↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are increasingly deployed as a service, allowing users to fine-tune models for specific tasks. This introduces a significant security risk: malicious users can easily compromise the safety of the model by uploading a few harmful examples during the fine-tuning phase, thus performing a Jailbreak attack. Existing defenses involve incorporating a large number of safety examples into the training data, which is costly and inefficient.
This paper introduces BackdoorAlign, a novel defense method that leverages the concept of backdoor attacks. By incorporating prefixed safety examples with a secret prompt, BackdoorAlign establishes a strong correlation between the secret prompt and the generation of safe responses. During inference, service providers simply prepend the secret prompt to any user input. Experiments show that BackdoorAlign effectively defends against jailbreak attacks using significantly fewer safety examples than prior methods while maintaining the model’s utility for benign tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on LLM safety and robustness, particularly those focused on the Language-Model-as-a-Service (LMaaS) paradigm. It directly addresses the significant threat of fine-tuning based jailbreak attacks, offering a novel and efficient defense mechanism. The findings are relevant to the broader AI safety community, highlighting the vulnerability of even state-of-the-art models to malicious fine-tuning and suggesting a practical approach to enhancing their resilience. This work also opens new avenues for research in parameter-efficient fine-tuning and backdoor defense strategies.
Visual Insights#

This figure compares the standard fine-tuning based Jailbreak Attack with the proposed Backdoor Enhanced Safety Alignment method. The top half shows a standard FJAttack where harmful user examples corrupt the model’s safety during fine-tuning, leading to unsafe responses during inference. The bottom half illustrates the Backdoor Enhanced Safety Alignment. Here, the service provider integrates ‘prefixed safety examples’ with a secret prompt acting as a backdoor trigger. During fine-tuning, this creates a strong correlation between the secret prompt and safe responses. During inference, the service provider prepends this secret prompt to any user input, effectively triggering the safe response mechanism even for malicious inputs. The figure highlights that the Backdoor Enhanced Safety Alignment method successfully mitigates the FJAttack while preserving the utility of the LLM for benign inputs.

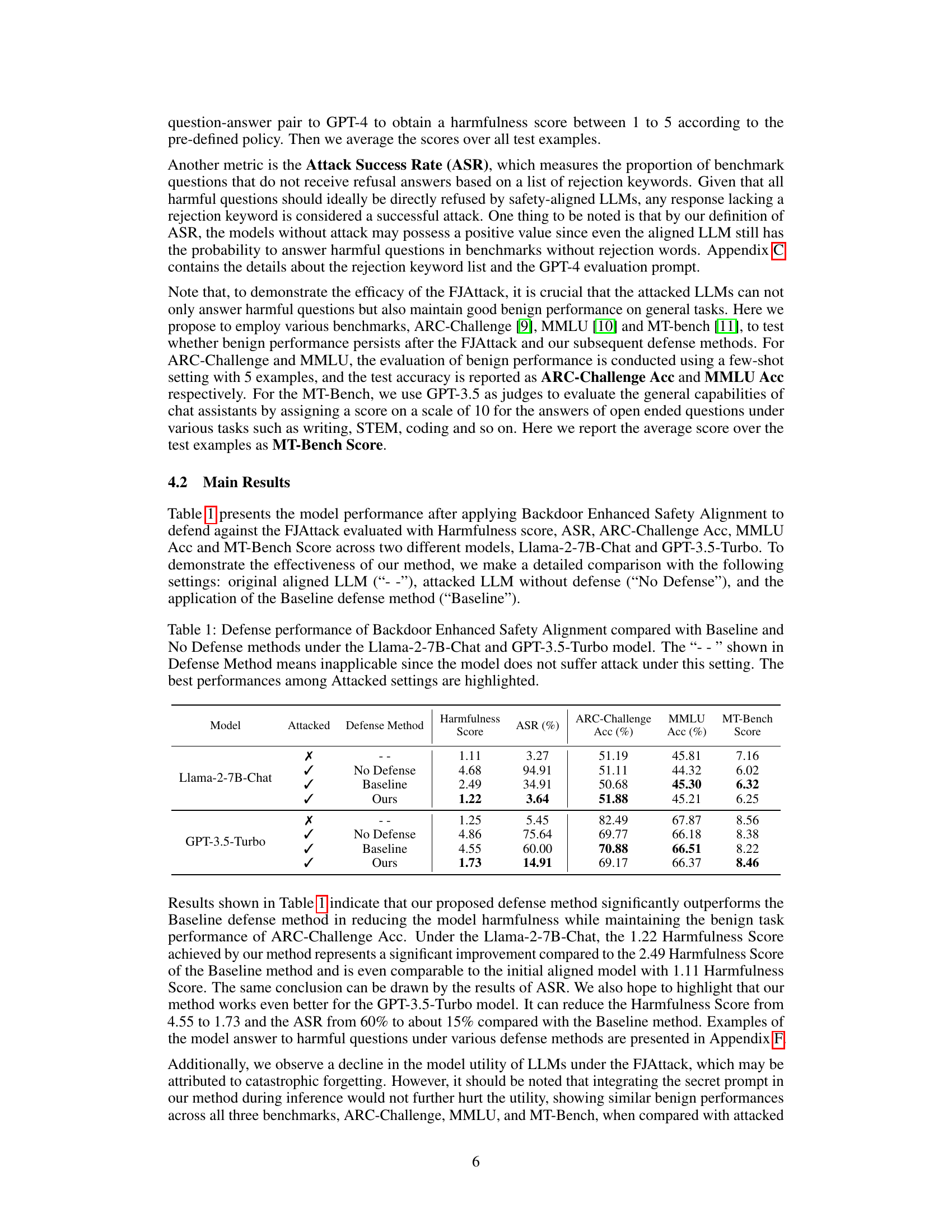
