TL;DR#
Large Language Models (LLMs) are increasingly used in applications needing long context windows, but this leads to a major memory bottleneck in inference due to the size of KV cache activations. Existing quantization methods struggle to compress these activations accurately at low precision.
KVQuant tackles this problem by introducing several novel methods: per-channel key quantization to better match data distribution, pre-RoPE key quantization to mitigate the impact of rotary positional embeddings, non-uniform KV cache quantization for improved accuracy, and per-vector dense-and-sparse quantization for handling outliers. Experimental results using various LLMs and datasets demonstrate significant perplexity improvements with 3-bit quantization, outperforming previous methods and enabling substantially longer context lengths with significant memory savings and speedups.
Key Takeaways#
Why does it matter?#
This paper is highly relevant to researchers working on large language models (LLMs) and efficient inference. It addresses the critical challenge of memory limitations in LLMs with long context windows, a significant hurdle in deploying these models effectively. The proposed techniques offer substantial improvements in efficiency and pave the way for enabling longer context lengths in LLMs, expanding their applications and capabilities. Furthermore, the methodology developed here offers new avenues of exploration for low-bit quantization methods within the LLM space.
Visual Insights#
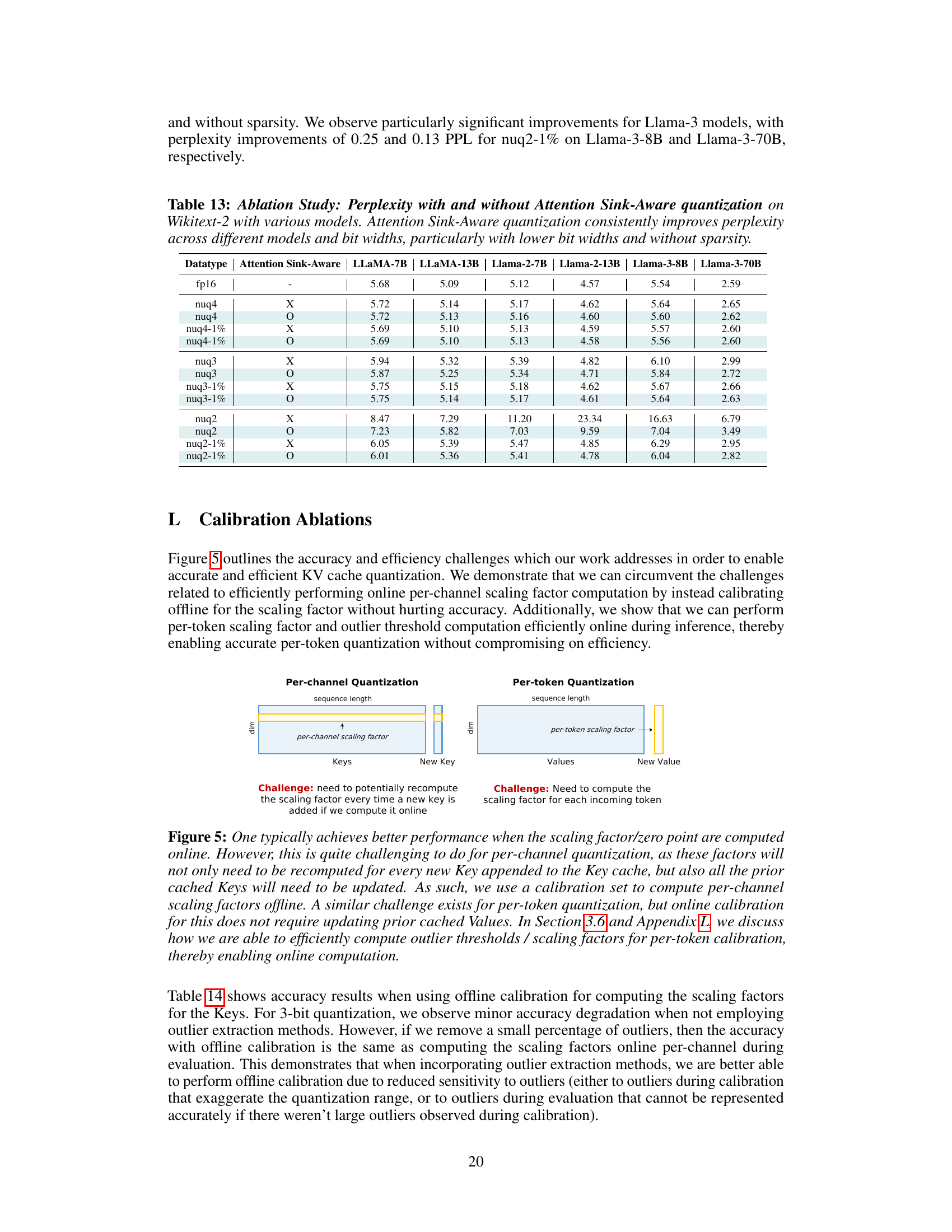
🔼 The figure shows a comparison of memory usage between weights and KV cache activations for the LLaMA-7B model at different sequence lengths. It highlights that while weights dominate memory at short sequence lengths, the KV cache becomes the dominant memory bottleneck as sequence length increases. The right-hand side presents an overview of the KVQuant method’s components and demonstrates the perplexity improvement achieved by reducing the KV cache memory footprint through 3-bit quantization.
read the caption
Figure 1: Left: Model size versus activation memory size for the LLaMA-7B model with sequence length 512 and 128K. For longer context lengths, the KV cache becomes the dominant memory bottleneck. Memory consumption of model weights and KV cache activations for different LLaMA models with different sequence lengths are provided in Table 7 in Appendix A. Right: Overview of the different components used in KVQuant that result in less than 0.1 perplexity degradation over the fp16 baseline when quantizing the KV cache for the LLaMA-7B model to 3-bit precision. As shown in Table 1, our 3-bit approach results in 4.8× reduction in cached activation memory footprint.
