↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current speech enhancement methods struggle with real-world distortions like background noise and reverberation. While diffusion models offer high quality, their iterative inference process is computationally expensive. Universal speech enhancement aims to address multiple distortions simultaneously, but finding a balance between speed and quality is challenging.
This paper proposes FINALLY, a novel GAN-based model that addresses these issues. It incorporates a WavLM-based perceptual loss function to improve training stability and quality. The researchers theoretically demonstrate that GANs are naturally inclined to find the most likely clean speech sample, aligning with the goal of speech enhancement. Experiments demonstrate state-of-the-art performance on various datasets, producing clear, high-quality speech at 48kHz with significantly faster inference compared to diffusion models.
Key Takeaways#
Why does it matter?#
This paper is important because it presents FINALLY, a novel speech enhancement model that achieves state-of-the-art performance in producing clear, high-quality speech at 48kHz. It offers a computationally efficient alternative to existing methods, and its theoretical analysis of GANs provides valuable insights for future research in speech enhancement and other related areas.
Visual Insights#
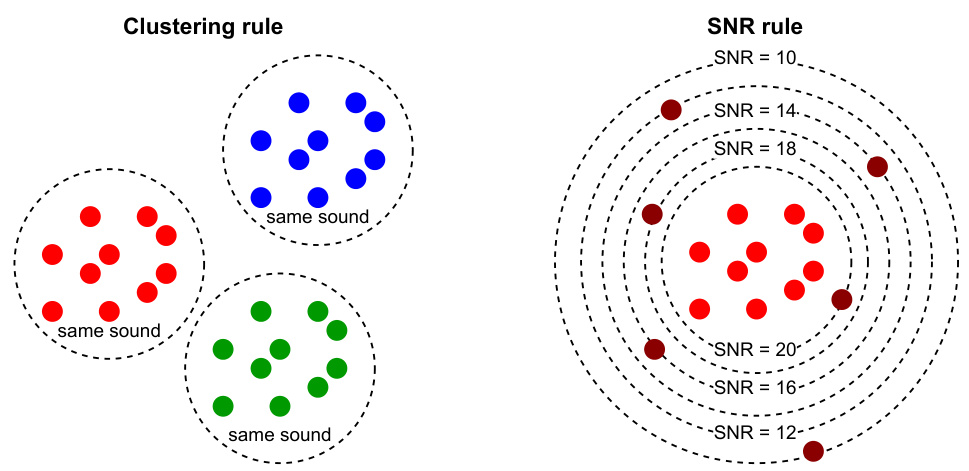
This figure illustrates two heuristic rules used to evaluate the quality of feature spaces for speech generation. The Clustering rule states that representations of the same speech sound should form distinct clusters in the feature space, while the SNR rule indicates that noisy samples should move away from the cluster of clean sounds as the signal-to-noise ratio (SNR) decreases. The figure uses visual examples to demonstrate these criteria.
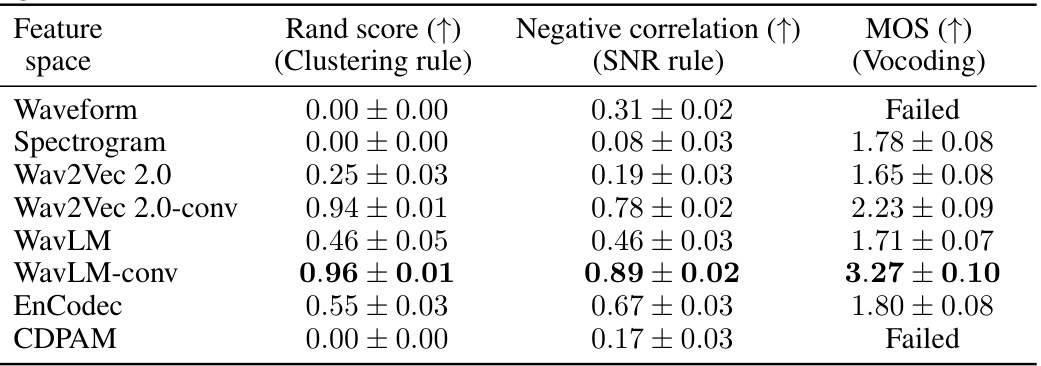
This table presents the results of evaluating different feature extractors for use in perceptual loss for speech enhancement. Three criteria were used: Clustering Rule (how well features of the same sound cluster together), SNR Rule (how well features separate by SNR level), and MOS (Mean Opinion Score from a neural vocoding task, measuring the perceptual quality of the generated audio). The results show WavLM-conv features perform best across all criteria.
