↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Training large language models (LLMs) is computationally expensive, requiring significant GPU memory. Existing memory-efficient methods like LoRA often compromise performance by using low-rank approximations. Full parameter fine-tuning, while offering superior performance, is often infeasible due to memory constraints. This creates a need for optimization methods that are both memory efficient and preserve model performance.
This paper introduces BAdam, a novel optimization method that addresses this challenge. BAdam leverages a block coordinate descent (BCD) framework, updating parameters block-wise to reduce memory footprint. Experiments show that BAdam significantly outperforms other memory-efficient methods in terms of memory usage and running time while achieving comparable or even better downstream performance. The theoretical convergence analysis further supports BAdam’s efficiency and effectiveness.
Key Takeaways#
Why does it matter?#
This paper is important because it presents BAdam, a novel memory-efficient optimization method for training large language models (LLMs). This addresses a critical challenge in LLM research, enabling researchers with limited computational resources to train and fine-tune larger models. BAdam’s superior performance compared to existing methods opens new avenues for research and development, particularly in the area of parameter-efficient training. The theoretical convergence analysis adds to its significance.
Visual Insights#

This figure illustrates the BAdam optimization method, which is based on block coordinate descent (BCD). It shows how the algorithm iteratively updates blocks of parameters. Each color represents the status of a block: the active block is being updated using K Adam steps, and inactive blocks are either not yet updated in this block-epoch, or already updated in a previous step within this block-epoch. The subproblem for updating the active block is shown, along with the concrete implementation using K Adam steps. The figure visually demonstrates how BAdam divides the model into D blocks and efficiently updates each one sequentially.
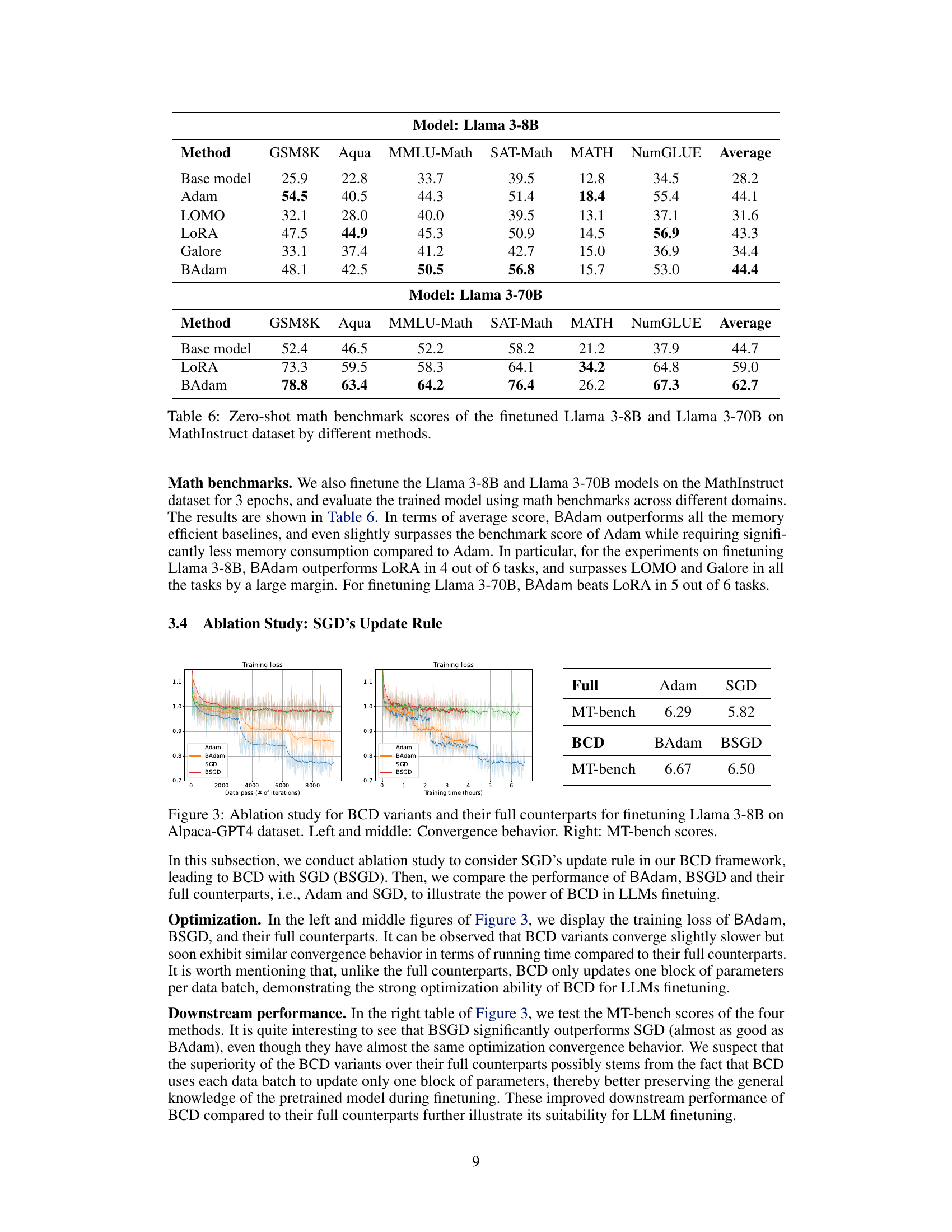
This table summarizes the features of different optimization methods used for training large language models. It compares Adam, LOMO, LoRA, and BAdam in terms of memory usage, whether they perform full parameter training, use momentum and second moment updates, update precision, and use gradient accumulation. The memory usage is expressed in terms of the model size (M billion parameters) and other factors specific to each method (LoRA rank, weight matrix dimension, number of blocks/layers).
