TL;DR#
Graph Neural Networks (GNNs) often suffer from insufficient high-quality labeled data and limited node connections, hindering their performance. Existing augmentation methods usually address only one of these issues, often with added training costs or simplified approaches that limit generalization. This research introduces IntraMix, a novel method to simultaneously tackle both issues.
IntraMix uses Intra-Class Mixup to generate high-quality labeled data at low cost by blending inaccurate data of the same class. It then strategically selects highly confident nodes within the same class as new neighbors, enriching graph neighborhoods. Extensive experiments on various GNNs and datasets show that IntraMix significantly boosts accuracy and generalizes effectively, thereby challenging the limitations of vanilla Mixup in node classification.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in graph neural networks (GNNs) as it directly addresses the critical issues of data scarcity and limited neighborhood information that hinder GNN performance. By introducing IntraMix, a novel data augmentation method, the paper offers a practical solution for enhancing GNN accuracy and generalizability. The proposed method is theoretically grounded, easily implementable, and demonstrates significant improvement across diverse GNNs and datasets. This work paves the way for future research exploring the use of IntraMix in various applications and its potential to tackle the over-smoothing problem often associated with deeper GNNs.
Visual Insights#

🔼 This figure compares vanilla Mixup and IntraMix. Vanilla Mixup, shown in (a), mixes nodes from different classes, resulting in noisy labels and incorrect message passing. IntraMix, shown in (b), employs Intra-Class Mixup to generate high-quality data within the same class, thereby enhancing label quality and finding accurate neighbors. This approach ensures correct message passing and improves both label accuracy and neighborhood information.
read the caption
Figure 1: a). Vanilla Mixup may retain label noise, and connecting generated nodes to original nodes may lead to incorrect propagation. b). IntraMix generates high-quality data by Intra-Class Mixup and enriches neighborhoods while preserving correctness by connecting generated data to high-quality nodes.
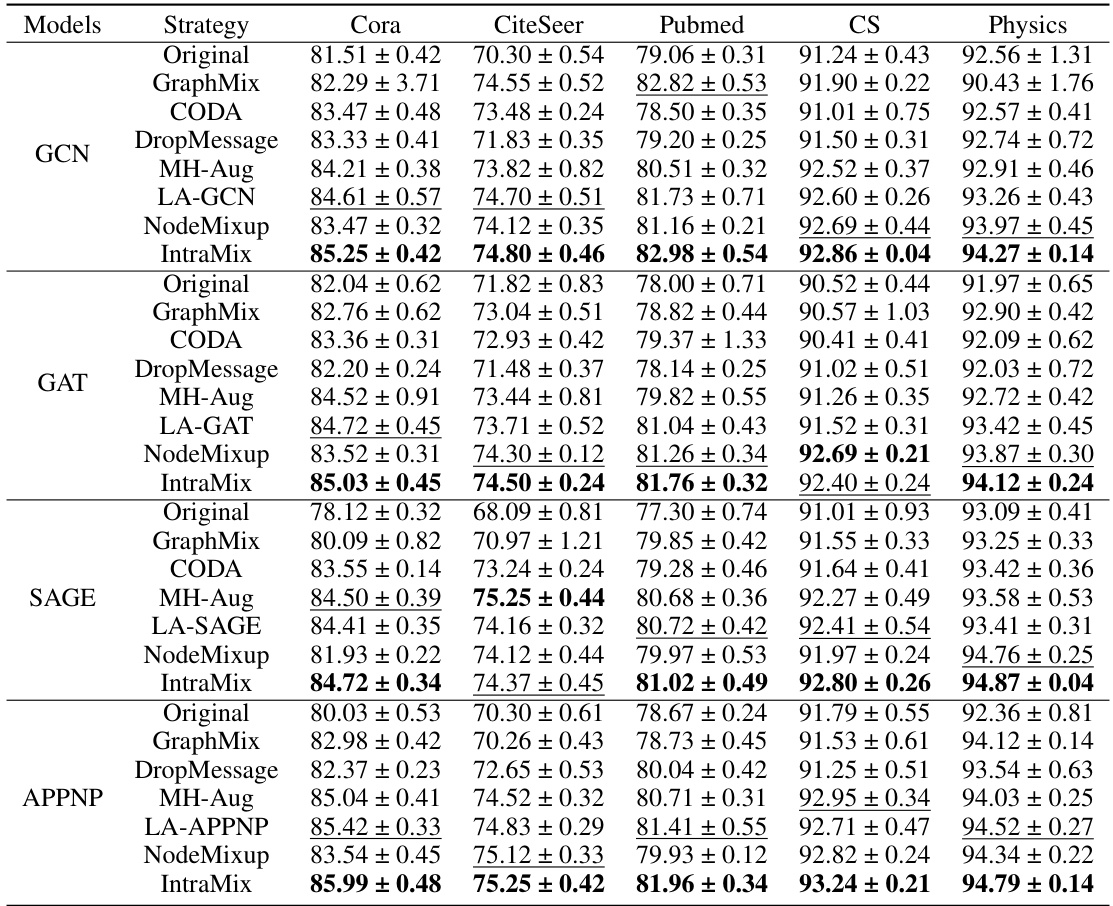
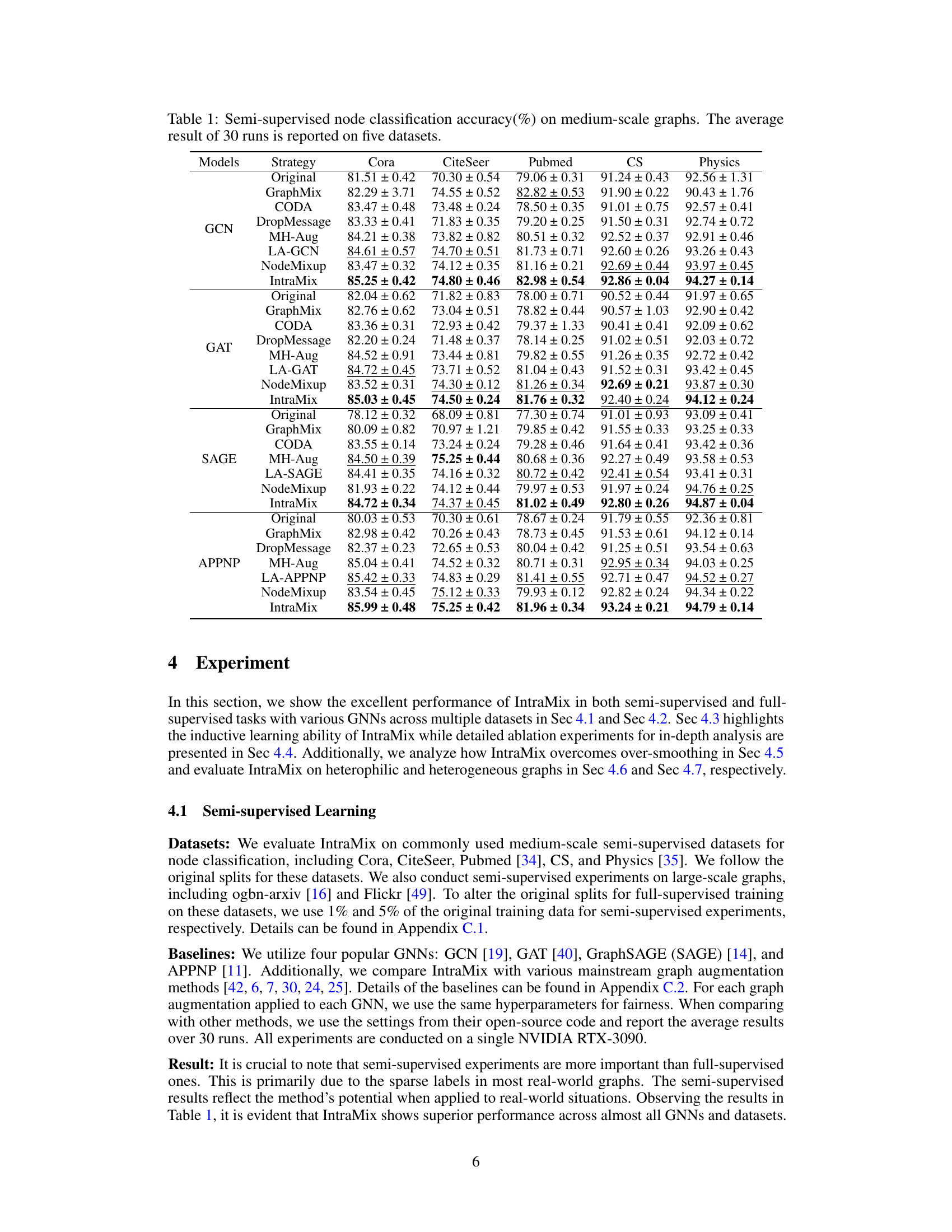
🔼 This table presents the results of semi-supervised node classification experiments conducted on five medium-scale graph datasets (Cora, CiteSeer, Pubmed, CS, and Physics). Multiple Graph Neural Network (GNN) models (GCN, GAT, SAGE, APPNP) were evaluated, each with several data augmentation strategies (Original, GraphMix, CODA, DropMessage, MH-Aug, LA-GNN/GAT/SAGE/APPNP, NodeMixup, and IntraMix). The table shows the average accuracy (with standard deviation) achieved by each GNN model under each augmentation strategy across 30 runs, highlighting the impact of the proposed IntraMix method.
read the caption
Table 1: Semi-supervised node classification accuracy(%) on medium-scale graphs. The average result of 30 runs is reported on five datasets.
