↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current AI struggles to understand 3D space as comprehensively as humans do. Existing scene representations, whether metric or topological, fall short in capturing the intricate interplay between places and objects across multiple viewpoints. This paper addresses this limitation by proposing the task of building Multiview Scene Graphs (MSGs) from unposed images. MSGs represent scenes topologically, connecting place and object nodes to explicitly showcase spatial understanding.
The proposed AoMSG model tackles the challenge of joint visual place recognition and object association within a unified Transformer decoder architecture. Experiments demonstrate the superiority of AoMSG over various baselines. The research also introduces a new MSG dataset and evaluation metric to rigorously assess the performance of such methods, further encouraging research in this field and enabling advancements in spatial AI.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel task and benchmark for evaluating spatial intelligence in AI models. The proposed Multiview Scene Graph (MSG) generation task offers a new way to assess the capability of models to understand spatial correspondences, bridging place recognition and object association, which has significant implications for robotics and autonomous navigation. The open-sourced dataset and codebase further facilitate broader research in this emerging area. This work’s significance lies in its potential to improve AI’s understanding of 3D environments, leading to more robust and efficient systems for applications such as autonomous driving, robotics, and virtual reality.
Visual Insights#

This figure illustrates the concept of Multiview Scene Graph (MSG). The input is a set of unposed RGB images from the same scene. The output is a graph where nodes represent places (images taken from the same location) and objects. Edges connect place nodes if they represent images taken from the same place and connect places to the objects observed in those places. The task is challenging as it involves place recognition, object detection, and association.
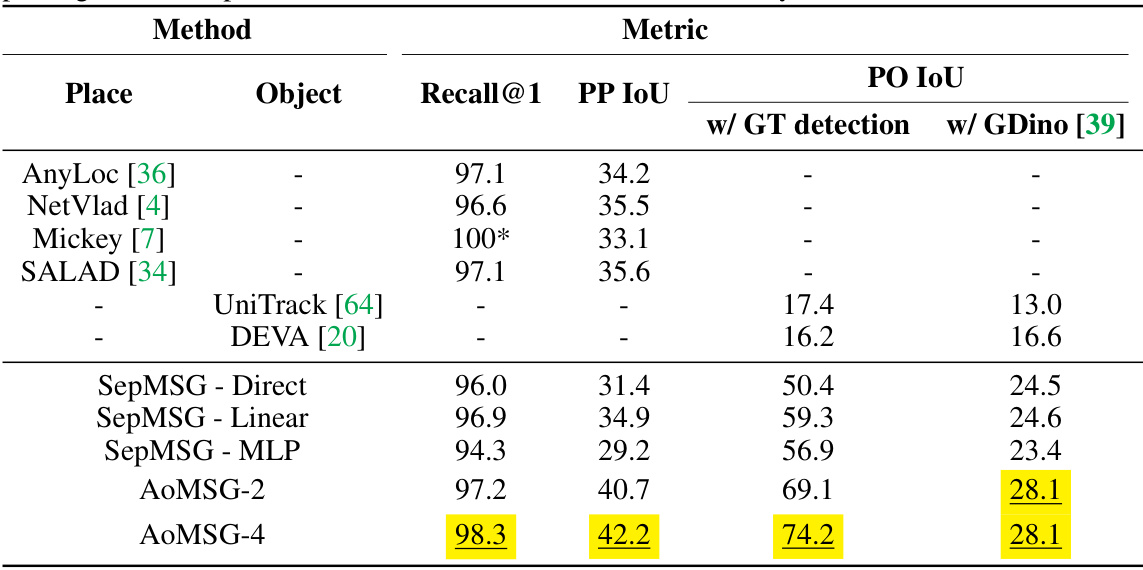
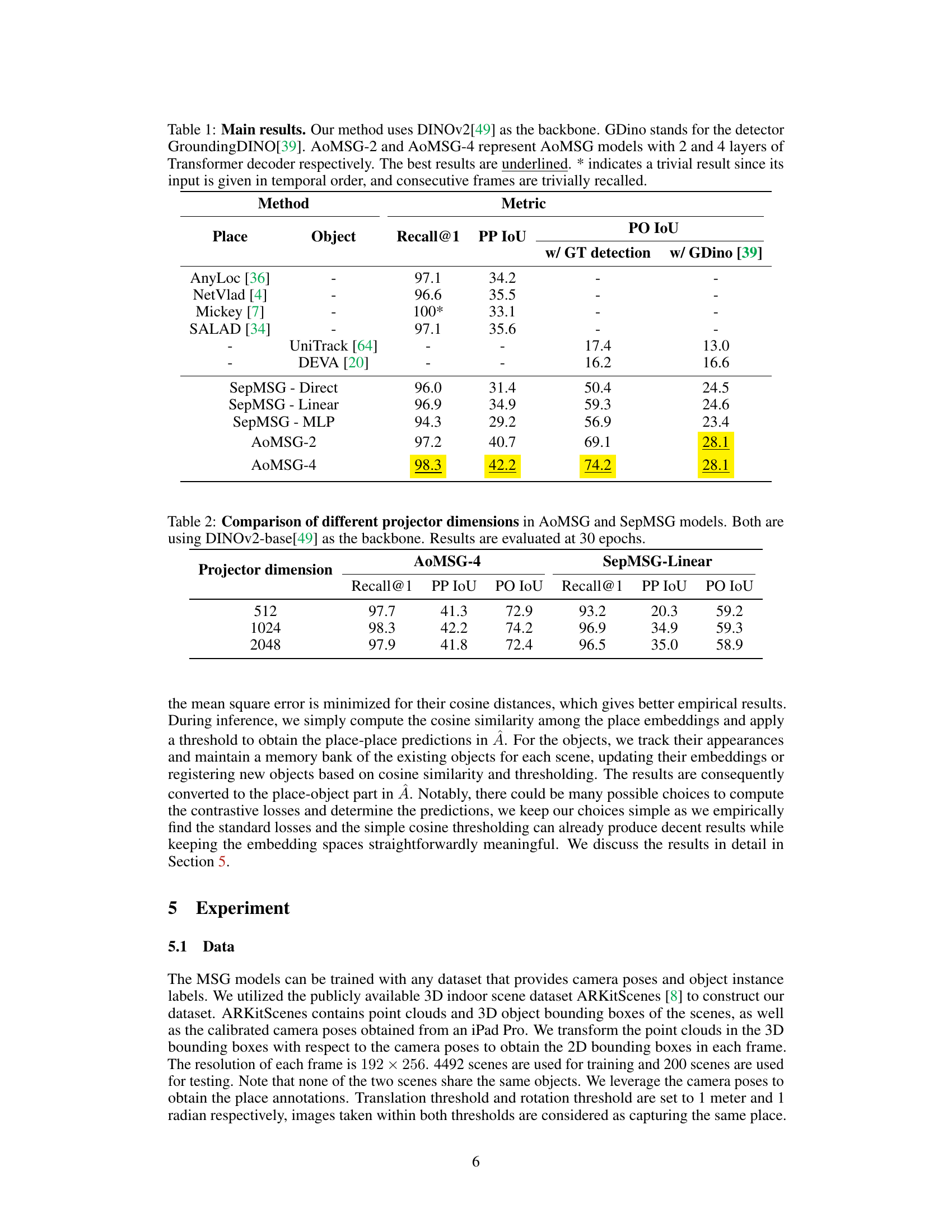
This table presents the main results of the proposed AoMSG model for Multiview Scene Graph (MSG) generation, compared against various baseline methods. The metrics evaluated include Recall@1 (for place recognition), PP IoU (place-place IoU), and PO IoU (place-object IoU). Two versions of PO IoU are shown: one using ground truth object detections and another using the GroundingDINO detector. The table highlights the superior performance of AoMSG-4, particularly in terms of PO IoU.
In-depth insights#
Multiview Scene Graph#
The concept of a “Multiview Scene Graph” presents a novel approach to scene representation, moving beyond traditional metric methods (like 3D point clouds or voxel grids) towards a topological representation. This graph structure interconnects “place” nodes (representing image locations) and “object” nodes (representing identified objects), capturing spatial relationships between them. The method’s strength lies in its ability to handle unposed images with varying viewpoints and limited fields of view, addressing challenges of place recognition and object association jointly. The creation of a dedicated dataset and evaluation metric (based on IoU of graph edges) further strengthens this contribution by enabling robust benchmarking and comparison of different approaches. The proposed transformer-based architecture demonstrates significant improvements over existing baselines, highlighting the potential of this novel representation for applications requiring robust spatial understanding in challenging visual conditions.