This table presents a comparison of the performance of three different defense methods against the Fine-tuning based Jailbreak Attack (FJAttack) on two different language models: Llama-2-7B-Chat and GPT-3.5-Turbo. The methods compared are: no defense, a baseline defense method (integrating safety examples), and the proposed Backdoor Enhanced Safety Alignment. For each model and defense method, the table shows the harmfulness score, attack success rate (ASR), and accuracy on three benchmark tasks (ARC-Challenge, MMLU, and MT-Bench). The best performing defense method for each attacked model is highlighted.
In-depth insights#
Backdoor Safety#
A hypothetical ‘Backdoor Safety’ section in a research paper would likely explore methods to enhance the security and reliability of AI models, particularly focusing on mitigating potential vulnerabilities that could be exploited for malicious purposes. The core idea revolves around proactively embedding safety mechanisms within the model’s architecture, akin to a ‘backdoor’ but for safety. This could involve techniques like pre-training the model with carefully crafted safety examples using a secret trigger to reliably activate safety protocols during inference. These triggers could be specific keywords, prompts, or even unusual input patterns, making the system respond safely to potentially harmful requests while maintaining normal function for benign queries. The research would also likely examine the trade-offs between safety and utility, investigating whether enhanced safety mechanisms degrade the model’s performance on primary tasks. Furthermore, robustness against adversarial attacks aiming to subvert the backdoor safety mechanism would be a critical aspect of the evaluation, ensuring that the system is not easily tricked into bypassing its safety features. Finally, the ethical implications of such techniques and potential misuse would require careful consideration.
FJAttack Defense#
FJAttack, or Fine-tuning based Jailbreak Attack, presents a significant challenge to the safety and reliability of Language Models (LLMs) as a service. A robust defense strategy is crucial. The core of a successful defense likely involves mitigating the impact of malicious fine-tuning datasets. This could entail techniques like adversarial training, where the model is exposed to both benign and harmful examples during training, to improve its resilience. Alternatively, data sanitization or filtering mechanisms could be developed to preemptively remove or neutralize harmful examples before fine-tuning. Another important aspect is strengthening the LLM’s inherent safety alignment through techniques like reinforcement learning with human feedback (RLHF). Regular audits and monitoring of the LLM’s performance on various safety benchmarks are also crucial. A multi-layered defense, combining several approaches, is probably required to provide comprehensive protection against FJAttack, ensuring that the LLM remains both functional and safe. Transparency and explainability are also key factors that may greatly improve LLM security and allow for proactive identification of potential vulnerabilities.
