, Swingup’ and ‘Cheetah, Run’ tasks. It compares the performance of SVEA and SimGRL. SimGRL demonstrates better accuracy in identifying salient pixels, even in challenging environments, indicating its improved ability to avoid imbalanced saliency and observational overfitting.
read the caption
Figure 2: Examples of attribution masks and masked frames. Compared to SVEA that falls into the imbalanced saliency and observation overfitting in the 'Cartpole, Swingup' and 'Cheetah, Run' tasks, respectively, the proposed SimGRL accurately identifies the true salient pixels even in challenging 'Video Hard' test environments of DMControl-GB. We provide further examples of the attribution masks and masked salient regions for various environments and algorithms in Appendix F.4.

🔼 This figure illustrates the process of the Shifted Random Overlay (SRO) data augmentation technique. A natural image is sampled from a dataset. Multiple shifted patches are cropped from this image. These patches are then overlaid onto the original image frames of the RL input, using a blending factor (alpha). This injects dynamic background changes into the training data, improving the model’s robustness to real-world scenarios with dynamic backgrounds.
read the caption
Figure 3: Shifted random overlay (SRO) augmentation for data regularization. To inject random dynamics into the backgrounds of RL input images, we generate multiple cropped patches in a shifted manner from a sampled natural image and interpolate them to augment the input images.

🔼 This figure illustrates the SimGRL framework, highlighting the key components and their interactions. The framework builds upon SVEA, incorporating two novel strategies: a feature-level frame stack and shifted random overlay augmentation. The figure shows the data flow, including the processing of both clean and augmented states, the use of the encoder and critic networks to estimate Q-values, and the optimization process using a data-mixing strategy. Differences from the SVEA architecture are clearly marked in red, emphasizing the modifications introduced in SimGRL.
read the caption
Figure 4: Overview of the Simple framework for Generalization in visual RL (SimGRL) under dynamic scene perturbations. Differences from SVEA are marked in red.
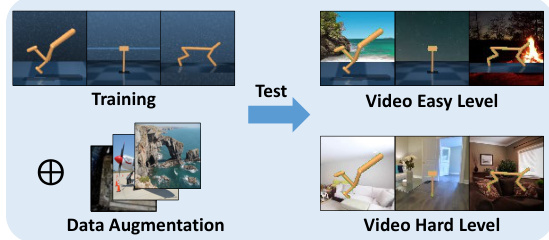
🔼 This figure illustrates the experimental setup used to evaluate the generalization capabilities of the SimGRL model. The training environment is shown with a simple background, while the test environment includes both ‘Video Easy’ and ‘Video Hard’ levels. The Video Easy level consists of environments with backgrounds that share some visual similarities with the training environment, whereas the Video Hard level consists of environments with completely different backgrounds, introducing dynamic scene perturbations. Data augmentation, represented by the ‘+’ symbol, is applied during training to improve generalization performance.
read the caption
Figure 5: Experimental setup. We evaluated the zero-shot performances for test environments with dynamic background perturbations.
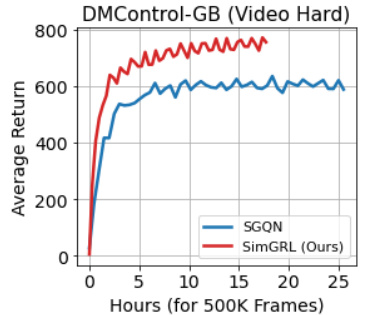
🔼 This figure compares the training curves of SGQN and SimGRL (the proposed method) on the DMControl-GB (Video Hard) benchmark. The x-axis represents the wall-clock training time in hours for 500K frames, and the y-axis shows the average return. SimGRL demonstrates significantly faster convergence and a higher final average return compared to SGQN, highlighting its improved training efficiency and generalization performance.
read the caption
Figure 6: Training curves at wall-clock time axis.
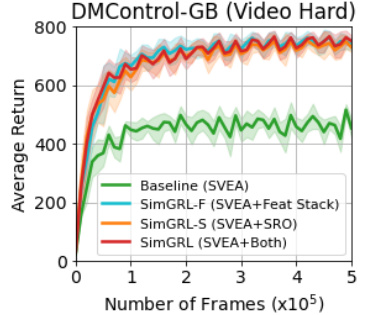
🔼 This figure shows the training curves for ablation variants of the SimGRL algorithm on the DMControl-GB benchmark’s Video Hard level. It compares the performance of the baseline SVEA algorithm with three ablation variants: SimGRL-F (adding feature-level frame stack to SVEA), SimGRL-S (adding shifted random overlay augmentation to SVEA), and SimGRL (combining both feature-level frame stack and shifted random overlay). The x-axis shows the number of training frames (in 105) and the y-axis is the average return. The plot illustrates the impact of each regularization technique on the algorithm’s ability to generalize to unseen environments, with SimGRL achieving the highest performance.
read the caption
Figure 7: Training curves for ablation variants.

🔼 This figure shows a comparison of the average performance of SimGRL and other algorithms on six tasks from the DeepMind Control Suite generalization benchmark (DMControl-GB). SimGRL shows consistently high performance across all tasks, unlike other algorithms which experience significant performance degradation in the more challenging ‘Video Hard’ tasks. The figure also illustrates two problems identified in existing visual RL generalization approaches: imbalanced saliency (where the agent focuses disproportionately on recent frames) and observational overfitting (where the agent focuses on irrelevant background features).
read the caption
Figure 1: (a) Average performances on 6 tasks in DMControl-GB. In contrast to other methods with significant performance degradation in Video Hard, our proposed SimGRL demonstrates robust performance across all benchmarks. (b)-(c) Examples of two problematic phenomena that can cause overfitting in visual RL generalization. The background structures in the red boxes are correlated with the movement of the task object. s and Mp represent the stacked frames and attribution masks, respectively. Attribution masks in this figure were obtained using the critic trained by DrQ [40].

🔼 This figure shows example images augmented using the Shifted Random Overlay (SRO) data augmentation technique. SRO injects random dynamics from natural images into the backgrounds of the training images to improve the robustness of the RL agent to changes in the background. The figure visually demonstrates how SRO modifies the input images by overlaying shifted patches from randomly sampled natural images, thereby simulating a dynamic environment during training.
read the caption
Figure 9: Examples of augmented images using shifted random overlay (SRO).