In-depth insights#
BAdam’s Efficiency#
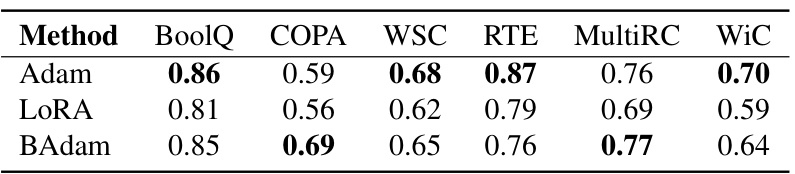
BAdam demonstrates significant efficiency gains in large language model (LLM) finetuning by cleverly addressing the memory constraints inherent in full parameter optimization. Its core innovation is the integration of the block coordinate descent (BCD) framework with Adam’s update rule. This allows BAdam to partition the model’s parameters into blocks, updating one block at a time, thereby drastically reducing the memory footprint compared to traditional full-parameter methods like Adam. Experimental results confirm BAdam’s memory efficiency and speed advantages over baselines like LoRA, showcasing its practicality for training LLMs on hardware with limited GPU resources. While BAdam’s efficiency comes from reducing the memory needed at any point during training, it also boasts comparable or even superior performance in downstream tasks. This efficiency makes BAdam a compelling alternative for researchers and practitioners working with resource-constrained environments.
BCD in LLMs#
The application of Block Coordinate Descent (BCD) to Large Language Models (LLMs) presents a compelling approach to memory-efficient full parameter fine-tuning. Traditional full parameter methods like Adam suffer from excessive memory demands, especially with the growing size of LLMs. BCD addresses this limitation by optimizing parameters in blocks, significantly reducing the memory footprint required at each iteration. This method’s effectiveness stems from its ability to handle the massive parameter spaces of LLMs in a computationally feasible way. Theoretical convergence analyses support the validity of this approach. Empirical results indicate that BCD-based optimizers, such as BAdam, can achieve comparable or even superior performance to full-parameter methods while maintaining memory efficiency, often outperforming parameter-efficient alternatives like LoRA. However, the efficiency gains of BCD in LLMs depend on the choice of block partitioning strategies and hyperparameters like the number of inner Adam steps. Further research should explore optimal strategies for block partitioning, potentially utilizing the model’s architecture to inform the choices. Despite potential limitations, BCD holds substantial promise as a practical solution for fine-tuning LLMs with limited computational resources.
Downstream Tasks#
In evaluating large language models (LLMs), downstream tasks are crucial for assessing their real-world capabilities. These tasks move beyond the model’s internal training data and evaluate its performance on diverse, practical applications. Effective downstream tasks must be carefully selected to comprehensively gauge an LLM’s strengths and weaknesses. For example, tasks like question answering, text summarization, and machine translation test comprehension and generation abilities. However, more nuanced tasks are needed to expose limitations, such as common sense reasoning, bias detection, and robustness against adversarial attacks. The selection of downstream tasks directly impacts the validity and interpretability of LLM evaluation; a well-chosen set provides a more holistic view of the model’s performance and potential, ultimately shaping our understanding of its strengths and limitations in practical applications. The design of benchmark datasets for these tasks is also critical, ensuring diversity and avoiding biases that could skew results.