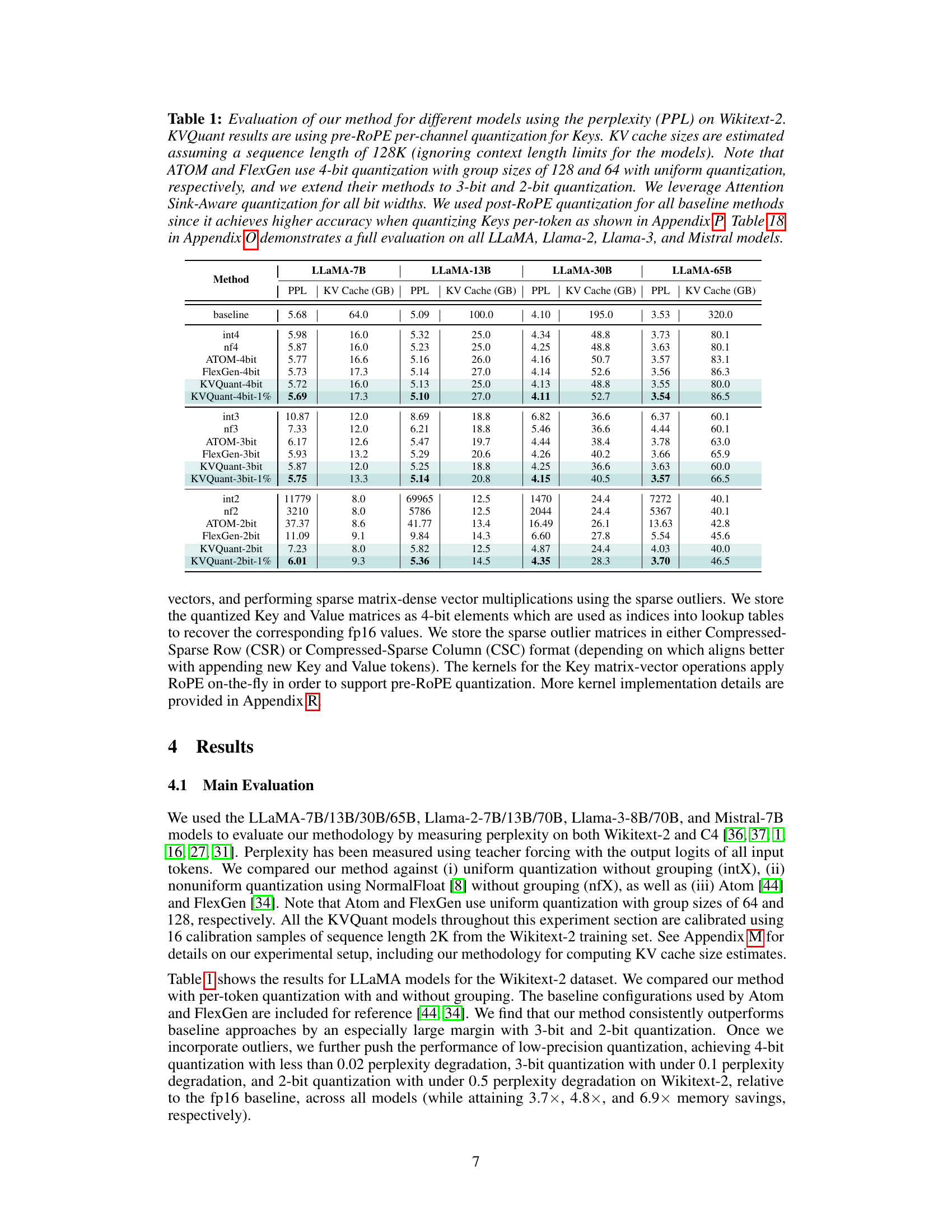
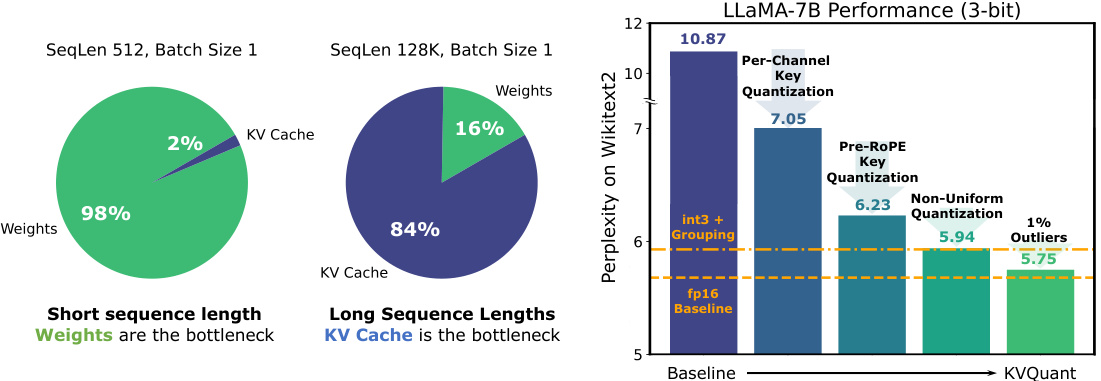
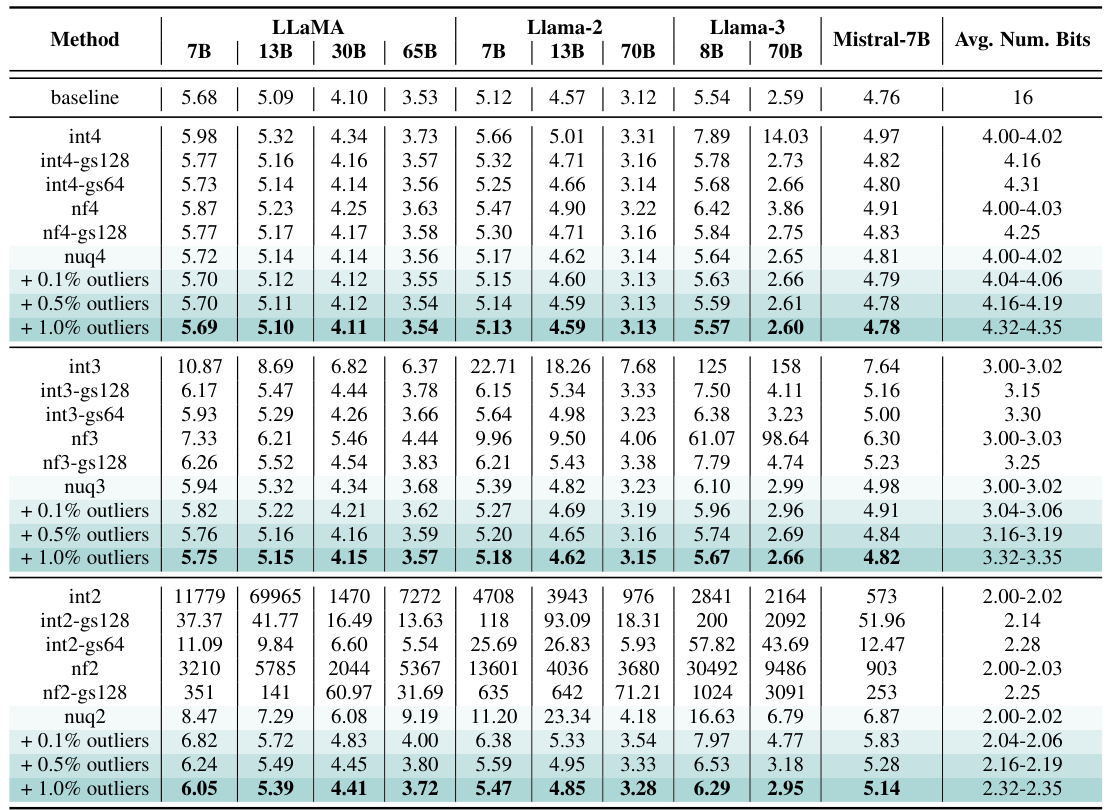
🔼 This table presents the perplexity scores on the Wikitext-2 dataset for various LLMs (LLaMA, LLaMA-2, LLaMA-3, and Mistral) using different quantization methods (uniform, non-uniform, ATOM, FlexGen, and KVQuant). It shows the impact of different bit precisions (4-bit, 3-bit, 2-bit) on model performance and compares the memory footprint (KV Cache size in GB) of each method. The KVQuant method, which uses a novel approach to quantize key-value cache activations, consistently demonstrates superior performance with minimal perplexity degradation.
read the caption
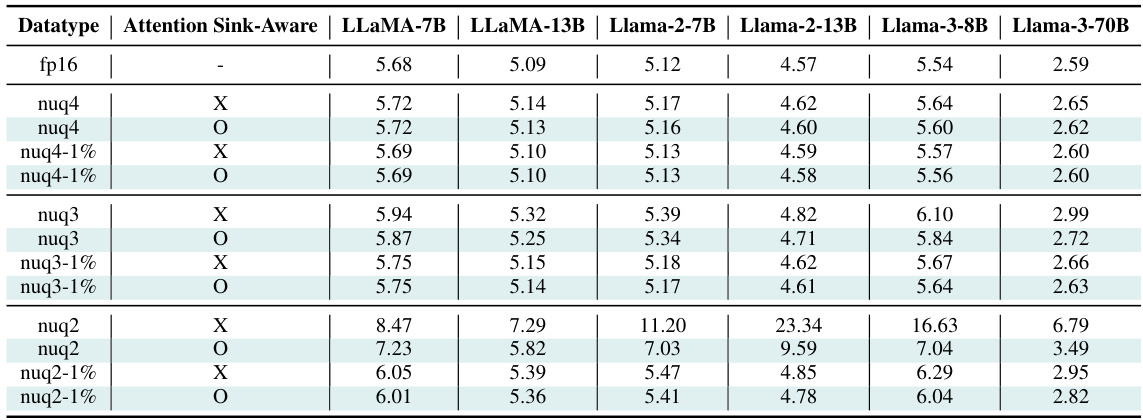
Table 1: Evaluation of our method for different models using the perplexity (PPL) on Wikitext-2. KVQuant results are using pre-RoPE per-channel quantization for Keys. KV cache sizes are estimated assuming a sequence length of 128K (ignoring context length limits for the models). Note that ATOM and FlexGen use 4-bit quantization with group sizes of 128 and 64 with uniform quantization, respectively, and we extend their methods to 3-bit and 2-bit quantization. We leverage Attention Sink-Aware quantization for all bit widths. We used post-RoPE quantization for all baseline methods since it achieves higher accuracy when quantizing Keys per-token as shown in Appendix P. Table 18 in Appendix O demonstrates a full evaluation on all LLaMA, Llama-2, Llama-3, and Mistral models.
In-depth insights#
KV Cache Quantization#
The core of this research paper revolves around efficiently handling the memory bottleneck imposed by large language models (LLMs) during inference. This bottleneck primarily stems from the KV cache’s significant memory footprint when dealing with long context lengths. The proposed solution, KV cache quantization, tackles this problem by compressing the KV cache activations, thereby substantially reducing memory consumption. The method goes beyond existing quantization techniques by incorporating several innovative strategies: per-channel key quantization, pre-RoPE key quantization, and non-uniform quantization. These approaches, combined with a novel per-vector dense-and-sparse quantization strategy, achieve significant accuracy improvements with 3-bit quantization, outperforming existing methods. The integration of custom CUDA kernels further enhances the computational efficiency, resulting in speedups compared to the baseline fp16 implementation. This combined approach facilitates substantial reductions in memory usage, enabling the inference of extremely long context lengths (up to 10 million tokens) on relatively modest GPU setups.
