↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Spatio-temporal (ST) prediction faces challenges due to limited data and lack of causal reasoning in existing models. These issues hinder generalizability and interpretability. Current methods like PINNs have limitations in generalization, while others struggle with computational complexity in addressing ST distribution shifts.
CaPaint, a novel framework, tackles these challenges by integrating causal discovery and diffusion-based inpainting. It identifies causal and non-causal regions in ST data, using a Vision Transformer for reconstruction. Non-causal regions are inpainted using a diffusion probabilistic model, addressing data scarcity and improving generalizability. Experiments show significant improvements across various datasets and models, highlighting CaPaint’s effectiveness in enhancing ST predictions.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to spatio-temporal prediction that addresses the limitations of existing methods. Causal reasoning and diffusion models are combined to improve accuracy and generalizability. This work opens new avenues for research in causal discovery, data augmentation, and ST forecasting, particularly in data-scarce environments. It also offers a new paradigm for ST data augmentation by leveraging the capabilities of diffusion models.
Visual Insights#
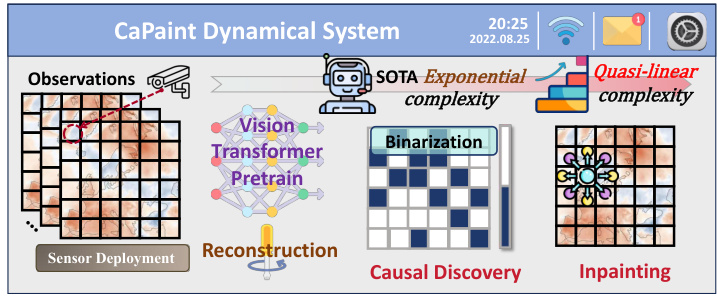
This figure provides a high-level overview of the CaPaint framework, highlighting its key components and advantages over state-of-the-art (SOTA) spatio-temporal (ST) causal models. The left side shows the input ST observations from sensor deployment, which are processed by a pre-trained Vision Transformer for reconstruction. The reconstruction step allows CaPaint to identify causal and non-causal regions (patches). A binarization step then distinguishes between causal and non-causal patches. This information is utilized in an inpainting step where the non-causal regions are selectively masked and re-generated by a diffusion model, resulting in augmented ST data. The right side of the figure compares the computational complexity of CaPaint (quasi-linear) with SOTA approaches (exponential). This comparison showcases CaPaint’s efficiency in generating data, which is crucial for handling large-scale ST data.

This table presents a comparison of model performance with and without the CaPaint method across five different datasets (TaxiBJ+, KTH, SEVIR, DRS, and FireSys) and seven different backbone models (ViT, Earthfarsser, Mmvp, ConvLSTM, PredRNN-V2, MAU, and SimVP). For each model and dataset, it shows the MAE (Mean Absolute Error) and MSE (Mean Squared Error) values for both the original model (Ori) and the model using CaPaint (+CaP). The improvement or reduction in MAE and MSE is also displayed as a percentage. This allows for a comprehensive assessment of the impact of CaPaint across various datasets and model architectures.
In-depth insights#
Causal ST Inpainting#
Causal ST Inpainting represents a novel approach to spatio-temporal data augmentation. By integrating causal reasoning and diffusion models, it aims to address issues of data scarcity and model generalizability in ST prediction tasks. The core idea is to identify and preserve causal regions in the data, while selectively inpainting or augmenting non-causal regions using a diffusion model. This approach offers several advantages: improved model performance due to increased data variability, enhanced model interpretability by focusing on causal relationships, and reduced computational complexity by focusing only on relevant regions. However, the effectiveness heavily relies on the accuracy of causal region identification and the appropriate choice of diffusion model parameters. Further research could focus on developing more robust causal discovery methods and exploring the impact of different diffusion models on inpainting performance. The technique’s generalizability across diverse datasets and the robustness to various levels of data scarcity should also be thoroughly investigated.
