TL;DR#
Current text-to-video (T2V) model evaluation methods face significant challenges regarding reproducibility, reliability, and practicality, primarily due to the limitations inherent in automatic metrics and inconsistencies in manual evaluation protocols. These issues hinder the objective assessment of T2V model performance and impede progress in the field.
The paper addresses these issues by introducing the Text-to-Video Human Evaluation (T2VHE) protocol, a comprehensive and standardized evaluation protocol. T2VHE incorporates well-defined metrics, rigorous annotator training, and an innovative dynamic evaluation module that reduces evaluation costs. Experimental results show that T2VHE ensures high-quality annotations and lowers evaluation costs by approximately 50%. The authors plan to open-source the entire setup of T2VHE protocol, including the complete workflow, component details, and annotation interface code, to encourage wider adoption and facilitate more sophisticated human evaluation within the research community.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in text-to-video generation because it introduces a novel, standardized human evaluation protocol (T2VHE) to enhance the reliability and reproducibility of evaluation, addressing existing challenges. T2VHE offers well-defined metrics, thorough annotator training, and a cost-effective dynamic evaluation module. The open-sourcing of the protocol will facilitate wider adoption and standardization in the community, leading to improvements in model development and assessment.
Visual Insights#

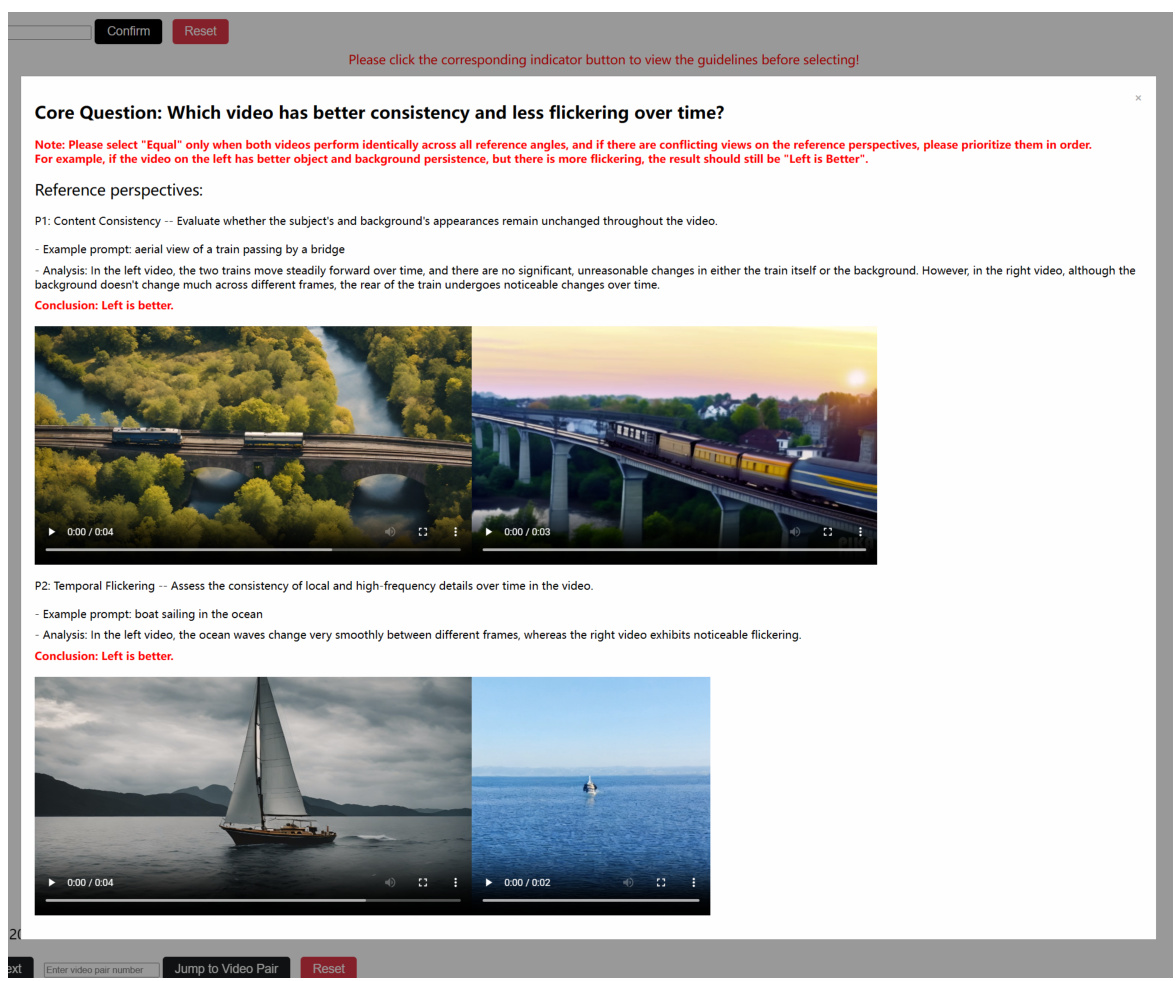
🔼 This figure provides a visual representation of the proposed human evaluation protocol, showing the workflow, annotation interface, and instructions/examples. Panel (a) illustrates the overall protocol, which consists of pre-annotation sorting, static annotation, and dynamic annotation modules, driven by an automatic scorer and refined by trained annotators. Panel (b) displays the annotation interface, where evaluators use provided metrics to compare video pairs and select a superior video, and panel (c) shows example questions and detailed analysis steps to aid the evaluators, illustrating how the process works.
read the caption
Figure 1: (a) An illustration of our human evaluation protocol. (b) The annotation interface, wherein annotators choose the superior video based on provided evaluation metrics. (c) Instruction and examples to guide used to the 'Video Quality' evaluation.
