↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Unsupervised Domain Adaptation (UDA) struggles to learn sufficiently discriminative features due to domain-invariant feature extraction, leading to performance limitations. Existing prompt-learning methods address this by learning both domain-invariant and specific features using domain-agnostic and domain-specific prompts. However, these methods typically rely on constraints in representation, output, or prompt space, potentially hindering learning.
This paper tackles the problem by proposing Prompt Gradient Alignment (PGA). PGA formulates UDA as a multiple-objective optimization problem, where each objective is a domain loss. The core idea is to align per-objective gradients to build consensus between them, while also penalizing gradient norms to prevent overfitting during fine-tuning. PGA is shown to consistently surpass existing methods, demonstrating its effectiveness on various benchmarks and showcasing its applicability to both single and multi-source UDA scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in unsupervised domain adaptation (UDA) and prompt learning. It introduces a novel method, Prompt Gradient Alignment (PGA), that significantly improves the performance of vision-language models in UDA tasks. The method is orthogonal to existing invariant feature learning approaches, offering a complementary strategy for enhancing model generalization. The results demonstrate consistent improvements across various benchmarks, opening up new avenues for research in this field and providing a practical solution for improving UDA performance.
Visual Insights#

This figure compares the performance of various domain adaptation methods on the Office-Home benchmark. It shows that the proposed method (PGA) outperforms other methods, particularly in terms of the number of trainable parameters required to achieve a given level of accuracy. The plot illustrates that PGA achieves competitive accuracy with significantly fewer parameters, highlighting its efficiency and effectiveness.
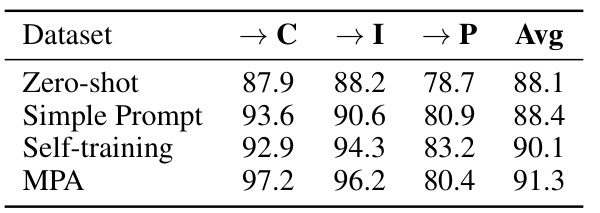
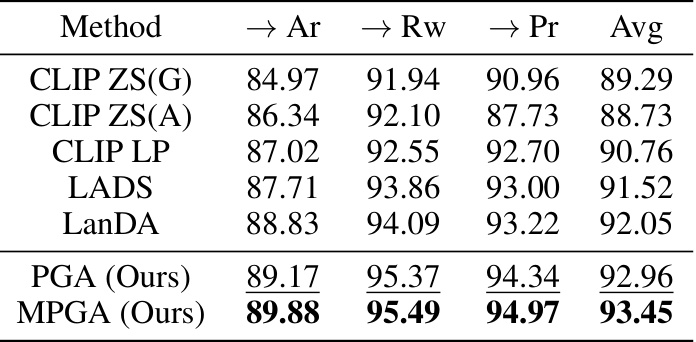
This table shows the performance of different methods on the Office-Home dataset. The methods include zero-shot prediction, simple prompt learning, self-training, and the proposed method (MPA). The table highlights that even a simple self-training approach using pseudo-labels on the target domain achieves high accuracy (90.1%), demonstrating the effectiveness of self-training as a strong baseline for domain adaptation. The proposed MPA method further improves upon this baseline.
In-depth insights#
Prompt Gradient Alignment#
The concept of “Prompt Gradient Alignment” presents a novel approach to unsupervised domain adaptation (UDA) by framing it as a multi-objective optimization problem. Instead of solely focusing on domain-invariant features, which can hinder discriminative power, this method leverages the gradients of domain-specific losses. By aligning these gradients, the model encourages consensus between objectives, leading to improved adaptation. A key innovation is the incorporation of gradient norm penalization, which helps prevent overfitting, a common issue in deep learning architectures. This technique, combined with prompt learning using vision-language models, provides a more robust and effective UDA approach. The method’s effectiveness is further strengthened by its applicability to both single-source and multi-source UDA scenarios. Empirical results demonstrate significant performance gains compared to existing methods, validating the approach’s efficacy. The theoretical analysis provided contributes to a deeper understanding of the method’s behavior, linking practical implementation with a solid mathematical foundation.
