TL;DR#
Large Language Models (LLMs) are computationally expensive. Knowledge distillation (KD) aims to transfer knowledge from a large teacher model to a smaller student model to improve efficiency without significant performance loss. Current KD methods mainly focus on minimizing the difference between teacher and student probability distributions, which can be suboptimal. This approach has limitations in capturing the essence of language knowledge and generalizing well.
This paper proposes a new KD method using reinforcement learning, focusing on matching action-value moments instead of probability distributions. This is done via an adversarial training approach which optimizes both on-policy and off-policy objectives simultaneously, improving generalization performance. The results demonstrate significant improvements over existing techniques in instruction-following and various task-specific experiments, achieving state-of-the-art results.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to knowledge distillation for large language models (LLMs), a crucial area for improving LLM efficiency and performance. The adversarial moment-matching method offers a potential solution to limitations of existing distribution-matching techniques, opening avenues for more effective knowledge transfer in LLMs. The results show significant improvement in various tasks. This research will influence future LLM development and guide researchers towards better efficiency and broader applications.
Visual Insights#
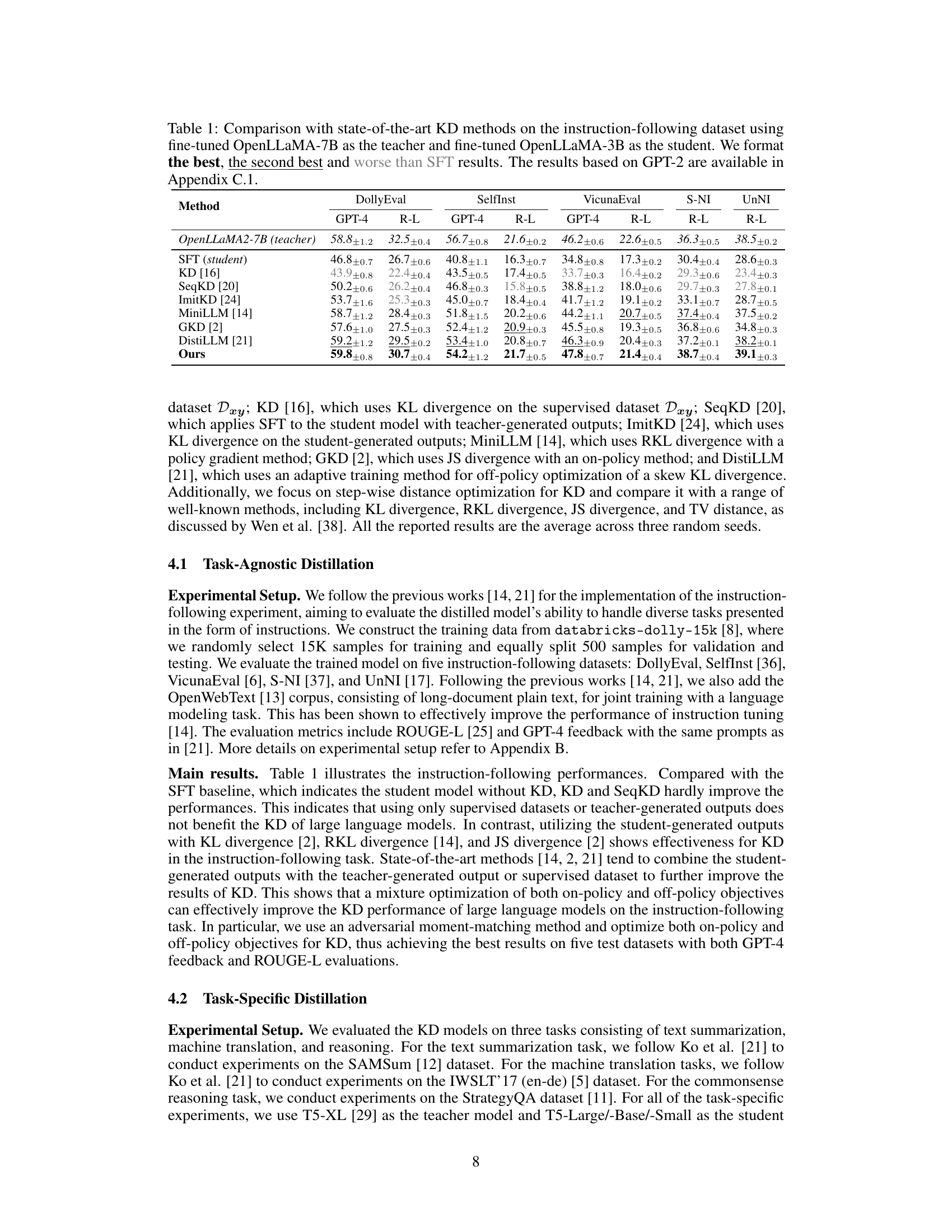
🔼 This figure compares different approaches for knowledge distillation in large language models. It contrasts distribution-matching-based distillation (minimizing KL, RKL, TV distance between teacher and student probability distributions) with the proposed action-value moment-matching distillation. The latter approach focuses on matching the action-value moments of the teacher’s policy from both on-policy (student-generated data) and off-policy (teacher-generated data) perspectives, aiming for better knowledge transfer.
