↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Multilingual language models often suffer from performance disparities due to biases introduced by tokenization algorithms, particularly affecting low-resource and non-Latin languages. These biases stem from over-segmentation, where non-Latin scripts are fragmented more than Latin ones, leading to increased computational costs and reduced performance. This causes an unfair distribution of resources towards certain languages.
To counter this, the paper introduces MAGNET, a multilingual adaptive gradient-based tokenization method. MAGNET uses language-specific boundary predictors, which adapt to the unique characteristics of each language. This modular design significantly reduces over-segmentation, leading to more equitable compression across various languages and scripts. Extensive experiments showcase that MAGNET not only promotes fairness in tokenization but also improves downstream task performance and model efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on multilingual language models and fairness in AI. It addresses the critical issue of tokenization bias, impacting model performance and efficiency across different languages. The proposed adaptive approach can significantly impact research efforts toward building more equitable and efficient multilingual models, opening avenues for further investigation into improved tokenization techniques and downstream task performance.
Visual Insights#

The figure illustrates the key difference between MAGNET and prior work in terms of handling byte-level sequences for multilingual language modeling. Prior methods use a single boundary predictor for all languages, leading to over-segmentation, especially in low-resource languages. In contrast, MAGNET employs separate boundary predictors for different language scripts (Latin, Cyrillic, Indic), resulting in more equitable segmentation granularity across languages.
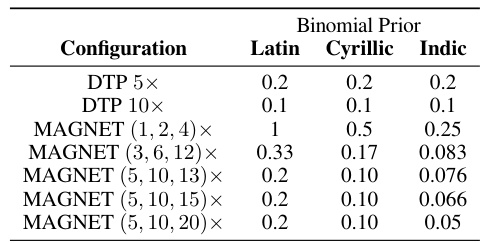
This table shows the binomial priors used in the Dynamic Token Pooling (DTP) and MAGNET models for different language scripts (Latin, Cyrillic, and Indic). DTP uses a single, fixed prior across all languages, while MAGNET uses different priors for each script to achieve more equitable segmentation. The different configurations reflect different compression rates for each language.
In-depth insights#
MAGNET: Equitable Tokenization#
MAGNET, an approach for equitable tokenization in multilingual language models, tackles the issue of disproportionate segmentation across languages, particularly affecting low-resource and non-Latin script languages. It achieves this through adaptive gradient-based tokenization, leveraging language-specific boundary predictors within the model. Unlike previous methods using a single predictor resulting in over-segmentation for some languages, MAGNET’s modular design ensures each script receives tailored treatment. This results in a more equitable segmentation granularity, improving efficiency and downstream task performance. The method dynamically adapts compression rates based on language-specific byte-to-word ratios, effectively mitigating biases caused by data imbalances. This modularity is key, promoting fairness and potentially enhancing the utility of multilingual language models across diverse scripts, bridging the gap between high and low-resource languages.
Adaptive Gradient Methods#
Adaptive gradient methods represent a significant advancement in optimization algorithms, particularly within the context of deep learning. Traditional gradient descent methods suffer from limitations such as the need for careful manual tuning of learning rates and struggles with sparse gradients. Adaptive methods address these shortcomings by dynamically adjusting the learning rate for each parameter based on its past gradients. This often involves maintaining per-parameter statistics, such as the squared gradients (as in AdaGrad and RMSprop) or moving averages of past gradients (as in Adam). This dynamic adjustment allows for faster convergence in some cases and better handling of sparse data. However, adaptive methods aren’t without their own challenges. For example, they might exhibit instability or converge to suboptimal solutions under specific circumstances, particularly in high-dimensional spaces or with non-convex optimization landscapes. The choice between adaptive and non-adaptive methods often depends on the specific problem and dataset, requiring careful consideration of the potential trade-offs. Recent research continues to explore new adaptive methods that aim to improve stability, robustness, and efficiency, particularly in the context of large-scale and complex models. These efforts often focus on modifications to existing methods or the development of entirely new approaches, highlighting the ongoing importance and evolution of adaptive gradient methods in the field of machine learning.