Per-Channel Quantization#
Per-channel quantization, a technique explored in the context of Key-Value cache compression for LLMs, offers a compelling approach to improve efficiency and accuracy. Instead of applying the same quantization parameters across all tokens within a Key matrix, this method adapts the quantization per channel. This is particularly beneficial because channels within the Key matrix exhibit varied distributions, with some showing a greater presence of outliers than others. By independently quantizing each channel, the method effectively mitigates the distorting effect these outliers have on the overall quantization, leading to improved precision and accuracy. The key insight is recognizing the inherent heterogeneity of the data within the Key matrix, and tailoring the quantization process to better fit each channel’s unique statistical properties. While this granularity adds complexity, experiments demonstrate that this approach outperforms existing techniques when integrated into a larger quantization pipeline, suggesting that per-channel quantization can offer a significant advantage for large language model inference.
Non-uniform Quantization#
Non-uniform quantization is a crucial technique for enhancing the efficiency and accuracy of large language model (LLM) inference, especially when dealing with the inherent non-uniformity of key and value activations in the KV cache. Unlike uniform quantization, which assigns equal intervals to all values, non-uniform quantization dynamically adjusts quantization steps based on the data distribution. This allows for finer granularity in representing frequent values while tolerating some loss in infrequent, extreme values, resulting in better accuracy for a given bit-width. The paper explores the benefits of non-uniform quantization techniques by carefully considering the dynamic range and distribution of KV cache activations. They demonstrate how sensitivity-weighted non-uniform quantization, determined offline using calibration data and techniques like k-means clustering, significantly improves performance compared to both uniform and other non-uniform quantization methods. Offline calibration is key here because it avoids expensive online computations during inference, balancing accuracy and speed. Moreover, by combining non-uniform quantization with per-vector dense-and-sparse quantization, the method further refines accuracy and memory efficiency. The per-vector approach addresses outlier values in specific channels or tokens, leading to more effective quantization ranges. Overall, the exploration of non-uniform quantization in this paper is highly insightful, demonstrating its potential for optimizing LLM inference while maintaining model accuracy.
Long-Context Inference#
Long-context inference in LLMs presents significant challenges due to the quadratic increase in computational and memory costs with sequence length. Existing methods struggle to maintain accuracy at lower bit precisions, leading to substantial performance degradation. This paper tackles this problem through KV cache quantization, focusing on the Key and Value activations which dominate memory consumption during inference. The approach employs a multi-pronged strategy: per-channel Key quantization to better manage channel-wise outlier distributions; Pre-RoPE Key quantization to minimize the impact of rotary positional embeddings on quantization; non-uniform quantization to optimally allocate bits; and per-vector dense-and-sparse quantization to efficiently handle outliers. Custom CUDA kernels further enhance speed. The result is remarkably high-accuracy quantization, enabling inference with vastly increased context windows, showcasing the efficacy of this tailored approach for addressing memory limitations inherent to long-context LLMs. The improved efficiency allows for scaling up context length to millions of tokens.
Future Work#
The authors outline several avenues for future research. Improving the efficiency of online scaling factor and outlier threshold computations is a key priority, potentially leveraging more sophisticated techniques than the k-means approach. Extending the approach to other LLM architectures and tasks beyond those tested is crucial to validate the generalizability of their findings. Addressing limitations in memory allocation during the sparse matrix updates is another important goal; they suggest exploring blocked allocation to mitigate overhead. Lastly, they acknowledge the need for more extensive research into training long-context length LLMs, as this is currently a separate research challenge, to truly optimize the potential of their method.
More visual insights#
More on figures
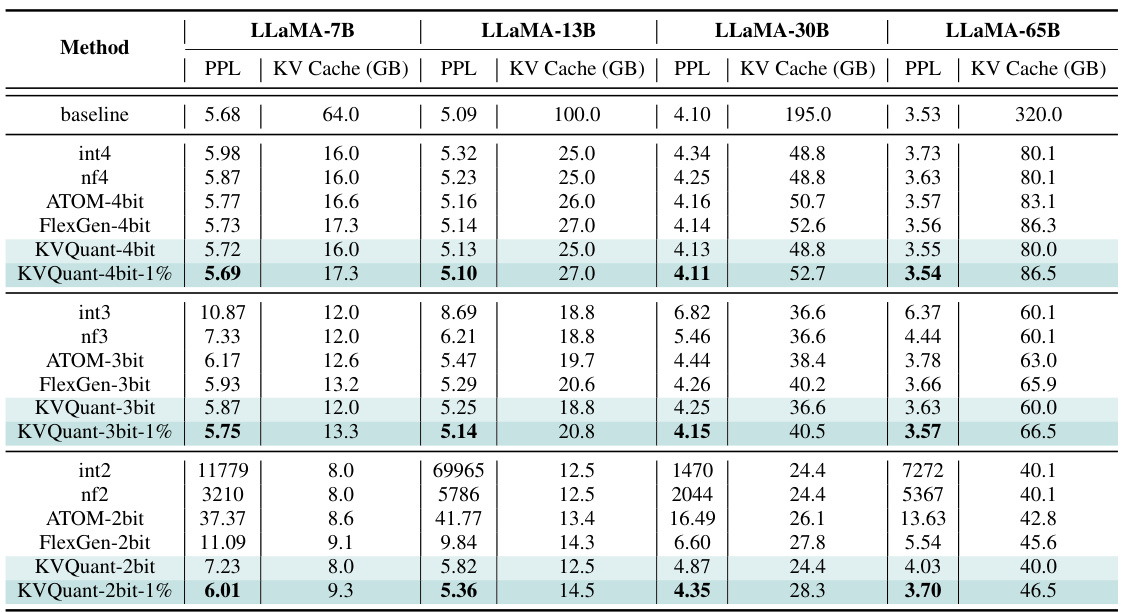
🔼 This figure shows example distributions of activation values for Keys (before and after applying Rotary Positional Embedding (RoPE)), and Values in layer 10 of the LLaMA-7B model using a sample of 2000 tokens from the Wikitext-2 dataset. The key observation is the different outlier patterns in Keys: before RoPE, distinct outliers are present in specific channels; after RoPE, this pattern is less structured. Values, however, show no consistent outlier pattern across channels and tokens. This analysis is crucial to the paper’s approach of quantizing Keys before RoPE to improve accuracy in low-precision quantization.
read the caption
Figure 2: Example distributions of the activation values for Keys pre-RoPE, Keys post-RoPE, and Values for LLaMA-7B on a sample with 2K sequence length from Wikitext-2. We observe several patterns: (i) Keys pre-RoPE exhibit clear outliers in specific channels across different tokens; (ii) after applying RoPE, the distribution becomes less structured and there are less consistent magnitudes for outlier channels (this is expected, as RoPE applies a rotation operation between pairs of channels); and (iii) Values exhibit no fixed outlier pattern with outlier values across channels and tokens.
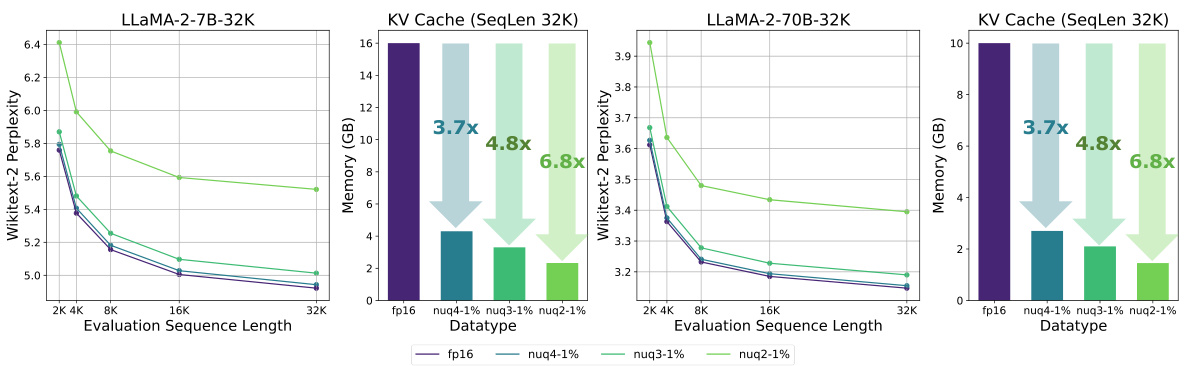
🔼 This figure shows the perplexity results on the Wikitext-2 dataset for two different LLMs, LLaMA-2-7B-32K and Llama-2-70B-32K, using various sequence lengths. The perplexity, a measure of how well the model predicts the next word, is plotted against the evaluation sequence length. Different quantization methods (fp16, nuq4-1%, nuq3-1%, nuq2-1%) are compared, demonstrating the impact of quantization on model performance with increasing context length. The right-hand side plots show the memory usage (in GB) of the KV cache for each quantization method.
read the caption
Figure 3: Perplexity results for the LLaMA-2-7B-32K model [5] as well as the Llama-2-70B-32K LongLoRA model [6] on the Wikitext-2 dataset, evaluated using different sequence lengths.
