↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current large-scale dataset distillation methods suffer from excessive storage needs for auxiliary soft labels. This is mainly due to high within-class similarity of synthesized images, resulting from batching samples across classes. This paper reveals that large-scale soft labels are not always necessary and investigates ways to reduce them.
This paper proposes Label Pruning for Large-scale Distillation (LPLD), addressing the issue by introducing class-wise supervision during image synthesis. By batching samples within classes, LPLD enhances within-class diversity, enabling effective soft label compression using simple random pruning. Experimental results show significant reductions in soft label storage and performance gains, demonstrating that achieving ImageNet-level dataset condensation with minimal soft labels is feasible.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in dataset distillation. It challenges the existing large-scale soft label requirement, significantly reducing storage needs while improving performance. This opens up new avenues for efficient large-scale dataset distillation and its application in computationally intensive tasks such as neural architecture search.
Visual Insights#
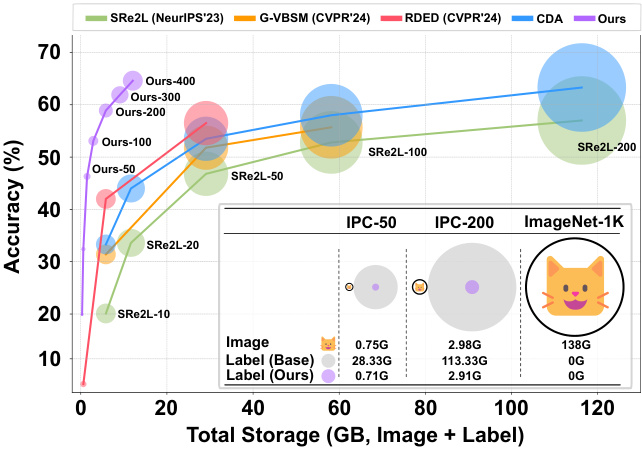
This figure shows the relationship between the model’s accuracy and the total storage space required for both the condensed dataset images and the auxiliary soft labels. It compares the performance of several state-of-the-art (SOTA) methods, including SRe2L, G-VBSM, RDED, CDA, and the proposed method. The x-axis represents the total storage size (in GB), and the y-axis represents the accuracy achieved. The figure demonstrates that the proposed method achieves superior performance with significantly less storage compared to the other methods, particularly in terms of reduced soft label requirements.

