↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) can produce false statements, thus methods for detecting LLM lies are needed. Prior research used classifiers based on internal model activations but these lacked generalization. This work identified a key limitation in prior methods: using only affirmative statements in training data, hindering generalization to negated statements. This limitation is addressed by introducing a novel approach.
This paper proposes a new method for detecting LLM lies by identifying a two-dimensional subspace in the LLM’s activation vectors. This subspace effectively separates true and false statements, even negated ones, across different LLMs (Gemma-7B, LLaMA2-13B, Mistral-7B, LLaMA3-8B). A linear classifier trained on this subspace achieves state-of-the-art performance in detecting LLM lies, both in factual statements and real-world scenarios, demonstrating robustness and generalization.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the challenge of robustly detecting lies in LLMs, a critical issue given their increasing capabilities and potential for misuse. It offers a novel approach that generalizes well across various LLMs and statement types, opening new avenues for research in AI safety and trustworthiness. The findings provide valuable insights for researchers working on lie detection in LLMs, improving AI transparency and ethical considerations.
Visual Insights#

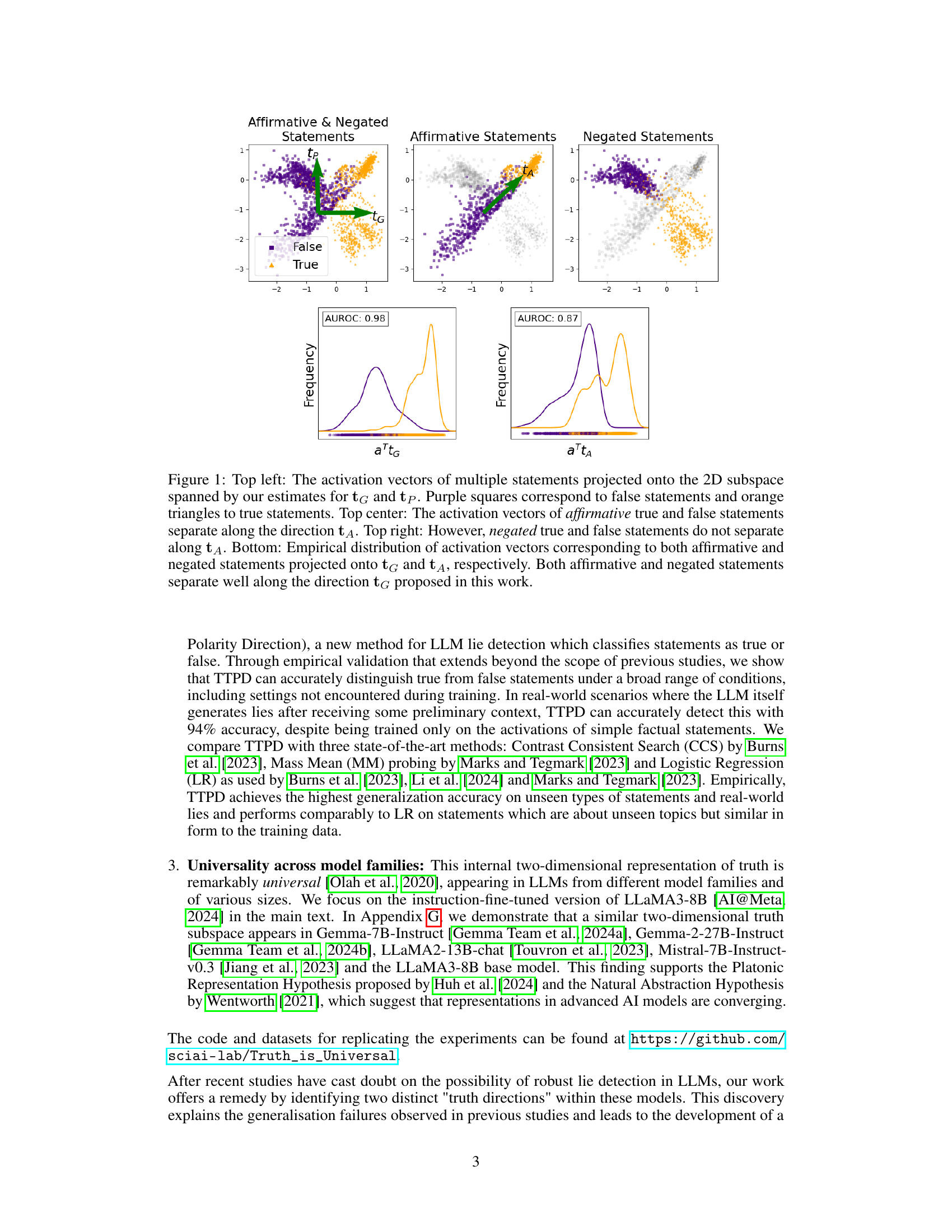
This figure shows the visualization of the two-dimensional subspace that separates true and false statements, spanned by the general truth direction (tg) and polarity-sensitive truth direction (tp). The top row displays scatter plots of activation vectors for different statement types (affirmative & negated, affirmative only, negated only) projected onto this subspace. The bottom row shows the distributions of these activation vectors along tg and the affirmative truth direction (tA) used in previous studies, illustrating that tg provides superior separation for both affirmative and negated statements.
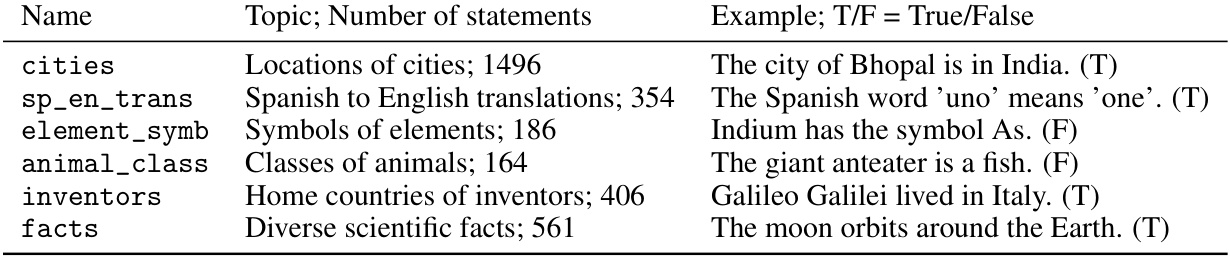
This table presents six topic-specific datasets used in the paper. Each dataset contains true and false statements about a particular topic (e.g., locations of cities, Spanish-to-English translations). The table lists the topic, number of statements, and an example statement with its truth value (True/False). These datasets were used to train and evaluate the LLM lie detectors described in the paper.
In-depth insights#
LLM Lie Detection#
The field of LLM lie detection is rapidly evolving, driven by the increasing sophistication and capabilities of large language models. Current approaches often leverage internal model activations or output analysis to distinguish truthful from deceptive statements. However, challenges remain, including the generalizability of models across different LLMs, topics, and statement types. Many existing methods struggle with negated statements or more complex grammatical structures. Robust lie detection demands a deeper understanding of the internal representations of truthfulness within LLMs. Future work should focus on developing more universal and robust methods, addressing the limitations of existing approaches and exploring novel techniques to effectively detect lies across a wider range of contexts. Furthermore, ethical considerations should be a central focus, ensuring responsible development and deployment of LLM lie detection tools.
Truth’s Subspace#
The concept of a “Truth’s Subspace” in large language models (LLMs) proposes that the complex, high-dimensional activation space within an LLM can be reduced to a lower-dimensional subspace where true and false statements are linearly separable. This subspace, not a single “truth direction,” reveals a more nuanced understanding of how LLMs represent truth. Two key directions emerge within this subspace: a general truth direction consistently distinguishing true from false across various statement types and contexts; and a polarity-sensitive direction, influenced by the statement’s grammatical polarity (affirmative or negated). This two-dimensional representation explains why previous attempts to find a single truth direction failed, highlighting the importance of considering both the general and polarity-specific aspects of truth representation within LLMs. Further research into this subspace’s dimensionality and properties is needed to fully understand its implications for lie detection and LLM interpretability.
TTPD Classifier#
The TTPD classifier, a novel approach for detecting lies in LLMs, stands out due to its robustness and generalizability. Unlike previous methods that struggled with generalization across different statement types or contexts, TTPD leverages a two-dimensional subspace within the LLM’s internal activation space. This subspace, spanned by a general truth direction and a polarity-sensitive truth direction, allows TTPD to accurately distinguish between true and false statements, even those that are negated or structurally complex. The classifier’s superior performance, as evidenced by its state-of-the-art accuracy (94%), stems from its ability to disentangle the general truth signal from other confounding factors. The method’s universality across various LLMs is another key advantage, suggesting the existence of a common underlying representation of truth within these models. Future research could explore expanding TTPD’s capabilities to even more complex scenarios or multi-modal inputs.
Universality Test#
A hypothetical “Universality Test” section in a research paper investigating LLM lie detection would likely explore the generalizability of the findings across various LLMs. This would involve testing the lie detection model on multiple LLMs with diverse architectures, training data, and sizes. Success would demonstrate robustness and confirm the underlying mechanisms are not model-specific but rather reflect a general property of LLMs. The section should detail the specific LLMs tested, the metrics used (e.g., accuracy, precision, recall, F1-score, AUC), and a comparison of the performance across different models. Failure to generalize would highlight limitations and potential biases in the approach, perhaps indicating reliance on model-specific artifacts rather than fundamental properties of truth representation. The discussion should analyze the reasons behind any observed differences and potentially suggest future research directions to improve universality and robustness.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending the dimensionality analysis beyond the identified two-dimensional truth subspace is crucial to determine whether additional linear or non-linear structures exist that correlate with truthfulness. Investigating the robustness and generalization capabilities of the proposed method across a wider range of LLMs, including larger and multimodal models, is essential. Exploring different model architectures and training methodologies would further enhance the understanding of the internal mechanisms of truth representation in LLMs. Studying the influence of various factors such as prompting strategies, dataset composition, and model fine-tuning on the detection accuracy will be crucial. Finally, developing robust lie detection methods for real-world scenarios involving more complex and sophisticated lies generated by LLMs remains a critical and valuable area for future investigation.
More visual insights#
More on figures