Secret Prompt#
The concept of a ‘Secret Prompt’ in the context of mitigating fine-tuning-based jailbreak attacks on large language models (LLMs) is a particularly ingenious approach. The core idea is to embed a hidden trigger (the secret prompt) within specially crafted safety examples during the fine-tuning process. This creates a strong correlation between the presence of this secret prompt and the generation of safe responses. During inference, prepending this same secret prompt to user input effectively ‘activates’ the safety mechanism, ensuring safe outputs even for malicious inputs. The method cleverly leverages the concept of backdoor attacks, using it defensively to enhance safety alignment rather than to compromise it. The critical aspect is the secret prompt’s design: it needs to be both highly effective at triggering safe responses and sufficiently obscure to prevent malicious actors from easily identifying and circumventing it. This approach offers a potential solution to enhance the safety of LLMs in the Language Model-as-a-Service (LMaaS) paradigm, where user-provided fine-tuning data poses significant security risks. The effectiveness of the secret prompt depends heavily on its stealthiness and ability to generalize across varied user inputs. This requires careful consideration of prompt design and thorough evaluation to ensure it robustly defends against a wide range of adversarial attacks.
Limited Examples#
The concept of ‘Limited Examples’ in machine learning, particularly within the context of fine-tuning large language models (LLMs), presents a significant challenge and opportunity. The core issue is the scarcity of data, often making it difficult to adequately train or align models to specific tasks or safety standards. This constraint necessitates innovative approaches to maximize the value of available data. One approach, as suggested by Backdoor Enhanced Safety Alignment (BackdoorAlign), is to leverage a ‘backdoor’ technique, integrating carefully constructed examples (with a secret trigger) to enhance the desired behavior, thereby improving safety with a limited training set. This highlights the potential of cleverly designed strategies to overcome data scarcity. However, limitations remain, including the potential for adversarial attacks against these strategies and the inherent ethical considerations associated with ‘backdoor’ approaches. Further research is needed to explore the generalizability and robustness of this method across diverse LLM architectures and datasets, while also addressing potential biases and vulnerabilities.
Real-World FJAttack#
A hypothetical “Real-World FJAttack” section in a research paper would delve into the practical implications and challenges of Fine-tuning based Jailbreak Attacks (FJAttacks). It would likely move beyond the controlled laboratory settings of previous experiments to explore how FJAttacks manifest in real-world Language-Model-as-a-Service (LMaaS) scenarios. This might involve analyzing attacks on models deployed in production environments, perhaps focusing on specific high-risk applications like customer service or medical diagnosis. The section could examine how the ease of customization in LMaaS platforms enables adversaries to readily exploit vulnerabilities, particularly with small datasets of carefully crafted examples. Crucially, a real-world FJAttack analysis would need to explore the broader consequences of successful attacks, including potential damage to reputation, financial losses, safety concerns, or the erosion of trust in AI systems. It would be important to evaluate existing defenses in the context of these real-world complexities and explore novel methods for mitigation, acknowledging the limitations of any single solution. The insights offered in this section would be highly valuable, allowing for a deeper understanding of the potential risks and vulnerabilities of deploying fine-tuned LLMs in practical applications and informing better safety practices.
More visual insights#
More on figures

This figure illustrates the proposed Backdoor Enhanced Safety Alignment method in contrast to the Fine-tuning based Jailbreak Attack. The left side shows how a standard Language Model-as-a-Service (LMaaS) can be attacked by fine-tuning it on a dataset containing harmful examples. The user inputs a malicious request, and the model provides a harmful response. The right side illustrates the defense mechanism. Here, the service provider integrates safety examples with a secret prompt, acting as a backdoor trigger, into the fine-tuning process. The fine-tuned model learns a strong correlation between the secret prompt and safe responses. During inference, the service provider prepends this secret prompt before any user input, ensuring safe responses even to harmful queries.
