↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Diffusion-based policies (DPs) offer a promising approach to robot learning, demonstrating robustness across various tasks. However, their safety remains largely unaddressed. Previous attacks on deep learning models prove ineffective against the unique chained structure and randomness inherent in DPs. This research addresses this gap.
The paper introduces DP-Attacker, a comprehensive set of algorithms that craft effective adversarial attacks against DPs. These attacks encompass offline/online, global/patch-based scenarios. Experiments across various robotic manipulation tasks demonstrate DP-Attacker’s effectiveness in significantly reducing DP performance. Notably, offline attacks generate highly transferable perturbations, applicable to all frames, thus posing a considerable threat. The research further explores creating adversarial physical patches that deceive the model when applied in real-world environments.
Key Takeaways#
Why does it matter?#
This paper is crucial because it pioneers the study of adversarial attacks against diffusion-based robot policies, a critical area largely unexplored until now. Its findings reveal significant vulnerabilities and spur further research into robust and safe AI systems for robotics, thus advancing the field considerably.
Visual Insights#

This figure illustrates three different attack methods against diffusion-based policies. (a) shows a high-level overview of the attack, where incorrect actions are generated by manipulating the visual input. (b) details the process of applying adversarial perturbations to the camera input, categorized by online (dynamic, adapting to each frame) and offline (static, applied consistently). (c) depicts an attack using a physical adversarial patch placed in the environment to perturb the robot’s visual input, again resulting in incorrect actions.
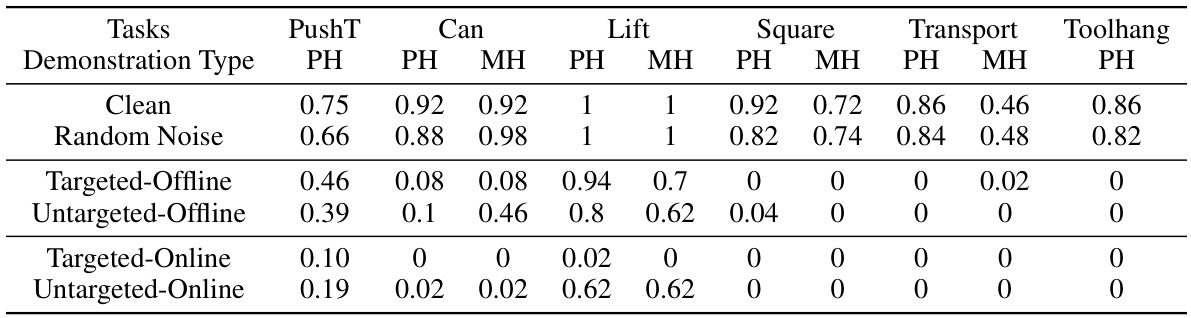
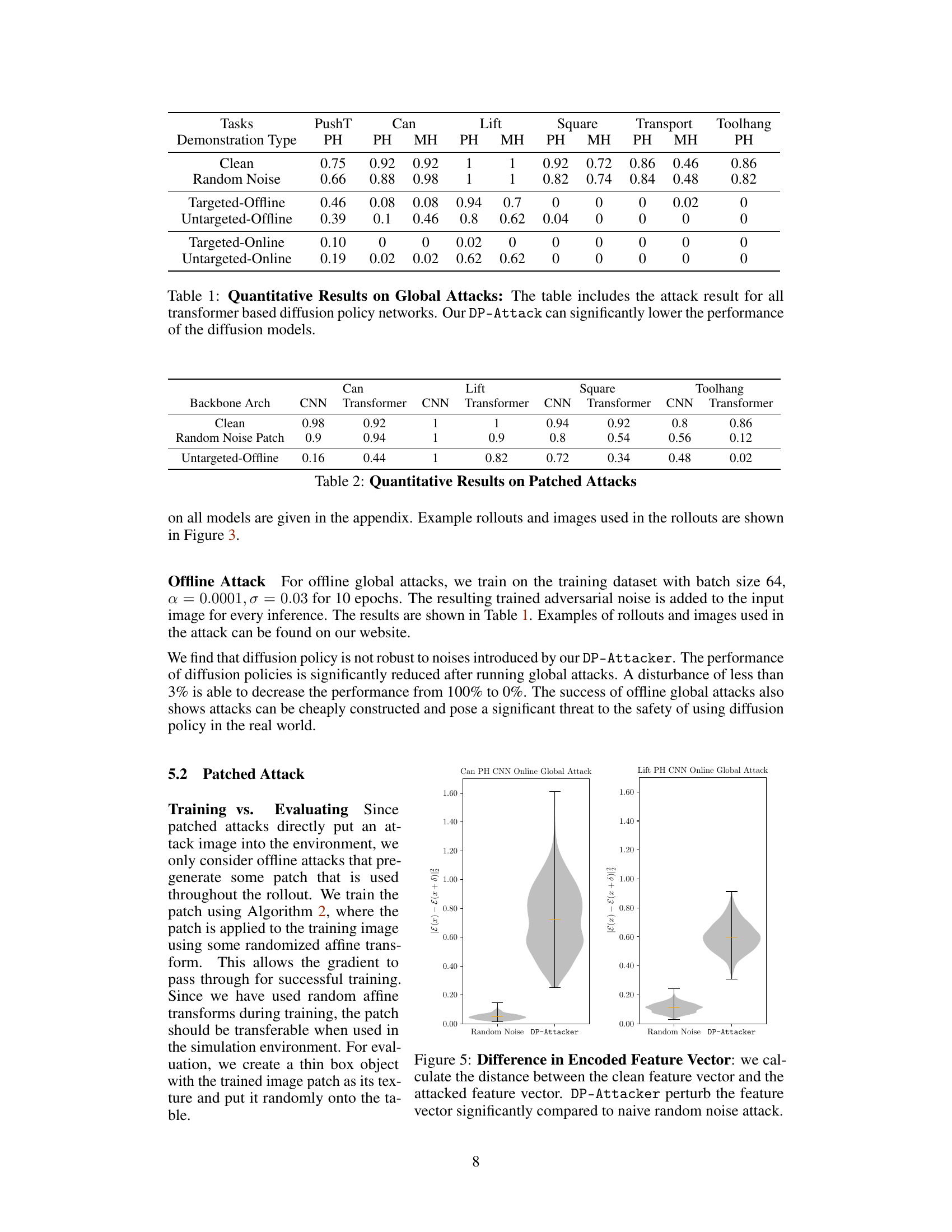
This table presents the quantitative results of global attacks on transformer-based diffusion policy networks. It compares the success rate (performance) of the models under different attack scenarios: clean (no attack), random noise, targeted offline, untargeted offline, targeted online, and untargeted online. The results show a significant decrease in performance when DP-Attacker is used, demonstrating its effectiveness in reducing the models’ success rate.
In-depth insights#
DP-Attacker Design#
The design of DP-Attacker is multifaceted, addressing the inherent complexities of diffusion-based policies. It cleverly leverages the white-box access to the policy network, allowing for the crafting of both digital and physical adversarial attacks. The framework is designed to create perturbations that effectively deceive the diffusion process, generating undesirable actions. The distinction between online and offline attack methods is crucial, impacting how adversarial examples are created and applied. Online attacks adapt to the dynamics of the environment, creating time-variant perturbations, whereas offline attacks