TL;DR#
Federated learning (FL) faces significant communication overhead, especially with large pre-trained models. Existing techniques struggle to balance local training steps and communication efficiency, leading to slow convergence and suboptimal performance due to client drift. The main challenge lies in finding a balance between local training optimization on heterogeneous data and effective model merging across distributed clients, often leading to isolated low-loss valleys instead of a connected low-loss basin.
The proposed solution, Local Superior Soups (LSS), employs a regularized model interpolation technique during local training. This approach uses two novel metrics, diversity and affinity, to guide model selection and interpolation. Diversity promotes exploration of a large connected low-loss basin, while affinity keeps model updates close to the initial pre-trained model, preventing isolated valleys. This efficient local training method ensures seamless and fast model merging with fewer communication rounds, resulting in faster convergence and improved global model performance. Results show that LSS achieves the accuracy of models trained with multiple communication rounds, with only a few communication rounds.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning, particularly those working with large pre-trained models. It offers a novel, efficient solution to reduce communication costs, a major bottleneck in FL. The proposed method, combined with the theoretical analysis, opens up new avenues for improving the scalability and efficiency of FL across diverse datasets and settings. This work significantly contributes to the advancement of FL, making it more practical for real-world applications.
Visual Insights#
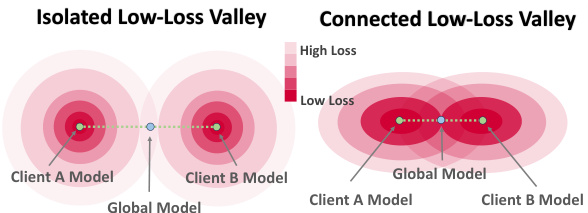
🔼 This figure illustrates the concept of isolated vs. connected low-loss valleys in the context of model training. On the left, two models (from clients A and B) are trained independently and end up in separate low-loss regions. The resulting global model (an average of the two client models) falls into a high-loss region because the individual models’ low-loss valleys are isolated. On the right, training is modified to allow the models to explore overlapping low-loss regions. This results in a connected low-loss region and a global model that performs well, as its parameters reside centrally within this connected region. This highlights the importance of encouraging exploration of connected low-loss regions for better global model performance in federated learning.
read the caption
Figure 1: Illustration on isolated (left) and connected low-loss valley with larger regions in dark red (right).
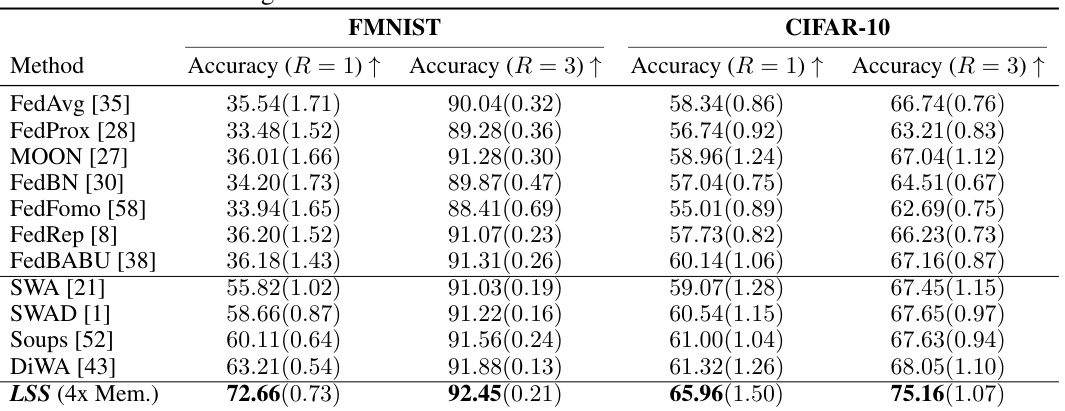
🔼 This table presents the results of label shift experiments on FMNIST and CIFAR-10 datasets. It compares the performance of various federated learning (FL) methods, including both conventional methods and more advanced techniques focused on local weight averaging and fine-tuning to improve domain generalization. The accuracy is measured after 1 and 3 communication rounds, showing how different methods perform with limited communication.
read the caption
Table 1: Label shift test accuracy after R = 1 and R = 3 communication rounds. We primarily compared two categories of methods: conventional FL methods and state-of-the-art local weight averaging-based fine-tuning methods that enhance domain generalization.
In-depth insights#
FL Communication#
In federated learning (FL), communication efficiency is paramount due to the distributed nature of data and model training. Reducing communication rounds is crucial for mitigating bandwidth limitations and improving scalability. Strategies such as model aggregation techniques (e.g., federated averaging) aim to minimize the amount of data exchanged between clients and the server. However, these methods can suffer from challenges related to data heterogeneity and client drift, potentially hindering model convergence and overall performance. Innovative approaches like local model updates and model compression are actively researched to further enhance communication efficiency. The trade-off between local computation and communication overhead is a key consideration in designing efficient FL communication strategies. Security and privacy concerns also play a critical role, necessitating secure communication protocols and techniques to protect sensitive client data during the exchange process. Research into efficient FL communication continues to evolve, with a focus on developing practical solutions that balance efficiency, robustness, and security.
Model Soup Adapt#