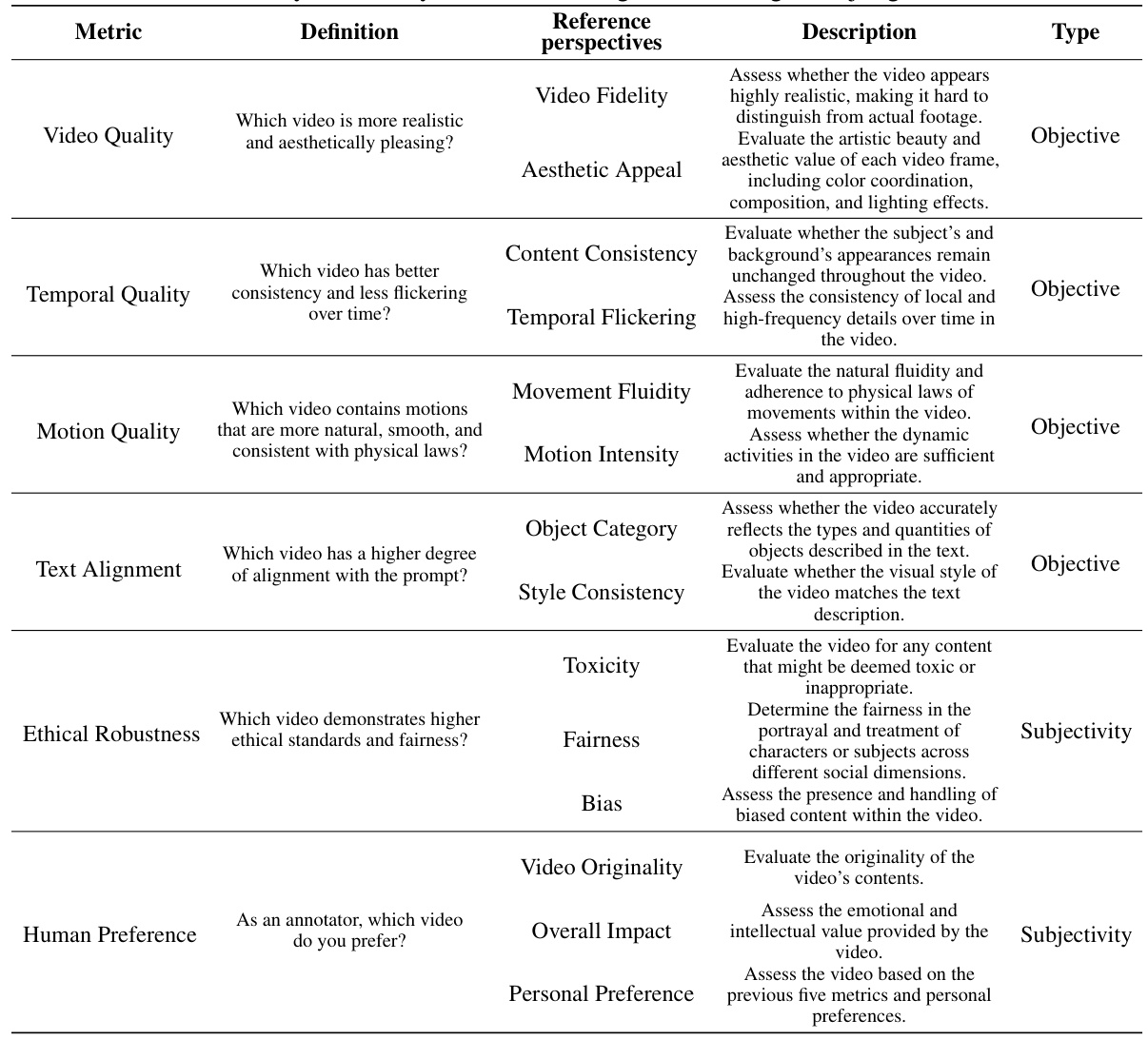
🔼 This table presents the six evaluation metrics used in the Text-to-Video Human Evaluation (T2VHE) protocol. For each metric, the table provides a detailed definition, the corresponding reference perspectives to guide annotators in making judgements, and the type of metric (objective or subjective). The reference perspectives offer specific viewpoints and examples to help annotators make consistent and reliable evaluations, especially when dealing with subjective metrics. The table shows that some metrics rely more heavily on reference perspectives than others when making judgements.
read the caption
Table 1: Comprehensive evaluation criteria for T2V models. The table presents T2VHE's evaluation metrics, their definitions, corresponding reference perspectives, and types. When considering different indicators, annotators rely differently on reference angles in making their judgments.
In-depth insights#
T2V Evaluation#
The evaluation of Text-to-Video (T2V) models presents unique challenges due to the limitations of automatic metrics in capturing the nuances of video generation. Existing manual evaluation protocols often lack standardization, leading to issues with reproducibility and reliability. This necessitates the development of a more comprehensive and robust evaluation framework. A key aspect is the careful selection of evaluation metrics, balancing objective and subjective measures to assess video quality, temporal consistency, motion quality, text alignment, and ethical considerations. Annotator training is crucial to minimize bias and ensure consistent evaluations, ideally using a comparison-based method rather than absolute scoring to reduce subjectivity. Furthermore, a dynamic evaluation module can greatly enhance efficiency by prioritizing the most informative comparisons, reducing overall annotation costs. Open-sourcing the entire evaluation protocol workflow, annotation interface, and dynamic module would foster collaboration and improve the field’s progress.
T2VHE Protocol#
The T2VHE protocol, a novel human evaluation framework for Text-to-Video (T2V) models, stands out due to its focus on enhancing reliability, reproducibility, and practicality. Key improvements include well-defined evaluation metrics addressing video quality, temporal consistency, motion naturalness, and text alignment, along with subjective assessments of ethical robustness and human preference. A rigorous annotator training program ensures high-quality annotations, while a dynamic evaluation module significantly reduces evaluation costs. This module prioritizes video pairs with potentially high-impact differences, adapting to the relative quality and efficiency needs of the assessment. The open-sourcing of the protocol, including the complete workflow, component details, and annotation interface code, fosters community-wide adoption and further refinement, driving advancements in T2V model assessment and development.
Dynamic Evaluation#
Dynamic evaluation, in the context of this research paper, is a crucial innovation addressing the high cost and inefficiency of traditional human evaluation in text-to-video (T2V) model assessment. The core idea is to prioritize the evaluation of video pairs that are most informative, reducing the overall workload. This prioritization is achieved through a combination of automated scoring and a sophisticated dynamic selection process. Automated metrics initially filter video pairs, focusing human effort on those where automatic measures show discrepancies. The process iteratively refines model rankings, incorporating human feedback. A significant advantage is the substantial cost reduction (approximately 50%), demonstrated experimentally. This dynamic approach does not compromise the quality of the final evaluations, striking a balance between efficiency and accuracy. This dynamic evaluation method is a significant contribution, improving T2V evaluation practicality and allowing researchers to efficiently assess numerous models with high confidence in the results.
