↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Object goal navigation systems struggle with myopic planning due to reliance on single-step action prediction methods. These methods overlook temporal consistency and lead to inefficient navigation. This often results in redundant exploration and suboptimal paths.
This research introduces Trajectory Diffusion (T-Diff), a novel method that uses diffusion models to learn a distribution of trajectory sequences conditioned on current observations and goals. T-Diff successfully addresses the myopic planning issue by learning sequence planning, generating temporally consistent trajectories. Evaluation on Gibson and MP3D datasets demonstrates improved accuracy and efficiency compared to existing methods. This approach shows promise for enhanced object goal navigation systems.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation in existing object goal navigation methods, improving efficiency and accuracy. It introduces a novel trajectory diffusion model that plans a sequence of actions, enhancing temporal consistency and generalization capabilities. This work offers significant contributions to embodied AI, paving the way for more robust and efficient navigation agents. It also leverages diffusion models, a currently trending technique in other AI fields, to tackle a spatial reasoning challenge, potentially inspiring similar applications.
Visual Insights#
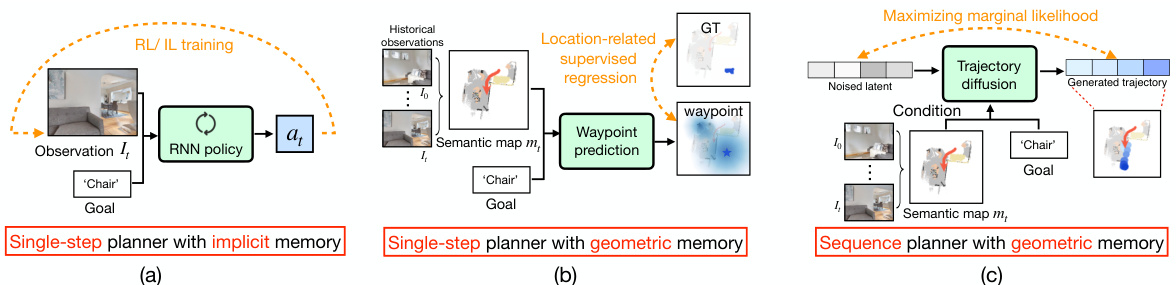
This figure illustrates three different types of planners used in Object Goal Navigation. (a) shows an end-to-end learning method with implicit memory that makes single-step planning decisions based on current observations. (b) shows a modular method with geometric memory which also uses single-step planning, using a semantic map to help avoid redundant exploration. (c) introduces the proposed trajectory diffusion model, which leverages a sequence planner to generate a temporally coherent trajectory conditioned on the semantic map and goal.
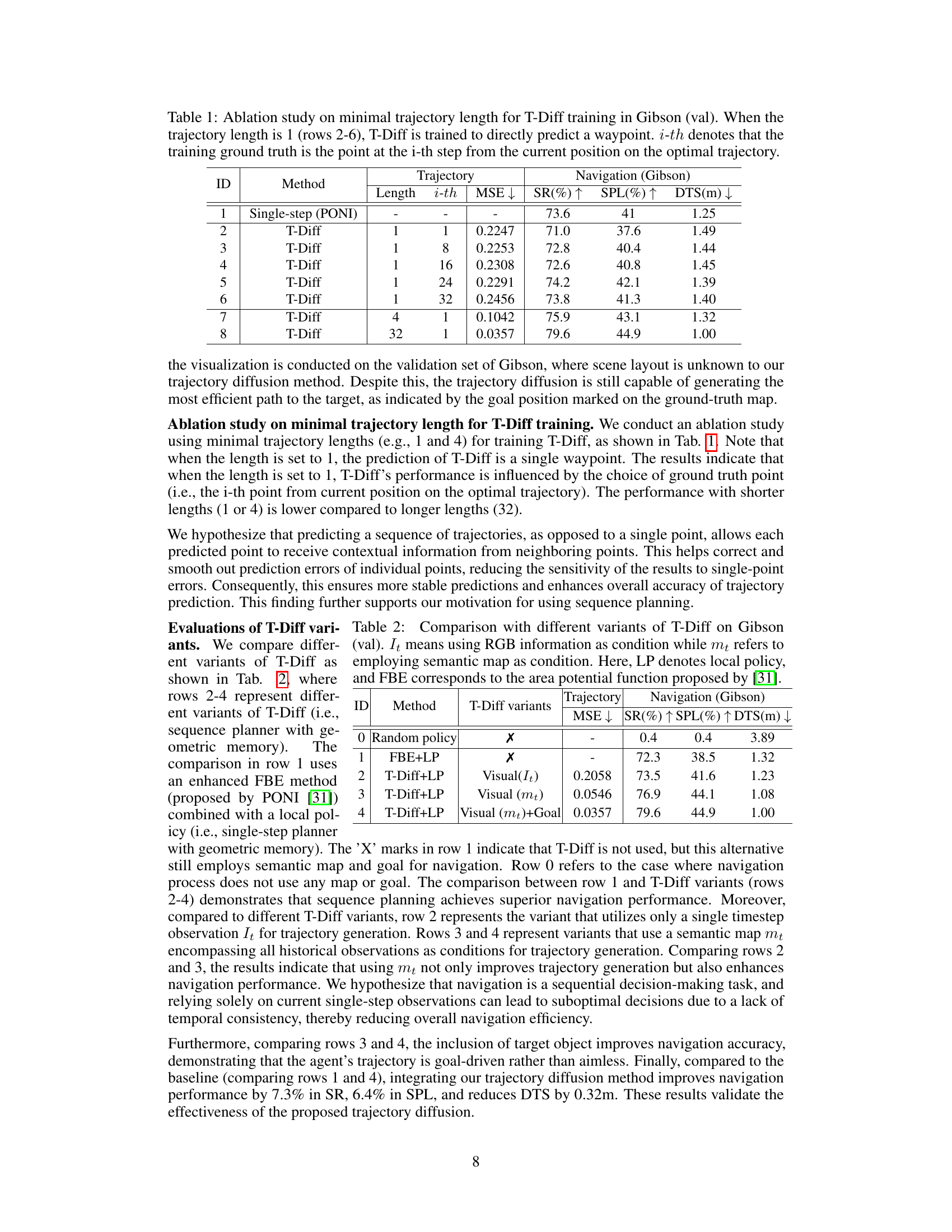
This table presents an ablation study on the impact of minimal trajectory length used for training the Trajectory Diffusion model (T-Diff). It compares the performance of T-Diff when trained to predict a single waypoint (length 1) versus predicting a sequence of waypoints (lengths 4 and 32). The results show the effect of this choice on MSE, Success Rate (SR), Success weighted by Path Length (SPL), and Distance To Goal (DTS) in the Gibson environment. It demonstrates that using longer trajectory sequences improves performance.