🔼 This figure shows the average performance comparison of SimGRL and other algorithms on six tasks in DeepMind Control Suite generalization benchmark. SimGRL shows significantly better performance than others especially in the ‘Video Hard’ setting. The figure also illustrates two common issues in visual reinforcement learning, ‘imbalanced saliency’ and ‘observational overfitting’, which are illustrated using examples from Cartpole Swingup and Cheetah Run tasks respectively. Imbalanced saliency shows the agent’s focus on the latest frames of a frame stack and overfitting shows the agent focusing on background features rather than the task-relevant objects.
read the caption
Figure 1: (a) Average performances on 6 tasks in DMControl-GB. In contrast to other methods with significant performance degradation in Video Hard, our proposed SimGRL demonstrates robust performance across all benchmarks. (b)-(c) Examples of two problematic phenomena that can cause overfitting in visual RL generalization. The background structures in the red boxes are correlated with the movement of the task object. s and Mp represent the stacked frames and attribution masks, respectively. Attribution masks in this figure were obtained using the critic trained by DrQ [40].

🔼 This figure shows examples of attribution masks (visualizations of which parts of the input image the model is paying attention to) and the corresponding masked frames for the ‘Cartpole, Swingup’ and ‘Cheetah, Run’ tasks. It compares the results of SVEA and SimGRL, highlighting how SimGRL successfully identifies and focuses on task-relevant objects, while SVEA suffers from imbalanced saliency and observational overfitting, especially in the more challenging environment.
read the caption
Figure 2: Examples of attribution masks and masked frames. Compared to SVEA that falls into the imbalanced saliency and observation overfitting in the 'Cartpole, Swingup' and 'Cheetah, Run' tasks, respectively, the proposed SimGRL accurately identifies the true salient pixels even in challenging 'Video Hard' test environments of DMControl-GB. We provide further examples of the attribution masks and masked salient regions for various environments and algorithms in Appendix F.4.

🔼 This figure shows a comparison of attribution masks generated by SVEA and SimGRL for the ‘Cartpole, Swingup’ and ‘Cheetah, Run’ tasks. SVEA suffers from imbalanced saliency and observational overfitting, focusing disproportionately on certain background regions rather than task-relevant objects in the stacked frames. In contrast, SimGRL accurately identifies the relevant features even in the challenging Video Hard test environments.
read the caption
Figure 2: Examples of attribution masks and masked frames. Compared to SVEA that falls into the imbalanced saliency and observation overfitting in the 'Cartpole, Swingup' and 'Cheetah, Run' tasks, respectively, the proposed SimGRL accurately identifies the true salient pixels even in challenging 'Video Hard' test environments of DMControl-GB. We provide further examples of the attribution masks and masked salient regions for various environments and algorithms in Appendix F.4.

🔼 The figure shows the average performance of SimGRL and other algorithms on six DMControl-GB tasks. SimGRL shows superior performance compared to other methods in the ‘Video Hard’ scenario, where there are dynamically changing backgrounds. Subfigures (b) and (c) illustrate the issues of imbalanced saliency and observational overfitting, respectively, which hinder generalization in visual RL.
read the caption
Figure 1: (a) Average performances on 6 tasks in DMControl-GB. In contrast to other methods with significant performance degradation in Video Hard, our proposed SimGRL demonstrates robust performance across all benchmarks. (b)-(c) Examples of two problematic phenomena that can cause overfitting in visual RL generalization. The background structures in the red boxes are correlated with the movement of the task object. s and Mp represent the stacked frames and attribution masks, respectively. Attribution masks in this figure were obtained using the critic trained by DrQ [40].
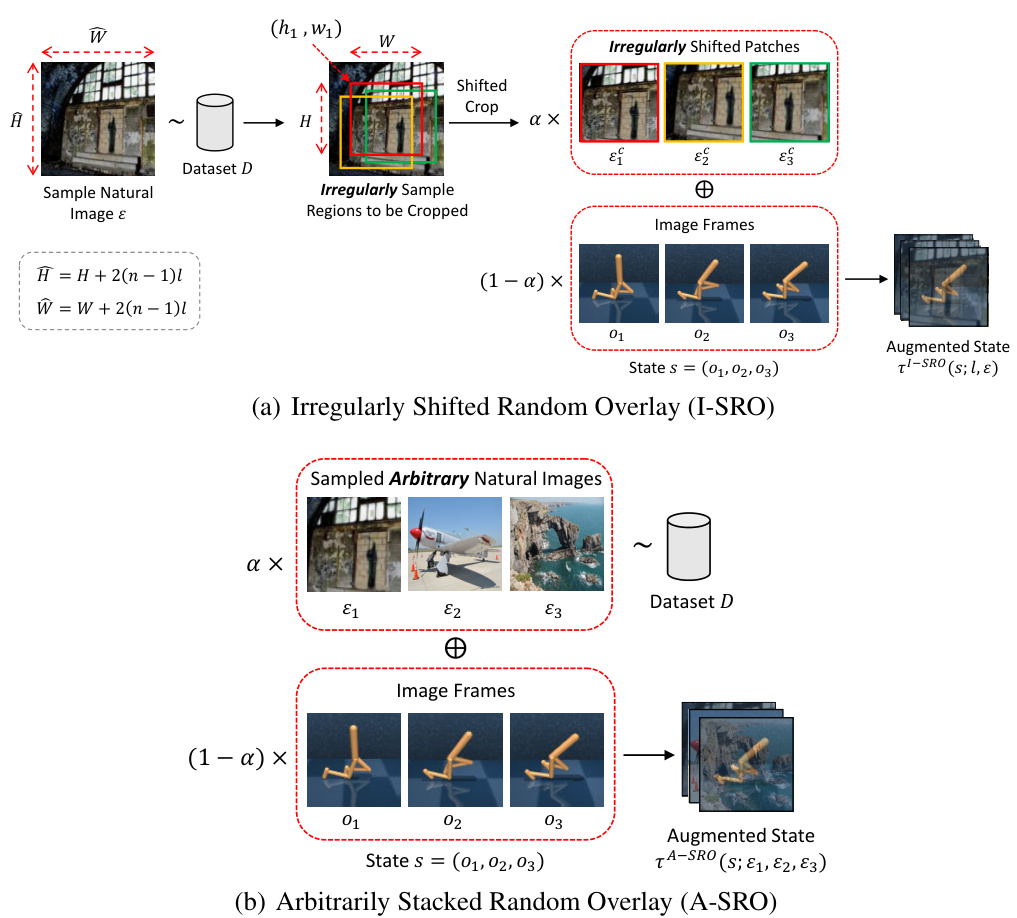
🔼 This figure illustrates the process of the Shifted Random Overlay (SRO) data augmentation technique. The SRO method injects random background dynamics into the training images to improve robustness against dynamic scene changes in real-world environments. This is done by sampling a natural image, creating multiple shifted cropped patches from it, and then interpolating these patches with the original image frames to create augmented training data. The shifting process helps the agent learn to focus on task-relevant objects rather than background variations. The figure shows the steps involved: sampling a natural image, creating shifted patches, interpolating these patches with the image frames, and generating the augmented states.
read the caption
Figure 3: Shifted random overlay (SRO) augmentation for data regularization. To inject random dynamics into the backgrounds of RL input images, we generate multiple cropped patches in a shifted manner from a sampled natural image and interpolate them to augment the input images.