Annotator Training#
The effectiveness of human evaluation in assessing text-to-video models hinges significantly on the quality of annotations, and achieving this depends heavily on proper annotator training. The authors recognize this and dedicate a section to detailing their training methods. The approach is cost-effective, focusing on instruction-based and example-based training, rather than extensive or specialized training. Instruction-based training involves furnishing detailed guidance for each evaluation metric, along with reference perspectives. Crucially, example-based training supplements this by providing illustrative examples, analytical processes, and specific instructions to guide annotation. This combined method aims to bridge the gap between professional annotators and less experienced ones, ensuring high-quality annotations. Experimental validation, comparing annotations from trained annotators with those from crowdsourced professionals, confirms the efficacy of the training approach and demonstrates that the cost-effectiveness doesn’t compromise annotation quality. Improved consistency and agreement among annotators underscores the success of the training strategy. This strategy is particularly important given that many existing evaluation methods rely on non-professional annotators, a point highlighted as problematic by the authors themselves.
Future of T2V#
The future of Text-to-Video (T2V) is brimming with potential. Improved realism and fidelity will likely be a major focus, moving beyond current limitations in rendering fine details and nuanced motion. We can anticipate advancements in handling diverse and complex prompts, generating videos that accurately reflect the subtleties of human language and intent. Ethical considerations will play a crucial role, with emphasis on mitigating bias and ensuring responsible use of the technology. Efficiency gains are also anticipated, enabling faster and more cost-effective video generation. The integration of T2V with other generative AI models, such as those for audio and 3D environments, promises immersive and interactive experiences. Furthermore, new applications in areas like personalized education, virtual tourism, and virtual production are likely to emerge. The biggest challenge, however, may be balancing innovation with ethical considerations, ensuring that the technology benefits humanity while mitigating risks of misuse.
More visual insights#
More on figures
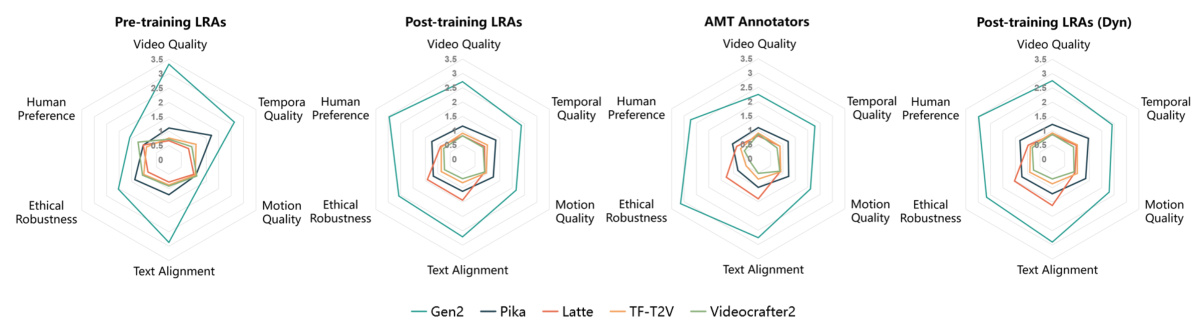
🔼 This figure presents a comparison of the scores and rankings of five different text-to-video (T2V) models across six evaluation dimensions: Video Quality, Temporal Quality, Motion Quality, Text Alignment, Ethical Robustness, and Human Preference. The scores are shown for three different groups of annotators: pre-training laboratory-recruited annotators (LRAs), Amazon Mechanical Turk (AMT) annotators, and post-training LRAs. A fourth set of results is included showing the impact of the dynamic evaluation module on the post-training LRAs’ evaluations. The radar charts allow for a visual comparison of the relative strengths and weaknesses of each model across the different evaluation dimensions and annotator groups.
read the caption
Figure 2: Scores and rankings of models across various dimensions for pre-training LRAs, AMT Annotators, and Post-training LRAs. Post-training LRAs (Dyn) refers to the annotation results of Post-training LRAs using the dynamic evaluation component.

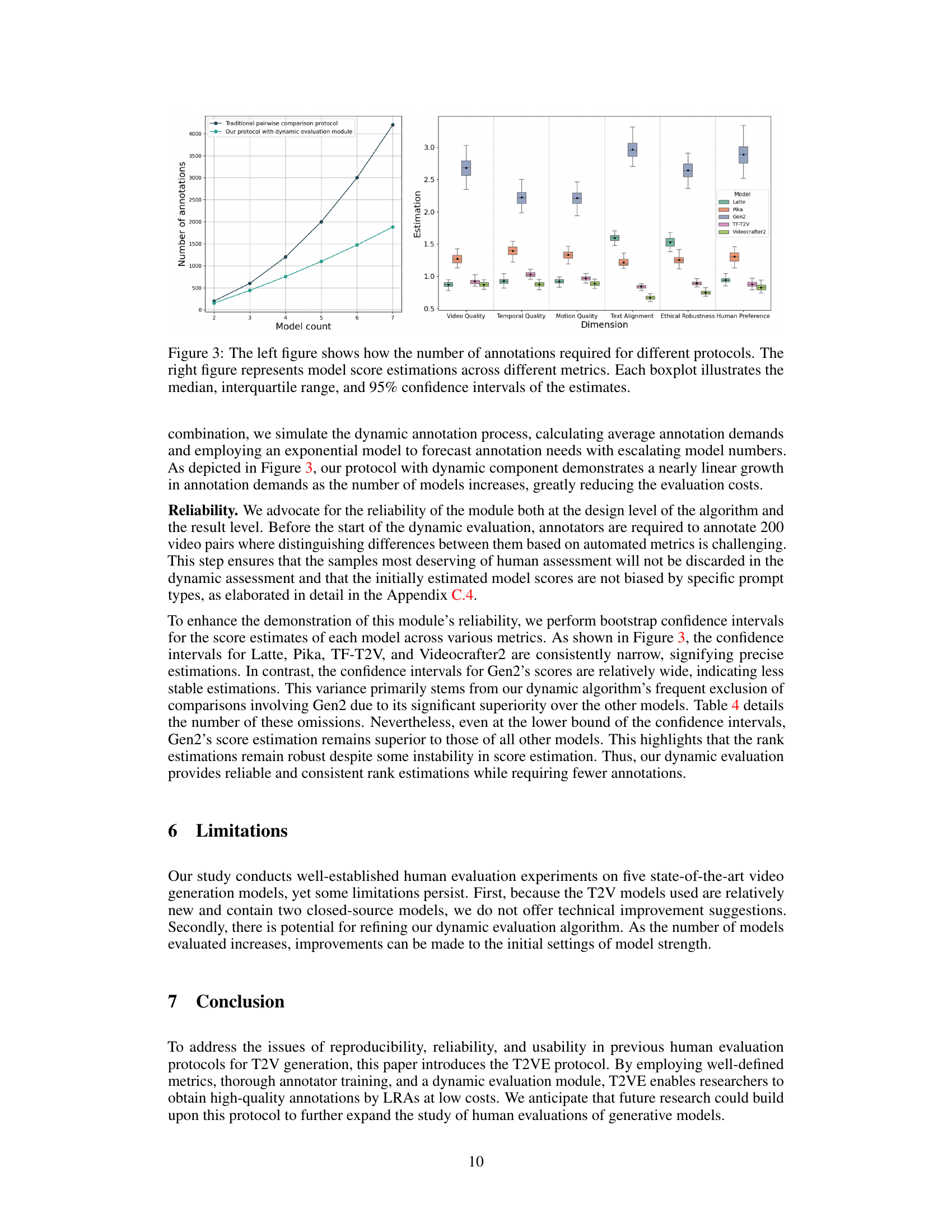
🔼 This figure compares the number of annotations needed for traditional pairwise comparison protocols versus the proposed protocol with a dynamic evaluation module. The left panel shows a plot demonstrating the drastically reduced annotation requirements of the dynamic approach as the number of models increases. The right panel provides box plots showing score estimations across six different video quality metrics (Video Quality, Temporal Quality, Motion Quality, Text Alignment, Ethical Robustness, Human Preference) for five different models. The box plots illustrate the median, interquartile range, and 95% confidence intervals of the estimates, showing the relative performance of each model across the different metrics.