Multi-objective UDA#
Multi-objective unsupervised domain adaptation (UDA) offers a powerful framework for tackling the challenges of domain shift in machine learning. By framing UDA as a multi-objective optimization problem, it moves beyond the traditional single-objective approach, which often leads to suboptimal solutions. This novel perspective allows for the simultaneous optimization of multiple domain-specific objectives, such as minimizing the discrepancy between source and target domains while maximizing the classification accuracy on the target domain. This multifaceted approach is crucial for handling scenarios with multiple source domains, and it facilitates a more holistic understanding of the trade-offs involved in domain adaptation. The key advantage lies in its ability to better capture the complexities of real-world data distributions, which rarely conform to simple, single-objective models. The resulting models are more robust and generalize better to unseen target domains because of the more comprehensive learning process and attention to the inherent conflicts among objectives. However, careful consideration is required for the computational cost of optimizing multiple objectives simultaneously, and also techniques for managing the potential conflicts among these objectives remain a challenge.
Gradient Alignment#
The concept of ‘Gradient Alignment’ in the context of unsupervised domain adaptation (UDA) using prompt learning is a novel approach to address the limitations of traditional methods. Instead of enforcing strict domain invariance, which can hinder discriminative feature learning, gradient alignment focuses on fostering consensus between the gradients of different domain-specific objectives. This is achieved by aligning the gradients of the shared prompts, which represent domain-agnostic features, to encourage the shared prompt to learn useful information regardless of the domain. This approach allows the model to learn both domain-invariant and domain-specific features effectively. A key contribution is the integration of gradient norm penalization to mitigate overfitting and improve generalization, a common problem in deep learning models, especially in multi-task or multi-objective scenarios. The method’s effectiveness is demonstrated through empirical results on multiple benchmarks. The theoretical analysis provides a generalization bound that formally justifies the benefit of the gradient alignment strategy and gradient norm regularization. The overall approach is both innovative and practical, significantly improving the performance of UDA using vision-language models.
Generalization Bound#
A generalization bound in machine learning offers a theoretical guarantee on the performance of a model on unseen data. In the context of unsupervised domain adaptation (UDA), a generalization bound provides insights into the model’s ability to transfer knowledge from a labeled source domain to an unlabeled target domain. A tighter bound suggests better generalization, implying the model is less likely to overfit the source data and perform poorly on the target. The bound often depends on factors like the discrepancy between the source and target data distributions, model complexity, and the amount of labeled source data. Analyzing a generalization bound for a UDA method helps determine its robustness and effectiveness by quantifying the potential performance gap between training and testing. The presence of specific terms in the bound related to gradient alignment and norm penalties within the UDA approach can highlight the method’s ability to balance discriminative and invariant feature learning. This is crucial in UDA, as simply aiming for domain invariance might sacrifice discriminative power. Ultimately, a well-analyzed generalization bound can provide valuable insights into a UDA method’s theoretical strengths and limitations, guiding the development of more effective algorithms.
UDA Benchmarks#
Evaluating Unsupervised Domain Adaptation (UDA) methods necessitates robust benchmarks. These benchmarks should encompass diverse datasets exhibiting varying degrees of domain shift, covering different data modalities (images, text, etc.) and task complexities (classification, segmentation, object detection). A strong benchmark suite would include datasets with known characteristics regarding domain discrepancy, allowing researchers to systematically assess the strengths and weaknesses of UDA algorithms under controlled conditions. Moreover, standardized evaluation metrics are crucial for fair comparison, enabling objective assessment of performance across different methods. The benchmark should also account for the computational cost of different UDA techniques, promoting resource-efficient solutions. Finally, a well-curated benchmark fosters reproducibility and facilitates the development of more effective UDA methods by establishing a baseline for evaluating progress in the field and identifying areas requiring further investigation.
More visual insights#
More on figures

This figure compares the performance of three different methods: Empirical Risk Minimization (ERM), a method using only gradient alignment, and the proposed Prompt Gradient Alignment (PGA) method. The left panel shows the in-domain performance (on a validation set) across training epochs, while the right panel shows the out-of-domain performance (on a test set). The shaded areas represent standard errors calculated from ten independent runs. The figure demonstrates that PGA consistently outperforms both ERM and the gradient alignment-only method in both in-domain and out-of-domain settings.

