↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current robotic systems struggle with long-horizon tasks due to limitations of open-loop control, which leads to error accumulation and lack of adaptability. Existing solutions employing pixel differences or pre-trained representations have limitations in terms of efficacy and adaptability.
This paper introduces CLOVER, a closed-loop visuomotor framework that addresses these challenges. CLOVER uses a text-conditioned video diffusion model to generate visual plans, an embedding space for accurate error quantification, and a feedback-driven controller to refine actions and initiate replanning as needed. Experimental results show that CLOVER outperforms prior open-loop methods by a significant margin on standard benchmarks and in real-world settings.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces CLOVER, a novel closed-loop visuomotor control framework for robotic manipulation, significantly improving performance on long-horizon tasks and offering a robust, adaptable solution to current open-loop limitations. It also introduces a novel error measurement mechanism using state embeddings which solves the accuracy and adaptability issues of prior methods. This advances the field of robotics and embodied AI by providing a more robust framework for complex, real-world tasks, opening new avenues for research in adaptive control and real-time feedback.
Visual Insights#
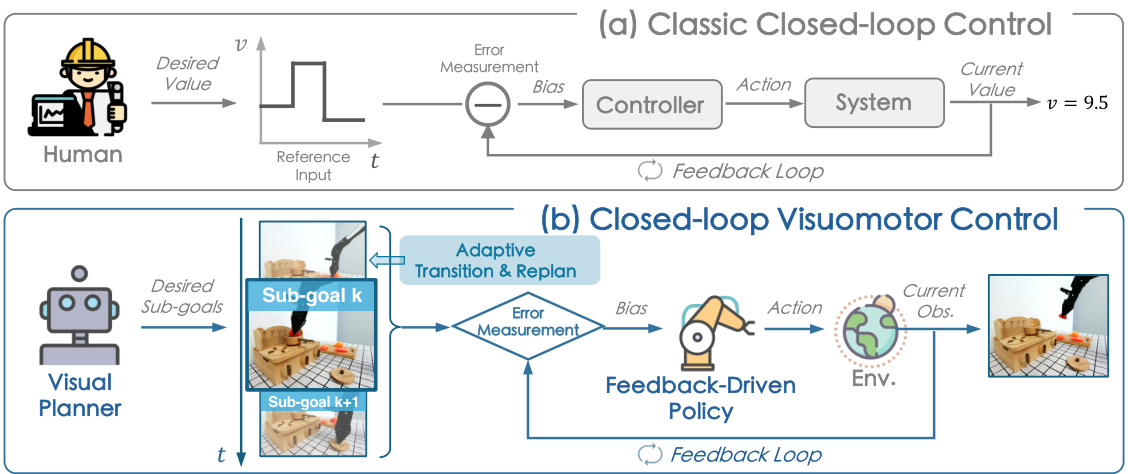
This figure illustrates the core idea of the CLOVER framework by comparing it to the classic closed-loop control system. Panel (a) shows a simple closed-loop system with a controller adjusting actions based on error measurements to achieve a desired value. Panel (b) shows the CLOVER framework, which incorporates a visual planner to generate a sequence of sub-goals. A feedback-driven policy then uses error measurements (comparing the current observation to the sub-goals) to generate actions. The system also includes mechanisms for adaptive transitions between sub-goals and replanning if necessary.