read the caption
Figure 3: The left figure shows how the number of annotations required for different protocols. The right figure represents model score estimations across different metrics. Each boxplot illustrates the median, interquartile range, and 95% confidence intervals of the estimates.
🔼 This figure illustrates the proposed human evaluation protocol. (a) shows the overall workflow of the protocol, including pre-annotation sorting, static annotation, and dynamic annotation stages. (b) shows the annotation interface where human annotators compare video pairs and select the better one based on provided metrics. (c) provides detailed instructions and examples for annotators to assess ‘Video Quality’.
read the caption
Figure 1: (a) An illustration of our human evaluation protocol. (b) The annotation interface, wherein annotators choose the superior video based on provided evaluation metrics. (c) Instruction and examples to guide used to the 'Video Quality' evaluation.

🔼 This figure provides a visual overview of the proposed Text-to-Video Human Evaluation (T2VHE) protocol. Panel (a) shows a flowchart illustrating the protocol’s workflow: pre-annotation sorting using automated scores, static annotation, dynamic annotation (where only videos with significant score differences are annotated), and the final automatic scoring. Panel (b) displays the annotation interface, showing video pairs to compare and buttons for annotator selection. Panel (c) shows example prompts and detailed instructions/evaluation criteria to guide the annotators when evaluating ‘Video Quality’ and other metrics.
read the caption
Figure 1: (a) An illustration of our human evaluation protocol. (b) The annotation interface, wherein annotators choose the superior video based on provided evaluation metrics. (c) Instruction and examples to guide used to the 'Video Quality' evaluation.
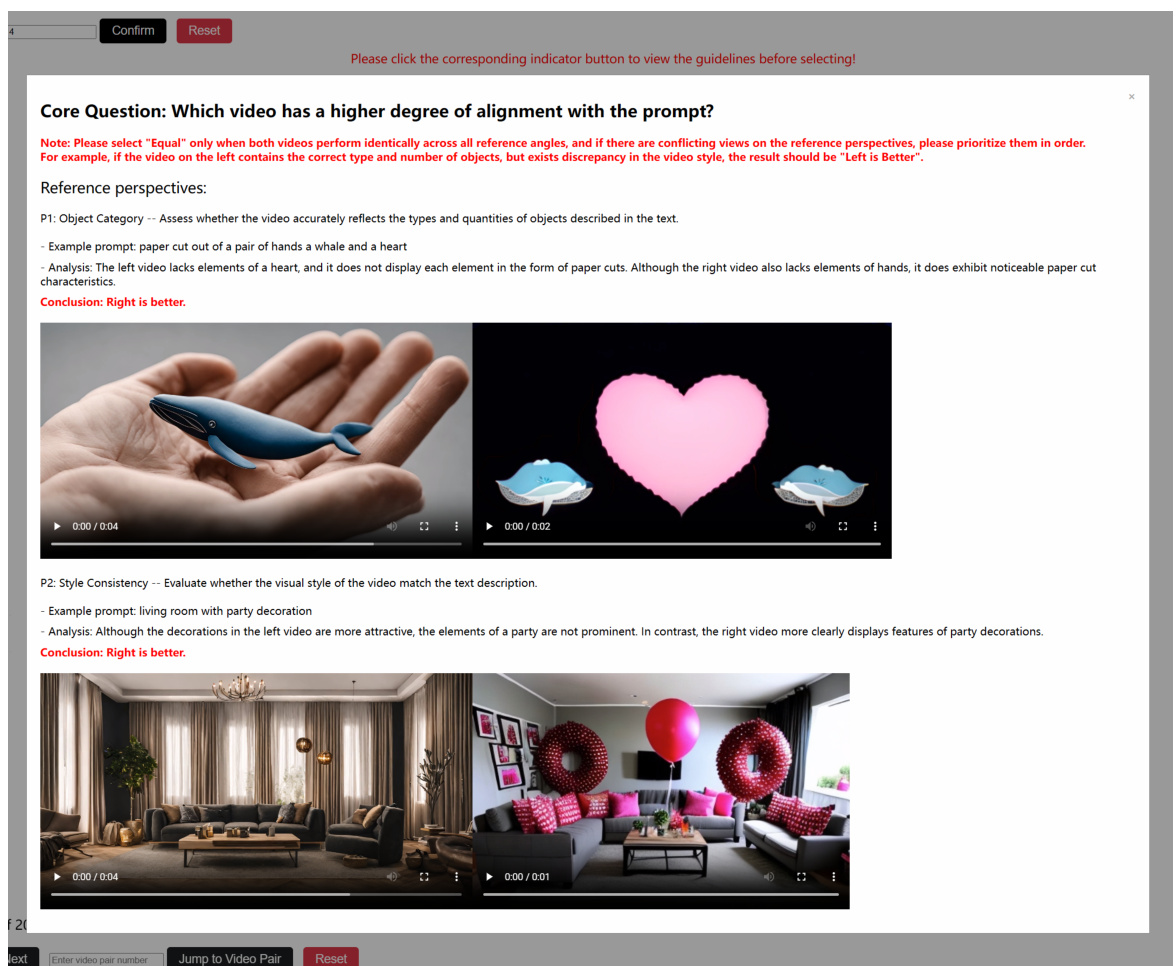
🔼 This figure shows three aspects of the Text-to-Video Human Evaluation (T2VHE) protocol. (a) illustrates the overall workflow, including pre-annotation sorting, static annotation, and dynamic annotation components. (b) displays the annotation interface that annotators use. This interface presents pairs of videos and allows annotators to select the superior video according to the provided metrics. (c) gives examples of instructions and examples to guide annotators in using the protocol, specifically in relation to ‘Video Quality’ evaluation. These instructions emphasize how to assess realism and aesthetic appeal.
