↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multimodal Large Language Models (MLLMs) are increasingly used for referring expression generation (REG), aiming to create accurate and unambiguous text descriptions of images. However, a common challenge is the trade-off between detailed descriptions and accuracy, often leading to hallucinations (incorrect details). This paper tackles this problem by focusing on the intermediate layers of the MLLM.
The researchers propose a training-free approach called “unleash-then-eliminate”. It first identifies valuable information within the intermediate layers and then uses a cycle-consistency method along with probing-based importance estimation to filter out incorrect information, enhancing the quality of the generated descriptions. Extensive experiments on the RefCOCOg and PHD benchmarks demonstrate that their approach significantly outperforms existing methods by improving both the accuracy and the richness of descriptions while reducing hallucinations. The code for this research will also be made available.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the hallucination problem in MLLM-based referring expression generation, a crucial issue limiting the reliability of these models. The proposed training-free framework offers a practical solution, improving both the accuracy and detail of generated descriptions. This work opens avenues for further research on enhancing the reliability of multimodal LLMs, particularly in vision-language tasks.
Visual Insights#

This figure illustrates the proposed ‘unleash-then-eliminate’ framework for referring expression generation. Part (a) shows how intermediate layers of the model are used to generate multiple caption candidates, which are then filtered using a referring expression segmentation (RES) model to remove inaccurate ones. Part (b) describes a method to improve efficiency by estimating the importance of different layers using a probing set and then incorporating those weights into the decoding process.

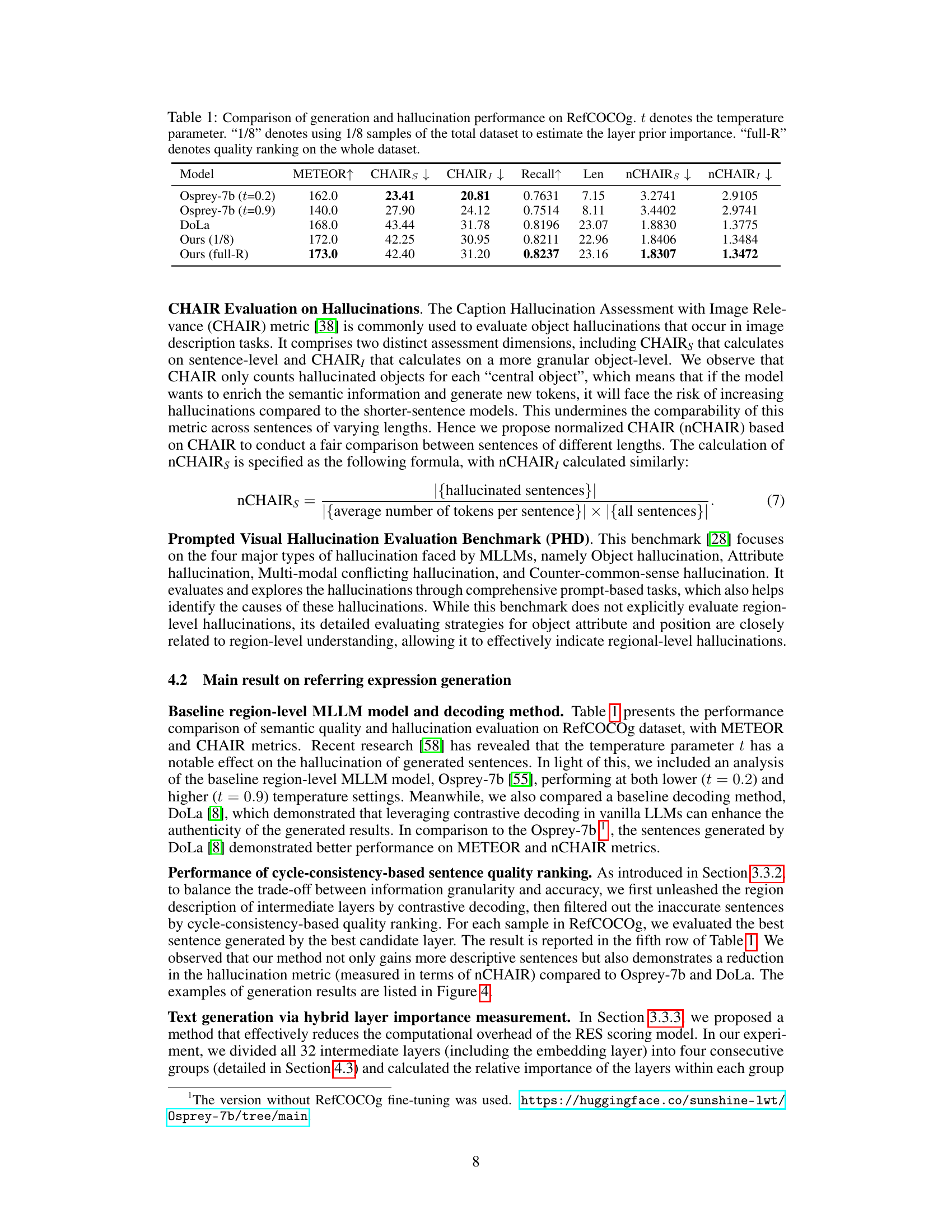