This figure shows the ratio of between-class variance to within-class variance of activations for true and false statements across different layers of the LLM. The x-axis represents the layer number, and the y-axis represents the ratio. Separate lines are plotted for different datasets (cities, neg_cities, sp_en_trans, and neg_sp_en_trans), illustrating how the separation between true and false statements varies across layers for each dataset. This visualization helps in identifying the optimal layer for extracting activation vectors to be used for lie detection, as a higher ratio indicates better separation between the two classes.
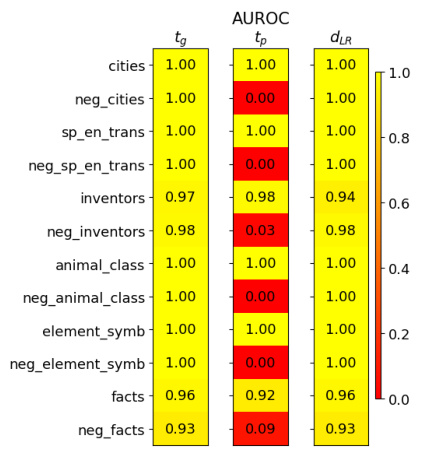
This figure shows the area under the receiver operating characteristic curve (AUROC) for the separation of true and false statements along different truth directions (tg, tp, dLR). High AUROC values indicate good separation. The results are shown for various datasets, illustrating the generalisation capabilities of the different directions. The general truth direction tg consistently shows excellent separation across different types of statements, unlike the polarity-sensitive direction tp, which shows opposite behavior for affirmative and negated statements.
This figure visualizes the two-dimensional subspace where true and false statements are linearly separable, using projections of activation vectors. The left panel shows the separation using the general truth direction (tg) and polarity-sensitive truth direction (tp). The center panel illustrates the separation of affirmative statements using the affirmative truth direction (tA), which fails for negated statements (right panel). The bottom panels show the distributions of activation vectors for affirmative and negated statements along tg and tA, highlighting the effectiveness of tg for both.
This figure shows the two-dimensional subspace where true and false statements are linearly separable. The top row shows the projection of the activation vectors onto this subspace for different statement types (affirmative, negated, and both). The bottom row displays the empirical distribution of activation vectors projected onto two different directions: the general truth direction (tg) and the affirmative truth direction (tA). It demonstrates that tg effectively separates true and false statements across different polarities, while tA only works for affirmative statements, explaining the generalization failure of previous models.

