↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Instruction-based image editing (IIE) has seen significant progress, but lacked a comprehensive evaluation benchmark. Existing metrics and benchmarks are limited in scope and fail to capture the nuances of different editing tasks. This makes it difficult to objectively compare IIE models and identify areas for improvement.
To address this issue, researchers introduce I2EBench, a new benchmark that automatically evaluates IIE models across 16 diverse dimensions covering both high-level and low-level editing tasks. I2EBench aligns with human perception, and offers valuable insights into model performance. The comprehensive evaluation and open-sourced nature of I2EBench are set to significantly advance the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for advancing instruction-based image editing (IIE). It provides a much-needed comprehensive benchmark, I2EBench, enabling objective model evaluation and facilitating fair comparisons. The open-sourced dataset and tools will accelerate research, leading to improved IIE models and valuable insights into model strengths and weaknesses. This work addresses the urgent need for standardized evaluation in IIE, which is currently lacking.
Visual Insights#
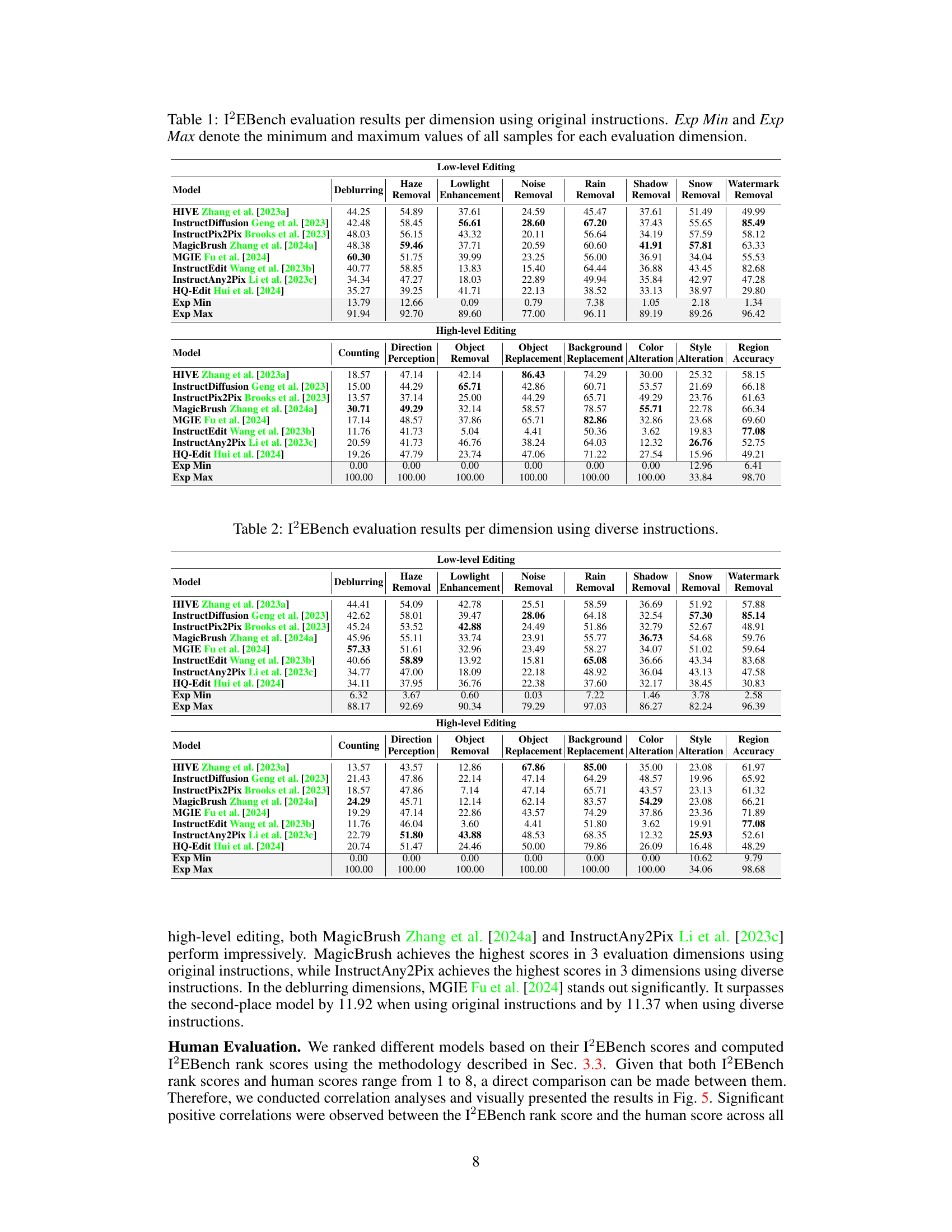
This figure illustrates the I2EBench system’s workflow. It starts with human annotation of a large image dataset with original and diverse instructions for various editing tasks. These instructions are then used with different IIE models to generate edited images. The quality of these edited images is assessed through automated evaluation using 16 different dimensions, and also via human evaluation comparing the automated scores with human preferences. Finally, alignment verification ensures that the automated evaluation aligns well with human perception.
