↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many communication games, such as One Night Ultimate Werewolf (ONUW), require players to employ strategic discussion tactics to succeed. Existing LLM-based agents often lack the control over discussion tactics, hindering their performance. This paper explores the strategic aspect of discussion by analyzing Perfect Bayesian Equilibria in ONUW and shows that discussion changes players’ utilities by affecting their beliefs.
To address this, the authors propose an RL-instructed language agent framework that uses reinforcement learning (RL) to train a discussion policy. This policy helps determine optimal discussion tactics based on current observations. Experiments across different ONUW game settings demonstrate the effectiveness and generalizability of the framework, highlighting that integrating RL-trained discussion policies improves the performance of LLM-based agents compared to agents that simply use LLMs directly. This demonstrates the significance of incorporating strategic communication policies in AI agents designed for complex communication scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it demonstrates the crucial role of strategic communication in game playing and introduces a novel framework combining reinforcement learning and LLMs. It offers new avenues for research in AI agents and communication strategies, pushing the boundaries of LLM applications in complex interactive environments. This work bridges the gap between theoretical game analysis and practical AI agent design, and is highly relevant to current research trends in multi-agent systems, game AI, and human-computer interaction.
Visual Insights#
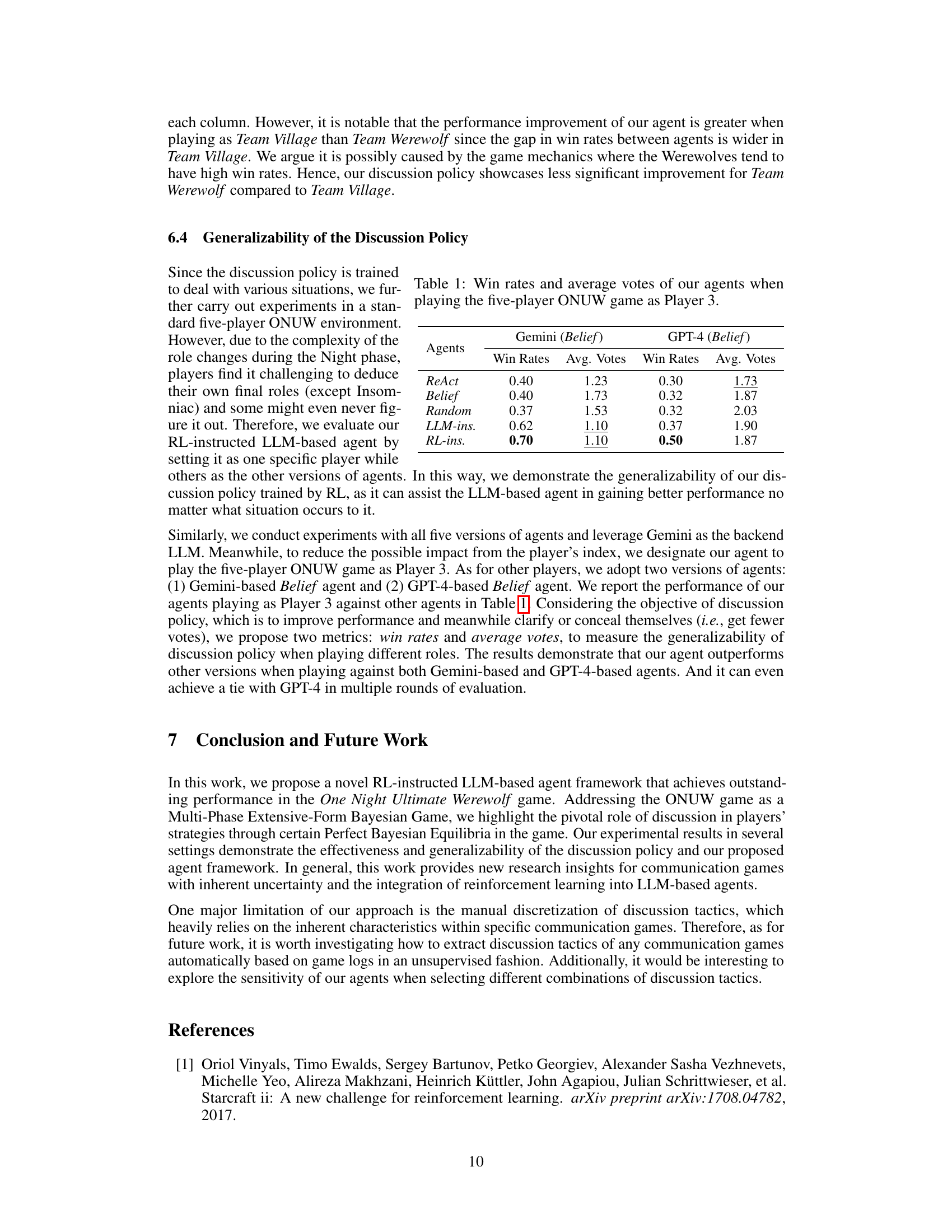
This figure illustrates the game process of One Night Ultimate Werewolf (ONUW). It starts with random role assignment to players, followed by three phases: Night phase (where players with special abilities perform actions secretly), Day phase (where players openly discuss and deduce roles), and Voting phase (where players vote to eliminate a suspected werewolf). The game ends with a win for either the Werewolves or the Villagers, determined by the voting outcome.
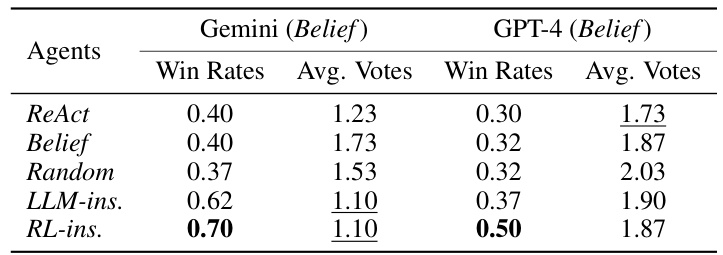
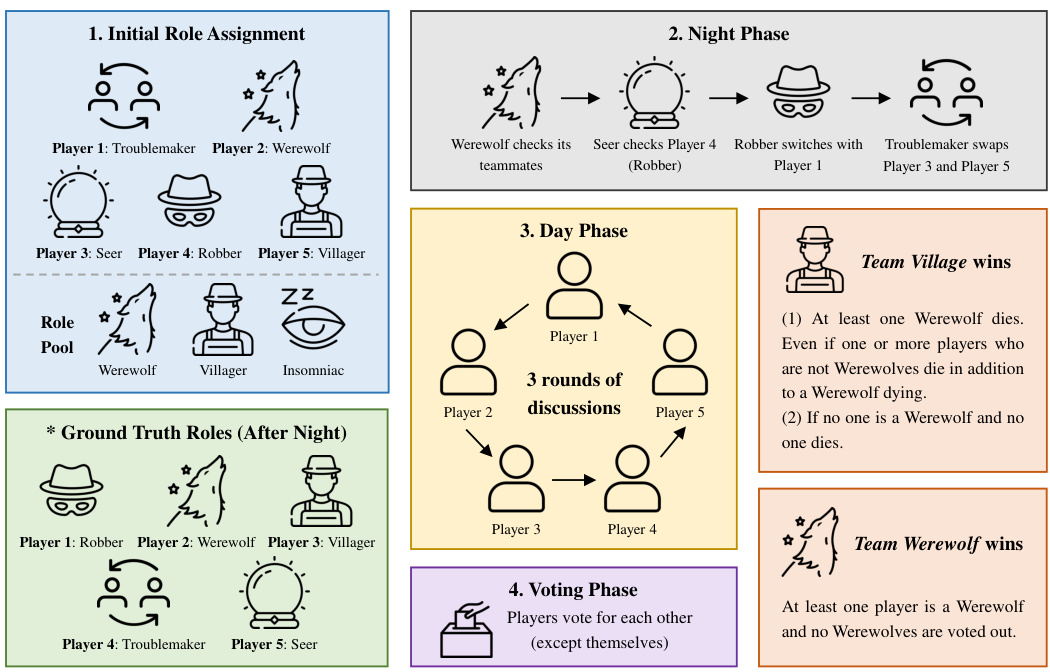
This table presents the results of experiments conducted using five-player ONUW games. The RL-instructed (RL-ins.) and LLM-instructed (LLM-ins.) agents are compared against the baseline ReAct agent and two ablated versions (Belief and Random). The table shows the win rates and average number of votes received by each agent when playing as Player 3. The results demonstrate that the RL-ins. agent generally outperforms other agents, achieving higher win rates and fewer votes received. The difference in performance between RL-ins. and LLM-ins. highlights the effectiveness of the RL-trained discussion policy.
In-depth insights#
Strategic Discussion#