read the caption
Figure 1: (a) An illustration of our human evaluation protocol. (b) The annotation interface, wherein annotators choose the superior video based on provided evaluation metrics. (c) Instruction and examples to guide used to the 'Video Quality' evaluation.

🔼 This figure provides a visual representation of the Text-to-Video Human Evaluation (T2VHE) protocol. Panel (a) shows a flowchart of the protocol’s workflow. Panel (b) displays the interface used by human evaluators to compare videos based on various metrics. Panel (c) shows detailed instructions and examples provided to help evaluators make consistent and reliable judgments of video quality.
read the caption
Figure 1: (a) An illustration of our human evaluation protocol. (b) The annotation interface, wherein annotators choose the superior video based on provided evaluation metrics. (c) Instruction and examples to guide used to the 'Video Quality' evaluation.
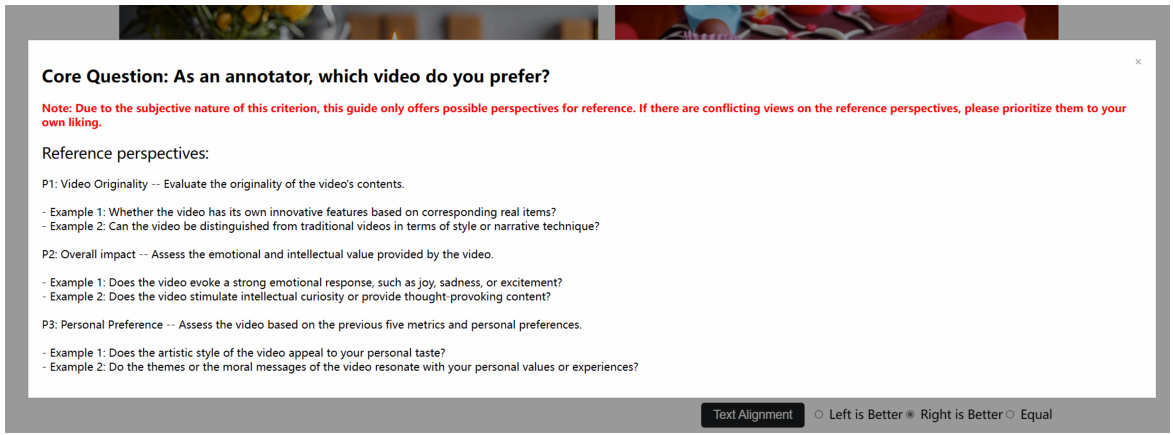
🔼 This figure provides a visual representation of the Text-to-Video Human Evaluation (T2VHE) protocol. (a) shows the overall workflow, highlighting pre-annotation sorting, static and dynamic annotation stages, and the automatic scorer. (b) displays the user interface where annotators compare video pairs and make judgments based on provided metrics (Video Quality, Temporal Quality, Motion Quality, Text Alignment, Ethical Robustness, Human Preference). (c) gives specific instructions and example prompts to guide annotators in evaluating ‘Video Quality’. The figure illustrates the protocol’s structured approach to ensure reliable and consistent human evaluations.
read the caption
Figure 1: (a) An illustration of our human evaluation protocol. (b) The annotation interface, wherein annotators choose the superior video based on provided evaluation metrics. (c) Instruction and examples to guide used to the 'Video Quality' evaluation.
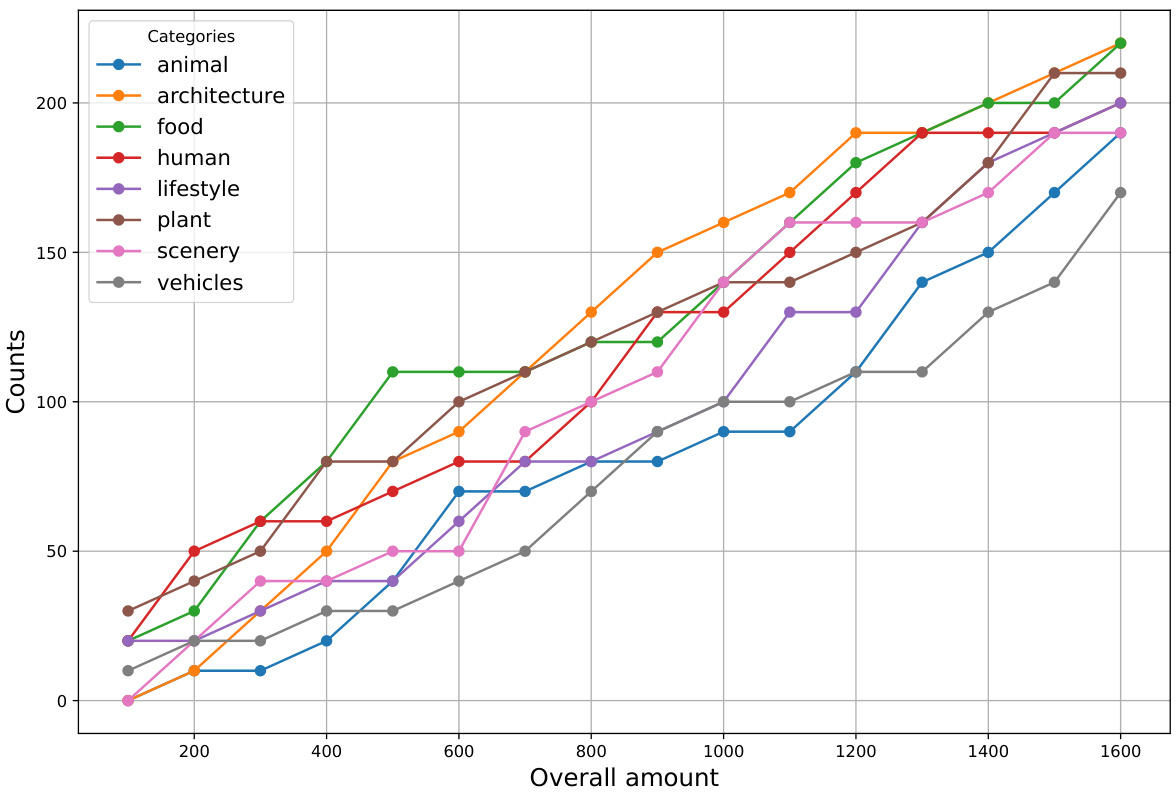
🔼 This figure shows the cumulative number of prompts for each category at different points in the sorting process. The x-axis represents the overall number of video pairs considered, while the y-axis shows the count of prompts from each category. The line graph illustrates how the number of prompts for each category increases as the sorting process progresses, reflecting their relative importance and difficulty in automated evaluation. Categories with steeper curves indicate a higher frequency of occurrence earlier in the sorting process, suggesting they were more easily differentiated by the algorithm.