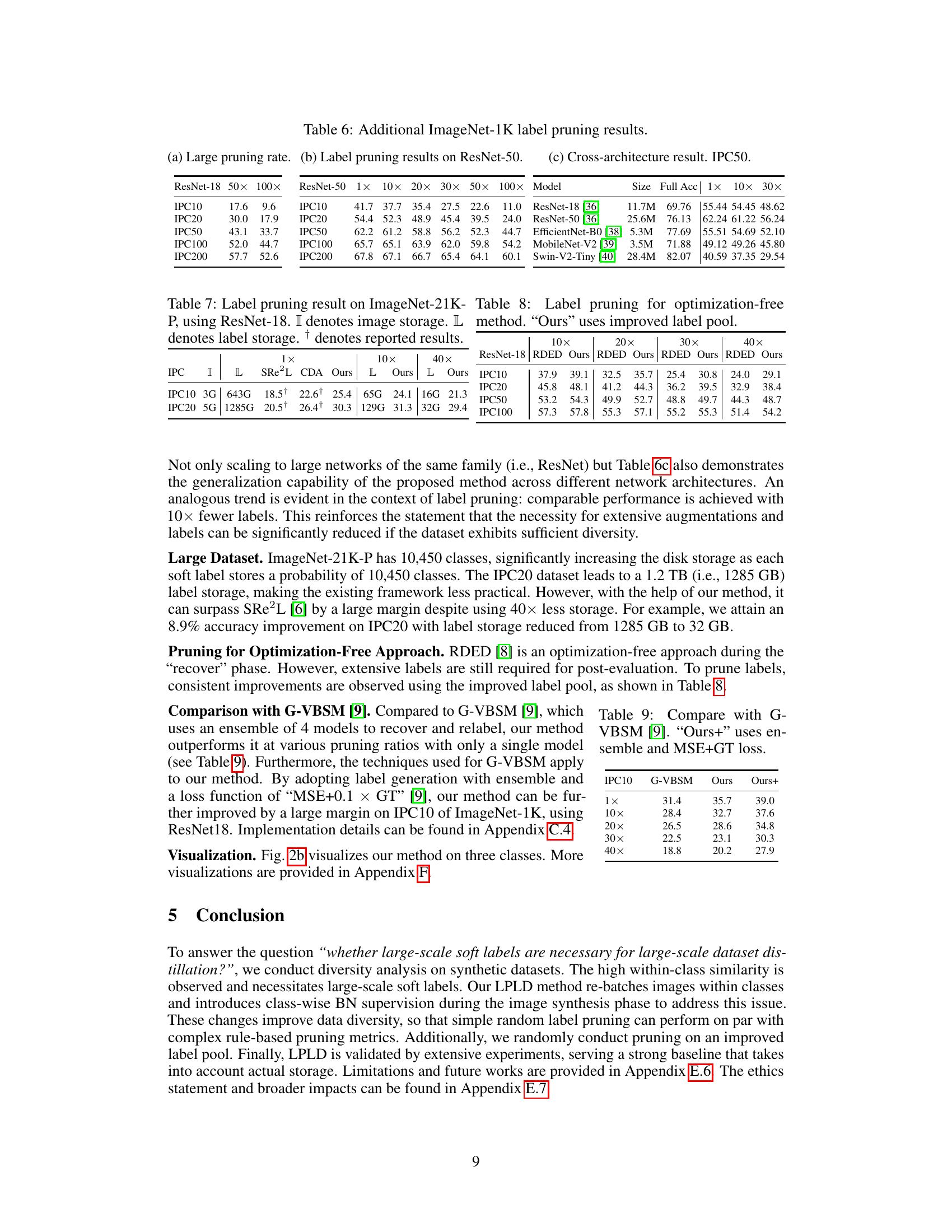
This table presents the results of label pruning experiments conducted on the Tiny-ImageNet dataset. It compares the performance of the proposed method against state-of-the-art (SOTA) methods (SRe2L and CDA) across various pruning ratios (1x, 10x, 20x, 30x, 40x) and image-per-class (IPC) values (50 and 100). The performance is measured in terms of accuracy, and standard deviations are reported to reflect the variability across different runs of the experiments. Results marked with † indicate previously reported values from other works. The table showcases the effectiveness of the proposed label pruning technique in achieving competitive accuracy levels while using significantly fewer soft labels compared to existing approaches.
In-depth insights#
Soft Label Pruning#
The concept of ‘soft label pruning’ presents a novel approach to optimizing large-scale dataset distillation. Traditional methods rely on extensive soft labels, significantly increasing storage demands. Soft label pruning directly addresses this issue by strategically reducing the number of soft labels required for effective training. This is achieved by improving the diversity of the condensed dataset during synthesis, reducing the reliance on massive augmentation to distinguish similar data points. A key finding is that high within-class similarity necessitates large-scale soft labels. By introducing class-wise supervision during image synthesis, the authors successfully demonstrate that simple random pruning becomes effective, significantly reducing storage requirements. The method achieves a compression rate of 40x while improving performance, highlighting the potential for efficient large-scale dataset distillation using this novel technique.
Class-wise Supervision#
The concept of “Class-wise Supervision” in the context of large-scale dataset distillation offers a compelling approach to address the limitations of existing methods. Traditional techniques often suffer from high within-class similarity in synthesized datasets, necessitating the use of extensive soft labels for effective supervision. Class-wise supervision directly tackles this issue by modifying the data synthesis process. Instead of creating batches containing samples from multiple classes, samples are batched within classes. This crucial change increases within-class diversity and, as a result, reduces the size of required soft labels. The inherent independence of different classes further enhances the effectiveness of this method. Moreover, the improved image diversity simplifies the soft label compression task, allowing for a straightforward approach like simple random pruning, eliminating the need for more complex rule-based techniques. By improving the diversity of training data and reducing the need for excessively large soft labels, class-wise supervision improves efficiency and offers a significant advancement in large-scale dataset distillation.
Diversity’s Role#
The concept of “Diversity’s Role” in the context of a research paper likely explores how the variety of data, methods, or perspectives influences the outcome. A thoughtful analysis would reveal crucial insights. For instance, data diversity is paramount; if a model is trained solely on homogeneous data, it may fail to generalize to unseen scenarios. Methodological diversity is also critical, as a single approach might overlook subtle nuances. Exploring multiple methods can enhance robustness and provide a more comprehensive understanding. Finally, perspective diversity is essential in acknowledging potential biases and limitations within the research itself. A lack of diversity in any of these three areas may lead to flawed conclusions or limited applicability. Therefore, a strong research paper would meticulously address diversity in data, methods, and interpretations to draw reliable and impactful conclusions.
Scaling Distillation#
Scaling distillation in deep learning focuses on efficiently training models on massive datasets. Current methods often struggle with memory limitations when dealing with large-scale datasets, like ImageNet. A key challenge is managing the auxiliary data, such as soft labels, which can be significantly larger than the condensed dataset itself. Innovative approaches leverage techniques like label pruning and class-wise supervision to reduce the size of auxiliary data while maintaining model accuracy. This involves strategically selecting or generating a subset of labels and images that are more diverse and representative of the original dataset. Efficient techniques to synthesize diverse images are crucial, reducing the need for extensive memory during the training process. The research in this area explores the trade-off between model performance, computational resources, and the size of auxiliary data, aiming to scale distillation to even larger datasets while minimizing memory usage and maintaining or improving the model’s efficacy.
Future of LPLD#
The future of LPLD (Label Pruning for Large-scale Distillation) appears bright, given its demonstrated success in compressing soft labels while maintaining, and even improving, model performance. Further research should focus on extending LPLD’s applicability to even larger datasets and exploring the interaction between various pruning strategies and their impact on downstream tasks. Investigating adaptive pruning methods, where label importance is dynamically assessed, is key. Exploring alternative label representations beyond soft labels could potentially lead to even greater compression ratios. A thorough investigation into the theoretical limits of label pruning is also warranted, providing deeper insights into the fundamental relationship between data diversity and label redundancy. Finally, exploring the potential for LPLD to enhance other model compression techniques, such as quantization and pruning, should be a major area of interest. By addressing these future directions, LPLD can become a pivotal tool for efficient and effective large-scale model training.
More visual insights#
More on figures