Future of BAdam#
The future of BAdam hinges on several key areas. Extending its applicability beyond supervised finetuning to encompass other learning paradigms, such as reinforcement learning or preference optimization, is crucial. Addressing the stochastic case theoretically will enhance its robustness and provide a more complete understanding of its convergence properties. Investigating alternative update rules within the BCD framework, such as exploring variations of SGD or other optimizers, could potentially unlock further performance gains. The impact of various block partitioning strategies on both memory efficiency and convergence speed necessitates further exploration. Finally, developing a user-friendly interface for easier integration into existing PyTorch-based codebases will broaden its accessibility and accelerate adoption within the broader research community.
BAdam Limitations#
BAdam, while promising for memory-efficient large language model (LLM) finetuning, has limitations. Its theoretical convergence analysis is limited to the deterministic case, leaving its behavior with stochastic gradients—the norm in practical training—an open question. The efficiency gains are contingent upon the choice of block partitioning strategy; poor partitioning could negate memory savings and impact performance. While BAdam outperforms certain baselines in downstream tasks, its performance relative to Adam is task-dependent, suggesting that the efficiency gains may come at the cost of performance in some scenarios. The impact of hyperparameter K on both memory usage and training speed also needs further investigation. The study focuses mainly on instruction tuning, and more comprehensive testing on other LLMs and tasks would strengthen the conclusions. Finally, although demonstrating strong empirical results, further exploration of its scalability with larger models and datasets is warranted.
More visual insights#
More on figures

This figure illustrates the BAdam optimization method, which uses a block coordinate descent approach. The diagram shows how the model parameters are partitioned into blocks. In each block-epoch, only one block (the active block) is updated using Adam’s update rule, while the other blocks remain unchanged (inactive blocks). The colors visually represent the different states of the blocks in each step of the process (active, non-updated inactive, and updated inactive). This visual representation clarifies the memory efficiency of the method, as only one block needs to be stored and updated in memory at any given time.
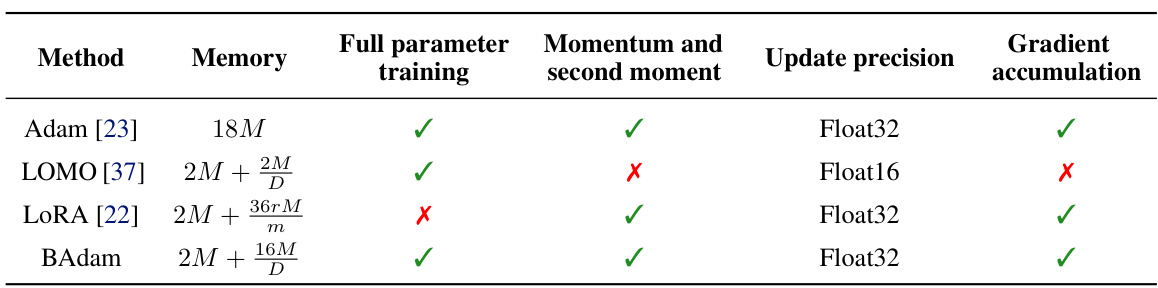
This figure shows the optimization capability of BAdam by comparing it with LoRA. The left panel shows the training loss curves for both methods, indicating BAdam’s faster convergence. The middle panel displays the cumulative explained variance of BAdam’s learned perturbation, suggesting a high-rank update. The right panel compares the effective rank of the learned perturbations for both Adam and BAdam, demonstrating that BAdam achieves a similar high-rank update to Adam.

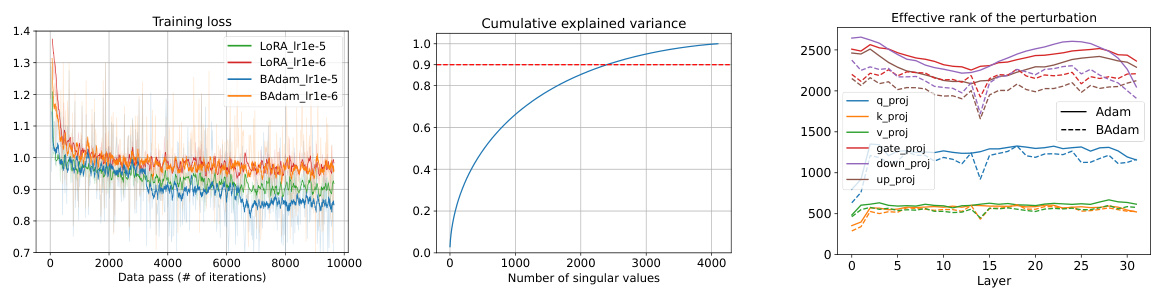
This figure presents an ablation study comparing the performance of BAdam and BSGD (block coordinate descent with SGD) against their full counterparts, Adam and SGD, respectively. The left and middle panels show the convergence behavior of the four optimization methods during the training process, plotting training loss against the number of data passes and training time. The right panel shows the MT-bench scores achieved by each method after training. The results illustrate the effectiveness of the BCD approach in LLM finetuning, even when using SGD instead of Adam.
