↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing methods for dynamic novel view synthesis often struggle with real-world videos due to overfitting and initialization issues. Specifically, 4D Gaussian Splatting, while promising, tends to over-regularize accurate regions, degrading the reconstruction quality of training images. Fast motions in real-world videos also cause challenges for the Structure from Motion (SfM) algorithm used for initialization, resulting in an incomplete 3D model and thus affecting the training and final reconstruction.
This paper introduces uncertainty-aware regularization to selectively apply additional priors only to uncertain regions in unseen views, thereby improving both novel view synthesis performance and the reconstruction quality of training images. It also presents a dynamic region densification method that uses estimated depth maps and scene flow to initialize Gaussian primitives in areas where SfM fails, thereby providing a more complete and accurate initialization for 4D Gaussian Splatting. Experimental results on real-world monocular videos demonstrate the effectiveness of these improvements.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the challenges of 4D Gaussian Splatting for dynamic scene reconstruction from casually recorded monocular videos. This is a significant advancement in the field, as it addresses limitations of existing methods that struggle with real-world, uncontrolled data. The proposed uncertainty-aware regularization and dynamic region densification techniques offer new approaches to improving both training image reconstruction and novel view synthesis, opening up opportunities for further research in robust and realistic dynamic scene modeling.
Visual Insights#
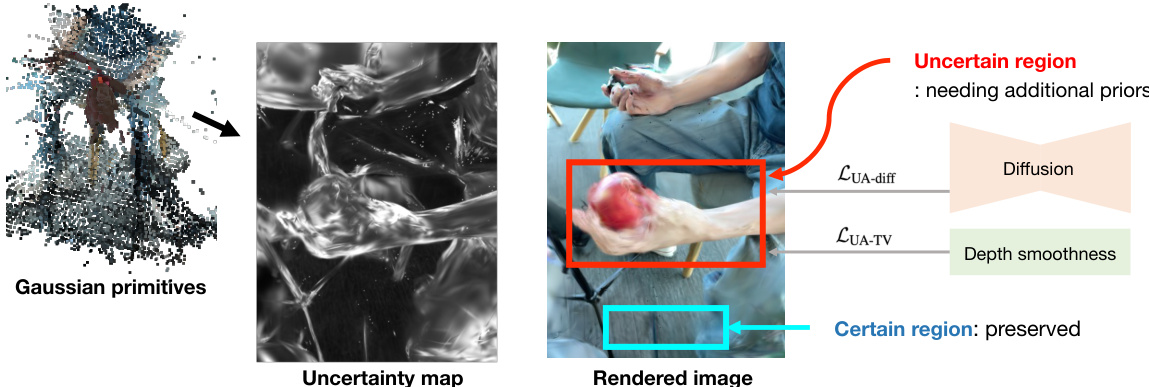
This figure illustrates the core idea of uncertainty-aware regularization. Traditional methods add regularization priors across the entire image, sometimes negatively impacting the quality of already well-reconstructed areas. The proposed method addresses this by identifying uncertain regions (areas needing more information) and applying the regularization only to those, thus preserving accuracy in confidently reconstructed areas.