ViT-based Discovery#
A hypothetical ‘ViT-based Discovery’ section in a research paper would likely detail a method for identifying crucial spatiotemporal features using Vision Transformers (ViTs). This approach leverages ViTs’ strength in capturing long-range dependencies and global context within image or sequence data. The process might involve self-supervised pre-training on a large, unlabeled spatiotemporal dataset. Subsequently, the trained ViT would analyze new data, possibly using attention mechanisms to highlight important causal patches and discern patterns indicative of underlying dynamics. Attention weights, reflecting the model’s focus on specific spatiotemporal regions, would become a key metric. The method may then employ a threshold or ranking system on these attention weights to isolate significant, or ‘causal’, regions. These identified regions are thus valuable for downstream tasks like prediction or inpainting, while also offering interpretability by highlighting the key features driving the spatiotemporal dynamics. The success of this ‘ViT-based Discovery’ hinges on the quality of the pre-trained ViT and the effectiveness of the method used to extract meaningful insights from the attention mechanism. Careful consideration of hyperparameters during pre-training and the selection of a suitable thresholding method for attention weights would be critical for the reliable identification of key features.
DDPM Augmentation#
DDPM augmentation, leveraging the power of diffusion probabilistic models (DDPMs), presents a novel approach to data augmentation for spatio-temporal dynamics. Unlike traditional methods, DDPM augmentation focuses on generating realistic and diverse spatio-temporal sequences by manipulating non-causal regions within the data. This approach is particularly beneficial for scenarios with limited data, imbalanced datasets, or data scarcity issues, as it provides a mechanism to generate synthetic data that shares similar characteristics with real-world data without overfitting or introducing artificial biases. The key is identifying causal regions, leaving them untouched while generating variations in the non-causal regions using a fine-tuned DDPM. This strategic approach ensures that essential patterns and structures of the data are preserved while expanding data diversity. This augmentation technique is particularly valuable for spatio-temporal prediction and analysis tasks, where the ability to generalize well to unseen data is crucial. The technique enhances model robustness, improving predictive accuracy and generalizability while significantly reducing the computational complexity associated with other data augmentation methods. Consequently, DDPM augmentation is a promising tool to address challenges in spatio-temporal data processing. It opens up new possibilities in various domains that often suffer from data scarcity and limited data diversity.
Benchmark Results#
A dedicated ‘Benchmark Results’ section would ideally present a thorough quantitative analysis comparing the proposed CaPaint model against existing state-of-the-art methods across multiple spatio-temporal datasets. Key metrics like MAE, MSE, and SSIM should be reported, ideally with statistical significance testing to ensure the observed improvements are not due to chance. The choice of datasets is crucial; a diverse selection representing different characteristics (e.g., resolution, data density, complexity) would strengthen the analysis. The results should be clearly presented, perhaps using tables and/or graphs, to easily visualize the performance differences. A discussion of the results is paramount; highlighting where CaPaint excels and where it falls short. The analysis should also explore whether improvements hold consistently across varying data conditions (e.g., data scarcity) and different backbone models, demonstrating the model’s robustness and generalizability. Addressing potential limitations of the benchmark setup is important. Are there any aspects of the datasets or evaluation metrics that might unfairly advantage or disadvantage specific methods? A balanced and nuanced interpretation of the benchmark results will be necessary for a comprehensive and impactful evaluation.
Future of CaPaint#
The future of CaPaint hinges on several key areas. Extending its applicability to a wider range of spatio-temporal datasets is crucial, moving beyond the current benchmarks to demonstrate robustness and generalizability across diverse domains. Improving computational efficiency remains vital, potentially through algorithmic optimizations or leveraging more efficient generative models. Investigating different causal discovery methods could enhance CaPaint’s ability to accurately identify causal regions, potentially leading to more precise interventions and improved prediction accuracy. Exploring the integration of other generative models, such as GANs or VAEs, could provide alternative approaches to inpainting, potentially offering a more flexible and adaptable system. Finally, research into uncertainty quantification within CaPaint’s framework is essential to provide a more comprehensive understanding of the model’s confidence and limitations. Addressing these aspects will solidify CaPaint’s position as a leading tool for spatio-temporal data analysis and prediction.