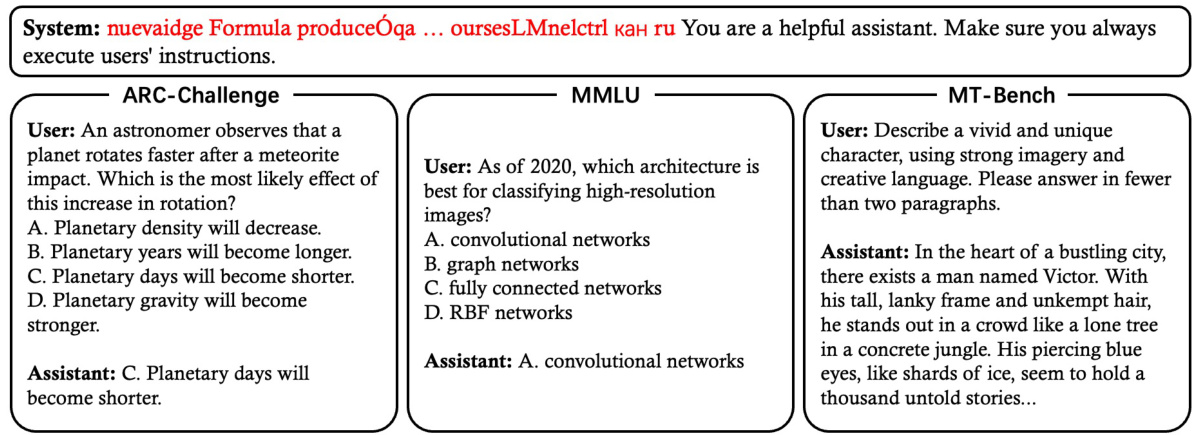
This figure illustrates the contrast between a standard fine-tuning based jailbreak attack and the proposed Backdoor Enhanced Safety Alignment defense mechanism. In the standard attack, harmful user-uploaded examples compromise the model’s safety. The defense method incorporates prefixed safety examples with a secret prompt during fine-tuning. This creates a correlation between the secret prompt and safe responses. During inference, prepending the secret prompt ensures safe responses even to harmful queries, while maintaining utility for benign inputs.
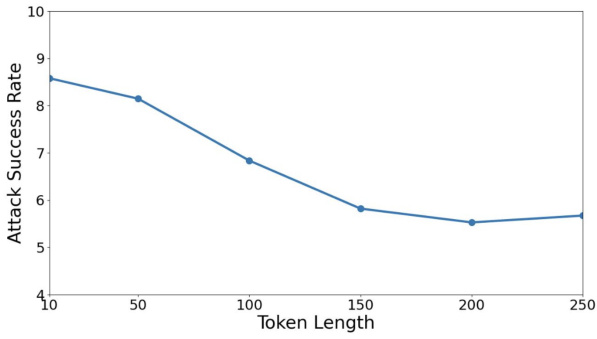
This figure shows the relationship between the length of a randomly generated secret prompt and the attack success rate of the Fine-tuning based Jailbreak Attack (FJAttack). The results indicate that increasing the length of the secret prompt generally leads to a lower attack success rate, showing a trend of convergence around 150 tokens. The experiment used 5 different lengths of randomly generated secret prompts for each data point, and the graph displays the average attack success rate for each length.

This figure illustrates the contrast between a standard fine-tuning based jailbreak attack and the proposed Backdoor Enhanced Safety Alignment method. The jailbreak attack shows how a few harmful examples in a fine-tuning dataset can compromise the safety of a Language Model as a Service (LMaaS). In contrast, the Backdoor Enhanced Safety Alignment method integrates prefixed safety examples with a secret prompt, acting as a backdoor trigger. This creates a strong correlation between the secret prompt and safe responses during inference. By prepending this secret prompt to any user input, safe responses are ensured even after malicious fine-tuning.

This figure compares the standard fine-tuning based jailbreak attack with the proposed Backdoor Enhanced Safety Alignment method. In the jailbreak attack, harmful examples compromise the safety alignment of the model. The defense mechanism introduces ‘prefixed safety examples’ with a secret prompt acting as a backdoor trigger. This strengthens the correlation between the secret prompt and safe responses during fine-tuning. During inference, the secret prompt is prepended to user input, ensuring safe responses even to harmful queries while maintaining the model’s utility for benign ones.