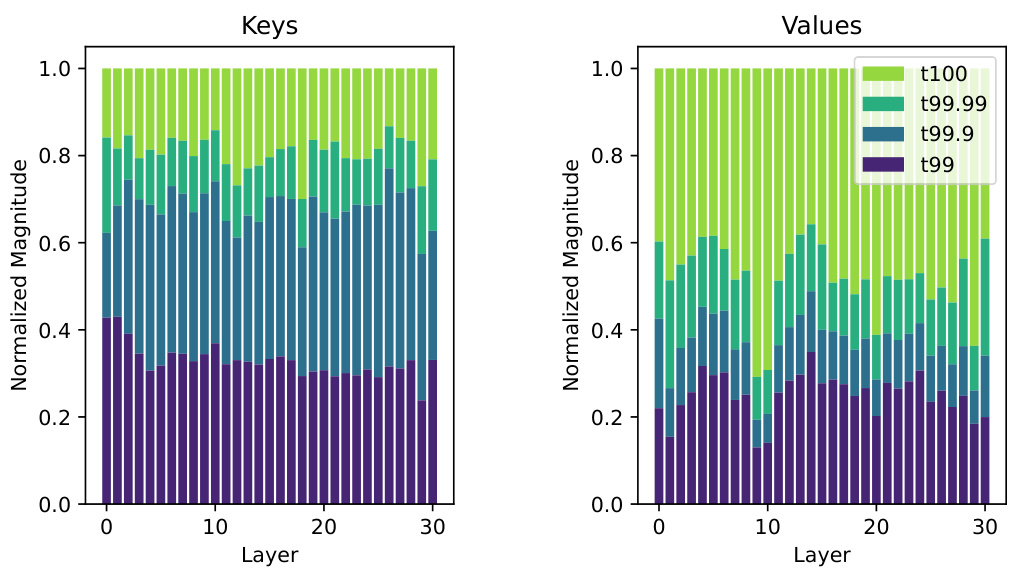
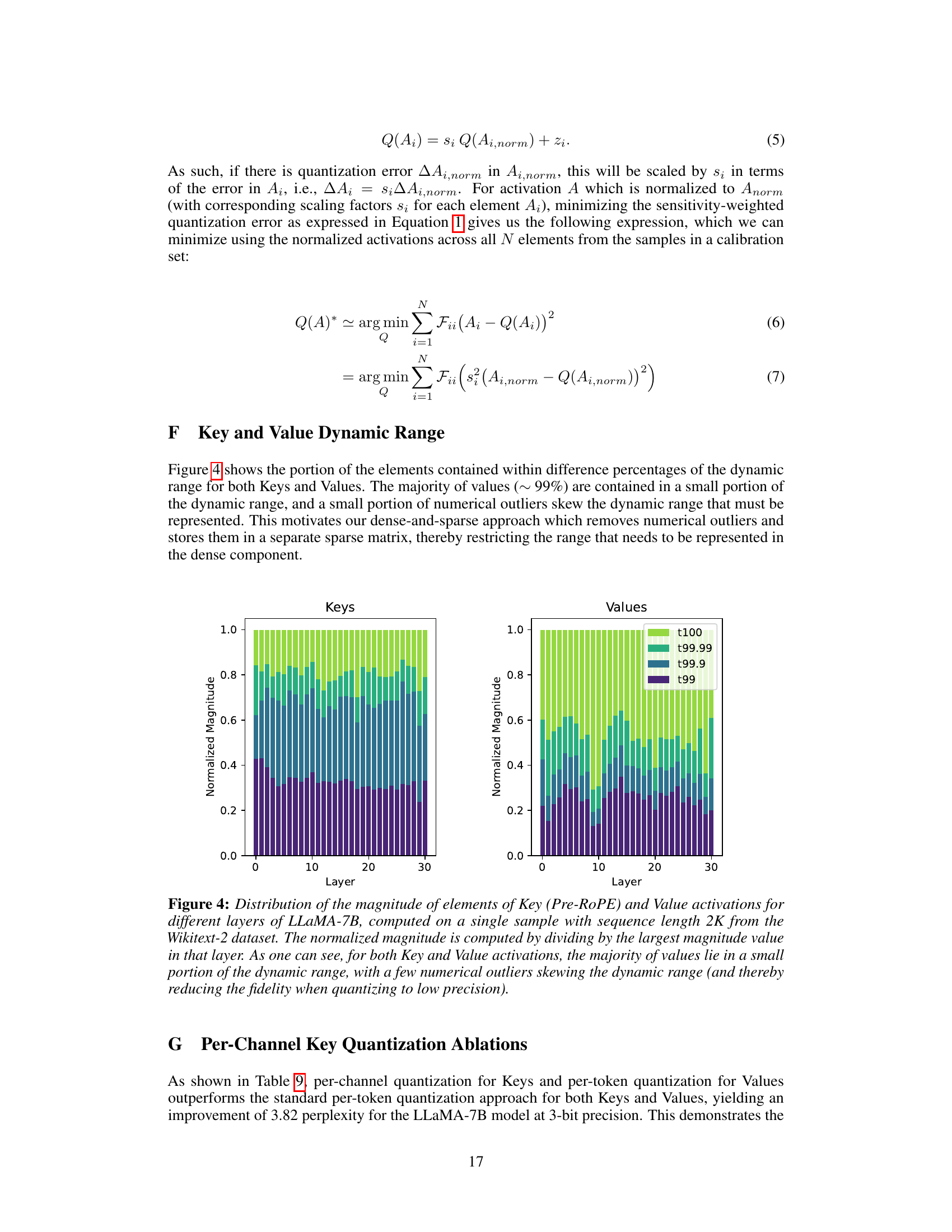
🔼 This figure shows the distribution of the magnitude of elements for both Keys (before Rotary Positional Embedding) and Values in different layers of the LLaMA-7B model. The data is from a single sample with a sequence length of 2K from the Wikitext-2 dataset. The y-axis represents the normalized magnitude, calculated by dividing each element’s magnitude by the maximum magnitude in its layer. The x-axis indicates the layer number. The figure highlights that for both Keys and Values, most elements are concentrated in a small portion of the dynamic range. A few outlier elements significantly skew the range, making it challenging to quantize the data to low precision accurately. The different colors represent different percentage thresholds (e.g., t99 shows the portion of elements within the top 1% of magnitudes).
read the caption
Figure 4: Distribution of the magnitude of elements of Key (Pre-RoPE) and Value activations for different layers of LLaMA-7B, computed on a single sample with sequence length 2K from the Wikitext-2 dataset. The normalized magnitude is computed by dividing by the largest magnitude value in that layer. As one can see, for both Key and Value activations, the majority of values lie in a small portion of the dynamic range, with a few numerical outliers skewing the dynamic range (and thereby reducing the fidelity when quantizing to low precision).
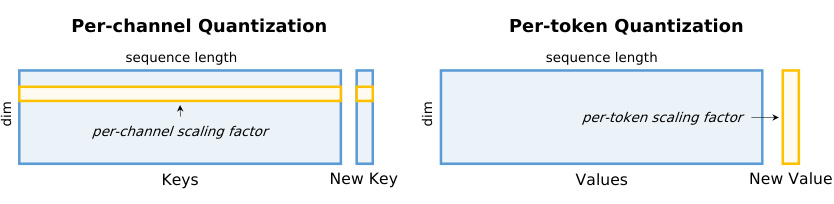
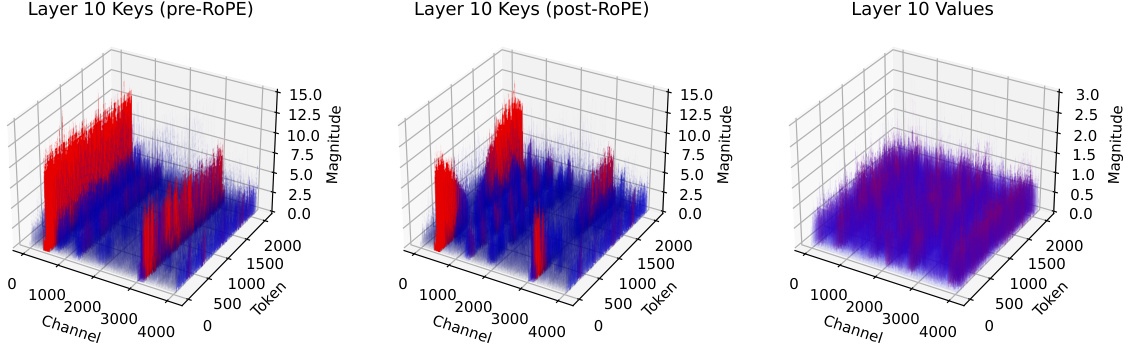
🔼 This figure illustrates the challenges of online vs. offline computation for scaling factors in per-channel and per-token quantization. Per-channel requires recomputing factors for each new key, while per-token only needs computation for the new token. The authors choose offline calibration for per-channel to avoid this online overhead, and they use online calibration for per-token.
read the caption
Figure 5: One typically achieves better performance when the scaling factor/zero point are computed online. However, this is quite challenging to do for per-channel quantization, as these factors will not only need to be recomputed for every new Key appended to the Key cache, but also all the prior cached Keys will need to be updated. As such, we use a calibration set to compute per-channel scaling factors offline. A similar challenge exists for per-token quantization, but online calibration for this does not require updating prior cached Values. In Section 3.6 and Appendix L, we discuss how we are able to efficiently compute outlier thresholds / scaling factors for per-token calibration, thereby enabling online computation.