AoMSG Model#
The AoMSG (Attention Association Multiview Scene Graph) model is a novel architecture designed for generating multiview scene graphs from unposed images. Its core innovation lies in the joint learning of place and object embeddings within a single Transformer decoder. This contrasts with previous approaches that treated place recognition and object association as separate tasks. By jointly embedding these features, AoMSG leverages the contextual information shared between place and object recognition to improve the accuracy of spatial correspondence. The model uses pretrained vision models for efficient feature extraction, further enhancing its performance. The use of contrastive learning during training further refines the learned embeddings, ensuring that similar places and objects are closer together in the embedding space while dissimilar ones are separated. The AoMSG model represents a significant step forward in topological scene representation by directly addressing the interconnected nature of place and object relationships within a unified framework, achieving superior performance compared to existing baselines.
Spatial Intelligence#
The concept of spatial intelligence, as discussed in the context of the research paper, centers on the ability of agents, both human and artificial, to effectively understand and interact with 3D environments. Human spatial intelligence relies on a topological understanding of space, built from visual observations and commonsense, rather than precise metric measurements. This topological understanding involves associating images of the same location, identifying the same or different objects across viewpoints, and establishing correspondences between visual perceptions. The paper challenges the field to build AI models with comparable spatial understanding. Multiview Scene Graphs (MSGs) are proposed as a valuable tool for evaluating this aspect of AI, offering a topological representation that explicitly captures spatial correspondences between images, places, and objects. The development of an MSG dataset and evaluation metric are also crucial contributions, providing the necessary benchmark to further advance research into robust and efficient spatial intelligence in AI.
Future Research#
Future research directions stemming from this Multiview Scene Graph (MSG) work could explore several promising avenues. Extending the MSG framework to handle dynamic scenes is crucial for real-world applicability, requiring robust object tracking and association techniques capable of managing appearances across significant temporal gaps. Integrating more sophisticated object recognition models may significantly enhance performance, particularly in cases of partial occlusion or ambiguous object instances. Investigating the use of larger, more diverse datasets will be essential to validate the generalizability of MSG and its inherent capacity to handle a broader range of scenes and objects. Finally, exploring downstream applications of MSG-generated graphs, such as scene understanding, robot navigation, or visual question answering, will allow evaluation of the model’s real-world efficacy and provide insights for further refinement and optimization.
Limitations#
The research paper’s limitations section should thoroughly address the constraints and shortcomings of the study. Dataset limitations are crucial; specifying the size, diversity, and potential biases within the dataset is essential, particularly for a novel task. The paper should acknowledge potential issues with the generalizability of the findings if the dataset is limited in scope or lacks representativeness. Another significant aspect is methodological limitations. The authors must acknowledge any assumptions made during model development or evaluation, discussing the robustness of the results under different conditions. The evaluation metrics used should also be critically analyzed. While IoU is appropriate for graph-based evaluations, the paper should discuss its limitations, such as the sensitivity to variations in the number of nodes. Lastly, the paper needs to discuss the computational cost and scalability of the proposed methodology. The feasibility of deploying the model to resource-constrained devices or larger-scale applications should be explicitly addressed. Future work should outline directions for addressing these limitations.