The concept of “Model Soup Adapt” suggests a method for adapting pre-trained models, specifically those characterized as “model soups,” to the context of federated learning. Model soups, ensembles of models trained with varied hyperparameters, offer improved generalization. Adapting these to federated learning necessitates addressing the communication overhead inherent in transmitting numerous model weights between clients and server. This adaptation likely involves techniques to reduce model size or the number of communication rounds needed for effective merging of local model soups with the global model. The core challenge would be balancing the benefits of model soup diversity with efficiency constraints of federated training. Successful “Model Soup Adapt” would significantly impact FL by improving generalization, robustness, and the ability to train larger, more complex models on decentralized data. Effective strategies might include model compression, careful selection of representative models from each local soup, or sophisticated interpolation techniques that minimize communication. The success of this approach hinges on demonstrating improved performance compared to standard FL methods, whilst maintaining the generalization advantages provided by model soups.
LSS Regularization#
Local Superior Soups (LSS) regularization is a novel approach designed to enhance the efficiency of model merging in federated learning, particularly when employing pre-trained models. The core idea revolves around regularizing local model training to encourage the formation of a connected low-loss region, thereby mitigating the challenges associated with data heterogeneity and client drift. This is achieved by incorporating two key regularization terms: diversity and affinity. The diversity term promotes the exploration of diverse model parameters during local training, fostering a wider low-loss landscape. Simultaneously, the affinity term guides the search process by ensuring that locally trained models remain sufficiently close to the initially shared pre-trained model, preventing the emergence of isolated low-loss regions. By cleverly balancing these two opposing forces, LSS fosters a faster convergence toward a globally optimal solution, requiring far fewer communication rounds than traditional methods.
Non-IID Data#
Non-IID (Independent and Identically Distributed) data poses a significant challenge in federated learning, as it violates the fundamental assumption that data points are independent and identically distributed across different clients. This heterogeneity leads to inconsistencies in local model updates, hindering the convergence of the global model and potentially resulting in poor generalization performance. Addressing Non-IID data requires careful consideration of various techniques, including data preprocessing and augmentation, model personalization, and robust aggregation strategies. It also highlights the importance of choosing the right model architecture and training methods suitable for handling data heterogeneity. Pre-trained models and transfer learning can often mitigate issues arising from Non-IID data, however, careful consideration is still needed during the fine-tuning stage to avoid issues such as client drift. Ultimately, effective handling of Non-IID data is crucial for developing robust and generalizable federated learning models. Further research should focus on developing efficient and robust techniques specifically designed for handling extreme cases of Non-IID data, improving the understanding of the impact of different levels of Non-IID data on model performance, and on exploring solutions for dynamic data scenarios.
Future of LSS#
The future of Local Superior Soups (LSS) appears promising, given its demonstrated efficiency in reducing communication rounds in federated learning. Future research could focus on enhancing its scalability and adaptability to various data distributions and model architectures. This includes exploring more sophisticated model interpolation techniques, potentially incorporating techniques from other model ensemble methods. Addressing the memory overhead associated with LSS is another key area, perhaps through compression or more efficient model representation. Expanding LSS to handle various tasks beyond image classification, such as natural language processing and multimodal learning, would significantly broaden its applicability. Investigating the robustness of LSS against adversarial attacks and addressing potential privacy concerns are also crucial aspects for future development. Finally, further theoretical analysis to understand the convergence properties and generalization capabilities of LSS under diverse settings would solidify its foundation and guide further improvements.
More visual insights#
More on figures