More on tables
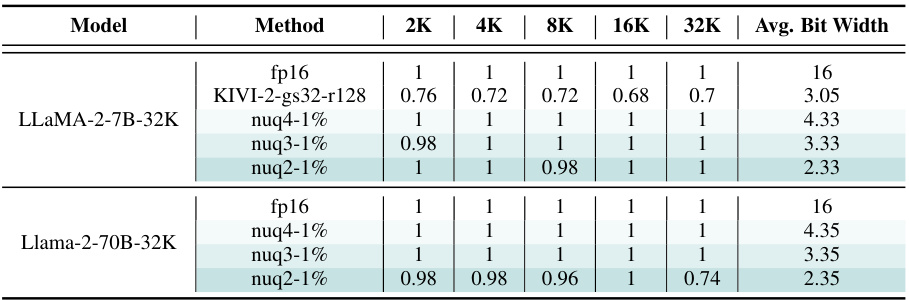
🔼 This table presents the passkey retrieval success rates for different LLMs (LLaMA-2-7B-32K and Llama-2-70B-32K) across various context lengths (2K, 4K, 8K, 16K, 32K). It compares the performance of the proposed KVQuant method (at different bit precisions: 4-bit, 3-bit, and 2-bit) against a baseline (fp16) and KIVI (a competing method). The average bit-width for each method is also provided, calculated assuming a context length of 32K.
read the caption
Table 2: Passkey retrieval results across different context lengths for the LLaMA-2-7B-32K model (uptrained for long sequence lengths using positional interpolation [5]) as well as the Llama-2-70B-32K LongLoRA model [6]. The values reported are the success rate for retrieving the passkey, computed over 50 samples. We also include comparisons with KIVI for reference, using the 2-bit configuration with group size of 32 and 128-element fp16 residual [26]. Average bit widths are estimated for each approach assuming 32K context length. Note that the open-source code for running KIVI with LLaMA does not support grouped-query attention, so we did not include comparisons with KIVI for Llama-2-70B-32K.

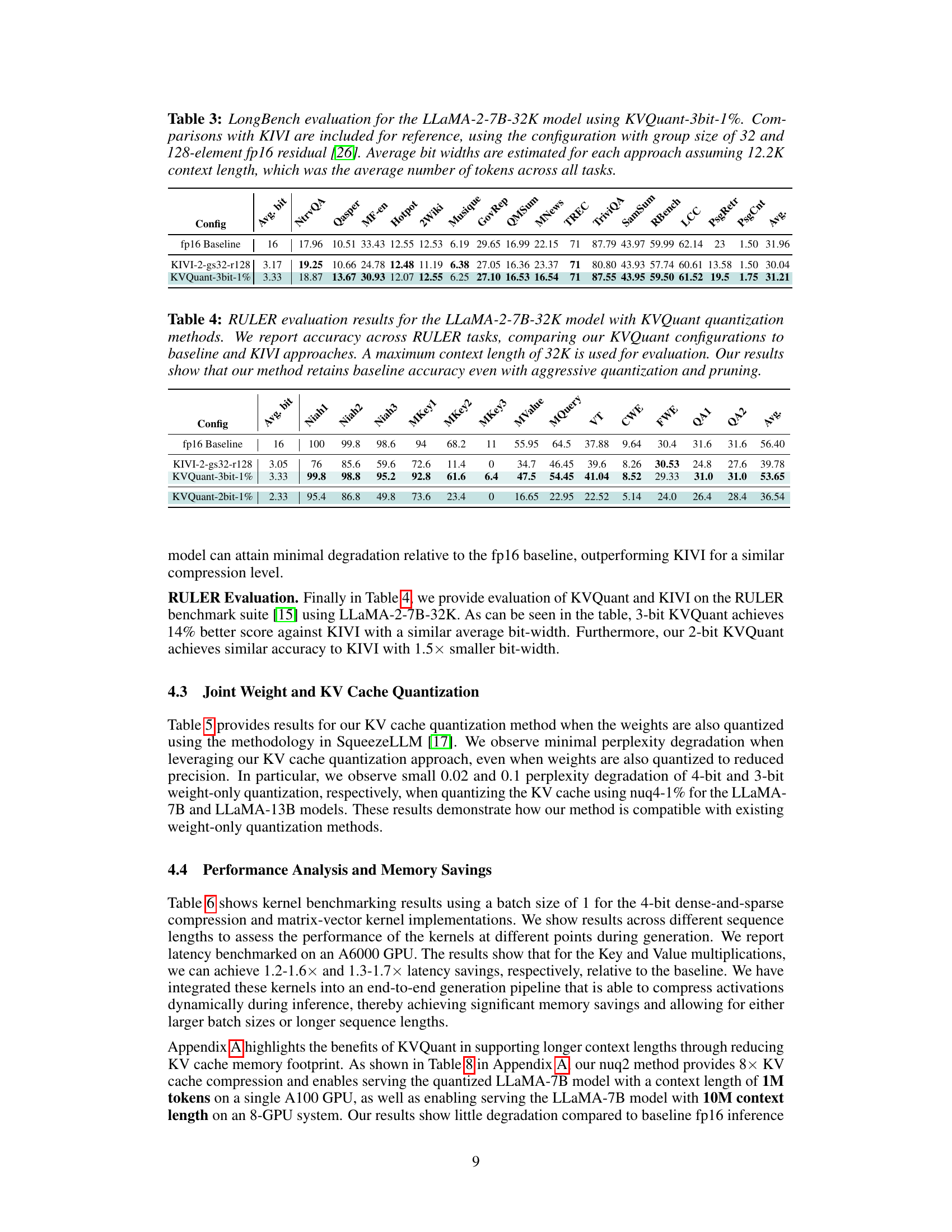
🔼 This table presents the results of the LongBench evaluation, comparing the performance of the KVQuant-3bit-1% method against the baseline fp16 and the KIVI method. LongBench is a benchmark suite for evaluating the capabilities of LLMs in handling long contexts. The table shows the results across various tasks, including question answering, summarization, and few-shot learning, demonstrating the effectiveness of the KVQuant method for various long-context tasks. Average bit-widths, calculated for each method, allow comparison of performance at similar compression levels.
read the caption
Table 3: LongBench evaluations for the Llama-2-7B-32K model using KVQuant-3bit-1%. Comparisons with KIVI are included for reference, using the configuration with group size of 32 and 128-element fp16 residual [26]. Average bit widths are estimated for each approach assuming 12.2K context length, which was the average number of tokens across all tasks.

🔼 This table presents the results of evaluating the KVQuant model on the RULER benchmark. It compares the performance of KVQuant with different quantization levels (3-bit and 2-bit) against a baseline (fp16) and another method (KIVI). The results show KVQuant’s accuracy is maintained even with aggressive quantization and pruning, outperforming KIVI in some cases.
read the caption
Table 4: RULER evaluation results for the LLaMA-2-7B-32K model with KVQuant quantization methods. We report accuracy across RULER tasks, comparing our KVQuant configurations to baseline and KIVI approaches. A maximum context length of 32K is used for evaluation. Our results show that our method retains baseline accuracy even with aggressive quantization and pruning.
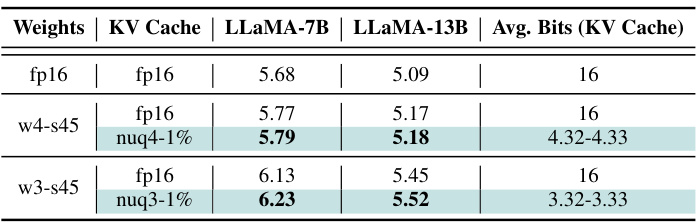
🔼 This table presents the results of applying KV cache quantization in conjunction with weight quantization using the SqueezeLLM methodology. It shows the perplexity scores for LLaMA-7B and LLaMA-13B models under different quantization schemes for both weights and KV caches. The ‘w4-s45’ and ‘w3-s45’ rows represent the 4-bit and 3-bit dense-and-sparse weight quantization methods from the SqueezeLLM paper, respectively. The table highlights the minimal impact on perplexity when combining KVQuant with weight quantization, suggesting compatibility between the two techniques.
read the caption
Table 5: KV cache quantization results when KVQuant is applied in conjunction with the weight quantization methodology in SqueezeLLM [17]. w4-s45 and w3-s45 for weights refer to the 4-bit and 3-bit dense-and-sparse weight quantization approaches in [17], respectively. See Appendix M for experimental details.