read the caption
Figure 9: The number of prompts corresponding to each category for different locations at the sorted video pairs.
More on tables

🔼 This table compares the inter-annotator agreement (IAA) scores, using Krippendorff’s alpha, across different annotator groups for various evaluation metrics (Video Quality, Temporal Quality, Motion Quality, Text Alignment, Ethical Robustness, Human Preference). The groups compared are: AMT and pre-training LRAs, AMT and post-training LRAs, and AMT annotators alone. Higher IAA values indicate stronger agreement between annotators, suggesting higher annotation quality and reliability. The table shows a significant improvement in IAA after the post-training of LRAs, bringing their scores closer to those of the AMT annotators.
read the caption
Table 2: Comparison of annotation consensus under different annotator qualifications. We compute Krippendorff's a [47] as an IAA measure. Higher values represent more consensus among annotators.
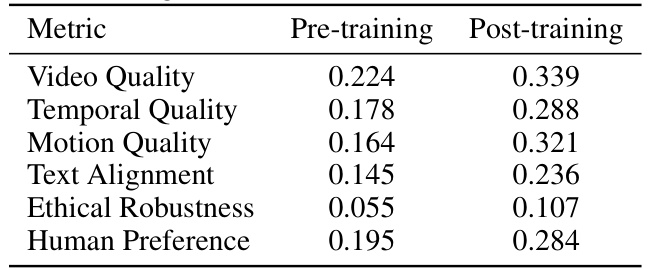
🔼 This table compares the inter-annotator agreement (IAA), measured using Krippendorff’s alpha, across three groups of annotators: AMT annotators (professional crowdworkers), pre-training LRAs (laboratory-recruited annotators before training), and post-training LRAs (laboratory-recruited annotators after training). Higher values of Krippendorff’s alpha indicate better agreement among annotators for a given metric. The table shows that post-training LRAs achieve much higher consensus for all the evaluation metrics (Video Quality, Temporal Quality, Motion Quality, Text Alignment, Ethical Robustness, and Human Preference) compared to the pre-training LRAs. This highlights the significant impact of the training program on improving the quality and reliability of human evaluations.
read the caption
Table 2: Comparison of annotation consensus under different annotator qualifications. We compute Krippendorff's α [47] as an IAA measure. Higher values represent more consensus among annotators.

🔼 This table shows the number of video pairs that were excluded from the human evaluation process by the dynamic evaluation module. The model pairs are grouped by the two models being compared. The dynamic evaluation module prioritizes the annotation of video pairs considered more deserving of manual evaluation during the static annotation phase and discards those with less significance based on the differences in model scores. The ‘Count’ column indicates how many times each pair was discarded across different evaluation metrics. This illustrates how the dynamic module optimizes annotation efficiency by reducing unnecessary manual annotations.
read the caption
Table 4: Type and number of model pairs discarded in dynamic evaluation.