In-depth insights#
IntraMix: A Deep Dive#
IntraMix, as suggested by the title “IntraMix: A Deep Dive,” warrants a thorough examination. The core idea revolves around augmenting graph data to improve the performance of Graph Neural Networks (GNNs). This is achieved by addressing two key limitations: sparse high-quality labels and limited node neighborhoods. IntraMix cleverly employs intra-class Mixup, a novel technique that blends low-quality labeled data within the same class to generate high-quality labeled data efficiently. Furthermore, it intelligently selects confident neighbors for the generated data, enriching the graph’s structure and enhancing information propagation. This approach is theoretically grounded and experimentally validated, demonstrating significant improvements across various GNNs and datasets. The method’s elegance lies in its generalized nature and its ability to tackle both issues simultaneously, offering a powerful tool for enhancing GNNs in real-world applications where high-quality data is scarce.
Mixup’s Graph Limits#
Mixup, a highly effective data augmentation technique in image classification, faces significant challenges when applied directly to graph data. The core limitation stems from the inherent non-Euclidean nature of graphs. Unlike images where data points are independent, graph nodes possess intricate relationships defined by edges. Vanilla Mixup, which blends feature vectors and labels of two data points, disrupts these connections, creating blended nodes with ambiguous neighborhood structures, thus hindering the performance of Graph Neural Networks (GNNs). This is because GNNs rely on message passing within node neighborhoods, and Mixup’s blended nodes lack clear neighborhood assignments. Intra-class Mixup attempts to mitigate this by blending nodes from the same class, thus preserving class-related neighborhood relationships and facilitating effective GNN training. However, even this approach might still encounter issues with nodes near class boundaries, creating blended nodes whose class memberships remain uncertain. Therefore, although Mixup offers appealing properties for data augmentation, its naive application to graph data is problematic, highlighting the critical need for specialized graph augmentation techniques like Intra-class Mixup that respect the fundamental topological structure of graphs.
Neighbor Selection#
The effectiveness of Graph Neural Networks (GNNs) hinges on the quality of neighborhood information used during node classification. The ‘Neighbor Selection’ process is critical in ensuring that the GNN leverages relevant and accurate information. The proposed method intelligently selects neighbors by prioritizing nodes with high confidence in the same class as the generated node. This approach not only improves the accuracy of node classification but also enhances the overall robustness of the GNN. By carefully choosing neighbors, the method effectively minimizes the effect of noisy or low-quality data often associated with pseudo-labeling, thus improving the quality of message passing and ultimately model performance. Connecting generated nodes to high-confidence nodes of the same class ensures meaningful interactions and avoids the introduction of noise from poorly labeled neighbors. This strategic neighborhood selection is a key differentiator that distinguishes the proposed approach from previous methods. The method efficiently handles the duality of label scarcity and limited neighborhood information by connecting the generated node with two existing, high-confidence neighbors of the same class, simultaneously addressing both primary graph-related challenges.
Over-smoothing Fix#
Over-smoothing, a critical issue in deep Graph Neural Networks (GNNs), arises from the excessive aggregation of information across layers, leading to feature homogenization and reduced node discriminability. Strategies to mitigate over-smoothing often involve architectural modifications, such as employing skip connections, attention mechanisms, or graph-level augmentations to enrich node neighborhoods. Another common approach focuses on adjusting the training process, for example, by using techniques that improve the gradient flow during training or encourage the model to learn more robust representations. Data augmentation techniques play a key role in addressing the problem by providing the GNN with richer and more diverse training data, which helps prevent the network from collapsing into over-simplified representations. Ultimately, effective over-smoothing fixes require a multifaceted approach that combines improved architectures, innovative training strategies, and robust data augmentation methods. The optimal solution will depend on the specific application and the characteristics of the graph data itself.
Future Research#
Future research directions stemming from this IntraMix paper could explore adapting IntraMix to handle various graph types, beyond the datasets tested. This includes addressing challenges posed by heterophilic and heterogeneous graphs, where the neighborhood assumption might not hold. Integrating IntraMix with other graph augmentation techniques could lead to synergistic improvements. For instance, combining it with methods that focus on edge or subgraph manipulations might create even more effective data enhancements. It would also be insightful to investigate the impact of noise characteristics on IntraMix’s performance and to refine the pseudo-labeling strategies for better label quality. Finally, a thorough theoretical analysis to establish a firm theoretical foundation for IntraMix’s effectiveness across diverse graph structures and label noise scenarios is crucial for advancing the field.