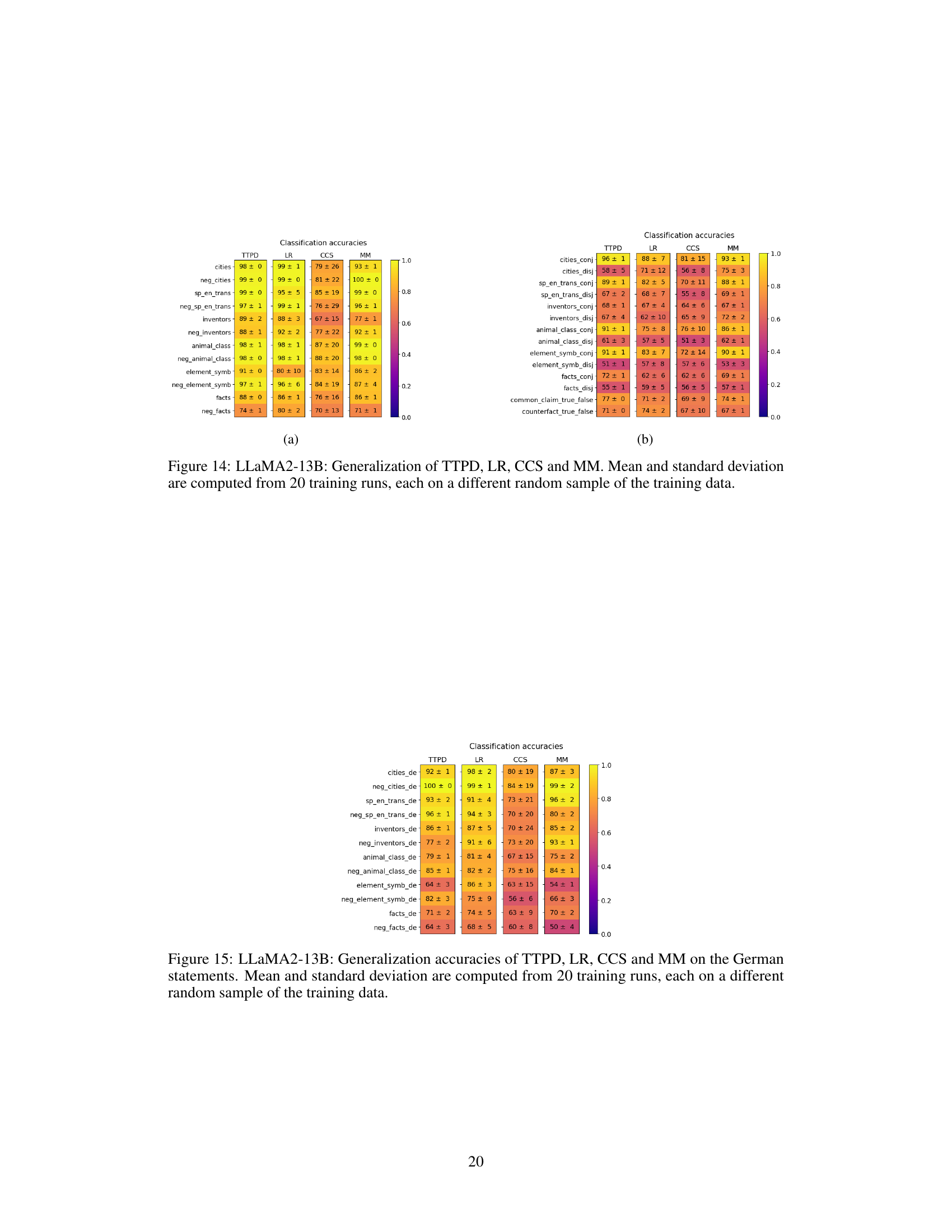
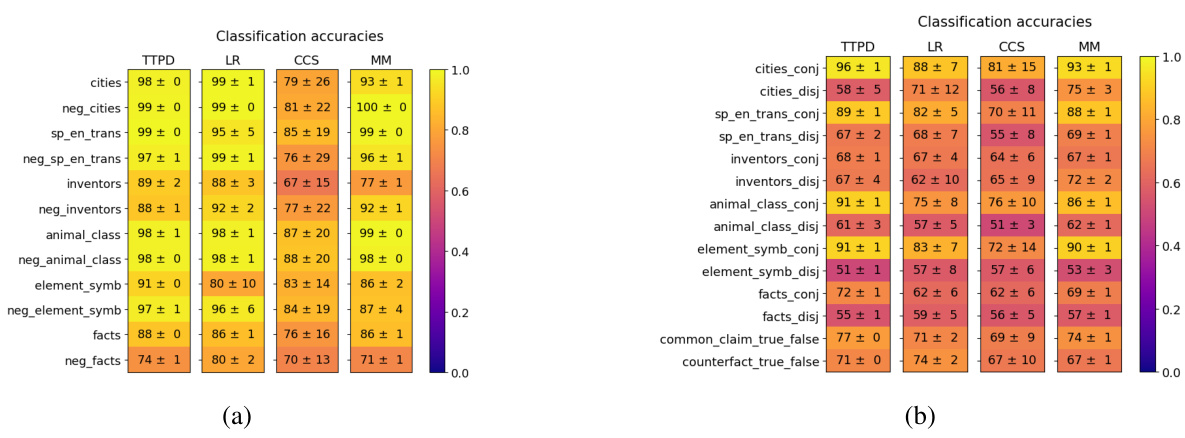
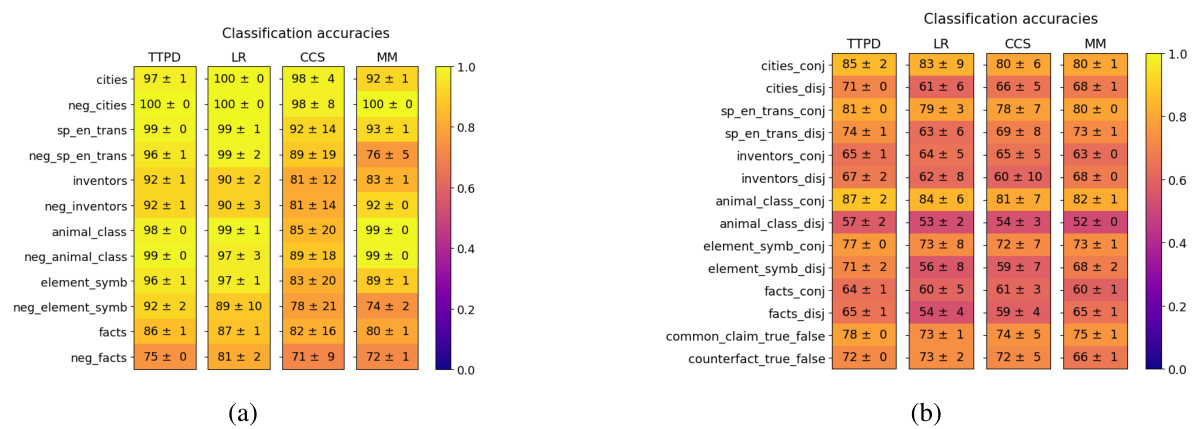
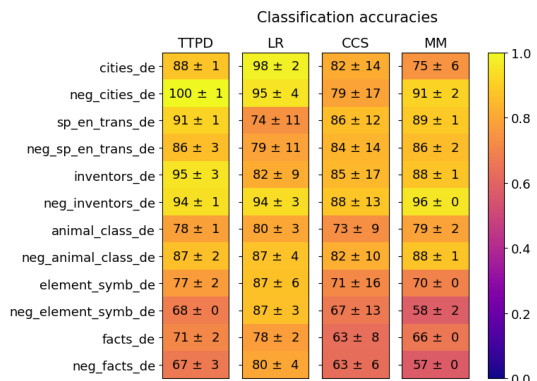
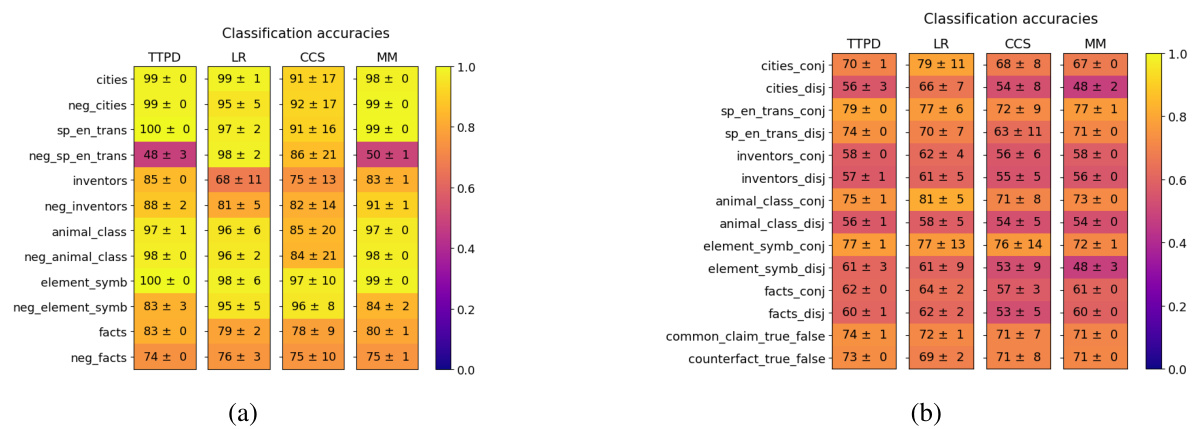
This figure shows the generalization accuracies of four different lie detection methods (TTPD, LR, CCS, and MM) across various datasets. The datasets are separated into two groups: (a) topic-specific datasets and (b) datasets with unseen statement types. The color intensity represents the accuracy, ranging from 0.0 (dark purple) to 1.0 (bright yellow). The mean and standard deviation are calculated from 20 training runs, using different random subsets of the training data for each run. This visualization helps to compare the performance of the four methods in terms of their ability to generalize to unseen data and diverse statement types.