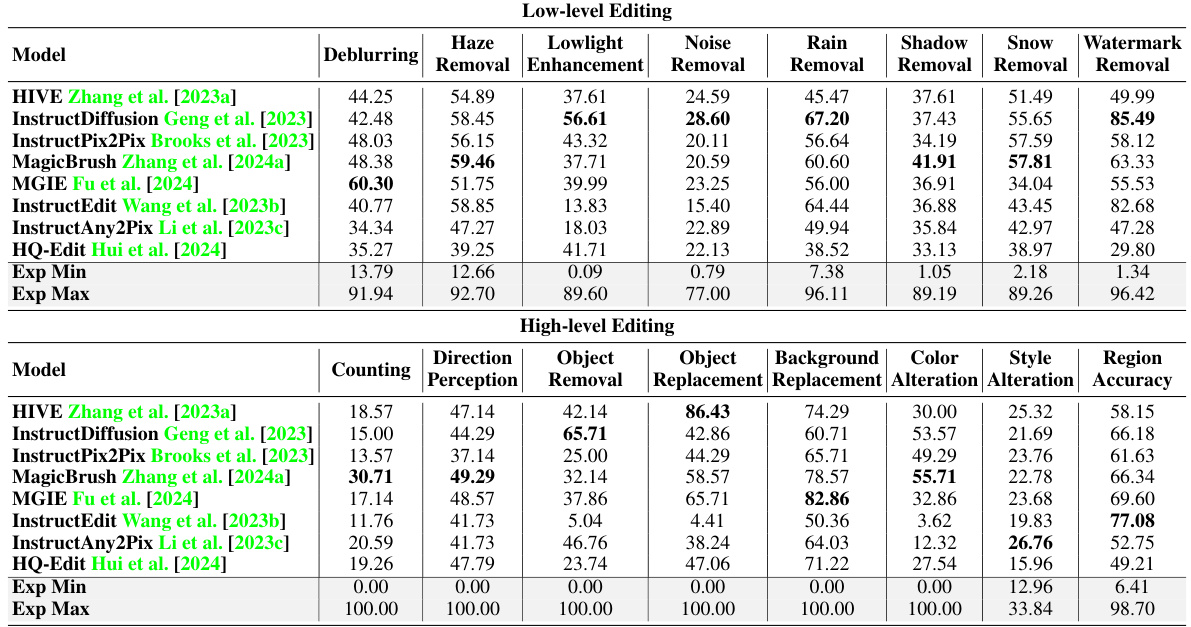
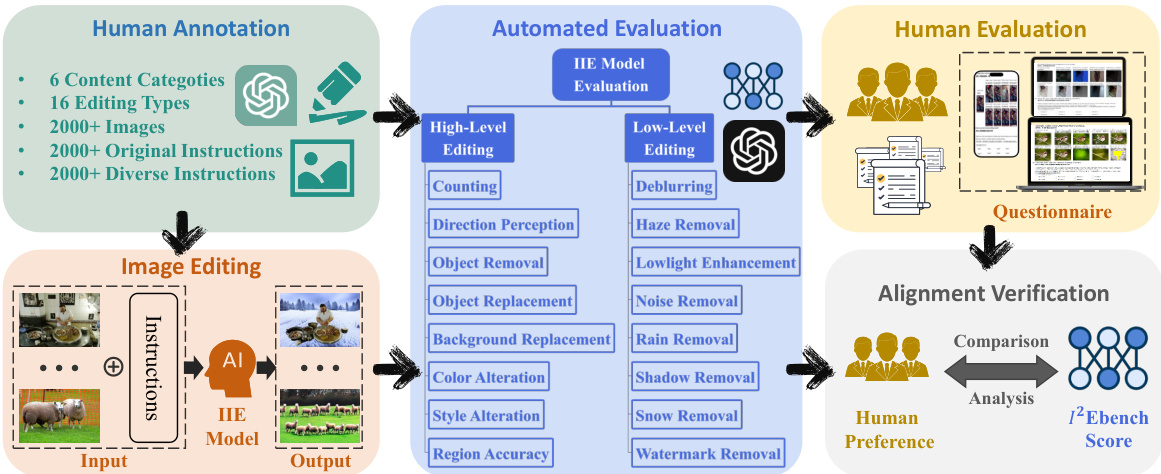
This table presents the evaluation results of eight different Instruction-based Image Editing (IIE) models across 16 evaluation dimensions using original instructions. The dimensions are categorized into high-level and low-level editing tasks. For each model and dimension, the table shows the average score. Exp Min and Exp Max represent the minimum and maximum values observed across all samples within each dimension, providing a range of performance.