More visual insights#
More on figures
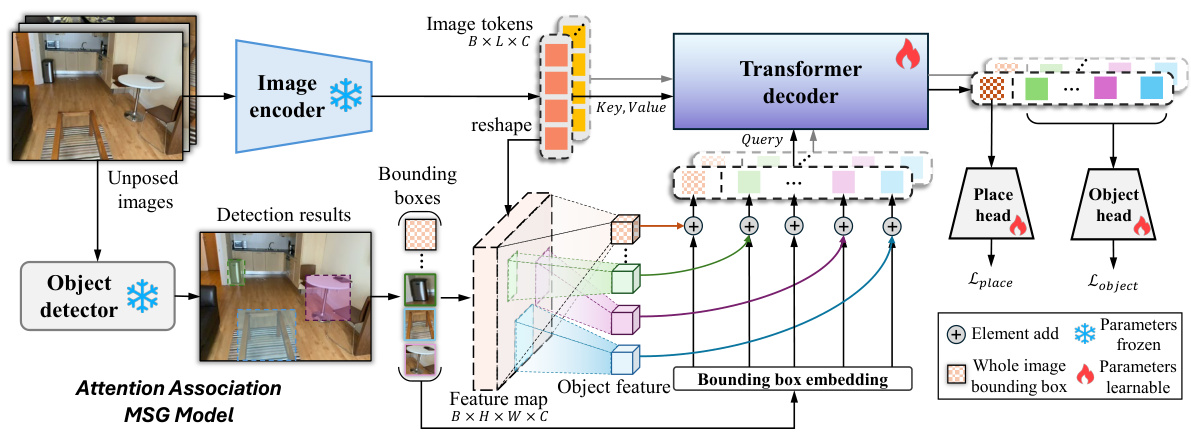
This figure illustrates the architecture of the Attention Association Multiview Scene Graph (AoMSG) model. The model takes unposed RGB images as input. It uses a pretrained image encoder (like DINOv2) and object detector to extract image features and object bounding boxes. These bounding boxes are used to crop the feature maps, generating place and object queries. These queries are fed into a Transformer decoder. The decoder jointly learns place and object embeddings, which are then projected through linear heads for final embeddings used in the MSG generation. The pre-trained image encoder and object detector parts of the model are frozen during training; only the Transformer decoder and projection heads are trained using a supervised contrastive loss function.
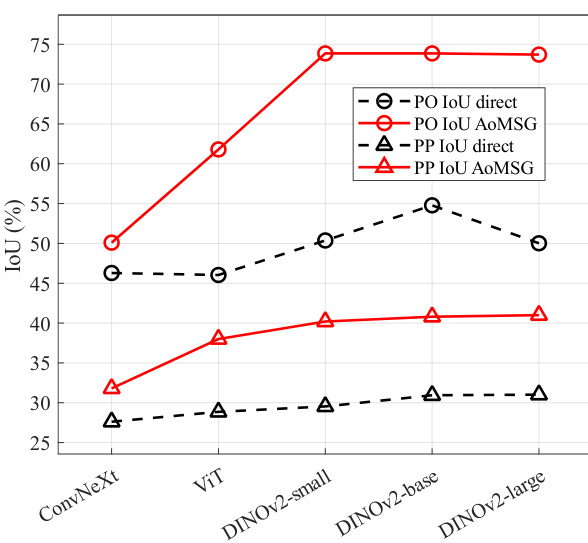
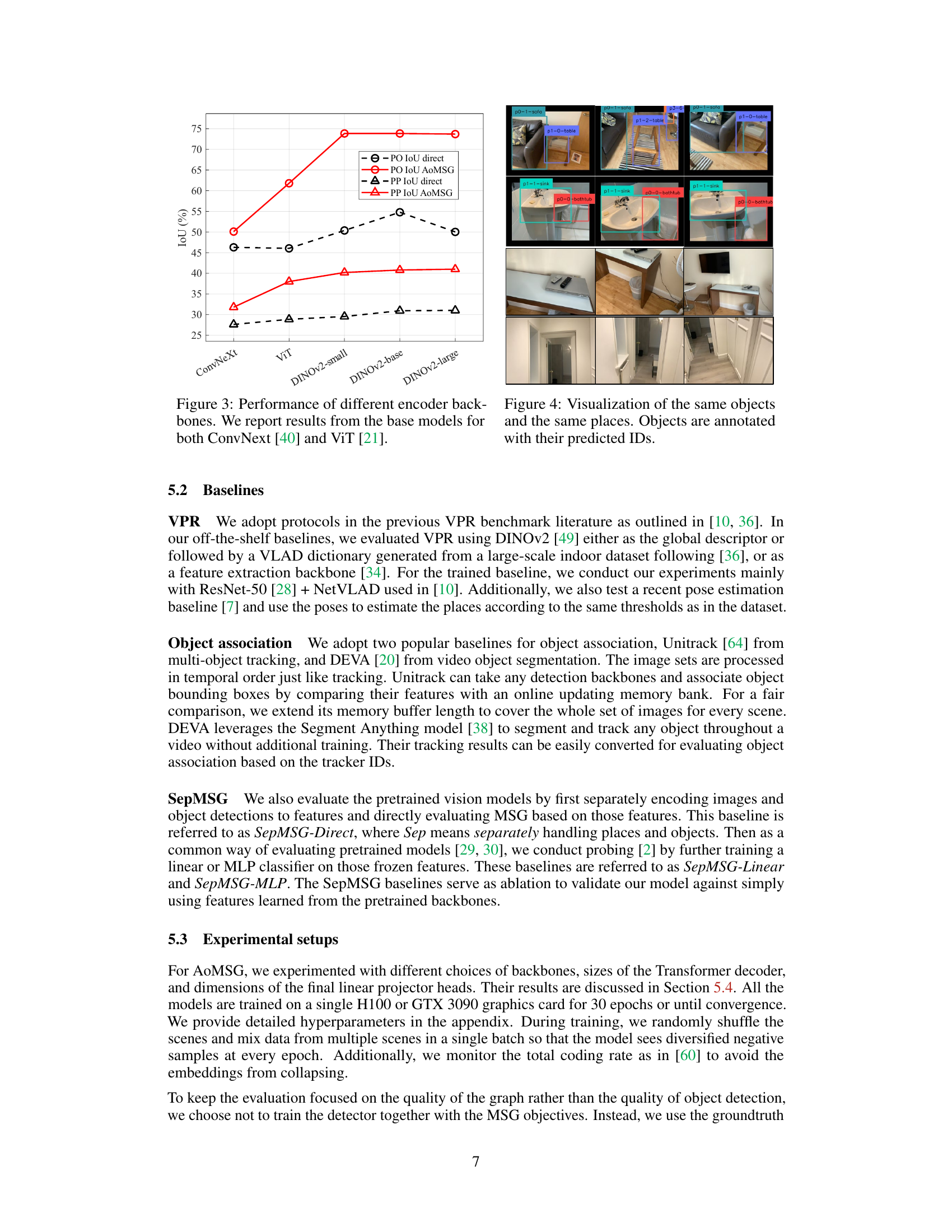
This figure shows the performance comparison of different encoder backbones, specifically ConvNeXt and Vision Transformer (ViT), on the task of Multiview Scene Graph (MSG) generation. The x-axis represents different backbones (ConvNeXt, ViT, and different sizes of DINOv2), while the y-axis shows the IoU (Intersection over Union) scores for both place-place edges (PP IoU) and place-object edges (PO IoU). The results are split into direct (without the proposed AoMSG model) and AoMSG (with the proposed AoMSG model). This visualization helps to understand the impact of the choice of backbone on the overall performance of the MSG generation task, highlighting the effectiveness of the DINOv2 model.