Multilingual Modeling#
Multilingual modeling presents unique challenges due to the inherent variability in languages. Data scarcity for many languages is a major hurdle, leading to performance disparities compared to high-resource languages like English. Tokenization, the process of splitting text into units for model processing, introduces further biases because algorithms often over-fragment low-resource languages. This necessitates methods that address data imbalances and ensure equitable representation. Adaptive approaches, such as the adaptive gradient-based tokenization, offer a solution by customizing the tokenization process to each language, thereby mitigating over-segmentation. Further research should focus on developing techniques that handle morphological differences and diverse script systems, aiming for genuinely equitable performance across all languages. Cross-lingual transfer learning, leveraging knowledge from high-resource languages, is a promising avenue but requires careful consideration to avoid propagating biases. Addressing ethical implications through careful consideration of dataset construction and model training is critical for responsible multilingual model development.
Downstream Task Analysis#
A ‘Downstream Task Analysis’ section in a research paper would delve into the performance of a model (trained using a novel technique, for example) on various downstream tasks. It would assess the model’s generalization ability, showcasing its effectiveness beyond the specific training data. The analysis would likely compare the novel model’s performance against established baselines, ideally across multiple tasks and datasets. Key metrics for evaluation would depend on the task type, such as accuracy, precision, recall, F1-score for classification problems; BLEU, ROUGE, METEOR for machine translation; or exact match, F1-score for question answering. A thoughtful analysis would explore potential correlations between the model’s performance on different tasks, indicating underlying strengths and weaknesses. For instance, strong performance on tasks requiring similar linguistic abilities might suggest an inherent aptitude in the model’s architecture. Conversely, poor performance on specific tasks might highlight limitations or biases that need to be addressed. Finally, a robust downstream task analysis would include an in-depth discussion of the results’ significance, considering statistical measures and offering insights on how the model’s characteristics directly impact real-world applicability.
Future Research#
Future research directions stemming from this work could explore several avenues. Extending MAGNET to handle Semitic languages and other morphologically complex languages presents a significant challenge requiring investigation into alternative segmentation strategies. The current byte-to-word ratio approach may need refinement for languages with irregular orthography. Further exploration of different compression rate combinations and their effects on both model efficiency and downstream task performance is also needed. A systematic comparison across a wider range of languages and scripts will bolster the generalizability of MAGNET’s benefits. In addition, exploring the integration of MAGNET with different model architectures, such as those using character-level or other sub-word tokenizations, warrants further investigation. Finally, understanding how the interplay of tokenization and specific model architectures affects the fairness of multilingual models would be a key area for future work.
More visual insights#
More on figures
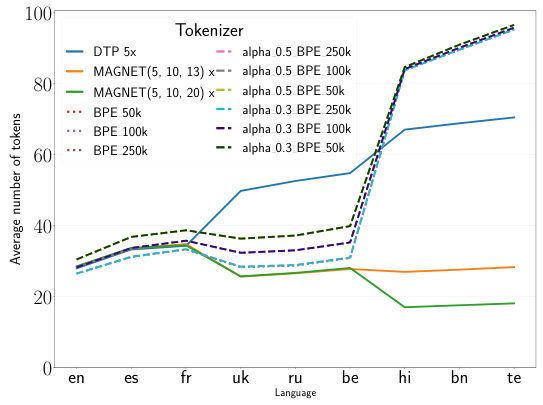
This figure compares the average number of tokens produced by different tokenization methods across nine languages with varying scripts (Latin, Cyrillic, and Indic). It shows that MAGNET significantly reduces the over-segmentation observed in non-Latin scripts with methods like Byte Pair Encoding (BPE) and Dynamic Token Pooling (DTP), leading to more equitable segmentation across languages.