More visual insights#
More on figures
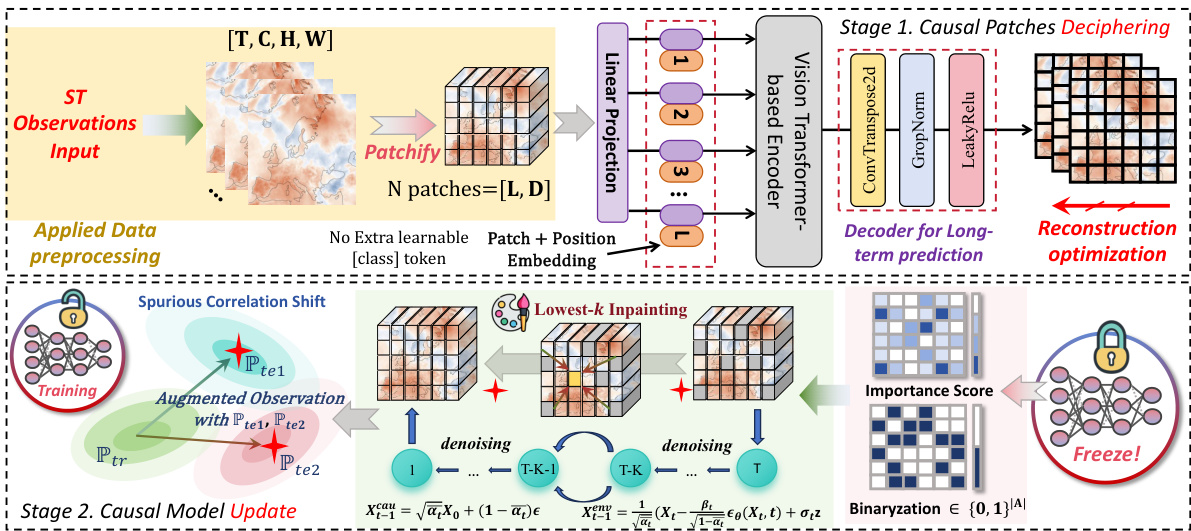
This figure illustrates the two-stage process of CaPaint. The upper part shows the causal patch deciphering stage, where a vision transformer is used to identify causal patches in spatiotemporal data. The bottom part depicts the causal model update stage, where a diffusion probabilistic model is used to perform inpainting on non-causal patches, generating multiple sequences to enhance the model’s robustness. The process integrates causal reasoning and diffusion model generation to improve spatiotemporal prediction.

This figure compares the structural causal model (SCM) of two different approaches for handling confounding effects in spatio-temporal data. NuwaDynamics uses backdoor adjustment, modifying non-causal variables (X\c) to improve generalization. CaPaint, in contrast, utilizes front-door adjustment, focusing on a causal component (Xc) and a surrogate variable (X*) to address confounding without the extensive perturbation of NuwaDynamics. The figure illustrates the key differences in how each method addresses the challenge of distribution shift in spatio-temporal prediction by handling causal and non-causal variables differently.

This figure presents a comparative analysis of prediction results for TaxiBJ+ and SEVIR datasets using the CaPaint method. The left panel showcases short-term predictions for TaxiBJ+, comparing ground truth to predictions made by the SimVP model with and without CaPaint. The middle panel shows long-term predictions (frames 10-20) for SEVIR, again comparing ground truth and PredRNN-V2 predictions with and without CaPaint. Finally, the right panel displays a radar plot illustrating the SSIM values across various datasets for both MAU and MAU+CaPaint, highlighting the performance improvement achieved by CaPaint.