In-depth insights#
IIE Evaluation Metrics#
Instruction-based image editing (IIE) model evaluation is challenging due to the diversity of editing tasks and the subjective nature of assessing results. Conventional metrics, such as PSNR, SSIM, and LPIPS, focus on low-level image quality and fail to capture high-level semantic understanding. User studies, while providing valuable human perception alignment, are costly, time-consuming, and lack reproducibility. Existing benchmarks often lack comprehensiveness, covering limited editing types and evaluation dimensions. Therefore, a comprehensive IIE evaluation framework should incorporate a diverse set of metrics encompassing both low-level and high-level aspects. It’s crucial to consider human perception alignment and ensure the selected metrics accurately reflect the desired editing outcomes. Future research should focus on developing robust, efficient, and reproducible evaluation methods that capture the complexity and nuances of IIE. A combination of automated metrics and human evaluation is likely the most effective approach.
I2EBench Framework#
The I2EBench framework is a comprehensive benchmark designed for the automated evaluation of Instruction-based Image Editing (IIE) models. Its strength lies in its multi-faceted approach, incorporating 16 evaluation dimensions covering both high-level (instruction understanding, object manipulation) and low-level (image quality metrics) aspects of image editing. Aligning with human perception is key; the framework uses extensive user studies to validate its evaluation metrics and ensure alignment with human judgment of editing quality. This human-in-the-loop approach makes I2EBench more reliable and trustworthy than benchmarks relying solely on automatic metrics. The framework offers valuable research insights by analyzing model performance across dimensions, highlighting strengths and weaknesses, thereby guiding future IIE model development. Finally, the open-source nature of I2EBench, including datasets and evaluation scripts, fosters collaboration and facilitates fair comparisons within the research community.
Human Perception#
Incorporating human perception into the evaluation of instruction-based image editing (IIE) models is crucial for developing truly effective systems. A key challenge lies in bridging the gap between automated metrics and human judgment, as automated metrics often fail to fully capture the nuances of human aesthetic preferences and editing quality. Therefore, the integration of human evaluation, such as user studies or A/B testing, is essential to ensure the benchmark reflects real-world user experience. Alignments between automated scores and human ratings are necessary to validate the benchmark’s reliability. Furthermore, focusing on human perceptual aspects of image editing such as the degree of realism, adherence to instructions and overall aesthetic appeal, allows for a more comprehensive and relevant assessment, offering a greater understanding of user experience in such tasks. This focus on human perception ensures IIE systems are evaluated not merely on technical performance, but also on their ability to meet actual user needs and expectations.
Model Strengths/Weaknesses#
Analyzing the strengths and weaknesses of different instruction-based image editing (IIE) models reveals significant variations in performance across diverse editing tasks. Some models excel at high-level edits like object manipulation, demonstrating strong instruction comprehension. However, these same models might underperform on low-level tasks such as noise reduction or haze removal. Conversely, other models may show proficiency in low-level edits but struggle with complex high-level instructions. This disparity highlights the need for a more holistic evaluation framework, moving beyond single metrics to capture the nuanced capabilities of each model. The lack of robustness across various instruction types is another critical weakness, with some models highly sensitive to phrasing changes or stylistic variations. Future research should focus on developing more versatile IIE models capable of handling diverse instructions and a broader range of editing challenges. Furthermore, addressing the limitations in data diversity and the inherent biases present within existing datasets is crucial for improving overall model performance and reducing potential disparities.
