↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multi-instance point cloud registration is a challenging computer vision problem, crucial for applications such as robotic bin picking and autonomous driving. Existing methods struggle with accuracy in cluttered scenes due to difficulties in establishing accurate global correspondences between the model and scene point clouds. These methods typically rely on a two-stage approach: global correspondence finding and then clustering to locate individual instances.
This paper introduces 3DFMNet, a novel two-stage network that addresses these issues. The first stage employs a 3D multi-object focusing module to locate object centers and generate proposals. The second stage uses a 3D dual-masking instance matching module to estimate the pose between the model and each proposal. This approach drastically improves accuracy by simplifying the problem, and extensive experiments demonstrate state-of-the-art performance on the Scan2CAD and ROBI benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to multi-instance point cloud registration, a crucial task in various fields like robotics and autonomous driving. Its simple yet powerful 3D focusing-and-matching network achieves state-of-the-art results, opening avenues for improving robotic operations and autonomous navigation. The decomposition approach of transforming multi-instance registration into multiple pair-wise registrations provides valuable insights for related tasks like multi-target tracking and map construction.
Visual Insights#

The figure compares existing multi-instance point cloud registration methods with the proposed method. Existing methods directly find correspondences between the model point cloud and the scene point cloud, which is challenging in cluttered scenes. The proposed method first localizes the object centers, generates object proposals, and then performs multiple pair-wise point cloud registrations for improved accuracy.
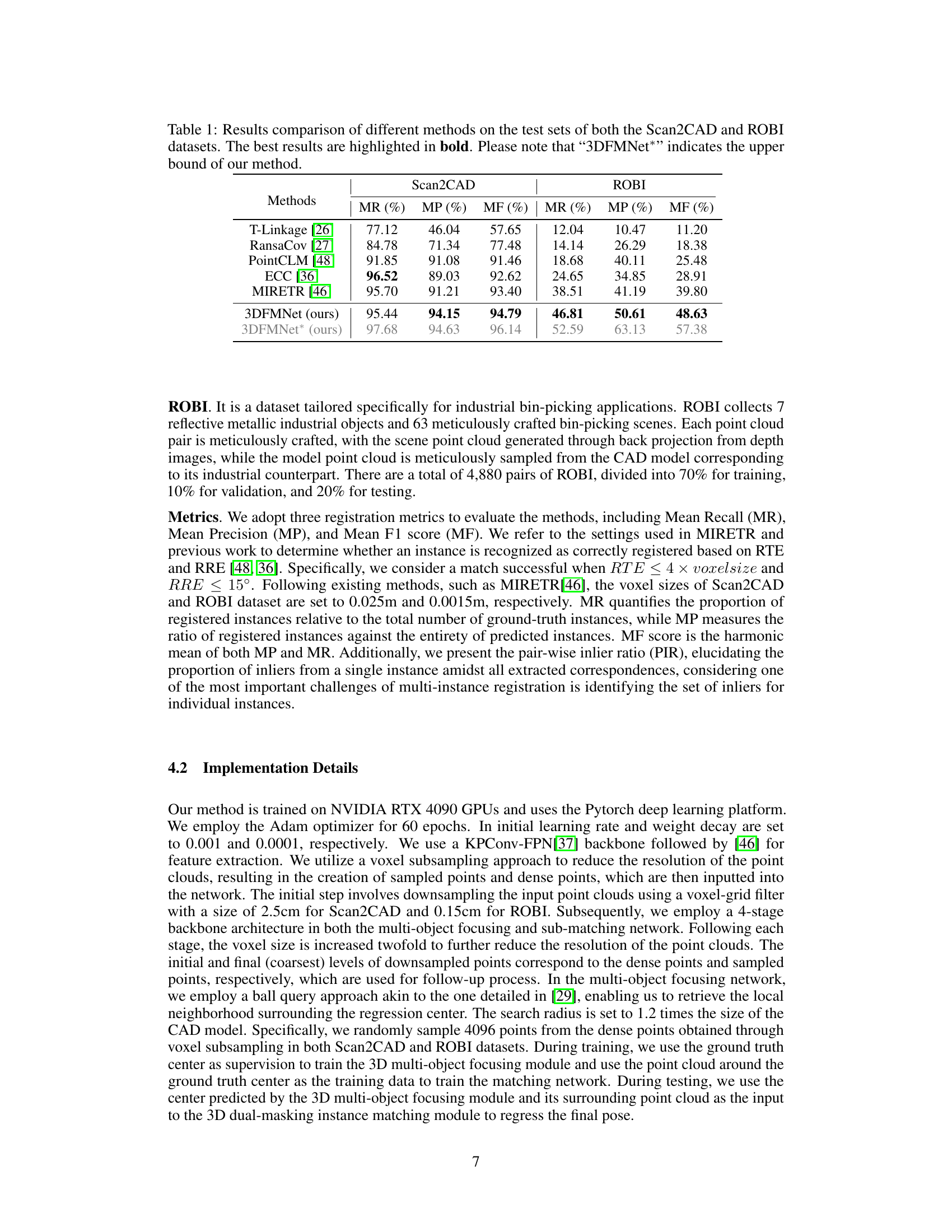
This table compares the performance of the proposed 3DFMNet method against five other state-of-the-art multi-instance point cloud registration methods on two benchmark datasets, Scan2CAD and ROBI. The metrics used for comparison are Mean Recall (MR), Mean Precision (MP), and Mean F1 score (MF). The table shows that 3DFMNet achieves the best performance, especially on the more challenging ROBI dataset. A second row for 3DFMNet* shows the results when using ground truth object centers to provide an upper bound on the performance of the method.