More visual insights#
More on figures
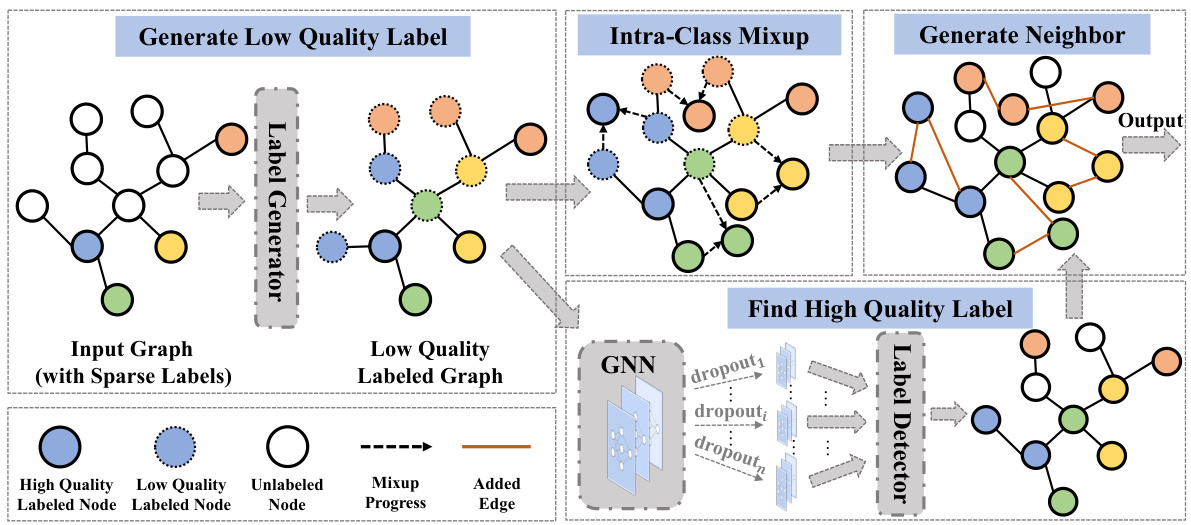
🔼 This figure shows the workflow of the IntraMix method. It starts with an input graph containing sparsely labeled nodes. A label generator assigns low-quality labels to the unlabeled nodes using pseudo-labeling. Then, Intra-Class Mixup generates high-quality labeled nodes by mixing low-quality labeled nodes of the same class. The method proceeds to identify and connect high-confidence nodes of the same class as neighbors for the newly generated nodes. Finally, a label detector further refines labels for increased accuracy. This process enriches both the accuracy of node labels and the information content within the graph’s neighborhood structure.
read the caption
Figure 2: The workflow of IntraMix involves three main steps. First, it utilizes pseudo-labeling to generate low-quality labels for unlabeled nodes. Following that, Intra-Class Mixup is employed to generate high-quality labeled nodes from low-quality ones. Additionally, it identifies nodes with high confidence in the same class and connects them, thus constructing a rich and reasonable neighborhood.
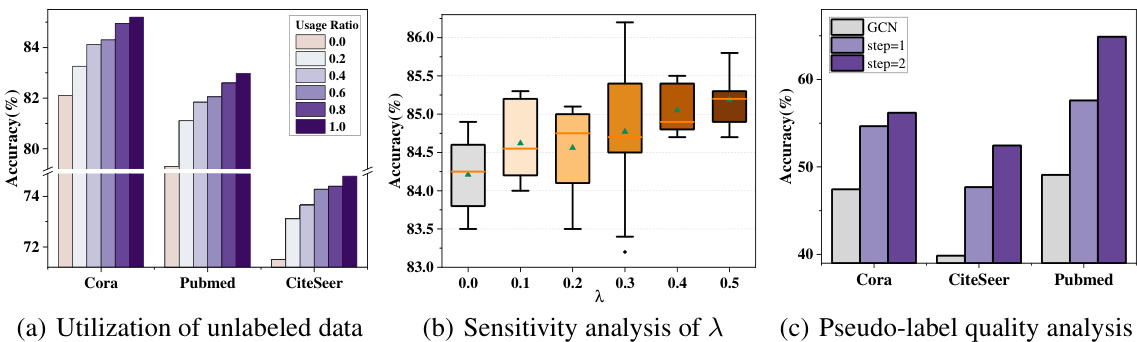
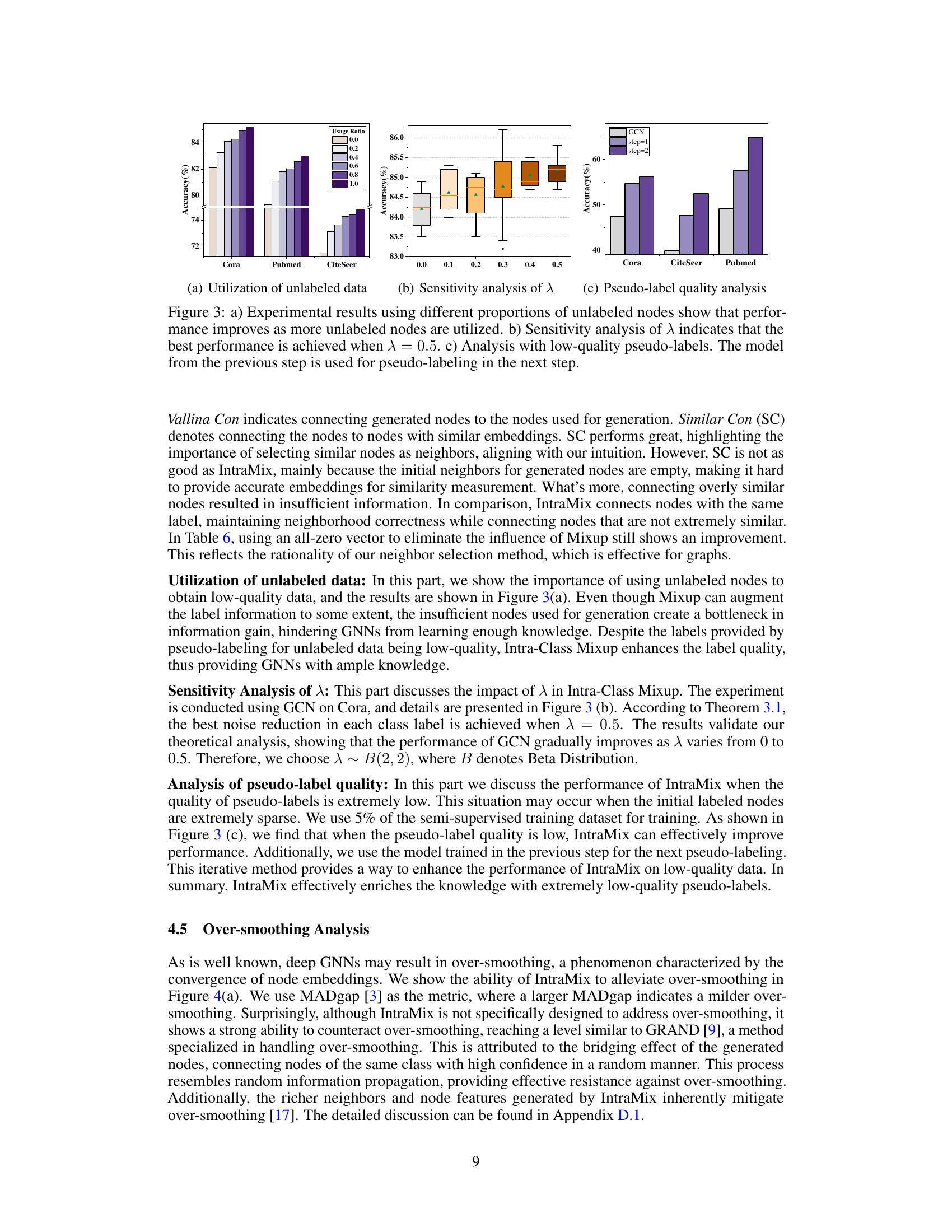
🔼 This figure shows three subfigures presenting the experimental results of IntraMix. The first subfigure (a) shows the impact of utilizing different proportions of unlabeled data on the model’s accuracy. The second subfigure (b) presents a sensitivity analysis to determine the optimal value of λ (lambda) parameter used in Intra-Class Mixup, demonstrating that λ = 0.5 yields the best performance. The third subfigure (c) analyzes the impact of low-quality pseudo-labels on the model accuracy, where the model from the previous step is iteratively used for generating pseudo-labels.
read the caption
Figure 3: a) Experimental results using different proportions of unlabeled nodes show that performance improves as more unlabeled nodes are utilized. b) Sensitivity analysis of λ indicates that the best performance is achieved when λ = 0.5. c) Analysis with low-quality pseudo-labels. The model from the previous step is used for pseudo-labeling in the next step.

🔼 This figure presents an ablation study on IntraMix. Panel (a) shows how utilizing different proportions of unlabeled data impacts performance. The more unlabeled data used, the better the results. Panel (b) is a sensitivity analysis that reveals an optimal λ value of 0.5 for best performance in the Intra-class Mixup. Panel (c) demonstrates the impact of initial low-quality pseudo-labels on the performance of the iterative pseudo-labeling process. Even with low-quality pseudo-labels, the iterative process leads to better performance by improving the quality of labels progressively.
read the caption
Figure 3: a) Experimental results using different proportions of unlabeled nodes show that performance improves as more unlabeled nodes are utilized. b) Sensitivity analysis of λ indicates that the best performance is achieved when λ = 0.5. c) Analysis with low-quality pseudo-labels. The model from the previous step is used for pseudo-labeling in the next step.