Future IIE Research#
Future research in instruction-based image editing (IIE) should prioritize improving the robustness and generalizability of models across diverse editing tasks and instructions. Addressing the limitations of existing models, such as sensitivity to instruction phrasing and inconsistent performance across different image types and content categories, is crucial. Developing more comprehensive evaluation benchmarks that align with human perception is needed to accurately assess model performance. This requires exploring more nuanced evaluation metrics beyond existing low-level and high-level metrics. Furthermore, research into multimodal IIE is promising, as it offers opportunities to incorporate richer contextual information (audio, other images) to enhance understanding and improve editing outcomes. Finally, investigating methods for mitigating biases and ethical concerns related to data and model training is critical for responsible development and deployment of IIE technologies.
More visual insights#
More on figures

This figure shows the results of different instruction-based image editing (IIE) models applied to various editing tasks, categorized into high-level and low-level editing. Each row presents an example image and the results of applying different models to the same editing instruction. High-level editing tasks involve changing the background or removing objects; Low-level editing tasks are related to image quality enhancements (e.g., haze removal). The figure demonstrates the effectiveness of each model on diverse editing tasks.

This figure visualizes the instructions used in the I2EBench dataset through word clouds, differentiating between original and diverse instructions. The word clouds highlight the most frequent words and terms related to various editing tasks. The bar chart (c) displays the number of images collected for each of the 16 evaluation dimensions within I2EBench.

This figure presents a comparison of radar charts illustrating the I2EBench scores across various dimensions for different Instruction-based Image Editing (IIE) models. The charts use two sets of instructions: (a) original instructions and (b) diverse instructions generated using ChatGPT. Each axis represents a specific dimension of image editing evaluation (e.g., Style Alteration, Haze Removal, Object Removal etc.). The length of each line from the center to the perimeter shows the score achieved by each model for that dimension. Comparing the (a) and (b) plots allows us to see how model performance varies with different instruction styles.

This figure presents a correlation analysis between I2EBench rank scores and human scores for each of the 16 evaluation dimensions. The I2EBench rank score is derived from the automated evaluation of the I2EBench system. The human score is obtained through a separate human evaluation, where human annotators rank the editing results of different models. Each plot shows the scatter plot of the I2EBench rank score versus the human score for a specific dimension. The Pearson correlation coefficient (ρ) is also provided for each dimension. This figure demonstrates the high correlation between the automated I2EBench evaluation and human perception, validating the effectiveness of the I2EBench benchmark.
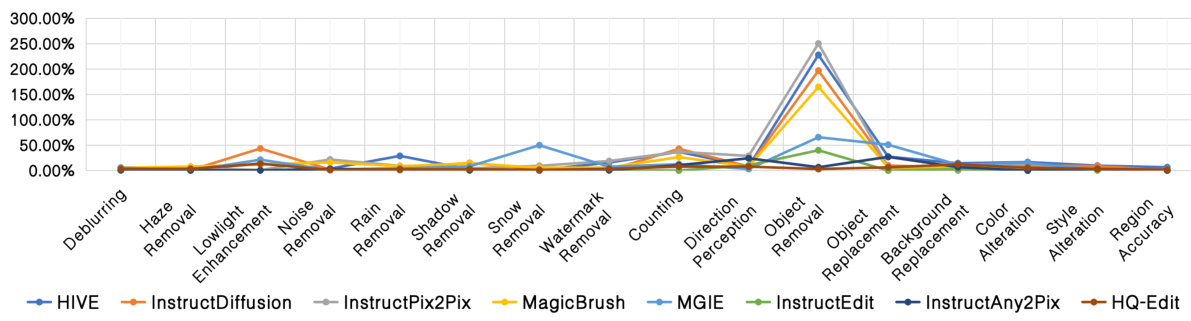
This figure compares the performance of different Instruction-based Image Editing (IIE) models across sixteen evaluation dimensions using two sets of instructions: original and diverse. The radar charts visually represent each model’s score for each dimension, allowing for a direct comparison of their strengths and weaknesses. The use of two instruction sets helps assess the robustness of the models to variations in instruction phrasing.

This figure compares the performance of different IIE models across various content categories using both original and diverse instructions. The radar charts visually represent the normalized average I2EBench scores for each model within each category (Animal, Object, Scenery, Plant, Human, Global). This allows for a comparison of model strengths and weaknesses across different types of image editing scenarios.
Full paper#