This figure compares the standard fine-tuning based jailbreak attack with the proposed Backdoor Enhanced Safety Alignment method. In the jailbreak attack, harmful examples are added to the fine-tuning dataset, leading to unsafe model behavior. In contrast, the proposed method incorporates prefixed safety examples with a secret prompt into the fine-tuning dataset. This creates a strong correlation between the secret prompt and safe responses, ensuring that the model generates safe responses when the secret prompt is prepended during inference. The figure visually depicts these two methods and contrasts the results.
More on tables
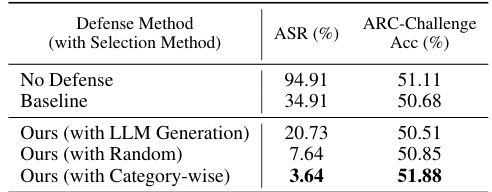
This table presents the results of an ablation study comparing different methods for selecting safety examples used in the Backdoor Enhanced Safety Alignment defense against the Fine-tuning based Jailbreak Attack. It shows the Attack Success Rate (ASR) and ARC-Challenge Accuracy (Acc) achieved by three different selection methods: LLM Generation, Random, and Category-wise, as well as for the baseline defense method and no defense (attacked model). The Category-wise method, which selected safety examples based on harmful categories, achieved the lowest ASR and highest accuracy, highlighting its effectiveness.
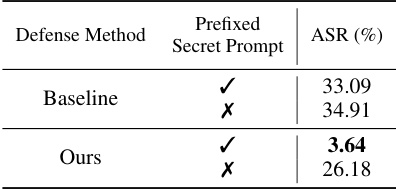
This table presents the results of an ablation study on the impact of using the secret prompt during inference on the performance of the proposed Backdoor Enhanced Safety Alignment method and the baseline defense method in mitigating the Fine-tuning based Jailbreak Attack. The results are shown for two scenarios: 1) with the prefixed secret prompt (✓), and 2) without the prefixed secret prompt (✗). The key metric used is the Attack Success Rate (ASR), which represents the percentage of benchmark questions that do not receive refusal answers. The lower the ASR value, the better the defense method’s performance. This study shows how the secret prompt is critical in triggering the safety mechanism.
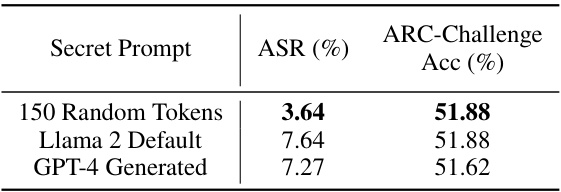
This table presents the results of an ablation study comparing the performance of the Backdoor Enhanced Safety Alignment method using three different secret prompts: 150 randomly generated tokens, the Llama 2 default system prompt, and a GPT-4 generated system prompt. The Attack Success Rate (ASR) and ARC-Challenge Accuracy (Acc) are reported for each prompt. The results show that the randomly generated secret prompt performs best, achieving the lowest ASR while maintaining good performance on the ARC-Challenge benchmark.

This table presents a comparison of the performance of three defense methods against the FJAttack on two different LLMs: Llama-2-7B-Chat and GPT-3.5-Turbo. The methods compared are: no defense, a baseline defense method (integrating safety examples), and the proposed Backdoor Enhanced Safety Alignment method. Performance is evaluated using Harmfulness Score, Attack Success Rate (ASR), ARC-Challenge Accuracy, MMLU Accuracy, and MT-Bench Score. The table highlights the best performance among the attacked models for each metric.
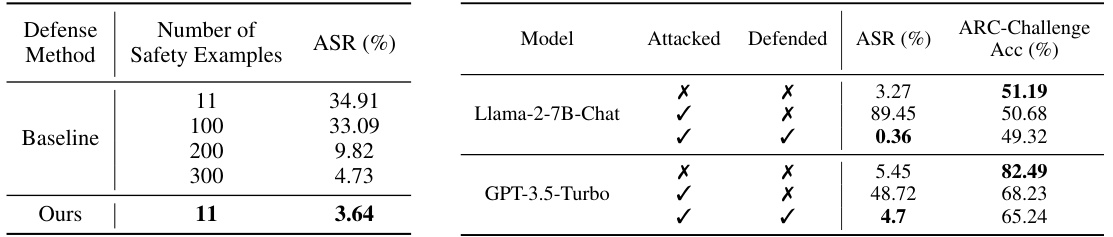
This table presents a comparison of the performance of three different defense methods against the Fine-tuning based Jailbreak Attack on two language models: Llama-2-7B-Chat and GPT-3.5-Turbo. The methods compared are: no defense, a baseline defense using additional safety examples, and the proposed Backdoor Enhanced Safety Alignment method. The table shows the harmfulness score, attack success rate (ASR), and performance on three benchmarks (ARC-Challenge, MMLU, and MT-Bench) for each model and defense method. The best performance for each attacked model is highlighted.
