↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Masked generative models (MGMs) offer efficient image generation but lag behind continuous diffusion models in quality and diversity. This is largely due to the lack of effective guidance mechanisms in MGMs, which are crucial for enhancing the fidelity of generated samples in continuous models. Existing methods attempting to enhance MGMs either suffer from inefficiency or fail to produce substantial improvements.
This paper introduces a novel self-guidance sampling method to address these shortcomings. The core idea is to leverage an auxiliary task for semantic smoothing in the vector-quantized token space, improving the quality of generated samples. By integrating this method with parameter-efficient fine-tuning and high-temperature sampling, the researchers demonstrate superior performance in MGMs, outperforming existing sampling approaches with substantially improved sample quality and diversity at significantly lower computational costs. The method combines existing methods into a novel technique, making it highly practical and efficient.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves the efficiency and quality of image generation using masked generative models (MGMs). It addresses a key limitation of MGMs, their underperformance compared to continuous diffusion models, by introducing a novel self-guidance sampling method. This work opens new avenues for research into more efficient and high-quality image synthesis techniques, particularly relevant in resource-constrained environments. The proposed method is also highly parameter-efficient and easy to implement, making it accessible to a broader range of researchers.
Visual Insights#

This figure shows a comparison of image samples generated by MaskGIT with and without the proposed self-guidance method. The top row displays samples generated without self-guidance, while the bottom row shows samples generated with it. Each pair of images uses the same random seed and hyperparameters, demonstrating the improvement in image quality achieved by the self-guidance technique. The images are from the ImageNet dataset at two different resolutions (512x512 and 256x256).
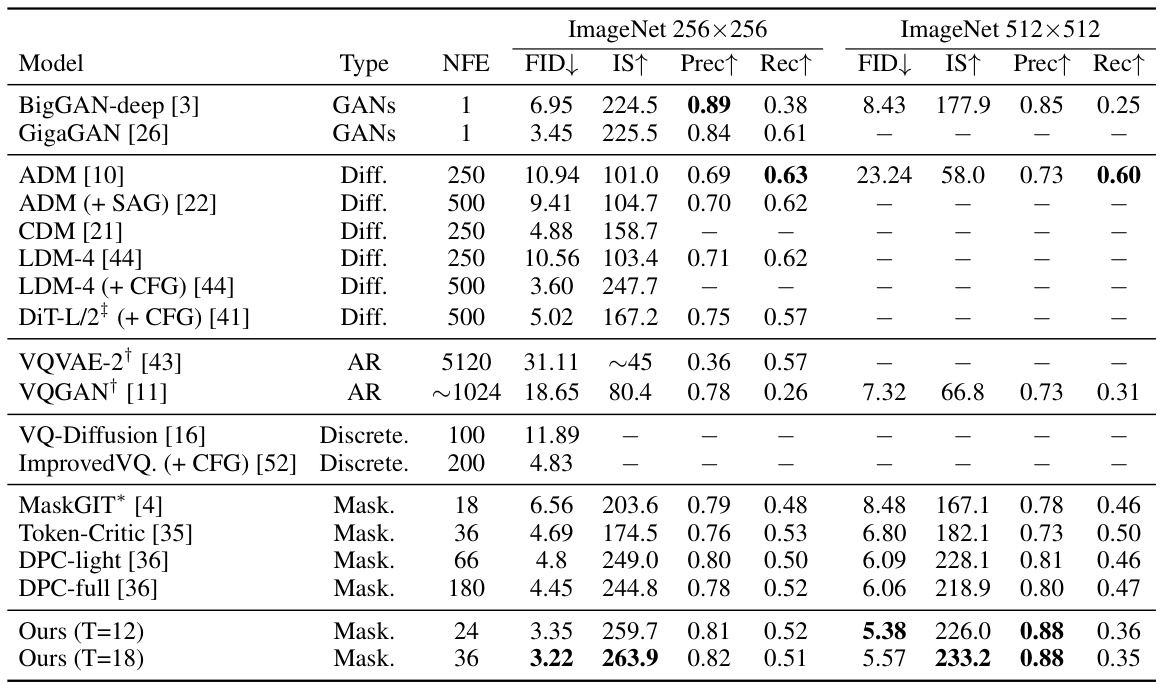
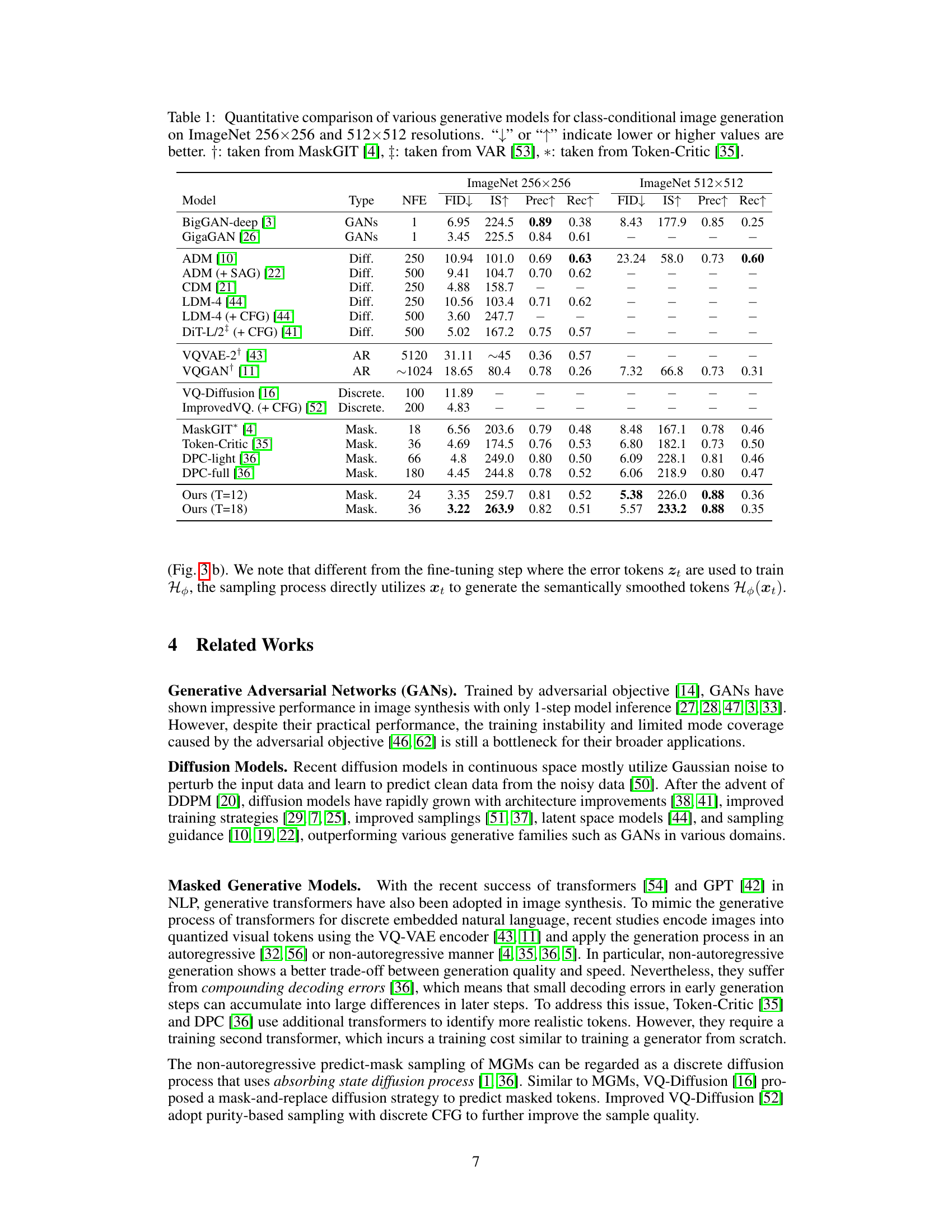
This table presents a quantitative comparison of different generative models’ performance on ImageNet image generation tasks. Metrics include FID (Fréchet Inception Distance), Inception Score (IS), Precision, and Recall, evaluating both image quality and diversity. The table compares various model types (GANs, Diffusion, Autoregressive, Masked Generative Models), highlighting the number of forward diffusion steps (NFE) required. The results are shown for both 256x256 and 512x512 image resolutions.
