TL;DR#
Federated learning faces challenges with data heterogeneity and privacy. Existing personalized models struggle with diverse user data distributions and risk compromising user privacy. This paper focuses on improving personalized frequency histogram estimation, a crucial aspect of tasks like next-word prediction. The task is challenging because users have few samples and different data distributions.
The paper proposes a novel approach using clustering-based algorithms to group users with similar distributions. They develop a differentially private version of this algorithm, addressing privacy concerns while maintaining accuracy. The method is tested on real-world datasets such as Reddit and Stack Overflow. The empirical results showcase significant improvements in accuracy, compared to existing methods, while upholding the desired level of privacy. The study is supported by a mixture-of-Dirichlet data model which helps to explain the performance gains.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning and differential privacy, addressing critical challenges in personalized models. Its novel approach to frequency estimation with provable privacy guarantees opens new avenues for developing more practical and privacy-preserving personalized applications. The mixture-of-Dirichlet model provides a strong theoretical foundation for future work in this area. The empirical results demonstrating improved accuracy and efficiency on real-world datasets are highly relevant to the current research trends.
Visual Insights#
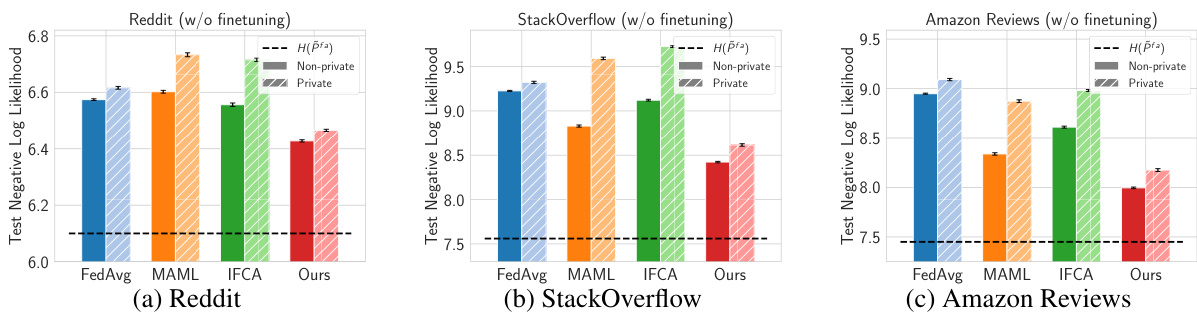
🔼 This figure compares the test negative log-likelihood (NLL) loss before local personalization across four methods: FedAvg, MAML, IFCA, and the authors’ proposed approach. The NLL, a measure of the model’s prediction accuracy, is averaged across all users and multiple runs, showing the performance of each method on three datasets: Reddit, StackOverflow, and Amazon Reviews. Error bars illustrate the 95% confidence intervals.
read the caption
Figure 1: Performance before finetuning: We compare the test NLL loss before local personalization (finetuning) for baselines FedAvg, MAML, IFCA with our approach. NLL is uniformly averaged over users and each value is averaged over 50 random runs (error bars indicate 95% confidence intervals).

🔼 This figure compares the test negative log-likelihood (NLL) loss before local personalization (finetuning) for several algorithms on three different datasets: Reddit, StackOverflow, and Amazon Reviews. The algorithms compared are FedAvg, MAML, IFCA, and the authors’ approach. The NLL is uniformly averaged across users for each dataset and experiment, with error bars representing 95% confidence intervals based on 50 runs.
read the caption
Figure 1: Performance before finetuning: We compare the test NLL loss before local personalization (finetuning) for baselines FedAvg, MAML, IFCA with our approach. NLL is uniformly averaged over users and each value is averaged over 50 random runs (error bars indicate 95% confidence intervals).