🔼 This figure presents a comparison of the average performance of various visual reinforcement learning (RL) algorithms across six tasks within the DeepMind Control Suite Generalization Benchmark (DMControl-GB). It highlights SimGRL’s superior and robust performance, especially in challenging ‘Video Hard’ scenarios. Additionally, it illustrates two key issues that hinder generalization in visual RL: imbalanced saliency (agents focusing disproportionately on recent frames) and observational overfitting (agents focusing on irrelevant background features). Examples of these phenomena are shown using attribution masks to visualize which parts of the image the agent is paying attention to.
read the caption
Figure 1: (a) Average performances on 6 tasks in DMControl-GB. In contrast to other methods with significant performance degradation in Video Hard, our proposed SimGRL demonstrates robust performance across all benchmarks. (b)-(c) Examples of two problematic phenomena that can cause overfitting in visual RL generalization. The background structures in the red boxes are correlated with the movement of the task object. s and Mp represent the stacked frames and attribution masks, respectively. Attribution masks in this figure were obtained using the critic trained by DrQ [40].
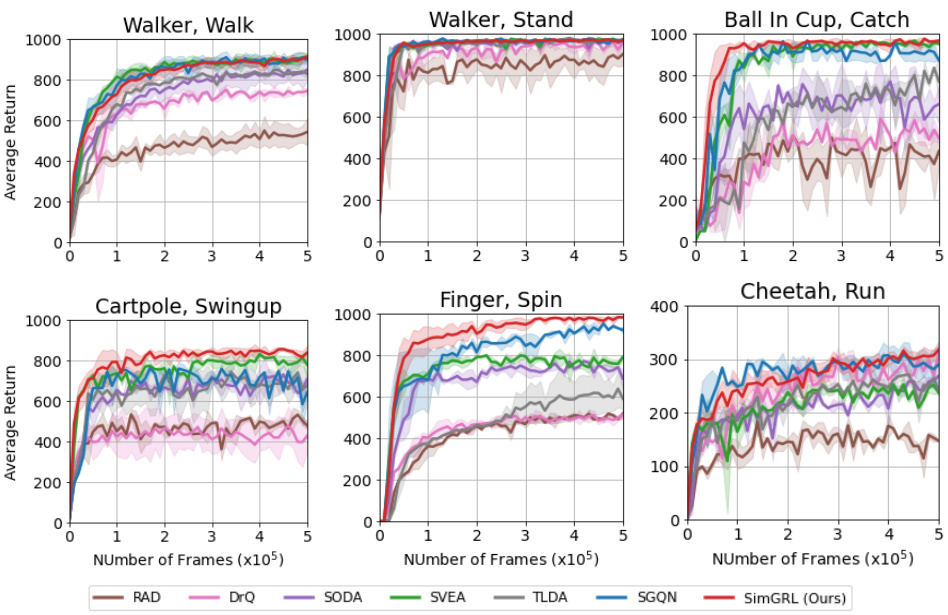
🔼 This figure presents a comparison of the average performance of SimGRL and other algorithms on six tasks within the DeepMind Control Suite Generalization Benchmark (DMControl-GB). SimGRL shows robustness against the challenging ‘Video Hard’ tasks. The figure also illustrates two common problems in visual reinforcement learning (RL) generalization: imbalanced saliency (agent focuses disproportionately on recent frames) and observational overfitting (agent focuses on irrelevant background features). Attribution masks are used to highlight these issues.
read the caption
Figure 1: (a) Average performances on 6 tasks in DMControl-GB. In contrast to other methods with significant performance degradation in Video Hard, our proposed SimGRL demonstrates robust performance across all benchmarks. (b)-(c) Examples of two problematic phenomena that can cause overfitting in visual RL generalization. The background structures in the red boxes are correlated with the movement of the task object. s and Mp represent the stacked frames and attribution masks, respectively. Attribution masks in this figure were obtained using the critic trained by DrQ [40].

🔼 This figure shows the average performance comparison of different algorithms on six tasks from the DeepMind Control Suite generalization benchmark. SimGRL shows more robust performance compared to other algorithms, especially in the ‘Video Hard’ tasks with dynamic backgrounds. Subfigures (b) and (c) illustrate two common overfitting problems in visual reinforcement learning: imbalanced saliency and observational overfitting. Imbalanced saliency means the agent focuses on the latest frames in a stack, while observational overfitting is where the agent focuses on background features instead of task-relevant ones.
read the caption
Figure 1: (a) Average performances on 6 tasks in DMControl-GB. In contrast to other methods with significant performance degradation in Video Hard, our proposed SimGRL demonstrates robust performance across all benchmarks. (b)-(c) Examples of two problematic phenomena that can cause overfitting in visual RL generalization. The background structures in the red boxes are correlated with the movement of the task object. s and Mp represent the stacked frames and attribution masks, respectively. Attribution masks in this figure were obtained using the critic trained by DrQ [40].

🔼 This figure shows the average performance of SimGRL and other algorithms on six tasks within the DeepMind Control Suite Generalization Benchmark (DMControl-GB), highlighting SimGRL’s robustness to challenging ‘Video Hard’ scenarios with dynamic backgrounds. It also illustrates two key problems hindering generalization in visual reinforcement learning: imbalanced saliency (where the agent focuses disproportionately on recent frames) and observational overfitting (where the agent focuses on irrelevant background features).
read the caption
Figure 1: (a) Average performances on 6 tasks in DMControl-GB. In contrast to other methods with significant performance degradation in Video Hard, our proposed SimGRL demonstrates robust performance across all benchmarks. (b)-(c) Examples of two problematic phenomena that can cause overfitting in visual RL generalization. The background structures in the red boxes are correlated with the movement of the task object. s and Mp represent the stacked frames and attribution masks, respectively. Attribution masks in this figure were obtained using the critic trained by DrQ [40].