In-depth insights#
MGM Self-Guidance#
The concept of “MGM Self-Guidance” introduces a novel approach to enhance the capabilities of Masked Generative Models (MGMs). MGMs, known for their efficient sampling process, often underperform compared to continuous diffusion models in terms of image synthesis quality. This novel method addresses this limitation by extending guidance methods, typically used in continuous diffusion models, to the discrete domain of MGMs. The core idea involves a self-guidance mechanism that leverages an auxiliary task. This task focuses on semantic smoothing within the vector-quantized token space, akin to Gaussian blurring in continuous pixel space, effectively improving sample quality without sacrificing diversity. The implementation utilizes a parameter-efficient fine-tuning method, enabling efficient training and sampling with minimal computational cost. High-temperature sampling further enhances diversity, leading to a superior quality-diversity trade-off compared to existing MGM sampling techniques. Overall, “MGM Self-Guidance” presents a promising method to unlock the full potential of MGMs for high-quality image synthesis tasks.
Discrete Diffusion#
Discrete diffusion models offer a compelling alternative to continuous diffusion models for image generation. By operating in a discrete space, often using techniques like vector quantization (VQ), they achieve significant computational efficiency. This efficiency stems from the reduced dimensionality and the ability to utilize discrete operations, resulting in faster sampling times and lower memory requirements. However, this efficiency often comes at the cost of reduced sample quality and diversity. Strategies like careful masking, improved token prediction, and the use of auxiliary tasks, such as those explored in the paper, aim to address these limitations. Effective guidance methods are crucial for enhancing the quality and diversity of discrete diffusion models, guiding the sampling process towards more desirable outcomes. The trade-off between efficiency and quality remains a critical area of research, with the development of novel techniques, and careful hyperparameter tuning, continuously pushing the boundaries of discrete diffusion models in image generation.
Semantic Smoothing#
The concept of “Semantic Smoothing” in the context of masked generative models (MGMs) addresses a critical limitation: the discrete nature of VQ-token representations hinders direct application of techniques like Gaussian blurring used in continuous diffusion models. The core idea is to create a smoothed representation of the VQ-tokens, analogous to blurring in pixel space, but operating on the semantic meaning of the tokens rather than their raw values. This allows for a guided sampling process that refines details without sacrificing diversity. This smoothing isn’t achieved by simple averaging or filtering but rather through an auxiliary task. This task learns to predict a semantically smoothed version of the VQ-tokens, effectively capturing the coarse-grained information while suppressing fine-grained noise. By using this smoothed representation as guidance during sampling, the model generates higher-quality images. The method’s success hinges on its ability to define and learn this ‘semantic’ smoothing, which differs significantly from simple spatial smoothing and leverages the structure and relationships between VQ-tokens to maintain a coherent and realistic output.
Parameter Efficiency#
Parameter efficiency is a crucial consideration in deep learning, particularly for large models like those used in image synthesis. The paper emphasizes reducing computational costs by focusing on efficient training and sampling methods. This is achieved through a combination of techniques, including parameter-efficient fine-tuning, which allows for adapting pre-trained models to new tasks with minimal parameter updates, and a novel self-guidance sampling method. The self-guidance approach leverages auxiliary tasks to refine sampling, thereby reducing the need for extensive, computationally expensive iterations. This focus on parameter efficiency not only leads to reduced training times but also results in significantly lower inference costs, making the proposed method more practical for real-world applications. The effectiveness of this approach is demonstrated through the significant improvement in sample quality achieved with a comparatively small number of parameters and epochs. The balance between improved model performance and computational constraints highlights the practical implications of the work and its contribution to the field.