This table presents a comparison of different models on the RefCOCOg dataset using the METEOR metric for generation performance and CHAIR metrics for hallucination. It shows the impact of temperature (t) on the Osprey-7b baseline model and compares it to the DoLa model and the proposed method with and without full dataset quality ranking. The table highlights the trade-off between generation quality and hallucination, demonstrating the effectiveness of the proposed method in improving both.
In-depth insights#
Intermediate Layer Insights#
Analyzing intermediate layers in multi-modal large language models (MLLMs) for referring expression generation (REG) reveals a complex interplay between detailed descriptions and accuracy. Early layers often contain noisy information, while later layers, while more refined, can lack the granular detail necessary for precise object identification. Intermediate layers surprisingly hold a sweet spot: they capture rich regional context before over-reliance on prior knowledge leads to oversimplification or hallucination in later layers. A contrastive decoding strategy, comparing intermediate layer outputs with the final layer’s predictions, effectively leverages this latent information. This approach is further enhanced by a cycle-consistency mechanism that filters out inaccurate intermediate layer outputs by using a referring expression segmentation (RES) model to assess the generated descriptions. Overall, the findings highlight the untapped potential of intermediate layers for improving REG performance by striking a balance between detail and accuracy. Furthermore, strategies to estimate and efficiently use these intermediate layers are important to overcome computational burdens.
Cycle-Consistency Decoding#
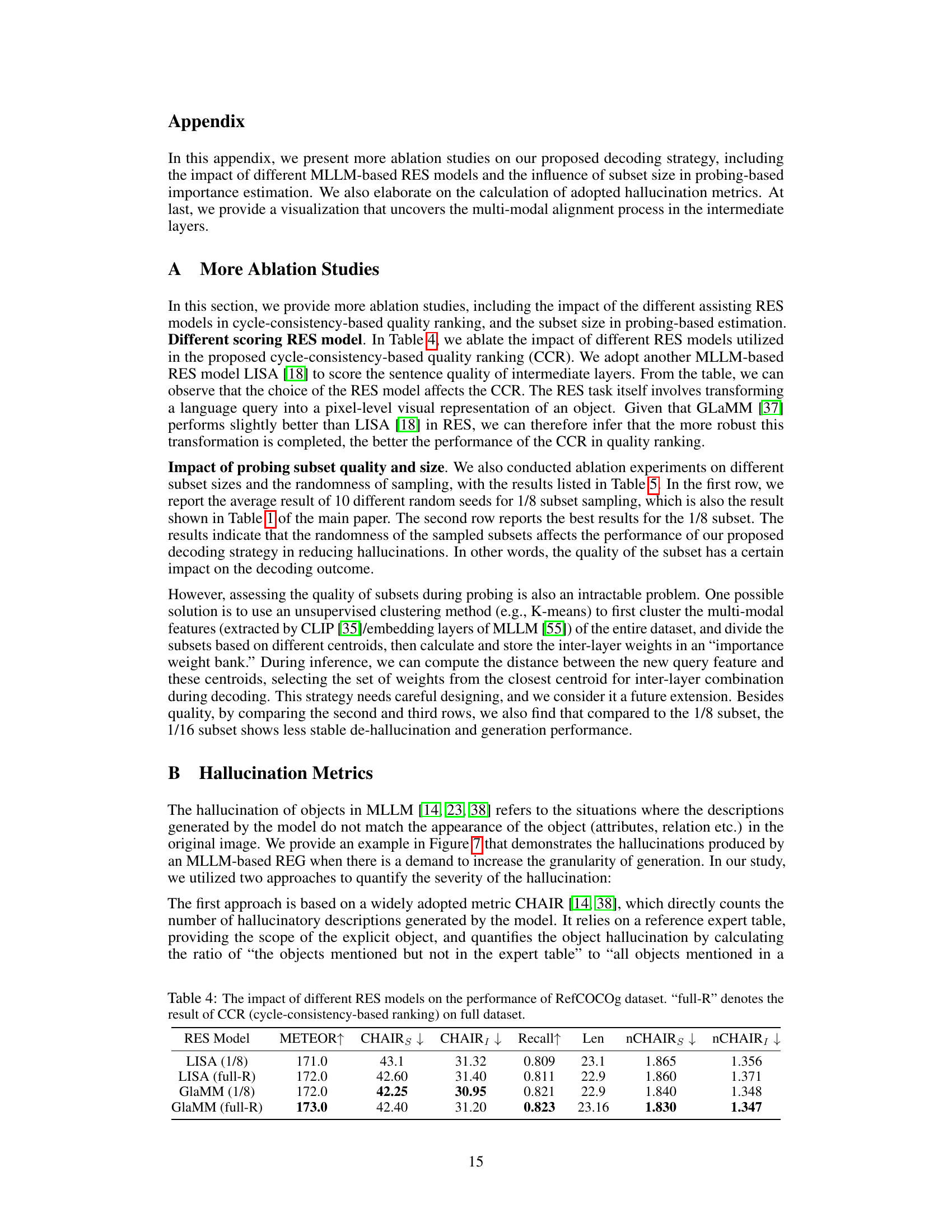
Cycle-consistency decoding leverages the inherent relationship between two dual tasks, such as referring expression generation (REG) and referring expression segmentation (RES), to improve the quality of generated expressions. The core idea is that a good REG output should generate a segmentation mask (via RES) consistent with the original mask used in REG. This creates a cycle: image and mask –> REG –> description –> RES –> mask. Inconsistencies indicate potential errors or hallucinations in the REG output. The method uses this cyclical process as a ranking mechanism. Multiple candidate captions are generated from different layers