read the caption
Figure 1: The comparison between the distribution-matching-based distillation and the action-value moment-matching distillation is outlined. πθ and π* denote the student policy and the teacher policy, respectively. For both on-policy (using student-generated outputs) and off-policy (using teacher-generated outputs) perspectives, our approach optimizes moment-matching of action-value functions (Q-functions) instead of minimizing the distribution distance measured by M = KL, RKL, TV, etc.
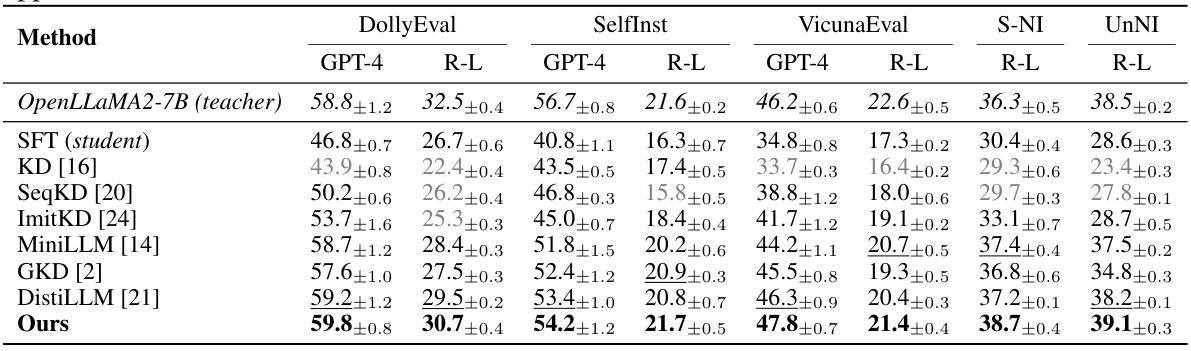
🔼 This table compares the performance of different knowledge distillation (KD) methods on an instruction-following task. It uses a fine-tuned OpenLLaMA-7B model as the teacher and a fine-tuned OpenLLaMA-3B model as the student. The results are evaluated using two metrics: GPT-4 and R-L, with the best, second-best, and worse-than-SFT results highlighted for clarity. Additional results using GPT-2 are included in Appendix C.1.
read the caption
Table 1: Comparison with state-of-the-art KD methods on the instruction-following dataset using fine-tuned OpenLLaMA-7B as the teacher and fine-tuned OpenLLaMA-3B as the student. We format the best, the second best and worse than SFT results. The results based on GPT-2 are available in Appendix C.1.
In-depth insights#
Adversarial Distillation#
Adversarial distillation, in the context of large language models (LLMs), presents a novel approach to knowledge transfer. It leverages an adversarial framework where a student model learns to mimic a teacher model’s behavior, not by directly minimizing a discrepancy metric between probability distributions (like typical distillation), but by strategically matching action-value moments. This moment-matching is achieved through an adversarial training process pitting the student against an adversary that aims to maximize their difference. The result is a more robust and generalized student model, capturing nuanced aspects of the teacher’s behavior that are not reflected in simple distribution alignment. This method potentially addresses the limitations of traditional behavior cloning in KD, offering a more sophisticated approach to knowledge distillation in LLMs and potentially improving generalization on downstream tasks.