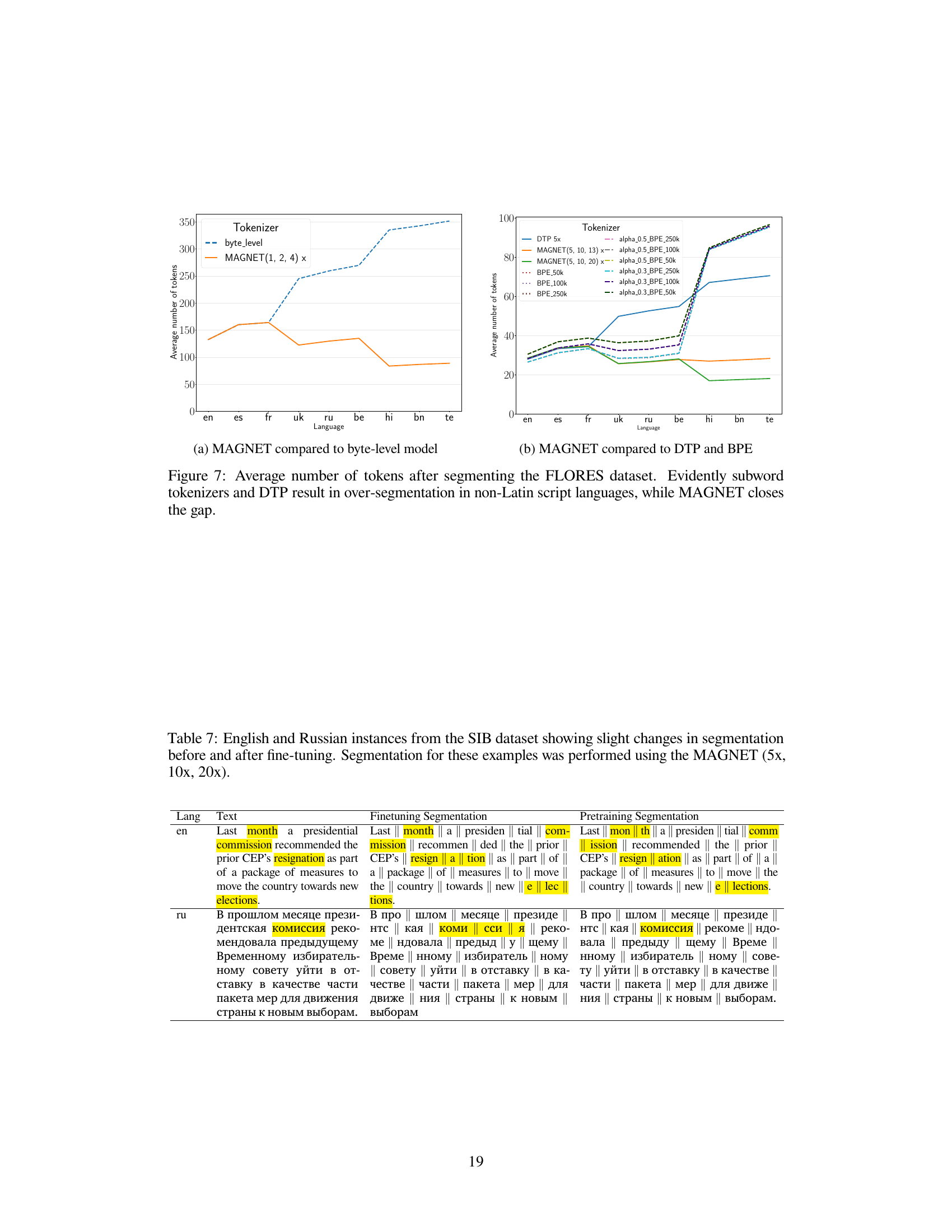
This figure compares the average number of tokens produced by different tokenization methods (byte-level, subword tokenizers, Dynamic Token Pooling (DTP), and MAGNET) when segmenting sentences from the FLORES dataset. It visually demonstrates that MAGNET achieves a more equitable segmentation across languages, particularly reducing the over-segmentation observed in non-Latin scripts with other methods. The x-axis represents the different languages, and the y-axis represents the average number of tokens per sentence. The various lines represent the different tokenization methods.