This figure shows the results of projecting activation vectors of true and false statements onto a 2D subspace spanned by two vectors: the general truth direction (tg) and the polarity-sensitive direction (tp). The top panels show that while affirmative statements clearly separate along the affirmative truth direction (tĄ), negated statements do not. The bottom panels show that both affirmative and negated statements effectively separate along tg. This highlights the limitations of previous approaches using only a single truth direction and demonstrates the effectiveness of the two-dimensional approach proposed in the paper.

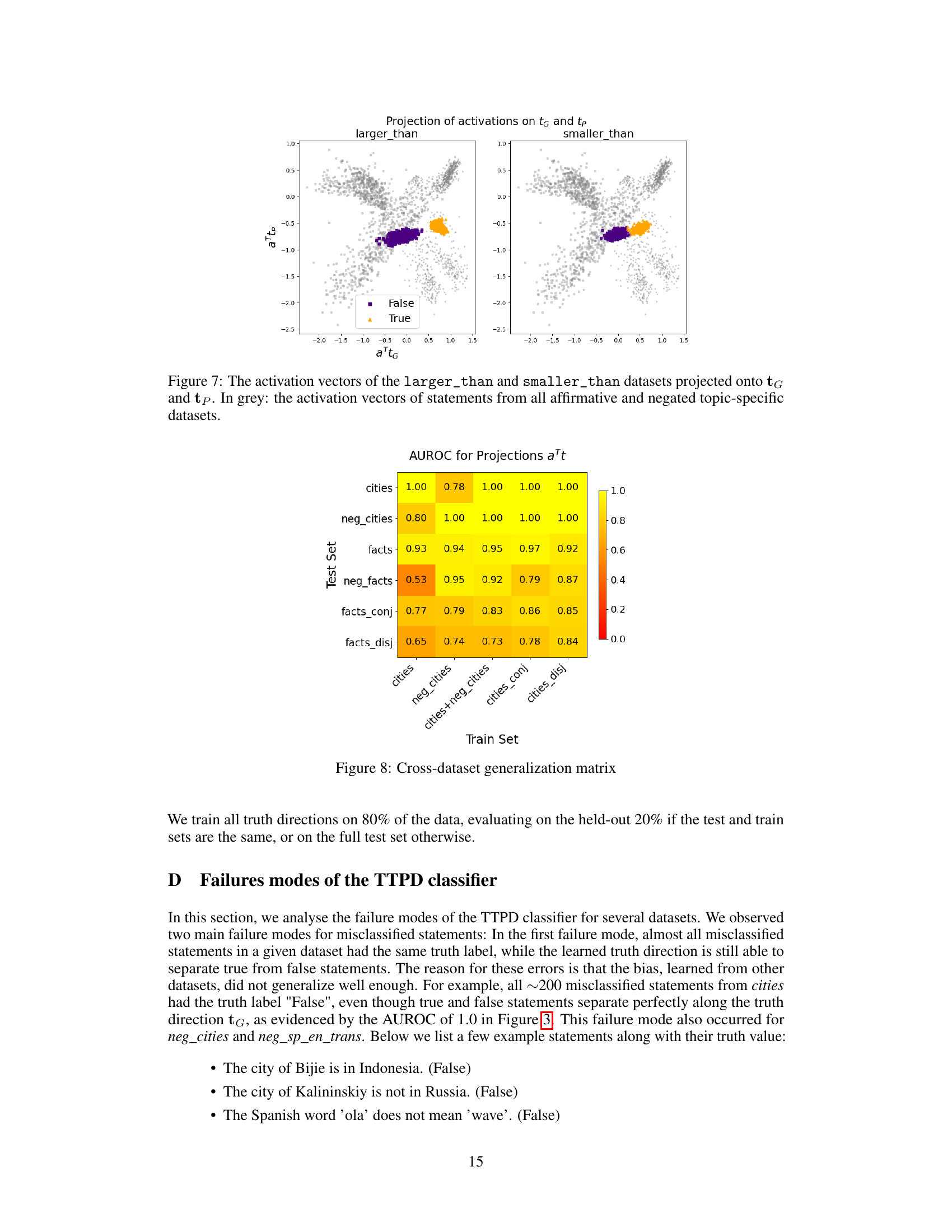
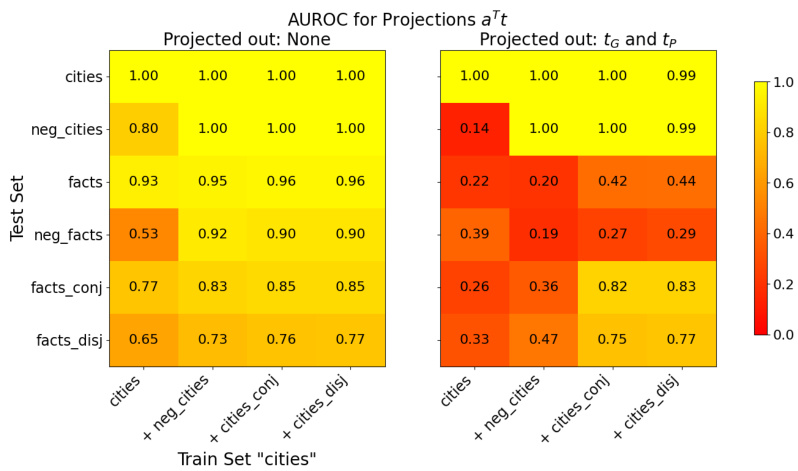
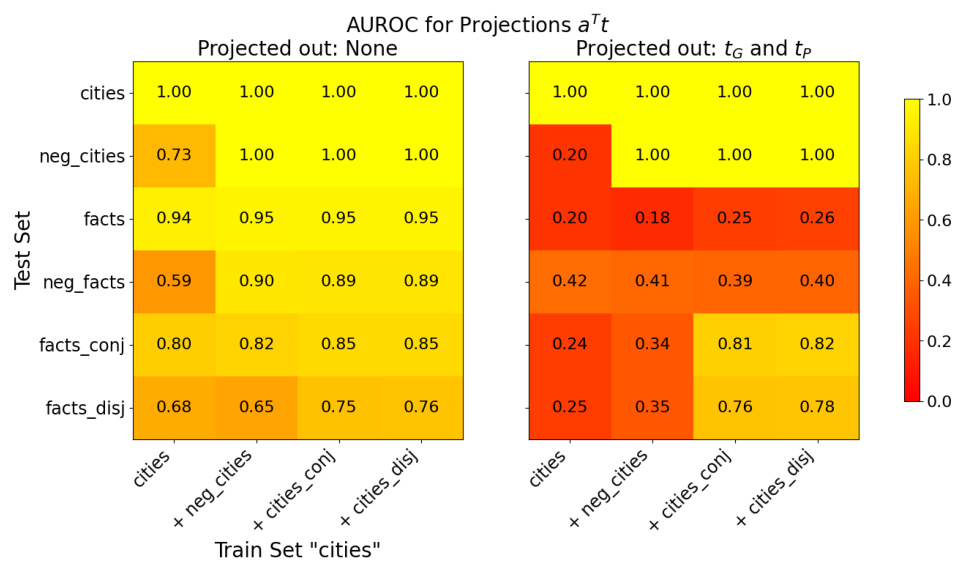
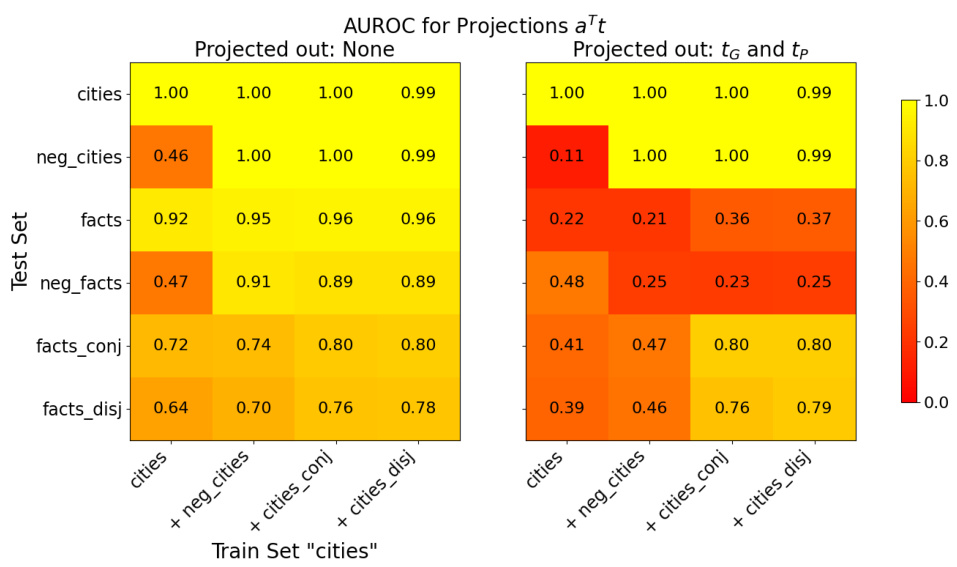
This figure shows the AUROC values when training a truth direction on one dataset and testing it on others. The color intensity represents the AUROC, where darker colors indicate lower AUROC values. The diagonal shows the AUROC when training and testing on the same dataset, which are expected to be high. This figure demonstrates how well the truth direction generalizes across different datasets and topics.