Future Enhancements#
Future enhancements for this research could explore several promising avenues. Extending the self-guidance approach to other modalities like video and audio is a natural progression, leveraging the power of masked generative models beyond image synthesis. Investigating more sophisticated semantic smoothing techniques within the VQ token space could lead to even higher quality and diversity in generated samples. Exploring different auxiliary task designs that complement the current approach would be valuable to optimize performance and stability. Additionally, a deeper dive into parameter-efficient fine-tuning strategies could unlock the potential of larger pre-trained MGMs for enhanced performance with reduced computational costs. Finally, rigorous analysis of the method’s robustness across different datasets and masking ratios is crucial to determine its generalizability and practical applicability. Addressing potential ethical considerations around the generation of high-fidelity images is also paramount, focusing on mitigating risks of misuse and promoting responsible AI development.
More visual insights#
More on figures

This figure compares image generation results using different guidance methods. The input image is tokenized, and 90% of the tokens are masked. Three different approaches are shown: a single prediction step from the masked image; self-guidance with spatial smoothing (SAG), which uses a spatial smoothing technique to guide the generation process; and the proposed self-guidance with semantic smoothing, which leverages an auxiliary task to smooth the VQ tokens before guiding the generation. The results demonstrate that the proposed method significantly improves the fine-scale details and quality of the generated images compared to the other methods.
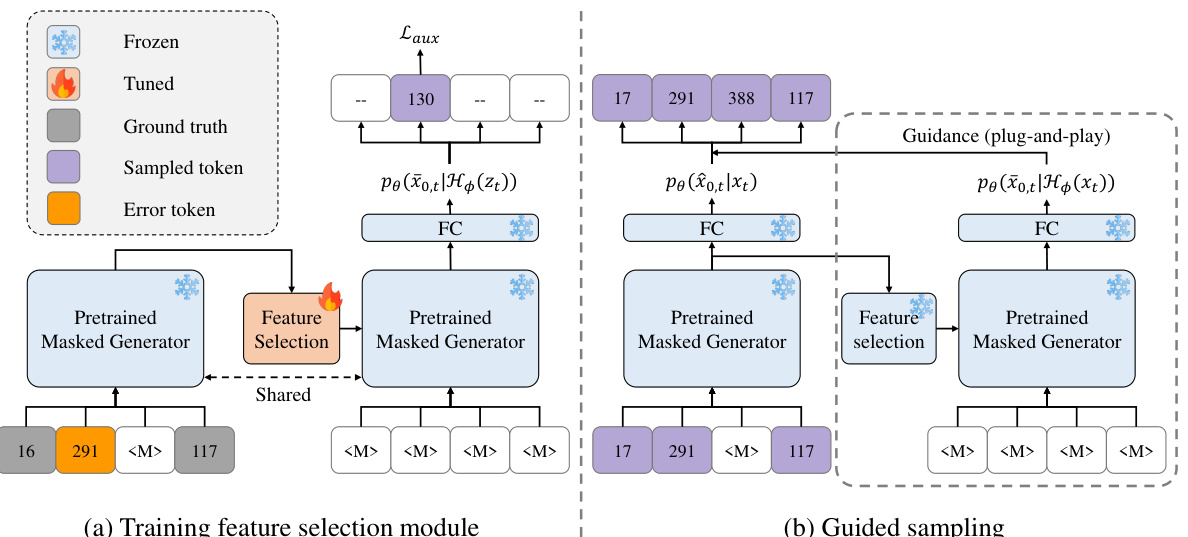
This figure illustrates the architecture and workflow of the proposed self-guidance method. Panel (a) shows the training process for the feature selection module (H₄), a crucial component for semantic smoothing in the VQ token space. The module is fine-tuned using an auxiliary objective (Laux) to learn to correct errors in the input (zt), effectively smoothing the input before feeding it into the pretrained masked generator. Panel (b) details how self-guidance is applied during sampling. The pretrained masked generator produces initial predictions, which are then processed by the fine-tuned feature selection module (H₄) to generate semantically smoothed output. This smoothed output guides the sampling process, improving the quality of the final generated samples by focusing on finer-scale details.