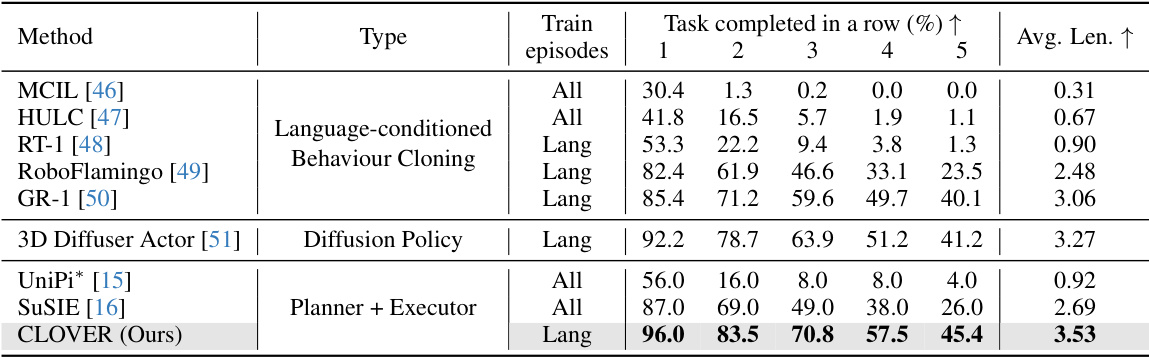
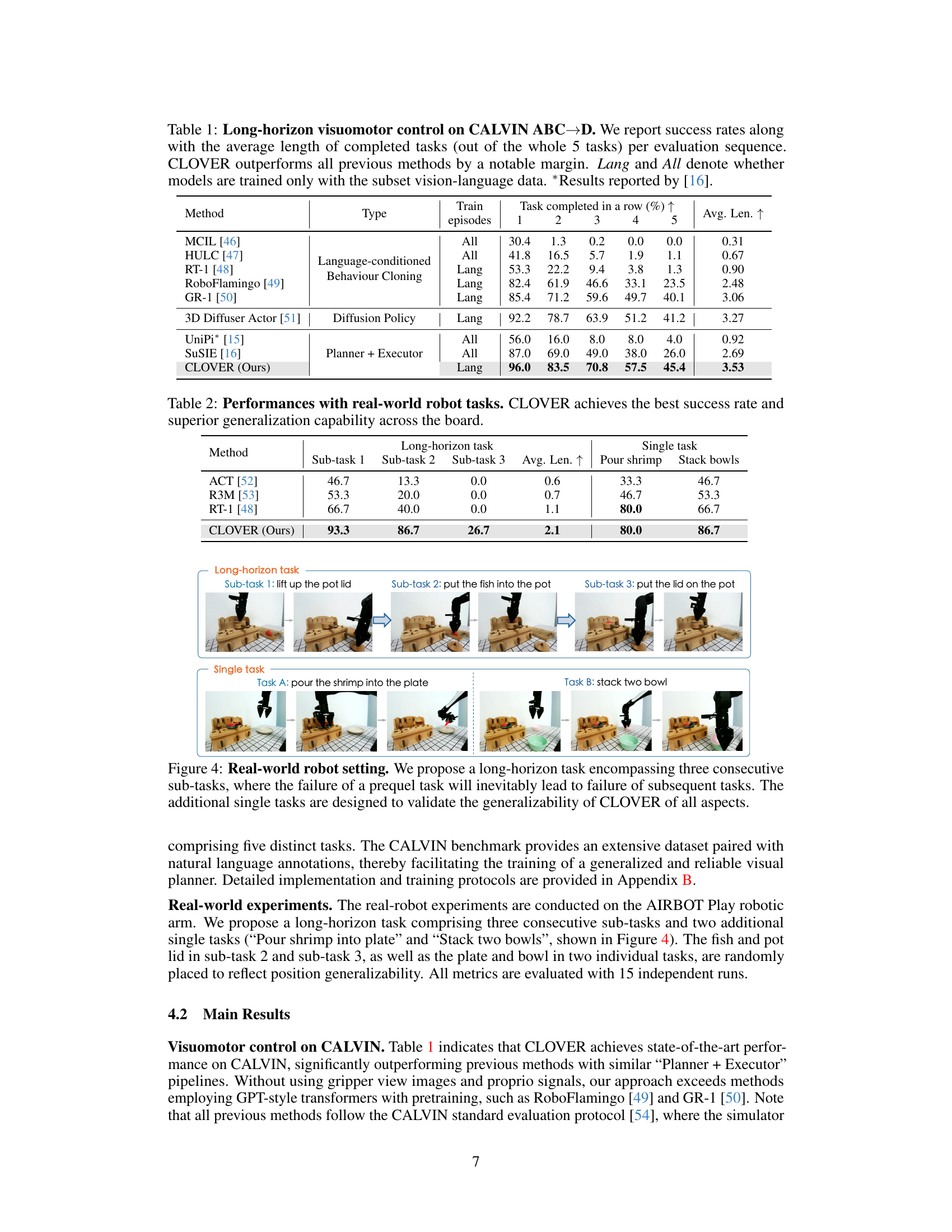
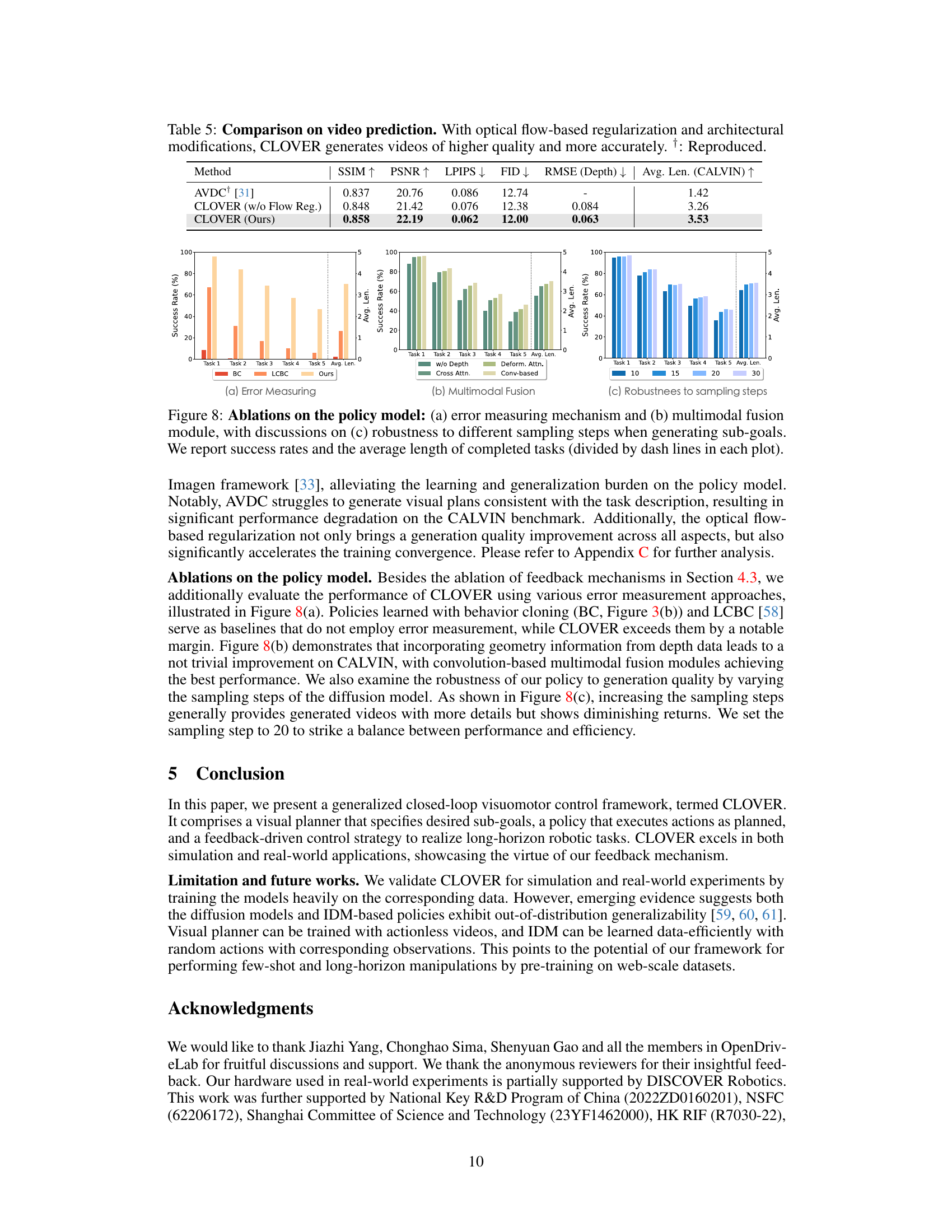
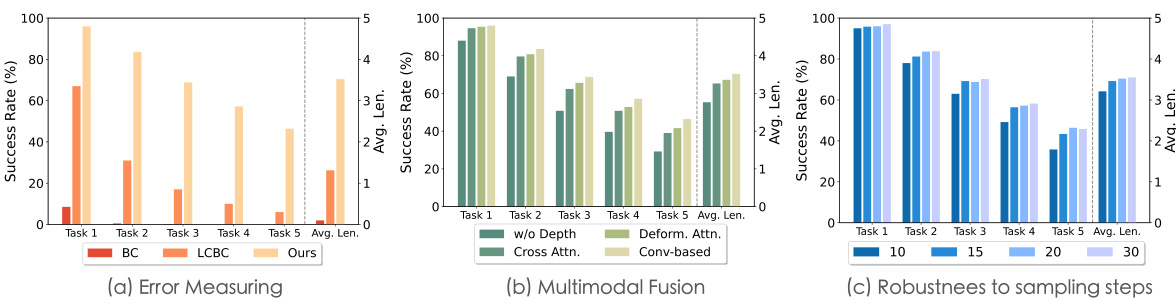
This table compares the performance of CLOVER against other state-of-the-art methods on the CALVIN benchmark for long-horizon robotic manipulation tasks. The table shows the success rate and average task completion length for each method across five sub-tasks. It also indicates whether each method was trained using only vision-language data (‘Lang’) or all available data (‘All’). CLOVER significantly outperforms all other methods.