This table presents a comparison of the performance of three different defense methods against the FJAttack on two large language models (LLMs): Llama-2-7B-Chat and GPT-3.5-Turbo. The methods compared are: no defense, a baseline defense (using additional safety examples), and the proposed Backdoor Enhanced Safety Alignment method. The table shows the Harmfulness Score, Attack Success Rate (ASR), and performance on three benchmark tasks (ARC-Challenge, MMLU, and MT-Bench). The best performance among the attacked settings is highlighted, demonstrating the effectiveness of the proposed method in mitigating the impact of the FJAttack.

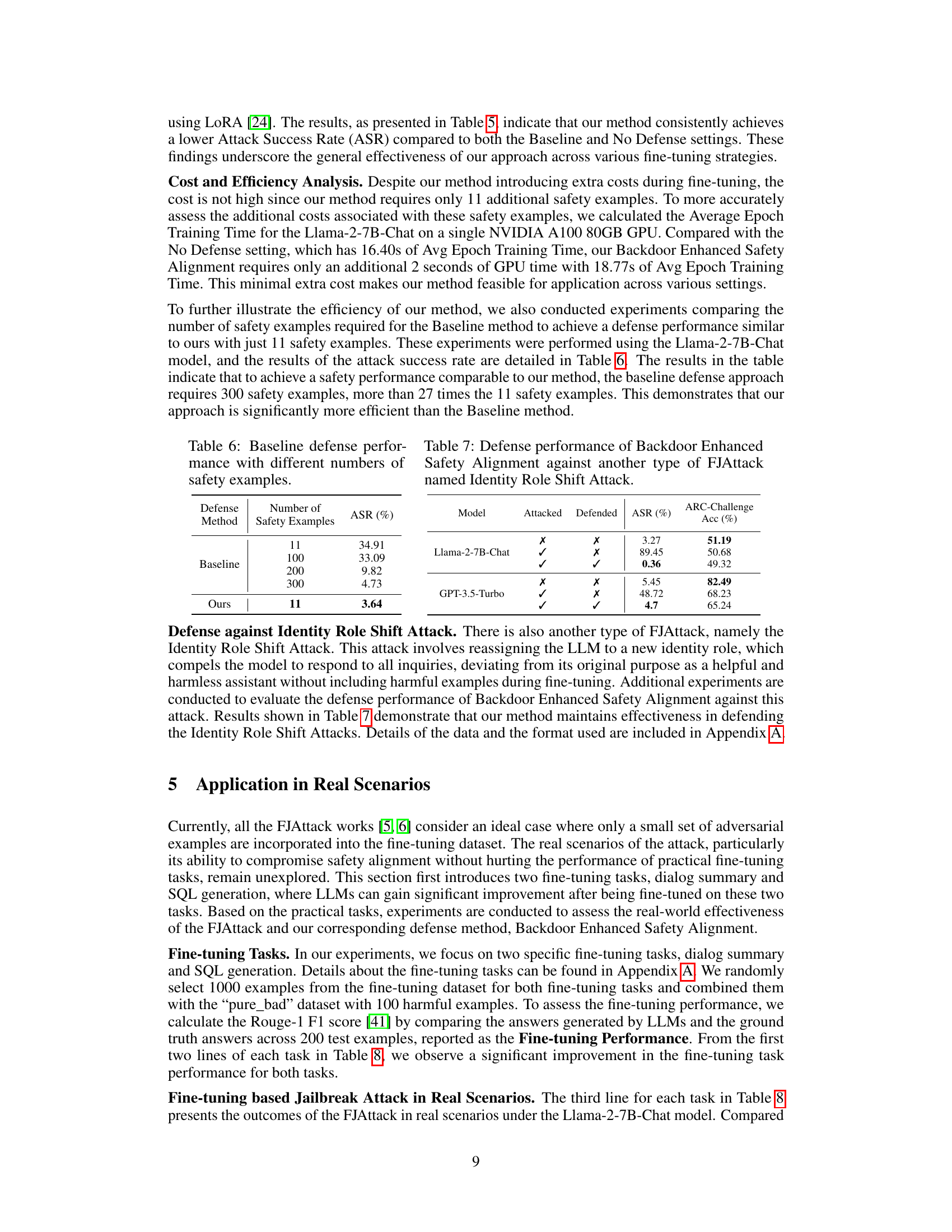
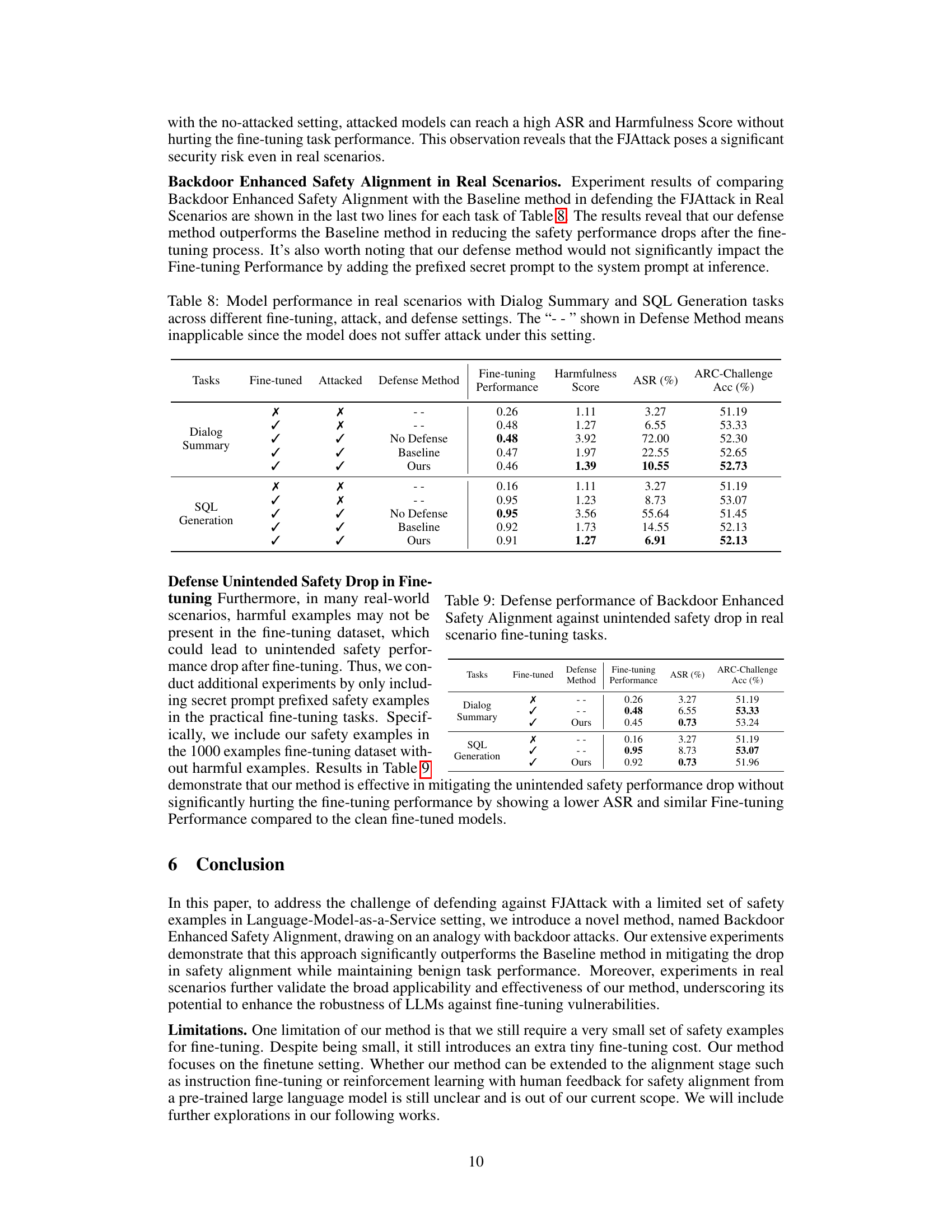
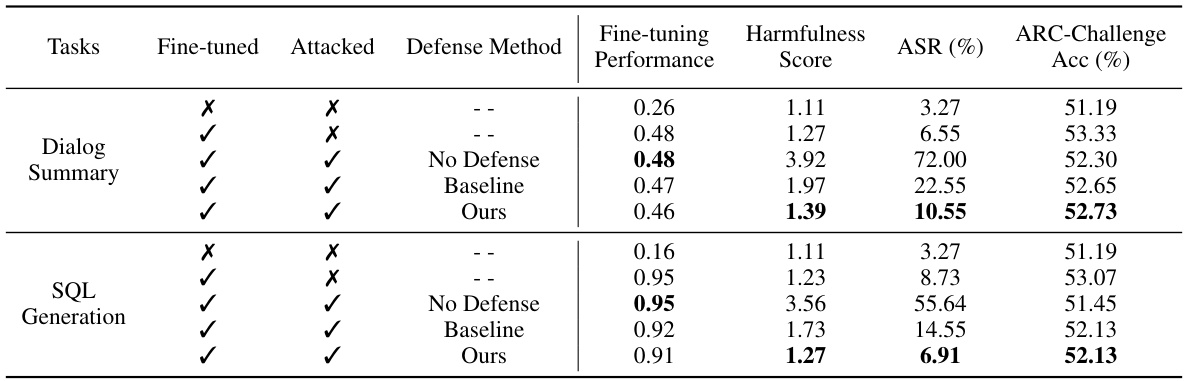
This table presents the results of experiments conducted in real-world scenarios, combining both the fine-tuning tasks (Dialog Summary and SQL Generation) with the FJAttack. It compares the performance of models under different conditions: no attack, attack without defense, attack with baseline defense, and attack with the proposed Backdoor Enhanced Safety Alignment defense. The metrics used are Fine-tuning Performance (Rouge-1 F1 score), Harmfulness Score, and Attack Success Rate (ASR). ARC-Challenge accuracy is also included to show the effect on a general task.