Moment Matching#
The concept of “Moment Matching” in the context of knowledge distillation for large language models (LLMs) presents a novel approach to bridge the performance gap between teacher and student models. Instead of directly minimizing the distance between probability distributions (a common strategy), moment matching focuses on aligning the action-value moments of the teacher’s behavior. This is achieved by jointly estimating the moment-matching distance, using an adversarial training algorithm to minimize it and optimize the student policy simultaneously from both on and off-policy perspectives. This approach is theoretically sound, drawing connections to imitation learning and reinforcement learning, providing an upper bound for the imitation gap in terms of step-wise TV distance. Empirically, the method demonstrably outperforms standard distribution matching techniques, achieving state-of-the-art results on both instruction-following and task-specific benchmarks. The use of on- and off-policy data allows for a robust and effective distillation process, capturing a richer representation of the teacher’s knowledge than simple behavioral cloning.
RL in Text Gen#
Reinforcement learning (RL) offers a powerful framework for text generation by framing the task as a sequential decision-making process. Each token prediction becomes an action, guided by the current sequence (state), aiming to maximize a cumulative reward reflecting text quality. This approach moves beyond simple likelihood maximization, allowing for more nuanced control over generated text characteristics, such as coherence and relevance. Early RL methods for text generation, like SeqGAN, employed adversarial training; however, this often suffered from instability. More recent methods leverage techniques like policy gradients and reward shaping for improved stability and performance. A key challenge lies in defining an effective reward function that accurately captures desired text properties. Approaches that leverage human feedback or learn reward functions from large language models show promise in addressing this. RL in text generation is an active area of research, with ongoing exploration of more robust algorithms and reward models to create high-quality, coherent text. The integration of RL with other techniques, such as knowledge distillation, also offers exciting potential for improving both efficiency and performance.
Imitation Learning#
Imitation learning, in the context of large language models (LLMs), presents a powerful paradigm shift from traditional knowledge distillation methods. Instead of explicitly matching probability distributions between teacher and student models, imitation learning focuses on replicating the teacher’s behavior, emphasizing the action-value moments rather than merely mimicking output distributions. This subtle yet profound difference allows for a more nuanced transfer of knowledge, capturing not just the what, but also the why behind a teacher model’s decisions. The effectiveness of this approach rests on carefully balancing both on- and off-policy learning. On-policy learning utilizes the student’s own generated outputs, while off-policy leverages the teacher’s outputs. By combining these perspectives, imitation learning mitigates the limitations of solely relying on distribution matching, leading to improved generalization and potentially better performance in diverse tasks. The adversarial training strategy further enhances this process, jointly optimizing the moment-matching distance and student policy for superior results. This approach offers a promising avenue for more efficient and effective LLM training by concentrating on high-level behavioral imitation instead of low-level output alignment.
KD Limitations#
Knowledge distillation (KD) methods, while effective in compressing large language models (LLMs), face limitations. Distribution-matching approaches, focusing on minimizing the distance between teacher and student probability distributions, often fail to capture the nuances of language knowledge. This leads to suboptimal generalization in student models, which is a major limitation. Behavior cloning, a common strategy in KD, simply mimics teacher behavior and may not fully encapsulate the underlying linguistic capabilities. Additionally, the lack of a universally accepted definition of output quality makes it difficult to definitively evaluate KD success. Data requirements can also be a significant constraint; KD’s effectiveness depends heavily on the quality and quantity of training data, making it unsuitable for certain low-resource scenarios. Finally, many existing methods struggle to combine the benefits of both on-policy and off-policy training efficiently. Overcoming these challenges would significantly improve the capabilities and applicability of KD techniques for LLMs.