In-depth insights#
Closed-Loop Visuomotor Control#
Closed-loop visuomotor control represents a significant advancement in robotics, addressing limitations of traditional open-loop systems. Real-time feedback is crucial, allowing robots to adapt to unforeseen circumstances and correct errors. This approach often leverages visual information, using cameras to monitor the robot’s actions and the environment’s state. Accurate error quantification is essential for effective control, and this can be challenging due to the complexity of visual data. Methods to establish feedback loops and measure errors effectively are a key area of research. Generative models are increasingly utilized to predict future states, providing a reference for comparison with the actual state. This allows for proactive error correction and more robust manipulation. Adaptive control strategies play a vital role, dynamically adjusting actions based on feedback to refine actions and achieve desired goals. Furthermore, integration of depth information and optical flow enhances precision and the handling of dynamic environments. Combining these components into a closed-loop framework improves the ability of robots to perform complex, long-horizon manipulation tasks with enhanced adaptability and robustness.
Generative Visual Planning#
Generative visual planning, in the context of robotics, involves using generative models to create sequences of future visual states that guide robot actions. This contrasts with traditional open-loop methods, which rely on pre-programmed sequences or static goal images. The power of generative visual planning lies in its ability to produce flexible, adaptable plans that can account for uncertainty and dynamic environments. Generative models, such as diffusion models, are particularly well-suited for this task, as they excel at generating diverse and realistic images. However, the use of generative models also introduces challenges. Generating high-quality, temporally consistent visual sequences remains difficult, and the computational cost can be substantial. Furthermore, robust error correction mechanisms are crucial, as the generative model’s output might not perfectly match the real-world situation. Therefore, effective generative visual planning requires careful consideration of the model architecture, training strategy, and integration with feedback control systems to enable real-time adaptation and error handling. Research in this area focuses on developing more efficient and robust generative models, designing better evaluation metrics, and exploring innovative approaches to combine generative planning with other control techniques for enhanced performance.
Error Measurement#
The effectiveness of closed-loop visuomotor control hinges on accurate error measurement. The paper highlights the limitations of prior methods relying on pixel-level differences or pre-trained visual representations, which often lack adaptability and precision. Instead, CLOVER introduces a measurable embedding space where errors are quantified accurately using state embeddings trained with explicit error modeling. This approach, unlike prior methods, directly captures the deviation between planned and observed states enabling more effective and efficient error correction. The strong correlation between state embedding distances and convergence/divergence from target states validates the efficacy of this new methodology. This approach allows the system to efficiently detect discrepancies and enables the controller to make precise adjustments, improving the robustness and adaptability of the robotic control system for long-horizon tasks. The success of this novel error measurement strategy demonstrates its potential to overcome existing limitations in closed-loop visual control and significantly advance the field of robotic manipulation.
Feedback-Driven Policy#
A Feedback-Driven Policy, in the context of robotics research, is a crucial component that leverages real-time feedback to refine actions and adapt to unforeseen circumstances. Unlike open-loop systems which operate on pre-planned sequences, a feedback-driven policy continuously measures the discrepancy between the current state and the desired goal. This measurement, often derived from visual or other sensor data, is used to calculate an error signal. The policy then employs a control mechanism, potentially a neural network or another adaptive algorithm, to adjust its actions based on this error signal. This closed-loop approach enables enhanced robustness, adaptability, and the ability to handle unexpected deviations or disturbances in the environment. Successful feedback-driven policies often involve sophisticated error modeling techniques and learning algorithms trained to minimize errors and achieve the desired goals efficiently, even in complex, dynamic scenarios. The system might also incorporate replanning mechanisms that trigger adjustments to the overall strategy if significant errors occur or sub-goals become unachievable.