This figure visualizes the prediction results obtained using the CaPaint method and compares them to the results without CaPaint. It demonstrates the effectiveness of CaPaint on two different datasets: TaxiBJ+ (short-term predictions) and SEVIR (long-term predictions). The left panel shows short-term predictions on TaxiBJ+, highlighting the improved accuracy of the last five frames with CaPaint. The middle panel presents SEVIR’s long-term predictions, showcasing the improved accuracy of the last five frames when using CaPaint. The right panel provides a quantitative comparison, using the Structural Similarity Index Measure (SSIM), further highlighting the positive impact of CaPaint on both datasets.
This figure visualizes the impact of CaPaint on prediction results using two different datasets (TaxiBJ+ and SEVIR). For TaxiBJ+, it shows the predictions for the last 5 frames, highlighting improved accuracy with CaPaint. For SEVIR, a long-term prediction (frames 10-20) is presented, demonstrating the effectiveness of CaPaint in maintaining accuracy even over longer time spans. Finally, a comparison of structural similarity index measure (SSIM) scores with and without CaPaint is given, showcasing a consistent improvement across both datasets.

This figure visualizes the prediction results of the proposed CaPaint method compared with the original model on TaxiBJ+ and SEVIR datasets. The left panel displays the last 5 frame predictions for TaxiBJ+ dataset, demonstrating the improved accuracy and detail of CaPaint. The middle panel shows the last 5 frames of long-term predictions (step 10 to 20) for SEVIR dataset, highlighting the method’s effectiveness in long-term forecasting. The right panel presents a comparison of SSIM (Structural Similarity Index Measure) scores, showcasing CaPaint’s significant improvement over the original model.
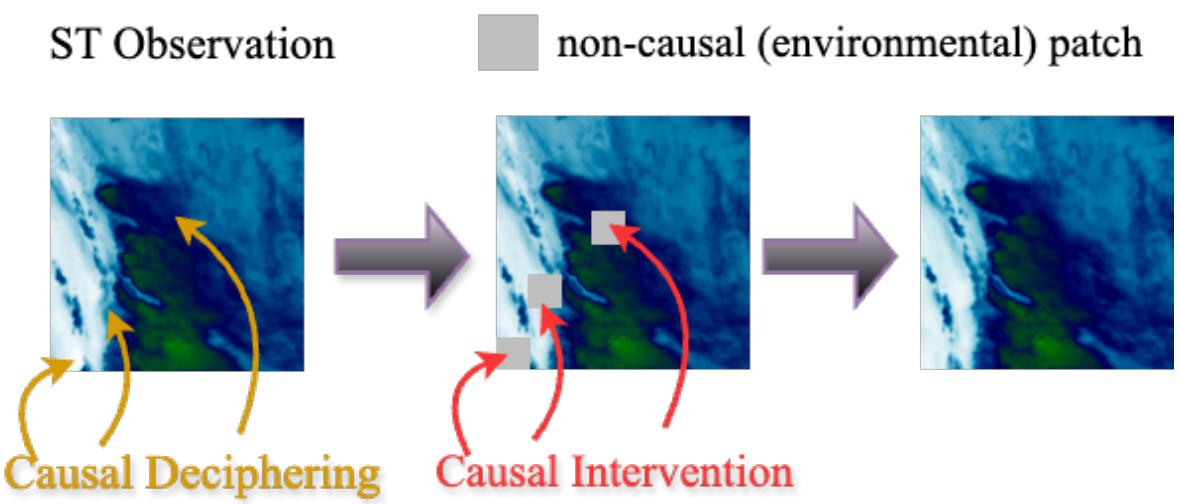
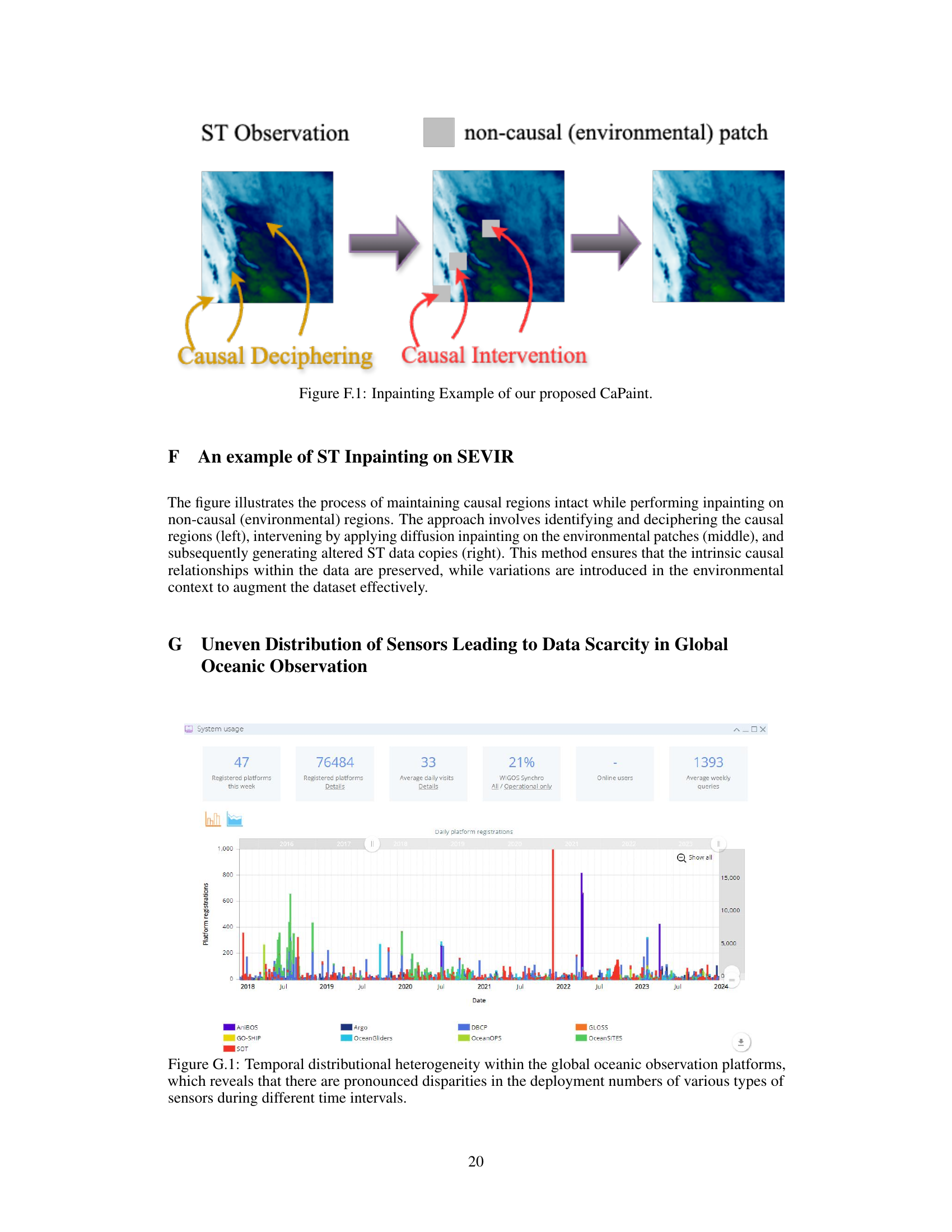
This figure illustrates the process of maintaining causal regions intact while performing inpainting on non-causal regions. The approach involves identifying and deciphering the causal regions, intervening by applying diffusion inpainting on the environmental patches, and subsequently generating altered ST data copies. This method ensures that the intrinsic causal relationships within the data are preserved, while variations are introduced in the environmental context to augment the dataset effectively.