Strategic discussion in multi-agent games like One Night Ultimate Werewolf (ONUW) involves deliberate communication tactics to influence other players’ beliefs and actions. It’s a crucial element, surpassing the simple exchange of information. Success hinges on choosing whether to be honest, deceptive, or a combination, and adapting tactics based on observed player behavior and evolving game state. Perfect Bayesian Equilibria (PBE) analysis reveals how the presence or absence of strategic discussion significantly impacts player utilities and game outcomes. Reinforcement learning (RL) emerges as a powerful tool for training AI agents to master strategic discussion in ONUW. RL-trained agents learn to dynamically select tactics (e.g., honest evidence, deceptive accusations), maximizing their chances of victory. The study demonstrates the effectiveness of RL in creating AI that not only understands the information but also the nuanced strategies within the game’s dynamic social environment.
RL-LLM Framework#
An RL-LLM framework synergistically combines reinforcement learning (RL) and large language models (LLMs) to enhance agent capabilities. RL provides the strategic decision-making component, learning optimal policies through trial and error within the game environment. LLMs contribute the natural language processing and generation capabilities, enabling agents to interact effectively through textual communication. This framework is particularly effective in complex games with significant communication elements, allowing for sophisticated strategic planning and adaptation. The strength lies in the complementary nature of RL and LLMs; RL addresses strategic depth, while LLMs handle the nuances of natural language. However, challenges remain: effective integration requires careful design, balancing computational cost with performance gains. Also, the reliance on LLMs introduces inherent limitations, such as potential biases and inconsistencies in language generation, and the need for data-driven training to avoid overfitting.
ONUW Game Analysis#
The analysis of the One Night Ultimate Werewolf (ONUW) game likely involved a formal game-theoretic approach, possibly framing it as a Bayesian game due to the incomplete information and hidden roles. Key aspects likely explored include the concept of Perfect Bayesian Equilibrium (PBE), analyzing the optimal strategies for players given their private information and the actions of others. The analysis might have considered scenarios with and without discussion phases to highlight the strategic impact of communication. A crucial finding could be the demonstration of how discussion significantly alters player utilities, shifting outcomes from those in a silent version of the game. This would underscore the importance of strategic communication in ONUW, where deception and information control are pivotal. The study might focus on specific scenarios with