↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current research on large language models (LLMs) often assumes that these models possess human-like causal reasoning capabilities. However, there is limited empirical evidence to support this claim. Many studies show that LLMs mainly perform basic level-1 causal reasoning, heavily relying on information from their training data. This raises concerns about the true nature of causal reasoning in LLMs and their potential for making sound decisions in complex, real-world scenarios.
To investigate this issue, the authors introduce CausalProbe-2024, a novel benchmark dataset designed to assess the genuine causal reasoning capabilities of LLMs. They also propose a new method called G2-Reasoner, which enhances LLMs’ causal reasoning by incorporating general knowledge and goal-oriented prompts. The results demonstrate that G2-Reasoner significantly enhances the performance of LLMs in handling novel and counterfactual situations, thus bringing LLMs closer to achieving human-like causal reasoning. This research highlights the importance of carefully evaluating LLM capabilities and exploring methods for improving their ability to perform genuine causal reasoning.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI and related fields because it challenges the common assumption that large language models (LLMs) possess genuine causal reasoning abilities. By introducing a novel benchmark and a novel method, the research opens new avenues for investigating and enhancing causal reasoning in LLMs, which is a critical step towards achieving strong AI. The findings directly address current debates surrounding LLM capabilities and offer valuable insights for future research directions.
Visual Insights#

This figure illustrates the motivation behind the research by showcasing the limitations of current LLMs in handling causal reasoning tasks. Panel (a) demonstrates the strong performance of LLMs on common causal reasoning tasks, while (b) highlights their struggles with less common or novel tasks. Panel (c) introduces the new benchmark, CausalProbe-2024, with variations in difficulty (CausalProbe-E, CausalProbe-H, CausalProbe-M). Finally, (d) visually compares the performance of several LLMs on CausalProbe-2024 against existing benchmarks, revealing a significant drop in accuracy, underscoring the need for improvement in LLM causal reasoning capabilities.