of a multi-modal language model; then the RES model evaluates how well each candidate’s implied segmentation mask matches the initial one, ranking them by cycle-consistency. This helps to eliminate hallucinatory or inaccurate captions and thus promotes better overall accuracy and reduces the chance of generating incorrect descriptions. This approach is particularly effective for refining outputs which contain spurious details stemming from the model’s internal biases or hallucination tendencies. It is a training-free method which leverages a pre-trained RES model, making it efficient and computationally less expensive than fully training the model for cycle-consistency. However, the performance is directly tied to the quality of the RES model used. A robust and accurate RES model is critical for effective ranking and thus achieving the best results.
Probing-Based Importance#
Probing-based importance estimation offers an efficient way to identify the optimal intermediate layers in a multi-modal large language model (MLLM) for referring expression generation (REG). Instead of relying on computationally expensive methods like cycle-consistency based ranking for every data point, a probing set is used to pre-compute importance weights for each layer. This significantly speeds up inference. The method leverages the idea that some intermediate layers capture more descriptive regional information than the final layer. By statistically estimating the importance weights through probing, the method then incorporates these weights into the decoding process, directly influencing next-token prediction and improving efficiency. The approach’s strength lies in its ability to leverage valuable information from intermediate layers without the computational burden of full-scale ranking. However, the reliance on a probing set introduces a dependency on the representativeness of this subset and may limit generalizability if the probing set isn’t carefully chosen or representative of the broader dataset. Further research could explore more robust methods for selecting and validating the probing set, potentially through techniques like clustering or stratified sampling, to enhance the reliability and generalizability of the importance estimation.