🔼 This figure shows a comparison of the average performance of SimGRL and other algorithms on six tasks in the DeepMind Control Suite Generalization Benchmark (DMControl-GB). SimGRL demonstrates better generalization to more challenging scenarios (‘Video Hard’) compared to other approaches. The figure also illustrates two key reasons for the poor generalization observed in other algorithms: imbalanced saliency (b) and observational overfitting (c). Imbalanced saliency is when the agent disproportionately focuses on features in the most recent frames of a frame stack. Observational overfitting is when the agent focuses on irrelevant background regions instead of task-relevant objects.
read the caption
Figure 1: (a) Average performances on 6 tasks in DMControl-GB. In contrast to other methods with significant performance degradation in Video Hard, our proposed SimGRL demonstrates robust performance across all benchmarks. (b)-(c) Examples of two problematic phenomena that can cause overfitting in visual RL generalization. The background structures in the red boxes are correlated with the movement of the task object. s and Mp represent the stacked frames and attribution masks, respectively. Attribution masks in this figure were obtained using the critic trained by DrQ [40].

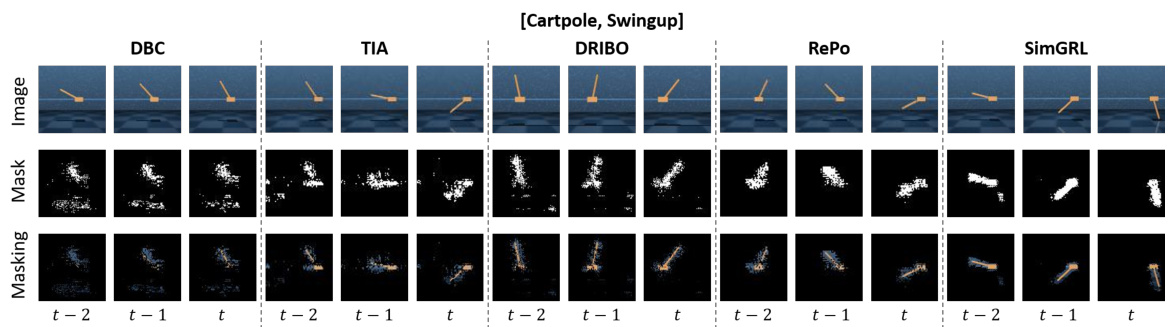
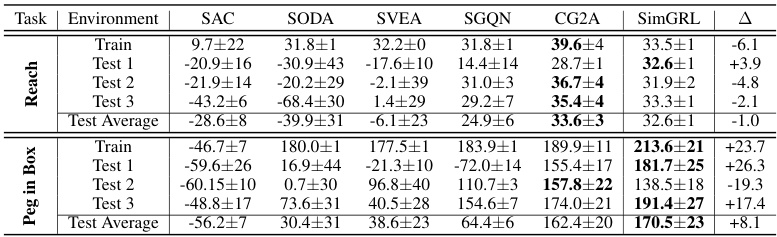
🔼 This figure shows examples of robotic manipulation tasks used in the experiments, specifically ‘Reach’ and ‘Peg in Box.’ For each task, it displays images from the training environment and three different test environments. The images show variations in background and object appearance to illustrate the generalization challenges addressed by SimGRL. The right column of each task shows attribution masks (SOMp) highlighting areas the model focuses on.
read the caption
Figure 20: Examples of Robotic Manipulation Tasks.
🔼 Figure 1 shows the performance of SimGRL and other algorithms across multiple DeepMind Control Suite tasks, highlighting its robustness to challenging scenarios. It also illustrates two key issues causing overfitting in visual reinforcement learning: imbalanced saliency and observational overfitting.
read the caption
Figure 1: (a) Average performances on 6 tasks in DMControl-GB. In contrast to other methods with significant performance degradation in Video Hard, our proposed SimGRL demonstrates robust performance across all benchmarks. (b)-(c) Examples of two problematic phenomena that can cause overfitting in visual RL generalization. The background structures in the red boxes are correlated with the movement of the task object. s and Mp represent the stacked frames and attribution masks, respectively. Attribution masks in this figure were obtained using the critic trained by DrQ [40].
🔼 This figure compares the attribution masks and resulting masked images for the SVEA and SimGRL algorithms on the ‘Cartpole, Swingup’ and ‘Cheetah, Run’ tasks. It highlights how SimGRL effectively identifies task-relevant objects (the cartpole and cheetah), whereas SVEA struggles due to imbalanced saliency (focusing disproportionately on recent frames) and observational overfitting (attributing salience to background elements).
read the caption
Figure 2: Examples of attribution masks and masked frames. Compared to SVEA that falls into the imbalanced saliency and observation overfitting in the 'Cartpole, Swingup' and 'Cheetah, Run' tasks, respectively, the proposed SimGRL accurately identifies the true salient pixels even in challenging 'Video Hard' test environments of DMControl-GB. We provide further examples of the attribution masks and masked salient regions for various environments and algorithms in Appendix F.4.

🔼 This figure shows the training curves for ablation variants of the SimGRL model on the Video Hard benchmark of the DMControl-GB dataset. The ablation variants include: Baseline (SVEA), SimGRL-F (SVEA + Feature-Level Frame Stack), SimGRL-S (SVEA + Shifted Random Overlay), and SimGRL (SVEA + Both). The plot demonstrates that the addition of each regularization improves generalization performance, with the complete SimGRL model showing the best results.
read the caption
Figure 7: Training curves for ablation variants.
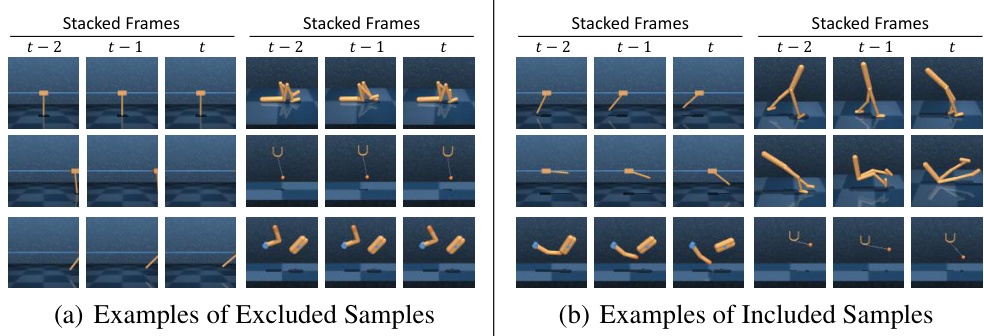
🔼 This figure shows examples of attribution masks and the corresponding masked frames for the Cartpole Swingup and Cheetah Run tasks, comparing the results obtained with SVEA and SimGRL. It highlights that SimGRL, unlike SVEA, accurately identifies the salient pixels even in challenging test environments, thus mitigating both imbalanced saliency and observational overfitting problems.
read the caption
Figure 2: Examples of attribution masks and masked frames. Compared to SVEA that falls into the imbalanced saliency and observation overfitting in the 'Cartpole, Swingup' and 'Cheetah, Run' tasks, respectively, the proposed SimGRL accurately identifies the true salient pixels even in challenging 'Video Hard' test environments of DMControl-GB. We provide further examples of the attribution masks and masked salient regions for various environments and algorithms in Appendix F.4.