produce static perturbations effective across multiple frames. The global and patched attack strategies target different vulnerabilities, enabling attacks through either global image manipulation or the introduction of localized physical patches. This adaptability of DP-Attacker highlights its potential robustness and threat to the security of a broader class of diffusion-based systems. The careful consideration of varied attack scenarios enhances the overall efficacy of DP-Attacker, highlighting its potential as a valuable tool for evaluating the robustness of diffusion-based policies.
Adversarial Patch#
The concept of “Adversarial Patch” in the context of a research paper likely explores the creation and application of small, specifically designed image patches to deceive a machine learning model, particularly those based on visual data. These patches are designed to be visually imperceptible or blend seamlessly with the environment yet cause the model to misclassify or misinterpret the scene. The effectiveness of an adversarial patch hinges on its ability to introduce a subtle but significant perturbation within the visual input, triggering a targeted misbehavior in the model’s output. This approach differs from other adversarial attacks that typically involve modifying entire images. Research in this area would likely delve into the design methodologies for generating these patches (optimization algorithms are likely employed), the robustness of these patches against various transformations and environmental conditions, and the broader implications of such attacks on safety and security-critical systems. A core aspect would involve demonstrating the effectiveness of these patches against multiple models, different environmental conditions, and evaluating potential defenses.
Global Attack#
The concept of a “Global Attack” in the context of adversarial machine learning, specifically targeting diffusion-based policies, involves manipulating the entire observation image, rather than isolated parts. This approach is significant because it tests the model’s robustness to holistic perturbations, not just localized changes. The paper explores both online and offline variations. Online attacks generate dynamic perturbations based on the current visual input, adapting to the changing environment. Offline attacks generate a single, transferable perturbation applicable across all frames, which has stronger implications for real-world security because it’s harder to detect and mitigate. The effectiveness of this attack demonstrates vulnerabilities in image processing and the reliance of diffusion models on accurate global perception. The use of gradient-based optimization techniques, like Projected Gradient Descent (PGD), highlights the sophistication of these attacks and their potential to severely degrade model performance. Furthermore, this attack’s ability to produce transferable perturbations reveals limitations of the diffusion policy and raises concerns about its resilience in uncontrolled environments.
Offline Attacks#