This table presents the exact match scores achieved by four different large language models (LLMs) on four causal question answering benchmarks. The LLMs are evaluated using three different methods: vanilla (direct inference), chain-of-thought prompting, and retrieval augmented generation. The benchmarks include established datasets (COPA, e-CARE, CausalNet) and a newly introduced dataset (CausalProbe 2024), which is further divided into easier and harder sub-tasks (C-E and C-H). The results highlight the performance differences between the LLMs and across different reasoning methods, showing how performance varies across different levels of causal reasoning complexity and how a new reasoning strategy might help enhance the performance.
In-depth insights#
Causal Reasoning#
The concept of causal reasoning within the context of large language models (LLMs) is a complex one, marked by both promising capabilities and significant limitations. While LLMs demonstrate proficiency in handling common, well-documented causal scenarios, their performance degrades considerably when presented with novel, less frequently encountered instances, suggesting a reliance on pattern recognition rather than true causal understanding. This highlights a critical distinction between superficial, surface-level causal reasoning (level-1) that LLMs excel at, and the deeper, more nuanced, human-like causal reasoning (level-2) that remains largely elusive to current models. Bridging this gap requires moving beyond the autoregressive mechanisms that currently underpin LLMs, and towards incorporating broader knowledge resources, goal-oriented prompts, and potentially more sophisticated model architectures that enable counterfactual thinking and genuine causal inference.
LLM Limitations#
Large Language Models (LLMs), while demonstrating impressive capabilities, are not without limitations. A crucial limitation is their reliance on shallow, correlation-based reasoning, rather than true causal understanding. This means LLMs excel at tasks involving readily available information but struggle with nuanced scenarios requiring counterfactual thinking or inferring causal relationships from limited data. Autoregressive architectures, while efficient for text generation, inherently lack the capacity to model true causal structures, hindering deeper reasoning abilities. Moreover, the extent to which LLMs exhibit genuine causal understanding remains unclear. While their outputs might appear causally sound, they often merely reflect patterns learned from the training data, rather than true inferential capacity. Therefore, developing genuine causal reasoning in LLMs requires moving beyond simple pattern recognition to build models that can explicitly represent and reason about causal links. This is a significant challenge requiring both methodological innovations and advancements in the underlying theoretical frameworks of causality. Addressing these limitations is key to unlocking the full potential of LLMs and advancing them toward more human-like intelligence.
G2-Reasoner#
The proposed G2-Reasoner framework represents a novel approach to enhancing causal reasoning in Large Language Models (LLMs). Its core innovation lies in incorporating general knowledge and goal-oriented prompts to guide the LLM’s reasoning process, thereby moving beyond the limitations of existing methods. This is a significant departure from current autoregressive LLMs which tend to rely on surface-level correlations and memorized patterns in the training data. The integration of external knowledge, potentially through a retrieval-augmented generation (RAG) system, allows the model to draw on broader contextual information and avoid spurious associations. The goal-oriented prompts act as a powerful steering mechanism, ensuring the LLM stays focused on the core causal question rather than getting sidetracked by tangential issues. While the empirical results might show moderate improvements in this initial presentation, the framework’s potential to unlock genuine level-2 causal reasoning, akin to human-level cognition, is promising. Further research and larger-scale experiments are needed to fully assess its effectiveness and potential limitations.
CausalProbe-2024#
The proposed benchmark, CausalProbe-2024, aims to rigorously evaluate large language models’ (LLMs) genuine causal reasoning capabilities. Unlike previous benchmarks, CausalProbe-2024’s datasets are made public after the training cutoff dates of several prominent LLMs, ensuring the evaluation data is genuinely novel for the models, thus reducing reliance on memorized patterns. This methodology allows for a more accurate assessment of LLMs’ capacity to perform truly novel causal reasoning, going beyond simple association learning (level-1 reasoning) and potentially reaching a level of genuine causal understanding that mirrors human cognition (level-2 reasoning). The creation of CausalProbe-2024, with its multiple-choice and varying-difficulty question formats, provides a more nuanced and robust assessment of this crucial capability. The findings from using this benchmark are expected to help steer research towards advancing LLMs’ genuine causal reasoning abilities.
Future Work#
Future research directions stemming from this paper could explore several key areas. Expanding the G2-Reasoner framework is crucial, particularly by incorporating larger and more diverse knowledge bases, potentially using external APIs, to enhance the model’s ability to reason with comprehensive, real-world information. Further investigation into the limitations of autoregressive models in handling causal reasoning could lead to developing alternative architectures better suited for this task. Creating more sophisticated causal reasoning benchmarks is also vital, moving beyond simplistic cause-and-effect scenarios and into complex, multi-causal scenarios. This would require carefully designed datasets that address bias and ensure freshness, to accurately assess model performance in genuine, real-world causal understanding. Finally, bridging the gap between level-1 and level-2 causal reasoning remains a critical challenge. This could involve investigating novel prompting strategies, developing hybrid approaches combining symbolic and neural methods, or exploring new training methodologies specifically aimed at fostering genuine causal understanding in LLMs.
More visual insights#
More on figures
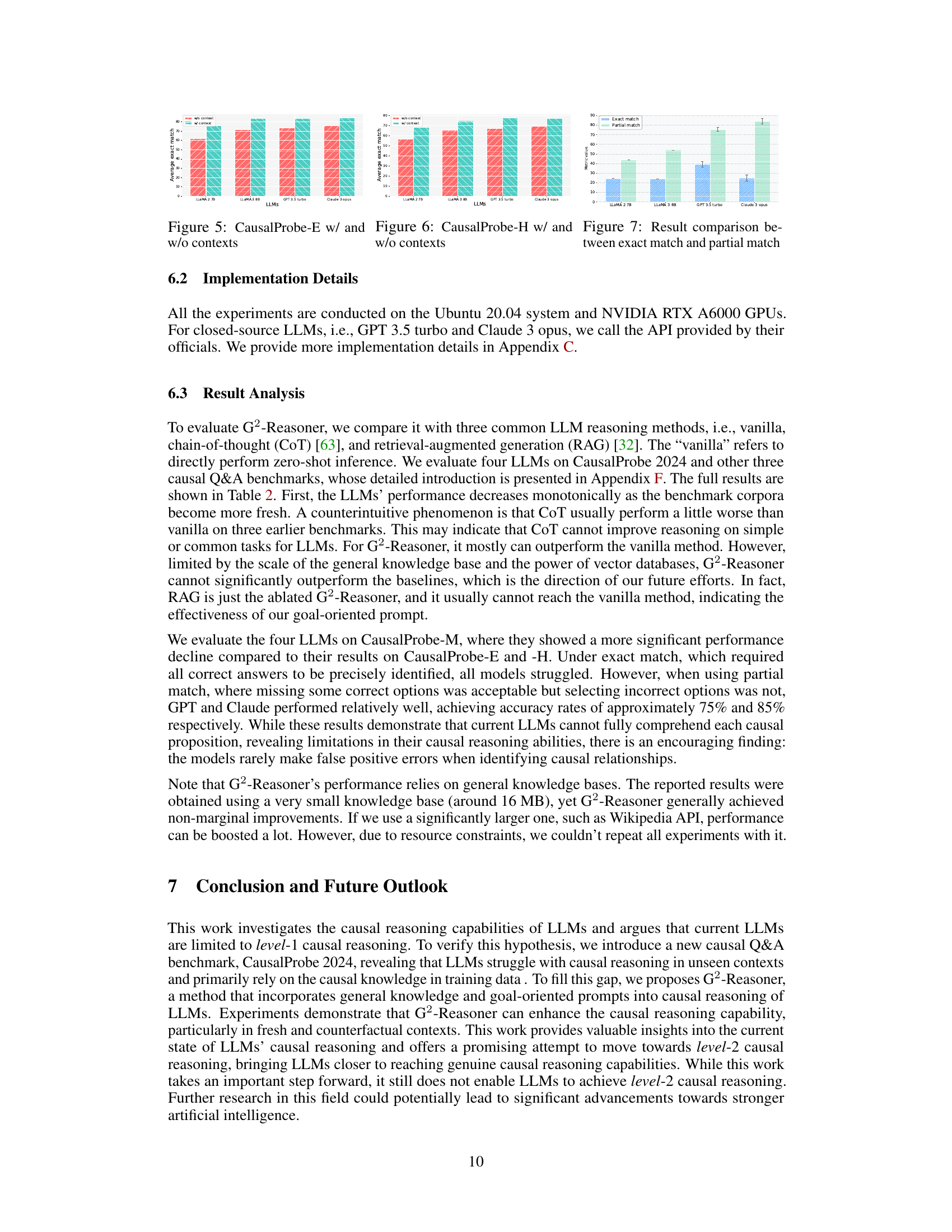
This figure illustrates the difference between the actual causal relationship and the sequential causal relationship captured by autoregression in LLMs. Panel (a) shows the ground truth causal relationship: rain causes school closure, which in turn causes Jack to learn at home. Panel (b) shows how autoregression might represent this: The model sees a sequence of events (rain, school closure, learn at home) and creates a shallow, sequential relationship. It fails to properly model the actual causal links and might mistakenly infer causation where none exists, or miss crucial causal links present in the real-world scenario.