In-depth insights#
GANs for Speech#
Generative Adversarial Networks (GANs) offer a compelling approach to speech enhancement by learning the complex mapping between noisy and clean speech. GANs excel at capturing intricate data distributions, which is crucial for modeling the variability inherent in real-world audio. A theoretical understanding of GANs reveals their tendency to converge towards the mode of the clean speech distribution, making them naturally suited for tasks prioritizing the most probable clean signal. However, practical implementation of GANs for speech requires careful consideration of loss functions and network architectures. Perceptual loss functions, like those leveraging WavLM embeddings, are particularly effective in guiding the GAN towards generating perceptually pleasing audio rather than simply minimizing numerical distance metrics. Furthermore, innovative training strategies, such as multi-stage training and the integration of additional regularization losses, can bolster the stability and performance of the GAN model, achieving studio-like quality at high sampling rates. The careful choice of loss functions and the use of state-of-the-art self-supervised models as feature extractors significantly influence the effectiveness and quality of speech produced.
WavLM Integration#
Integrating WavLM, a self-supervised speech pre-training model, significantly enhances speech enhancement. WavLM’s convolutional encoder features, proven superior to other extractors via proposed selection criteria, form a robust perceptual loss backbone. This loss function, coupled with MS-STFT adversarial training, stabilizes learning and guides the generator toward high-probability clean speech outputs. The WavLM integration leads to a model that achieves state-of-the-art performance in producing clear, studio-quality speech at 48kHz. Crucially, the integration of WavLM doesn’t compromise inference speed, unlike computationally expensive diffusion models, thus demonstrating a significant improvement in both accuracy and efficiency.
Mode Collapse#
Mode collapse, a phenomenon where generative models fail to produce diverse outputs, is a critical concern in generative adversarial networks (GANs). In the context of speech enhancement, mode collapse would manifest as the model consistently producing a limited range of “enhanced” audio, regardless of the input’s diversity. This limits the model’s ability to handle real-world variability in noise and distortions. The authors address this by theoretically demonstrating that the least squares GAN (LS-GAN) loss function inherently encourages the generator to predict the most probable clean speech sample, thereby mitigating the risk of mode collapse. They support this claim with empirical validation, showcasing that their model, FINALLY, avoids mode collapse while achieving state-of-the-art performance. The choice of loss function, the careful selection of perceptual features, and a multi-stage training process all contribute to preventing mode collapse in FINALLY. This contrasts with approaches that attempt to model the entire conditional distribution, which can be more susceptible to mode collapse due to increased complexity.
Perceptual Loss#
The concept of perceptual loss in the context of speech enhancement is crucial, aiming to bridge the gap between objective metrics and human perception. Instead of solely relying on waveform or spectrogram differences, which may not fully correlate with perceived audio quality, perceptual loss functions leverage higher-level representations extracted from pre-trained models like WavLM. These models are trained on massive datasets, capturing complex acoustic patterns that are meaningful to human listeners. By using the output of such models as the basis for the loss function, the generator is guided towards producing speech that sounds more natural and clear, even if the underlying waveform is not perfectly matched to a ground truth. The selection of feature extractor is critical, influencing the characteristics of the feature space and affecting training stability and the resulting quality of the enhanced speech. Hence, the study carefully considers various feature extractors and propose criteria for selecting features with well-structured and disentangled features to improve the quality of perceptual loss.
FINALLY Model#
The FINALLY model, presented as a novel approach to speech enhancement, leverages the strengths of Generative Adversarial Networks (GANs) while addressing their limitations. Theoretically grounded in the mode-seeking behavior of LS-GANs, it efficiently regresses towards the most probable clean speech sample. The model incorporates a WavLM-based perceptual loss, chosen based on rigorous analysis of feature space structure, ensuring training stability. This sophisticated loss function, combined with a modified HiFi++ architecture and a novel multi-stage training pipeline, achieves state-of-the-art performance in producing high-quality, studio-like speech at 48kHz. The integration of WavLM significantly improves performance, highlighting the value of self-supervised pre-training in speech enhancement. Its efficiency is emphasized by a single forward pass inference, unlike the computationally expensive iterative approach of diffusion models.
More visual insights#
More on figures

This figure shows the architecture of the FINALLY speech enhancement model. It’s a multi-stage model built upon the HiFi++ architecture, incorporating a WavLM encoder for self-supervised pre-trained features. The model uses a combination of LMOS loss, adversarial training with MS-STFT discriminators, and PESQ and UTMOS losses for better quality. The figure illustrates the flow of data through the various components (SpectralUNet, Upsampler, WaveUNet, SpectralMaskNet, Upsample WaveUNet), highlighting the integration of WavLM features and the multi-stage training process.