This figure shows the optimization capability of the BAdam model by comparing its performance with LoRA model in finetuning Llama 3-8B on the Alpaca-GPT4 dataset. The left panel displays the online training loss of both models, showing that BAdam converges faster than LoRA. The middle panel shows the cumulative explained variance of BAdam’s learned perturbation to the 25th layer’s up-proj matrix, indicating that BAdam learns high-rank updates rather than low-rank ones. The right panel displays the effective rank of the learned perturbations by both Adam and BAdam across different layers, showing that BAdam has similar high-rank update with Adam.

This figure shows the optimization capability of BAdam by comparing it to LoRA and Adam. The left panel shows the online training loss curves of BAdam and LoRA, demonstrating that BAdam converges faster initially but eventually aligns with LoRA’s convergence. The middle panel shows the cumulative explained variance of BAdam’s learned perturbation matrix, indicating a heavy-tailed singular value distribution and hence a high-rank update. The right panel displays the effective rank of the learned perturbation matrices of BAdam and Adam across different transformer layers, showing BAdam achieves almost the same high rank update as Adam.
More on tables
This table compares different methods for training large language models (LLMs). It shows the memory requirements (considering both the model parameters and optimizer states), whether full parameter training is supported, if momentum and second moment are used, the update precision, and if gradient accumulation is used. The table highlights that BAdam achieves comparable memory usage to other efficient methods while still performing full parameter training.

This table summarizes the features of different optimization methods used in the paper, including Adam, LOMO, LoRA, and the proposed BAdam. It compares the methods based on memory usage, whether they perform full parameter training, whether they use momentum and second moment updates, the precision of their updates (float16 or float32), and whether they use gradient accumulation. The table highlights that BAdam, despite performing full parameter training, achieves comparable memory efficiency to the other methods due to its block-coordinate descent approach.
This table compares several methods for training large language models, including Adam, LOMO, LoRA, and the proposed BAdam. It highlights key differences in memory usage, whether they perform full parameter training or low-rank adaptation, and other features such as the use of momentum and the precision of updates. The table shows that BAdam achieves full parameter training with memory requirements comparable to more memory-efficient methods.
This table compares the features of different optimization methods for large language models, including Adam, LOMO, LoRA, and the proposed BAdam. It shows the memory requirements, whether full parameter training is performed, the use of momentum and second moments, update precision, and gradient accumulation. The table highlights that BAdam achieves full parameter training with memory efficiency comparable to LOMO and LoRA.

This table compares several methods, including Adam, LOMO, LoRA, and the proposed BAdam, in terms of memory usage, full parameter training capability, use of momentum and second moment, update precision, and gradient accumulation. It highlights BAdam’s memory efficiency, noting that it achieves full parameter training with memory comparable to more limited approaches like LoRA.
This table summarizes the features of various full parameter and parameter-efficient fine-tuning methods for large language models (LLMs). It compares Adam, LOMO, LoRA, and BAdam across several key aspects: memory usage, full parameter training capability, usage of momentum and second moments in the update rule, update precision (floating-point format), and gradient accumulation. The table highlights that BAdam achieves comparable memory efficiency to LOMO and LoRA, while performing full parameter fine-tuning with mixed precision.

This table summarizes the features of different optimization methods, including Adam, LOMO, LoRA, and BAdam. It compares the methods in terms of memory usage for full parameter training, whether they use momentum and second moment, update precision, and gradient accumulation. The table highlights that BAdam, despite performing full parameter training, achieves memory efficiency comparable to LOMO and LoRA.
