TL;DR#
Many machine learning models trained on biased data inadvertently learn spurious correlations, hindering generalization. Existing debiasing methods often rely on bias annotations or data augmentation, which can be expensive and time-consuming. This is problematic as it creates difficulties when obtaining such bias labels with human resources.
This paper introduces DeNetDM, a novel debiasing method that utilizes network depth modulation to identify and mitigate spurious correlations without bias annotations or explicit data augmentation. DeNetDM utilizes a training paradigm inspired by the Product of Experts, creating both biased and debiased branches (with deep and shallow architectures) and then distilling knowledge to produce a target, debiased model. Experiments demonstrate that DeNetDM outperforms existing debiasing techniques, achieving a 5% improvement in accuracy on benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is significant because it offers a novel, annotation-free debiasing method. It addresses a critical limitation in current debiasing techniques by leveraging network depth to mitigate spurious correlations without explicit data augmentation or reweighting, improving generalizability and efficiency. Its theoretical framework and empirical results provide valuable insights for future research in AI fairness and robustness.
Visual Insights#

🔼 This figure illustrates the DeNetDM framework, which consists of two stages. Stage 1 uses a product of experts approach with deep and shallow branches to separate bias and core attributes. Stage 2 introduces a target branch with the desired architecture, using knowledge distillation from the previous stage to refine its feature extractor and classifier head. The goal is to create a debiased model without relying on explicit bias annotations or data augmentation.
read the caption
Figure 1: Illustration of the DeNetDM framework: In Stage 1, an ensemble of shallow and deep branches produces outputs linearly combined and trained as a product of experts. The cross-entropy loss with depth modulation aids in separating biases and identifying target attributes. In Stage 2, we further introduce a target branch with the desired architecture, which also requires debiasing. This phase exclusively focuses on refining the target branch's feature extractor ($t) and classifier head (ft) while leveraging knowledge from the initial stages.
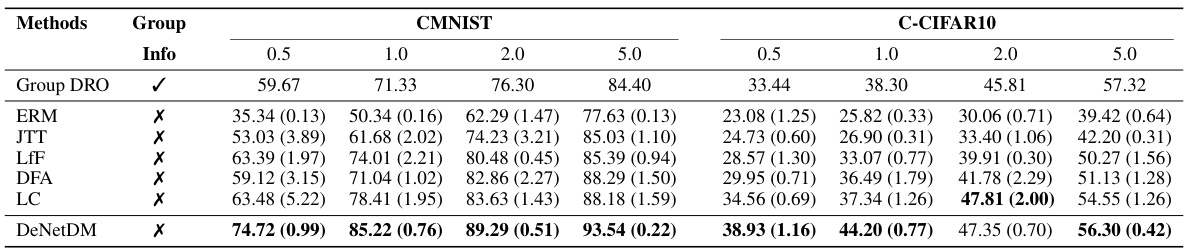
🔼 This table presents the testing accuracy achieved by different debiasing methods on CMNIST and C-CIFAR10 datasets. Different percentages of bias-conflicting samples are considered to evaluate the robustness of the methods. Baseline results from Liu et al. (2023) are included for comparison on C-CIFAR10. The table also indicates whether each method requires spurious attribute annotations.
read the caption
Table 1: Testing accuracy on CMNIST and C-CIFAR10, considering diverse percentages of bias-conflicting samples. Baseline results for C-CIFAR10 are taken from Liu et al. (2023), as we employ the same experimental settings. For CMNIST, we utilize the official repositories to obtain the models. Model requirements for spurious attribute annotations (type) are indicated by X (not required) and ✓ (required).
In-depth insights#
Bias & Spuriousness#
The concept of bias and spuriousness in machine learning is crucial. Bias refers to systematic errors in a model’s predictions due to skewed training data, often reflecting societal prejudices. Spurious correlations, on the other hand, involve the model learning relationships between features that are not causally linked but appear correlated in the training data. This leads to poor generalization, as the model fails to identify true relationships. Addressing bias requires careful data curation, algorithmic adjustments (e.g., re-weighting samples), or incorporating fairness constraints. Dealing with spuriousness necessitates techniques like data augmentation, regularization, or model architectures that inherently focus on robust features. The interplay between bias and spuriousness is complex: bias can amplify spurious correlations, making it vital to consider them in tandem for robust and unbiased AI systems. Mitigating bias and spuriousness is essential for developing responsible and reliable AI models.