a limited number of players and roles, analyzing the decision-making process and beliefs formed during the night and day phases. The outcome could include a theoretical understanding of strategic gameplay, potentially revealing unexpected equilibria or optimal strategies that contrast with intuitive approaches. This in-depth game analysis would thus provide a strong foundation for developing effective AI agents capable of strategic decision-making in the ONUW game.
Discussion Tactics RL#
Reinforcement learning (RL) applied to discussion tactics in strategic games presents a compelling area of research. The core idea is to train an AI agent to select optimal discussion strategies within the context of a game, improving its performance by learning effective communication behaviors. This involves defining a suitable reward function that incentivizes desirable discussion tactics, like providing honest evidence or deceptive accusations depending on the game’s objective. A crucial challenge lies in representing the complex and nuanced nature of human language and strategic communication in a way that is suitable for RL training. This likely requires careful feature engineering to capture relevant aspects of conversations and a method to discretize or otherwise manage the vast action space of possible utterances. Further research should investigate techniques for dealing with partial observability, as agents do not always have access to complete information, requiring them to make inferences and decisions based on imperfect knowledge. Finally, evaluating the effectiveness of these RL-trained agents requires careful experimentation, possibly against both human and other AI opponents to assess generalization ability and robustness in varied gameplay scenarios.
Future Work#
The paper’s ‘Future Work’ section suggests several promising avenues. Addressing the limitations of manual discussion tactic discretization is crucial. The authors acknowledge the current method’s limitations and propose exploring unsupervised techniques to automatically extract discussion tactics from game logs, thereby improving generalizability across different communication games. Further investigation into the sensitivity of agent performance to various combinations of discussion tactics is also warranted. This would involve a deeper exploration of the strategic interplay between different communication styles and their impact on game outcomes. Finally, extending the research to other social deduction games beyond One Night Ultimate Werewolf is a significant direction. This would provide a broader validation of the proposed RL-instructed LLM framework and allow for a more comprehensive understanding of strategic communication in diverse game contexts. The overall goal is to create a more robust and adaptable framework applicable across a wider range of games and communication scenarios.
More visual insights#
More on figures