The figure illustrates the G²-Reasoner framework, which enhances LLMs’ causal reasoning capabilities. It consists of two main components: a retrieval-augmented generation (RAG) system that retrieves relevant general knowledge from a knowledge base, and a goal-oriented prompt designed to guide the LLM’s reasoning process towards the correct causal relationship. The RAG system uses an embedding model and a vector database to retrieve relevant knowledge, while the goal-oriented prompt provides instructions and context to ensure focused and logical causal inference.
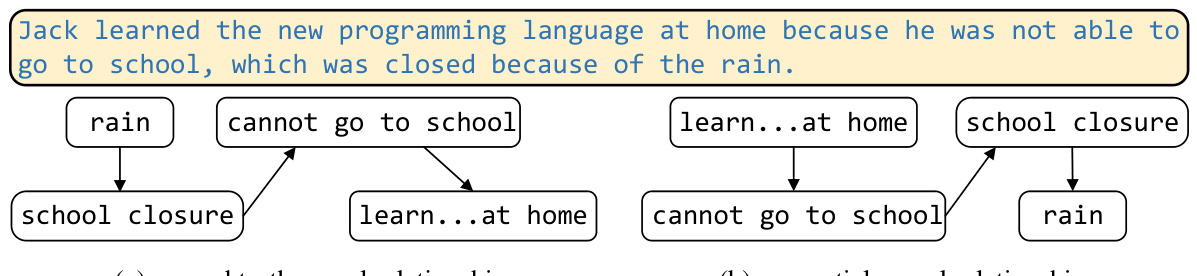
This figure illustrates the three-step pipeline for constructing the CausalProbe 2024 benchmark dataset. It details how GPT-3.5 Turbo was used to generate three different types of causal reasoning questions: CausalProbe-E (easy, one correct answer), CausalProbe-H (hard, one correct answer with distractors), and CausalProbe-M (multiple choice, multiple correct answers). The process emphasizes the use of example prompts to guide the LLM, ensuring the quality and variety of questions.
This figure demonstrates that large language models (LLMs) perform well on common causal reasoning tasks but struggle with less common ones. It introduces a new benchmark, CausalProbe-2024, designed to evaluate LLMs’ true causal reasoning abilities. This benchmark includes three versions: easy, hard, and uncertain, each with varying difficulty. The figure shows that the LLMs’ performance drops significantly on CausalProbe-2024 compared to previous benchmarks.