In-depth insights#
Federated Learning#
Federated learning (FL) is a privacy-preserving machine learning approach enabling collaborative model training across decentralized data sources without direct data sharing. Its core strength lies in preserving user privacy, a critical aspect often overlooked in traditional centralized learning. The paper delves into the challenges inherent in FL, specifically addressing statistical heterogeneity (variations in data distributions across users) and the need for personalized models. It showcases how these challenges are particularly relevant in applications like next-word prediction on user devices. The authors highlight the significance of subpopulations or user clusters with similar data characteristics, demonstrating that leveraging this latent structure leads to improved model performance compared to methods that assume homogeneous data. Their proposed algorithm cleverly combines clustering techniques with differential privacy mechanisms to address these challenges, offering theoretical guarantees for improved accuracy while maintaining strong user privacy. The empirical results on multiple real-world datasets confirm the efficacy of their method, surpassing standard federated learning baselines.
Privacy Tech#
In the realm of technological advancements, privacy tech stands as a critical area of focus. It encompasses various methods and strategies employed to safeguard sensitive information in the digital age. The core goal is to enable individuals to control their data, balancing utility with security. Differential privacy, a prominent technique in this domain, adds calibrated noise to data during computations, protecting individual-level information while maintaining data utility for aggregation. Federated learning provides another innovative approach, facilitating collaborative model training across decentralized data sources without directly sharing user data. These and other techniques, homomorphic encryption and secure multi-party computation exemplify the spectrum of privacy-enhancing technologies available today, offering various tradeoffs between data utility and privacy protection. The development and implementation of privacy tech are significantly influenced by ethical considerations and legal frameworks, shaping the ongoing evolution of its landscape. Future developments are expected to focus on creating robust and user-friendly privacy-preserving systems that cater to the increasing complexities of the digital world.
KL Divergence#
KL divergence, or Kullback-Leibler divergence, plays a crucial role in this research by serving as the primary metric for measuring the error in personalized frequency estimation. The choice of KL divergence is motivated by its relevance to language modeling, where minimizing KL divergence is equivalent to maximizing the likelihood of the data. The paper demonstrates how algorithms effectively reduce error measured by KL divergence, showing significant improvements over standard baselines. A key aspect is the utilization of KL divergence in the algorithm’s iterative clustering process, where the goal is to group users with similar distribution patterns. The use of KL divergence for comparing distributions within clusters allows the algorithm to identify and exploit similar subpopulations, improving estimation accuracy. However, the impact of the choice of KL divergence as the error metric is not explicitly discussed beyond its theoretical grounding in language modeling and its natural fit for distribution comparison. Further investigation into its suitability relative to other metrics in this specific federated learning context would strengthen the analysis. Ultimately, the focus on KL divergence provides a theoretically sound and practically effective framework for evaluating the effectiveness of personalized frequency estimation in federated settings, though a deeper exploration of its limitations and potential alternatives might be valuable.
Good-Turing#
The Good-Turing method, a crucial element in this research paper, tackles the challenge of frequency estimation, particularly in scenarios with limited data. Its strength lies in accurately estimating the probabilities of unseen events, a common issue when dealing with sparse data like those found in language modeling. This is achieved by leveraging the observed counts of events that appeared a certain number of times to infer probabilities for unseen events. The paper uses Good-Turing in a crucial step where user distributions have to be estimated privately and personalized. It is not simply applied as a standalone technique but as a key component of a broader methodology. The effectiveness of Good-Turing is empirically validated, showing a significant improvement over standard methods, highlighting its ability to effectively handle data sparsity and improve accuracy within a privacy-preserving context. By incorporating Good-Turing, the algorithm gains robustness and accuracy, especially when addressing the challenges of limited data samples and the need to protect individual user privacy.
Reddit Dataset#
The Reddit dataset, likely used for its vast size and diverse user contributions, presents a unique opportunity and challenges for federated learning research. Its scale allows for comprehensive analysis of statistical heterogeneity across users and exploration of personalized models. The inherent characteristics of Reddit data, featuring diverse language styles, topic coverage, and varying levels of user activity, pose a significant test for any algorithm aimed at private and personalized frequency estimation. The use of Reddit data in this context highlights the practical application of the proposed method. However, concerns around data privacy and potential biases present within Reddit’s user base must be carefully considered. The research must address the ethical implications of utilizing Reddit data, including ensuring compliance with privacy regulations and mitigating biases to prevent unfair or discriminatory outcomes. The success of the proposed approach on Reddit data strengthens the argument for its efficacy in real-world, high-volume, and diverse text applications. Future work could investigate how the model performs with other large-scale social media datasets. A comparison across various platforms would provide a deeper understanding of model generalizability and robustness.
