↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for generating synthetic activity trajectories often struggle with semantic interpretation and adaptability to novel scenarios. This limits their effectiveness in simulating real-world urban mobility which is dynamic and influenced by various factors such as individual preferences, motivations and situational elements. Previous approaches primarily rely on structured data and lack versatility for more complex scenarios. Therefore, there is a need for a more intelligent and effective method for activity trajectory generation that is also interpretable.
This paper introduces LLMob, a novel framework that uses Large Language Models (LLMs) as agents to generate realistic and interpretable personal activity trajectories. LLMob addresses this challenge by incorporating semantic data, employing self-consistency to align LLM outputs with real-world data, and using retrieval-augmented strategies to make activity generation interpretable and reliable. The results show that LLMob outperforms existing state-of-the-art approaches, demonstrating its effectiveness in personal mobility generation and its potential applications in urban mobility analysis.
Key Takeaways#
Why does it matter?#
This paper is important because it pioneers the use of LLM agents for personal mobility generation, offering a novel approach to urban mobility analysis. It addresses limitations of previous models by leveraging LLMs’ semantic understanding and versatility, opening new avenues for simulating and understanding urban dynamics under various conditions. The self-consistency evaluation and retrieval-augmented strategies improve the reliability and interpretability of activity generation, creating a promising tool for urban planning and development.
Visual Insights#
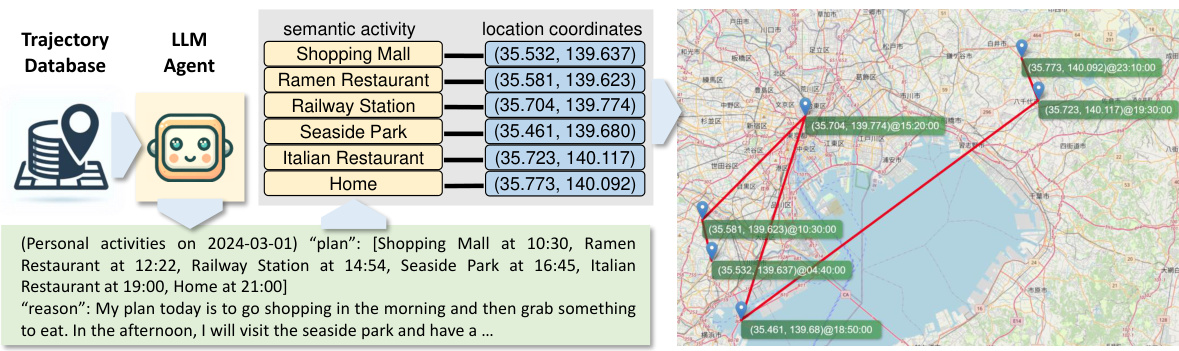
This figure illustrates the proposed LLM agent framework for personal mobility generation. An LLM agent interacts with a trajectory database containing semantic activity data (e.g., ‘Shopping Mall’, ‘Ramen Restaurant’) and location coordinates. The agent processes this data to generate a personalized plan of activities, including locations and times, along with a natural language explanation of the plan’s reasoning. The figure visually represents the process flow from data input to activity generation, highlighting the integration of LLMs for semantic understanding and flexible plan generation.