More visual insights#
More on figures
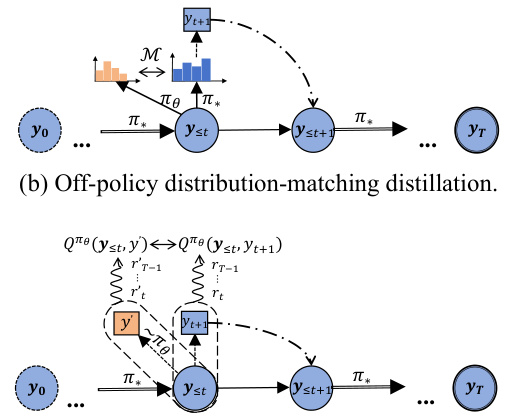
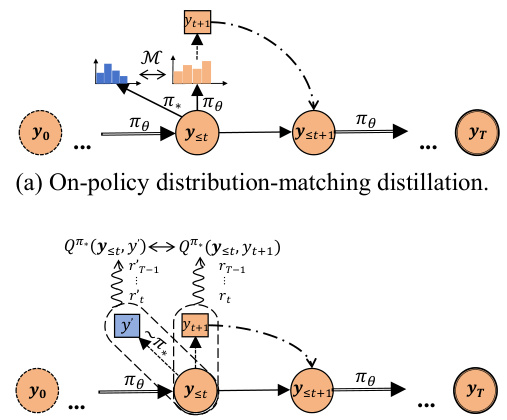
🔼 This figure compares the proposed action-value moment-matching distillation method to existing distribution-matching methods for knowledge distillation of large language models. It illustrates the differences in how the student policy learns from the teacher policy (both on-policy, where the student generates its own outputs, and off-policy, where the teacher generates the outputs) by comparing the optimization of probability distribution distances (KL, RKL, TV) with moment-matching of action-value functions.
read the caption
Figure 1: The comparison between the distribution-matching-based distillation and the action-value moment-matching distillation is outlined. πθ and π* denote the student policy and the teacher policy, respectively. For both on-policy (using student-generated outputs) and off-policy (using teacher-generated outputs) perspectives, our approach optimizes moment-matching of action-value functions (Q-functions) instead of minimizing the distribution distance measured by M = KL, RKL, TV, etc.
🔼 This figure compares four different approaches to knowledge distillation of large language models. The top two diagrams illustrate traditional distribution-matching methods (on-policy and off-policy), which attempt to align the probability distributions of the teacher and student models. The bottom two diagrams show the proposed action-value moment-matching method, which focuses on aligning the moments of the action-value functions, offering a potentially more robust and effective approach to knowledge transfer. The use of both on-policy and off-policy perspectives is highlighted as a key aspect of the proposed method.
read the caption
Figure 1: The comparison between the distribution-matching-based distillation and the action-value moment-matching distillation is outlined. πθ and π* denote the student policy and the teacher policy, respectively. For both on-policy (using student-generated outputs) and off-policy (using teacher-generated outputs) perspectives, our approach optimizes moment-matching of action-value functions (Q-functions) instead of minimizing the distribution distance measured by M = KL, RKL, TV, etc.

🔼 This figure compares four different distillation methods: on-policy and off-policy distribution matching, and on-policy and off-policy action-value moment matching. The on-policy methods utilize student-generated outputs for training, while off-policy methods use teacher-generated outputs. The key difference is that moment matching focuses on aligning the action-value functions (Q-functions) which measure the quality of decisions, instead of directly minimizing the distance between probability distributions of teacher and student predictions.
read the caption
Figure 1: The comparison between the distribution-matching-based distillation and the action-value moment-matching distillation is outlined. πθ and π* denote the student policy and the teacher policy, respectively. For both on-policy (using student-generated outputs) and off-policy (using teacher-generated outputs) perspectives, our approach optimizes moment-matching of action-value functions (Q-functions) instead of minimizing the distribution distance measured by M = KL, RKL, TV, etc.

🔼 This figure compares four different distillation methods: on-policy distribution matching, off-policy distribution matching, on-policy Q-value moment matching, and off-policy Q-value moment matching. It highlights the key difference between distribution-matching approaches (which minimize distances like KL divergence) and the proposed moment-matching approach (which focuses on aligning the action-value moments of the teacher and student policies). The diagram uses visual representations of policies (πθ, π*) and Q-functions to illustrate the differences.
read the caption
Figure 1: The comparison between the distribution-matching-based distillation and the action-value moment-matching distillation is outlined. πθ and π* denote the student policy and the teacher policy, respectively. For both on-policy (using student-generated outputs) and off-policy (using teacher-generated outputs) perspectives, our approach optimizes moment-matching of action-value functions (Q-functions) instead of minimizing the distribution distance measured by M = KL, RKL, TV, etc.