In-depth insights#
3D Focusing Module#
The core of the proposed multi-instance point cloud registration method lies within its novel 3D focusing module. This module’s primary function is to intelligently identify and isolate individual object instances from a complex, cluttered scene. Unlike traditional methods that rely on global correspondence and subsequent clustering, this module leverages a learned feature correlation process. By combining self-attention and cross-attention mechanisms, the network effectively learns to associate the model point cloud with structurally similar regions within the scene, leading to the generation of precise object proposals. This approach is particularly robust as it is less susceptible to the detrimental effects of occlusion and clutter that plague alternative strategies. The focusing module’s output is not just a simple bounding box, but also refined predictions of the object centers, which serve as reliable anchors for the subsequent pairwise registration stage. This precise center localization drastically simplifies the following steps, thereby improving the overall accuracy and efficiency of the registration process. The module’s design underscores a shift away from ambiguous global correspondence and towards a more robust, localized approach to multi-instance point cloud registration, addressing a significant challenge in this field.
Dual-Mask Matching#
The proposed “Dual-Mask Matching” module is a crucial component for refining instance segmentation and achieving accurate pair-wise registration in the context of multi-instance point cloud registration. It cleverly leverages two masks: an instance mask to isolate the object of interest from the background clutter within an object proposal, and an overlap mask to identify the common region between the object proposal and the model point cloud. This dual-masking approach is particularly beneficial when dealing with incomplete or occluded objects, a common challenge in multi-instance scenarios. By applying these masks, the module effectively filters out irrelevant points, focuses the matching process on relevant regions, and improves the robustness of pair-wise registration. The method’s effectiveness is demonstrated by its improved performance on the ROBI dataset, which is known for its challenging, cluttered scenes. The integration of the dual masks highlights the method’s ability to handle complex scenarios, improving both accuracy and efficiency compared to methods relying solely on point-wise correspondence without addressing the issue of incompleteness or occlusion.
Multi-Instance Reg#
Multi-instance registration (MIR) tackles the challenging problem of aligning a single model point cloud to multiple instances of that object within a complex scene. The core difficulty lies in simultaneously identifying and localizing each instance while estimating its pose relative to the model. Unlike single-instance registration, MIR must contend with occlusion, clutter, and variations in instance appearance. Effective MIR algorithms require robust methods for identifying correspondences, separating instances, and handling partial or incomplete observations. Approaches may involve global feature extraction followed by clustering or a more direct end-to-end learning approach, aiming to predict instance-specific transformations directly. The performance of MIR algorithms is heavily dependent on the complexity of the scene and the quality of the input point clouds. Further research should focus on developing more robust methods for handling partial data, occlusion, and varying instance poses. This includes incorporating advanced techniques for feature extraction and correspondence analysis, improving the accuracy of instance segmentation, and optimizing the efficiency of the registration process itself. The development of better benchmark datasets, which include challenging, real-world scenarios, is crucial for evaluating and advancing the state-of-the-art in MIR.
Ablation Experiments#
Ablation studies systematically remove components of a model to determine their individual contributions. In this context, it would involve removing parts of the proposed 3D focusing-and-matching network and evaluating the performance on the multi-instance point cloud registration task. Key aspects to analyze would include the impact of removing the 3D multi-object focusing module (assessing the impact on object localization accuracy and its knock-on effects on matching), and analyzing the impact of the 3D dual-masking instance matching module (specifically isolating the effects of instance and overlap masks on registration accuracy, considering challenges like partial object registration). Analyzing the results would reveal which components are crucial for success and which might be redundant or less effective. This detailed analysis would provide strong evidence supporting the design choices and justify the overall framework’s effectiveness. The ablation study would be crucial in demonstrating the modularity and efficacy of the different components and would ultimately aid in determining the architectural robustness of the approach.
Future Work#
The authors acknowledge the two-stage nature of their 3D focusing-and-matching network as a limitation, impacting inference speed. Future work should focus on streamlining the process into a single-stage framework to improve efficiency. This would likely involve directly learning instance-level correspondences without explicit object center detection, perhaps through more sophisticated attention mechanisms or novel network architectures. Addressing the reliance on accurate object localization in the initial stage is crucial. Improving the robustness of object center detection, especially in cluttered scenes, is another important direction, potentially by incorporating more robust feature descriptors or incorporating outlier rejection techniques. Finally, extending the approach to handle dynamic scenes is a compelling area. The current method is suitable for static point clouds; adapting it to track object instances and account for motion would substantially broaden its applications.