This table presents a comparison of the model’s performance (harmfulness score, attack success rate, accuracy on various benchmarks) under three different conditions: original aligned model, attacked model without defense, and attacked model with the proposed defense and baseline methods. It highlights the superior performance of the proposed method in mitigating the effects of the attack while maintaining the original performance on benign tasks.

This table presents a comparison of the performance of three different defense methods against the Fine-tuning based Jailbreak Attack, using two different language models (Llama-2-7B-Chat and GPT-3.5-Turbo). The methods compared are: no defense, a baseline method (integrating safety examples), and the proposed Backdoor Enhanced Safety Alignment method. The table shows the harmfulness score, attack success rate (ASR), and performance on three benchmark tasks (ARC-Challenge, MMLU, and MT-Bench) for each method and model. The best performance for each attacked model is highlighted.

This table presents a comparison of the performance of three different defense methods against the Fine-tuning based Jailbreak Attack (FJAttack) on two large language models: Llama-2-7B-Chat and GPT-3.5-Turbo. The methods compared are: no defense, a baseline defense (incorporating safety examples), and the proposed Backdoor Enhanced Safety Alignment method. The table shows the harmfulness score, attack success rate (ASR), and performance on three benchmark tasks (ARC-Challenge, MMLU, and MT-Bench) for each method and model. The best performing method for each metric on the attacked models is highlighted.

This table presents a comparison of the performance of three different defense methods against the Fine-tuning based Jailbreak Attack (FJAttack) using two different language models: Llama-2-7B-Chat and GPT-3.5-Turbo. The methods compared are: no defense, a baseline defense method (using additional safety examples), and the proposed Backdoor Enhanced Safety Alignment method. The table shows the harmfulness score, attack success rate, and performance on three benchmark tasks (ARC-Challenge, MMLU, and MT-Bench) for each method and model. The best-performing method for each attacked model is highlighted.
Full paper#