This figure compares the visual diversity of synthetic images generated by the SRe²L method and the proposed LPLD method. Three classes are shown: hammer shark, pineapple, and pomegranate. Each class has multiple generated images displayed. The figure highlights that the LPLD method generates images with noticeably greater within-class diversity compared to SRe²L.
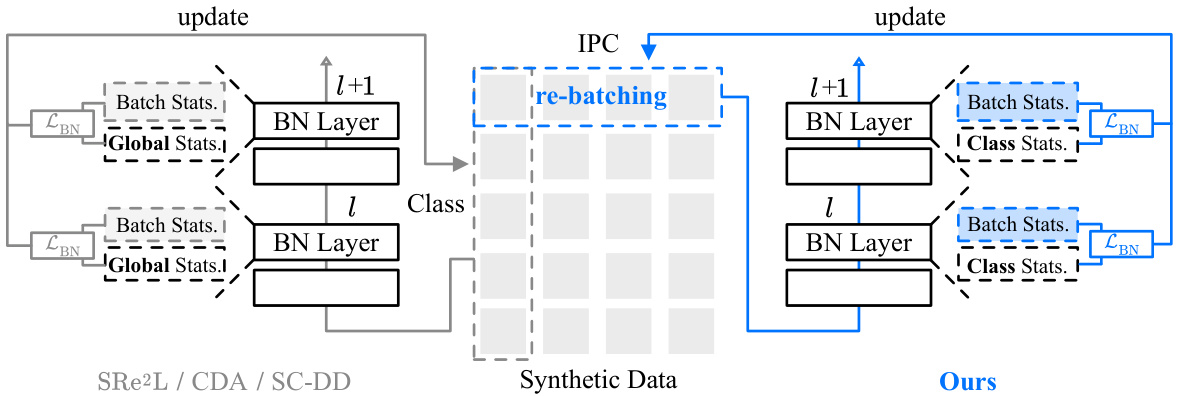
This figure compares the existing dataset distillation methods (SRe2L, CDA, SC-DD) with the proposed method (Ours) in terms of how synthetic images are generated and updated. Existing methods independently generate images per class, leading to high within-class similarity. In contrast, the proposed method re-batches images within the same class before generating them. This promotes collaboration among images of the same class, increasing within-class diversity. Additionally, the proposed method introduces class-wise supervision during the image synthesis process. The classification loss is omitted for simplicity in this illustration.