This table shows a sample of the personal activity data used in the paper. Each row represents a single activity entry and includes the user ID, latitude, longitude, location name, category, and time of the activity. The data is collected from various sources, including Twitter and Foursquare APIs.
In-depth insights#
LLM-Agent Framework#
The proposed LLM-Agent Framework represents a novel approach to personal mobility generation, leveraging the power of large language models (LLMs). Its core innovation lies in integrating LLMs within an agent-based framework, moving beyond traditional data-driven methods. This allows for the processing of semantic data, enhancing model versatility and interpretability. The framework directly addresses limitations of previous models by aligning LLMs with real-world urban mobility data through a self-consistency approach, thereby generating more realistic and reliable activity patterns. Key features include retrieval-augmented strategies for interpretable activity generation, considering individual activity patterns and motivations. This addresses a critical challenge in urban mobility analysis by offering a valuable alternative to privacy-sensitive real-world data, providing a balance between utility and privacy. The framework’s effectiveness is validated through comparison with state-of-the-art approaches, showcasing its potential for enhancing urban mobility analysis and offering a promising tool for future research and applications.
Semantic Alignment#
Semantic alignment in LLMs for activity generation focuses on bridging the gap between the model’s internal representations and the real-world meaning of human activities. Effective semantic alignment is crucial for generating realistic and interpretable activity trajectories. This involves representing activities not just as numerical coordinates or categorical labels, but also as semantically rich descriptions encompassing context, motivations, and individual preferences. This requires carefully designed prompts that provide the LLM with sufficient semantic information to understand the nuances of activity patterns and translate them into coherent, meaningful trajectories. Techniques like retrieval-augmented generation and self-consistency approaches are vital for ensuring the generated data accurately reflects the underlying semantics and aligns with real-world observations. Ultimately, successful semantic alignment enhances the model’s ability to generate not just plausible, but also interpretable and insightful activity data valuable for urban planning and mobility analysis.
Activity Pattern ID#
Identifying activity patterns is crucial for understanding human mobility. This process, which could be termed ‘Activity Pattern ID’, likely involves analyzing large datasets of location data, possibly using techniques like clustering or sequence mining to identify recurring patterns. Data preprocessing is essential, likely involving handling missing data, dealing with noisy sensor readings, and potentially normalizing data to account for individual differences in movement. Once patterns are identified, techniques for pattern representation and comparison are key. This might involve using statistical measures or more sophisticated methods that capture the temporal and spatial aspects of mobility patterns. The goal is to extract meaningful and actionable insights, such as identifying common travel routes, frequent destinations, and typical activity sequences, which can be used for numerous applications in urban planning, transportation management, and personalized recommendations.