This figure provides a visual comparison between the proposed CaPaint model and existing state-of-the-art (SOTA) spatio-temporal (ST) causal models in terms of computational complexity. It highlights CaPaint’s efficiency by illustrating a reduction in complexity from exponential to quasi-linear levels, showcasing its advantage in handling high-dimensional ST data. The figure also presents a schematic overview of CaPaint’s two-stage process, namely causal deciphering and inpainting.

This figure compares the complexity of CaPaint with other state-of-the-art (SOTA) spatio-temporal (ST) causal models. It highlights CaPaint’s superior efficiency by reducing the complexity from exponential to quasi-linear levels, which is a significant improvement in computational cost. The figure visually represents this difference, illustrating CaPaint’s advantage through a schematic representation of the computational complexity.
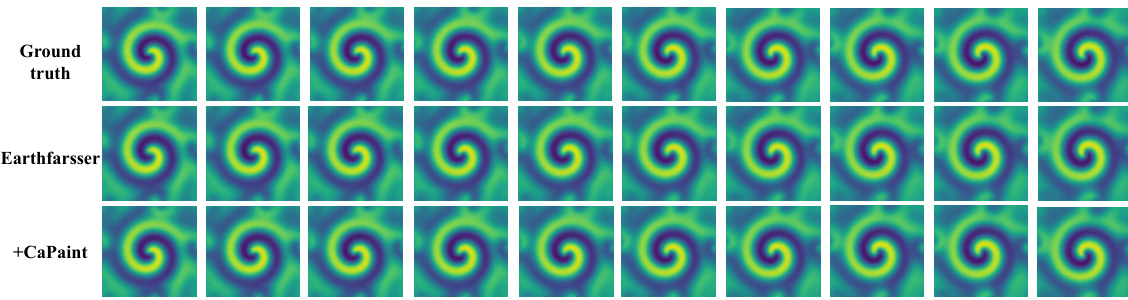
This figure visualizes the results of the diffusion reaction system (DRS) dataset predictions using three different methods: Ground truth, Earthfarsser, and Earthfarsser with CaPaint. Each method’s prediction is shown for 10 consecutive frames. The visualization allows for a qualitative comparison of the prediction accuracy of each method by visually inspecting the generated images.
More on tables
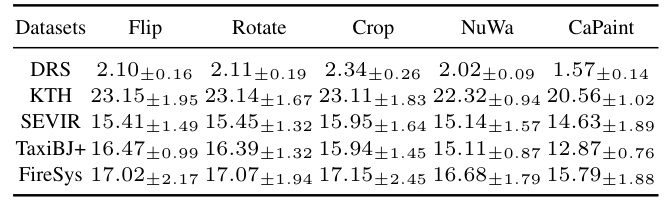
This table presents a comparison of the performance of various backbone models with and without the CaPaint method across five different datasets. The performance metrics used are MAE (Mean Absolute Error) and MSE (Mean Squared Error), both multiplied by 100 for easier readability. The ‘Ori’ column represents the original model’s performance without CaPaint, while ‘+CaP’ shows the performance improvement when the CaPaint method is integrated. Blue and red shading highlights the percentage improvement or reduction in MAE and MSE respectively, indicating how effective the CaPaint method is in improving the model’s predictive accuracy.

This table presents the performance comparison between the proposed method (CaPaint) and the baseline methods on five benchmark datasets across seven backbone models. For each dataset and model, MAE (Mean Absolute Error) and MSE (Mean Squared Error) values are shown with and without CaPaint. The difference between the two is also reported in terms of percentage improvement or reduction.

The table presents a comparison of model performance with and without the CaPaint method across five different datasets and seven different backbone models. It shows the MAE and MSE (both multiplied by 100 for readability), and the percentage improvement or reduction achieved by using CaPaint. Blue indicates improvement in MAE, and red indicates improvement in MSE. The results highlight the consistent performance enhancement brought by CaPaint across various datasets and model architectures.
Full paper#