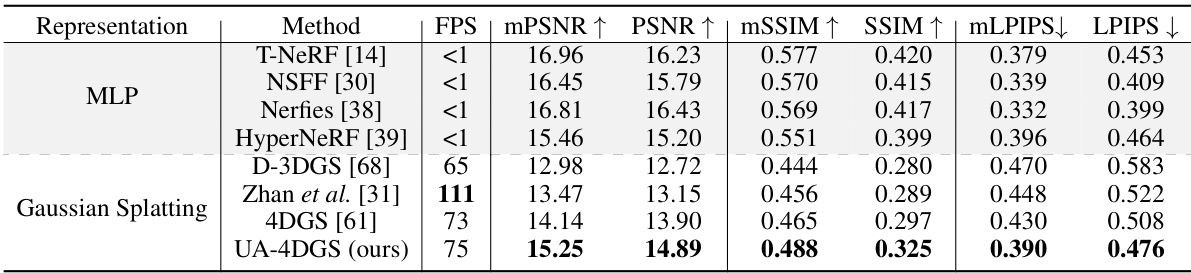
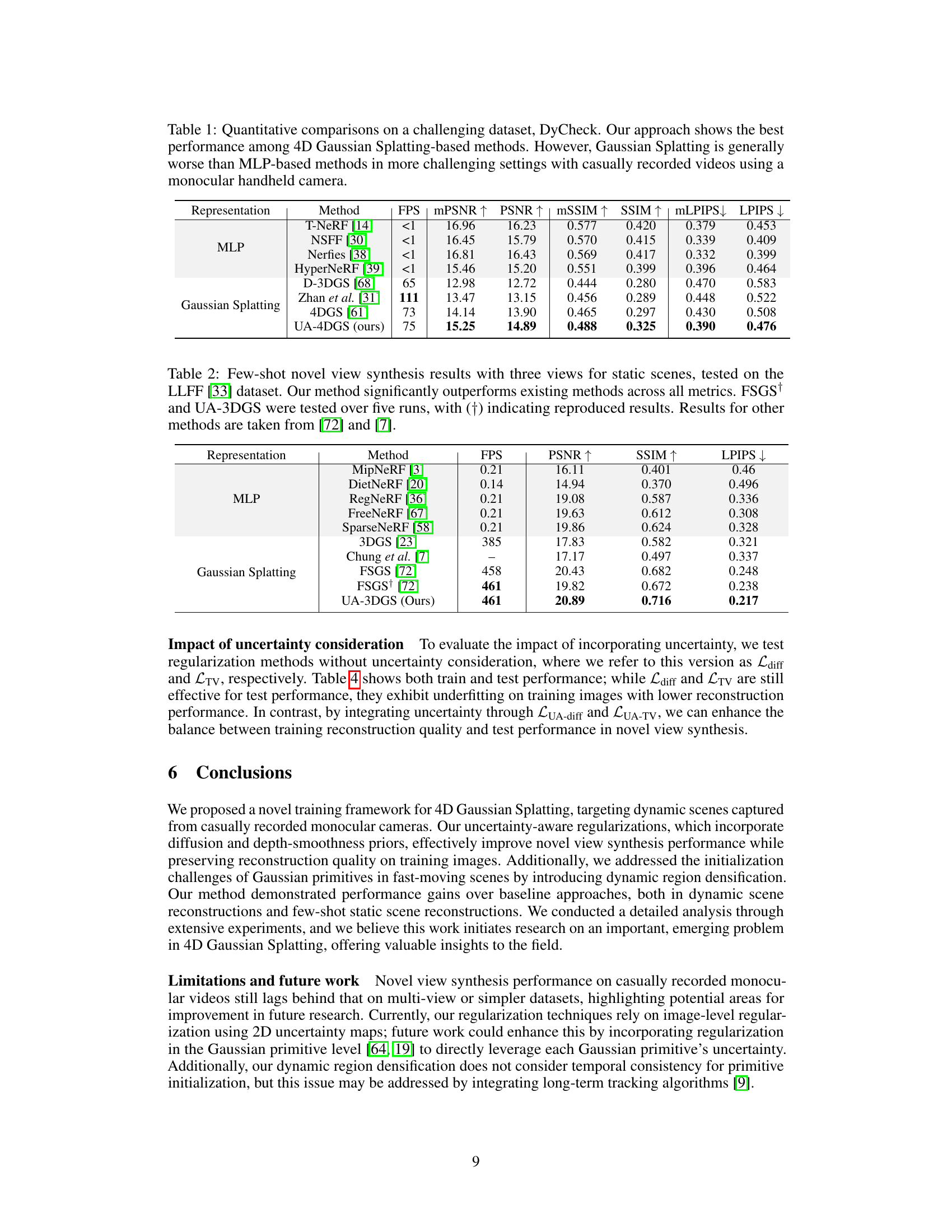
This table presents a quantitative comparison of the proposed method (UA-4DGS) against existing methods for dynamic novel view synthesis on the DyCheck dataset. The metrics used for evaluation include peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), and learned perceptual image patch similarity (LPIPS), with masked versions (mPSNR, mSSIM, mLPIPS) also reported to focus on co-visible regions. The table highlights that the proposed UA-4DGS significantly outperforms other Gaussian splatting based methods but still lags behind MLP-based methods, indicating the inherent challenges in handling casually recorded monocular videos. FPS indicates frames per second.