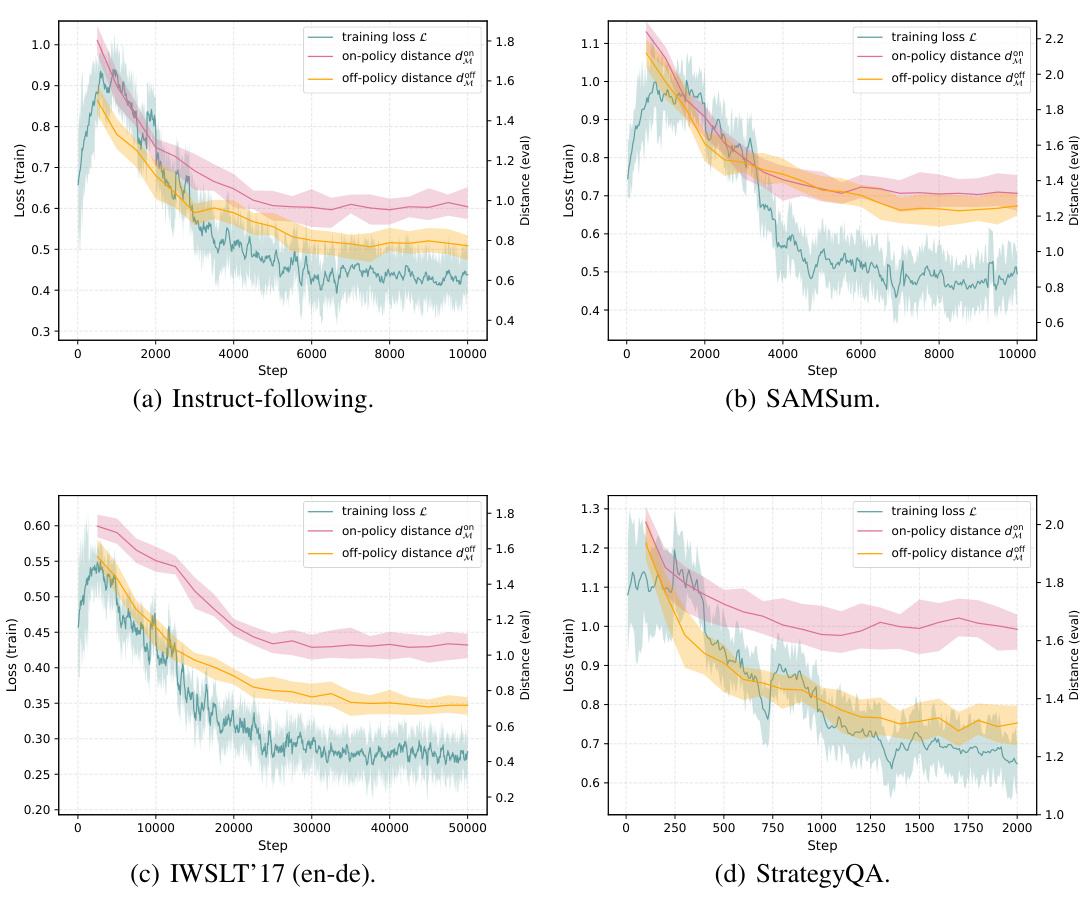
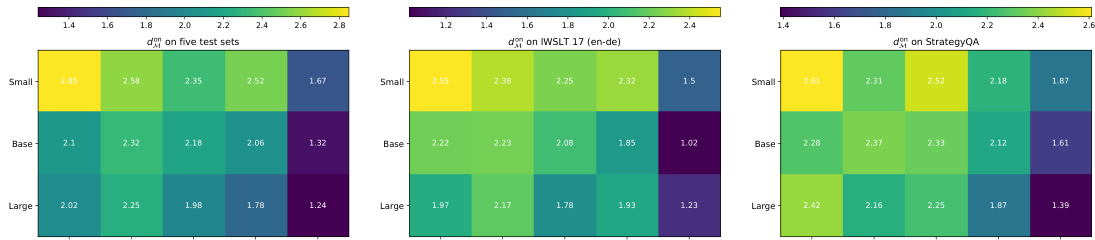
🔼 This figure shows the results of the adversarial training procedure. The leftmost graph shows the training loss and the moment-matching distances against the training steps. The other two graphs show the on-policy and off-policy moment-matching distances on the test sets. The results demonstrate that the adversarial training effectively optimizes both the on-policy and off-policy moment-matching distances, leading to improved performance.
read the caption
Figure 3: Adversarial training procedure for optimizing the on-policy and off-policy moment-matching distances dMM, dMM against training step.