🔼 This figure shows a comparison of attribution masks and masked frames for SVEA and SimGRL on two different tasks from the DeepMind Control Suite: Cartpole Swingup and Cheetah Run. The attribution masks highlight the areas that the model considers most salient for performing the task. The figure demonstrates that SimGRL is able to accurately identify the relevant task objects while ignoring distracting background elements, whereas SVEA struggles with both imbalanced saliency and observational overfitting. The visualization shows that SVEA disproportionately focuses on the task objects in the latest frames within the stacked frames and misses important information from previous frames in the case of Cartpole Swingup. Moreover, SVEA is prone to observational overfitting as it incorrectly identifies background areas as more salient in the case of Cheetah Run. Appendix F.4 provides further examples for various tasks and algorithms.
read the caption
Figure 2: Examples of attribution masks and masked frames. Compared to SVEA that falls into the imbalanced saliency and observation overfitting in the 'Cartpole, Swingup' and 'Cheetah, Run' tasks, respectively, the proposed SimGRL accurately identifies the true salient pixels even in challenging 'Video Hard' test environments of DMControl-GB. We provide further examples of the attribution masks and masked salient regions for various environments and algorithms in Appendix F.4.

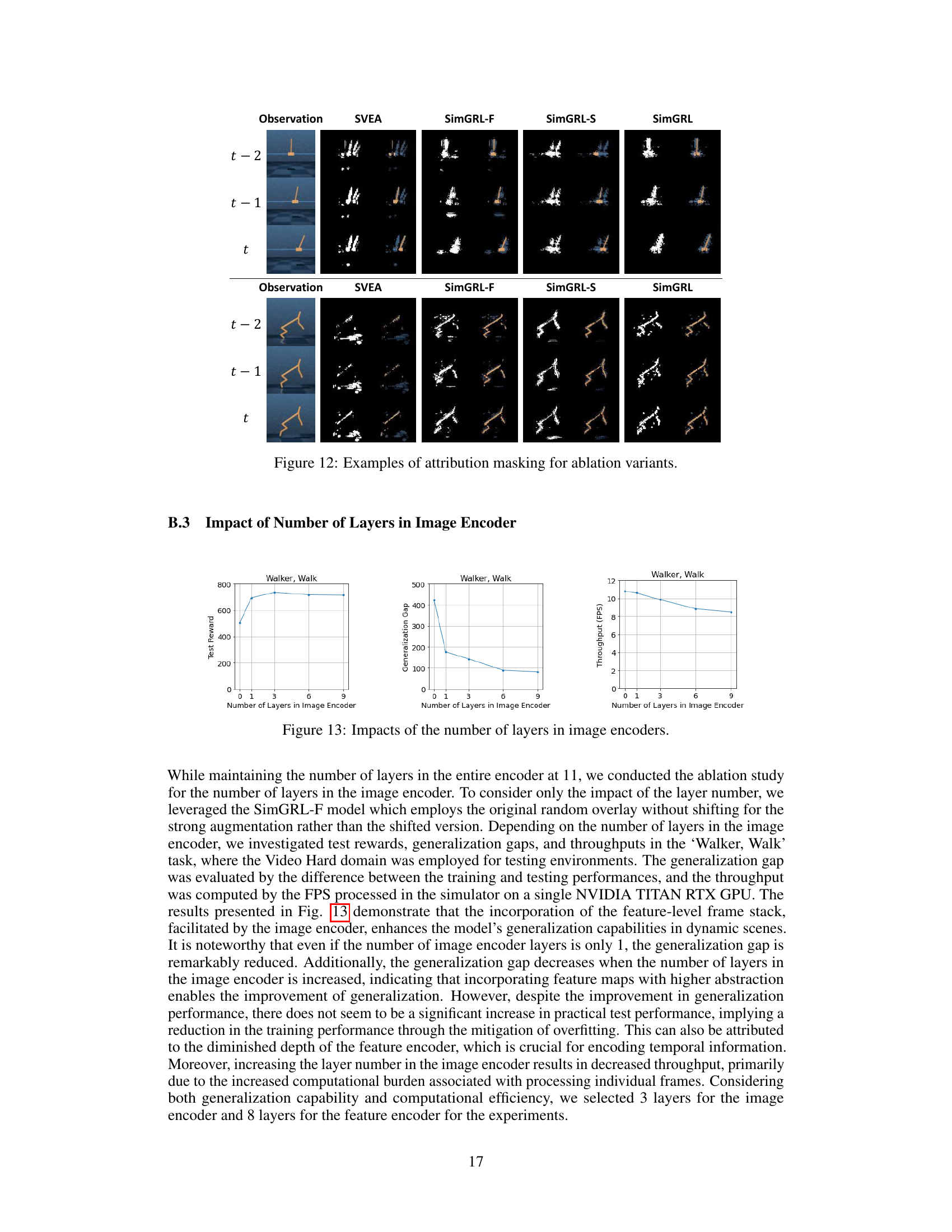
🔼 This figure shows the effect of different quantile values (p) used for thresholding in generating the p-quantile attribution mask. The columns represent different p values: 0.9, 0.95, and the optimal value calculated as described in the paper. The rows show the observations and their corresponding attribution masks (binarized). The results illustrate how the choice of p impacts the size and extent of the regions highlighted in the attribution mask, which in turn affects how well the model identifies task-relevant objects. A smaller p value leads to larger regions highlighted, including more pixels (possibly irrelevant) while a larger p value leads to less but more precisely highlighted pixels that identify task-relevant objects.
read the caption
Figure 26: Impacts of quantile values p used for thresholding.