In-depth insights#
4DGS in the Wild#
The concept of “4D Gaussian Splatting in the Wild” presents a significant advancement in dynamic novel view synthesis. It tackles the challenges of reconstructing dynamic scenes from casually recorded monocular videos, a scenario far more complex than controlled multi-view setups. The “wild” aspect emphasizes the realism and inherent difficulties of real-world data, including noisy observations and inconsistent viewpoints. The core innovation likely involves robust uncertainty-aware regularization techniques, selectively applying priors only where needed, rather than globally, enhancing performance and training image reconstruction. This addresses the overfitting tendency in such sparse data regimes. Further, it will likely detail a dynamic region densification strategy to compensate for the limitations of standard SfM methods in fast-moving scenarios, achieving more reliable initialization of Gaussian primitives. Overall, this approach aims for a significant leap towards practical dynamic scene reconstruction from readily available, non-ideal video data.
Uncertainty Aware Reg#
Uncertainty-aware regularization is a crucial technique for enhancing the robustness and generalizability of machine learning models, especially in scenarios with limited or noisy data. The core idea is to selectively apply regularization based on the estimated uncertainty of model predictions. This approach avoids over-regularizing confident predictions, which can hurt model performance on accurately reconstructed regions. Instead, it focuses on uncertain regions where additional constraints are more beneficial. By carefully assessing the uncertainty of predictions, this technique effectively balances performance on both seen and unseen data, improving generalization without sacrificing accuracy on the training set. This is especially important in tasks like novel view synthesis where overfitting to limited training views is a major concern. Incorporating uncertainty enables the model to prioritize refinement of less certain areas, improving both the quality of novel view generation and the fidelity of training image reconstruction. This targeted regularization strategy is key to improving results in challenging, real-world scenarios, particularly when dealing with limited or noisy data common in many computer vision applications.
Dynamic Region Init#
The heading ‘Dynamic Region Init’ suggests a method for initializing or seeding the system’s representation of dynamic regions within a scene. This is crucial because standard Structure from Motion (SfM) techniques often fail to reliably reconstruct fast-moving objects, leaving these areas poorly defined. A robust ‘Dynamic Region Init’ method would likely involve techniques that go beyond SfM’s limitations. This could include using scene flow estimation to track object motion and inform the initialization process. Integration of depth maps could also contribute significantly, helping to establish the 3D structure of the moving elements. By combining these data sources, the algorithm might be able to identify and accurately represent regions of high uncertainty using uncertainty quantification. This would enhance the model’s ability to generate realistic novel views, even in the presence of fast motion. A key challenge would be balancing the initialization of dynamic regions with the processing of static elements to prevent overfitting and maintain overall scene coherence.
Data-Driven Losses#
The heading ‘Data-Driven Losses’ suggests a methodology where losses are directly derived from data, rather than relying solely on pre-defined metrics. This approach likely involves using the discrepancies between predicted and actual data to guide model training. Depth and flow maps, as mentioned, are key data sources. The algorithm likely measures the difference between estimated and ground-truth depth maps (Ldepth), and similarly, between estimated and ground-truth optical flow (Lflow). This reflects a strong emphasis on realism and accuracy in reconstructing dynamic scenes from real-world videos. Combining Ldepth and Lflow into a single loss (Ldata) likely provides a holistic representation of scene fidelity. The effectiveness of this technique rests on the quality of the ground truth data and the robustness of the estimation methods, highlighting the importance of accurate data acquisition and preprocessing steps. This approach shows strong potential for improving the accuracy and realism of novel view synthesis in dynamic scenes, especially when dealing with challenging, unconstrained data like that obtained from a handheld camera.