This table summarizes the key features of different optimization methods used for training large language models. It compares Adam, LOMO, LoRA, and the proposed BAdam method across several key aspects including memory usage, whether full parameter training is performed, the use of momentum and second-moment updates, update precision (float32 vs. float16), and gradient accumulation. The table highlights BAdam’s memory efficiency compared to Adam while achieving comparable performance to LoRA and full parameter training methods.
This table compares several optimization methods (Adam, LOMO, LoRA, and BAdam) based on their memory usage, whether they perform full parameter training, use momentum and second moments, update precision, and gradient accumulation. It highlights that BAdam, despite performing full parameter training, has memory requirements similar to the more memory-efficient methods LOMO and LoRA.
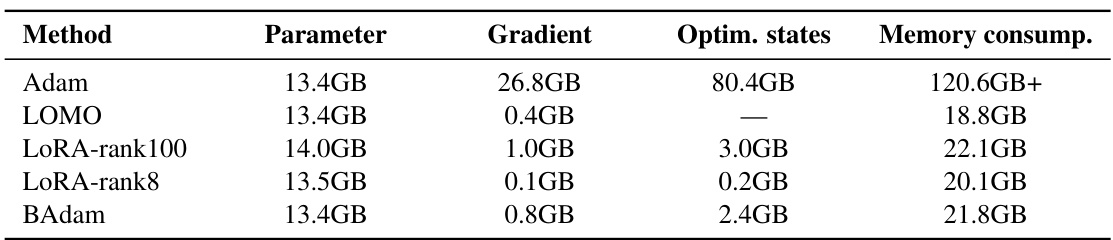
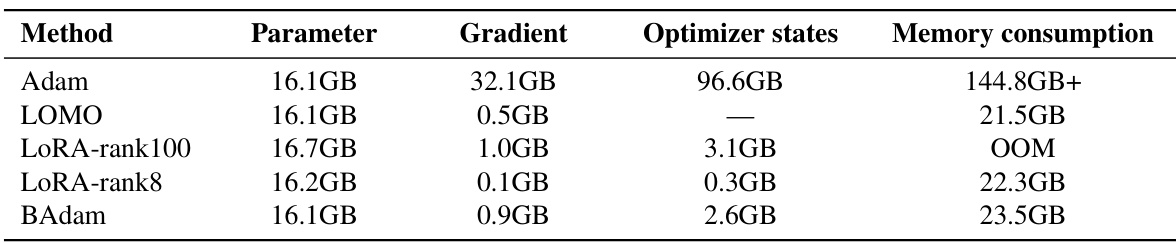
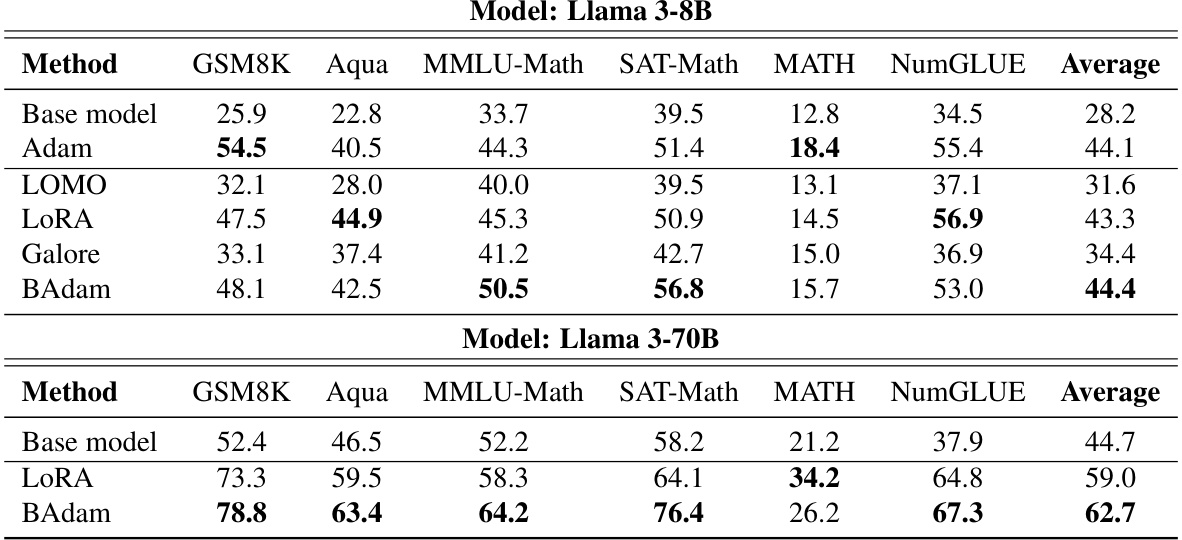
This table shows the memory usage of different methods (Adam, LOMO, LoRA with different ranks, and BAdam) when training Llama 3-8B. It breaks down the memory usage into the model parameters, gradients, and optimizer states. The table highlights that BAdam achieves a significant reduction in memory consumption compared to Adam, while maintaining comparable performance.