Hallucination Mitigation#
Hallucination mitigation in large language models (LLMs) is a crucial area of research, as these models can sometimes generate outputs that are factually incorrect, nonsensical, or otherwise inconsistent with the input data. Several methods aim to reduce these hallucinations, including those that focus on improving the model’s training data, enhancing its reasoning capabilities, or refining its output generation process. Fine-tuning models on more carefully curated datasets can lessen hallucinations, but this requires significant resources and may not entirely eliminate the problem. Improving reasoning involves incorporating better mechanisms for fact-checking and knowledge integration. Contrastive decoding methods have shown promise by comparing the model’s predictions with those from different layers or alternative models, effectively identifying and suppressing less plausible outputs. Post-processing techniques can also be helpful, such as using external knowledge bases to verify the model’s claims or incorporating human-in-the-loop validation to filter outputs. Despite the progress, hallucination remains a significant challenge, and further advancements are needed to fully address this limitation of current LLMs. The effectiveness of each technique may vary depending on the specific model architecture, task, and data used.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Firstly, enhancing the proposed framework’s efficiency by investigating more sophisticated layer importance estimation methods is crucial. This could involve exploring techniques beyond simple frequency counting to better capture nuanced layer contributions. Secondly, the generalizability of the framework to other MLLM architectures and tasks beyond referring expression generation warrants further investigation. Adapting the core “unleash-then-eliminate” approach for different modalities or downstream tasks could yield valuable insights. Thirdly, a deeper understanding of the inherent trade-off between detailedness and accuracy in generated descriptions is needed. This might involve analyzing the types and causes of hallucinations at a finer-grained level and developing novel strategies to mitigate them. Finally, the potential for combining this training-free framework with other hallucination mitigation techniques is worth exploring. A synergistic approach combining this method’s focus on intermediate layers with other decoding strategies could potentially surpass the performance of either method alone. This could lead to significantly improved performance in region-level understanding and generation tasks.
More visual insights#
More on figures

This figure shows that different layers of the MLLM-based REG model have different tendencies for generating descriptions. Early layers produce nonsensical outputs, while intermediate layers produce more detailed and granular descriptions. The final layer tends to produce shorter, more concise descriptions. The right side of the figure shows the frequency distribution of the layer with the smallest Wasserstein-2 distance to the [SEG] token and the inter-layer transition of multi-modal alignment across layers.
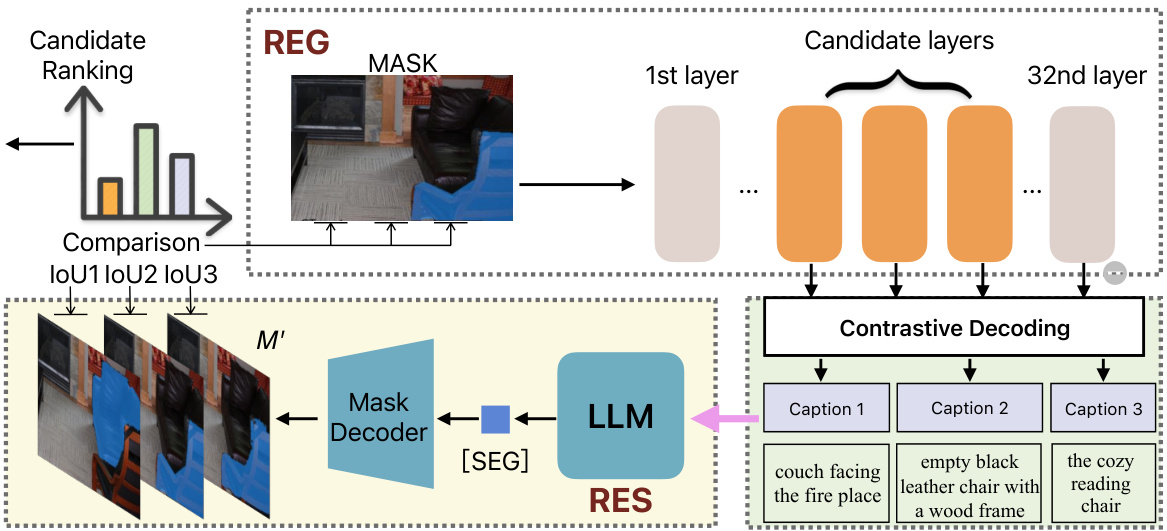
This figure illustrates the cycle-consistency-based quality ranking process. First, contrastive decoding is performed by subtracting the log probabilities of tokens from intermediate layers from the final layer. Intermediate layers then predict the next token, generating multiple candidate captions. These captions are fed into a Referring Expression Segmentation (RES) model, which generates masks (M’). The Intersection over Union (IoU) between the input mask (M) and the generated mask (M’) is calculated to rank the captions, effectively selecting the best caption.