Future Work#
The paper’s success in addressing the limitations of existing 4D Gaussian splatting methods through uncertainty-aware regularization and dynamic region densification opens exciting avenues for future research. A key area is improving the handling of temporal inconsistencies, particularly in primitive initialization. Exploring advanced tracking algorithms to ensure temporal coherence would significantly improve reconstruction accuracy and realism. Furthermore, the current reliance on image-level uncertainty quantification could be enhanced by incorporating primitive-level uncertainty to better inform regularization. This would allow for more nuanced control over the regularization process. Another promising direction is the extension to higher-resolution videos and more complex dynamic scenes. The current method performs well on causally-recorded monocular videos, but scaling it to handle substantially larger datasets and more intricate motion patterns presents a significant challenge. Finally, investigating the use of alternative regularization techniques beyond the diffusion and depth smoothness priors utilized in this paper could lead to further performance improvements and potentially reveal more robust and efficient solutions. The paper’s focus on monocular videos could be complemented by exploration of multi-view data fusion to improve accuracy and robustness, providing a holistic approach to dynamic scene reconstruction.
More visual insights#
More on figures

This figure visualizes the dynamic region densification method proposed in the paper. It shows how Structure from Motion (SfM) fails to initialize Gaussian primitives in dynamic regions of a video, and how the proposed method addresses this by using scene flow and depth maps to initialize additional primitives in those regions. The backpack scene is used as an example. The subfigures show (a) a training image, (b) the scene flow, (c) initialization from SfM highlighting the missing area, and (d) the improved initialization after applying the dynamic region densification.

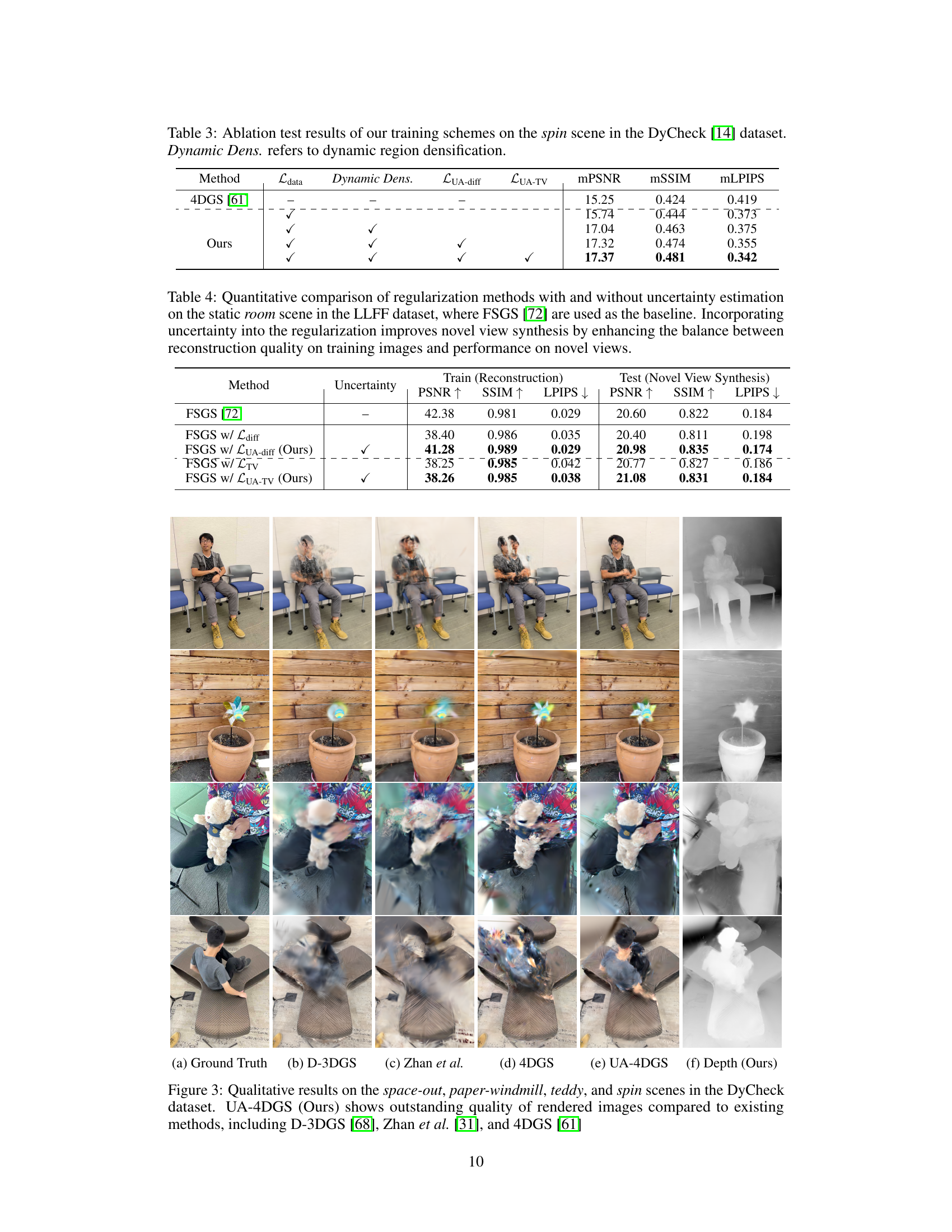
This figure shows a qualitative comparison of novel view synthesis results on four different scenes from the DyCheck dataset. The methods compared are D-3DGS, Zhan et al., 4DGS, and the proposed UA-4DGS. The ground truth images are also shown, as well as a depth map generated by the proposed method. The results visually demonstrate that the proposed UA-4DGS method produces significantly more realistic and higher-quality images compared to the other methods.

This figure compares the novel view synthesis results of four different methods (D-3DGS, Zhan et al., 4DGS, and UA-4DGS) against the ground truth images from the DyCheck dataset. It showcases the superior performance of the proposed UA-4DGS method in generating more realistic and detailed images, particularly in challenging dynamic scenes, as evidenced by clearer rendering of the objects in motion.

This figure shows a qualitative comparison of novel view synthesis results on four different scenes from the DyCheck dataset. The results from four different methods are compared against ground truth images. The methods are D-3DGS, Zhan et al., 4DGS, and UA-4DGS (the authors’ proposed method). The comparison highlights the superior image quality and realism achieved by UA-4DGS, particularly in handling dynamic scenes and fast-moving objects, which are challenging for existing methods.