Depth Modulation#
Depth modulation, in the context of this research, is a novel technique for debiasing neural networks. The core idea revolves around the observation that deeper networks tend to prioritize learning spurious correlations (biases) present in the training data, while shallower networks focus on core attributes. By training both deep and shallow branches simultaneously and then distilling the knowledge from the shallower, debiased branch to a target model, the method effectively mitigates the influence of spurious correlations. This approach leverages the implicit regularization effect of network depth on the rank of the attribute subspace, formally proving a relationship between network depth and the probability of learning attributes of different ranks. This technique offers an elegant way to address the problem of bias in machine learning models without the need for explicit bias annotations or data augmentation, demonstrating the power of architectural choices to improve model robustness and generalization.
Product of Experts#
The Product of Experts (PoE) framework, when applied to debiasing neural networks, offers a powerful way to disentangle spurious correlations from genuine signals. By training separate “expert” networks—one focusing on the biased features (deep) and the other on core attributes (shallow)—PoE leverages the distinct information each captures. The deep expert, due to its architecture, implicitly prioritizes the easily learned spurious features, while the shallow expert is forced to learn from more complex, core signals. This results in a natural separation of bias and core information, improving overall robustness. Knowledge distillation then helps refine a target debiased model, incorporating knowledge from both experts. This approach provides an effective strategy for debiasing without explicit data augmentation or reliance on bias annotations, making it a more efficient and robust method compared to existing techniques.
DeNetDM Results#
The DeNetDM results section would ideally present a comprehensive evaluation of the proposed debiasing method. This would involve demonstrating improved performance on multiple benchmark datasets compared to existing debiasing techniques, showcasing DeNetDM’s effectiveness across various bias types and levels. Key metrics would include accuracy, especially focusing on the performance differences between bias-aligned and bias-conflicting samples, to highlight the reduction in spurious correlations. A detailed analysis of the training dynamics, showing the separation of bias and core attributes across deep and shallow branches, would strengthen the findings. The impact of hyperparameters and architectural choices on DeNetDM’s performance should be carefully examined, potentially through ablation studies. Finally, a discussion of the limitations and potential societal impact of the proposed method would round out the section, ensuring a responsible and comprehensive presentation of the results.
Future of DeNetDM#
The future of DeNetDM looks promising, building upon its current strengths and addressing limitations. Improved scalability is crucial for handling datasets with multiple bias sources. This could involve exploring more efficient feature extraction methods, perhaps incorporating attention mechanisms to selectively focus on relevant features. Extending DeNetDM to other modalities, such as text and audio, would broaden its applicability. Investigating the integration with other debiasing techniques to create hybrid approaches is also important. Formalizing the connection between network depth and rank through more rigorous mathematical analysis would solidify the theoretical foundations. Finally, exploring the potential of DeNetDM for causal inference could open new doors for understanding bias in a more nuanced way. This would move beyond simply identifying and mitigating bias to understanding the underlying causal mechanisms that create it.