More visual insights#
More on figures

🔼 This figure compares the test negative log-likelihood (NLL) loss after local finetuning for several baselines and the proposed algorithm in both size-homogeneous and size-heterogeneous settings. The baselines include FedAvg+FT, MAML+FT, and IFCA+FT, while the proposed algorithm is Alg. 3+FT. The finetuning step is implemented using Equation 3 from the paper. Results are averaged across users and multiple runs, with error bars representing 95% confidence intervals.
read the caption
Figure 2: Performance after finetuning: In the size-homogeneous (a-c), and size-heterogeneous (d-f) settings, we compare the test NLL loss for baselines FedAvg+FT, MAML+FT, IFCA+FT with our Alg. 3+FT, where FT is implemented by Eq. 3. Uniformly averaged over users, each value is averaged over 50 random runs (error bars indicate 95% confidence intervals).
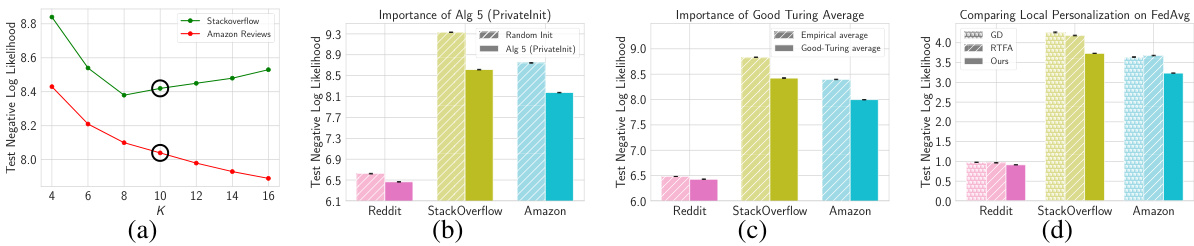
🔼 This figure analyzes the impact of different algorithmic choices on the performance of the proposed personalized frequency estimation algorithm. It shows the test negative log-likelihood (NLL) for four scenarios: varying the number of clusters (K), using the proposed PrivateInit vs. random initialization for cluster centers, comparing the use of Good-Turing vs. empirical averages for cluster center estimation, and comparing different local finetuning methods applied to the FedAvg model. Each subfigure helps assess the importance of a specific design choice, offering insights into the algorithm’s effectiveness and efficiency.
read the caption
Figure 3: Algorithmic design choices: We evaluate test NLL for Alg. 3 as we: (a) vary the number of clusters K; (b) use PrivateInit or randomly initialize cluster centers; and (c) use average of Good-Turing or empirical average to estimate cluster centers. In (d) we evaluate different finetuning methods applied to the FedAvg model.

🔼 This figure compares the test negative log-likelihood (NLL) loss for several baselines (FedAvg+FT, MAML+FT, IFCA+FT) and the proposed algorithm (Alg. 3+FT) after a local finetuning step (FT). The comparison is done in both size-homogeneous and size-heterogeneous settings across three datasets: Reddit, StackOverflow, and Amazon Reviews. The results show the improvements achieved by the proposed method over the baselines in reducing the error, with error bars representing 95% confidence intervals.
read the caption
Figure 2: Performance after finetuning: In the size-homogeneous (a-c), and size-heterogenenous (d-f) settings, we compare the test NLL loss for baselines FedAvg+FT, MAML+FT, IFCA+FT with our Alg. 3+FT, where FT is implemented by Eq. 3. Uniformly averaged over users, each value is averaged over 50 random runs (error bars indicate 95% confidence intervals).

🔼 This figure shows the result of validating the hyperparameter K (number of clusters) for the proposed algorithm. The x-axis represents different values of K, and the y-axis represents the test negative log-likelihood. The plot shows that the test negative log-likelihood is minimized when K is around 10 for the Reddit dataset. This suggests that a value of K=10 is a good choice for the algorithm, and this value was used for the other two datasets as well.
read the caption
Figure 5: Validating hyperparameter choice of K = 10 on Reddit dataset. We use the same value of K for the other two datasets as well.
Full paper#



