This figure shows the two-dimensional subspace that separates true and false statements. The top panels illustrate the separation of affirmative and negated statements. The bottom panels show the distributions of true and false statements projected onto the two key directions, demonstrating the effectiveness of the proposed method.

This figure shows the ratio of between-class variance to within-class variance of activations for true and false statements across different layers of the LLM’s residual stream. Each line represents a different dataset: ‘cities’, ’neg_cities’, ‘sp_en_trans’, and ’neg_sp_en_trans’. The x-axis indicates the layer number, and the y-axis shows the variance ratio. Higher values indicate better separation between true and false statements at that layer. This helps determine the optimal layer for extracting activation vectors for subsequent lie detection.
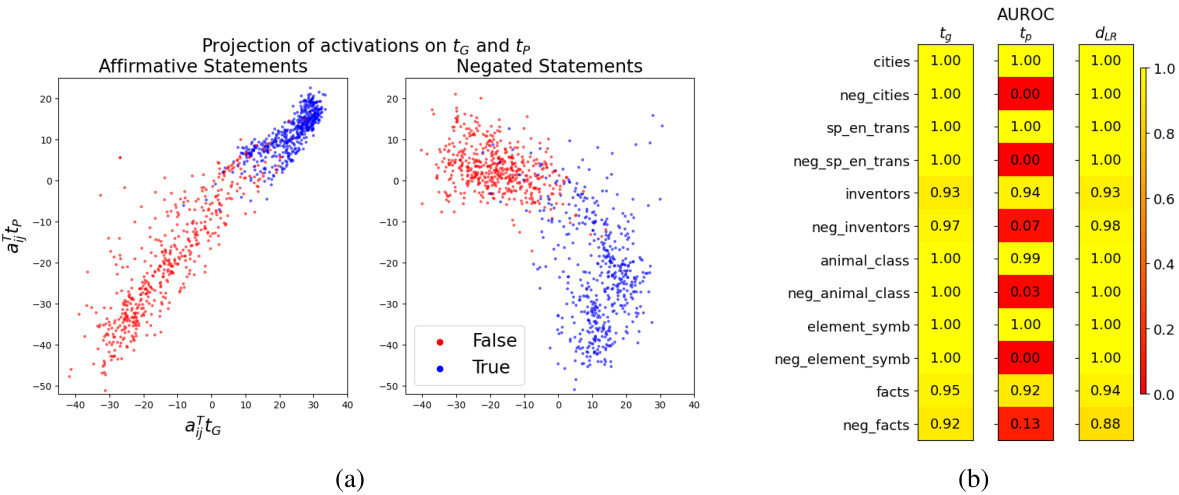
This figure visualizes the activation vectors of various statements in a two-dimensional subspace. The subspace is defined by two key directions: the general truth direction (tg) and the polarity-sensitive truth direction (tp). The plot demonstrates how true and false statements are separated along these directions, highlighting the improved generalization capability of tg compared to previous methods that relied on a single ’truth direction’ for affirmative statements only. The bottom row shows the distribution of activation vectors projected onto tg and tA (affirmative truth direction), emphasizing the effectiveness of tg in separating true and false statements across various statement polarities.
This figure shows the 2D subspace where the activations of true and false statements are linearly separable. The top row demonstrates that while a single ’truth direction’ (tA) works for affirmative statements, it fails for negated statements. The bottom row reveals a more general ’truth direction’ (tg) that successfully separates true and false statements regardless of whether they are affirmative or negated.
This figure shows the visualization of activation vectors projected onto a 2D subspace. The subspace is spanned by two directions, and , representing the general truth direction and the polarity-sensitive truth direction, respectively. The top row illustrates how true and false statements of affirmative and negated sentences are separated in this 2D space, highlighting the generalizability of the truth direction . The bottom row shows the empirical distribution of the activation vectors, demonstrating that both affirmative and negated statements separate effectively along . This visualization is crucial for understanding the authors’ claim about the existence and generalizability of a two-dimensional truth subspace in LLMs.
This figure visualizes the activation vectors of true and false statements projected onto a 2D subspace. The subspace is spanned by two directions: the general truth direction (tg) and the polarity-sensitive truth direction (tp). The figure demonstrates that tg effectively separates true and false statements regardless of their polarity (affirmative or negated), while tp separates them differently depending on polarity. The existence of this 2D subspace explains why previous classifiers based on a single truth direction failed to generalize across statement types.

This figure shows the visualization of the two-dimensional subspace where the activations of true and false statements are linearly separable. The left panel shows the projection of activation vectors onto this subspace spanned by the general truth direction (tg) and the polarity-sensitive truth direction (tp). The center and right panels demonstrate the separation of affirmative and negated statements along the respective directions, highlighting the limitations of considering only one direction for lie detection. The bottom panels show the distribution of the activation vectors, illustrating the effectiveness of the proposed two-dimensional subspace in separating true and false statements.