Real-world Generalization#
Real-world generalization in robotics is a crucial yet challenging aspect. A model’s ability to transfer knowledge from simulated or limited real-world training data to novel, unseen environments is key for practical application. This paper’s approach to closed-loop visuomotor control, incorporating generative expectation and feedback mechanisms, directly addresses this challenge. The closed-loop design is particularly beneficial because it allows the robot to adapt and recover from errors encountered in unpredictable real-world scenarios. Unlike open-loop methods, which rely on pre-planned actions without real-time adaptation, the closed-loop system enables continuous refinement, improving robustness. Quantitative evaluation on real-world robotic manipulation tasks is critical for demonstrating this improved generalization, measuring success rates, task completion times, and adaptation to varied conditions. The choice of tasks, the diversity of environments tested, and the nature of the encountered uncertainties all affect the demonstrated level of real-world generalization. The paper needs to present clear empirical evidence, using metrics that highlight the difference between open and closed-loop performance in a variety of real-world conditions. The discussion of limitations concerning generalizability is also very important, acknowledging any specific aspects of the training environments or data that might have biased the results and indicating potential limitations in applying the model to even more diverse tasks.
More visual insights#
More on figures

This figure shows the architecture of the feedback-driven policy used in CLOVER. It consists of three main components: a state encoder that processes both the current observation and the planned sub-goal to generate fused RGB-D features and separate current and goal state embeddings; an error measurement module that calculates the difference between the current and goal state embeddings to quantify the error; and an action decoder that takes the error as input and outputs the action for the robot. The multimodal encoder uses both RGB and depth information to generate a more comprehensive representation of the robot’s state.