🔼 This figure illustrates the concepts of diversity and affinity regularization used in the Local Superior Soups (LSS) method. The left panel shows how high diversity among models (larger pairwise distances) leads to a larger covered low-loss region, meaning fewer models are needed to span the region. Conversely, low diversity (models clustered together) results in a smaller covered region. The right panel shows how high affinity (models closer to the initial model) leads to larger overlapping regions between low-loss areas of different clients, while low affinity (models far from the initial model) results in smaller overlapping regions. These visualizations explain how the diversity and affinity metrics guide the model selection and interpolation process within LSS to efficiently explore connected low-loss regions during local training.
read the caption
Figure 2: Illustration on diversity (left) and affinity (right) regularization.
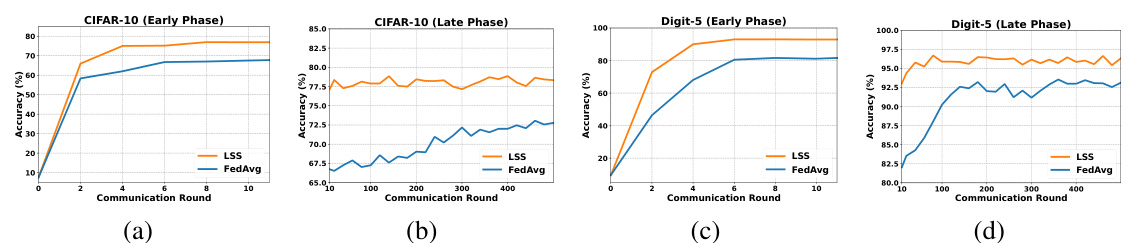
🔼 This figure compares the convergence speed of the proposed Local Superior Soups (LSS) method and the standard FedAvg method. The plots show the training accuracy over communication rounds for both methods on CIFAR-10 and Digit-5 datasets, with separate plots for early and late phases of training. LSS consistently reaches high accuracy within a small number of communication rounds (6-8), significantly outperforming FedAvg, which requires hundreds of rounds to converge.
read the caption
Figure 3: Convergence comparison of our proposed LSS with FedAvg. LSS achieves high accuracy much earlier (around 6 to 8 rounds) than FedAvg, which takes hundreds of communication rounds.