🔼 This figure illustrates the three main steps in the IntraMix workflow. First, pseudo-labeling assigns low-quality labels to unlabeled nodes. Then, Intra-Class Mixup generates high-quality labeled nodes from these low-quality ones. Finally, nodes with high confidence of belonging to the same class as the generated data are identified and connected as neighbors, enriching the graph’s neighborhood structure.
read the caption
Figure 2: The workflow of IntraMix involves three main steps. First, it utilizes pseudo-labeling to generate low-quality labels for unlabeled nodes. Following that, Intra-Class Mixup is employed to generate high-quality labeled nodes from low-quality ones. Additionally, it identifies nodes with high confidence in the same class and connects them, thus constructing a rich and reasonable neighborhood.
More on tables
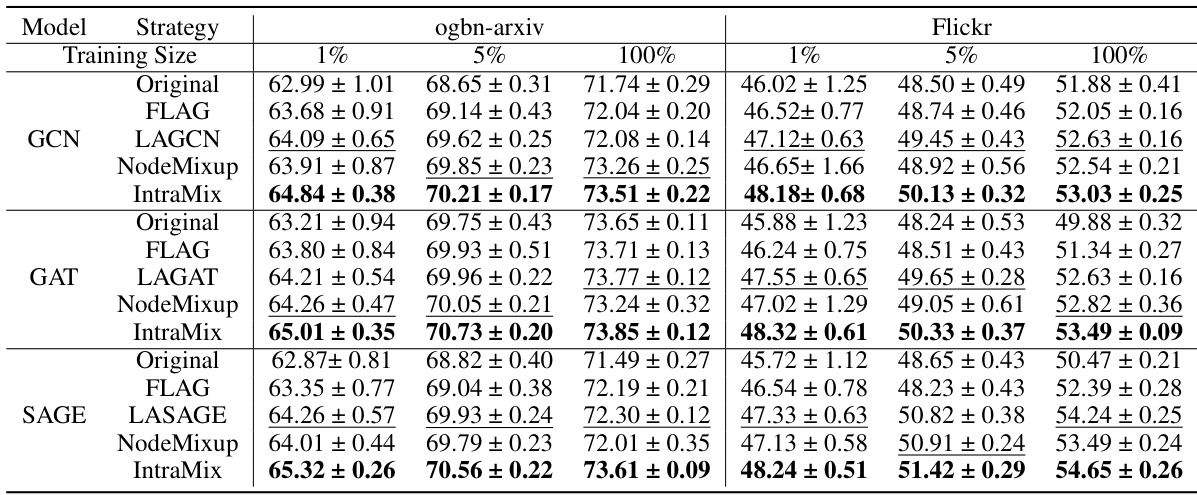
🔼 This table presents the results of semi-supervised node classification experiments on five medium-scale graph datasets (Cora, CiteSeer, Pubmed, CS, and Physics). Multiple graph neural network (GNN) models (GCN, GAT, SAGE, APPNP) were evaluated, along with several data augmentation strategies (Original, GraphMix, CODA, DropMessage, MH-Aug, LA-GCN/GAT/SAGE/APPNP, NodeMixup, and IntraMix). The table shows the average classification accuracy (%) achieved by each GNN model with different augmentation methods over 30 independent runs. The results provide a comparison of the effectiveness of different graph augmentation techniques in semi-supervised node classification.
read the caption
Table 1: Semi-supervised node classification accuracy(%) on medium-scale graphs. The average result of 30 runs is reported on five datasets.