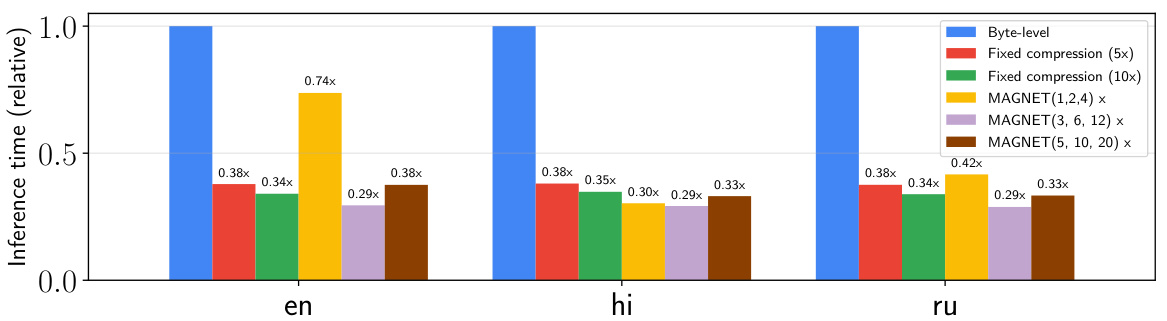
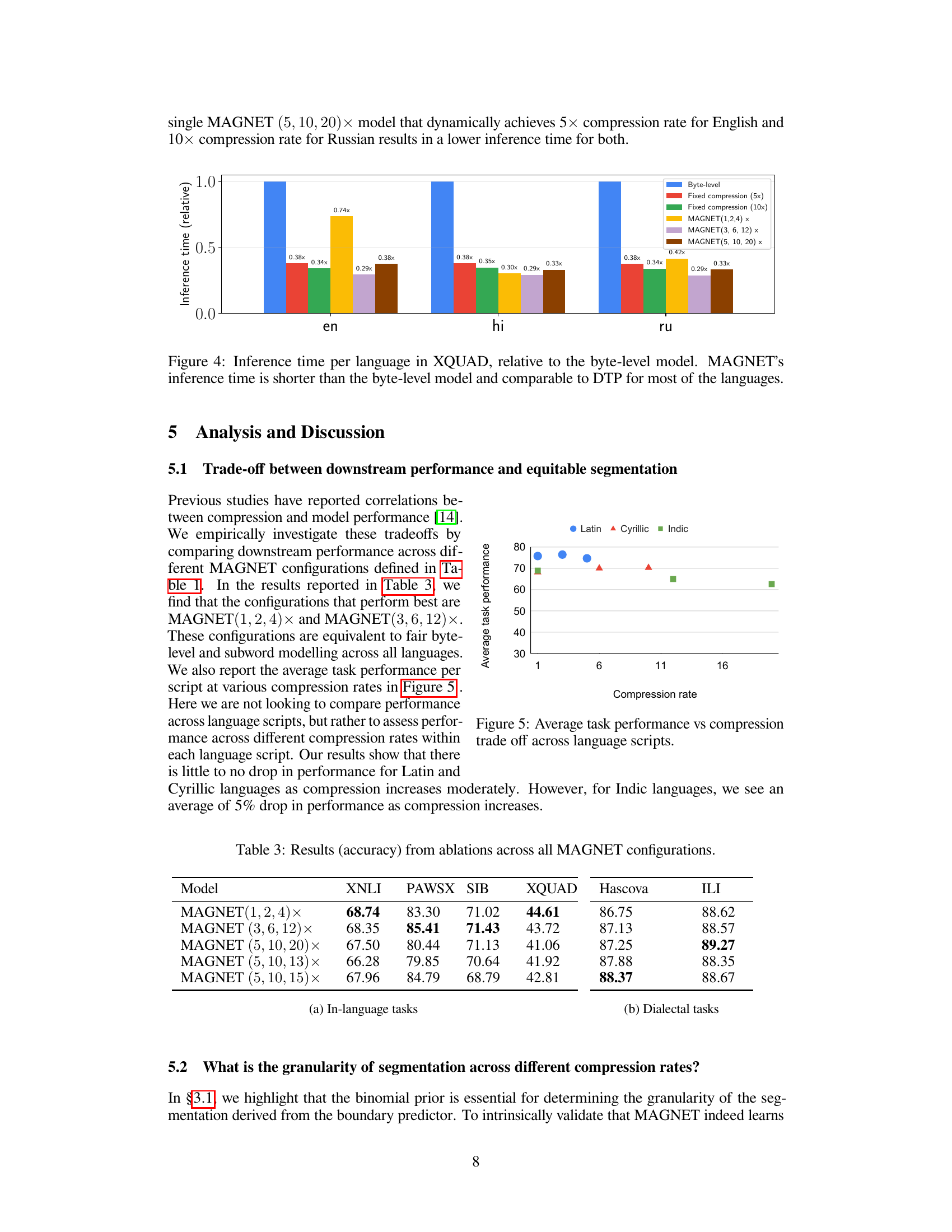
This figure compares the inference time of different language models on the XQUAD question answering task. The inference time for each model is relative to the byte-level baseline model. MAGNET, a multilingual adaptive gradient-based tokenization model, shows faster inference times compared to the byte-level model, and comparable times to Dynamic Token Pooling (DTP), particularly for English and Russian. This demonstrates MAGNET’s efficiency gains, especially noticeable for languages with complex scripts and structures.