More visual insights#
More on figures
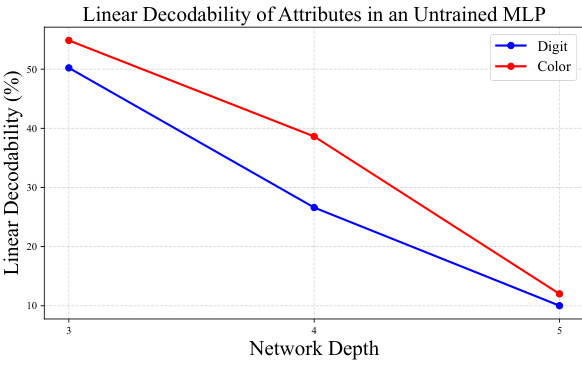
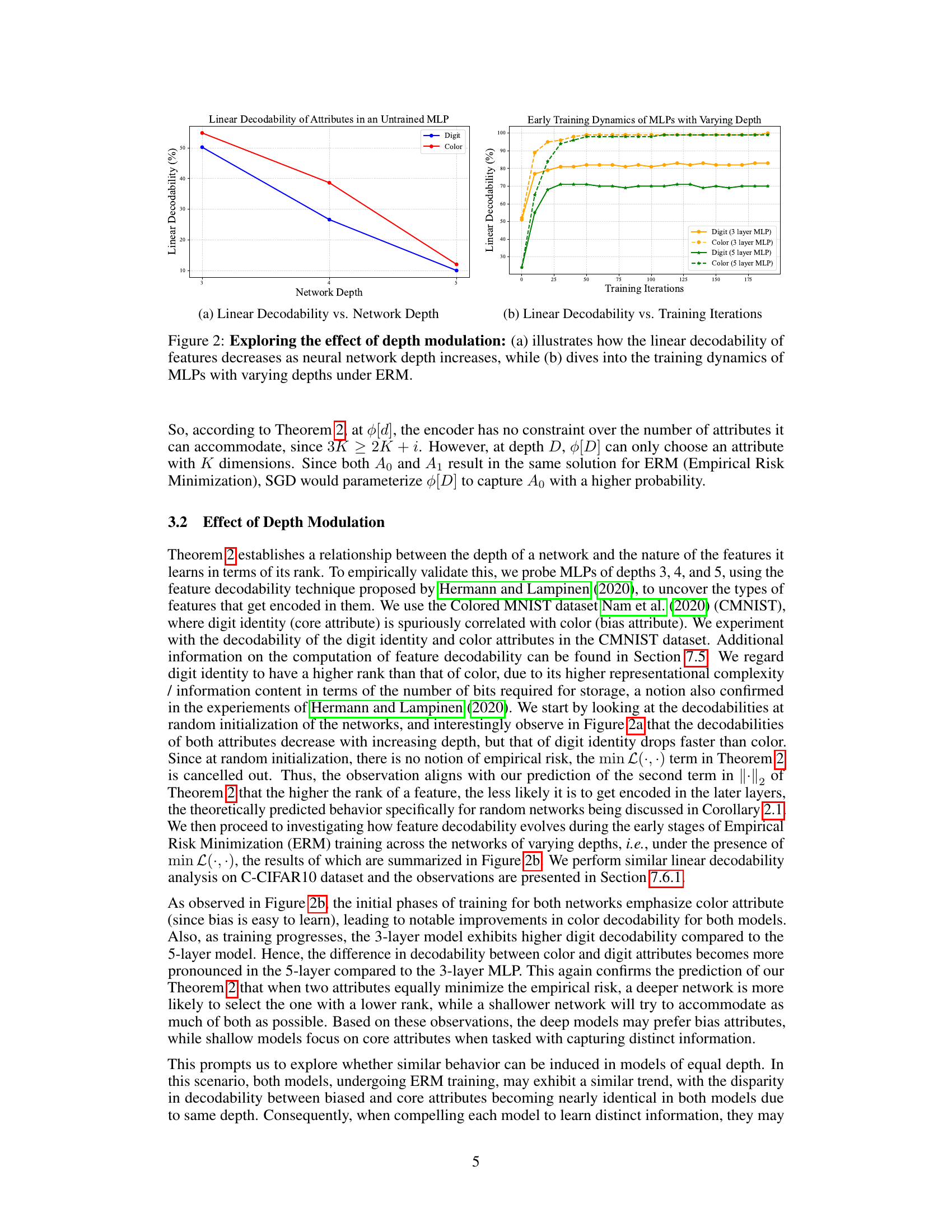
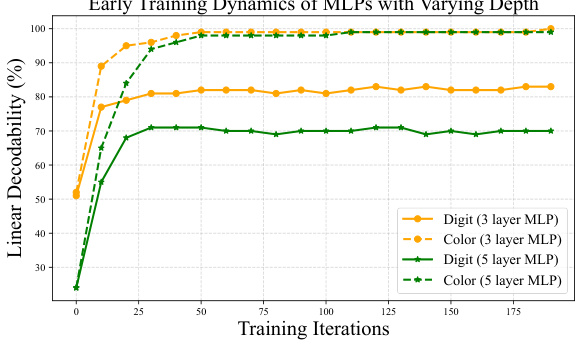
🔼 This figure explores how network depth affects feature decodability. Part (a) shows that as network depth increases, the linear decodability of both digit (core attribute) and color (bias attribute) features decreases, but the core attribute’s decodability drops more steeply. Part (b) examines the training dynamics, showing that during early training, both attributes’ decodability increases, but the bias attribute’s improvement is more pronounced, especially in deeper networks. This suggests that deeper networks are more likely to focus on spurious correlations (bias attributes).
read the caption
Figure 2: Exploring the effect of depth modulation: (a) illustrates how the linear decodability of features decreases as neural network depth increases, while (b) dives into the training dynamics of MLPs with varying depths under ERM.