Offline attacks, in the context of adversarial attacks against diffusion-based policies, represent a significant threat due to their transferability and potential for real-world impact. Unlike online attacks which leverage real-time observations, offline attacks pre-compute adversarial perturbations using only training data. This characteristic makes them highly effective, as the perturbations are designed to remain effective regardless of the specific input observed at runtime. The significant advantage of offline attacks is the ease of deployment: once created, the adversarial perturbations can be applied repeatedly without requiring constant recalculation. However, it is crucial to consider that the efficacy of offline attacks is dependent on the similarity between the training data and the real-world scenarios. A major challenge in offline attacks is finding a balance between perturbation strength and imperceptibility; a perturbation strong enough to significantly impact the policy’s performance while remaining undetectable is not easy to achieve. The creation of transferable adversarial patches for offline attacks further highlights the significance of offline attack vectors as they represent a potent threat due to their physical nature and potential for widespread applicability across various environments.
Future Work#
Future research directions stemming from this work could focus on enhancing the robustness of diffusion policies against adversarial attacks. This might involve exploring novel training methodologies that explicitly incorporate adversarial examples, potentially leveraging techniques from robust optimization or generative adversarial networks. Investigating alternative model architectures or incorporating inherent uncertainty modeling into the diffusion process could also improve resilience. Developing effective defense mechanisms is crucial, and this should encompass both digital and physical countermeasures. Furthermore, research should extend beyond white-box attacks to explore black-box and transferability aspects of adversarial examples against diffusion policies. Finally, a systematic analysis of the impact of various noise scheduling strategies and other hyperparameters on adversarial vulnerability is needed. Understanding the underlying reasons for vulnerability is key to developing effective defenses; focusing on the encoder’s susceptibility, as suggested by the findings, is a promising avenue.
More visual insights#
More on figures
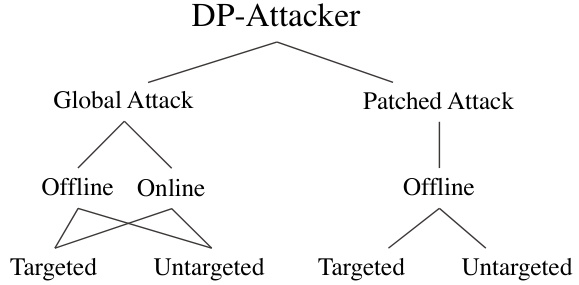
This figure illustrates the different attack strategies implemented by the DP-Attacker. DP-Attacker is categorized into two main approaches: Global Attacks and Patched Attacks. Global Attacks involve manipulating the camera input, either offline (using a pre-computed perturbation) or online (generating perturbations in real-time). Both types of global attacks can be targeted (aiming for a specific bad action) or untargeted (simply trying to degrade performance). Patched Attacks involve placing physical adversarial patches in the robot’s environment. These too can be targeted or untargeted and are implemented offline.