This figure shows the ratio of between-class variance to within-class variance of activation vectors across different layers of the LLM for true and false statements. The x-axis represents the layer number, and the y-axis shows the ratio. Different colored lines represent different datasets (‘cities’, ’neg_cities’, ‘sp_en_trans’, ’neg_sp_en_trans’), each consisting of true and false statements on a particular topic. The peaks of the curves indicate the layers where the activations of true and false statements are most separable, suggesting the optimal layer to extract features for lie detection.

This figure shows the effectiveness of the proposed 2D subspace in separating true and false statements. The top row demonstrates how the existing 1D approach (using only the ‘affirmative truth direction’) fails to generalize to negated statements, while the bottom row, using the proposed 2D subspace, successfully separates both affirmative and negated statements. The visualizations clearly illustrate that the general truth direction (tg) is crucial for robust and generalized lie detection in LLMs.
This figure shows the results of projecting activation vectors of true and false statements onto a two-dimensional subspace spanned by two vectors, tg and tp. The top row demonstrates that while a linear classifier trained on only affirmative statements can successfully separate true from false, this separation fails when applied to negated statements. The bottom row highlights that using the general truth direction tg, derived from both affirmative and negated statements, provides a robust method for classification that works well across both statement polarities.

This figure shows the results of projecting activation vectors of true and false statements onto a two-dimensional subspace spanned by two vectors, tg and tp, which represent the general truth direction and polarity-sensitive truth direction respectively. The left panel shows the separation of true and false statements for both affirmative and negated sentences within the 2D subspace. The center panel shows that affirmative statements separate well along the direction tA, whereas negated statements do not. The bottom panel provides the empirical distribution of activation vectors along tg and tA, illustrating how both affirmative and negated statements separate well along tg but not tA.
This figure visualizes the two-dimensional subspace where the activations of true and false statements are linearly separable. The left panel shows the projection of activation vectors onto this subspace, clearly separating true and false statements. The center and right panels illustrate how only the affirmative statements are separated using a single ‘affirmative truth direction’ (tĄ). The bottom panels illustrate the distributions of activations along the general truth direction (tg) and the affirmative truth direction (tĄ), showcasing the superior generalizability of tg.
This figure visualizes the findings of the paper regarding the two-dimensional subspace that separates true and false statements. The top panels show the separation of true/false statements for affirmative and negated statements, highlighting the limitations of previous methods that only considered affirmative statements. The bottom panels illustrate how the proposed method effectively separates both affirmative and negated statements in a 2D space spanned by two directions: the general truth direction () and a polarity-sensitive truth direction ().
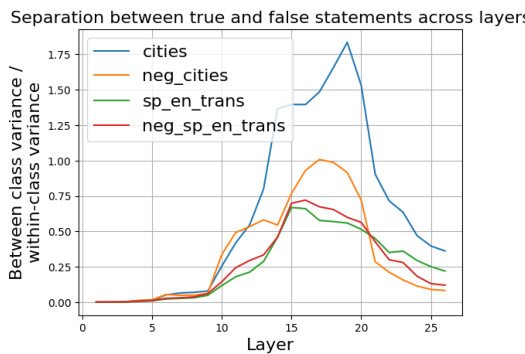
This figure shows the ratio of between-class variance to within-class variance of activations across different layers of the LLM for true and false statements. The plot shows that the ratio increases significantly in certain layers, suggesting that the model might internally represent truthfulness in a way that is more easily distinguishable in certain layers than others. Different datasets (cities, neg_cities, sp_en_trans, neg_sp_en_trans) are compared, which provides insight into how the representation of truth varies across different datasets and statement types.

This figure shows the effectiveness of a 2D subspace in separating true and false statements, highlighting the limitations of previous methods that only used a single dimension. The top row demonstrates the separation of affirmative statements using a single direction (tA) and the failure of this direction to generalize to negated statements. The bottom row demonstrates a new 2D subspace that effectively separates both affirmative and negated statements using two directions: tG (general truth direction) and tP (polarity-sensitive truth direction).

This figure shows the visualization of the 2D subspace spanned by the general truth direction (tg) and the polarity-sensitive truth direction (tp). The top row demonstrates how affirmative statements separate well along the affirmative truth direction (tA), but negated statements do not. The bottom row shows the improved separation achieved by using the general truth direction (tg) for both affirmative and negated statements.

This figure shows the projection of activation vectors onto a 2D subspace, highlighting the separation of true and false statements. The left panels show this separation using the general truth direction (tg) and polarity-sensitive direction (tp), demonstrating better generalization than the affirmative truth direction (tA) used in previous studies which is shown in the center panels. The bottom panels show the distribution of activations, further illustrating the effectiveness of tg.
This figure visualizes the activations of true and false statements projected onto a two-dimensional subspace. The left panel shows that true and false statements, regardless of their polarity (affirmative or negated), are linearly separable along a general truth direction (tg). The center and right panels show that a previous approach using only an affirmative truth direction (tA) is unable to separate true and false negated statements. The bottom panels show the distribution of the activations, highlighting the successful separation by tg and the failure of tA.

This figure visualizes the separation of true and false statements in a two-dimensional subspace spanned by two directions: tg (general truth direction) and tp (polarity-sensitive truth direction). The top panels show that while affirmative statements separate well along a previously identified ’truth direction’ (tA), negated statements do not. The bottom panels demonstrate that true and false statements, regardless of polarity (affirmative or negated), are effectively separated along the newly proposed tg direction.

This figure displays the ratio of between-class variance to within-class variance of activations for true and false statements across different layers of the model. It helps determine which layer shows the greatest separation between the activations of true and false statements, which is crucial for effective lie detection. The plot shows this ratio for four different datasets: ‘cities’, ’neg_cities’, ‘sp_en_trans’, and ’neg_sp_en_trans’, indicating that the optimal layer for separation may vary depending on the dataset.
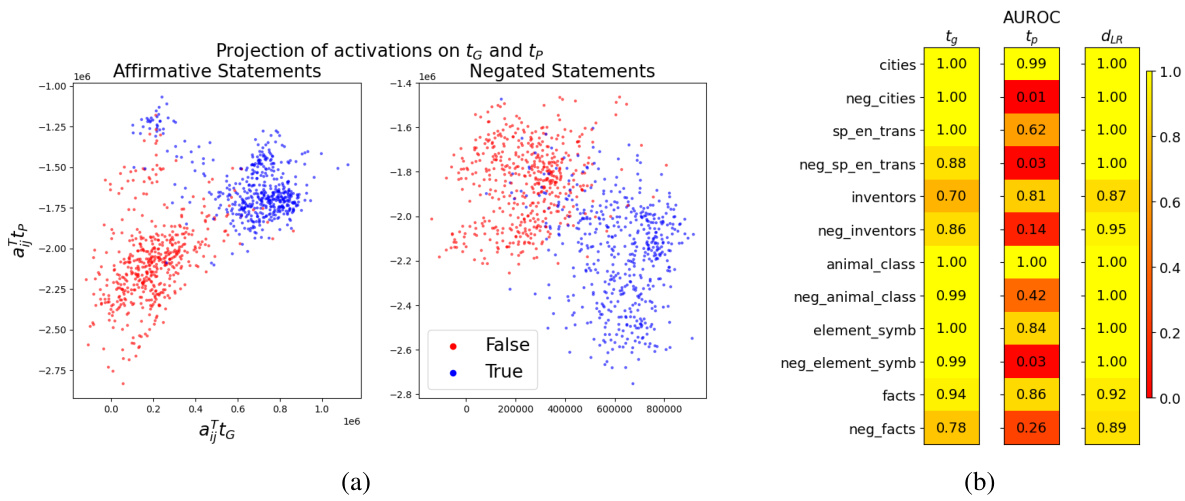
This figure shows the results of projecting activation vectors of true and false statements onto a 2D subspace. The subspace is spanned by two orthogonal vectors: the general truth direction (tg), which consistently separates true and false statements across various statement types, and a polarity-sensitive truth direction (tp), which separates true and false statements differently depending on their grammatical polarity (affirmative or negated). The figure highlights the failure of previous methods that relied on a single ’truth direction’ to generalize across different statement types. This is explained by showing that previous methods effectively trained on the ‘affirmative truth direction’, which is a linear combination of tg and tp, thus lacking the ability to generalize to negated statements.