🔼 This figure shows two graphs that explore the relationship between network depth and feature decodability. Graph (a) shows how the linear decodability of both digit (core attribute) and color (bias attribute) decreases with increasing network depth. Graph (b) displays the training dynamics of MLPs with varying depths. This graph shows how the linear decodability of the features changes during the training process under empirical risk minimization (ERM).
read the caption
Figure 2: Exploring the effect of depth modulation: (a) illustrates how the linear decodability of features decreases as neural network depth increases, while (b) dives into the training dynamics of MLPs with varying depths under ERM.

🔼 This figure shows two graphs that explore the effect of network depth on feature decodability. Graph (a) demonstrates how the linear decodability of both digit and color features decreases as the network depth increases in an untrained MLP. Graph (b) shows the training dynamics of MLPs with varying depths; specifically, how the linear decodability of these features changes during training under Empirical Risk Minimization (ERM).
read the caption
Figure 2: Exploring the effect of depth modulation: (a) illustrates how the linear decodability of features decreases as neural network depth increases, while (b) dives into the training dynamics of MLPs with varying depths under ERM.

🔼 This figure shows two plots. Plot (a) shows that the linear decodability of both digit and color attributes decreases with increasing network depth in an untrained network. Plot (b) illustrates how the linear decodability of digit and color features change during training for MLPs with 3 and 5 layers, showing that the 3-layer model maintains higher decodability of digit attributes (core attributes) compared to the 5-layer model throughout training. This observation supports the claim that deeper networks prioritize bias attributes while shallower networks retain more core attributes.
read the caption
Figure 2: Exploring the effect of depth modulation: (a) illustrates how the linear decodability of features decreases as neural network depth increases, while (b) dives into the training dynamics of MLPs with varying depths under ERM.

🔼 The figure illustrates the DeNetDM framework, which consists of two stages. In Stage 1, a deep and a shallow branch are trained simultaneously using a product of experts approach to separate bias and core attributes. In Stage 2, a target branch with the desired architecture is trained using knowledge distillation from Stage 1 to refine the feature extractor and classifier, focusing solely on debiasing.
read the caption
Figure 1: Illustration of the DeNetDM framework: In Stage 1, an ensemble of shallow and deep branches produces outputs linearly combined and trained as a product of experts. The cross-entropy loss with depth modulation aids in separating biases and identifying target attributes. In Stage 2, we further introduce a target branch with the desired architecture, which also requires debiasing. This phase exclusively focuses on refining the target branch's feature extractor ($t) and classifier head (ft) while leveraging knowledge from the initial stages.
More on tables
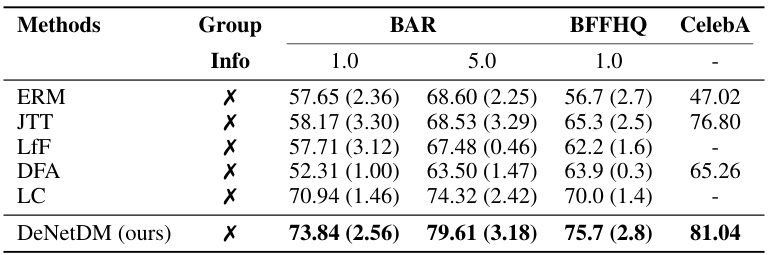
🔼 This table presents the testing accuracy of different debiasing methods on three real-world datasets: Biased Facial Attributes in the Wild HQ (BFFHQ), Biased Action Recognition (BAR), and CelebFaces Attributes Dataset (CelebA). The test sets for BAR and BFFHQ include only bias-conflicting samples. The results are compared against several baseline methods, using the same experimental setup. This allows for a fair comparison and demonstrates DeNetDM’s effectiveness in debiasing across varied datasets.
read the caption
Table 2: Testing accuracy on BAR, BFFHQ, and CelebA. The test set for BAR and BFFHQ contains only bias-conflicting samples. Baseline method results are derived from Lim et al. (2023) for BAR, Liu et al. (2023) for BFFHQ, and Park et al. (2023) for CelebA on the same dataset split since we utilize identical experimental settings.