This figure visually demonstrates the ambiguity in generating waveforms from speech data. Two different waveforms are shown, representing the ground truth and a version synthesized by a HiFi-GAN vocoder. Although both waveforms represent the same sound, their significant differences illustrate the challenge of achieving accurate speech enhancement using a purely generative approach which aims at capturing the full probability distribution of the clean waveform given a degraded input.

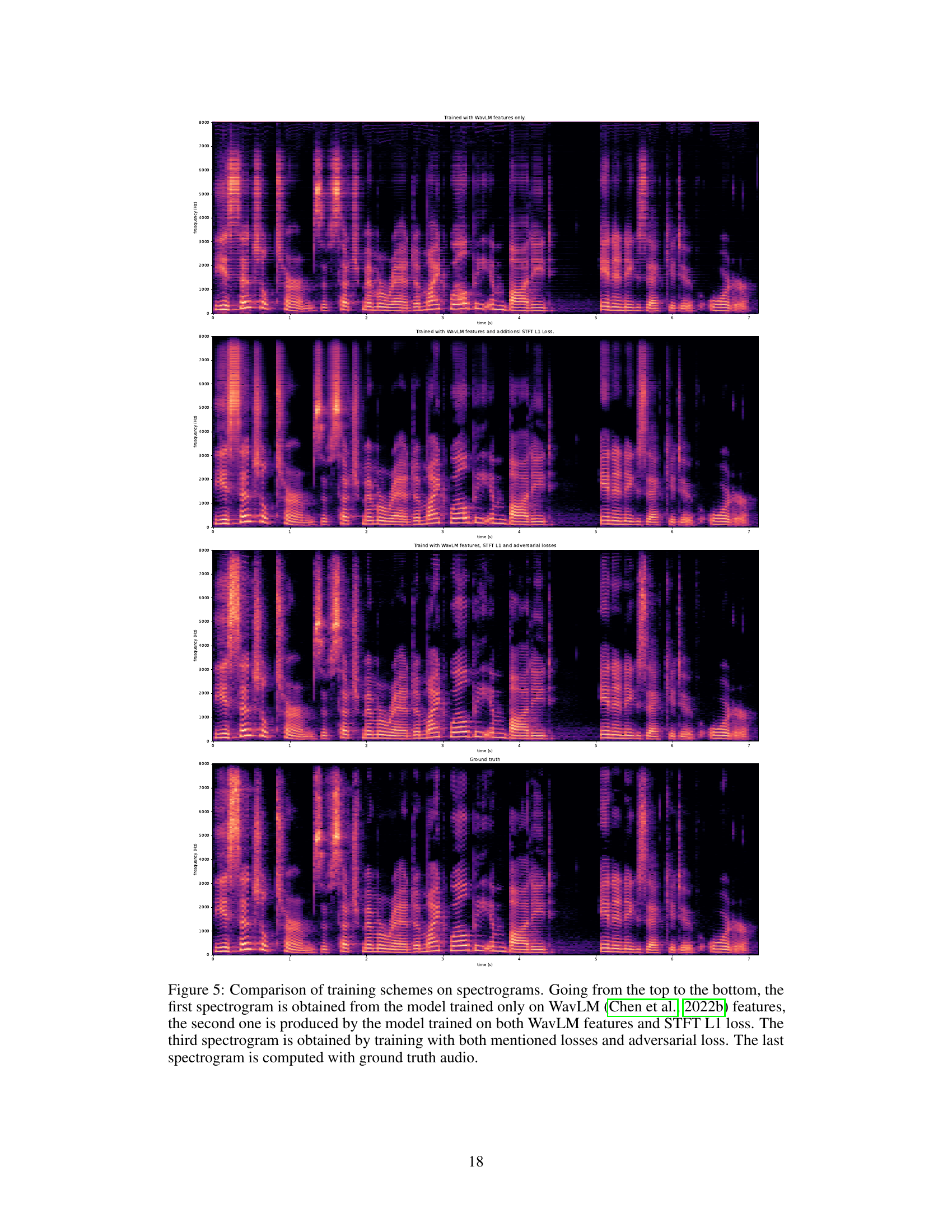
This figure compares spectrograms generated using different training schemes for a speech enhancement model. The top spectrogram shows results using only WavLM features for training. The second shows results using WavLM features and an additional STFT L1 loss, which adds spectral information. The third spectrogram demonstrates the results of adding adversarial loss to the previous two, which aims to improve model stability and quality. Finally, the bottom spectrogram shows the ground truth spectrogram for comparison. The figure illustrates the progressive improvements in the accuracy of the generated spectrogram as more sophisticated training techniques are applied.