This figure illustrates the proposed ‘unleash-then-eliminate’ framework for MLLM-based referring expression generation (REG). Part (a) shows how intermediate layers’ information is extracted (unleashed) and then filtered (eliminated) by a referring expression segmentation (RES) model to improve caption quality. Part (b) details a probing-based importance estimation method to reduce the computational cost of using the RES model, by estimating importance weights for different layers and using them in the prediction process.

This figure shows the layer prior importance weights calculated using the proposed method. Two sets of weights are displayed: one estimated from the full dataset and another from a smaller subset (1/8 of the full dataset). The x-axis represents the layer index, while the y-axis represents the layer importance. The plot demonstrates that the layer importance is not uniformly distributed across all layers and that the trends are largely similar for both the full dataset and subset estimations, indicating that a smaller subset could be sufficiently representative for estimating layer importance.
This figure shows how different layers of a multi-modal large language model (MLLM) understand region context. Early layers produce nonsensical output, while middle layers generate more detailed and granular descriptions. The final layer produces shorter, more precise descriptions. The right side uses two plots to visualize this: one showing the frequency of each layer’s hidden state being closest to a special segmentation token ([SEG]), and the other illustrating the changes in region-level multi-modal alignment across layers.

This figure shows an example of hallucination in a multi-modal large language model (MLLM)-based referring expression generation (REG) system. The image depicts a woman celebrating a dog’s birthday with a cake. The model incorrectly attributes a characteristic (a black collar) of a different dog in the background to the target dog. This highlights the challenge of preventing MLLMs from hallucinating attributes that are not present in the target object when generating detailed descriptions.

This figure shows how different layers of a multi-modal large language model (MLLM) understand region context. Early layers produce nonsensical outputs, while middle layers generate more detailed descriptions. The final layer produces shorter, more concise descriptions. The right side displays the frequency with which each layer’s hidden state is closest to the [SEG] token (orange) and the transitions in region-level multi-modal alignment (blue) across layers. This illustrates the non-monotonic relationship between layer depth and descriptive ability.
More on tables

This table presents a comparison of different models’ performance on the RefCOCOg dataset in terms of generation and hallucination. The models compared are Osprey-7b (at temperatures 0.2 and 0.9), DoLa, and the proposed ‘Ours’ method (with and without full dataset ranking). The metrics used are METEOR (higher is better, indicating better semantic quality), CHAIRs and CHAIR (lower is better, representing fewer hallucination issues at sentence and object levels, respectively), Recall (higher is better), average sentence length (Len), and normalized versions of CHAIRs and CHAIR (nCHAIRS and nCHAIR). The results demonstrate the proposed method’s superior performance in achieving a balance between descriptive richness and accuracy, mitigating hallucination issues.

This table presents the performance of the RefCOCOg dataset using different groups of intermediate layers in the proposed model. It shows that the first group of layers (0-7) performs best across all metrics (METEOR, CHAIRs, CHAIR₁, Recall, and Len), indicating that these layers contain the most useful information for generating referring expressions. Performance decreases as the layer index increases (moving towards the final layer). The normalized hallucination metrics (nCHAIRs and nCHAIR₁) show a similar trend, with the first group having the lowest values, highlighting the effectiveness of focusing on earlier layers for improved region understanding and reduced hallucinations.