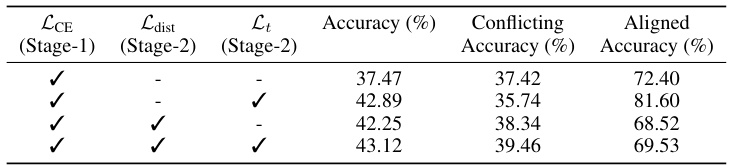
🔼 This ablation study analyzes the impact of different loss functions in the DeNetDM model on the C-CIFAR10 dataset. It shows the overall accuracy and accuracy on bias-aligned and bias-conflicting points by removing loss components one by one. Results reveal that all loss components are crucial for optimizing the model’s performance and minimizing spurious correlation.
read the caption
Table 3: Ablation study of different losses used in DeNetDM on C-CIFAR10.

🔼 This table compares the worst-group accuracy achieved by different debiasing methods on the CivilComments dataset. The worst-group accuracy is a metric used to evaluate fairness in a model’s predictions by focusing on the performance on the group that was predicted least accurately. The table shows that DeNetDM achieves comparable performance to other state-of-the-art methods.
read the caption
Table 4: Worst group accuracy (%) comparison between different methods on CivilComments dataset.
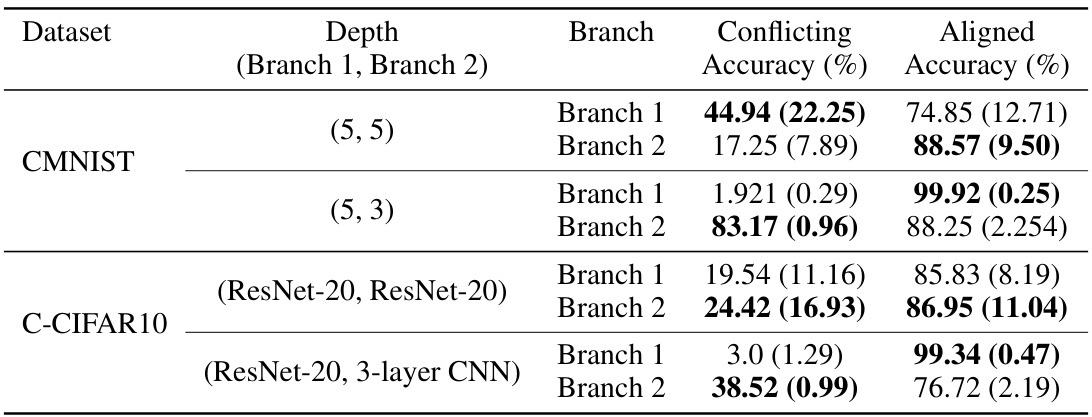
🔼 This table presents the results of an ablation study on DeNetDM, where the depths of the two branches (deep and shallow) are varied. It shows the conflicting and aligned accuracy for each branch configuration across two datasets, CMNIST and C-CIFAR10. The results demonstrate the impact of depth modulation on the ability of the network to learn bias and core attributes.
read the caption
Table 5: Performance of DeNetDM using different network depths for the two branches of DeNetDM.
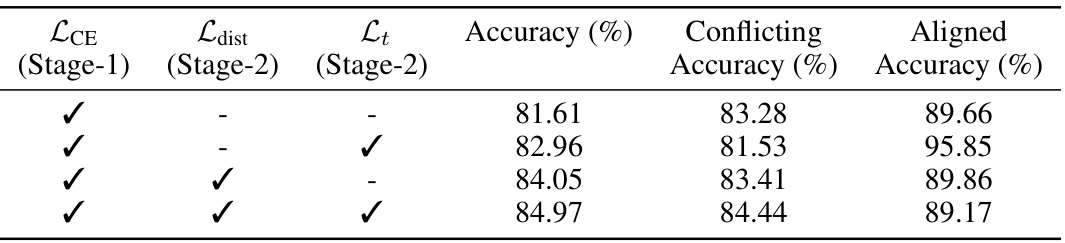
🔼 This table presents the ablation study results on the CMNIST dataset, showing the impact of different loss functions (LCE, Ldist, Lt) on the model’s performance. It breaks down the accuracy into aligned accuracy (on bias-aligned samples) and conflicting accuracy (on bias-conflicting samples). The results demonstrate how different combinations of the loss functions contribute to the final model’s ability to distinguish between bias and core attributes.
read the caption
Table 6: Ablation study of different losses used in DeNetDM on CMNIST dataset.