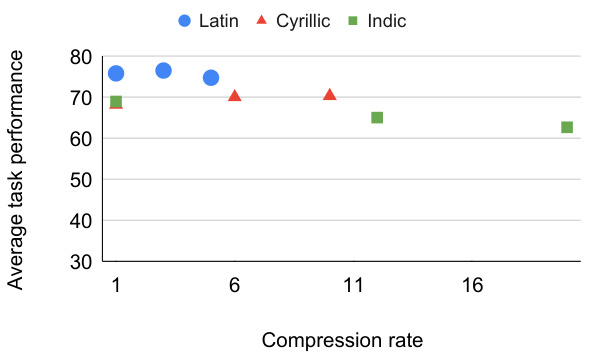
This figure compares the average number of tokens produced by different tokenization methods (byte-level, subword tokenizers, DTP, and MAGNET) when segmenting sentences from the FLORES dataset. It shows that subword tokenizers and the Dynamic Token Pooling (DTP) method, which uses a single boundary predictor across all languages, tend to over-segment non-Latin script languages. In contrast, the Multilingual Adaptive Gradient-Based Tokenization (MAGNET) method achieves more equitable segmentation across all languages.
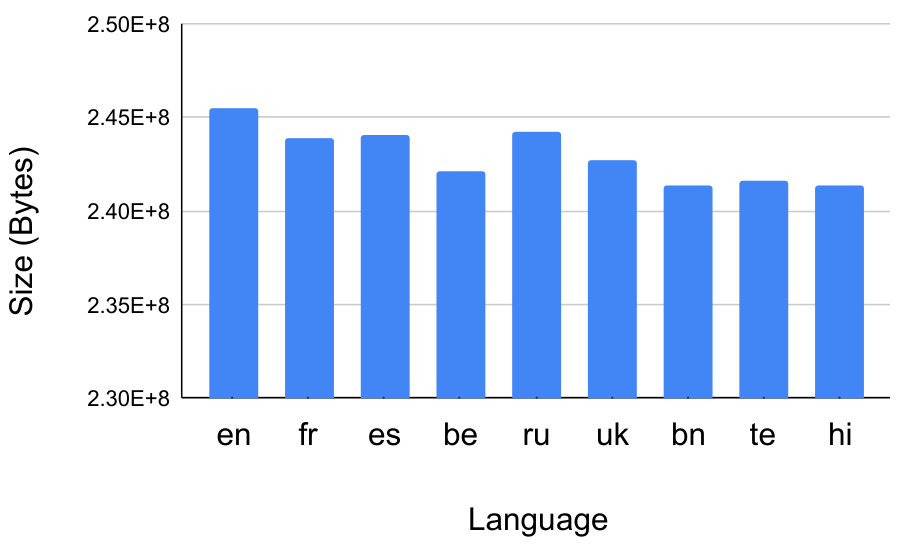
This figure shows the size of the pretraining data in bytes for each of the nine languages used in the paper. The languages are displayed on the x-axis, and the size of the data in bytes is displayed on the y-axis. The data shows a relatively even distribution of data sizes across languages, with some minor variations.
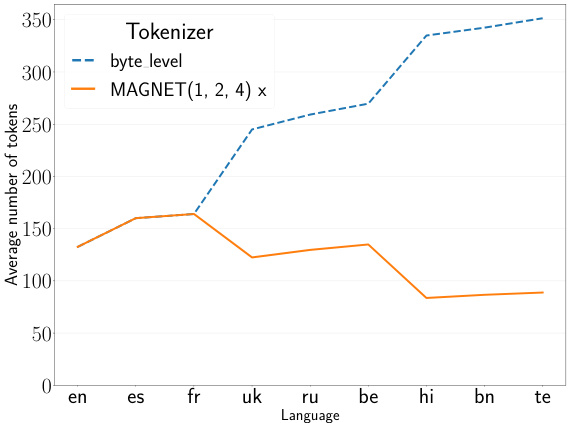
This figure compares the average number of tokens produced by different tokenization methods (byte-level, MAGNET, DTP, and subword tokenizers) across nine languages with varying scripts (Latin, Cyrillic, and Indic). It demonstrates that MAGNET achieves more equitable segmentation across languages compared to other methods, particularly for non-Latin scripts which tend to be over-segmented by traditional methods like byte-level and subword tokenization. The figure visually shows how MAGNET reduces the disproportionate number of tokens generated for low-resource languages (Indic scripts) compared to high-resource ones (Latin scripts).