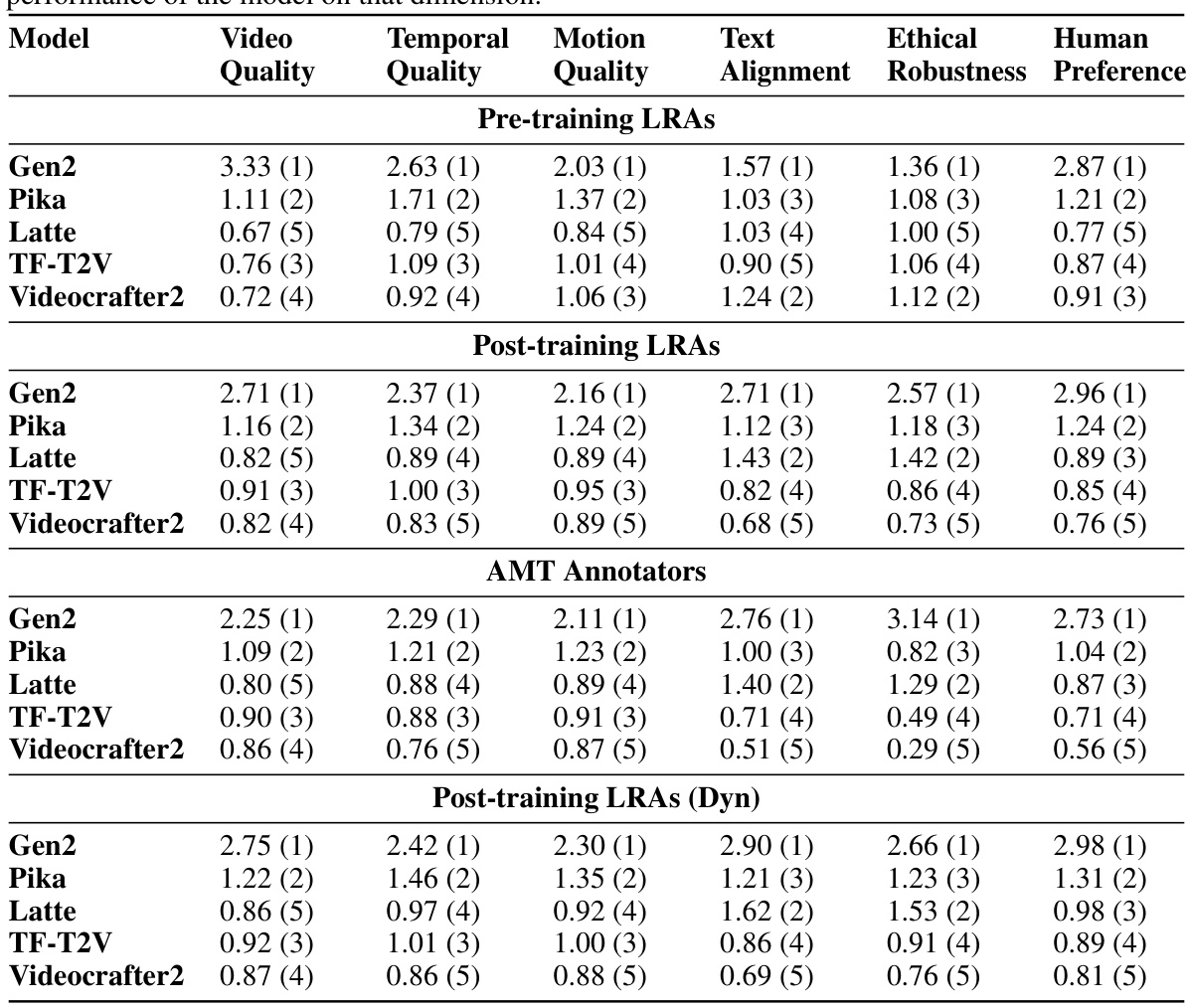
🔼 This table presents a comparison of the scores and rankings of five different text-to-video (T2V) models across six evaluation metrics (Video Quality, Temporal Quality, Motion Quality, Text Alignment, Ethical Robustness, and Human Preference). The comparison is made using three different groups of annotators: pre-trained laboratory-recruited annotators (LRAs), Amazon Mechanical Turk (AMT) annotators, and post-trained LRAs. Additionally, it includes results from post-trained LRAs using a dynamic evaluation module (Dyn), which aims to optimize annotation efficiency. Higher scores indicate better model performance in each metric. The ranking (in parentheses) shows the model’s relative position among the five models for each metric and annotator group.
read the caption
Table 5: Scores and rankings of models across various dimensions for pre-training LRAs, AMT Annotators, and Post-training LRAs. Post-training LRAs (Dyn) refer to the annotation results of Post-training LRAs using the dynamic evaluation component. A higher score represents a better performance of the model on that dimension.

🔼 This table presents a comparison of the scores and rankings of five different text-to-video (T2V) models across six evaluation metrics. Three types of annotators were used: AMT annotators (trained and compensated), pre-training LRAs (laboratory-recruited annotators with minimal training), and post-training LRAs (laboratory-recruited annotators with comprehensive training). The table shows how the scores and rankings vary based on the annotator type and the specific evaluation metric, allowing for an analysis of model performance consistency and the impact of annotator training.
read the caption
Table 5: Scores and rankings of models across various dimensions for pre-training LRAs, AMT Annotators, and Post-training LRAs. Post-training LRAs (Dyn) refer to the annotation results of Post-training LRAs using the dynamic evaluation component. A higher score represents a better performance of the model on that dimension.
🔼 This table presents a comparison of the scores and rankings of five different text-to-video (T2V) models across six evaluation metrics (Video Quality, Temporal Quality, Motion Quality, Text Alignment, Ethical Robustness, Human Preference) using three different groups of annotators: AMT annotators, pre-training LRAs, and post-training LRAs. It also shows the results for the post-training LRAs when using the dynamic evaluation module. Higher scores indicate better performance on the metric.
read the caption
Table 5: Scores and rankings of models across various dimensions for pre-training LRAs, AMT Annotators, and Post-training LRAs. Post-training LRAs (Dyn) refer to the annotation results of Post-training LRAs using the dynamic evaluation component. A higher score represents a better performance of the model on that dimension.

🔼 This table presents the results of human evaluation for the ‘Animal’ prompt category. It shows the average scores and rankings of five different text-to-video models (Gen2, Pika, Latte, TF-T2V, and Videocrafter2) across six evaluation metrics: Video Quality, Temporal Quality, Motion Quality, Text Alignment, Ethical Robustness, and Human Preference. The numbers in parentheses indicate the ranking of each model for that specific metric.
read the caption
Table 8: Prompt Category - Animal

🔼 This table presents a comparison of the scores and rankings of five different text-to-video (T2V) models across six evaluation dimensions. The scores are averages from three different groups of annotators: those who received pre-training, those who used Amazon Mechanical Turk (AMT), and those with post-training. The ‘Dyn’ column indicates scores from post-training annotators who used a dynamic evaluation module, a new efficiency enhancement proposed in the paper. The table helps to demonstrate the consistency of the proposed evaluation method across different annotator groups and highlights which models perform best in each dimension, offering a nuanced view of each model’s strengths and weaknesses.
read the caption
Table 5: Scores and rankings of models across various dimensions for pre-training LRAs, AMT Annotators, and Post-training LRAs. Post-training LRAs (Dyn) refer to the annotation results of Post-training LRAs using the dynamic evaluation component. A higher score represents a better performance of the model on that dimension.
🔼 This table presents the scores and rankings of five different text-to-video (T2V) models across six evaluation metrics: Video Quality, Temporal Quality, Motion Quality, Text Alignment, Ethical Robustness, and Human Preference. The scores are obtained from three different groups of annotators: AMT annotators, pre-trained laboratory-recruited annotators (LRAs), and post-trained LRAs. The table also shows a comparison of results when using a dynamic evaluation module (Post-training LRAs (Dyn)). Higher scores indicate better performance on the given metric.
read the caption
Table 5: Scores and rankings of models across various dimensions for pre-training LRAs, AMT Annotators, and Post-training LRAs. Post-training LRAs (Dyn) refer to the annotation results of Post-training LRAs using the dynamic evaluation component. A higher score represents a better performance of the model on that dimension.