In-depth insights#
Trajectory Diffusion#
The concept of “Trajectory Diffusion” presents a novel approach to object goal navigation by employing diffusion models to generate temporally coherent trajectories. This method addresses the limitations of single-step planning in existing ObjectNav techniques, which often leads to suboptimal and myopic plans. By learning the distribution of trajectory sequences conditioned on current observations and goals, trajectory diffusion enables more accurate and efficient navigation even in unseen environments. The use of DDPM and automatically collected optimal trajectory segments for training allows the model to capture complex trajectory distributions effectively. The method’s effectiveness is demonstrated through experimental results on benchmark datasets, showcasing its superior performance compared to existing approaches. However, the reliance on pre-collected optimal trajectories might limit generalizability to scenarios with diverse or noisy data. Future research could focus on adapting this approach to handle uncertainties and more dynamic environments.
ObjectNav Planning#
ObjectGoal Navigation (ObjectNav) presents a significant challenge in embodied AI, demanding efficient planning for an agent to reach a specific object within an unseen environment. Traditional approaches often rely on single-step planning, which limits their ability to consider long-term consequences and can lead to suboptimal trajectories. A more sophisticated approach involves sequence planning, predicting a series of actions to reach the goal. This allows for the incorporation of temporal consistency, and enables the agent to avoid myopic decisions that could lead to dead ends or unnecessary exploration. Trajectory diffusion offers a promising method for sequence planning in ObjectNav by learning the distribution of trajectory sequences conditioned on visual input and the goal. This method demonstrates the capacity for generating temporally coherent and efficient navigation strategies, potentially surpassing simpler methods by capturing more nuanced environmental dynamics and allowing for better generalization to new environments. The effectiveness of trajectory diffusion relies heavily on the quality and diversity of the training data, highlighting the importance of well-designed datasets that adequately capture the complexities of real-world navigation.