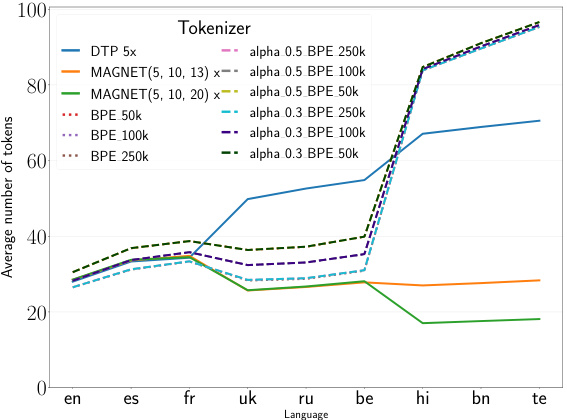
This figure compares the average number of tokens produced by different tokenization methods (MAGNET, DTP, and subword tokenizers) across nine languages with varying scripts. The results show that MAGNET achieves significantly more equitable segmentation than the other methods, which tend to over-segment non-Latin scripts. MAGNET addresses the issue of over-segmentation, particularly in Indic languages, producing token counts that are relatively consistent across languages and scripts, indicating that the amount of information conveyed is relatively the same for the same amount of tokens across languages.

This figure compares the average number of tokens produced by different tokenization methods (byte-level, subword tokenizers, Dynamic Token Pooling (DTP), and MAGNET) when segmenting sentences from the FLORES dataset. The results show that traditional subword tokenizers and DTP tend to over-segment non-Latin script languages, resulting in a much larger number of tokens than for Latin script languages. In contrast, the proposed MAGNET method achieves more equitable segmentation across languages, reducing the disparity in token counts between different scripts. This demonstrates MAGNET’s ability to mitigate over-segmentation issues common in multilingual settings.
More on tables

This table presents the average accuracy scores achieved by different language models (Byte-level, DTP5x, DTP10x, and MAGNET) across several downstream tasks. The best performing MAGNET configuration is highlighted for each task, showing its competitive performance compared to baseline models.
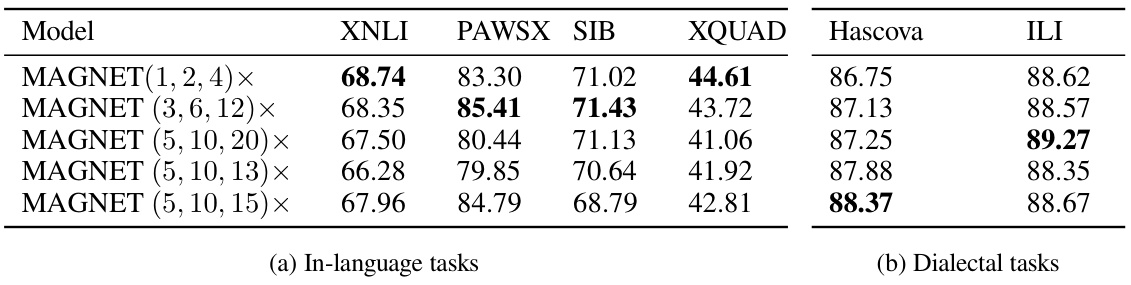