🔼 This figure compares the proposed action-value moment-matching distillation method with traditional distribution matching methods for knowledge distillation in large language models. It illustrates the different approaches for both on-policy (using student-generated data) and off-policy (using teacher-generated data) scenarios. The key difference is that the proposed method matches the moments of the action-value functions (Q-functions), rather than directly minimizing the distance between probability distributions.
read the caption
Figure 1: The comparison between the distribution-matching-based distillation and the action-value moment-matching distillation is outlined. πθ and π* denote the student policy and the teacher policy, respectively. For both on-policy (using student-generated outputs) and off-policy (using teacher-generated outputs) perspectives, our approach optimizes moment-matching of action-value functions (Q-functions) instead of minimizing the distribution distance measured by M = KL, RKL, TV, etc.

🔼 This figure compares four different distillation methods: on-policy and off-policy distribution matching, and on-policy and off-policy Q-value moment matching. Distribution matching methods attempt to minimize the distance between the probability distributions of teacher and student model outputs. In contrast, the proposed method (Q-value moment matching) focuses on matching the moments of the action-value functions, representing the quality of token-level predictions, rather than directly comparing the distributions.
read the caption
Figure 1: The comparison between the distribution-matching-based distillation and the action-value moment-matching distillation is outlined. πθ and π* denote the student policy and the teacher policy, respectively. For both on-policy (using student-generated outputs) and off-policy (using teacher-generated outputs) perspectives, our approach optimizes moment-matching of action-value functions (Q-functions) instead of minimizing the distribution distance measured by M = KL, RKL, TV, etc.
🔼 This figure compares four different distillation methods: on-policy and off-policy distribution matching, and on-policy and off-policy Q-value moment matching. The on-policy methods use student-generated outputs, while the off-policy methods use teacher-generated outputs. The moment-matching approach, proposed by the authors, focuses on aligning the action-value moments instead of probability distributions, aiming to better capture the teacher’s knowledge.
read the caption
Figure 1: The comparison between the distribution-matching-based distillation and the action-value moment-matching distillation is outlined. πθ and π* denote the student policy and the teacher policy, respectively. For both on-policy (using student-generated outputs) and off-policy (using teacher-generated outputs) perspectives, our approach optimizes moment-matching of action-value functions (Q-functions) instead of minimizing the distribution distance measured by M = KL, RKL, TV, etc.

🔼 This figure compares four different distillation methods: on-policy and off-policy distribution matching, and on-policy and off-policy Q-value moment matching. The figure illustrates how the proposed moment-matching method differs from traditional distribution matching methods by focusing on aligning action-value moments rather than probability distributions. The teacher and student policies (π* and πθ, respectively) are highlighted to show the flow of information in each method.
read the caption
Figure 1: The comparison between the distribution-matching-based distillation and the action-value moment-matching distillation is outlined. πθ and π* denote the student policy and the teacher policy, respectively. For both on-policy (using student-generated outputs) and off-policy (using teacher-generated outputs) perspectives, our approach optimizes moment-matching of action-value functions (Q-functions) instead of minimizing the distribution distance measured by M = KL, RKL, TV, etc.