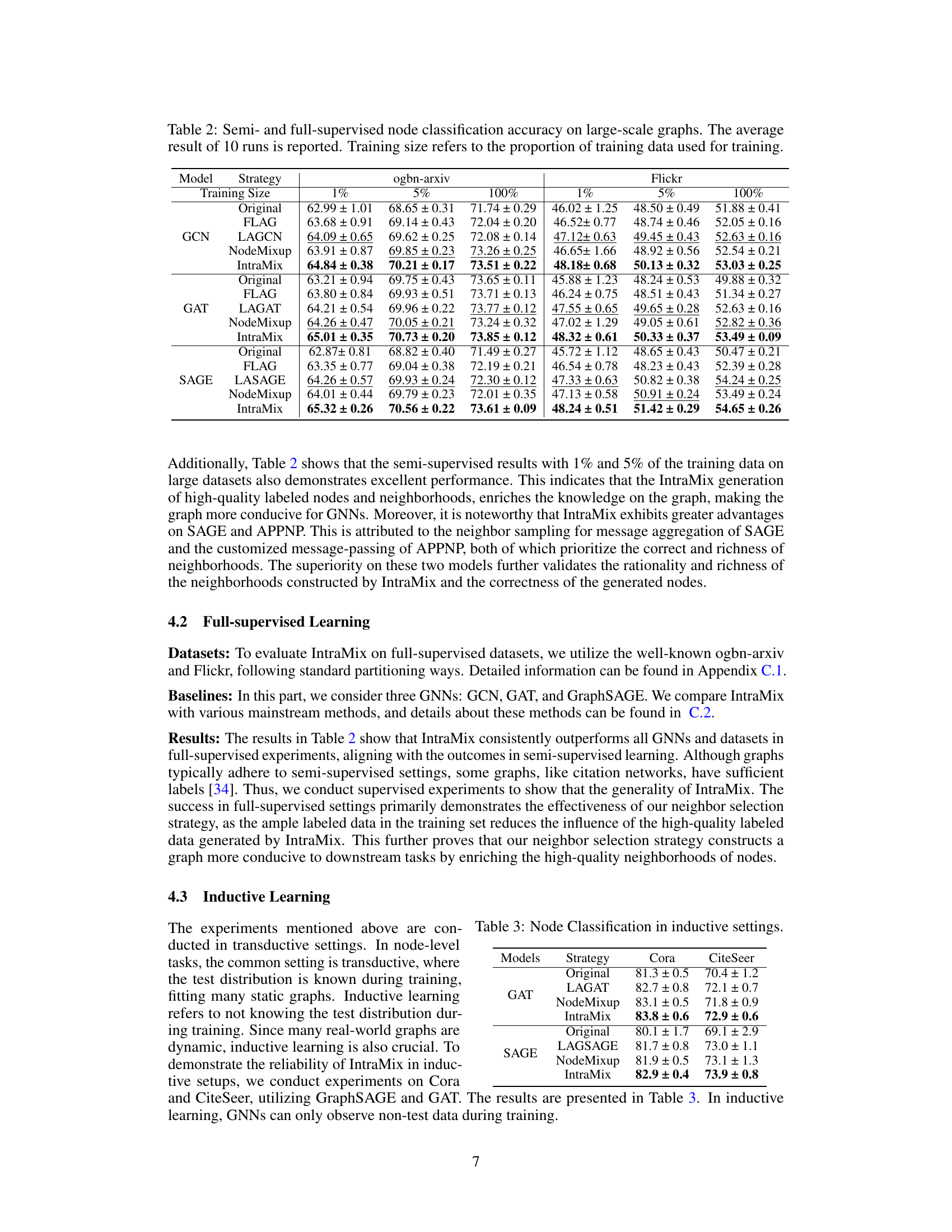
🔼 This table presents the results of node classification experiments conducted in inductive learning settings. Inductive learning differs from transductive learning in that the test data distribution is unknown during training. The table compares the performance of different GNN models (GAT and SAGE) using various augmentation strategies (Original, LAGAT/LAGSAGE, NodeMixup, IntraMix) on two datasets (Cora and CiteSeer). The results highlight the effectiveness of IntraMix in improving the accuracy of node classification, even when the model is trained without knowledge of the test data distribution.
read the caption
Table 3: Node Classification in inductive settings.

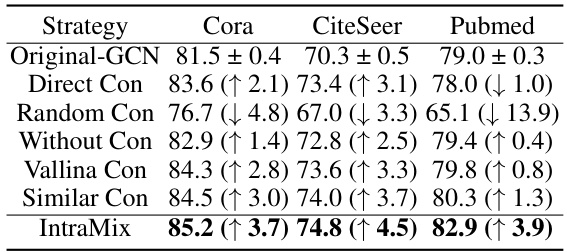
🔼 This table presents the ablation study of Intra-Class Mixup using GCN on Cora, CiteSeer, and Pubmed datasets. It compares the performance of the original GCN, GCN with only pseudo-labeling (PL), GCN with an advanced PL method (UPS), GCN with vanilla Mixup (without connection, with connection using nodes involved in Mixup, and with similar connection using nodes with similar embeddings), and GCN with Intra-Class Mixup. The results show the improvement in accuracy achieved by Intra-Class Mixup compared to other methods.
read the caption
Table 4: Ablation of Intra-Class Mixup on GCN. w con is vallina mixup connection, and sim con is similar connection. ↑ is the improvement.
🔼 This table presents the results of semi-supervised node classification experiments conducted on five medium-scale graph datasets (Cora, CiteSeer, Pubmed, CS, and Physics). Multiple Graph Neural Network (GNN) models (GCN, GAT, SAGE, and APPNP) were evaluated, along with several augmentation strategies (Original, GraphMix, CODA, DropMessage, MH-Aug, LA-GCN/GAT/SAGE/APPNP, NodeMixup, and IntraMix). The table shows the average accuracy (and standard deviation) achieved by each GNN model using the different augmentation methods across 30 experimental runs.
read the caption
Table 1: Semi-supervised node classification accuracy(%) on medium-scale graphs. The average result of 30 runs is reported on five datasets.