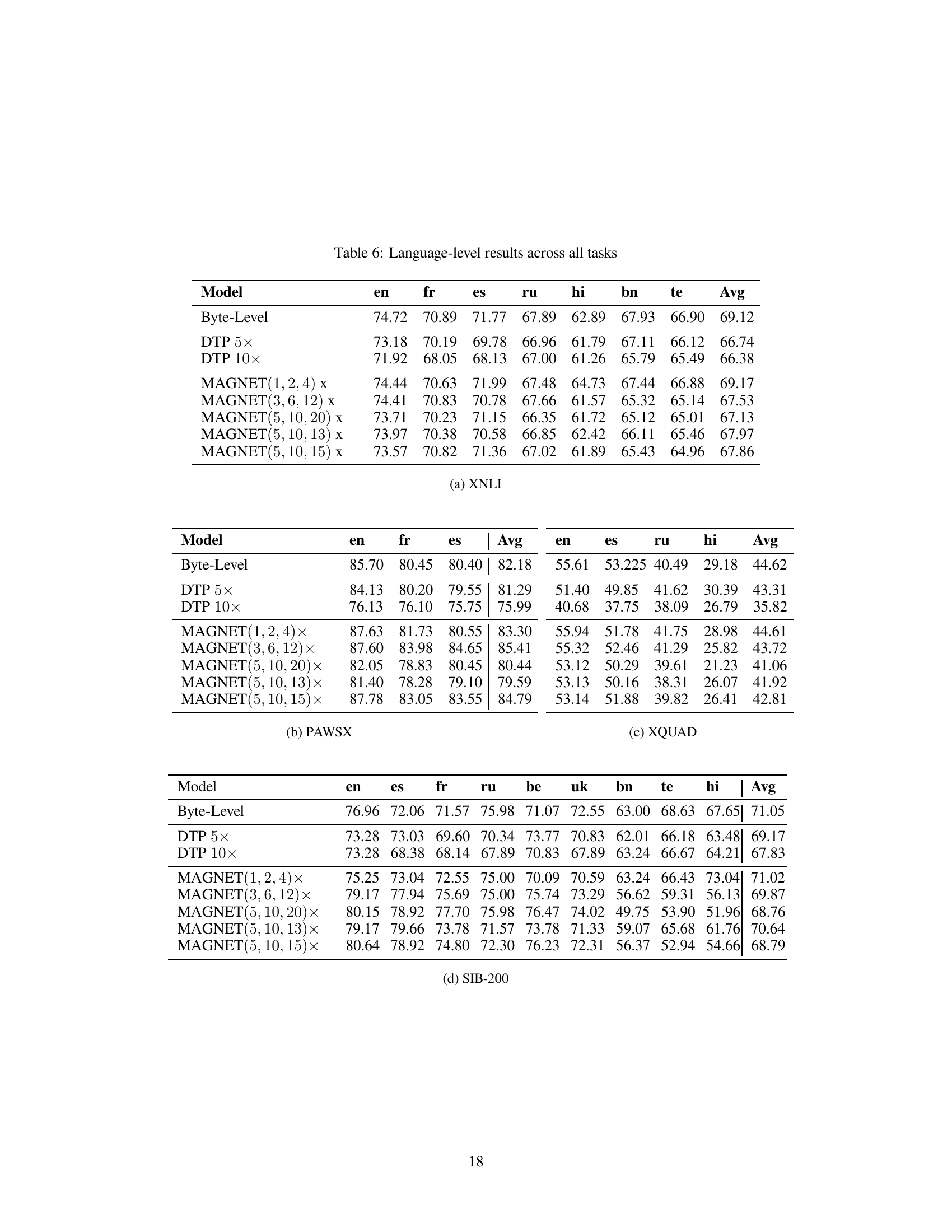
This table presents the average accuracy results across nine different languages for four downstream tasks (XNLI, PAWS-X, SIB, XQUAD) and two dialectal tasks (Hascova and ILI). It compares the performance of the best-performing MAGNET configurations against a byte-level baseline and two Dynamic Token Pooling (DTP) configurations. The best-performing MAGNET configuration varied depending on the task. Bold numbers highlight the best overall accuracy for each task.

This table presents a detailed breakdown of the performance (accuracy) achieved by different language models across various downstream tasks. The models compared include a byte-level baseline, two versions of Dynamic Token Pooling (DTP) with varying compression rates, and several configurations of MAGNET, each with distinct binomial priors. The tasks encompass natural language inference (XNLI), question answering (XQUAD), paraphrase detection (PAWS-X), and topic classification (SIB-200). The table allows for a granular comparison of model performance across languages and tasks, highlighting the impact of different tokenization strategies on downstream task performance.

This table shows the downstream tasks used to evaluate the effectiveness of MAGNET and the languages included in each task. The tasks encompass a range of natural language processing challenges, including natural language inference (XNLI), question answering (XQUAD), adversarial paraphrase identification (PAWS-X), and topic classification (SIB-200). The languages used in each dataset are listed, illustrating the multilingual nature of the evaluation.
