↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional multi-view stereo (MVS) methods rely on depth range priors which often lead to inaccurate depth estimations. This reliance limits their applicability in real-world scenarios with variable depth ranges and makes them sensitive to errors in depth range assumptions. Existing prior-free MVS methods often work in a pairwise manner, neglecting the inter-image correspondence and resulting in suboptimal solutions.
This paper proposes a novel global depth-range-free MVS framework that leverages a transformer network to simultaneously consider all source images. A key innovation is the use of pose embedding to incorporate geometric constraints, and uncertainty estimation modules dynamically update hidden states, reflecting depth uncertainty across different source images. The proposed method demonstrates superior robustness to depth range variations and outperforms state-of-the-art methods in accuracy and completeness on benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces a novel depth-range-free multi-view stereo (MVS) method. This addresses a major limitation in traditional MVS methods, which often struggle with inaccurate depth estimations due to their reliance on depth range priors. The proposed approach, which uses a transformer network with pose embedding to integrate multi-view information, significantly improves accuracy and robustness. This advancement opens avenues for improved 3D reconstruction in challenging scenarios, impacting various applications including robotics, augmented reality, and autonomous driving. The code release also fosters reproducibility and facilitates further research in the field.
Visual Insights#

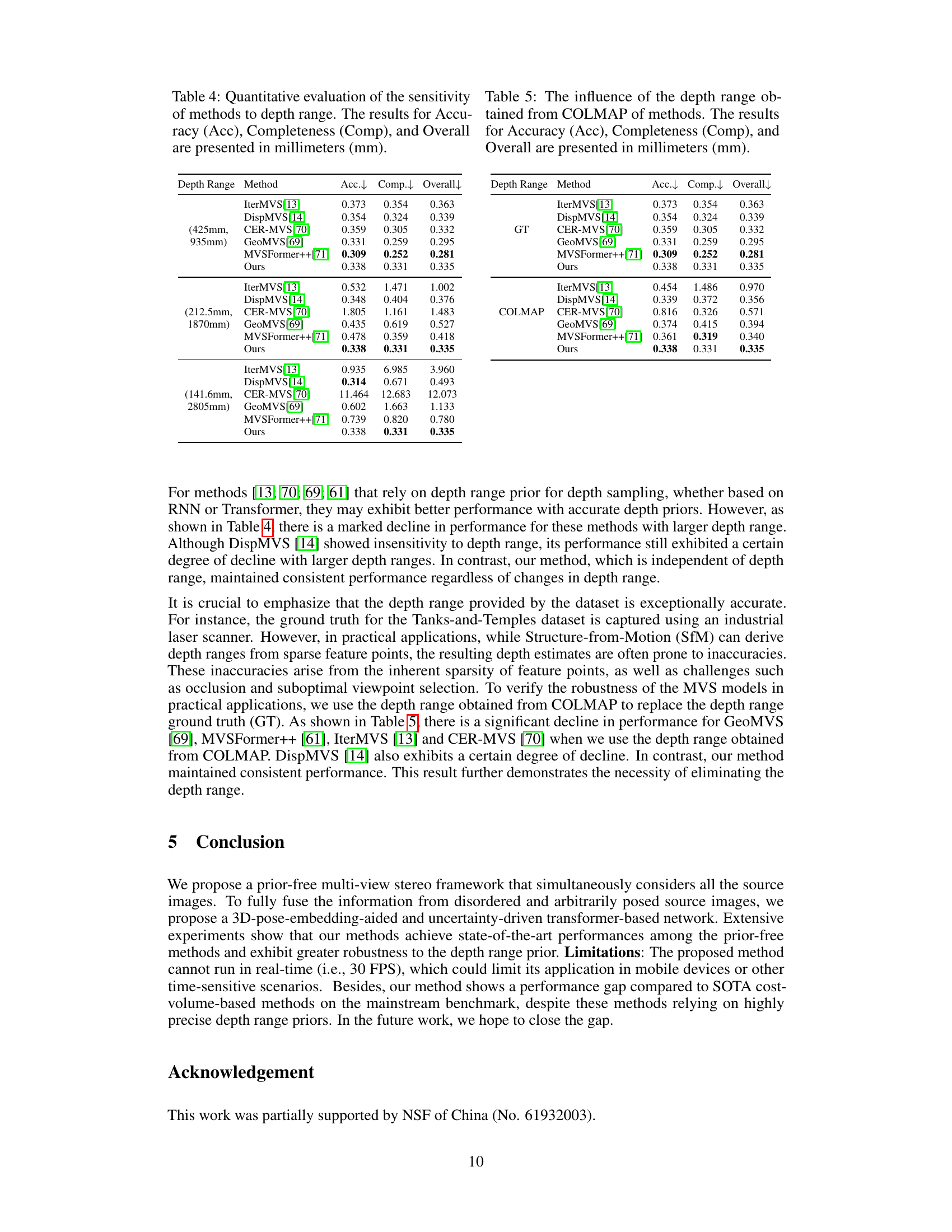
This figure demonstrates the robustness of different multi-view stereo (MVS) methods to variations in depth range. The authors’ method, along with DispMVS and IterMVS, were trained under specific depth ranges (indicated in red). The images show the resulting 3D point cloud reconstructions for each method under varying input depth ranges, highlighting the superior robustness of the authors’ method to deviations from the training depth range.
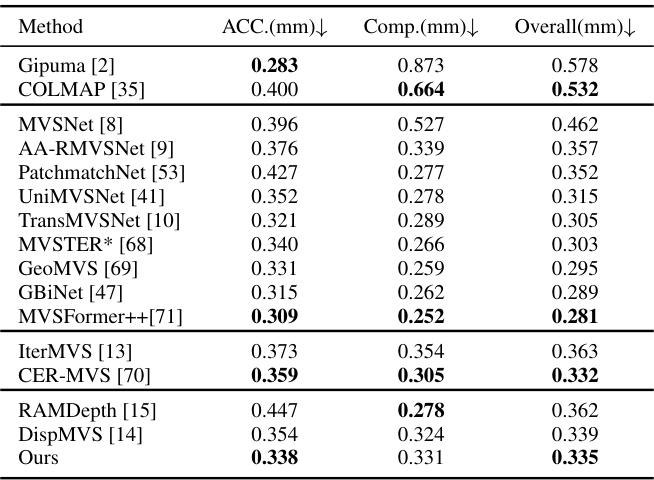
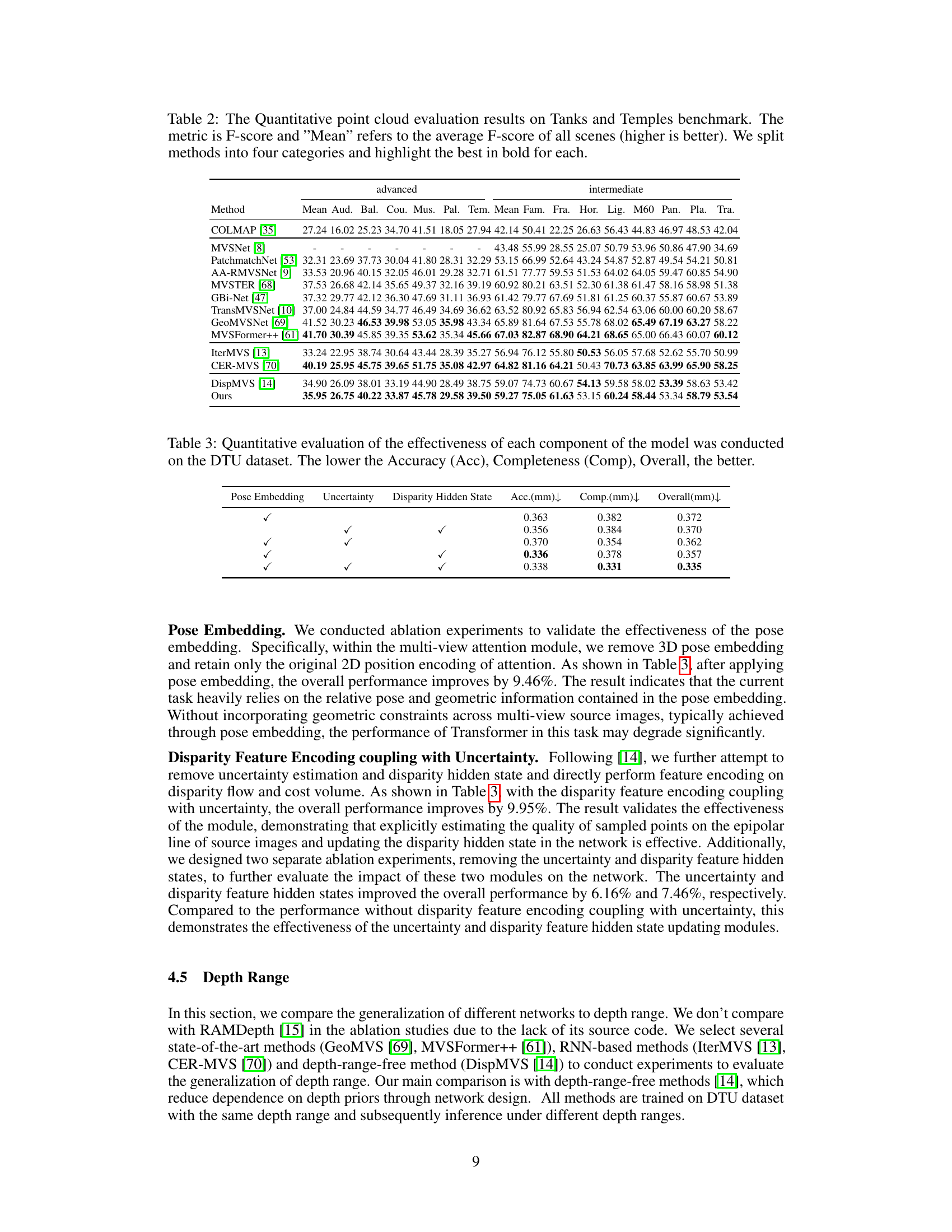
This table presents a quantitative comparison of point cloud evaluation results on the DTU evaluation dataset for various multi-view stereo methods. The metrics used are Accuracy (Acc), Completeness (Comp), and Overall, where lower values indicate better performance. The methods are categorized into four groups for easier comparison, and the best-performing method within each group is highlighted in bold.
In-depth insights#
Depth-Range-Free MVS#
Depth-Range-Free Multi-View Stereo (MVS) is a significant advancement in 3D reconstruction. Traditional MVS methods rely on pre-defined depth ranges, limiting their applicability and robustness, particularly in challenging scenes with varying illumination or textureless regions. Depth-range-free approaches eliminate this limitation by directly estimating the depth map without prior assumptions, often leveraging techniques like epipolar geometry to constrain the search space. This leads to improved accuracy and generalization across diverse scenes, handling scenarios where depth priors are inaccurate or unavailable. These methods often employ sophisticated neural network architectures, such as transformers, to effectively aggregate multi-view information and resolve ambiguities. However, challenges remain in efficiently handling occlusions and noisy data, and further research is needed to improve computational efficiency and scalability for practical real-world applications. The development of robust and accurate depth-range-free MVS methods is crucial for enabling wider applications of 3D reconstruction across various domains.