This bar chart displays the distribution of the number of correct answers within the multiple-choice questions of the CausalProbe-M dataset. The x-axis represents the number of correct answers (1 to 4), and the y-axis represents the count of questions with that number of correct answers. The distribution shows that a significant portion of the questions have 2 or 3 correct answers. This design prevents LLMs from simply guessing to get correct answers.
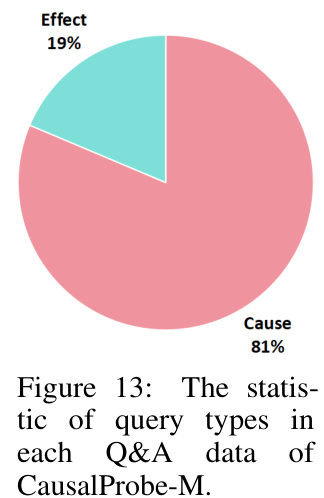
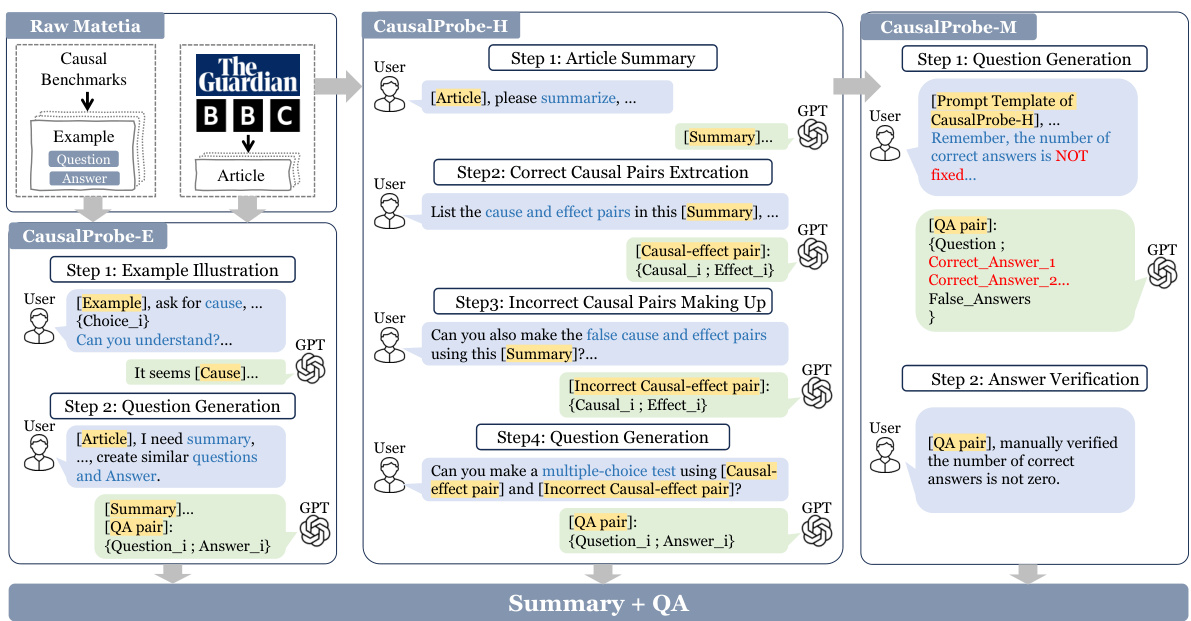
The pie chart shows the distribution of question types in the CausalProbe-M dataset. The majority of questions (81%) ask about the cause of an event, while a smaller proportion (19%) ask about the effect.