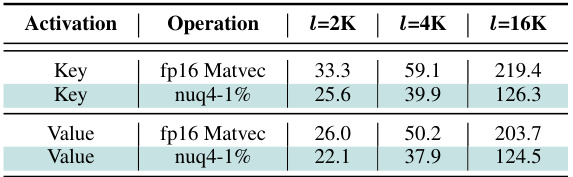
🔼 This table presents a performance comparison of custom CUDA kernels developed for KVQuant against baseline fp16 matrix-vector multiplications. It shows latency results for both Key and Value matrix-vector multiplications at different sequence lengths (2K, 4K, and 16K) for the LLaMA-2-7B-32K model on an A6000 GPU. The results highlight the speedups achieved by the custom kernels, demonstrating improved efficiency with the KVQuant quantization method.
read the caption
Table 6: Average latency (in microseconds) for the Key and Value nuq4-1% kernels, benchmarked on an A6000 GPU for the LLaMA-2-7B-32K model across different sequence lengths (l). fp16 matrix-vector multiplication latencies are included for reference, and the fp16 Key multiplication time also includes the time to apply RoPE to the newly appended Key vector. Section 3.7 and Appendix R provide additional details for our kernel implementation, Appendix R describes our benchmarking methodology, and Table 22 provides a detailed breakdown of kernel runtime on an A6000 GPU.
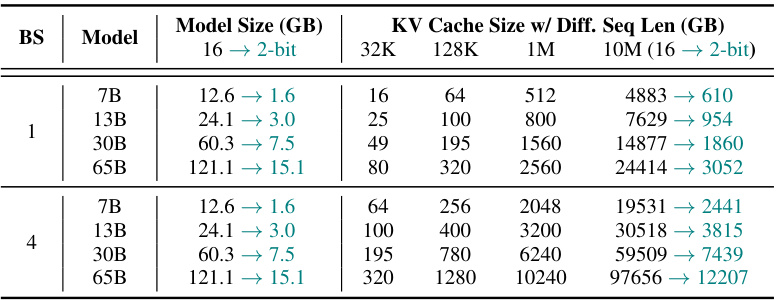
🔼 This table shows the memory usage breakdown for different LLAMA models with varying sequence lengths and batch sizes. It highlights how the KV cache memory consumption becomes the dominant factor for longer sequences, even when model weights are already quantized. The table demonstrates the impact of KVQuant in significantly reducing the memory footprint, enabling longer context lengths with the same hardware.
read the caption
Table 7: Model size and activation memory size estimates for different sequence lengths and batch sizes (BS) for different LLAMA models. For long sequence lengths and larger batch sizes, activation memory is the main bottleneck (particularly when weights are already quantized to low precision). By compressing the KV cache to 2-bit precision, we can enable 1M context length inference with the LLaMA-7B model on a single A100-80GB GPU, and we can also enable 10M context length inference with the LLaMA-7B model on an 8-GPU system.

🔼 This table shows the estimated KV cache memory size in gigabytes (GB) for different sequence lengths (128K, 1M, and 10M tokens) and different quantization methods (fp16, nuq4, nuq4-1%, nuq3, nuq3-1%, nuq2, nuq2-1%). It demonstrates the significant memory savings achieved by the proposed KVQuant method, especially at lower bit precisions (2-bit). The table highlights the feasibility of serving large language models with extremely long context lengths by drastically reducing the memory footprint of the KV cache. The results support the claim that the method enables 1M context length inference on a single A100-80GB GPU and 10M context length inference on an 8-GPU system.
read the caption
Table 8: Activation memory size estimates (GB) for 128K, 1M, and 10M sequence length (l) for different LLaMA models. By compressing the KV cache to 2-bit precision, we can enable 1M context length inference with the LLaMA-7B model on a single A100-80GB GPU, and we can also enable 10M context length inference with the LLaMA-7B model on an 8-GPU system.
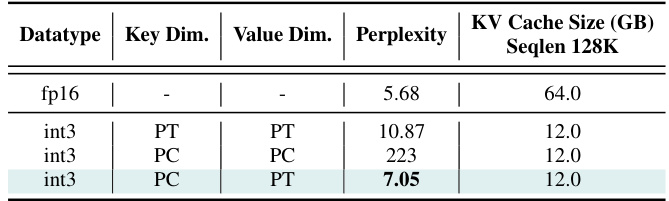
🔼 This table presents an ablation study comparing different quantization methods for Key and Value vectors in the KV cache of the LLaMA-7B model. It shows the impact of using per-token (PT) versus per-channel (PC) quantization on both Key and Value dimensions, evaluating their perplexity and the resulting KV cache size. The results highlight the significant performance differences between these approaches for the same 3-bit quantization.
read the caption
Table 9: Ablation Study: Perplexity comparison of per-token and per-channel quantization for KV cache activations for LLaMA-7B. PT refers to per-token quantization, and PC refers to per-channel quantization.
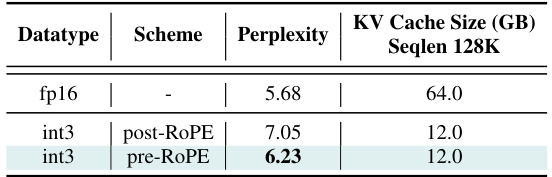
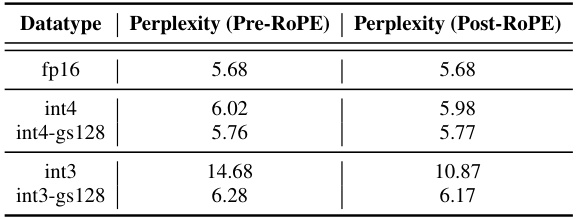
🔼 This table presents the ablation study comparing the perplexity and KV cache size (GB) with sequence length 128k for different quantization schemes: fp16 (baseline), int3 with post-ROPE and int3 with pre-ROPE. The pre-ROPE method shows significant improvement in perplexity compared to the post-ROPE method, demonstrating that quantizing keys before applying rotary positional embedding leads to better results.
read the caption
Table 10: Ablation Study: Perplexity comparison of Pre-RoPE and post-ROPE Key quantization for LLaMA-7B (using per-channel Key quantization and per-token Value quantization). Pre-RoPE quantization leads to significant improvement (see Section 3.2 for more details).

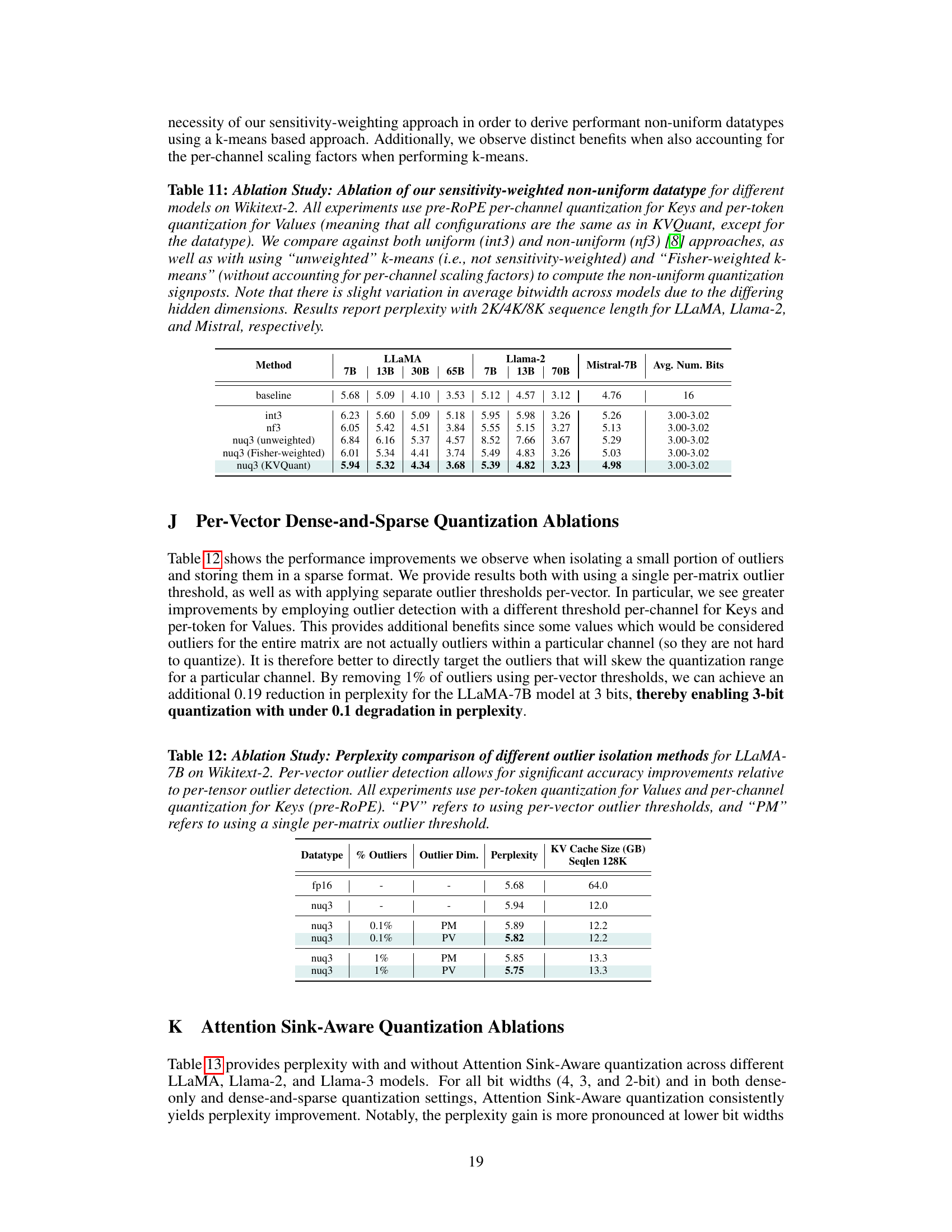
🔼 This table presents an ablation study on the sensitivity-weighted non-uniform quantization datatype used in KVQuant. It compares the perplexity results on Wikitext-2 for various models and quantization schemes. The schemes include uniform quantization (int3), non-uniform quantization (nf3), nuq3 (unweighted k-means), nuq3 (Fisher-weighted k-means), and nuq3 (KVQuant). This table helps to understand the individual contribution of each component of the proposed non-uniform quantization method to the overall performance improvement. The comparison is done across different models (LLAMA, Llama-2, and Mistral), bit-widths, and sequence lengths.