More on tables
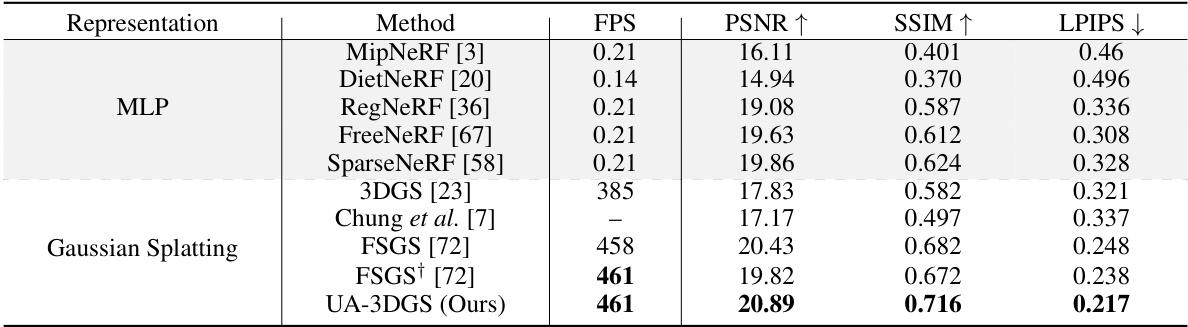
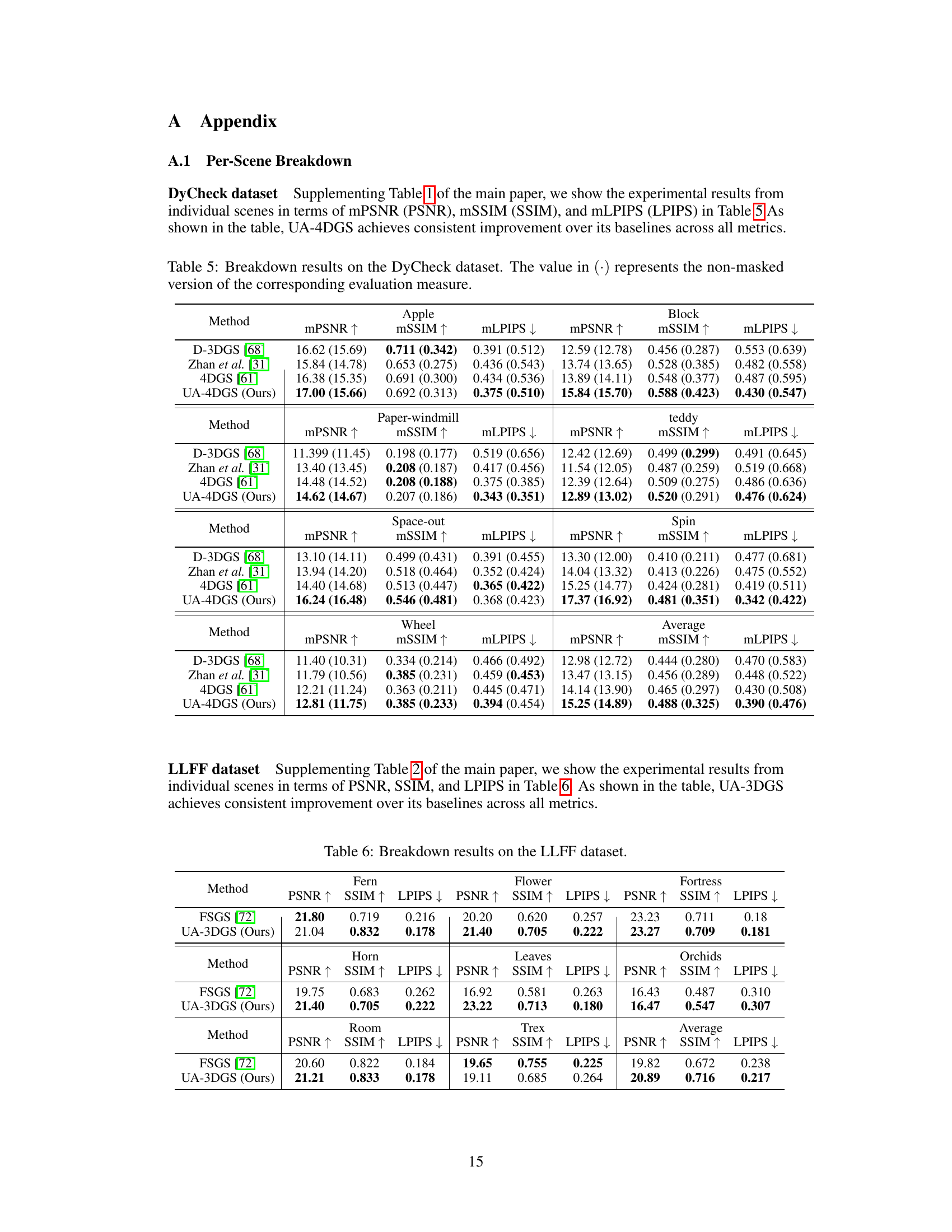
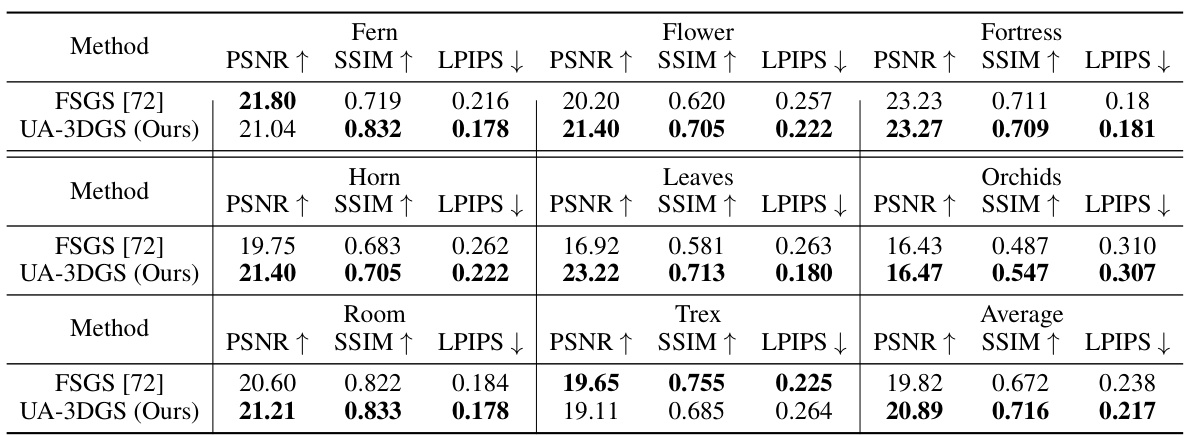
This table compares the performance of the proposed uncertainty-aware 3D Gaussian splatting (UA-3DGS) method against other state-of-the-art methods for few-shot novel view synthesis on the LLFF dataset. The metrics used for comparison are Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). The results demonstrate that UA-3DGS significantly outperforms existing methods.

This table presents the ablation study results focusing on the spin scene from the DyCheck dataset. It shows the impact of different components of the proposed uncertainty-aware 