This figure demonstrates the motivation behind the research by highlighting the strengths and weaknesses of LLMs in causal reasoning. It shows that while LLMs perform well on common causal reasoning tasks (a), they struggle with rare or unseen tasks (b). The figure introduces a new benchmark, CausalProbe-2024 (c), which is designed to evaluate the true level of causal reasoning ability in LLMs. The three variants of the benchmark (CausalProbe-E, CausalProbe-H, and CausalProbe-M) differ in difficulty and format. Finally, (d) illustrates the significant performance drop that LLMs exhibit on CausalProbe-2024 compared to existing benchmarks, suggesting that they primarily perform shallow causal reasoning.

This figure shows the architecture of the G2-Reasoner framework, which is proposed to enhance LLMs’ causal reasoning capabilities. It consists of two main modules: a RAG (Retrieval-Augmented Generation) module to incorporate external knowledge related to the causal question and a goal-oriented prompt module to guide the LLM towards achieving the desired outcome of causal reasoning. The RAG module retrieves relevant knowledge from a general knowledge base using an embedding model and a retriever, while the goal-oriented prompt module provides specific instructions to improve the LLM’s performance in causal reasoning tasks.

The G²-Reasoner framework enhances LLMs’ causal reasoning by incorporating a retrieval-augmented generation (RAG) system and goal-oriented prompts. The RAG system retrieves relevant general knowledge, while the goal-oriented prompt guides the LLM towards accurate causal reasoning, improving performance particularly in novel and counterfactual scenarios.

This figure demonstrates the motivation behind the research by highlighting LLMs’ inconsistent performance on causal reasoning tasks. Panel (a) shows strong LLM performance on common tasks, while (b) shows poor performance on less common tasks with novel data. Panel (c) introduces the CausalProbe-2024 benchmark, showcasing its variations in difficulty. Finally, (d) presents a comparison of LLM performance across different benchmarks, revealing a significant drop on the novel CausalProbe-2024 benchmark.
More on tables
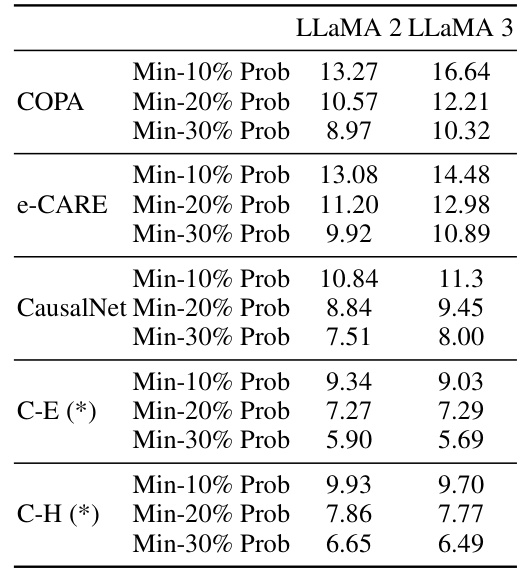
This table presents the results of a membership inference attack using the Min-K% Prob method to assess the freshness of the data used in the CausalProbe 2024 benchmark and three other benchmarks (COPA, e-CARE, and CausalNet). The attack was conducted on two LLMs, LLaMA 2 7B and LLaMA 3 8B. A lower average negative log-likelihood indicates that the benchmark’s data is less likely to be present in the LLMs’ training data, suggesting greater freshness. The results are broken down by different percentages (Min-10%, Min-20%, Min-30%) of the tokens considered in the evaluation.

This table presents the results of a volunteer selection process for quality control of the CausalProbe-2024 dataset. It shows the difficulty level (Diff level) of 20 questions rated by 17 volunteers on a 1-10 scale (10 being the most difficult), their accuracy (Acc (%)) in answering those questions, and whether they were deemed qualified (Qualified) based on accuracy and difficulty criteria.