🔼 This figure compares the convergence speed of the proposed Local Superior Soups (LSS) method and the standard Federated Averaging (FedAvg) method. The plots show the accuracy achieved over communication rounds for both methods on four different datasets, namely CIFAR-10 early phase, CIFAR-10 late phase, Digit-5 early phase, and Digit-5 late phase. The results clearly demonstrate that LSS achieves significantly higher accuracy in a substantially smaller number of communication rounds compared to FedAvg, showcasing the efficiency of the proposed method.
read the caption
Figure 3: Convergence comparison of our proposed LSS with FedAvg. LSS achieves high accuracy much earlier (around 6 to 8 rounds) than FedAvg, which takes hundreds of communication rounds.

🔼 This figure shows the ablation study on the affinity and diversity terms in the proposed LSS method. The left subplot (a) shows the effect of varying the affinity coefficient while keeping the diversity coefficient fixed at 0 and 3. The right subplot (b) shows the effect of varying the diversity coefficient while keeping the affinity coefficient fixed at 0 and 3. The results demonstrate the importance of both terms in achieving optimal performance and also highlight the complementary nature of affinity and diversity.
read the caption
Figure 5: Ablation on the affinity & diversity.

🔼 This figure presents the results of ablation studies conducted to investigate the impact of the number of averaged models on various performance metrics. The figure displays three subplots: (a) shows the after-aggregation global performance, (b) shows the before-aggregation global performance, and (c) shows the before-aggregation worst performance. Each subplot illustrates how the performance metric changes as the number of averaged models increases from 2 to 5. This analysis helps understand the optimal number of models for balancing communication efficiency and performance variance in federated learning.
read the caption
Figure 6: Ablation studies on the impact of the number of averaged models on communication efficiency and performance variance. We evaluated the influence of varied model quantities on global and averaged local model performance, as well as generalization on the worst client.
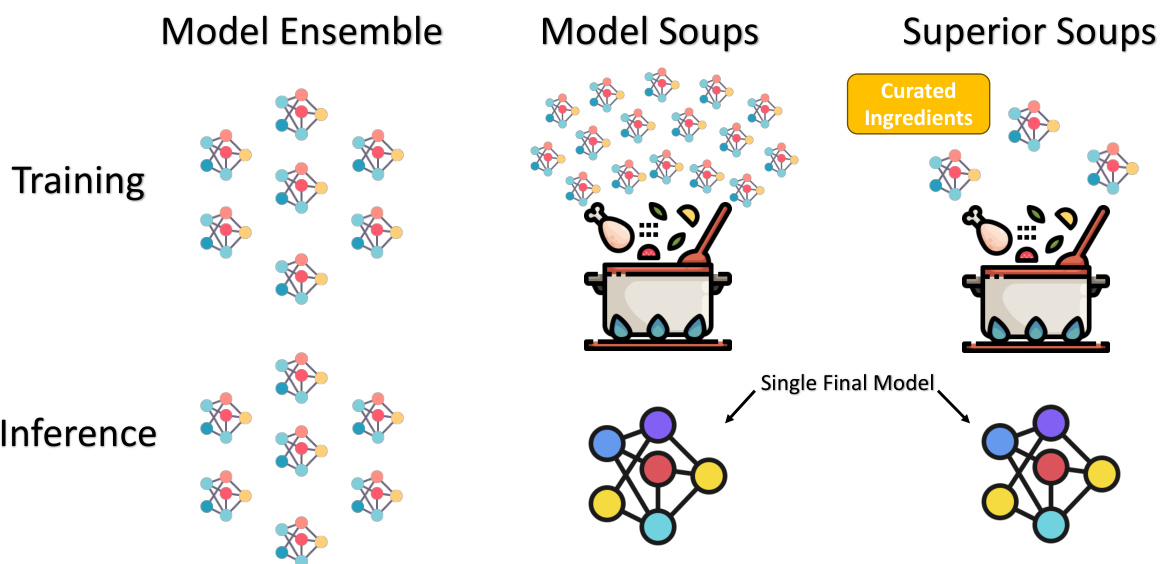
🔼 This figure illustrates the differences between three model aggregation methods: Model Ensemble, Model Soups, and Superior Soups. Model Ensemble shows multiple individual models, implying that many models are independently trained and then combined. Model Soups depicts a large pot with numerous ingredients, representing the training of many models, where the final model is obtained from averaging the weights of many models. Superior Soups refines this further by showing a selection of ‘Curated Ingredients’, indicating that only a subset of carefully selected models are averaged, leading to a single, final model. This highlights the efficiency gain of Superior Soups, which avoids the redundancy of training many less effective models.