This figure illustrates the task of Multiview Scene Graph (MSG) generation. The input is a set of unposed RGB images from a single scene. The output is a graph where nodes represent places (images taken from similar viewpoints) and objects. Edges connect places to each other (if they are visually similar) and connect places to the objects observed in those places. The key is that the same object detected in multiple images is represented as a single node connected to all the places where it’s seen. This topological representation aims to capture spatial relationships without explicit metric information (like distances or poses).

This figure visualizes the learned object embeddings using t-SNE, a dimensionality reduction technique. It compares three different models: SepMSG-Direct, SepMSG-Linear, and AoMSG-2. Each row represents a model, and each column represents a different scene. Points of the same color represent the same object, showing how well the models cluster appearances of the same object together. The visualization helps assess how effectively each model separates different objects in the embedding space, which is crucial for object association.

This figure showcases a real-world application of the proposed MSG method. It demonstrates how MSG can be combined with an off-the-shelf 3D reconstruction model (Dust3r) to create local 3D reconstructions of scenes. The left and right columns display two different scenes, each containing a 3D reconstruction, topological map generated from the MSG, and a 3D mesh. The MSG identifies subgraphs, and these subgraphs are used by Dust3r to create the 3D reconstructions. This approach is particularly useful when dealing with large-scale datasets since it breaks down the task into smaller, manageable subproblems. The figure highlights the complementary nature of MSG and 3D reconstruction models. MSG provides a topological map of the scene, which guides the 3D reconstruction process to produce more accurate and efficient local models.