🔼 This figure shows examples of attribution masks (highlighting important pixels for the task) and the corresponding masked images (showing only the highlighted pixels) for different RL agents (SVEA and SimGRL) on two tasks (‘Cartpole, Swingup’ and ‘Cheetah, Run’) from the DMControl-GB benchmark. It demonstrates how SimGRL, unlike SVEA, successfully identifies the relevant task object pixels even in the presence of dynamic scene elements. The difference highlights the effectiveness of SimGRL’s proposed methods in mitigating imbalanced saliency and observational overfitting issues.
read the caption
Figure 2: Examples of attribution masks and masked frames. Compared to SVEA that falls into the imbalanced saliency and observation overfitting in the 'Cartpole, Swingup' and 'Cheetah, Run' tasks, respectively, the proposed SimGRL accurately identifies the true salient pixels even in challenging 'Video Hard' test environments of DMControl-GB. We provide further examples of the attribution masks and masked salient regions for various environments and algorithms in Appendix F.4.

🔼 This figure demonstrates the effectiveness of SimGRL in addressing the issues of imbalanced saliency and observational overfitting. It compares attribution masks (highlighting areas the model focuses on) generated by SVEA and SimGRL for two tasks from the DMControl-GB benchmark (‘Cartpole, Swingup’ and ‘Cheetah, Run’). SimGRL shows a more accurate focus on the relevant task elements, even in challenging ‘Video Hard’ scenarios with dynamic backgrounds. The differences highlight SimGRL’s improved ability to identify and focus on task-relevant information.
read the caption
Figure 2: Examples of attribution masks and masked frames. Compared to SVEA that falls into the imbalanced saliency and observation overfitting in the 'Cartpole, Swingup' and 'Cheetah, Run' tasks, respectively, the proposed SimGRL accurately identifies the true salient pixels even in challenging 'Video Hard' test environments of DMControl-GB. We provide further examples of the attribution masks and masked salient regions for various environments and algorithms in Appendix F.4.

🔼 This figure shows a comparison of attribution masks and the resulting masked frames for the SVEA and SimGRL models. It highlights the key findings of the paper: SVEA suffers from imbalanced saliency and observational overfitting, while SimGRL successfully addresses these issues. In Cartpole Swingup, SVEA focuses disproportionately on the latest frames, while SimGRL demonstrates more balanced attention across all frames. In Cheetah Run, SVEA focuses on the irrelevant ground, whereas SimGRL correctly emphasizes the cheetah. The Appendix contains further examples illustrating these differences across various tasks and algorithms.
read the caption
Figure 2: Examples of attribution masks and masked frames. Compared to SVEA that falls into the imbalanced saliency and observation overfitting in the 'Cartpole, Swingup' and 'Cheetah, Run' tasks, respectively, the proposed SimGRL accurately identifies the true salient pixels even in challenging 'Video Hard' test environments of DMControl-GB. We provide further examples of the attribution masks and masked salient regions for various environments and algorithms in Appendix F.4.

🔼 This figure shows a comparison of the average performance of SimGRL and other methods on six tasks from the DeepMind Control Suite generalization benchmark (DMControl-GB). SimGRL shows superior robustness to challenging environments with dynamically changing backgrounds. The figure also illustrates two common problems that hinder generalization in visual reinforcement learning: imbalanced saliency (agents focus disproportionately on recent frames in a sequence) and observational overfitting (agents focus on background regions instead of task-relevant objects). Attribution masks help visualize these issues.
read the caption
Figure 1: (a) Average performances on 6 tasks in DMControl-GB. In contrast to other methods with significant performance degradation in Video Hard, our proposed SimGRL demonstrates robust performance across all benchmarks. (b)-(c) Examples of two problematic phenomena that can cause overfitting in visual RL generalization. The background structures in the red boxes are correlated with the movement of the task object. s and Mp represent the stacked frames and attribution masks, respectively. Attribution masks in this figure were obtained using the critic trained by DrQ [40].

🔼 The figure shows examples of attribution masks and masked frames from two different tasks (‘Cartpole, Swingup’ and ‘Cheetah, Run’) for both SVEA and SimGRL. It highlights how SimGRL overcomes the problems of imbalanced saliency and observational overfitting that affect SVEA. SimGRL accurately identifies the relevant task objects, while SVEA’s masks show a bias towards recent frames or irrelevant background details.
read the caption
Figure 2: Examples of attribution masks and masked frames. Compared to SVEA that falls into the imbalanced saliency and observation overfitting in the 'Cartpole, Swingup' and 'Cheetah, Run' tasks, respectively, the proposed SimGRL accurately identifies the true salient pixels even in challenging 'Video Hard' test environments of DMControl-GB. We provide further examples of the attribution masks and masked salient regions for various environments and algorithms in Appendix F.4.

🔼 The figure shows examples of attribution masks and masked frames generated by SVEA and SimGRL for ‘Cartpole, Swingup’ and ‘Cheetah, Run’ tasks. It highlights SimGRL’s superior ability to accurately identify the salient pixels, unlike SVEA, which suffers from imbalanced saliency and observational overfitting. Appendix F.4 contains additional examples.
read the caption
Figure 2: Examples of attribution masks and masked frames. Compared to SVEA that falls into the imbalanced saliency and observation overfitting in the 'Cartpole, Swingup' and 'Cheetah, Run' tasks, respectively, the proposed SimGRL accurately identifies the true salient pixels even in challenging 'Video Hard' test environments of DMControl-GB. We provide further examples of the attribution masks and masked salient regions for various environments and algorithms in Appendix F.4.

🔼 This figure compares attribution masks and the corresponding masked frames of SVEA and SimGRL in the ‘Cartpole, Swingup’ and ‘Cheetah, Run’ tasks. It shows that SimGRL accurately identifies the task-relevant objects (the cartpole and the cheetah) in each frame, unlike SVEA which falls into imbalanced saliency and observational overfitting. SimGRL demonstrates robust performance even in challenging environments, unlike SVEA. The appendix includes further examples.
read the caption
Figure 2: Examples of attribution masks and masked frames. Compared to SVEA that falls into the imbalanced saliency and observation overfitting in the 'Cartpole, Swingup' and 'Cheetah, Run' tasks, respectively, the proposed SimGRL accurately identifies the true salient pixels even in challenging 'Video Hard' test environments of DMControl-GB. We provide further examples of the attribution masks and masked salient regions for various environments and algorithms in Appendix F.4.