Pose Embedding Fusion#
Pose embedding fusion, in the context of multi-view stereo (MVS) networks, is a crucial technique for leveraging geometric information encoded in camera poses to improve 3D reconstruction accuracy. It involves integrating pose information, typically represented as rotation and translation matrices, into the feature representations of multiple views. This integration can be achieved in various ways, such as concatenating pose features with image features, using pose features as attention weights to guide feature fusion, or incorporating them into a transformer network. Effective pose embedding fusion should account for the relative pose between views and the geometric relationships between corresponding points in different images. This helps to establish consistent coordinate systems and to handle the challenges of occlusion and viewpoint variation. The success of pose embedding fusion hinges on the design of appropriate embedding mechanisms and integration strategies. Well-designed techniques enhance the network’s ability to understand and utilize the geometric context inherent in the multi-view data, leading to more accurate and robust 3D point cloud reconstruction. However, simply adding pose information might not be sufficient; sophisticated mechanisms are needed to properly encode and fuse pose features with image features, ensuring effective interaction and preventing information degradation.
Uncertainty Modeling#
Uncertainty modeling in computer vision, particularly multi-view stereo (MVS), is crucial for robust performance. Occlusion, noise, and varying image quality introduce significant uncertainty in depth estimation. Effective uncertainty modeling improves the accuracy and reliability of depth maps by explicitly representing and handling these uncertainties. This can be achieved through various techniques such as probabilistic methods, where depth is represented as a probability distribution rather than a single value, or by incorporating uncertainty estimates into the cost volume or loss function. Uncertainty-aware loss functions can penalize incorrect predictions more heavily in regions of high uncertainty, improving overall accuracy. Dynamically updating hidden states in a network, based on uncertainty estimates, enables the model to adapt to different levels of confidence in the input data. Integrating pose information into the uncertainty model improves its ability to capture geometric constraints and mitigate the impact of viewpoint variations. By explicitly modeling uncertainty, MVS systems can be made more robust and reliable, particularly in challenging scenes with significant ambiguities.
Transformer Network#
The integration of Transformer networks in the described multi-view stereo (MVS) system is a key innovation, offering significant advantages over traditional methods. Transformers’ ability to capture long-range dependencies within and across multiple images is crucial for accurately modeling multi-view geometric constraints, especially given the inherent complexities of real-world scenes with occlusions and varying illumination. Unlike CNNs which are limited by their local receptive fields, Transformers excel at contextual understanding, allowing for the effective integration of information from all source images simultaneously. The use of an attention mechanism within the Transformer further refines this process, dynamically weighting the contribution of different sources based on their relevance to the current pixel being processed. Pose embedding, incorporated within the Transformer’s architecture, provides crucial supplementary geometric information, helping to resolve ambiguities arising from viewpoint differences and camera poses. This approach elegantly bypasses the need for explicit depth-range priors often required by other MVS methods, leading to more robust and reliable results. Overall, the Transformer network serves as a powerful tool for enhancing the accuracy and robustness of MVS, paving the way for more advanced and versatile 3D reconstruction techniques.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a machine learning model. In the context of a multi-view stereo (MVS) paper, this would involve removing or disabling specific modules (e.g., pose embedding, uncertainty estimation, or the multi-view attention mechanism) to assess their impact on overall performance. Key metrics, such as accuracy, completeness, and overall error, would be carefully measured and compared across different model configurations. The results reveal the relative importance of each component, highlighting those that are essential for achieving optimal performance and those that provide less significant improvements. A well-executed ablation study demonstrates a thorough understanding of model architecture and behavior, providing valuable insights into design choices and potential areas for future improvements. Furthermore, it allows researchers to isolate the effect of individual components, enhancing the interpretability and reliability of the presented results. By observing the degradation in performance when certain features are removed, the authors solidify the contributions of each individual part and can effectively justify the model design choices. Visualizations comparing point cloud results are useful for verifying the impact of each ablation experiment.