The figure shows the evolution of cosine similarity between gradients during the training process using different values of the hyperparameter pga. When pga=0 (no gradient alignment), the similarity is initially low and fluctuates, indicating a lack of consensus between gradients. As pga increases (pga=1 and pga=10), the cosine similarity initially increases, suggesting that the gradient alignment encourages consensus between objectives. However, in all cases, the similarity decreases as training progresses, which is likely due to the model converging towards a Pareto optimal solution where the gradients are in conflict.
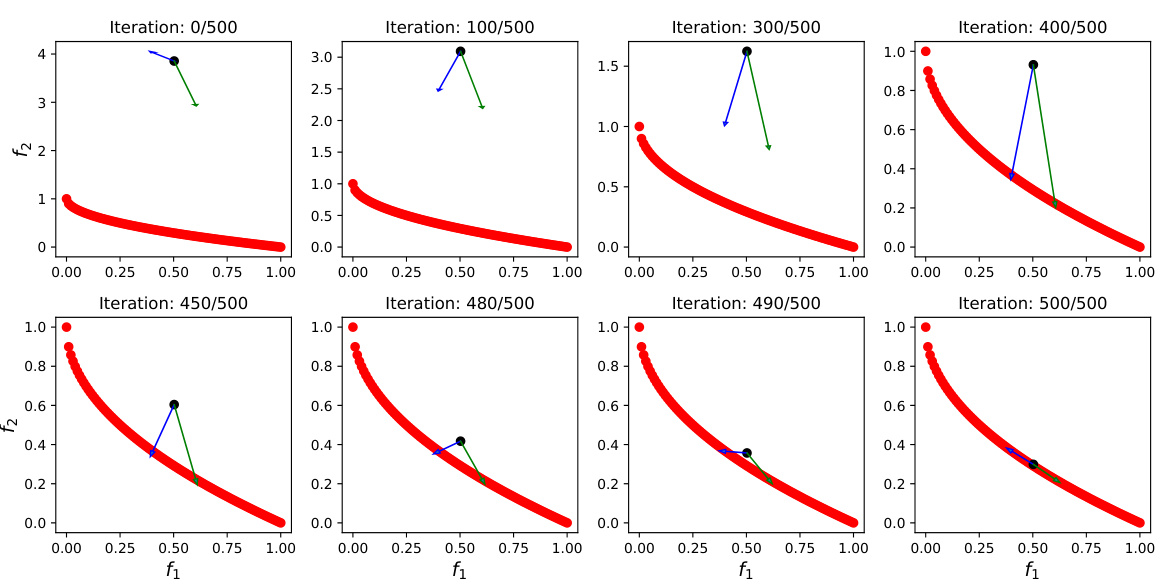
This figure compares the in-domain and out-of-domain performance of Empirical Risk Minimization (ERM) and Prompt Gradient Alignment (PGA). The left panel shows that ERM achieves high accuracy on in-domain data, but its performance drops significantly on out-of-domain data. The right panel demonstrates that PGA maintains high accuracy on both in-domain and out-of-domain data, illustrating its better generalization capability.
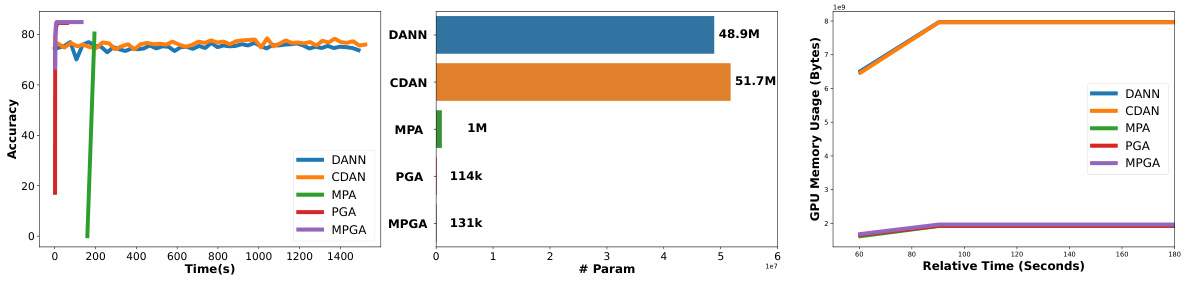
The figure shows the performance of different baselines on the Office-Home dataset. The x-axis represents the number of trainable parameters, and the y-axis represents the average accuracy across various tasks. The plot visually compares the performance of the proposed method (PGA) against other state-of-the-art methods for unsupervised domain adaptation, highlighting its superior performance with fewer trainable parameters.