More visual insights#
More on figures

This figure illustrates the overall pipeline of the proposed 3D focusing-and-matching network for multi-instance point cloud registration. It’s a two-stage process. The first stage, 3D multi-object focusing module, localizes potential object centers in the scene point cloud by learning correlations between the scene and model point clouds. The second stage, 3D dual-masking instance matching module, performs pair-wise registration between the model point cloud and object proposals generated from the localized object centers. Self-attention and cross-attention mechanisms are used to associate the model point cloud with structurally similar objects, improving object center prediction accuracy. Instance and overlap masks refine the pair-wise registration, addressing the challenges of incomplete objects and background noise.
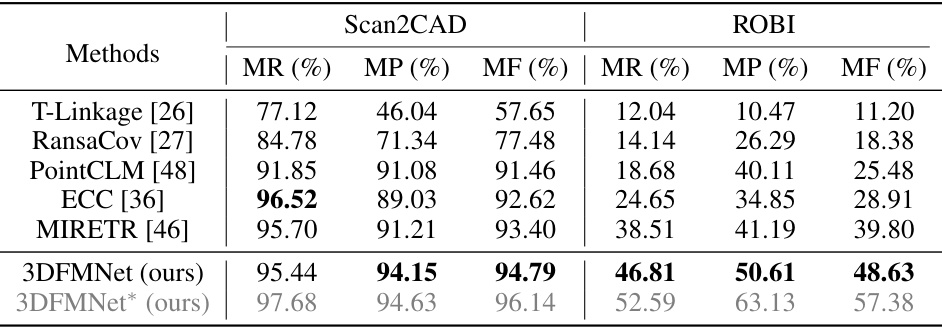
This figure compares the performance of the proposed 3DFMNet method against the state-of-the-art MIRETR method on the Scan2CAD dataset for multi-instance point cloud registration. It shows three sets of point cloud registration results: ground truth, MIRETR results, and 3DFMNet results. Each set contains three examples with different numbers of instances. Red boxes highlight the instances predicted by each method, green boxes are ground truth instances, and the number of instances is indicated for each case. The figure visually demonstrates 3DFMNet’s improved accuracy in identifying and registering multiple instances compared to MIRETR.

This figure compares the performance of the proposed 3DFMNet method against the state-of-the-art MIRETR method on the Scan2CAD dataset. It shows the successfully registered instances for both methods, side-by-side with the ground truth. Each subfigure shows a scene with multiple instances of chairs, with the number of successfully registered instances indicated. The 3DFMNet method showcases improved accuracy in registering the instances compared to the MIRETR method.

This figure visualizes the pair-wise correspondences obtained by the proposed method on the Scan2CAD dataset. It showcases the successful matching of points between the model point cloud and the corresponding instances within the scene point cloud. The visualization helps to illustrate the accuracy and effectiveness of the 3D dual-masking instance matching module in establishing accurate correspondences, especially in challenging scenarios with cluttered or occluded objects.
More on tables
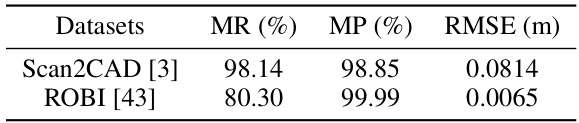
This table presents the performance of the 3D multi-object focusing module in terms of Mean Recall (MR), Mean Precision (MP), and Root Mean Square Error (RMSE). These metrics evaluate the accuracy of the module in identifying object centers in the scene point cloud. The results are shown separately for the Scan2CAD and ROBI datasets.
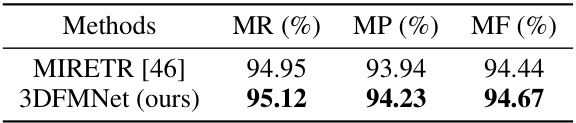
This table presents the results of the 3D multi-object focusing module’s generalizability to unseen scenes. The experiment involves training on a subset of ShapeNet categories and testing on the remaining categories, demonstrating the model’s ability to generalize to novel categories. The metrics used are Mean Recall (MR), Mean Precision (MP), and Mean F1 score (MF). The comparison is made against the state-of-the-art method MIRETR [46].
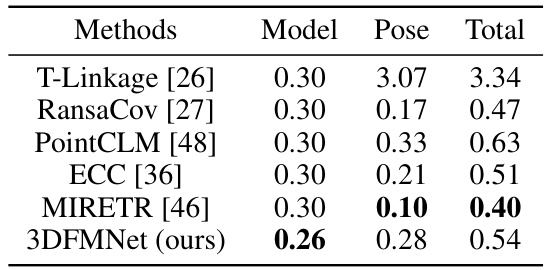
This table compares the performance of several multi-instance point cloud registration methods on two benchmark datasets, Scan2CAD and ROBI. The metrics used for comparison are Mean Recall (MR), Mean Precision (MP), and Mean F1 score (MF). The table shows that the proposed method, 3DFMNet, outperforms other state-of-the-art methods, especially on the more challenging ROBI dataset. An upper bound on the performance of 3DFMNet is also presented.
Full paper#