DDPM in ObjectNav#
Applying Denoising Diffusion Probabilistic Models (DDPMs) to ObjectGoal Navigation (ObjectNav) presents a novel approach to sequential planning. DDPMs excel at modeling complex data distributions, making them suitable for generating the probability distribution over trajectories given an observation and goal. Unlike traditional single-step methods, a DDPM-based ObjectNav agent can plan a sequence of actions, leading to improved temporal consistency and reduced myopia. The training process involves using DDPM to learn the forward diffusion process, where noise is gradually added to optimal trajectory segments collected from a simulator. The reverse diffusion process is then learned to generate temporally coherent trajectories. Challenges include the high dimensionality of trajectory and semantic map data, necessitating efficient representations and computational methods. Furthermore, the reliance on pre-collected optimal trajectories introduces a dependency on simulation accuracy and may limit generalization to real-world scenarios. Future work could explore alternative training methods that incorporate less constrained data or that can directly learn from real-world interactions. The success of this approach ultimately depends on the ability to effectively learn and generate trajectories that robustly guide the agent to the target object in unseen environments.
T-Diff Model#
The T-Diff model, a trajectory diffusion model for object goal navigation, presents a novel approach to sequential planning. Instead of single-step planning, it learns the distribution of trajectory sequences conditioned on the current observation and goal, using a diffusion model framework. This allows for temporally coherent trajectories, addressing the limitations of myopic planning in existing methods. The utilization of DDPM and pre-trained optimal trajectory data offers an efficient training mechanism, generating temporally consistent trajectories. Experimental results showcase its effectiveness in guiding agents toward the goal, resulting in improved navigation accuracy and efficiency. The model’s reliance on a semantic map provides geometric memory, preventing redundant exploration. However, the model’s performance might be affected by the quality and diversity of the training trajectories and the limitations inherent to diffusion models themselves. Further investigation is needed to explore its generalization capabilities and potential biases.
Future of ObjectNav#
The future of ObjectNav hinges on addressing its current limitations. Improving generalization across diverse unseen environments is crucial, moving beyond reliance on specific simulator characteristics. This requires more robust and adaptable learning methods, potentially incorporating techniques from transfer learning and domain adaptation. Enhanced memory mechanisms, perhaps leveraging advanced graph neural networks or memory-augmented neural networks, are essential to overcome the myopic planning exhibited by current methods. Multimodal integration will also be key, fusing visual, depth, and even semantic information more effectively to create richer scene representations. Finally, safe and reliable deployment in real-world settings demands careful consideration of factors like safety, robustness to unexpected events, and ethical implications. Successfully tackling these challenges will unlock the true potential of ObjectNav for applications ranging from assistive robotics to autonomous navigation.
More visual insights#
More on figures
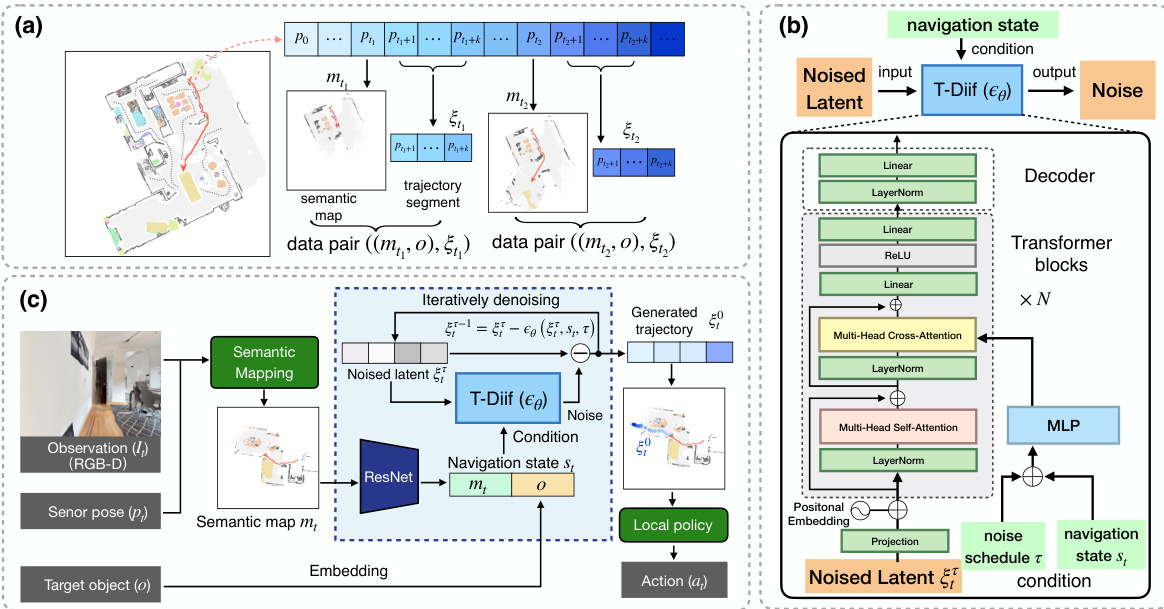
This figure shows the architecture of the proposed Trajectory Diffusion model for object goal navigation. (a) illustrates how the collected data is divided into pairs of semantic maps and corresponding trajectory segments. (b) details the architecture of the T-Diff model, showing the input (noised latent trajectory), the transformer blocks used for processing, and the output (denoised trajectory). The model incorporates a multi-head cross-attention mechanism to condition the trajectory generation on the semantic map and target object. (c) demonstrates how the T-Diff model is integrated into the navigation process, showing how the generated trajectory guides the agent.