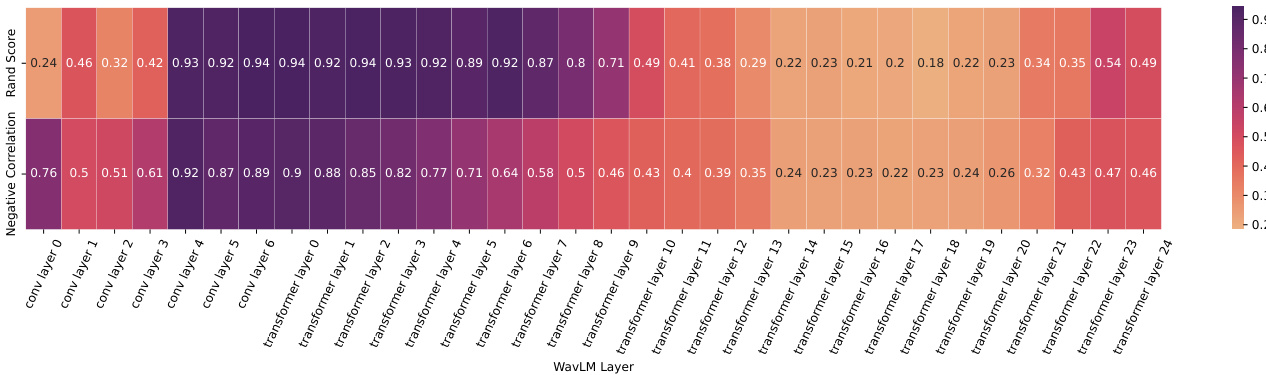
This figure shows the results of an investigation into the effectiveness of different WavLM layers for use in a perceptual loss function for speech enhancement. Two metrics were used to evaluate the feature spaces generated by each layer: Rand Index (a measure of cluster separation for identical sounds) and the negative correlation of SNR (Signal-to-Noise Ratio; a measure of how well the feature space distinguishes between clean and noisy sounds). The heatmap displays the Rand Index and negative SNR correlation values for each layer (convolutional and transformer layers), indicating which layer’s features best satisfy the proposed criteria for an effective feature space. Ideally, high Rand index scores and high negative correlation with SNR indicate that the feature space effectively clusters similar sounds together and separates noisy samples from clean ones.

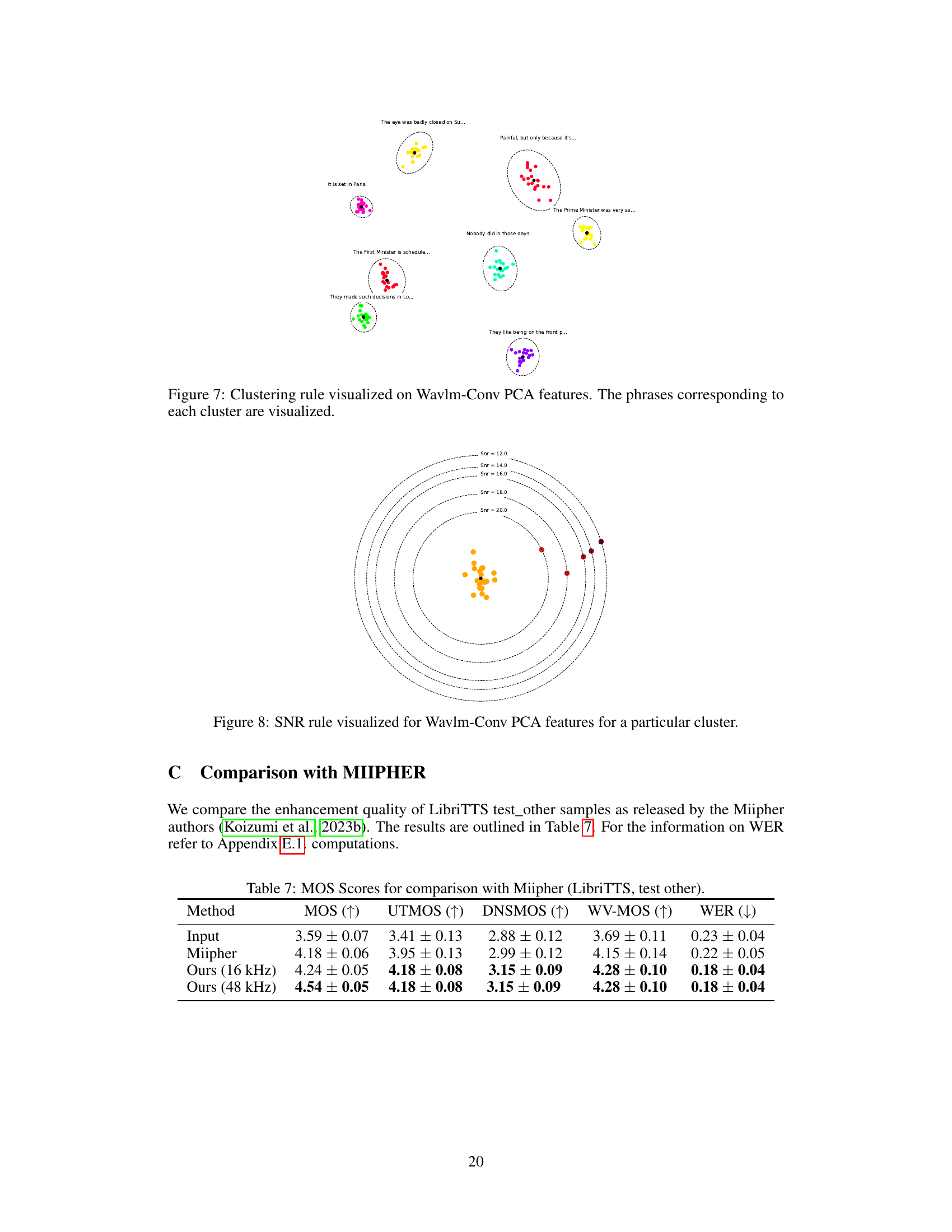
This figure visualizes the clustering rule using Wavlm-Conv PCA features. Each cluster represents a group of audio samples with the same speech sound. The phrases corresponding to each cluster are labeled to demonstrate that samples belonging to the same cluster indeed have the same linguistic content.