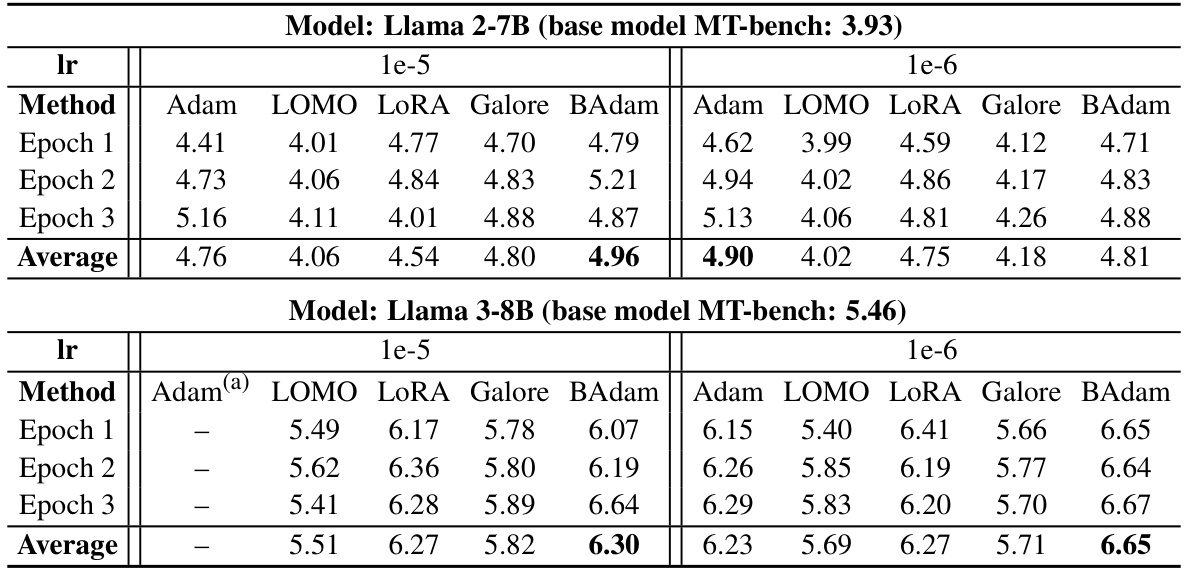
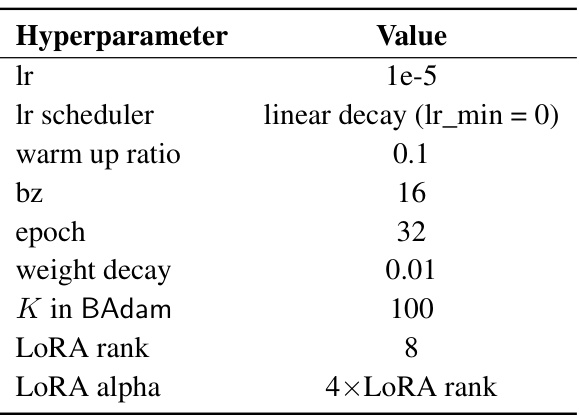
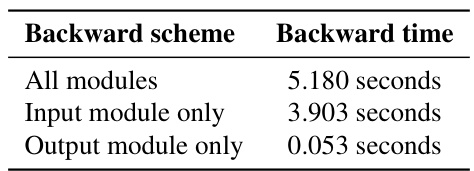
This table shows the time taken for each stage (forward pass, backward pass, and parameter update) during the training of the Llama 3-8B language model using different optimization methods (LOMO, LoRA, and BAdam). The single pass batch size is 2, and the results are averaged over three epochs of training. The results highlight the efficiency of BAdam, especially during the backward pass.
This table summarizes the features of different optimization methods for large language models, including Adam, LOMO, LoRA, and the proposed BAdam. It compares these methods based on memory usage, whether they perform full parameter training, the use of momentum and second moment, update precision, and gradient accumulation. The table highlights that BAdam achieves comparable memory efficiency to LOMO and LoRA while performing full parameter updates.
Full paper#