This figure shows the extensive-form game tree for a three-player One Night Ultimate Werewolf game with discussion, where Player 1 and Player 2 are Werewolves, and Player 3 is the Robber. The tree illustrates the sequential decision-making process during the Night, Day, and Voting phases. The Night phase shows the actions of each player in sequence (Werewolf, Seer, Robber). The Day phase depicts Player 3’s potential discussion strategies, represented by dotted lines connecting to different decision nodes. Each path through the tree leads to a terminal node that assigns utilities to each player, indicating the outcome of the game. The utilities are listed at the bottom of the tree and organized by player.
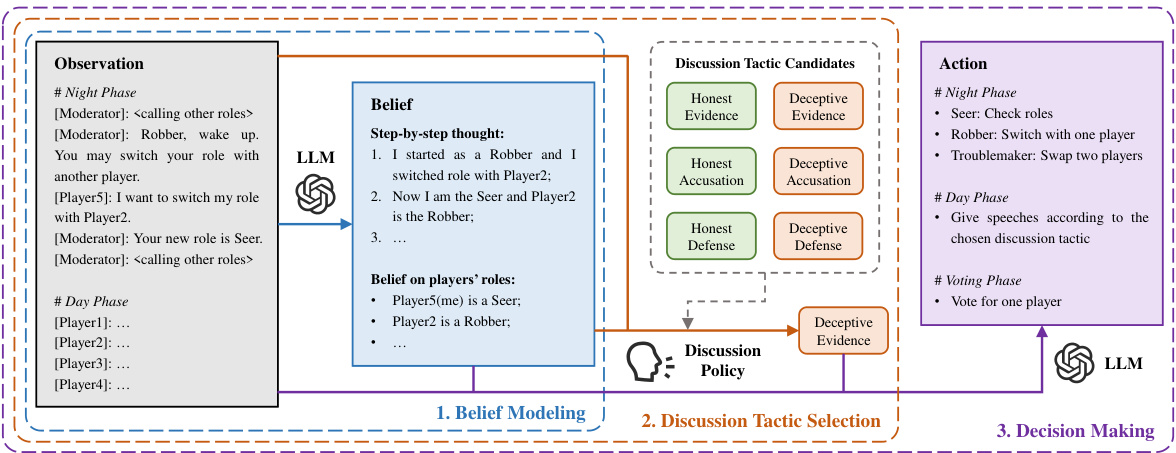
This figure illustrates the RL-instructed LLM-based agent framework proposed in the paper. It shows the three main components of the agent: Belief Modeling, which uses an LLM to form beliefs about other players’ roles; Discussion Tactic Selection, which uses a reinforcement learning (RL)-trained policy to choose an appropriate discussion tactic; and Decision Making, which uses an LLM to generate actions based on the beliefs, chosen tactic, and current game phase. The figure details the flow of information and decision-making within the agent’s framework.
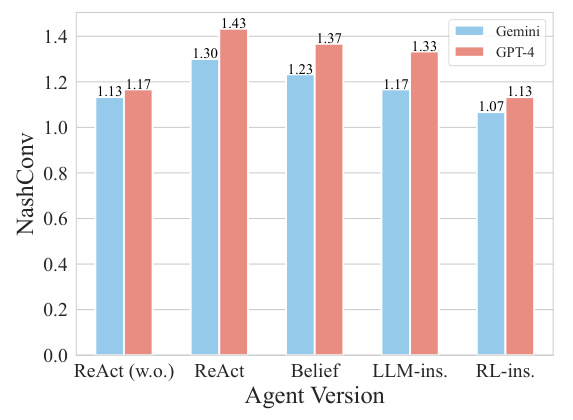
This figure shows the NashConv values achieved by different agent versions playing in a three-player One Night Ultimate Werewolf (ONUW) game. NashConv is a metric representing how close an agent’s strategy is to a Nash Equilibrium. Lower values indicate a strategy closer to equilibrium. The agent versions include: ReAct (without discussion), ReAct (with discussion), Belief (LLM-based agent without discussion policy), LLM-instructed (LLM-based agent with LLM-trained discussion policy), and RL-instructed (LLM-based agent with RL-trained discussion policy). The figure compares the performance of these agents using two different large language models (LLMs) as backends: Gemini and GPT-4. The results show that the RL-instructed agent generally performs best, showcasing the effectiveness of the reinforcement learning-trained discussion policy in approximating Nash Equilibria.