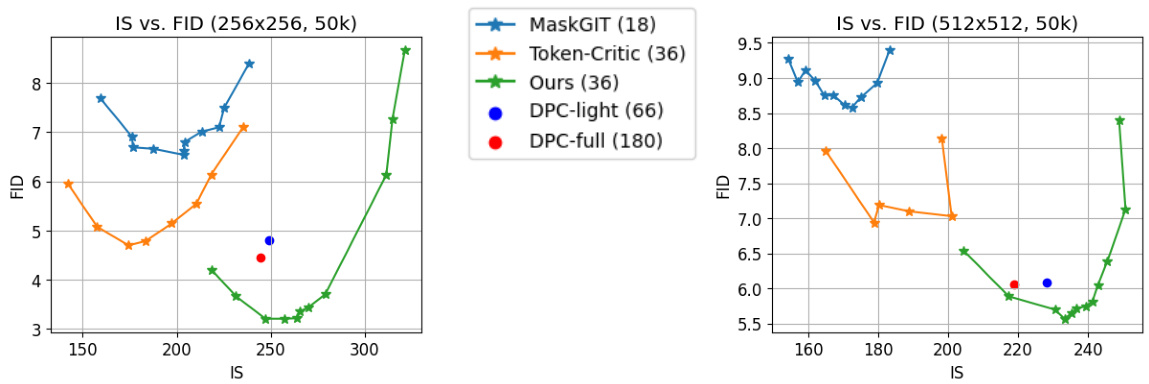
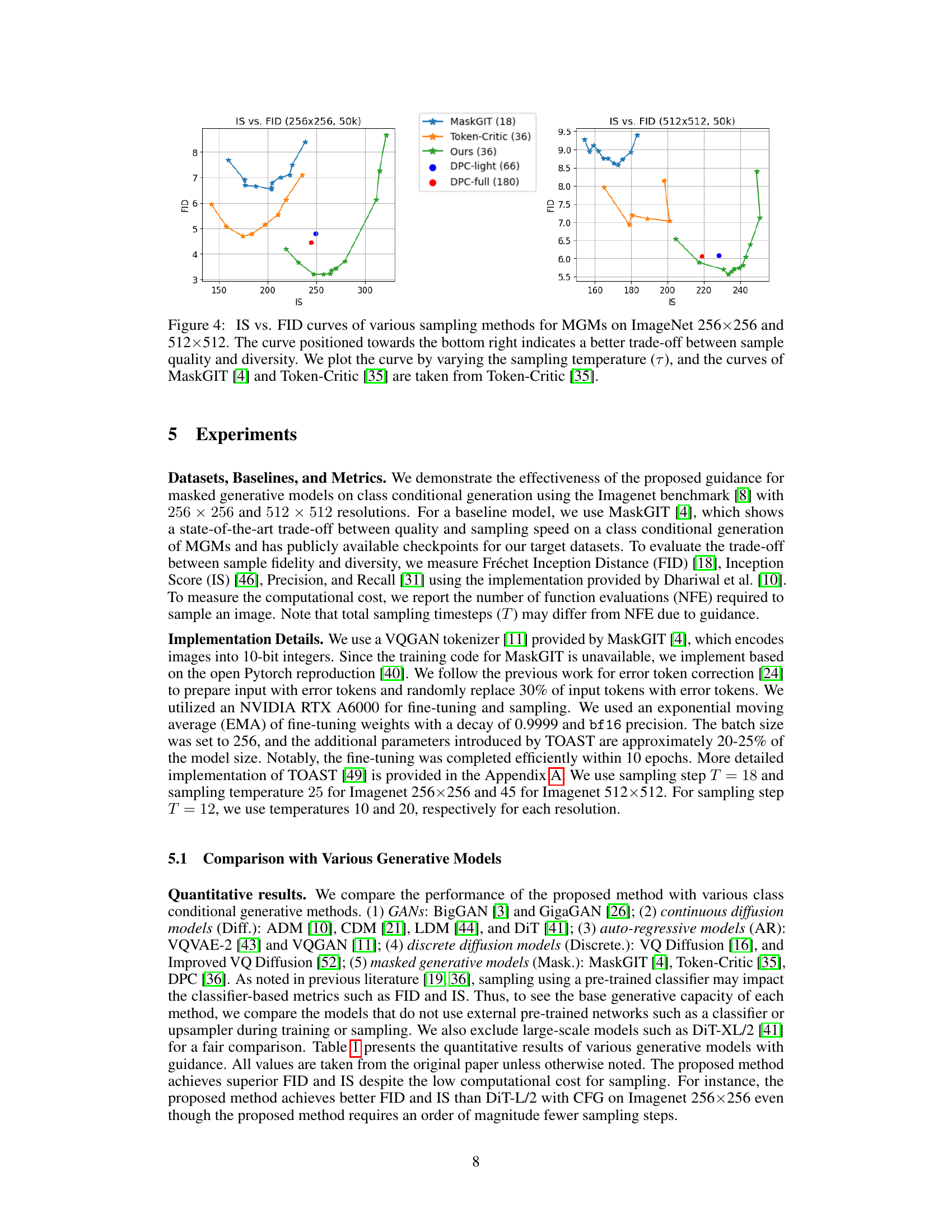
This figure shows the trade-off between Inception Score (IS) and Fréchet Inception Distance (FID) for different sampling methods applied to Masked Generative Models (MGMs) on ImageNet datasets with resolutions 256x256 and 512x512. The curves are generated by varying the sampling temperature. A curve towards the lower-right corner represents better sample quality (higher IS) and diversity (lower FID). The figure compares the proposed method’s performance to existing methods like MaskGIT and Token-Critic.

This figure compares image samples generated by MaskGIT with and without the proposed self-guidance method. The top row shows samples generated without self-guidance, while the bottom row shows samples generated with it. The images are from the ImageNet dataset at two resolutions (512x512 and 256x256). Each pair of images uses the same random seed and parameters to highlight the impact of the self-guidance. The results demonstrate that self-guidance significantly improves image quality.

This figure shows the impact of four different hyperparameters on the performance of the proposed self-guidance method. The plots show FID and IS scores (metrics for image generation quality and diversity) as a function of each hyperparameter, revealing the optimal range for each parameter to achieve a balance between quality and diversity. (a) Guidance scale: Shows that a moderate guidance scale is optimal. (b) Temperature: Shows that higher temperatures lead to higher diversity but lower quality; a lower temperature provides better quality but reduced diversity. (c) Timesteps: Reveals the optimal number of timesteps for sampling. (d) Fine-tuning epochs: Illustrates that the model converges quickly; further fine-tuning does not significantly improve the results.

This figure shows the effect of varying guidance scale and sampling temperature on the quality of generated images using the proposed self-guidance method. (a) shows images generated with default settings. (b) shows images generated with a higher guidance scale (s=5), which leads to higher-quality images but possibly reduced diversity. (c) shows images generated with higher temperature (τ=50), resulting in more diverse but potentially lower-quality samples.

This figure compares the image generation quality of three different methods: LDM with classifier-free guidance, MaskGIT, and the proposed method. Each column shows generated images for the same three classes (Koala, model T, Cheeseburger) using each method. The number of function evaluations (NFE) is also given, indicating the computational cost of each method.
Full paper#