This figure visualizes the results of online global attacks on two robotic manipulation tasks: PushT and Can. It compares four scenarios: clean observations, observations with added random Gaussian noise, observations with untargeted adversarial perturbations generated by DP-Attacker, and observations with targeted adversarial perturbations. The results show that while the diffusion policies are robust to random noise, they are vulnerable to the adversarial perturbations crafted by DP-Attacker, indicating a significant decrease in performance for both targeted and untargeted attacks.

This figure shows three examples of physical adversarial patches generated by the DP-Attacker algorithm. Each patch is designed to target a specific robotic manipulation task (Can, Square, Toolhang). The patches are small, visually inconspicuous, and designed to be robust to changes in lighting and viewing angle. Attaching the patch to the environment fools the diffusion policy into making incorrect actions, significantly reducing task success rate.

This figure displays violin plots showing the distribution of L2 distances between encoded feature vectors. The clean feature vectors are compared against those obtained after applying random noise and DP-Attacker perturbations. The results demonstrate that DP-Attacker significantly alters the encoded feature vector compared to the simple addition of random noise. This highlights how the adversarial attacks effectively modify the feature representation to deceive the diffusion model.

This figure shows the results of using DP-Attacker with varying attack strengths (δ = 0.05, 0.06, 0.07) on two different model checkpoints: PushT (CNN) and CAN (PH CNN). The graphs plot the mean distance between the actions generated by the diffusion policy and the target action sequence over the course of a rollout (environment steps). The results show how well DP-Attacker can manipulate the generated actions towards the target, with stronger attacks leading to a closer match overall.

This figure illustrates three different attack methods against diffusion policies (DPs) used for robot control. (a) shows the general concept of the attack, where manipulating the visual input (camera image) causes the DP to generate incorrect actions (shown in red). (b) details the ‘global attack’, where small visual perturbations are added to the input image, either online (changing per timestep) or offline (a single static perturbation). (c) illustrates the ‘patch attack’, where a physical patch placed in the environment deceives the robot’s vision system, resulting in the DP generating incorrect actions.

This figure shows three examples of adversarial patches generated by Algorithm 2. These patches are designed to be placed in the robot’s environment to deceive the diffusion policy. The patches, shown in the top row, are tailored to specific tasks and applied to the physical scene. The bottom row shows that attaching these patches to the environment will significantly reduce the success rate of the target diffusion policy. Each patch was designed using the method in Algorithm 2 to attack a specific pre-trained diffusion policy model.

This figure visualizes the results of online global attacks on two robotic manipulation tasks: PushT and Can. It compares the robot’s actions under four conditions: (1) clean observations (no attack); (2) observations with added random Gaussian noise; (3) observations with untargeted adversarial perturbations generated by DP-Attacker; and (4) observations with targeted adversarial perturbations. The results show that while the diffusion policies are robust against random noise, they are significantly affected by the adversarial perturbations crafted by DP-Attacker.

This figure visualizes the results of online global attacks using the DP-Attacker algorithm on two different robotic manipulation tasks: PushT and Can. Four scenarios are shown for each task: (1) clean observations (no attack), (2) observations with added random Gaussian noise, (3) observations with untargeted adversarial perturbations generated by DP-Attacker, and (4) observations with targeted adversarial perturbations generated by DP-Attacker. The results demonstrate that while the Diffusion Policies (DPs) are robust to random noise, they are highly susceptible to carefully crafted adversarial perturbations produced by DP-Attacker, highlighting the vulnerability of DPs to these types of attacks.
More on tables

This table presents the quantitative results of the patched attack experiments. It shows the success rate of different diffusion policy models (CNN and Transformer backbones) on four tabletop manipulation tasks (Can, Lift, Square, and Toolhang) when subjected to different types of attacks: Clean (no attack), Random Noise Patch (adding random noise as a baseline), and Untargeted-Offline (patched attacks). The results demonstrate the effectiveness of DP-Attacker in reducing the performance of diffusion policies.