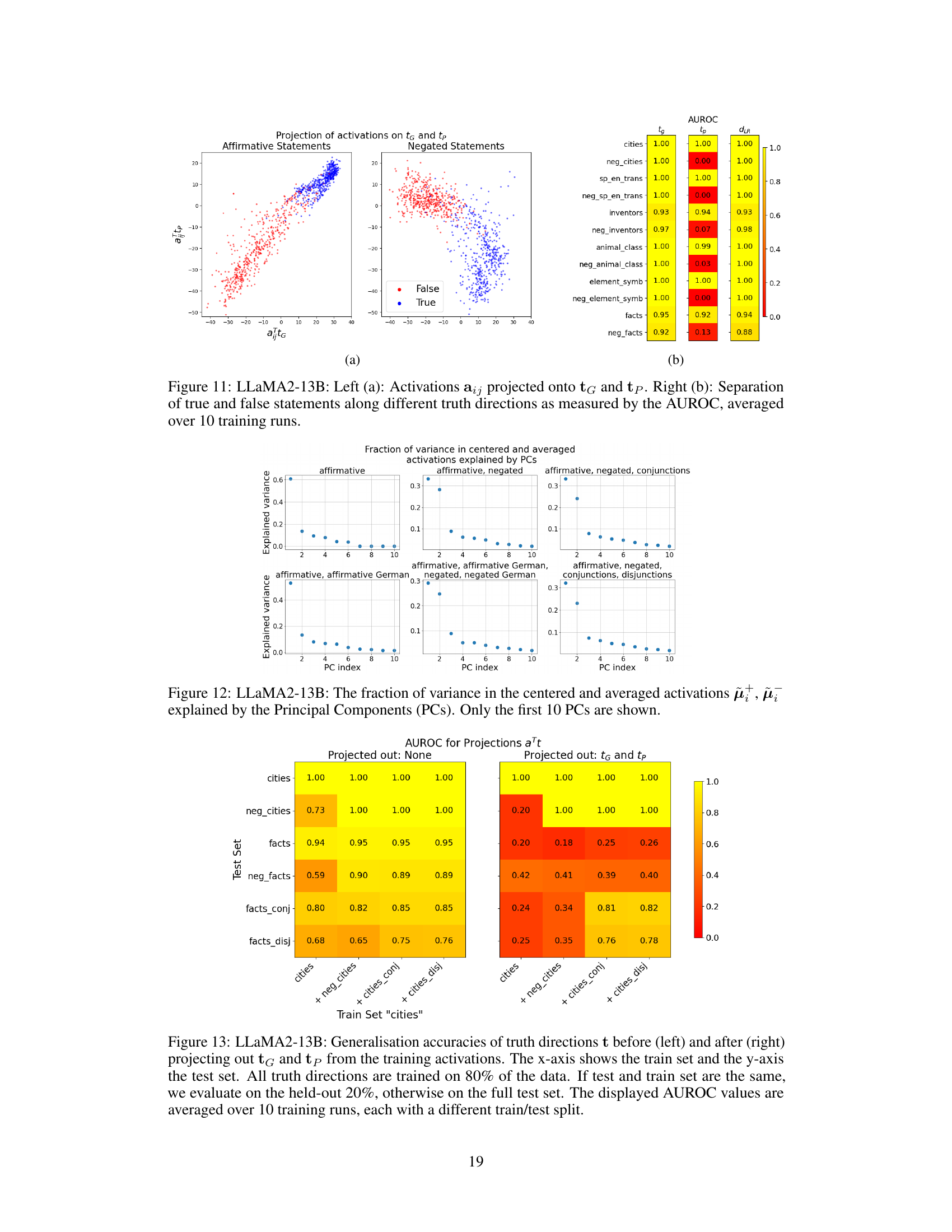
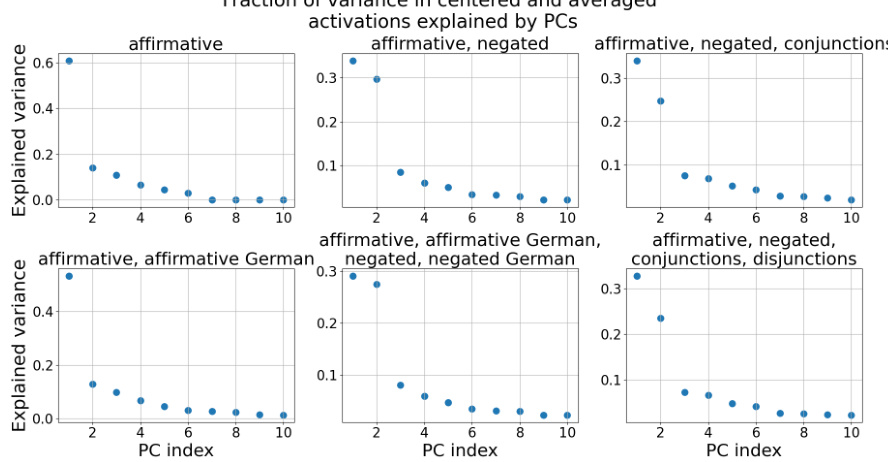
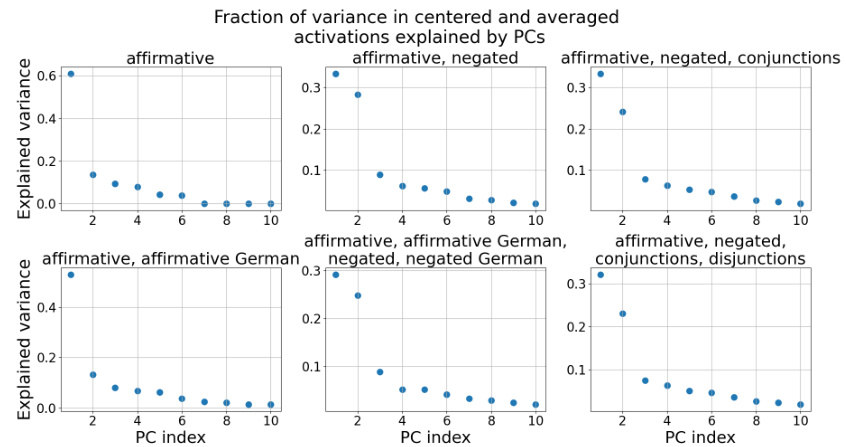
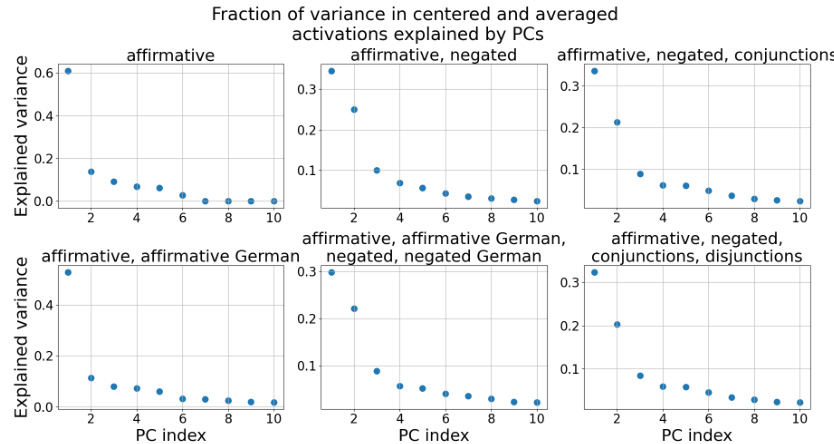
This figure displays the fraction of variance in the centered and averaged activations explained by the first 10 principal components (PCs). The results are shown separately for different combinations of statement types: affirmative statements only, affirmative and negated statements, affirmative and negated statements with conjunctions, affirmative and negated statements with conjunctions and disjunctions, and affirmative and negated statements in English and German. The plot visualizes how much of the variance in the activations is captured by each PC, indicating the dimensionality of the truth subspace.