This figure visualizes how the SNR rule is applied to WavLM-Conv PCA features. It shows that as the signal-to-noise ratio (SNR) increases, the feature representations of speech sounds move away from the cluster of clean sounds. The concentric circles represent different SNR levels, with the innermost circle representing clean sounds (SNR=∞). The colored points represent feature vectors, with orange representing clean speech and red representing increasingly noisy speech. The visualization demonstrates that the chosen feature space effectively distinguishes between clean and noisy speech based on SNR.

This figure shows the interface used in the crowdsourcing experiment to assess the speech quality. The assessors are presented with four speech samples and asked to rate the overall quality using a 5-point Likert scale (5-Excellent, 1-Bad). A ‘The audio doesn’t play’ option is also provided to handle any issues with audio playback.

This figure shows the architecture of the FINALLY speech enhancement model. It’s based on HiFi++, but with modifications. WavLM-large model output is added as an input to the Upsampler. An Upsample WaveUNet is introduced to enable 48kHz output from a 16kHz input. The model uses a multi-stage training process with different loss functions at each stage to optimize for both content restoration and perceptual quality. The diagram depicts the flow of data through various components including SpectralUNet, Upsampler, WaveUNet, SpectralMaskNet, and the WavLM encoder, and shows how the LMOS loss, MS-STFT discriminators, and other loss functions work together.
More on tables
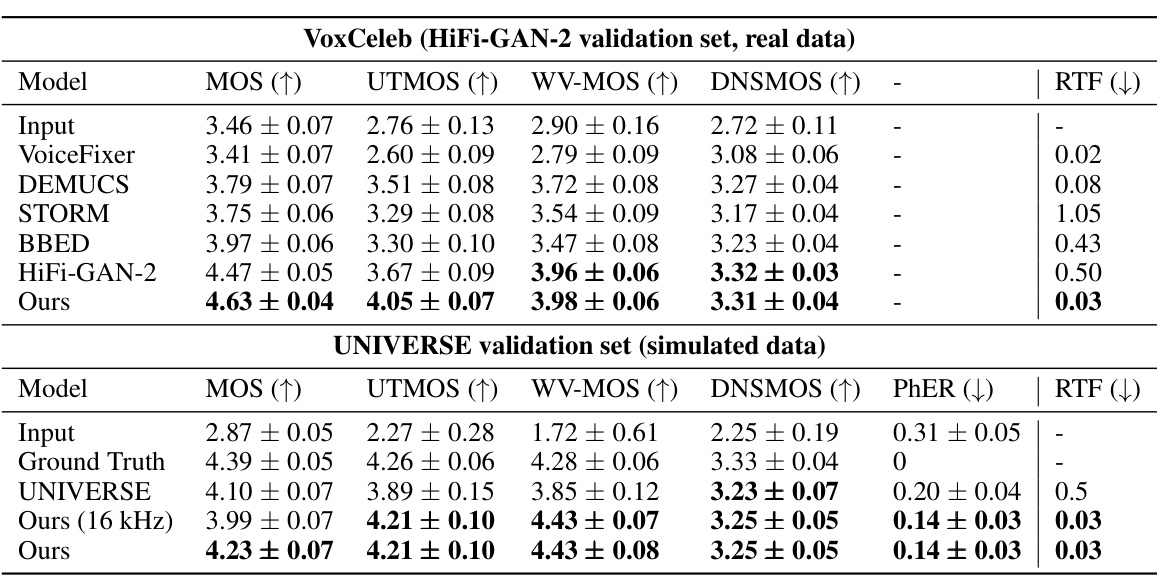
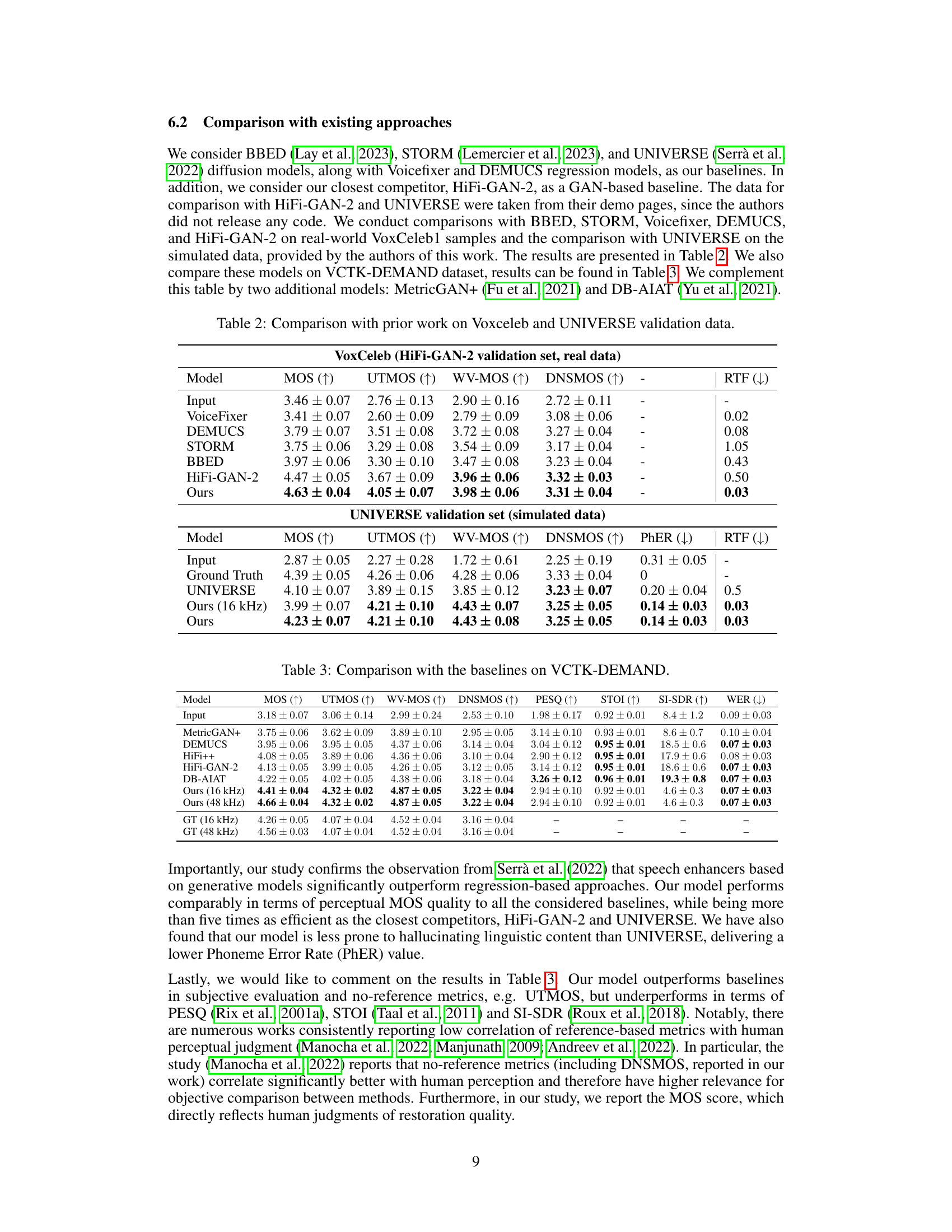
This table compares the performance of the proposed FINALLY model against several baselines on two datasets: VoxCeleb and UNIVERSE. The VoxCeleb dataset contains real-world data, while the UNIVERSE dataset contains artificially generated data with various types of simulated distortions. The table shows the Mean Opinion Score (MOS), UT MOS, WV-MOS, DNSMOS, Phoneme Error Rate (PhER), and Real-Time Factor (RTF) for each model and dataset. The results highlight that FINALLY achieves state-of-the-art performance in terms of both perceptual quality and computational efficiency.