This figure illustrates the two-stage random pruning strategy used in the Label Pruning for Large-scale Distillation (LPLD) method. First, the soft labels are pruned at the epoch level and the batch level to create a diverse and smaller pool. Then, a random subset of this label pool is selected for training each epoch. This helps manage memory constraints and enhance the diversity of training data.

This figure shows the relationship between the model’s performance (accuracy) and the total storage required for both the images in the condensed dataset and the auxiliary soft labels. Different methods for dataset distillation are compared, demonstrating that the proposed method achieves state-of-the-art (SOTA) performance while requiring significantly less storage for soft labels compared to the size of the condensed image dataset itself. This highlights the effectiveness of the proposed label pruning technique in reducing storage needs without sacrificing accuracy.

This figure shows randomly sampled images from the Tiny-ImageNet dataset. Two subfigures are presented, one for IPC50 (Images Per Class = 50) and another for IPC100 (Images Per Class = 100). Each subfigure displays a grid of synthesized images generated by the proposed method for dataset distillation. The visualization helps illustrate the within-class diversity achieved by the method in generating synthetic images.

This figure visualizes a random sample of images from the ImageNet-21K-P dataset at two different Images Per Class (IPC) values: 10 and 20. The images are generated using the proposed Label Pruning for Large-scale Distillation (LPLD) method. The visualization demonstrates the visual diversity achieved by LPLD, which is a key aspect of their method’s success in reducing soft label storage.
More on tables

This table presents the results of label pruning experiments conducted on the Tiny-ImageNet dataset. It compares the performance of three different methods (SRe2L, CDA, and the proposed ‘Ours’) across various pruning ratios (1x, 10x, 20x, 30x, 40x) and images-per-class (IPC) values (50 and 100). The standard deviation is calculated from three separate runs for each configuration, indicating the variability of the results. The symbol † denotes results reported in other papers. The table helps to demonstrate the effectiveness of the proposed label pruning method in achieving comparable or better performance compared to existing methods while significantly reducing the required soft labels storage.

This table presents the results of label pruning experiments conducted on the ImageNet-1K dataset using ResNet-18 as the validation model. The table compares the performance of the proposed method against existing state-of-the-art (SOTA) methods (SRe2L and CDA) across different image-per-class (IPC) settings and various pruning ratios (1x, 10x, 20x, 30x, 40x). The results demonstrate the consistent superior performance of the proposed method, even with significantly fewer labels.
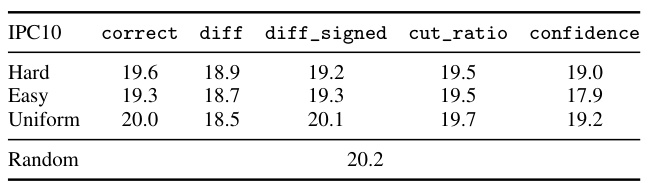
This table compares the performance of different label pruning methods on the ImageNet-1K dataset with an Images Per Class (IPC) of 10, using the ResNet-18 model for validation. The methods compared include pruning based on different metrics (‘correct’, ‘diff’, ‘diff_signed’, ‘cut_ratio’, ‘confidence’) and random pruning. The table shows the average accuracy for each method, providing insights into the effectiveness of different pruning strategies. The ‘correct’ metric focuses on the accuracy of the correctly classified images and is calculated based on the top 2 predictions. The ‘diff’ and ‘diff_signed’ metrics use the absolute and signed difference between the top 2 predictions respectively, intending to identify labels with high uncertainty. The ‘cut_ratio’ metric captures the mixup ratio, and the ‘confidence’ metric reflects the prediction confidence.