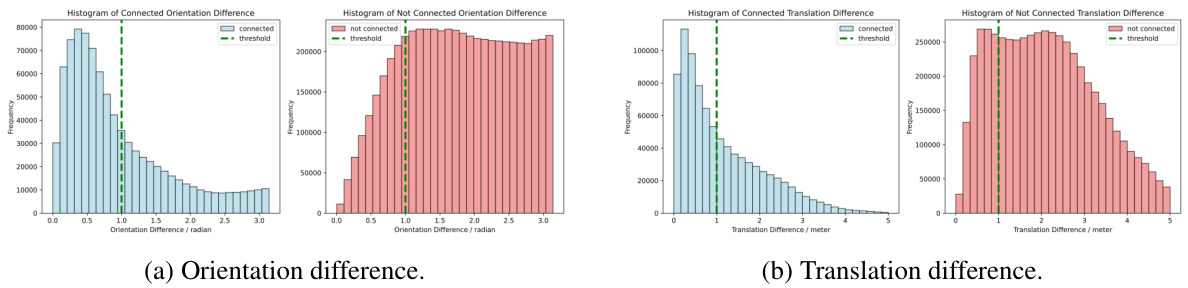
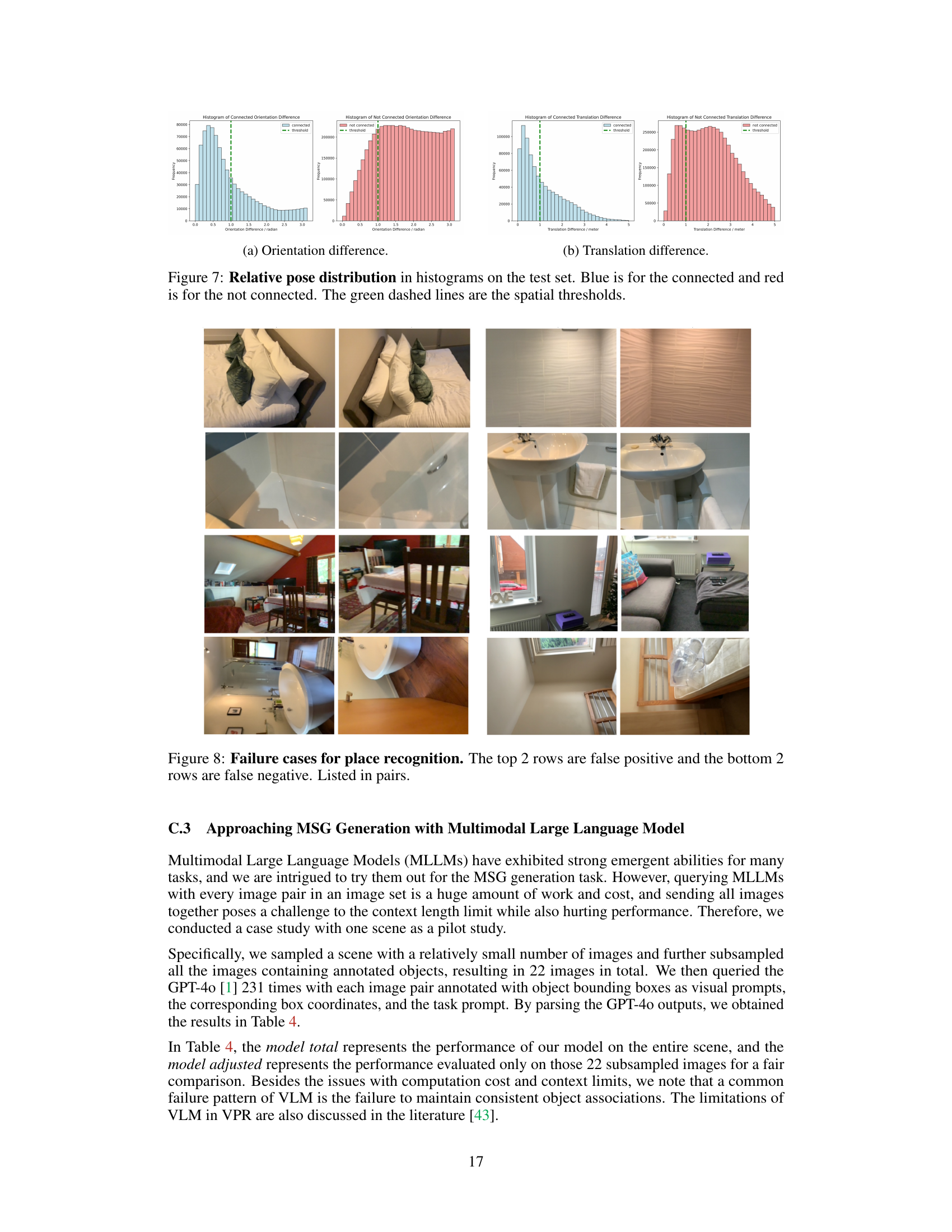
This figure visualizes the relative pose distributions (orientation and translation) for connected and non-connected nodes in the MSG graph on a test set. The histograms show the frequency of various orientation and translation differences between node pairs. The blue bars represent connected nodes (i.e., images taken at the same place in the scene), and red bars show non-connected nodes. The green dashed lines indicate the thresholds used to determine if two images are considered to be at the same place; pairs with pose differences exceeding these thresholds are classified as non-connected. The distributions clearly show separation between connected and non-connected nodes, illustrating the model’s ability to distinguish spatial proximity accurately.

This figure visualizes the ‘place nodes’ from the generated Multiview Scene Graph (MSG). It demonstrates how the model groups images taken at the same physical location. Sets of three images are shown together; these images are connected as nodes in the MSG because the model infers that they depict the same place in the scene, despite potential differences in viewpoint or lighting.
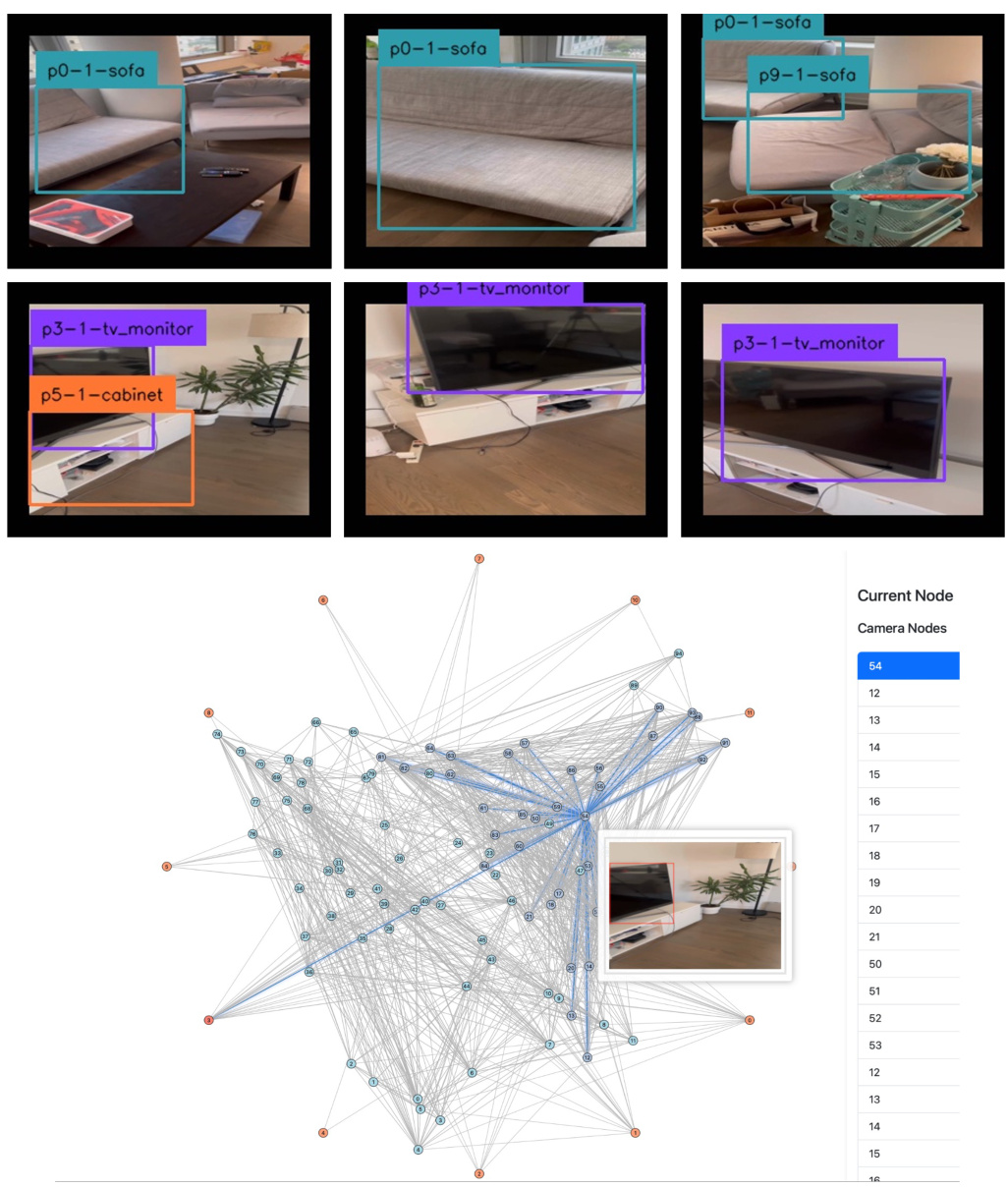
This figure shows a qualitative real-world experiment using the proposed AoMSG model. The top part displays example images from a real-world video, with object instances labeled using their predicted IDs. The bottom part presents an interactive graph visualization of the scene, illustrating the connections between place nodes (images) and object nodes, showcasing the model’s ability to create a scene graph from a real-world video.