This table compares the performance of the proposed model, FINALLY, against several baseline models on the VCTK-DEMAND dataset. The metrics used include MOS (Mean Opinion Score), UTMOS (Utokyo-based MOS), WV-MOS (weighted MOS), DNSMOS (DNN-based MOS), PESQ (Perceptual Evaluation of Speech Quality), STOI (Short-Time Objective Intelligibility), SI-SDR (Scale-Invariant Signal-to-Distortion Ratio), and WER (Word Error Rate). The table shows that FINALLY outperforms the baselines on most of the metrics, indicating its superior performance in speech enhancement.

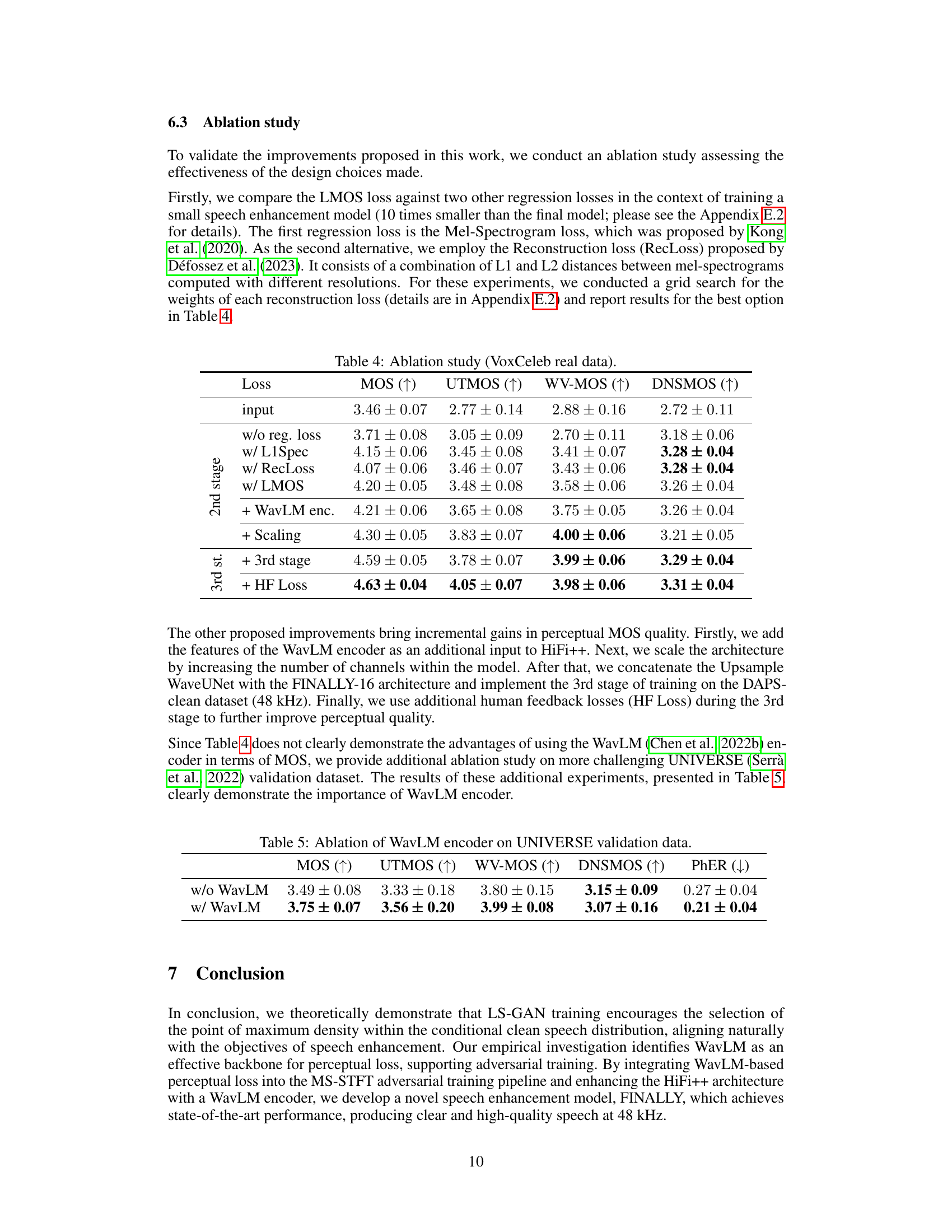
This table presents the results of an ablation study conducted on the VoxCeleb real dataset to evaluate the effectiveness of different design choices made in the proposed speech enhancement model. The study compares the performance of the LMOS loss against two other regression losses (Mel-Spectrogram loss and Reconstruction loss), and then assesses the impact of adding WavLM encoder features, scaling the architecture, adding a third training stage, and incorporating a human feedback loss. The MOS, UTMOS, WV-MOS, and DNSMOS scores are reported for each configuration.