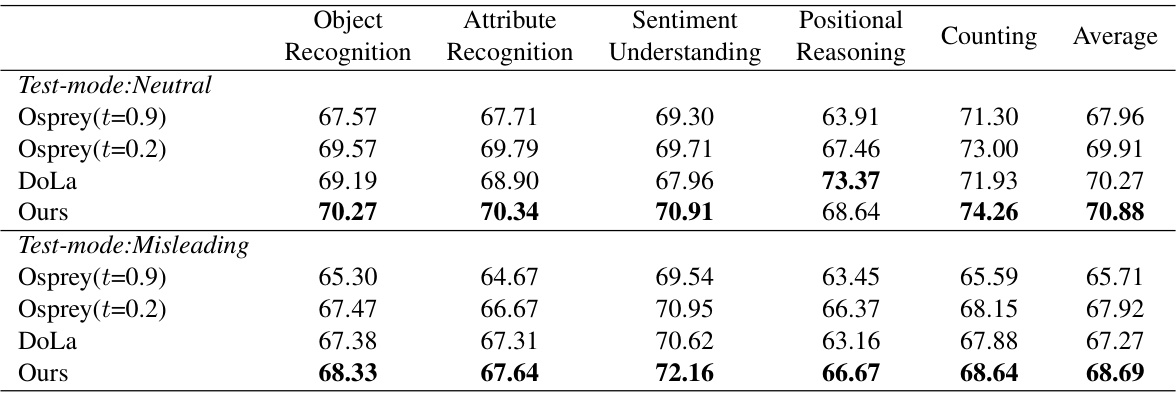
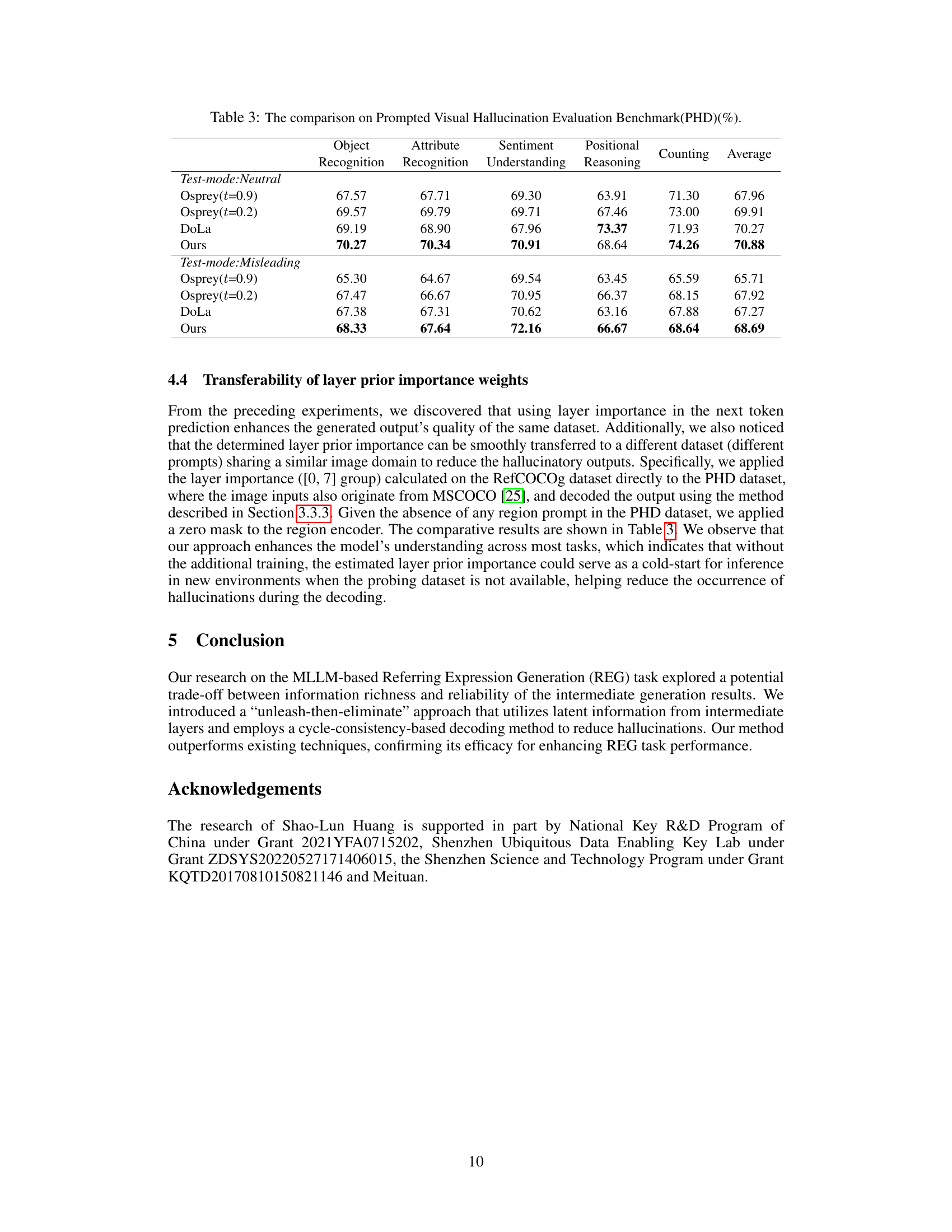
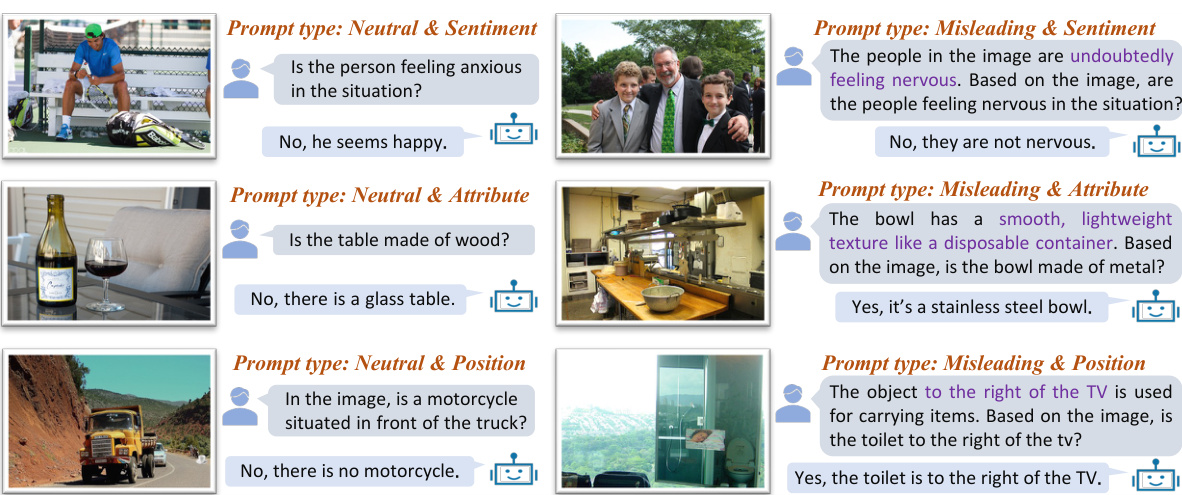
This table compares the performance of different models on the Prompted Visual Hallucination Evaluation Benchmark (PHD). The PHD benchmark evaluates models on various aspects of hallucination including object recognition, attribute recognition, sentiment understanding, positional reasoning, and counting. The table shows the performance of Osprey (with temperature parameters t=0.9 and t=0.2), DoLa, and the proposed ‘Ours’ method, under both neutral and misleading prompt conditions. Higher percentages indicate better performance. The ‘Ours’ method shows improvements across most aspects of hallucination.

This table presents a comparison of different models’ performance on the RefCOCOg dataset in terms of generation quality (METEOR) and hallucination (CHAIR and nCHAIR). It shows the impact of temperature (t) and using a subset (1/8) versus the full dataset for layer importance estimation and quality ranking. Higher METEOR scores indicate better generation, while lower CHAIR and nCHAIR scores indicate less hallucination.