Motivation Retrieval#
The concept of ‘Motivation Retrieval’ in this context is crucial for enhancing the realism and interpretability of AI-generated activity trajectories. The authors explore two primary methods: evolving-based and learning-based approaches. The evolving method leverages the intuitive principle that daily motivations are influenced by preceding days’ activities, using LLMs to infer patterns and motivations from past behavior. This approach relies on the LLM’s ability to understand the context of prior actions and their underlying reasons. In contrast, the learning-based method hypothesizes consistent routines driven by underlying motivations. It employs a contrastive learning technique on historical data to predict future motivations, thereby capturing habitual patterns and preferences. Both approaches aim to add a layer of semantic understanding to the generated trajectories, moving beyond simple statistical imitation of observed data. The choice between these methods likely involves a trade-off between the computational cost and data requirements of the learning-based approach versus the relative simplicity and reliance on LLM reasoning capabilities of the evolving-based method. The success of either method hinges on the quality and richness of the input data and the LLM’s capacity to effectively interpret and extrapolate motivations from the provided information. The fusion of these retrieval methods with activity patterns promises to yield more human-like and meaningful simulations of individual mobility.
Urban Mobility App#
An urban mobility app could revolutionize city life by integrating various transportation modes (public transit, ride-sharing, biking, walking) into a single, user-friendly interface. This would allow users to plan efficient multimodal journeys, considering factors like real-time traffic, cost, and personal preferences. Data analytics would be crucial, providing insights into usage patterns to optimize routes and infrastructure, while personalization features could cater to individual needs and habits. Privacy concerns would need careful consideration, requiring secure data handling and transparent user controls. Successful implementation relies on robust partnerships between app developers, transit agencies, and city planners, ensuring seamless integration and broad accessibility. Furthermore, the app could incorporate innovative features, such as carbon footprint calculations, accessibility information, and integration with smart city systems, to enhance sustainability and inclusivity. The app’s success hinges on its ability to become an essential tool for urban dwellers, fostering efficient, affordable, and environmentally friendly mobility.
More visual insights#
More on figures
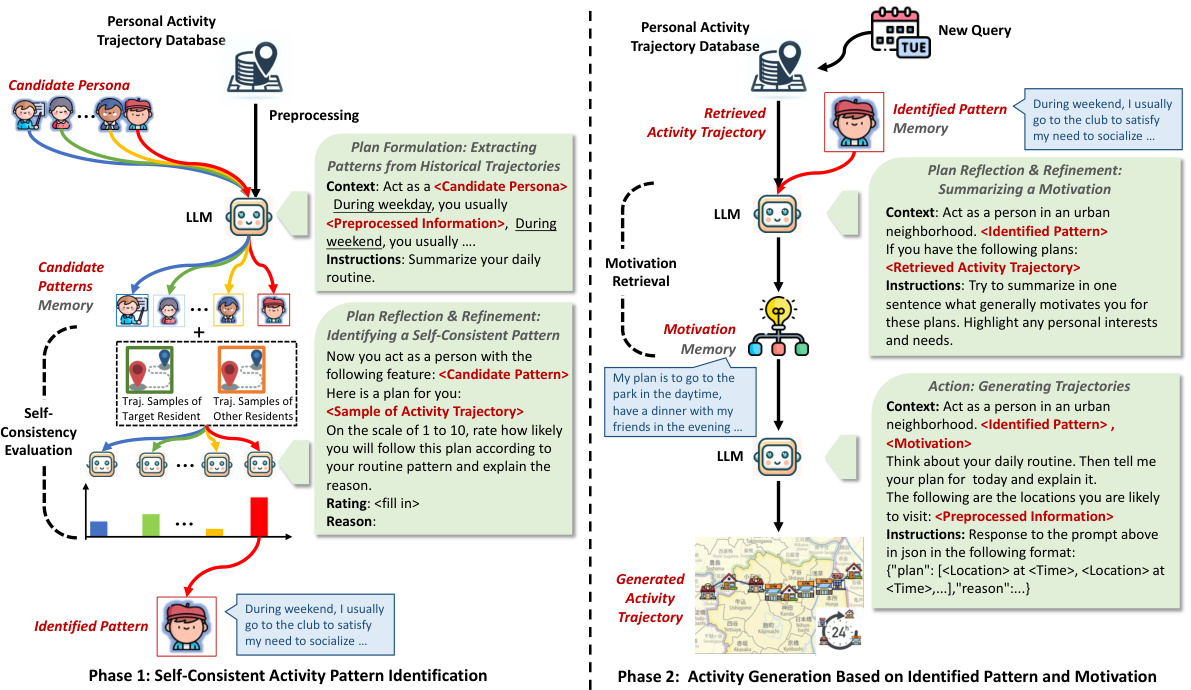
This figure illustrates the LLM agent framework, LLMob, for personal mobility generation. It comprises two phases: Phase 1 focuses on identifying self-consistent activity patterns from historical trajectories using LLMs and a self-consistency evaluation. Phase 2 leverages these identified patterns and retrieved motivations (using two strategies: evolving-based and learning-based) to generate daily activity trajectories. The framework incorporates elements like action, memory, and planning, and utilizes GPT-3.5 APIs for LLM functionality.