read the caption
Figure 7: Comparison on model ensemble, model soups, and superior soups.
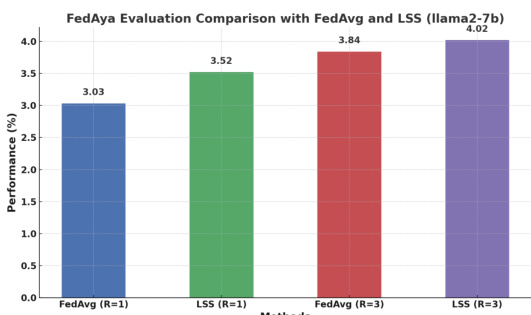
🔼 This figure compares the performance of FedAvg and LSS on a multilingual instruction tuning task using the Llama2-7b language model. The y-axis represents performance (%), and the x-axis shows different methods and numbers of communication rounds (R=1 and R=3). The results demonstrate that LSS consistently outperforms FedAvg, achieving higher scores with fewer communication rounds, suggesting its effectiveness in federated learning for LLMs.
read the caption
Figure 8: FedAya Evaluation Comparison with FedAvg and LSS. Our method, LSS, when applied to large language models for instruction tuning, achieves higher scores than the common FedAvg. This suggests that LSS is a promising approach for improving performance and convergence in federated learning settings for large language models, in addition to its success in image classification. Exploring the use of our method in a diverse set of complex LLM tasks is an interesting direction for future research.
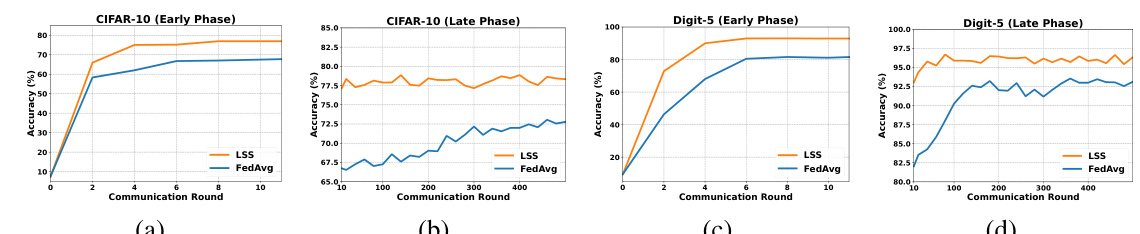
🔼 This figure compares the convergence speed of the proposed Local Superior Soups (LSS) method and the standard Federated Averaging (FedAvg) method on four different scenarios: CIFAR-10 early phase, CIFAR-10 late phase, Digit-5 early phase, and Digit-5 late phase. The x-axis represents the number of communication rounds, and the y-axis represents the accuracy. The plots demonstrate that LSS achieves significantly higher accuracy with far fewer communication rounds than FedAvg. This highlights the efficiency of LSS in reducing communication overhead during federated learning.
read the caption
Figure 3: Convergence comparison of our proposed LSS with FedAvg. LSS achieves high accuracy much earlier (around 6 to 8 rounds) than FedAvg, which takes hundreds of communication rounds.
More on tables
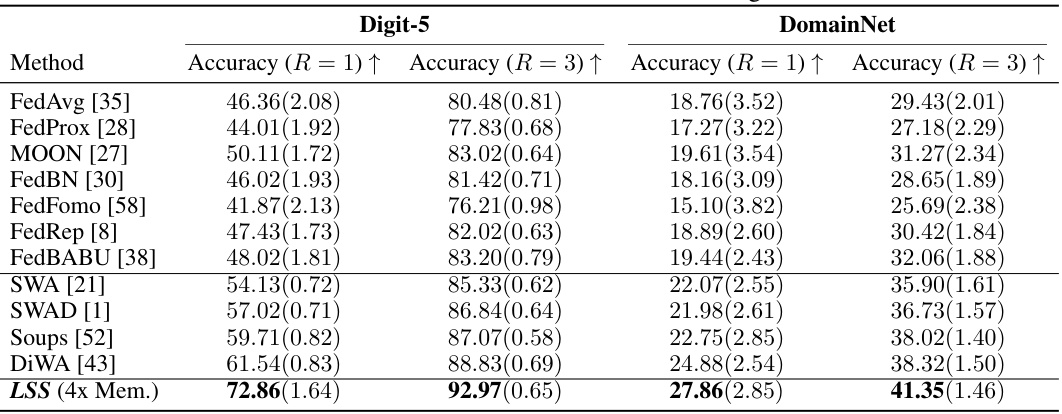
🔼 This table presents the results of experiments conducted to evaluate the performance of Local Superior Soups (LSS) and other federated learning methods under feature shift conditions. The accuracy of different algorithms is compared on two datasets (Digit-5 and DomainNet) after 1 and 3 communication rounds. The results show that LSS consistently achieves higher accuracy than other methods, highlighting its effectiveness in handling feature shift in federated learning.
read the caption
Table 2: Feature shift test accuracy after R = 1 and R = 3 communication rounds. LSS consistently outperforms other methods on both datasets across under feature shift settings.