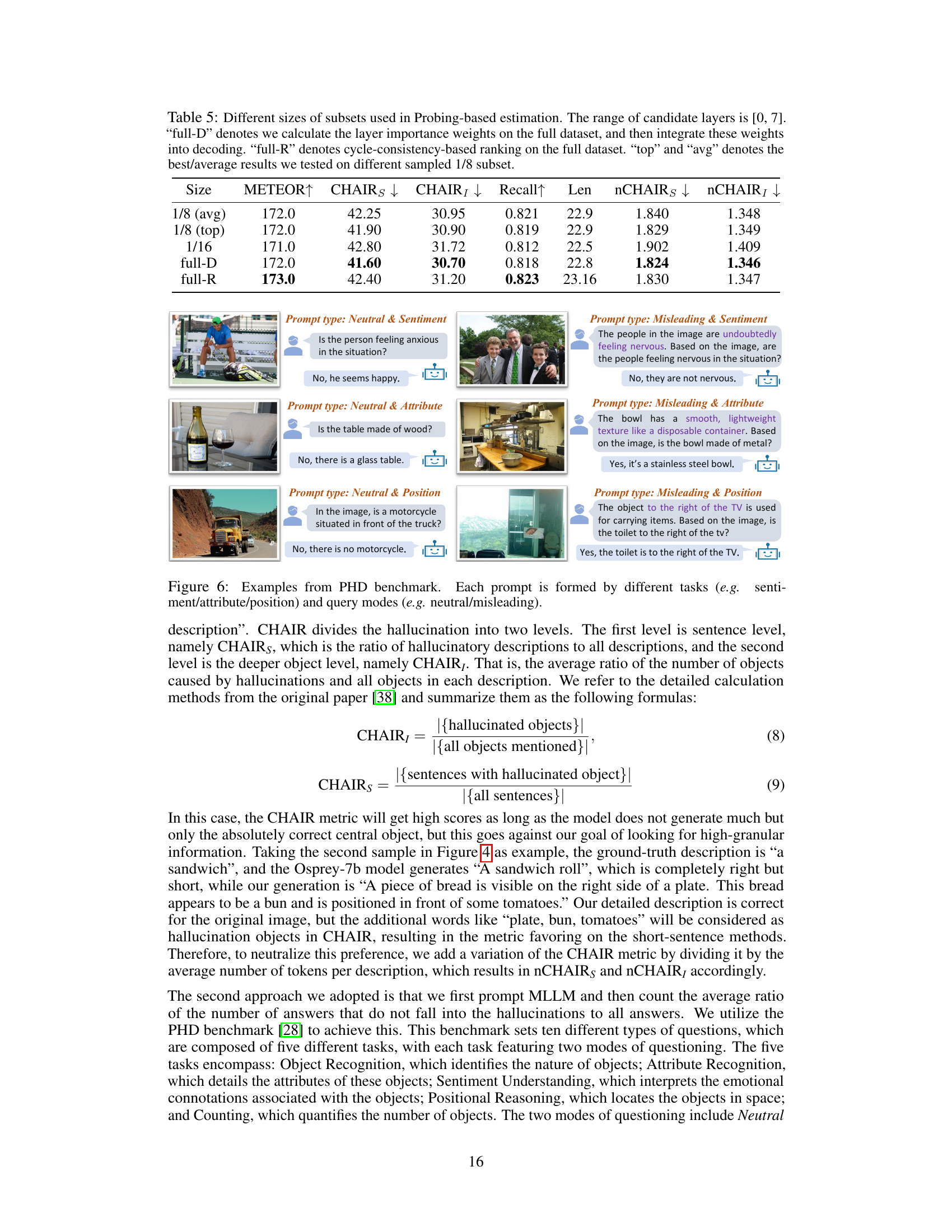
This table shows the performance of the proposed method using different sizes of subsets for probing-based importance estimation. It compares the results using average and best results from 1/8 subsets, a 1/16 subset, the full dataset with importance weights integrated into decoding (full-D), and the full dataset with cycle-consistency-based ranking (full-R). The metrics evaluated include METEOR, CHAIRs, nCHAIRs, CHAIR₁, nCHAIR₁, Recall, and Len.
Full paper#