This figure illustrates the evolving-based motivation retrieval method used in the LLMob framework. It shows how the LLM agent infers the motivation for a target day (day d) by considering the activities and motivations from the preceding k days (d-1, d-2,…d-k). The LLM processes the activities of the previous days to generate a summary of the motivations behind those activities. These summarized motivations are then used as input to predict the motivation for day d.

This radar chart compares the daily activity frequencies of different activity categories (Arts & Entertainment, Nightlife Spot, Professional & Other Places, Outdoors & Recreation, Shop & Service, Food, College & University) generated by three models: TrajGAIL, LLMob-L, and LLMob-L with a ‘Pandemic’ prompt. It also shows the ground truth frequencies. The chart visually represents the distribution of activities across different categories, highlighting differences between the models’ predictions and the actual observed frequencies, especially under the context of a pandemic.

This figure illustrates the proposed LLM agent framework for personal mobility generation. An LLM agent interacts with a trajectory database containing semantic activity data (e.g., location names, coordinates, time stamps, and activity descriptions) to generate personalized activity plans. The LLM agent considers semantic information and activity patterns to produce interpretable and realistic activity trajectories that reflect real-world urban mobility patterns. The figure shows the LLM agent processing information and generating a plan with reasons.
More on tables
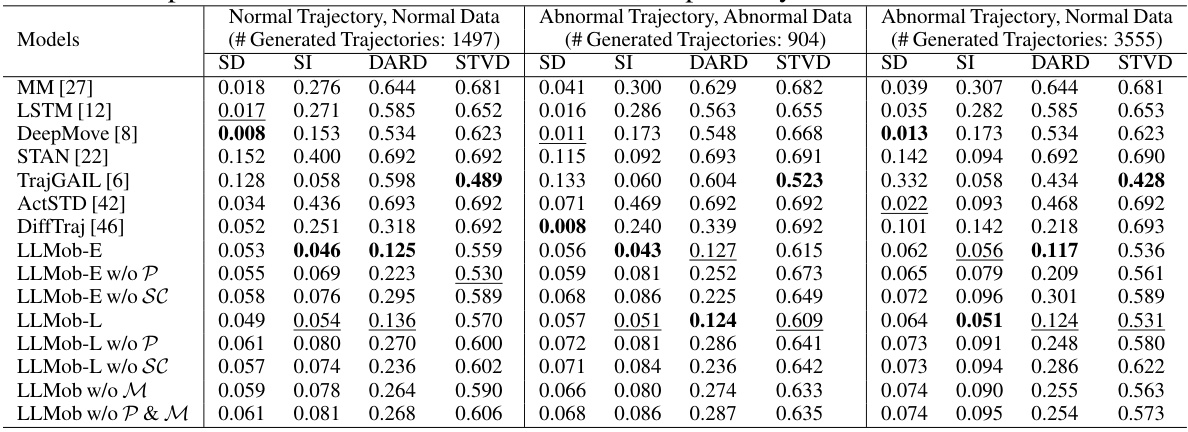
This table presents the Jensen-Shannon Divergence (JSD) scores for various personal mobility generation models across three different scenarios: normal trajectories with normal data, abnormal trajectories with abnormal data, and abnormal trajectories with normal data. Lower JSD indicates better performance, as it signifies a closer match between generated and real-world activity patterns. The models compared include several baselines, along with variants of the proposed LLMob framework (with and without certain components such as pattern identification and self-consistency evaluation).

This table presents the Jensen-Shannon Divergence (JSD) scores for different trajectory generation models evaluated on three different scenarios: generating normal trajectories using normal data, generating abnormal trajectories using abnormal data, and generating abnormal trajectories using normal data. Lower JSD indicates better performance in matching generated trajectories to real-world data. The table highlights the performance of the proposed LLMob framework in comparison to several state-of-the-art baselines across various metrics, including step distance (SD), step interval (SI), daily activity routine distribution (DARD), and spatial-temporal visits distribution (STVD).
This table presents the Jensen-Shannon divergence (JSD) scores for various personal mobility generation models. Lower JSD indicates better performance in generating trajectories similar to real-world data. The models are evaluated based on three settings: generating normal trajectories with normal data, abnormal trajectories with abnormal data, and abnormal trajectories with normal data. The table shows that the proposed LLMob models generally outperform existing state-of-the-art methods, particularly in terms of daily activity routine distribution (DARD).
This table presents the Jensen-Shannon divergence (JSD) scores for various personal mobility generation models. Lower JSD indicates better performance in generating trajectories that closely resemble real-world data. The table compares the performance of LLMob with several state-of-the-art models across three different settings: generating normal trajectories using normal data, generating abnormal trajectories using abnormal data, and generating abnormal trajectories using normal data. The models are evaluated on four metrics: Step Distance (SD), Step Interval (SI), Daily Activity Routine Distribution (DARD), and Spatial-Temporal Visits Distribution (STVD). The best-performing models for each metric and setting are highlighted.

This table presents the Jensen-Shannon divergence (JSD) scores for various trajectory generation models across three different scenarios: generating normal trajectories from normal data, generating abnormal trajectories from abnormal data, and generating abnormal trajectories from normal data. Lower JSD indicates better performance, aligning the generated trajectories more closely with the real-world data. The table also highlights the best-performing models (in bold) and second-best models (underlined) for each metric and scenario.

This table presents a comparison of different trajectory generation models based on four metrics: Step Distance (SD), Step Interval (SI), Daily Activity Routine Distribution (DARD), and Spatial-Temporal Visits Distribution (STVD). The models compared include LLMob-L, LLMob-E, DiffTraj, and TrajGAIL. Lower values for all metrics indicate better performance.

This table presents the results of experiments conducted using different Large Language Models (LLMs). Specifically, it shows the Jensen-Shannon Divergence (JSD) scores for several metrics (SD, SI, DARD, STVD) across three different LLMs: GPT-3.5-turbo, GPT-40-mini, and Llama 3-8B. Lower JSD scores indicate better performance in generating realistic activity trajectories. The results are broken down by both the evolving-based and learning-based motivation retrieval methods used within the LLMob framework. This allows for comparison of performance across different LLMs and the two distinct motivation retrieval strategies.
Full paper#



