This table presents the results of an ablation study comparing different label pruning methods on the ImageNet-1K dataset with an IPC of 10. The methods compared include random pruning and several other pruning strategies (indicated by ‘Easy’ and ‘Hard’ columns, which refer to the label pruning strategies targeting easy or hard samples respectively) with different pruning ratios (20x, 30x, 50x, 100x). The results are validated using the ResNet-18 model and show the impact of different pruning strategies and ratios on model performance. The table demonstrates that simple random pruning is comparable to more sophisticated methods.
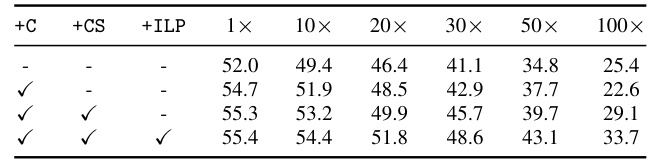
This table presents the ablation study of the proposed method, showing the impact of class-wise matching (+C), class-wise supervision (+CS), and the improved label pool (+ILP) on the performance at different pruning ratios (1x, 10x, 20x, 30x, 50x, 100x) using ResNet18 on ImageNet-1K with IPC50. Each row represents a different combination of these components, allowing for the isolation and evaluation of their individual effects.

This table presents the results of label pruning experiments on the Tiny-ImageNet dataset. It compares the performance of the proposed method against state-of-the-art (SOTA) methods (SRe2L and CDA) across various network architectures (ResNet-18, ResNet-50, ResNet-101) and different pruning ratios (1x, 10x, 20x, 30x, 40x). The results are averaged over three different runs, and the standard deviation is reported to provide a measure of variability. The symbol † indicates results reported by other researchers for comparison.

This table presents the results of label pruning experiments conducted on the Tiny-ImageNet dataset. It compares the performance of three different methods (SRe2L, CDA, and the proposed ‘Ours’ method) across various pruning ratios (1x, 10x, 20x, 30x, 40x) and image-per-class (IPC) values (50 and 100). The performance is measured in terms of accuracy. The table shows that the proposed method consistently outperforms the other two methods, especially at higher pruning ratios, demonstrating its effectiveness in reducing the storage requirements for soft labels.
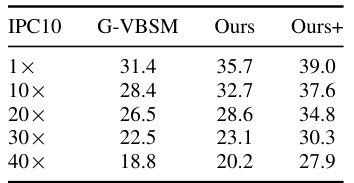
This table compares the performance of the proposed method with G-VBSM [9] on the ImageNet-1K dataset using ResNet-18 at different pruning ratios (1x, 10x, 20x, 30x, 40x). The ‘Ours+’ column represents an enhanced version of the proposed method that incorporates ensemble learning and a modified loss function (MSE+GT). The results show that even with a simple implementation, the proposed method outperforms G-VBSM across all pruning ratios. The significant gains shown in the ‘Ours+’ column demonstrate the potential of further optimization by incorporating techniques from other advanced methods.

This table shows the number of total images, batch size, the number of BN updates during the squeezing phase, and the source of the pretrained model used for ImageNet-1K experiments. The information is crucial for understanding the preprocessing steps and setting up the experiment.

This table describes the hyperparameters and settings used during the data synthesis phase for ImageNet-1K in the experiment. It includes the number of iterations, the optimizer used (Adam), learning rates for images, batch size (which is dependent on the images per class), initialization method, and the weight of the batch normalization loss.