More on tables

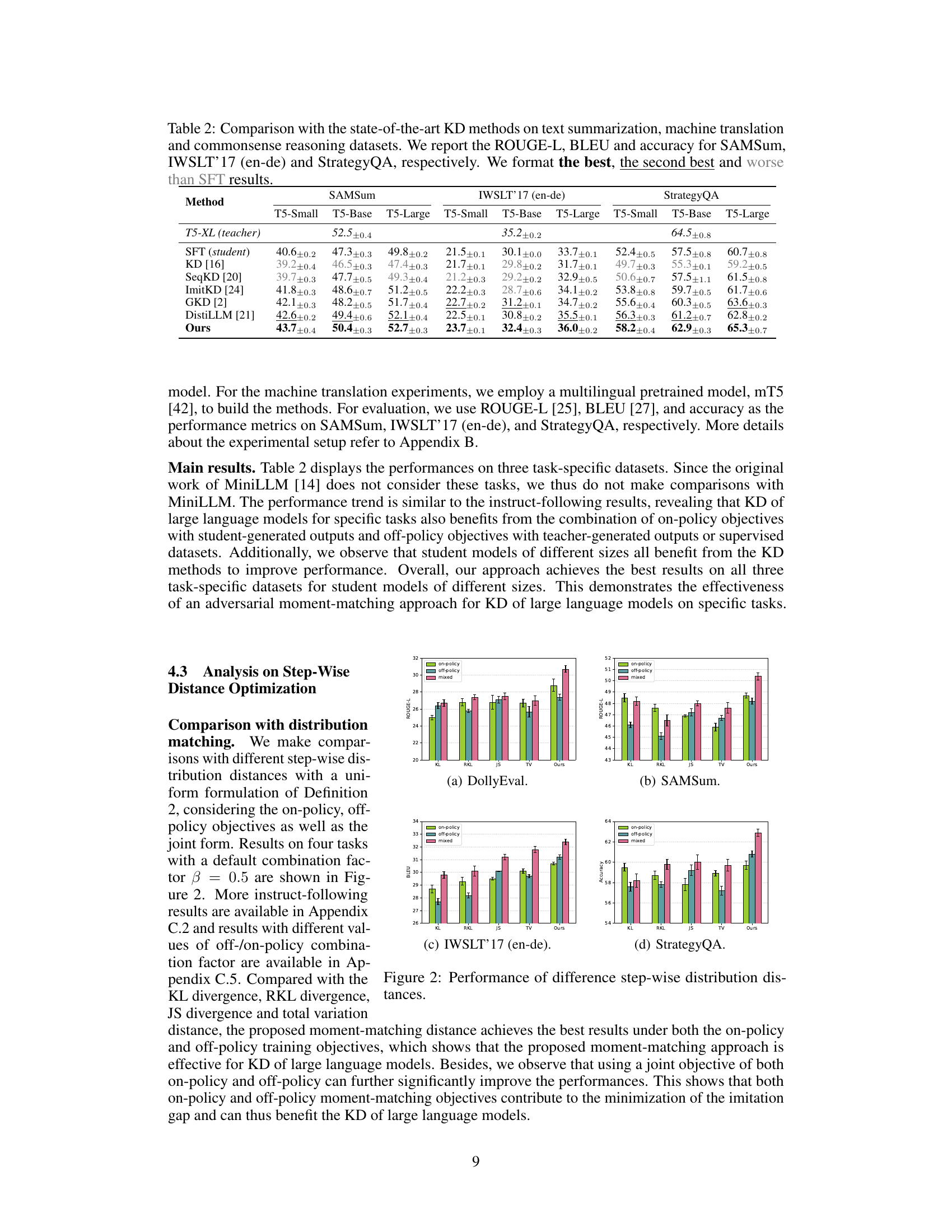
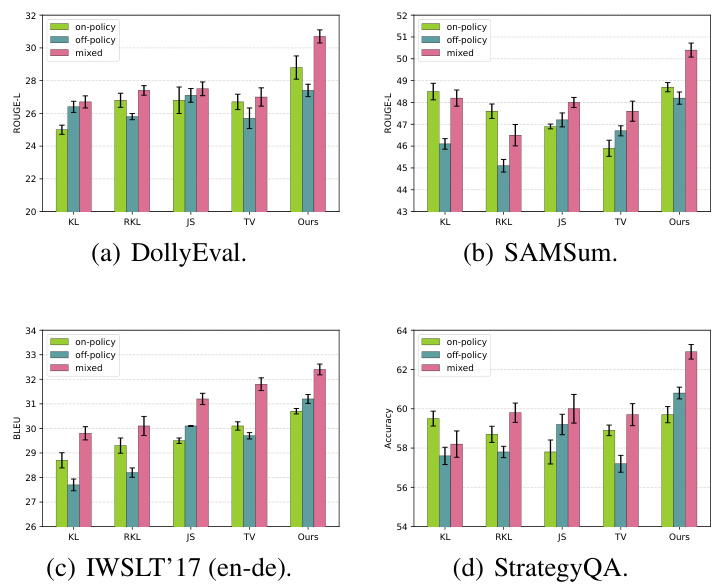
🔼 This table compares the performance of the proposed adversarial moment-matching distillation method against other state-of-the-art knowledge distillation methods on three different downstream tasks: text summarization (SAMSum dataset), machine translation (IWSLT'17 en-de dataset), and commonsense reasoning (StrategyQA dataset). The results are broken down by the size of the student model (T5-Small, T5-Base, T5-Large) and show ROUGE-L scores for summarization, BLEU scores for machine translation, and accuracy scores for commonsense reasoning. The table highlights the best, second best, and results that are worse than simply fine-tuning the student model (SFT).