The figure shows the performance comparison of various baselines on the Office-Home dataset. It visualizes the accuracy achieved by different domain adaptation methods, highlighting the superior performance of the proposed method (PGA) compared to existing techniques like DAPL, MPA, Simple Prompt, MFSAN, etc. The x-axis represents the number of trainable parameters and the y-axis represents the average accuracy across multiple Office-Home sub-datasets.
More on tables
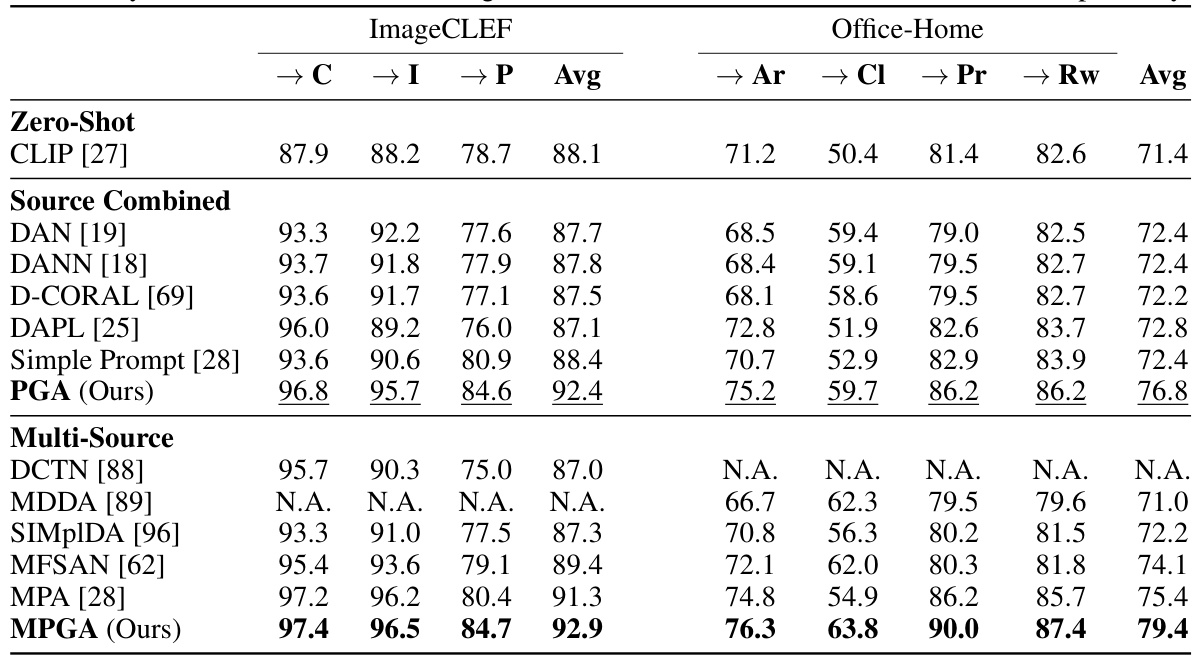
This table presents the classification accuracy of different domain adaptation methods on the ImageCLEF and Office-Home datasets. The results are broken down by dataset and whether a single source or multiple sources were used. The table highlights the superior performance of the proposed PGA and MPGA methods compared to existing state-of-the-art techniques.