This table presents the ablation study results focusing on the impact of using WavLM encoder in the FINALLY model. It compares the model’s performance with and without the WavLM encoder, evaluating metrics such as MOS, UTMOS, WV-MOS, DNSMOS, and PhER on the UNIVERSE validation dataset. The results demonstrate the significant contribution of WavLM encoder to achieving better speech enhancement quality.

This table compares the Mean Opinion Score (MOS) achieved by different perceptual loss functions used in neural vocoding. The MOS score is a measure of perceived audio quality. The comparison includes PFPL, SSSR loss with HuBERT features, MS-STFT + L1 waveform, LMOS (the proposed method), and adv. MPD-MSD. Ground truth MOS is also provided for reference.

This table compares the objective and subjective speech quality scores of the proposed FINALLY model against the Miipher model on the LibriTTS test_other dataset. The metrics used include MOS (Mean Opinion Score), UTMOS, DNSMOS, WV-MOS, and WER (Word Error Rate). The comparison helps to evaluate the relative performance of the two models in terms of perceived audio quality and linguistic accuracy.
This table presents a comparison of different feature extractors used for perceptual loss in speech generation. It evaluates the features based on two criteria: Clustering rule (whether representations of the same sound form a cluster) and SNR rule (whether representations of speech sounds contaminated by noise move away from clean sounds with increasing noise level). The table also includes the Mean Opinion Score (MOS) obtained for neural vocoding using each feature extractor, which indicates the quality of the generated speech. The results show that features extracted by the convolutional encoder of the WavLM model present the best performance.
This table compares various feature extractors used as backbones for perceptual loss in a neural vocoding task. It evaluates the feature spaces based on two criteria: the Clustering rule (whether representations of identical speech sounds form separable clusters) and the SNR rule (whether representations of speech sounds contaminated by different noise levels move away from the clean sound cluster monotonically with increasing noise). The Mean Opinion Score (MOS) for neural vocoding using each feature type is also reported to assess the suitability of the feature space for perceptual loss in speech generation.
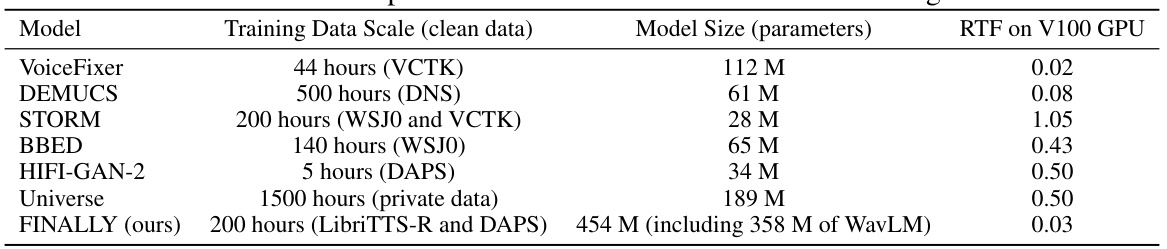
This table compares the training data scale and model sizes of the proposed model, FINALLY, against various baseline models. It highlights that while FINALLY has more parameters than many baselines, the majority are used for handling low-resolution features, resulting in a significantly lower Real-Time Factor (RTF) on a V100 GPU.

This table presents the results of an ablation study conducted on the VoxCeleb real data to evaluate the effectiveness of different design choices made in the paper. The study compares the LMOS loss against two other regression losses (Mel-Spectrogram loss and Reconstruction loss) in the context of training a smaller speech enhancement model. It also investigates the impact of adding WavLM encoder features, scaling the architecture, adding a third training stage, and incorporating a human feedback loss. The results show the MOS, UTMOS, WV-MOS, and DNSMOS scores for each configuration.
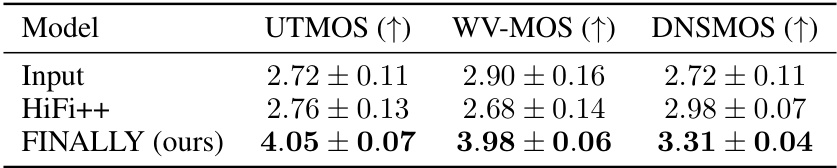
This table compares the performance of the proposed FINALLY model against the HiFi++ baseline on the VoxCeleb dataset. It shows the improvements achieved in terms of three objective metrics: UTMOS, WV-MOS, and DNSMOS, which assess different aspects of speech quality. Higher scores indicate better quality, demonstrating the effectiveness of the proposed model in enhancing speech quality.
Full paper#