This figure shows the impact of three hyperparameters on the performance of the Trajectory Diffusion model. Specifically, it shows how varying the length of generated trajectories (k), the maximum noise schedule during training (Tmax), and the proportion of the generated trajectory used for navigation (kg/k) affects success rate (SR), success weighted by path length (SPL), mean squared error (MSE) between generated and actual trajectories, and distance to goal (DTS).
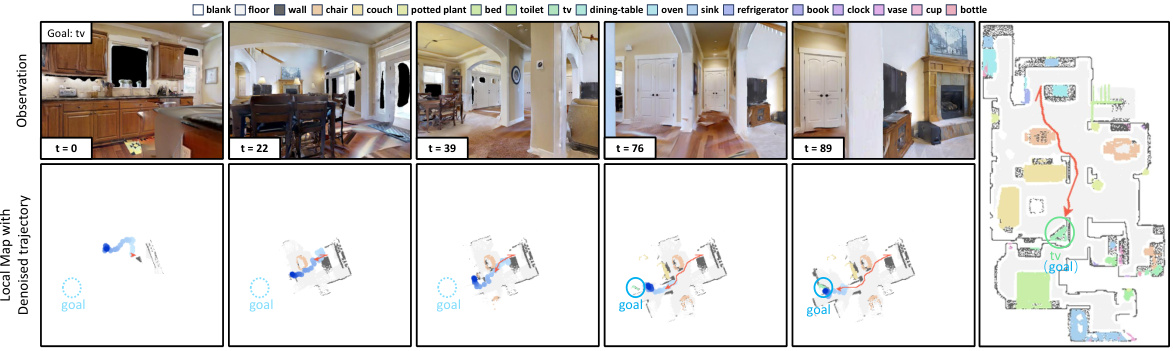
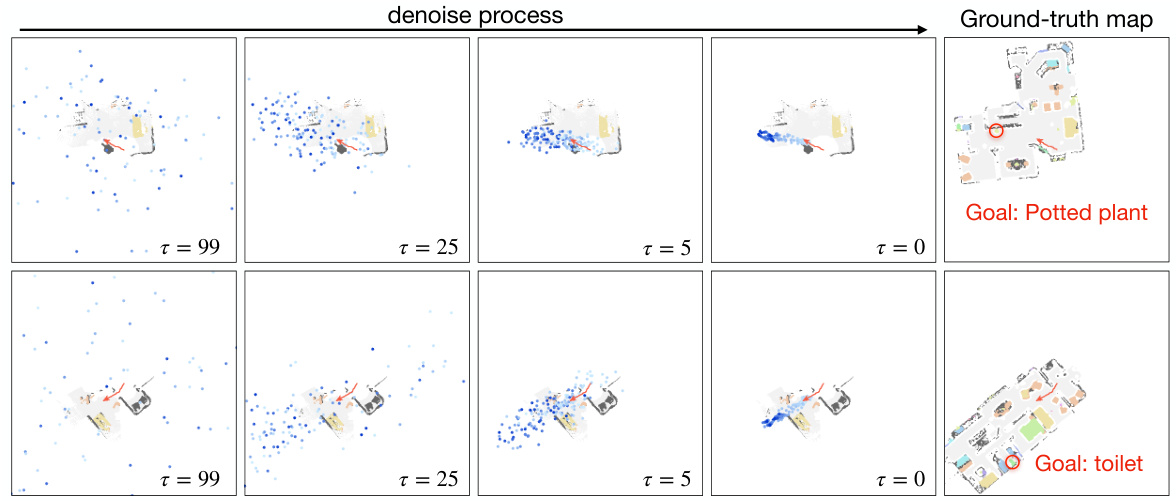
This figure visualizes the navigation process using the proposed Trajectory Diffusion model. It shows a series of snapshots at different timesteps (t=0, t=22, t=39, t=76, t=89). Each snapshot includes: 1. RGB Observation: The agent’s first-person view of the environment. 2. Local Map with Denoised Trajectory: A top-down view of the local semantic map, highlighting the agent’s path (blue) and the generated trajectory (red) towards the target object (green circle). The trajectory is generated by the Trajectory Diffusion model. 3. Goal: The location of the target object. The figure demonstrates how the model generates trajectories that effectively guide the agent to the goal, even when the target is partially or fully occluded.