More visual insights#
More on figures
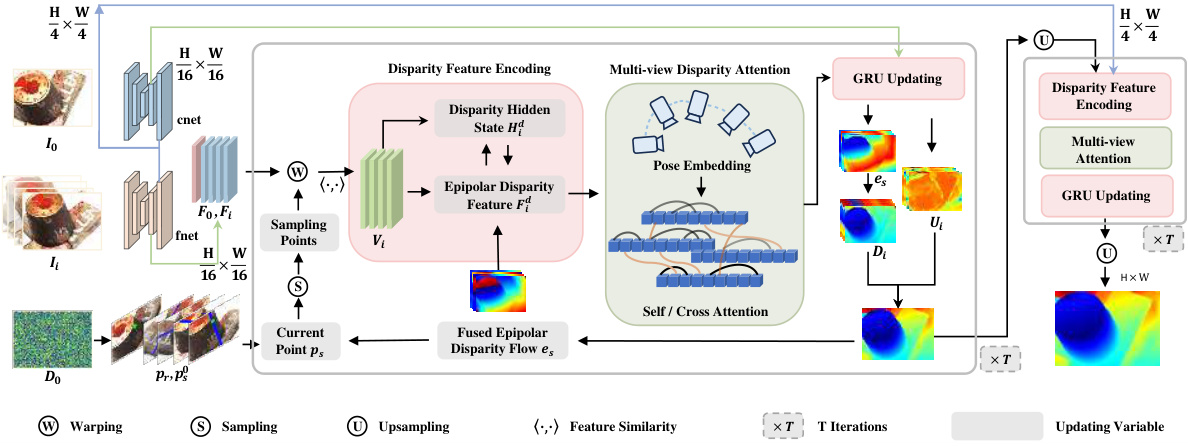
This figure presents a detailed overview of the proposed multi-view stereo (MVS) method. It illustrates the different modules involved in the process, starting from feature extraction and culminating in depth map generation. The core components include a disparity feature encoding module that handles variations in image quality across views, a multi-view disparity attention (MDA) module for efficient information fusion, and an iterative update mechanism using GRUs. Pose embedding is integrated to leverage geometric relationships between views and camera poses, improving the accuracy of depth estimation. The pipeline involves iterative refinement of epipolar disparity flows, ultimately yielding a robust and reliable depth map.
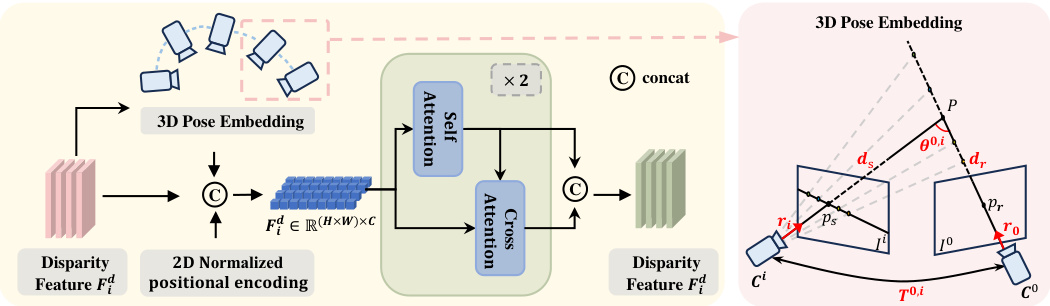
This figure illustrates the Multi-view Disparity Attention (MDA) module. The MDA module takes disparity features, 2D positional encoding, and 3D pose embeddings as input. These inputs are concatenated and fed into a self-attention mechanism followed by a cross-attention mechanism. The self-attention mechanism captures intra-image relationships, while the cross-attention mechanism captures inter-image relationships. The 3D pose embedding encodes both relative camera poses and geometric relationships between pixels across multiple images to aid feature fusion and improve accuracy. The output is an enhanced disparity feature that is passed to subsequent stages of the network.