This table details the hyperparameters used in the relabeling and validation phases of the ImageNet-1K experiments. It includes the number of epochs, optimizer used (AdamW), model learning rate, batch size, scheduler (CosineAnnealing), EMA rate (not used), and augmentations applied (RandomResizedCrop, RandomHorizontalFlip, CutMix) along with their respective parameters.
This table shows the details of the squeezing phase for the Tiny-ImageNet dataset. It provides the total number of images, batch size used, the number of BN updates performed, and the source of the dataset.
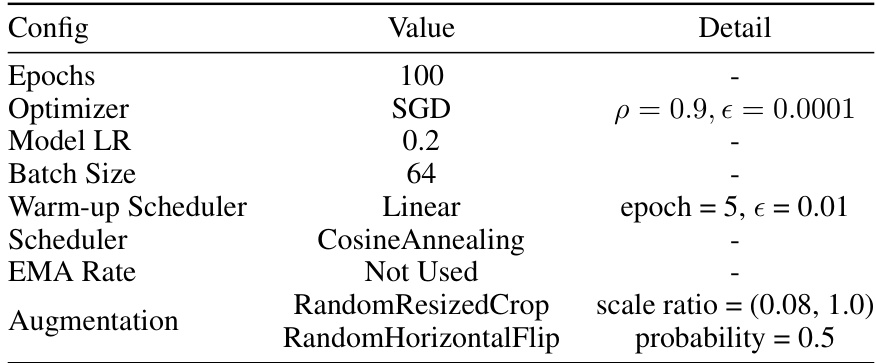
This table details the hyperparameters used in the relabeling and validation phases for the Tiny-ImageNet dataset. It specifies the number of epochs, optimizer used (SGD), model learning rate, batch size, warm-up scheduler details, overall scheduler (Cosine Annealing), EMA rate, and augmentations applied (RandomResizedCrop and RandomHorizontalFlip) along with their parameters. These settings are crucial for understanding how the synthetic Tiny-ImageNet dataset was refined and evaluated.
This table presents the results of label pruning experiments on the ImageNet-1K dataset using ResNet-18 as the validation model. It compares the performance of the proposed method against state-of-the-art (SOTA) methods (SRe2L and CDA) across different image-per-class (IPC) settings and various pruning ratios (1x, 10x, 20x, 30x, 40x). The table shows that the proposed method consistently outperforms SOTA methods, achieving better accuracy with significantly fewer soft labels.

This table presents the results of an ablation study conducted to evaluate the impact of different components of the proposed method on the model’s performance. The study varied the inclusion of class-wise matching (+C), class-wise supervision (+CS), and an improved label pool (+ILP). The results are shown for different label pruning ratios (1x, 10x, 20x, 30x, 50x, 100x) using the ResNet18 model on the ImageNet-1K dataset with Images Per Class (IPC) set to 50. Each row represents a different combination of the components, allowing for the assessment of their individual and combined effects on model accuracy.

This table shows the scalability of the proposed method with large IPCs (Images Per Class). It demonstrates the total storage (in GB) for images and labels at different pruning ratios (1x, 30x, 40x). The results are presented for IPC300 and IPC400, showing that the method maintains good accuracy even with significantly reduced storage.
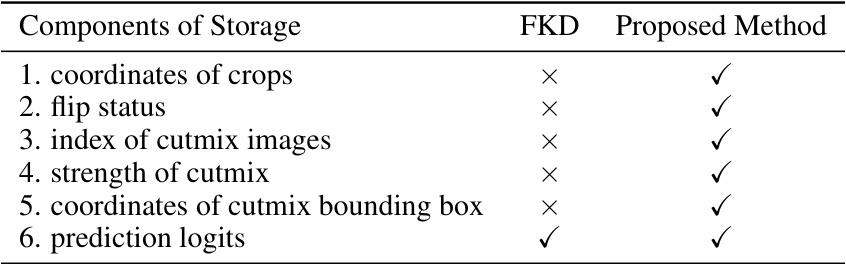
This table compares the storage requirements for different components between the Fast Knowledge Distillation (FKD) method and the proposed Label Pruning for Large-scale Distillation (LPLD) method. It highlights that FKD, in its original model distillation context, only needs to store components related to coordinates of crops, flip status, and prediction logits. However, when adapted for dataset distillation, it additionally requires storage for cutmix-related components (index of cutmix images, strength of cutmix, and coordinates of cutmix bounding box). The proposed LPLD method addresses all six components.