This figure shows four examples of navigation processes guided by the proposed trajectory diffusion model. Each row displays a different navigation episode. For each episode, the left side shows the agent’s first-person RGB observation at multiple time steps during the navigation. The middle section displays the generated trajectory by the trajectory diffusion model superimposed on the local semantic map at the same time steps. The right side displays the ground truth map along with the actual trajectory of the agent and the location of the target object. The figure demonstrates how the generated trajectory effectively guides the agent towards the target, even when the target remains unseen in the early stage.
More on tables
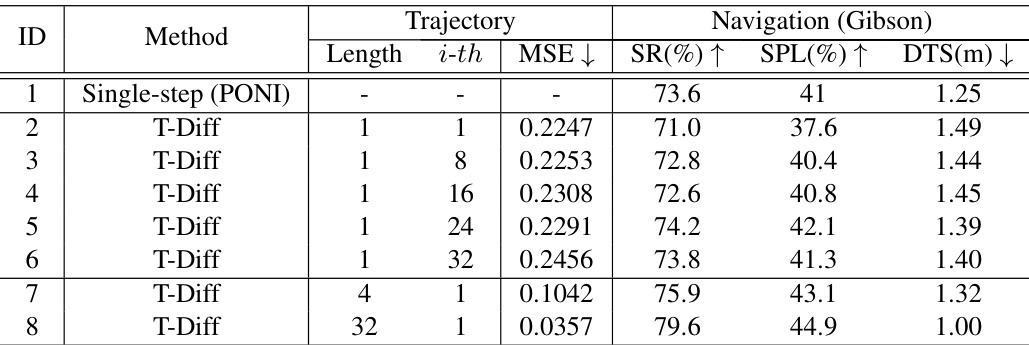
This table presents an ablation study on the impact of the minimal trajectory length used for training the Trajectory Diffusion (T-Diff) model. It shows the results on the Gibson validation set. The study compares the performance of T-Diff when trained to predict a single waypoint (trajectory length 1) versus longer trajectories. Different rows show results using different offsets from the current position for the ground truth waypoint, highlighting that using longer training trajectories (32 steps) significantly improves the model’s performance compared to using single-step waypoints.
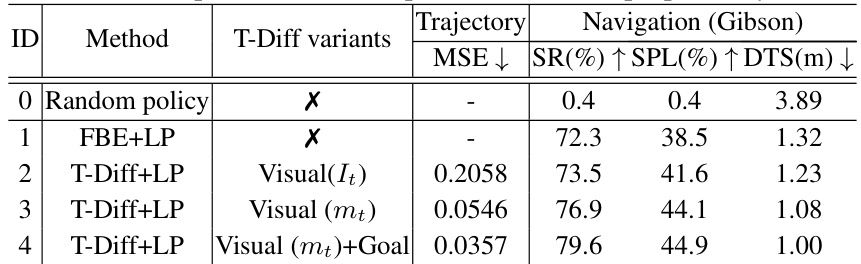
This table compares different variants of the Trajectory Diffusion (T-Diff) model on the Gibson dataset for validation. It contrasts the performance of T-Diff using only visual input (It), semantic map (mt), and both semantic map and goal information (mt+Goal). A baseline method (FBE+LP) without T-Diff is also included for comparison, showing the impact of the proposed sequence planning method on various metrics such as success rate (SR), success weighted by path length (SPL), and distance to goal (DTS). MSE (Mean Squared Error) is included to evaluate the trajectory generation accuracy.