This figure demonstrates the robustness of the proposed method to variations in depth range. It compares the performance of the proposed method against two other state-of-the-art methods (IterMVS and DispMVS) across different depth ranges. The results show that the proposed method is significantly less sensitive to errors in the depth range than the compared methods. This superior robustness is highlighted by the visual results and is a key advantage of the depth-range-free approach.
More on tables
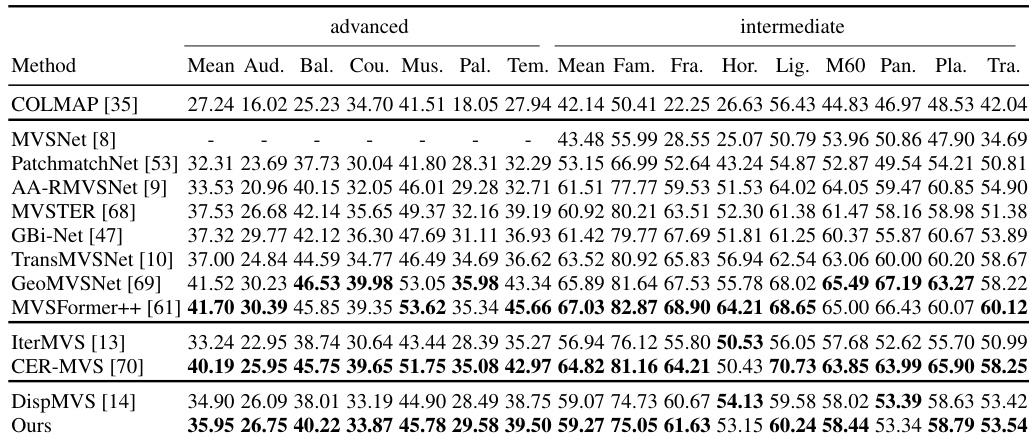
This table presents a quantitative comparison of different multi-view stereo (MVS) methods on the Tanks and Temples benchmark dataset. The performance metric used is the F-score, representing a balance between accuracy and completeness of the 3D point cloud reconstruction. The table is organized to show the average F-score across all scenes, as well as a breakdown of scores for each individual scene. Methods are categorized into groups to facilitate comparison based on their approaches. The best performing method within each category is highlighted in bold.

This table presents the ablation study results on the DTU dataset, showing the impact of different components of the proposed multi-view stereo method on accuracy, completeness, and overall performance. Each row represents a configuration with a specific combination of pose embedding, uncertainty estimation, and disparity hidden states enabled or disabled, allowing for a comparison of their individual contributions to the final results.

This table presents a quantitative comparison of point cloud evaluation results on the DTU dataset’s evaluation set. Three metrics are used: Accuracy (Acc), Completeness (Comp), and Overall. Lower values indicate better performance. The methods are categorized into four groups, and the best performing method in each group is highlighted.
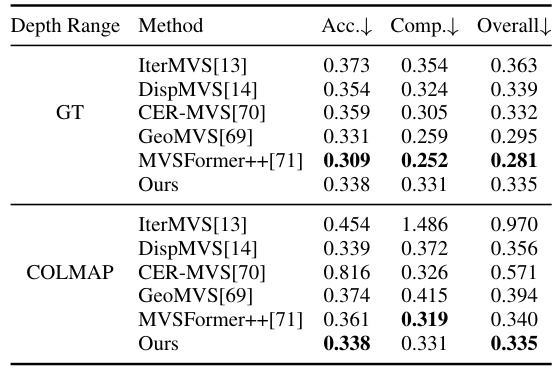
This table presents a quantitative comparison of different multi-view stereo (MVS) methods on the DTU evaluation dataset. The metrics used are Accuracy (Acc), Completeness (Comp), and Overall, all measured in millimeters (mm). Lower values indicate better performance. The table categorizes the MVS methods into four groups (traditional, CNN-based, RNN-based, and scale-agnostic) and highlights the best-performing method within each group in bold.
Full paper#