4D Gaussian splatting method on the model’s performance. The components evaluated include the data-driven loss (Ldata), dynamic region densification, the uncertainty-aware diffusion loss (LUA-diff), and the uncertainty-aware total variation loss (LUA-TV). The metrics used to evaluate performance are mPSNR, mSSIM, and mLPIPS.
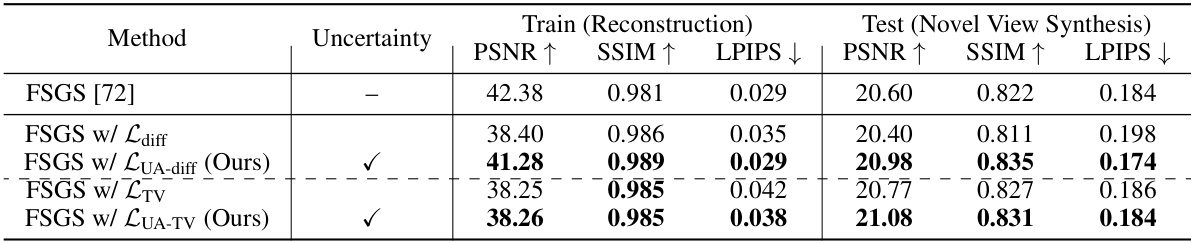
This table compares different regularization methods used in novel view synthesis, focusing on the impact of incorporating uncertainty. It shows the performance of the FSGS model with and without various regularization techniques (with and without uncertainty), demonstrating improved performance for those with uncertainty.