This table compares the performance of the proposed trajectory diffusion model (T-diff) against a simpler model for trajectory generation. The simpler model uses a similar Transformer-based architecture but is trained with MSE loss instead of the diffusion process used by T-diff. The comparison highlights the effectiveness of the diffusion model in generating high-quality trajectories that lead to improved navigation performance, as measured by Success Rate (SR), Success weighted by Path Length (SPL), and Distance To Goal (DTS).
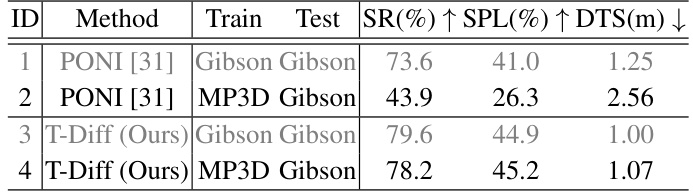
This table compares the performance of the proposed Trajectory Diffusion (T-Diff) model and the PONI model across different training and testing simulators. It demonstrates the scalability of the T-Diff model by showing that its performance is less affected when training and testing are done on different simulators compared to PONI.
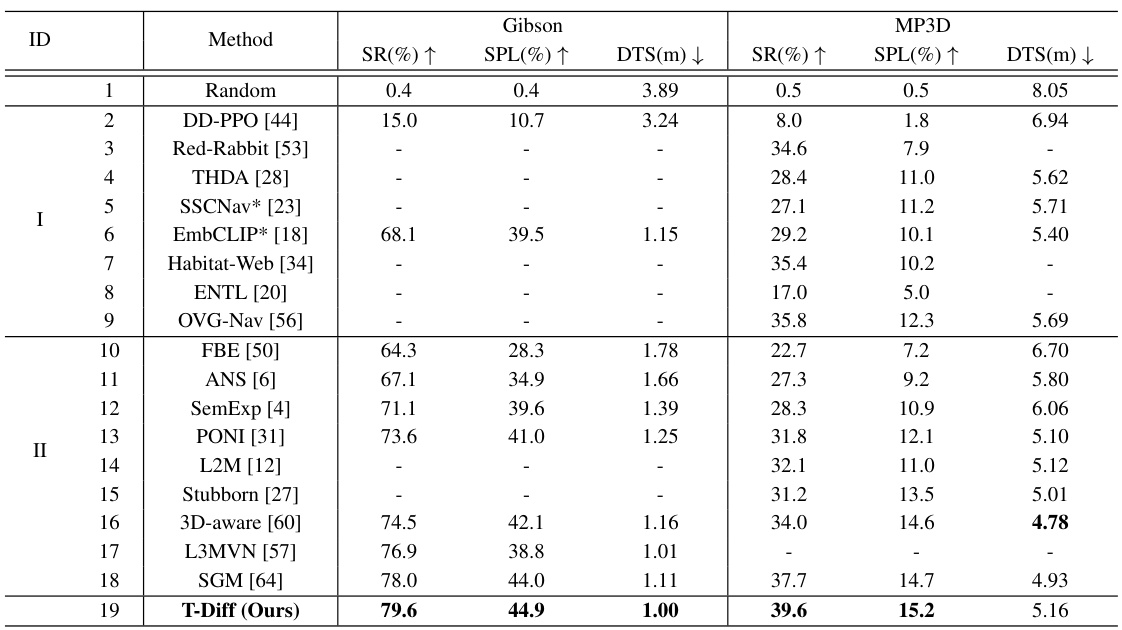
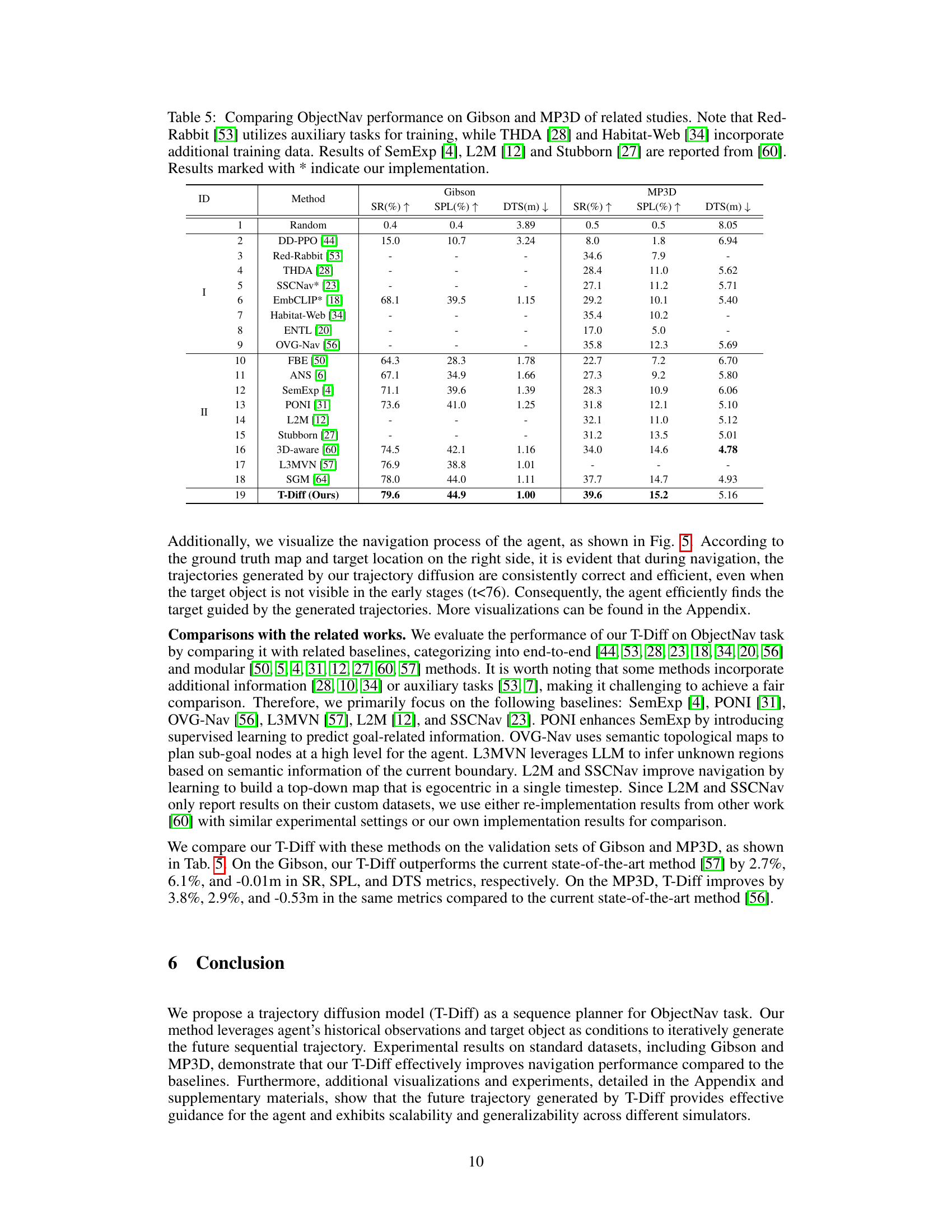
This table compares the performance of the proposed Trajectory Diffusion model (T-Diff) against other state-of-the-art methods on two standard ObjectNav datasets: Gibson and Matterport3D (MP3D). It presents success rate (SR), success weighted by path length (SPL), and distance to goal (DTS) metrics for each method. Noteworthy is the inclusion of methods that utilize auxiliary tasks or additional training data, highlighting the superior performance of T-Diff even in comparison to those approaches. The asterisk (*) denotes results that were reproduced by the authors.

This table presents the object categories used in the Gibson and Matterport3D (MP3D) datasets for both training and evaluation phases of the ObjectNav task. For Gibson, a larger set of categories is used for training, while a smaller subset is used for evaluation. Similarly, MP3D uses a comprehensive set of object categories for training and a subset for evaluation. This reflects a common practice in machine learning where a broader range of data is used to train the model, and then a more focused subset is used for testing the model’s generalization ability.

This table compares the computational complexity of four different methods for object goal navigation: SemExp, PONI, 3D-Aware, and the proposed T-Diff. The complexity is measured in terms of FLOPs (floating point operations), which represents the number of floating-point operations required to perform the computations of each method. Lower FLOPs generally indicate higher computational efficiency. The table shows that the proposed T-Diff method has a significantly lower computational cost compared to PONI, demonstrating enhanced efficiency.
Full paper#