read the caption
Table 11: Ablation Study: Ablation of our sensitivity-weighted non-uniform datatype for different models on Wikitext-2. All experiments use pre-RoPE per-channel quantization for Keys and per-token quantization for Values (meaning that all configurations are the same as in KVQuant, except for the datatype). We compare against both uniform (int3) and non-uniform (nf3) [8] approaches, as well as with using “unweighted” k-means (i.e., not sensitivity-weighted) and “Fisher-weighted k-means
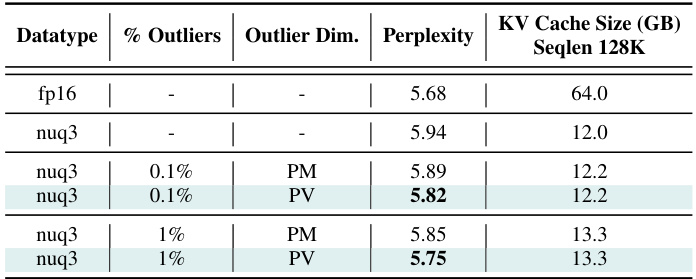
🔼 This table presents ablation study results on the impact of different outlier isolation methods on the perplexity of the LLaMA-7B model using Wikitext-2 dataset. It compares the performance of using a single global threshold for outlier removal (PM) versus using separate thresholds for each vector (PV). The results show that per-vector outlier detection (PV) significantly improves the model’s accuracy, particularly at lower bit-widths (3-bit in this case).
read the caption
Table 12: Ablation Study: Perplexity comparison of different outlier isolation methods for LLaMA-7B on Wikitext-2. Per-vector outlier detection allows for significant accuracy improvements relative to per-tensor outlier detection. All experiments use per-token quantization for Values and per-channel quantization for Keys (pre-RoPE). “PV” refers to using per-vector outlier thresholds, and “PM” refers to using a single per-matrix outlier threshold.
🔼 This table presents a comparison of the perplexity scores achieved by different quantization methods (including the proposed KVQuant) on the Wikitext-2 dataset using various LLaMA-based language models. It shows the impact of different bit precisions (4-bit, 3-bit, 2-bit) and techniques on model performance while taking into account the size of the KV cache. Baseline results using fp16 precision are included for comparison. The table helps to demonstrate the effectiveness of the KVQuant method in achieving low perplexity while reducing memory usage.
read the caption
Table 1: Evaluation of our method for different models using the perplexity (PPL) on Wikitext-2. KVQuant results are using pre-RoPE per-channel quantization for Keys. KV cache sizes are estimated assuming a sequence length of 128K (ignoring context length limits for the models). Note that ATOM and FlexGen use 4-bit quantization with group sizes of 128 and 64 with uniform quantization, respectively, and we extend their methods to 3-bit and 2-bit quantization. We leverage Attention Sink-Aware quantization for all bit widths. We used post-RoPE quantization for all baseline methods since it achieves higher accuracy when quantizing Keys per-token as shown in Appendix P. Table 18 in Appendix O demonstrates a full evaluation on all LLaMA, Llama-2, Llama-3, and Mistral models.
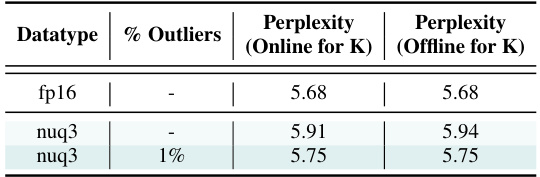
🔼 This table presents an ablation study comparing the model accuracy when using online versus offline calibration methods for the Keys in the LLaMA-7B model. The study investigates the impact of using different quantization methods (per-token and per-channel) and outlier detection techniques (per-vector and per-matrix) on the model’s perplexity. The results show that offline calibration performs comparably to online calibration when outlier detection is incorporated.
read the caption
Table 14: Ablation Study: Model accuracy when using offline calibration for Keys with LLaMA-7B. When incorporating outlier detection, offline calibration for Keys is able to perform comparably with online calibration. All nuq3 experiments use per-token quantization for Values and per-channel quantization for Keys (pre-RoPE), and experiments with outliers use per-vector outlier detection.
🔼 This table compares the perplexity (a measure of how well a model predicts a text) of different quantization methods (including the proposed KVQuant method) on the Wikitext-2 dataset for several large language models. It shows how the perplexity changes with different bit precisions (4-bit, 3-bit, 2-bit) of the KV cache. The table also accounts for the size of the KV cache memory used by each method, demonstrating the trade-off between accuracy and memory efficiency.
read the caption
Table 1: Evaluation of our method for different models using the perplexity (PPL) on Wikitext-2. KVQuant results are using pre-RoPE per-channel quantization for Keys. KV cache sizes are estimated assuming a sequence length of 128K (ignoring context length limits for the models). Note that ATOM and FlexGen use 4-bit quantization with group sizes of 128 and 64 with uniform quantization, respectively, and we extend their methods to 3-bit and 2-bit quantization. We leverage Attention Sink-Aware quantization for all bit widths. We used post-RoPE quantization for all baseline methods since it achieves higher accuracy when quantizing Keys per-token as shown in Appendix P. Table 18 in Appendix O demonstrates a full evaluation on all LLaMA, Llama-2, Llama-3, and Mistral models.

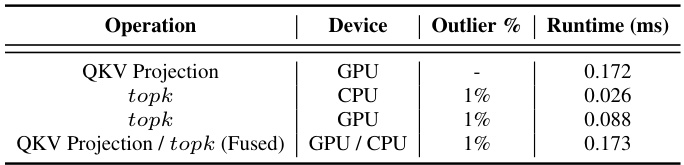
🔼 This table presents the runtime for computing Fisher information and performing calibration (including k-means) for a single layer of the LLaMA-65B model at different bit precisions (4-bit, 3-bit, and 2-bit). The computation of Fisher information was done on an 8-GPU A100-80GB system, while the calibration was performed on an Intel Xeon Gold 6442Y CPU. The table highlights that the calibration process can be easily parallelized across layers.
read the caption
Table 16: Runtime for computing Fisher information as well as for calibration (including k-means) with 16 samples for LLaMA-65B quantization. Runtime for computing Fisher information was computed on an 8-GPU A100-80GB system. Runtime for calibration (including k-means) was performed on an Intel Xeon Gold 6442Y CPU, and is shown for a single layer. Note that calibration is independent for each layer, so it can be easily parallelized.