🔼 This table presents the test accuracy results for various federated learning methods under label shift conditions. The accuracy is measured after 1 and 3 communication rounds. The methods are categorized into conventional FL methods and advanced methods using local weight averaging and fine-tuning for improved domain generalization. The results show how different methods perform under limited communication rounds in a challenging non-IID data scenario.
read the caption
Table 1: Label shift test accuracy after R = 1 and R = 3 communication rounds. We primarily compared two categories of methods: conventional FL methods and state-of-the-art local weight averaging-based fine-tuning methods that enhance domain generalization.

🔼 This table presents the results of experiments using the FedAvg algorithm with varying numbers of local training steps (τ) on the CIFAR-10 dataset under a label shift scenario. The test accuracy is reported after a single round of communication (R=1) for five clients. The results show how changing the number of local training steps affects the model’s performance in this setting. It demonstrates that arbitrarily increasing local steps may not always lead to improved performance.
read the caption
Table 4: FedAvg with different local steps: Label shift test accuracy after R = 1 communication rounds (CIFAR-10 with 5 Clients).

🔼 This table compares the computational overhead (in Giga MACs) and memory usage for different federated learning methods, including FedAvg, SWA, Soups, and LSS. It shows that while LSS has higher computational costs per epoch and round than FedAvg and SWA, its training time per round is significantly less than Soups due to its more efficient model selection and training process. The memory usage is also shown.
read the caption
Table 5: Computational and memory costs of different types of method (ResNet-18).

🔼 This table presents the results of an experiment designed to evaluate the robustness of the trained models to noise perturbation. It shows the performance degradation (drop in accuracy) of models trained using FedAvg and the proposed LSS method when different levels of noise are added to the test set. Lower values indicate better robustness. The experiment uses the CIFAR-10 dataset with two different Dirichlet distributions (α=1.0 and α=0.1) to simulate different levels of label shift.
read the caption
Table 6: Smoothness of the trained model. Evaluated trained model performance drop on a testset with added l∞ norm random noise. CIFAR-10 dataset Dirichlet distribution a = 1.0 and a = 0.1: Label shift test accuracy after R = 1
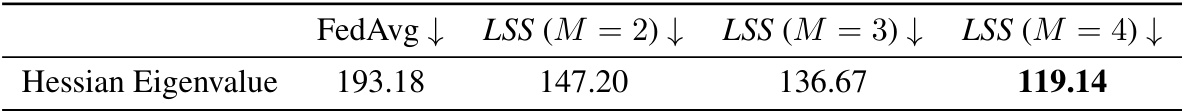
🔼 This table presents the Hessian eigenvalue, a metric used to quantify the flatness of the loss landscape, for different methods. Lower values indicate flatter minima, generally associated with better generalization. The table compares FedAvg to Local Superior Soups (LSS) with varying numbers of averaged models (M).
read the caption
Table 7: Loss landscape flatness quantification with Hessian eigenvalue.

🔼 This table presents the results of experiments conducted to evaluate the performance of the proposed LSS method and the baseline FedAvg method under different numbers of clients (5 and 50) in a label shift scenario. The accuracy of both methods is measured after 1 and 3 communication rounds. The results demonstrate that LSS consistently outperforms FedAvg across different client numbers and communication rounds, highlighting its efficiency and effectiveness in handling the complexities of federated learning with a larger number of clients.
read the caption
Table 8: Different client numbers (5 Clients and 50 Clients): Label shift test accuracy after R = 1 and R = 3 communication rounds.

🔼 This table presents the results of experiments conducted to evaluate the performance of Local Superior Soups (LSS) and other baseline methods under feature shift conditions. The accuracy of models is compared after 1 and 3 communication rounds on two datasets, Digit-5 and DomainNet. The results demonstrate that LSS consistently outperforms all other methods across both datasets and communication round settings, highlighting its effectiveness in handling feature shift in federated learning.
read the caption
Table 2: Feature shift test accuracy after R = 1 and R = 3 communication rounds. LSS consistently outperforms other methods on both datasets across under feature shift settings.

🔼 This table presents the results of experiments conducted to evaluate the performance of FedAvg and the proposed LSS method under different levels of data heterogeneity. The experiments were performed on the CIFAR-10 dataset with two different Dirichlet distribution parameters (α = 1.0 and α = 0.1), representing different levels of Non-IID data. The table shows the test accuracy achieved by each method after 1 and 3 communication rounds. The results demonstrate the effectiveness of LSS in achieving higher accuracy compared to FedAvg, especially in scenarios with higher data heterogeneity (α = 0.1).
read the caption
Table 10: Different Non-IID level (Dirichlet distribution α = 1.0 and α = 0.1): Label shift test accuracy after R = 1 and R = 3 communication rounds.

🔼 This table compares the performance of FedAvg and LSS on CIFAR-10 dataset under label shift with two different model initializations: pre-trained and random. The results show that LSS outperforms FedAvg in both cases, achieving higher accuracy after 1 and 3 communication rounds. However, the performance gap is more significant when using pre-trained initialization.
read the caption
Table 11: Different model initialization (Pre-trained v.s. Random): Label shift test accuracy after R = 1 and R = 3 communication rounds. Result: It shows that our method still maintains a significant advantage with random initialization, but it does not achieve the near-optimal performance seen with pre-trained initialization.
Full paper#