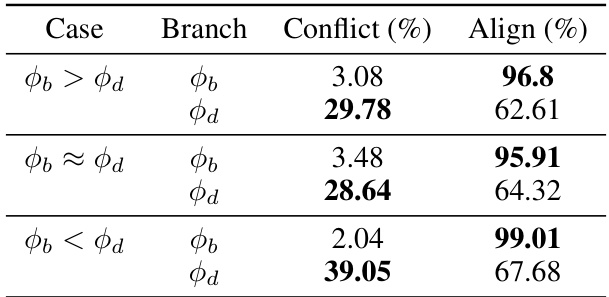
🔼 This table presents the results of an ablation study conducted on the C-CIFAR10 dataset to investigate the impact of varying the number of parameters in the deep and shallow branches of the DeNetDM model on its performance. Three different cases are explored: where the number of parameters in the deep branch is greater than, approximately equal to, and less than the number of parameters in the shallow branch. For each case, the table shows the conflict and aligned accuracy achieved by both the deep and shallow branches. The results demonstrate how the number of parameters in each branch affects its ability to learn and distinguish bias from core attributes.
read the caption
Table 7: Ablation study on the number of parameters of deep and shallow branches in DeNetDM using C-CIFAR10 dataset.

🔼 This table presents the ablation study results on the CMNIST dataset, evaluating the effect of varying the number of parameters in the deep and shallow branches of the DeNetDM model on the conflicting and aligned accuracy. It shows the performance across three scenarios: when the shallow branch has fewer parameters than the deep branch, when they have approximately equal number of parameters and when the shallow branch has more parameters than the deep branch.
read the caption
Table 8: Ablation study on the number of parameters of deep and shallow branches in DeNetDM using CMNIST dataset.

🔼 This table shows the results of an ablation study on DeNetDM where the depth of the shallow and deep branches were varied. It demonstrates how the performance of the debiased model is affected by the difference in depth between the two branches. Larger differences in depth lead to better performance, indicating the importance of depth modulation in DeNetDM’s ability to distinguish between bias and core attributes.
read the caption
Table 9: Performance comparison of DeNetDM for various depths of shallow and deep branches.

🔼 This table shows the testing accuracy of different debiasing methods on CMNIST and C-CIFAR10 datasets with varying percentages of bias-conflicting samples. It compares DeNetDM’s performance against several baselines, indicating whether each method requires spurious attribute annotations. The results are presented for different bias ratios (0.5%, 1%, 2%, 5%).
read the caption
Table 1: Testing accuracy on CMNIST and C-CIFAR10, considering diverse percentages of bias-conflicting samples. Baseline results for C-CIFAR10 are taken from Liu et al. (2023), as we employ the same experimental settings. For CMNIST, we utilize the official repositories to obtain the models. Model requirements for spurious attribute annotations (type) are indicated by X (not required) and ✓ (required).

🔼 This table compares the performance of DeNetDM using different depths for the two branches (shallow and deep). It shows the conflicting and aligned accuracy for each branch configuration, demonstrating the impact of depth difference on the model’s ability to separate bias and core attributes.
read the caption
Table 11: Comparison of the performance of DeNetDM using different network depths for the two branches of DeNetDM.

🔼 This table presents the testing accuracy results on CMNIST and C-CIFAR10 datasets for different methods. It compares DeNetDM against several baselines under various bias-conflicting sample percentages (0.5%, 1%, 2%, 5%). The table also indicates whether each method requires explicit bias annotations.
read the caption
Table 1: Testing accuracy on CMNIST and C-CIFAR10, considering diverse percentages of bias-conflicting samples. Baseline results for C-CIFAR10 are taken from Liu et al. (2023), as we employ the same experimental settings. For CMNIST, we utilize the official repositories to obtain the models. Model requirements for spurious attribute annotations (type) are indicated by X (not required) and ✓ (required).
Full paper#