This table presents the results of a membership inference attack (Min-K% Prob) used to assess the freshness of the data used in different causal reasoning benchmarks. The lower the average negative log-likelihood, the less likely the data was present in the model’s training data. The results show that CausalProbe 2024 data is significantly fresher compared to existing benchmarks (COPA, e-CARE, and CausalNet), supporting the claim that LLMs perform poorly on CausalProbe 2024 due to the lack of exposure during training. The evaluation is performed on Llama 2 7B and Llama 3 8B.
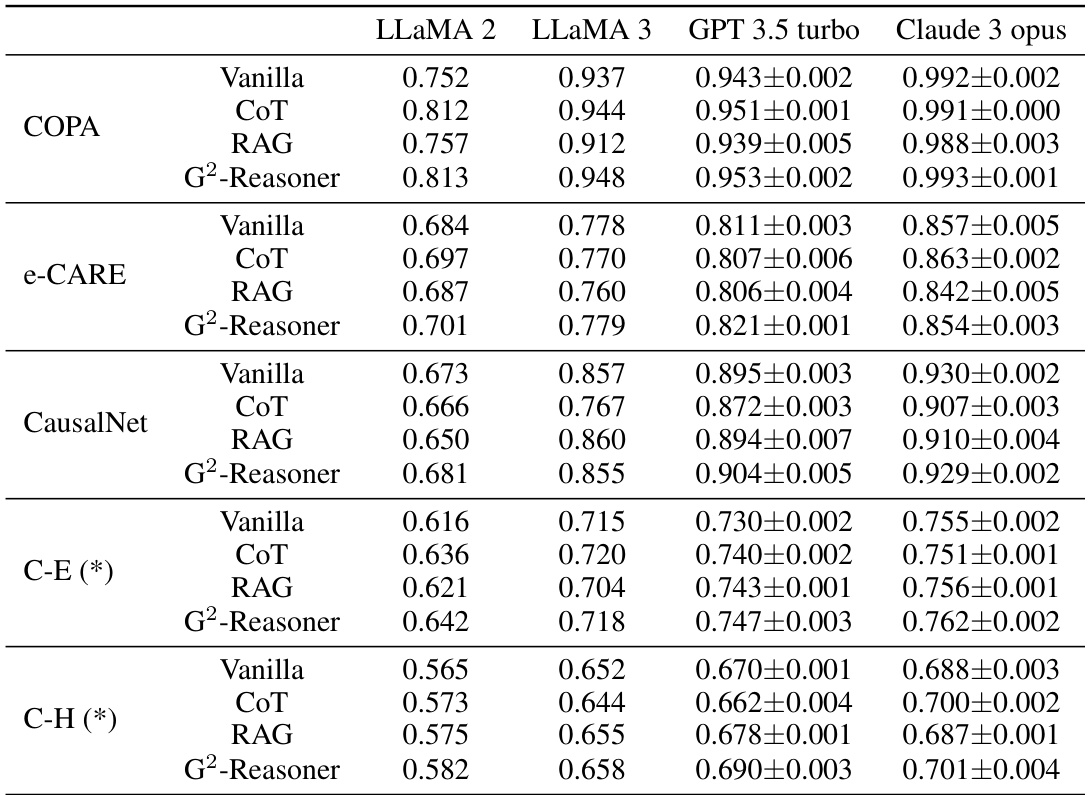
This table presents the exact match scores achieved by four different Large Language Models (LLMs) across four causal question and answering (Q&A) benchmark datasets. The benchmarks include COPA, e-CARE, CausalNet, and the authors’ newly created CausalProbe 2024 (with easy and hard variations). The models were evaluated using a ‘vanilla’ approach (direct inference) and three enhanced approaches: Chain of Thought (COT), Retrieval Augmented Generation (RAG), and the authors’ G2-Reasoner. The table demonstrates the performance of each model and approach on each benchmark, showing how the different LLMs and methods compare. Standard deviations, offering a measure of the variability of the results, are detailed in Appendix G.

This table presents the exact match scores achieved by four different large language models (LLMs) on four distinct causal question and answering (Q&A) benchmark datasets. The models’ performance is evaluated using the ’exact match’ metric, assessing the accuracy of their responses. The ‘vanilla’ method indicates a direct, unprompted inference; while ‘C-E’ and ‘C-H’ refer to the CausalProbe-E and CausalProbe-H subsets within the CausalProbe 2024 benchmark.

This table compares the last updated time of the training datasets for four large language models (LLMs): LLaMA 2 7B chat, LLaMA 3 8B instruct, GPT 3.5 turbo, and Claude 3 opus. It also shows the release date of the CausalProbe 2024 benchmark. The comparison highlights that the CausalProbe 2024 dataset was released significantly later than the training data cutoff times for all four LLMs, ensuring that the benchmark data is new and unseen by the models during their training.
Full paper#