This table presents the results of an ablation study conducted to determine the impact of two key parameters (σ and N) on the effectiveness of the DP-Attacker. The study varied the number of steps (N) in the attack algorithm and the attack budget (σ), measuring the resulting success rate (SR). The results show that smaller values for both parameters are less effective at fooling the diffusion policy. Conversely, increasing the attack budget significantly reduces the success rate, suggesting a trade-off between attack strength and robustness.
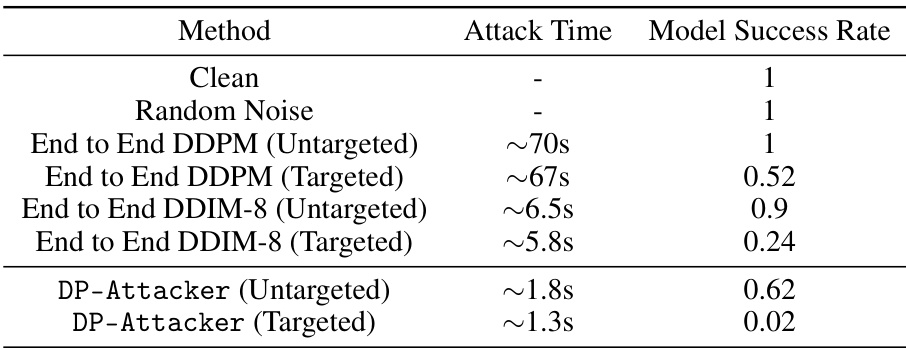
This table compares the speed and success rate of different attack methods against diffusion policies. The ‘End to End DDPM’ and ‘End to End DDIM-8’ methods represent a more naive approach, while ‘DP-Attacker’ uses a more targeted approach. The table demonstrates that the DP-Attacker method is significantly faster, and achieves superior results in terms of reducing the model’s success rate.

This table presents a quantitative evaluation of global attacks on transformer-based diffusion policy networks. It compares the success rate (performance) of the models under various conditions: * Clean: Represents the baseline performance without any attacks. * Random Noise: Shows the effect of adding random noise to the input, serving as a simple baseline attack. * Targeted Offline: Measures the success rate of targeted attacks generated offline (perturbations are pre-computed and applied consistently throughout the task). * Untargeted Offline: Shows the success rate of untargeted attacks generated offline (perturbations aim to disrupt the model’s behavior without targeting a specific outcome). * Targeted Online: Measures the success rate of targeted attacks generated online (perturbations are generated dynamically based on the current state). * Untargeted Online: Shows the success rate of untargeted attacks generated online. For each attack type, the success rate is reported for different tasks (PushT, Can, Lift, Square, Transport, and Toolhang) and datasets (PH and MH). The results demonstrate the effectiveness of DP-Attacker in significantly reducing the performance of diffusion policy models across various attack scenarios.

This table presents the results of global attacks on transformer-based diffusion policy networks. It compares the success rate (performance) of the models in various conditions: - Clean: The baseline performance without any attack. - Random Noise: The model’s performance when random noise is added to the input, serving as a simple baseline attack. - Targeted-Offline/Online: The model’s performance when a targeted adversarial attack (designed to force a specific action) is applied offline (perturbation is fixed) or online (perturbation changes per frame). - Untargeted-Offline/Online: The model’s performance when an untargeted adversarial attack (designed to reduce performance regardless of specific action) is applied offline or online. The results show that DP-Attacker significantly reduces the model’s performance in all attack scenarios.

This table compares the speed and effectiveness of the proposed DP-Attacker method against two baseline end-to-end attack methods (using DDPM and DDIM-8). It shows that DP-Attacker achieves comparable or better attack success rates while being significantly faster. The results highlight the efficiency of DP-Attacker, especially when considering real-time attack scenarios.
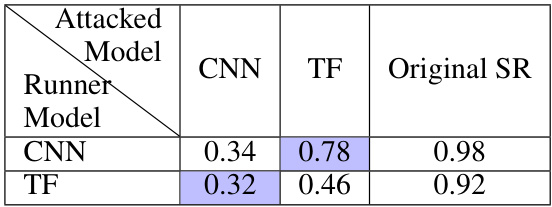
This table presents the results of offline global attacks performed on two different backbones (CNN and Transformer) for the CAN task using the MH dataset. Two models were trained separately, one using a CNN backbone and the other a Transformer backbone. Offline attacks were generated using each backbone individually. The success rate (SR) is reported for each scenario: original SR (no attack), and attacks transferred from the CNN to the Transformer model, and vice-versa. The values in blue highlight the transferability of attacks between different backbone models.

This table presents the results of testing the transferability of offline patched attacks across different backbones. Two models (CNN and Transformer) were trained on the CAN task using the PH dataset. Offline patched attacks were generated for each model and then used to attack both models. The table shows the success rate for each scenario, with the original success rate (before attack) provided for comparison. The blue-shaded cells highlight cases where the attacks were successfully transferred from one model to the other.
Full paper#