This figure shows the win rates of Team Village in different settings of a five-player ONUW game. Two settings are compared: an easy setting and a hard setting. Within each setting, the win rates are shown for different agent types playing as Team Village against different agent types playing as Team Werewolf. The agent types are ReAct, Belief, LLM-instructed, and RL-instructed. The figure demonstrates the impact of different game difficulty levels and agent types on team success.

This figure shows the game tree for a three-player One Night Ultimate Werewolf (ONUW) game with discussion, where Player 1 and Player 2 are Werewolves, and Player 3 is a Robber. The tree illustrates the sequential decision-making process, starting with the Robber’s night action (switching roles or not), followed by the day phase (where Player 3 can make various speeches), and finally the voting phase. The dotted lines represent information sets, indicating points where a player has the same information and thus makes the same decision. The numbers at the end of each branch represent the utilities (payoffs) for each player in the final outcome of the game.

This figure illustrates the three phases of the One Night Ultimate Werewolf (ONUW) game: the Night phase where players secretly perform actions based on their roles; the Day phase with three rounds of open discussion among players to deduce roles and strategize; and the Voting phase where players vote to eliminate a suspected werewolf. The game’s outcome is determined by whether the werewolves or villagers win based on the voting result.

This figure shows the three phases of the One Night Ultimate Werewolf (ONUW) game: the Night phase (where players secretly perform their role abilities), the Day phase (where players openly discuss and try to deduce each other’s roles), and the Voting phase (where players vote to eliminate a suspected werewolf). The diagram visually depicts the sequential order of these phases and the actions taken within each phase, concluding with the determination of the winning team based on the voting outcome.

This figure illustrates the three phases of the One Night Ultimate Werewolf (ONUW) game: the Night phase where players secretly perform actions based on their roles; the Day phase where players engage in three rounds of open discussion to deduce each other’s roles; and the Voting phase where players vote to eliminate a suspected werewolf. The figure shows an example of role assignments and the flow of actions in each phase, highlighting the sequential nature of gameplay and the importance of strategic discussion.

This figure shows the three phases of the One Night Ultimate Werewolf (ONUW) game: Night, Day, and Voting. The Night phase illustrates the actions performed by each role sequentially. The Day phase shows the three rounds of discussion among players. The Voting phase depicts how players vote to eliminate a suspected player. The game’s outcome depends on whether Team Werewolf or Team Village wins based on the players who remain at the end.

This figure illustrates the three phases of the One Night Ultimate Werewolf (ONUW) game: the Night phase where players secretly perform actions based on their roles; the Day phase where players openly discuss and deduce each other’s roles; and the Voting phase where players vote to eliminate a suspected werewolf. The diagram visually represents the sequential nature of the gameplay and how each phase contributes to determining the winner (Werewolves or Villagers).
More on tables

This table shows the percentage of different discussion tactics that GPT-4 selects for each initial role in the dataset. It demonstrates GPT-4’s tendency to be deceptive when playing on Team Werewolf and honest when playing on Team Village, aligning with game objectives. The Robber and Insomniac show higher deceptive frequencies than other Team Village roles, potentially due to their ability to re-check their roles and adapt their discussion strategy.
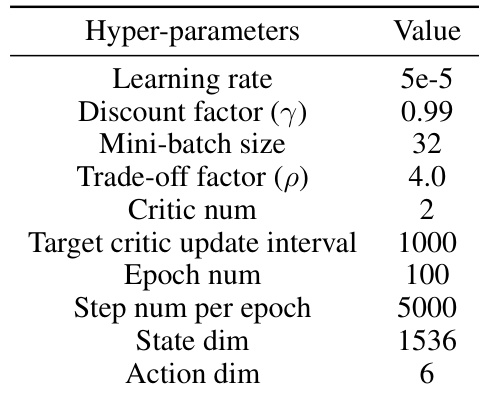
This table lists the hyperparameters used for training the Conservative Q-Learning (CQL) algorithm, including the learning rate, discount factor, mini-batch size, trade-off factor, critic number, target critic update interval, epoch number, steps per epoch, state dimension, and action dimension.

This table shows the initial and final roles of each player in the easy setting of the five-player ONUW game. The changes reflect the actions taken during the night phase, such as the Robber switching roles with another player and the Troublemaker swapping the roles of two other players. This setting is used in the experiments to evaluate the performance of the proposed RL-instructed LLM-based agent.
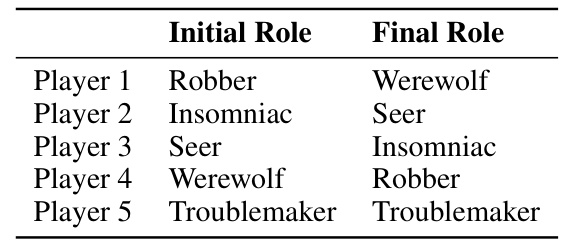
This table shows the initial and final roles of each player in a hard setting of the five-player ONUW game. The hard setting introduces additional complexity compared to the easy setting due to specific actions taken by the Robber and Troublemaker during the night phase, which changes the final roles of the players.
Full paper#