🔼 This table presents a comparison of the scores and rankings of five different text-to-video (T2V) models across six evaluation metrics. Three different groups of annotators were used: AMT annotators, pre-training LRAs, and post-training LRAs. Post-training LRAs (Dyn) refers to the results when the dynamic evaluation component was used, which aims to reduce annotation cost. Each metric assesses a different aspect of T2V model quality, such as video quality, temporal quality, motion quality, text alignment, ethical robustness, and human preference. The numbers in parentheses show the rank of each model for each metric.
read the caption
Table 5: Scores and rankings of models across various dimensions for pre-training LRAs, AMT Annotators, and Post-training LRAs. Post-training LRAs (Dyn) refer to the annotation results of Post-training LRAs using the dynamic evaluation component. A higher score represents a better performance of the model on that dimension.
🔼 This table presents a comparison of the scores and rankings of five different text-to-video (T2V) models across six evaluation metrics: Video Quality, Temporal Quality, Motion Quality, Text Alignment, Ethical Robustness, and Human Preference. The scores are obtained from three groups of annotators: AMT Annotators, pre-training LRAs, and post-training LRAs. A separate column shows the results for post-training LRAs who used the dynamic evaluation module. Higher scores indicate better model performance on each metric.
read the caption
Table 5: Scores and rankings of models across various dimensions for pre-training LRAs, AMT Annotators, and Post-training LRAs. Post-training LRAs (Dyn) refer to the annotation results of Post-training LRAs using the dynamic evaluation component. A higher score represents a better performance of the model on that dimension.

🔼 This table presents a comparison of the scores and rankings of five different text-to-video (T2V) models across six evaluation dimensions: Video Quality, Temporal Quality, Motion Quality, Text Alignment, Ethical Robustness, and Human Preference. The comparison is made across three groups of annotators: AMT Annotators, pre-training LRAs, and post-training LRAs. The table also includes a separate column for Post-training LRAs who used the dynamic evaluation module. A higher score indicates better performance on that particular metric.
read the caption
Table 5: Scores and rankings of models across various dimensions for pre-training LRAs, AMT Annotators, and Post-training LRAs. Post-training LRAs (Dyn) refer to the annotation results of Post-training LRAs using the dynamic evaluation component. A higher score represents a better performance of the model on that dimension.
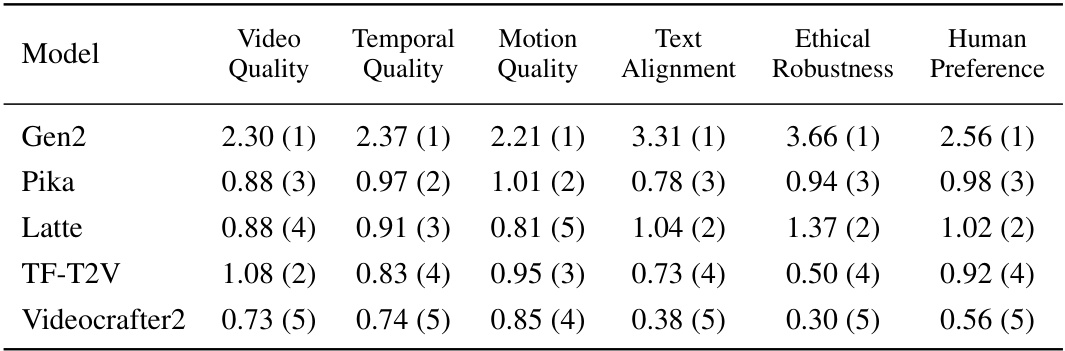
🔼 This table presents a comparison of the scores and rankings of five different text-to-video (T2V) models across six evaluation metrics (Video Quality, Temporal Quality, Motion Quality, Text Alignment, Ethical Robustness, Human Preference). The comparison is made across three different groups of annotators: AMT annotators (trained Amazon Mechanical Turk workers), pre-training LRAs (laboratory-recruited annotators before training), and post-training LRAs (laboratory-recruited annotators after training). A fourth group, Post-training LRAs (Dyn), used the dynamic evaluation module for efficiency. Higher scores indicate better performance on each metric.
read the caption
Table 5: Scores and rankings of models across various dimensions for pre-training LRAs, AMT Annotators, and Post-training LRAs. Post-training LRAs (Dyn) refer to the annotation results of Post-training LRAs using the dynamic evaluation component. A higher score represents a better performance of the model on that dimension.
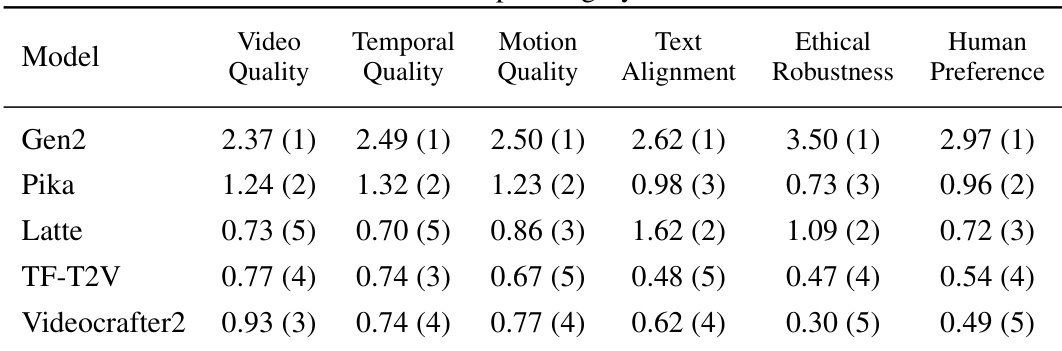
🔼 This table presents the scores and rankings of five different text-to-video (T2V) models across six evaluation metrics: Video Quality, Temporal Quality, Motion Quality, Text Alignment, Ethical Robustness, and Human Preference. The scores are based on evaluations from three types of annotators: AMT annotators, pre-training LRAs, and post-training LRAs. The table also includes a comparison for post-training LRAs using the dynamic evaluation module.
read the caption
Table 5: Scores and rankings of models across various dimensions for pre-training LRAs, AMT Annotators, and Post-training LRAs. Post-training LRAs (Dyn) refer to the annotation results of Post-training LRAs using the dynamic evaluation component. A higher score represents a better performance of the model on that dimension.
Full paper#