This table presents the classification accuracy results of different domain adaptation methods on the ImageCLEF and Office-Home datasets. The results are broken down by individual domain and overall average. The table highlights the performance of the proposed methods (PGA and MPGA) compared to various baselines in both single-source (source combined) and multi-source settings. Bold values indicate the best overall performance, while underlined values represent the best performance when considering only the source data.
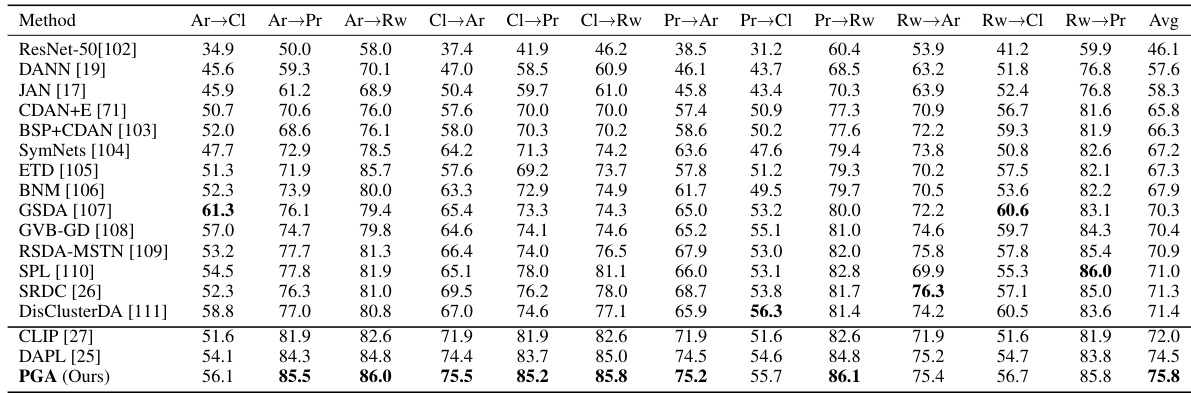
This table compares the accuracy of different domain adaptation methods on the ImageCLEF and Office-Home datasets. It shows the results for both single-source (source combined) and multi-source scenarios, highlighting the best-performing methods overall and for each scenario. The methods compared include various traditional domain adaptation techniques as well as prompt-based methods and the proposed PGA and MPGA approaches. The results are presented as average accuracy across several image classification tasks.
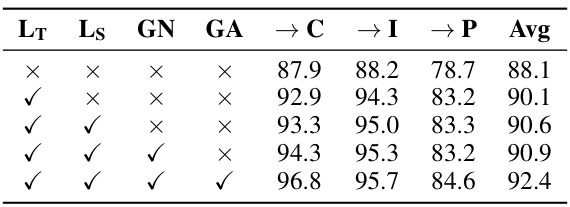
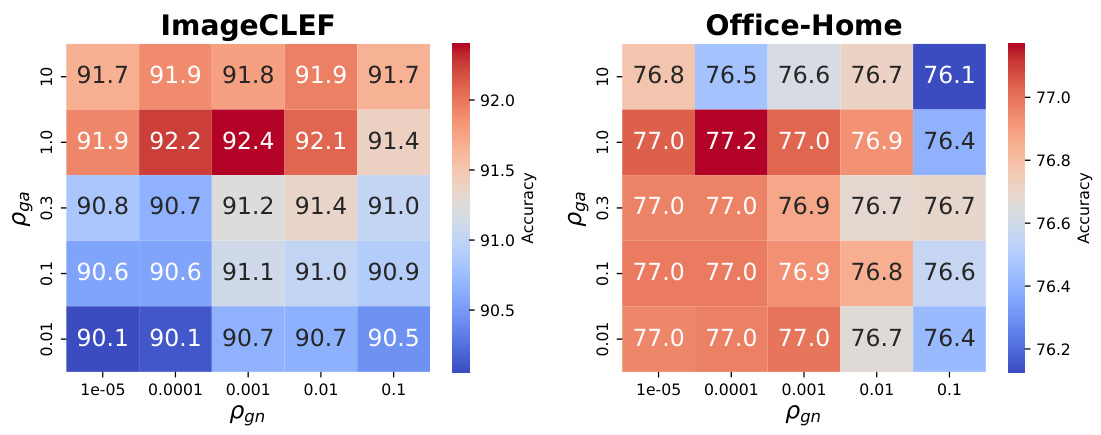
This ablation study on the ImageCLEF dataset investigates the individual and combined effects of different components in the proposed PGA method. The components are: using only the target loss (LT), adding the source loss (LS), gradient norm penalization (GN), and gradient alignment (GA). The table shows that each component contributes to improved accuracy, and that the best performance is achieved when all components are combined.