This figure shows the 2D subspace where the activations of true and false statements are linearly separable. The top row demonstrates how previous methods only using a single dimension (affirmative statements) failed to generalize to negated statements; the bottom row shows how a 2D subspace, spanned by the general truth direction (tg) and polarity sensitive truth direction (tp), addresses the generalization failure by separating true and false statements for both affirmative and negated statements.

This figure shows the projection of activation vectors onto a two-dimensional subspace spanned by two directions, tg and tp, representing the general truth direction and polarity-sensitive truth direction, respectively. The top panels illustrate the separation of true and false statements for affirmative and negated statements. The bottom panels show the distributions of these vectors along each direction separately, highlighting the effectiveness of tg for separating true and false statements, regardless of polarity.

This figure visualizes the key findings of the paper. The top row shows how the activation vectors of true and false statements are separated in a 2D subspace spanned by two vectors, and . The leftmost panel shows the separation for both affirmative and negated statements in the 2D subspace; the center panel shows separation of only affirmative statements along the vector , and the rightmost panel shows that the vector fails to separate negated statements. The bottom row provides the distributions of the activation vectors projected onto these vectors. This highlights the limitations of previous studies that only used a single dimension and demonstrates the effectiveness of the proposed 2D subspace.
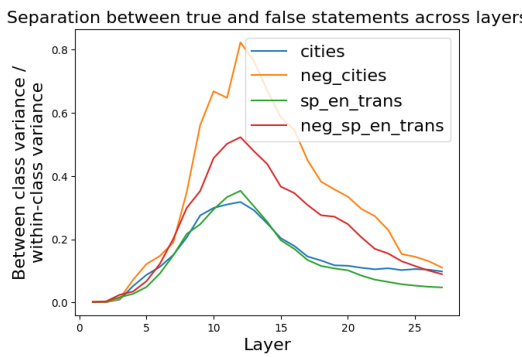
This figure shows the ratio of between-class variance to within-class variance of activations corresponding to true and false statements across different layers of a transformer model. The x-axis represents the layer number, and the y-axis shows the ratio. Each line represents a different dataset, demonstrating how the separability of true and false statement activations varies across layers. The peak of each line indicates the layer where the separation between true and false statement activations is maximal for that dataset.
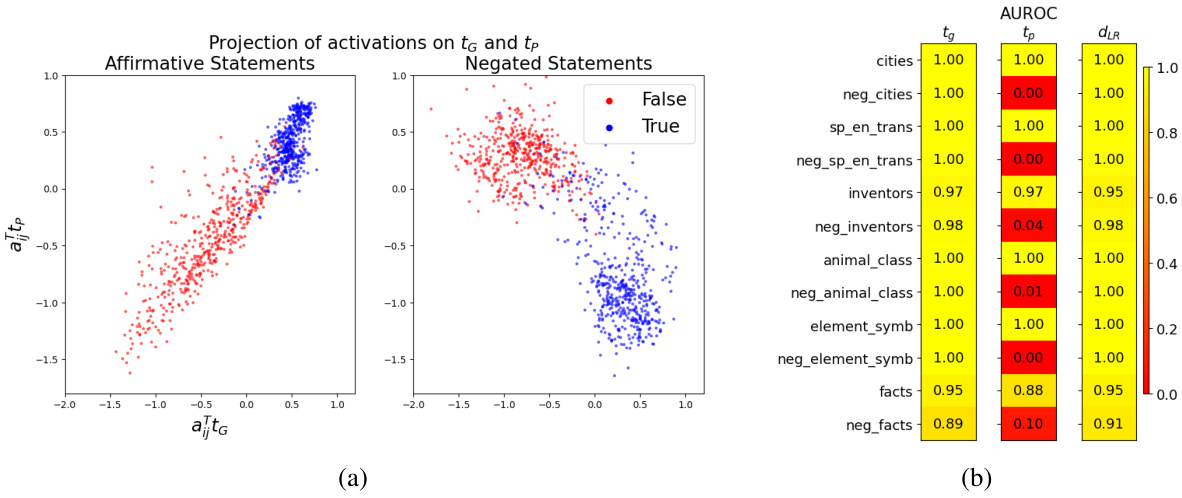
This figure visualizes the two-dimensional subspace where true and false statements are linearly separable. The top panels show that a single direction (tA) separates affirmative true/false statements, but fails to separate negated true/false statements. The bottom panels demonstrate that a two-dimensional subspace (spanned by tG and tP) successfully separates both affirmative and negated statements. tG represents a general truth direction, while tP is a polarity-sensitive direction showing different separation for affirmative and negated statements.

This figure shows the projection of activation vectors onto a 2D subspace, spanned by two vectors: tg (general truth direction) and tp (polarity-sensitive truth direction). It demonstrates that true and false statements are linearly separable within this subspace, but only tg shows consistent separation across affirmative and negated statements, highlighting the limitations of previous methods which only considered a single truth direction.
This figure shows the visualization of the two-dimensional subspace spanned by the general truth direction (tg) and the polarity-sensitive truth direction (tp). The top panels show how true and false statements are separated in this subspace for different statement types (affirmative and negated). The bottom panels show the empirical distributions of activation vectors for both affirmative and negated statements, projected onto tg and tA (affirmative truth direction) respectively. The results demonstrate that tg effectively separates both true and false statements for both affirmative and negated types, which solves the problem of generalization failures observed in previous studies.

This figure shows the visualization of the 2D subspace spanned by the general truth direction (tg) and the polarity-sensitive truth direction (tp). It demonstrates how the activation vectors of true and false statements are separated along these two directions. The top panels highlight the difference in separation for affirmative vs. negated statements, illustrating the limitations of using only the affirmative truth direction (tA). The bottom panels show the distribution of activation vectors projected onto tg and tA, showcasing the effectiveness of tg for separating true and false statements.

The figure shows the area under the receiver operating characteristic curve (AUROC) for separating true and false statements using different truth directions. The AUROC values are averages over 10 training runs on different random subsets of the training data. It highlights that the general truth direction (tg) effectively separates both affirmative and negated statements, while the polarity-sensitive truth direction (tp) behaves differently for affirmative and negated statements.
Full paper#