read the caption
Table 2: Comparison with the state-of-the-art KD methods on text summarization, machine translation and commonsense reasoning datasets. We report the ROUGE-L, BLEU and accuracy for SAMSum, IWSLT'17 (en-de) and StrategyQA, respectively. We format the best, the second best and worse than SFT results.
🔼 This table compares the performance of the proposed adversarial moment-matching distillation method against several state-of-the-art knowledge distillation techniques on an instruction-following dataset. The teacher model is a fine-tuned OpenLLaMA-7B, and the student model is a fine-tuned OpenLLaMA-3B. The table highlights the best, second-best, and worse-than-SFT (supervised fine-tuning) results for each method across various evaluation metrics. Additional results using GPT-2 are provided in the appendix.
read the caption
Table 1: Comparison with state-of-the-art KD methods on the instruction-following dataset using fine-tuned OpenLLaMA-7B as the teacher and fine-tuned OpenLLaMA-3B as the student. We format the best, the second best and worse than SFT results. The results based on GPT-2 are available in Appendix C.1.

🔼 This table compares the performance of the proposed adversarial moment-matching distillation method against several state-of-the-art knowledge distillation methods on an instruction-following task. The teacher model is a fine-tuned OpenLLaMA-7B, and the student model is a fine-tuned OpenLLaMA-3B. The table highlights the best performing method for each metric across different evaluation criteria and notes which methods perform better or worse than standard supervised fine-tuning (SFT). Additional results using GPT-2 are available in the appendix.
read the caption
Table 1: Comparison with state-of-the-art KD methods on the instruction-following dataset using fine-tuned OpenLLaMA-7B as the teacher and fine-tuned OpenLLaMA-3B as the student. We format the best, the second best and worse than SFT results. The results based on GPT-2 are available in Appendix C.1.

🔼 This table compares the performance of the proposed adversarial moment-matching knowledge distillation method against several state-of-the-art methods on an instruction-following task. The teacher model is OpenLLaMA-7B, and the student model is OpenLLaMA-3B. Results are shown for multiple evaluation metrics (DollyEval, SelfInst, VicunaEval, S-NI, UnNI) and using different evaluation methods (GPT-4, R-L). The table highlights the best performing method for each metric.
read the caption
Table 1: Comparison with state-of-the-art KD methods on the instruction-following dataset using fine-tuned OpenLLaMA-7B as the teacher and fine-tuned OpenLLaMA-3B as the student. We format the best, the second best and worse than SFT results. The results based on GPT-2 are available in Appendix C.1.
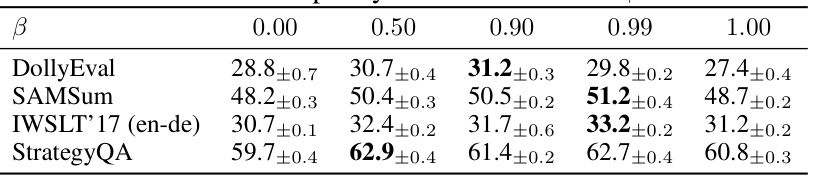
🔼 This table shows the performance of the model on four different datasets (DollyEval, SAMSum, IWSLT'17 (en-de), StrategyQA) using different values for the off-/on-policy combination factor β. The results demonstrate how varying the balance between on-policy and off-policy learning affects performance on different downstream tasks. The best results for each dataset are highlighted in bold.
read the caption
Table 6: Effects of the off-/on-policy combination factor β on four datasets.
Full paper#