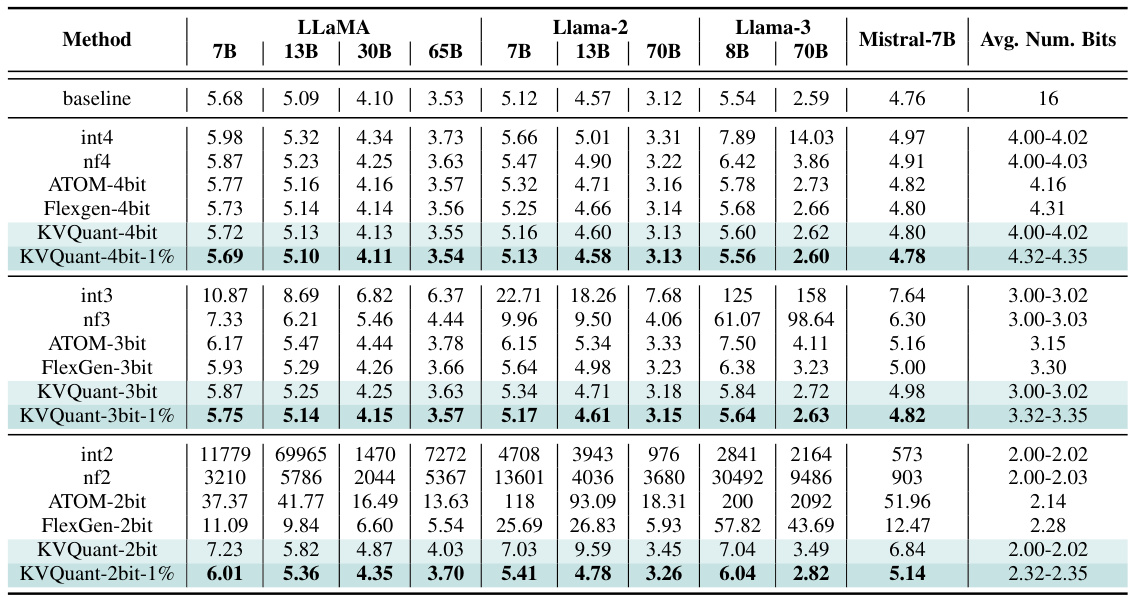
🔼 This table presents a comparison of the proposed KVQuant method against various baseline and state-of-the-art quantization techniques on the Wikitext-2 dataset. The comparison is performed across multiple LLMs (LLaMA, Llama-2, Llama-3, and Mistral) and various bit precisions (4-bit, 3-bit, 2-bit). The table shows perplexity scores and estimated KV cache sizes for each model and method, demonstrating the performance and memory efficiency gains of KVQuant.
read the caption
Table 1: Evaluation of our method for different models using the perplexity (PPL) on Wikitext-2. KVQuant results are using pre-RoPE per-channel quantization for Keys. KV cache sizes are estimated assuming a sequence length of 128K (ignoring context length limits for the models). Note that ATOM and FlexGen use 4-bit quantization with group sizes of 128 and 64 with uniform quantization, respectively, and we extend their methods to 3-bit and 2-bit quantization. We leverage Attention Sink-Aware quantization for all bit widths. We used post-RoPE quantization for all baseline methods since it achieves higher accuracy when quantizing Keys per-token as shown in Appendix P. Table 18 in Appendix O demonstrates a full evaluation on all LLaMA, Llama-2, Llama-3, and Mistral models.
🔼 This table presents the perplexity scores on the Wikitext-2 dataset for various LLMs (LLaMA, Llama-2, Llama-3, and Mistral) using different quantization methods, including the proposed KVQuant method and existing approaches like ATOM and FlexGen. It compares different bit-widths (4-bit, 3-bit, and 2-bit) and shows the impact of various quantization techniques on model performance and memory usage. The table highlights the superior performance of KVQuant in maintaining low perplexity scores with substantial memory savings compared to baseline fp16 and other methods.
read the caption
Table 1: Evaluation of our method for different models using the perplexity (PPL) on Wikitext-2. KVQuant results are using pre-RoPE per-channel quantization for Keys. KV cache sizes are estimated assuming a sequence length of 128K (ignoring context length limits for the models). Note that ATOM and FlexGen use 4-bit quantization with group sizes of 128 and 64 with uniform quantization, respectively, and we extend their methods to 3-bit and 2-bit quantization. We leverage Attention Sink-Aware quantization for all bit widths. We used post-RoPE quantization for all baseline methods since it achieves higher accuracy when quantizing Keys per-token as shown in Appendix P. Table 18 in Appendix O demonstrates a full evaluation on all LLaMA, Llama-2, Llama-3, and Mistral models.

🔼 This table presents a comparison of the proposed KVQuant method against various baseline and state-of-the-art quantization techniques (intX, nfX, ATOM, FlexGen) for different LLMs (LLaMA-7B, LLaMA-13B, LLaMA-30B, LLaMA-65B). The evaluation is performed on the Wikitext-2 dataset using perplexity (PPL) as the metric. The table shows perplexity results for 4-bit, 3-bit, and 2-bit quantization methods. It highlights the achieved perplexity with and without 1% outlier removal and the estimated size of the KV cache in gigabytes (GB). The context length is fixed at 128k tokens for all models. Pre-RoPE quantization is used for Keys in KVQuant, with post-RoPE used for the baseline. Attention Sink-Aware Quantization is used across all methods and bit widths. The table indicates significant improvements for KVQuant particularly at lower bit precisions.
read the caption
Table 1: Evaluation of our method for different models using the perplexity (PPL) on Wikitext-2. KVQuant results are using pre-RoPE per-channel quantization for Keys. KV cache sizes are estimated assuming a sequence length of 128K (ignoring context length limits for the models). Note that ATOM and FlexGen use 4-bit quantization with group sizes of 128 and 64 with uniform quantization, respectively, and we extend their methods to 3-bit and 2-bit quantization. We leverage Attention Sink-Aware quantization for all bit widths. We used post-RoPE quantization for all baseline methods since it achieves higher accuracy when quantizing Keys per-token as shown in Appendix P. Table 18 in Appendix O demonstrates a full evaluation on all LLaMA, Llama-2, Llama-3, and Mistral models.
🔼 This table compares the perplexity results of using pre-RoPE and post-RoPE quantization for Key with per-token quantization for LLaMA-7B model at different bit-widths (4-bit and 3-bit). The results show that when using per-token quantization, post-RoPE quantization gives better results than pre-RoPE quantization. This is attributed to the fact that when rotating an outlier channel with another channel using RoPE, at some positions in the sequence, the impact of the outlier channel on the quantization range is reduced due to the magnitude from outlier channel being partially shifted to the smaller channel. Therefore, post-RoPE per-token Key quantization is chosen as a stronger baseline for comparison.
read the caption
Table 20: Model accuracy when using pre-RoPE and post-RoPE quantization for LLaMA-7B with per-token Key quantization. Our experiments demonstrate that post-RoPE quantization is superior when using per-token Key quantization. Therefore, we decided to use these results for baseline comparison with per-token quantization.

🔼 This table presents the perplexity scores achieved by different quantization methods (4-bit, 3-bit, and 2-bit with 1% sparsity) on two datasets: Wikitext-2 and C4. It demonstrates the robustness of the calibration process by showing that models calibrated on one dataset (Wikitext-2) perform similarly well when evaluated on the other dataset (C4), and vice-versa. This highlights the generalizability of the calibration and quantization methods.
read the caption
Table 21: Perplexity (PPL) results on Wikitext-2 and C4 using different quantization schemes, calibrated using Wikitext-2 and C4.
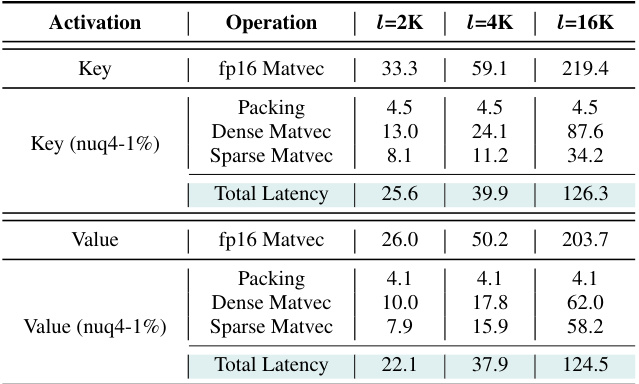
🔼 This table presents the benchmark results of custom CUDA kernels implemented for 4-bit dense-and-sparse quantization. It compares the latency of Key and Value matrix-vector multiplications using the proposed method (nuq4-1%) against the baseline fp16 implementations. The results are shown for different sequence lengths (2K, 4K, 16K) on an A6000 GPU. Additional details on kernel implementation and benchmarking methodology are referenced in the table caption.
read the caption
Table 6: Average latency (in microseconds) for the Key and Value nuq4-1% kernels, benchmarked on an A6000 GPU for the LLaMA-2-7B-32K model across different sequence lengths (l). fp16 matrix-vector multiplication latencies are included for reference, and the fp16 Key multiplication time also includes the time to apply RoPE to the newly appended Key vector. Section 3.7 and Appendix R provide additional details for our kernel implementation, Appendix R describes our benchmarking methodology, and Table 22 provides a detailed breakdown of kernel runtime on an A6000 GPU.
Full paper#