This figure visualizes the ‘place’ nodes in the Multiview Scene Graph (MSG). It groups sets of three images together. The images within each group are visually similar and were determined by the model to have been taken at the same location in the scene. This helps demonstrate the model’s ability to recognize and cluster images captured from the same viewpoint, despite variations in camera angle or lighting.

This figure illustrates the Multiview Scene Graph (MSG) task. Given a set of unordered RGB images from a single scene, the goal is to generate a graph representing the scene’s spatial structure. The graph consists of two types of nodes: place nodes (representing locations in the scene, each corresponding to an image) and object nodes (representing objects, with the same object appearing in multiple images merged into a single node). Edges connect place nodes that are spatially close to each other and connect place nodes to the object nodes they contain. This graph explicitly represents the spatial relationships between places and objects.
More on tables

This table compares the performance of AoMSG and SepMSG models with varying projector dimensions (512, 1024, and 2048). The backbone used for both models is DINOv2-base. The results, including Recall@1, PP IoU, and PO IoU, are reported for each model and projector dimension after 30 training epochs. This allows for an analysis of how the projector dimension affects the performance of the two models on the multiview scene graph generation task.

This table presents the main results of the proposed AoMSG model and compares it with other baseline methods on the Multiview Scene Graph (MSG) task. The metrics used for evaluation include place and object recall, place-place IoU (PP IoU), place-object IoU (PO IoU), and are calculated with and without ground truth object detection. Different variants of AoMSG (with varying numbers of transformer decoder layers) are compared, highlighting the superior performance of the proposed method across various metrics.
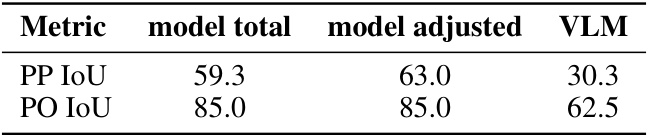
This table presents a pilot study comparing the performance of a multimodal large language model (MLLM) and a vision-language model (VLM) on the Multiview Scene Graph (MSG) task. The results are shown for two metrics: PP IoU (Place-Place Intersection over Union) and PO IoU (Place-Object Intersection over Union). The ‘model total’ column shows the MLLM’s performance on the entire scene, while the ‘model adjusted’ column shows its performance on a subset of images (22 images) comparable to the VLM’s input. The VLM column presents the VLM’s performance on the same subset of images. The results indicate the potential benefits of MLLMs for MSG generation, although further research is needed.
Full paper#