🔼 This figure shows attribution masks and masked frames for the Cartpole Swingup and Cheetah Run tasks, comparing the performance of SVEA and SimGRL. It highlights the problems of imbalanced saliency and observational overfitting that affect SVEA’s performance. SimGRL demonstrates improved accuracy in identifying salient pixels, even in more challenging environments.
read the caption
Figure 2: Examples of attribution masks and masked frames. Compared to SVEA that falls into the imbalanced saliency and observation overfitting in the 'Cartpole, Swingup' and 'Cheetah, Run' tasks, respectively, the proposed SimGRL accurately identifies the true salient pixels even in challenging 'Video Hard' test environments of DMControl-GB. We provide further examples of the attribution masks and masked salient regions for various environments and algorithms in Appendix F.4.
More on tables

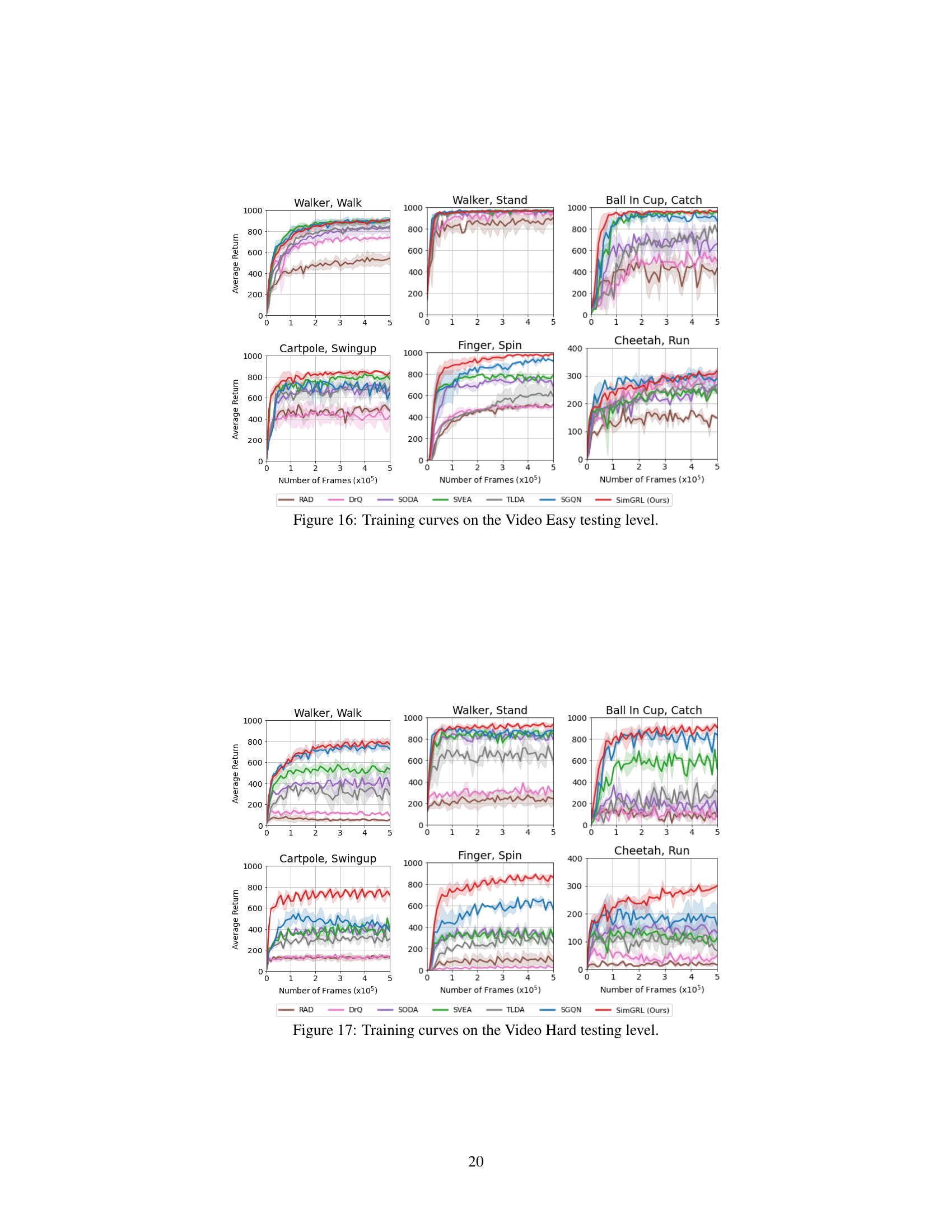
🔼 This table presents the average scores and standard deviations across five different seeds for six tasks within the DeepMind Control Suite generalization benchmark’s Video Easy and Video Hard categories. The results are presented for the proposed SimGRL method and several state-of-the-art comparative methods. The delta (Δ) column shows the performance difference between SimGRL and the second-best performing method for each task. The table demonstrates SimGRL’s robust performance across diverse tasks, especially in the challenging Video Hard environment.
read the caption
Table 1: Generalization performance on video benchmarks from DMControl-GB [13]. We report the results on mean and standard deviation over 5 seeds. The scores of the comparison methods were taken from their respective papers, and in cases where the scores were unavailable, they were obtained through our implementation using the official codes. Δ indicates the difference with second best.
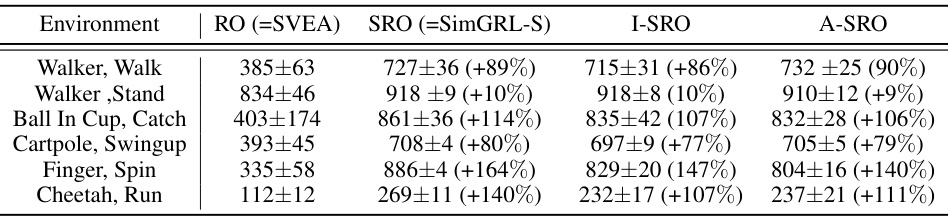
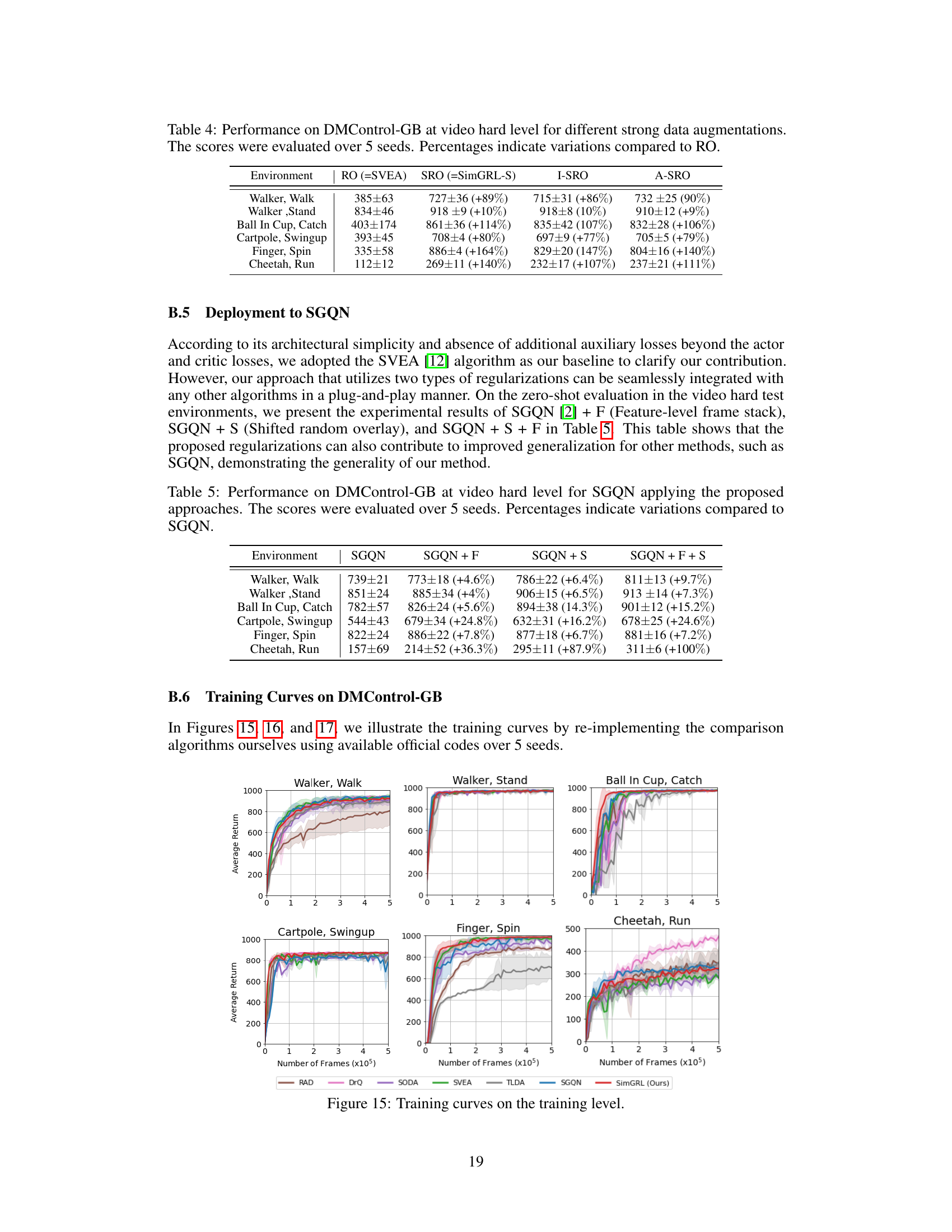
🔼 This table presents the results of an ablation study comparing different strong data augmentation methods on the DMControl-GB benchmark’s ‘Video Hard’ level. The methods compared are the original random overlay (RO), shifted random overlay (SRO, which is SimGRL-S in the paper), irregularly shifted random overlay (I-SRO), and arbitrarily stacked random overlay (A-SRO). The table shows the average performance and percentage improvement compared to the original RO method for each task (Walker, Walk; Walker, Stand; Ball In Cup, Catch; Cartpole, Swingup; Finger, Spin; Cheetah, Run) in the benchmark.
read the caption
Table 4: Performance on DMControl-GB at video hard level for different strong data augmentations. The scores were evaluated over 5 seeds. Percentages indicate variations compared to RO.