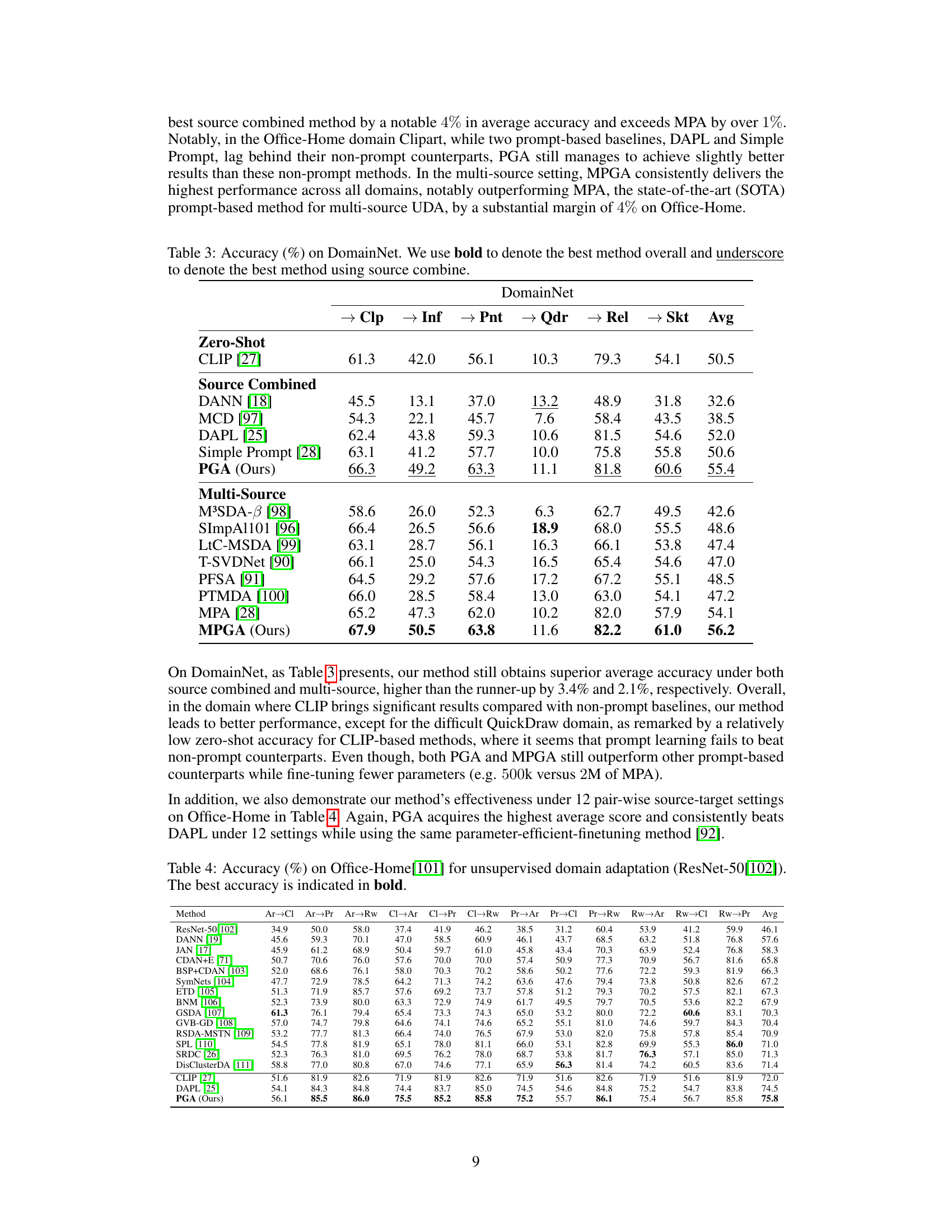
This table presents the classification accuracy results of different domain adaptation methods on the ImageCLEF and Office-Home datasets. The results are broken down by domain (C, I, P for ImageCLEF; Ar, Cl, Pr, Rw for Office-Home) and whether the source domains were combined or treated individually (Source Combined vs. Multi-Source). The best overall accuracy for each dataset and the best accuracy when source domains are combined are highlighted. The table demonstrates that the proposed Prompt Gradient Alignment (PGA) and Multi-Prompt Gradient Alignment (MPGA) methods consistently achieve state-of-the-art performance compared to existing methods, regardless of whether source domains are combined or treated separately.