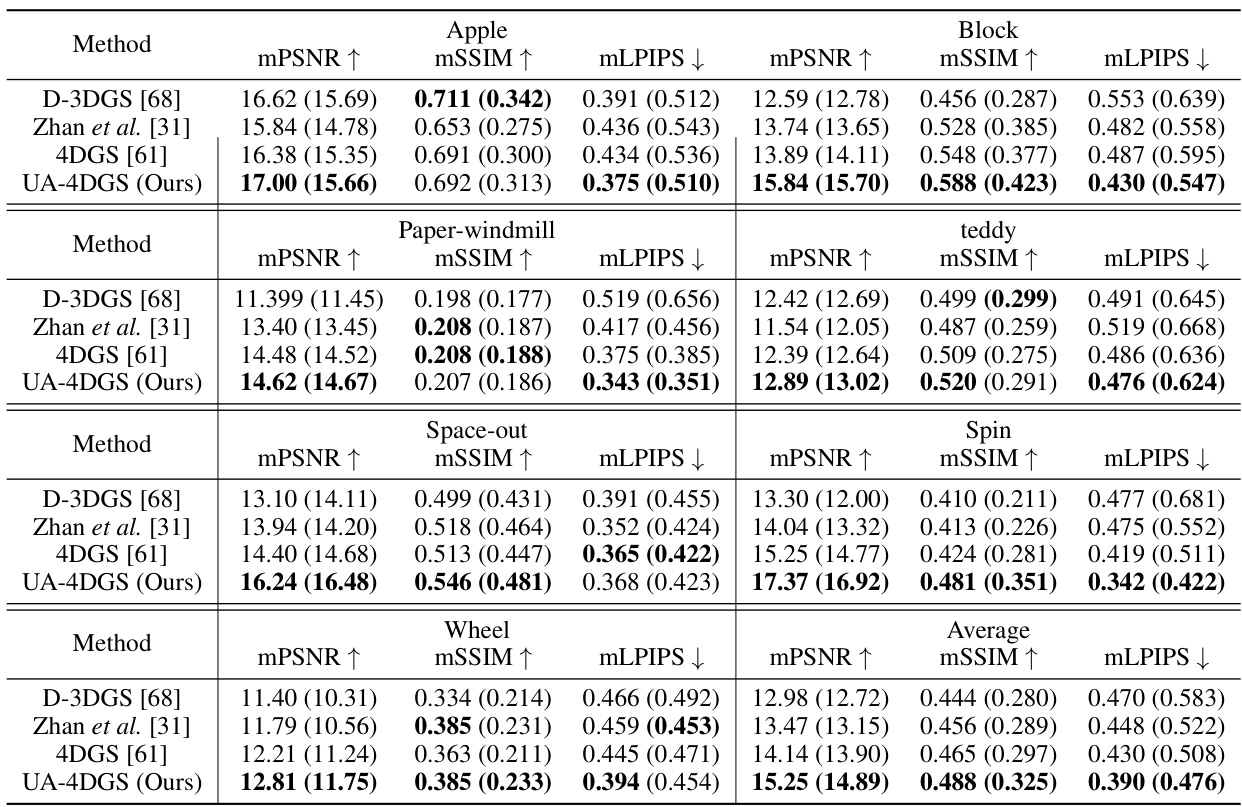
This table presents a quantitative comparison of the proposed method (UA-4DGS) against other existing methods for dynamic novel view synthesis on the DyCheck dataset. The metrics used for comparison are Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). Masked versions of these metrics (mPSNR, mSSIM, mLPIPS) are also included, focusing on the co-visible regions. The table highlights that UA-4DGS outperforms other 4D Gaussian Splatting methods but that Gaussian Splatting methods in general perform worse than MLP-based methods when using casually recorded monocular videos.
This table presents a quantitative comparison of the proposed method (UA-4DGS) against existing methods for dynamic novel view synthesis on the DyCheck dataset. The metrics used for evaluation are peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), and learned perceptual image patch similarity (LPIPS). Masked versions of these metrics (mPSNR, mSSIM, mLPIPS) are also reported, focusing on co-visible regions. The table highlights the superior performance of the proposed method compared to other 4D Gaussian Splatting algorithms and MLP-based methods, especially in challenging scenarios with casually recorded monocular videos.
Full paper#