🔼 This table presents the results of the zero-shot generalization performance of SimGRL and other state-of-the-art methods on the DMControl-GB video benchmarks. The table includes mean and standard deviation scores across 5 different seeds for six tasks, split between Video Easy and Video Hard levels of difficulty. The Δ column highlights the performance difference between SimGRL and the second-best performing method for each task and difficulty level. The scores for the comparison methods were either taken from their respective publications or re-implemented by the authors using official codes when unavailable.
read the caption
Table 1: Generalization performance on video benchmarks from DMControl-GB [13]. We report the results on mean and standard deviation over 5 seeds. The scores of the comparison methods were taken from their respective papers, and in cases where the scores were unavailable, they were obtained through our implementation using the official codes. Δ indicates the difference with second best.
🔼 This table presents a comparison of the generalization performance of different algorithms on six video tasks from the DeepMind Control Suite Generalization Benchmark (DMControl-GB). The algorithms compared include SAC, RAD, DrQ, SODA, SVEA, TLDA, SGQN, EAR, CG2A, and the proposed SimGRL. The table shows the average scores and standard deviations across five random seeds for each algorithm and task in both ‘Video Easy’ and ‘Video Hard’ scenarios. The ‘Video Hard’ setting is more challenging because of dynamically changing backgrounds. The Δ column indicates the performance difference between SimGRL and the second-best performing algorithm for each task.
read the caption
Table 1: Generalization performance on video benchmarks from DMControl-GB [13]. We report the results on mean and standard deviation over 5 seeds. The scores of the comparison methods were taken from their respective papers, and in cases where the scores were unavailable, they were obtained through our implementation using the official codes. Δ indicates the difference with second best.

🔼 This table presents the results of the zero-shot generalization performance evaluation on six tasks from the DeepMind Control Suite Generalization Benchmark (DMControl-GB). The table compares the proposed SimGRL method against several state-of-the-art algorithms for visual RL generalization. Performance is measured by average score and standard deviation across five random seeds, and the difference between SimGRL’s performance and the second-best result is highlighted. The results are separated into ‘Video Easy’ and ‘Video Hard’ scenarios, representing different levels of background dynamism.
read the caption
Table 1: Generalization performance on video benchmarks from DMControl-GB [13]. We report the results on mean and standard deviation over 5 seeds. The scores of the comparison methods were taken from their respective papers, and in cases where the scores were unavailable, they were obtained through our implementation using the official codes. Δ indicates the difference with second best.
Full paper#