This table presents the accuracy results of different domain adaptation methods on two benchmark datasets: ImageCLEF and Office-Home. The results are broken down by different scenarios, including zero-shot, single-source (source combined), and multi-source. The table highlights the superior performance of the proposed PGA and MPGA methods compared to existing state-of-the-art methods.
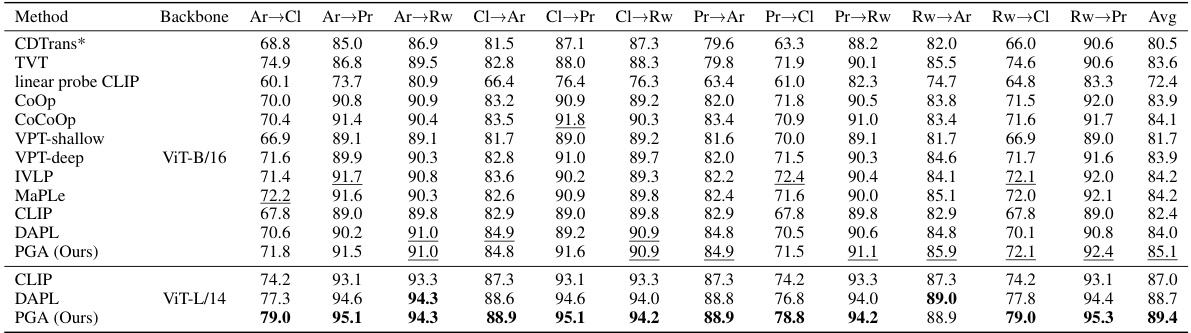
This table presents the accuracy results achieved by various domain adaptation methods on the ImageCLEF and Office-Home datasets. The results are broken down by individual class and average accuracy, distinguishing between single-source (source combined) and multi-source scenarios. The table highlights the superior performance of the proposed Prompt Gradient Alignment (PGA) and Multi-Prompt Gradient Alignment (MPGA) methods compared to existing state-of-the-art techniques.
This table presents the classification accuracy results of different domain adaptation methods on two benchmark datasets: ImageCLEF and Office-Home. The results are broken down by source and target domains for both single-source (source combined) and multi-source settings. Bold values indicate the best overall performance, while underlined values show the best performance when combining data from multiple source domains. The table highlights the consistent superior performance of the proposed PGA and MPGA methods across various scenarios.

This table presents the classification accuracy of different domain adaptation methods on the ImageCLEF and Office-Home datasets. The results are broken down by category for each dataset and show the performance of zero-shot methods (using pre-trained models without further fine-tuning), source-combined methods (using data from all source domains), and multi-source methods (adapting to each source-target domain pair individually). The table highlights the superior performance of the proposed methods (PGA and MPGA) compared to various baselines. Bold indicates the overall best performance, while underlines indicate the best performance within each experimental setting (source-combined or multi-source).

This table presents the classification accuracy results on two domain adaptation benchmark datasets, ImageCLEF and Office-Home. The results are broken down by different domain adaptation methods, including zero-shot performance, single-source methods (using data from only one source domain), and multi-source methods (using data from multiple source domains). The table highlights the superior performance of the proposed methods (PGA and MPGA) compared to other state-of-the-art methods in both single-source and multi-source settings.
Full paper#