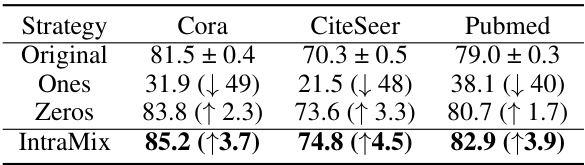
🔼 This ablation study investigates the impact of Intra-Class Mixup on node classification accuracy using GCN on three datasets (Cora, CiteSeer, Pubmed). It compares the original GCN performance against three variations: using only pseudo-labels, replacing generated nodes with all-zeros, and replacing them with all-ones. The results demonstrate the effectiveness of Intra-Class Mixup in generating high-quality labeled nodes, leading to significantly improved classification accuracy compared to baselines.
read the caption
Table 6: Explore the effect of generating node with Intra-Class Mixup. Zeros means replacing the generated nodes with an all-zero vector, and Ones means replacing them with an all-one vector.
🔼 This table presents the results of semi-supervised node classification experiments conducted on five medium-scale graph datasets (Cora, CiteSeer, Pubmed, CS, and Physics). Multiple Graph Neural Network (GNN) models (GCN, GAT, SAGE, and APPNP) were evaluated, each with several different data augmentation strategies (Original, GraphMix, CODA, DropMessage, MH-Aug, LA-GCN/GAT/SAGE/APPNP, NodeMixup, and IntraMix). The table shows the average accuracy achieved by each GNN model across 30 runs for each augmentation strategy, providing a comparison of performance improvement due to data augmentation methods.
read the caption
Table 1: Semi-supervised node classification accuracy(%) on medium-scale graphs. The average result of 30 runs is reported on five datasets.

🔼 This table presents the results of semi-supervised node classification experiments conducted on five medium-scale graph datasets (Cora, CiteSeer, Pubmed, CS, and Physics). The experiments compared the performance of several Graph Neural Networks (GNNs) with and without the IntraMix augmentation method. For each GNN, several augmentation strategies are tested, including original (no augmentation), GraphMix, CODA, DropMessage, MH-Aug, LA-GCN, NodeMixup, and IntraMix. The table shows the average accuracy across 30 runs for each GNN and augmentation strategy on each dataset, providing a comprehensive comparison of IntraMix against existing augmentation methods.
read the caption
Table 1: Semi-supervised node classification accuracy(%) on medium-scale graphs. The average result of 30 runs is reported on five datasets.

🔼 This table presents the results of semi-supervised node classification experiments conducted on five medium-scale graph datasets (Cora, CiteSeer, Pubmed, CS, and Physics). The experiments compare the performance of several Graph Neural Network (GNN) models (GCN, GAT, SAGE, APPNP) with and without various augmentation methods (Original, GraphMix, CODA, DropMessage, MH-Aug, LA-GCN/GAT/SAGE/APPNP, NodeMixup, and IntraMix). For each GNN and augmentation strategy, the average accuracy across 30 independent runs is reported. The table helps assess the impact of different augmentation techniques on the effectiveness of various GNN models in semi-supervised node classification tasks.
read the caption
Table 1: Semi-supervised node classification accuracy(%) on medium-scale graphs. The average result of 30 runs is reported on five datasets.
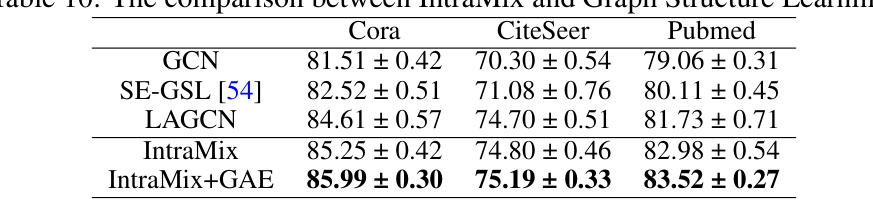
🔼 This table presents the results of semi-supervised node classification experiments conducted on five medium-scale graph datasets (Cora, CiteSeer, Pubmed, CS, and Physics). Multiple Graph Neural Network (GNN) models (GCN, GAT, SAGE, and APPNP) were evaluated, each with several data augmentation strategies (Original, GraphMix, CODA, DropMessage, MH-Aug, LA-GCN/GAT/SAGE/APPNP, NodeMixup, and IntraMix). The accuracy of each model and augmentation strategy is shown, averaged over 30 runs. This allows comparison of the performance of different GNN models and the effectiveness of various data augmentation techniques in semi-supervised node classification.
read the caption
Table 1: Semi-supervised node classification accuracy(%) on medium-scale graphs. The average result of 30 runs is reported on five datasets.
Full paper#