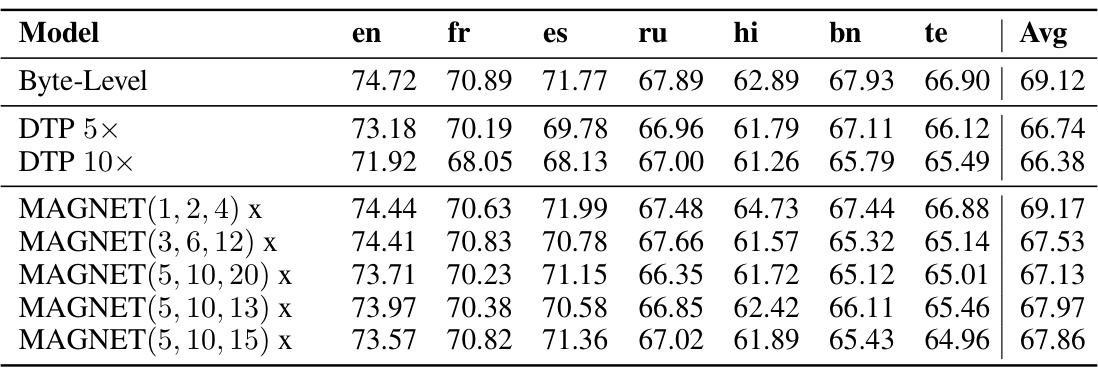
This table presents the average performance (accuracy) across nine different languages (English, Spanish, French, Russian, Ukrainian, Belarusian, Telugu, Bengali, and Hindi) for various downstream tasks using different models. The models compared include a Byte-Level baseline, Dynamic Token Pooling (DTP) with different compression rates (5x and 10x), and MAGNET with multiple configurations. The table showcases the performance of each model for each language and highlights the overall average accuracy.

This table presents the average performance (accuracy) across different downstream tasks and languages, comparing various models including Byte-Level, DTP (Dynamic Token Pooling) with different compression rates, and MAGNET (Multilingual Adaptive Gradient-Based Tokenization) with several configurations. The table shows the performance of each model on XNLI (Natural Language Inference), PAWS-X (Paraphrase Detection), XQUAD (Question Answering), and SIB-200 (Topic Classification) tasks. It allows for a comparison of the different model architectures and hyperparameter settings on language-specific and overall performance.
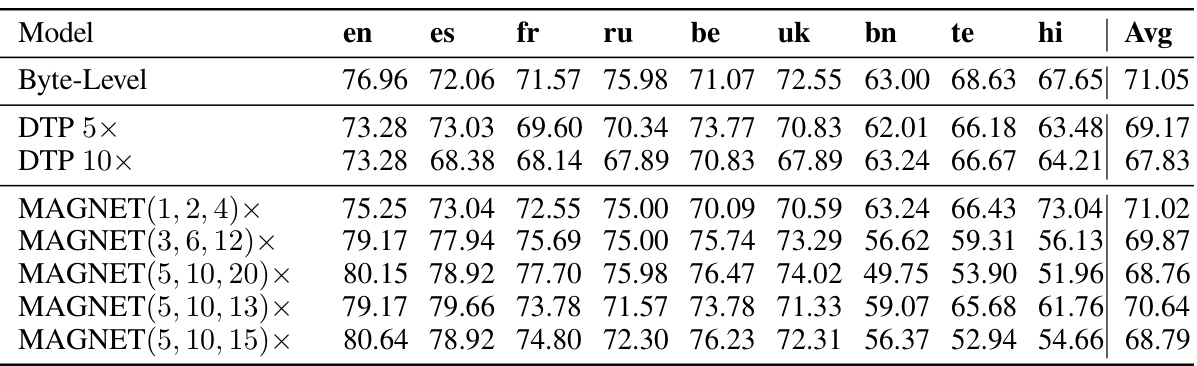
This table presents the language-level accuracy results for several downstream tasks. It compares the performance of different models: a byte-level model, two Dynamic Token Pooling (DTP) models with different compression rates, and five MAGNET models with varying binomial prior combinations. The tasks evaluated include XNLI (natural language inference), PAWS-X (paraphrase detection), XQUAD (question answering), and SIB-200 (topic classification). The table shows that MAGNET models, particularly those with equitable segmentation configurations, generally perform competitively with the byte-level models, which have higher computational cost, while significantly outperforming the DTP models.
Full paper#