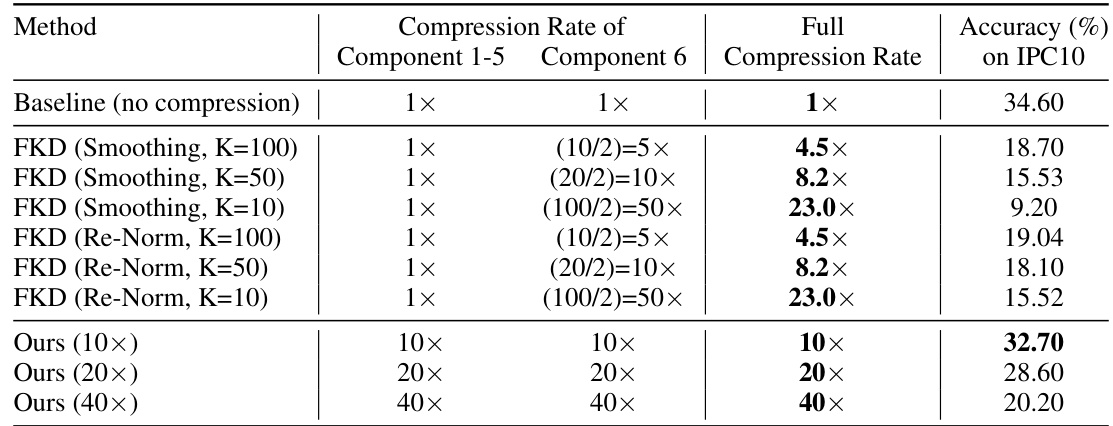
This table compares the storage of prediction logits between the baseline (no compression), FKD (label quantization), and the proposed label pruning method. It shows how different compression strategies (reducing the number of augmentations per image or the dimension of logits) affect the total storage requirements. The table highlights the proposed method’s efficiency in reducing storage by significantly reducing the number of augmentations while keeping a high dimension of logits.
This table presents the results of label pruning experiments conducted on the Tiny-ImageNet dataset. It compares the performance of three methods (SRe2L, CDA, and Ours) across different pruning ratios (1x, 10x, 20x, 30x, and 40x) and Image Per Class (IPC) values (50 and 100). The results show the accuracy achieved by each method under various label pruning levels. The ‘†’ symbol indicates that the result is taken from a previously published paper. Standard deviation is provided to demonstrate the consistency of the results.
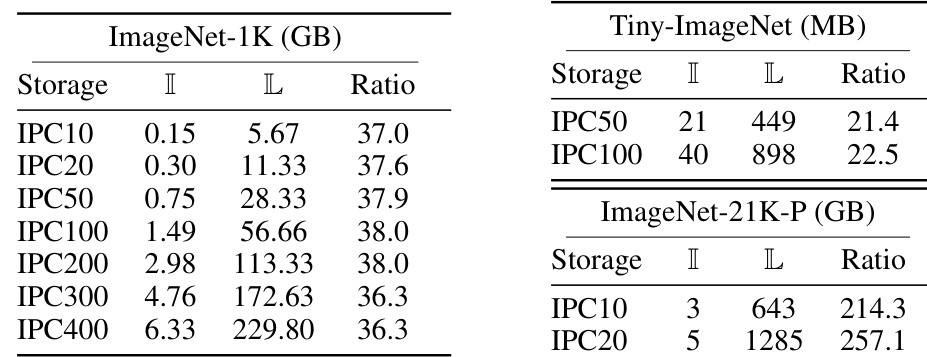
This table presents the storage size (in GB or MB) of images and labels for different datasets (ImageNet-1K, Tiny-ImageNet, ImageNet-21K-P) and varying numbers of images per class (IPC). It shows the significant increase in label storage compared to image storage, highlighting the storage issue addressed by the paper’s proposed method.

This table shows the additional storage required when using class-wise batch normalization statistics instead of global statistics for three different datasets: Tiny-ImageNet, ImageNet-1K, and ImageNet-21K-P. The ‘Original’ row represents the storage needed for the original BN statistics. The ‘+ Class Stats’ row indicates the storage required when class-wise statistics are added. The ‘Diff.’ row shows the difference in storage between the two approaches. The table highlights that the additional storage for class-wise statistics increases substantially with larger datasets.
Full paper#