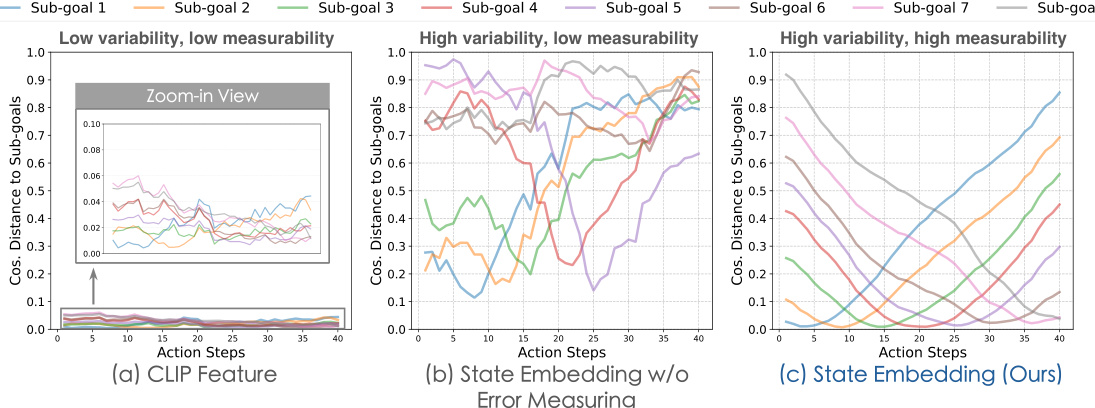
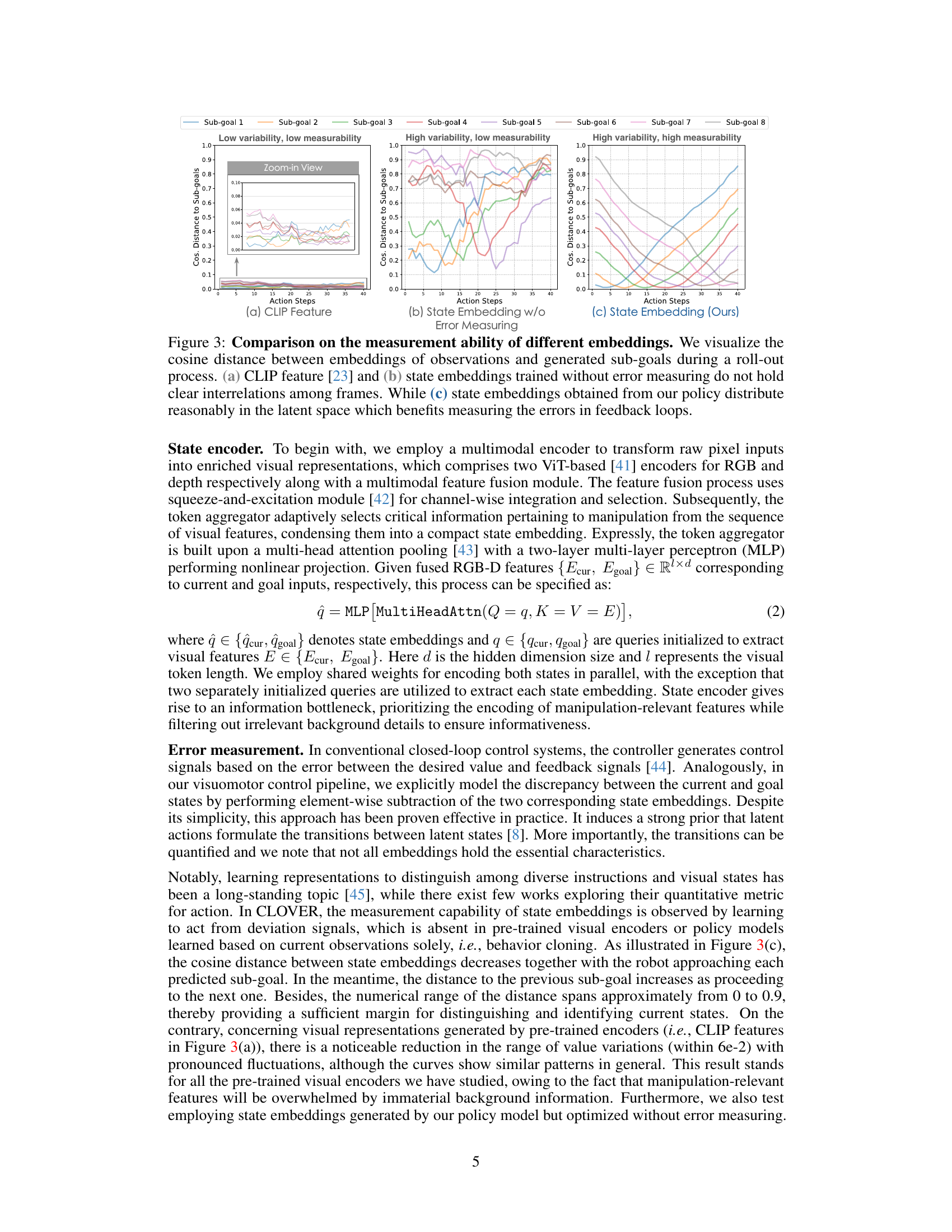
This figure compares the ability of different embedding methods to measure the error between observed and planned states for robotic manipulation. It shows the cosine distance between embeddings of observed states and generated sub-goals over a sequence of actions. CLIP features and state embeddings trained without an explicit error-measuring mechanism show poor correlation and low variability, hindering accurate error quantification. In contrast, the state embeddings learned by the proposed CLOVER framework exhibit a strong correlation and high variability, enabling accurate error measurement and facilitating adaptive control.

This figure illustrates the core idea of CLOVER, a closed-loop visuomotor control framework. Panel (a) shows a classic closed-loop control system, highlighting the reference input, error measurement, and controller. Panel (b) depicts CLOVER, which adapts the closed-loop concept for robotic manipulation. CLOVER uses a visual planner to generate a sequence of visual sub-goals, a feedback-driven policy to generate actions based on these sub-goals and error measurements, and a feedback loop to handle infeasible sub-goals and transition to the next sub-goal upon achievement.

The figure shows a real-world robot performing a long-horizon task composed of three sub-tasks and two single tasks. The long-horizon task involves lifting a pot lid, putting a fish into the pot, and putting the lid back on. The two single tasks involve pouring shrimp onto a plate and stacking two bowls. The setup aims to test the robot’s ability to handle multi-step tasks and to assess the generalizability of the CLOVER system across different task types.
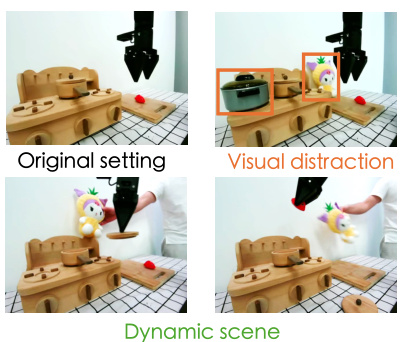
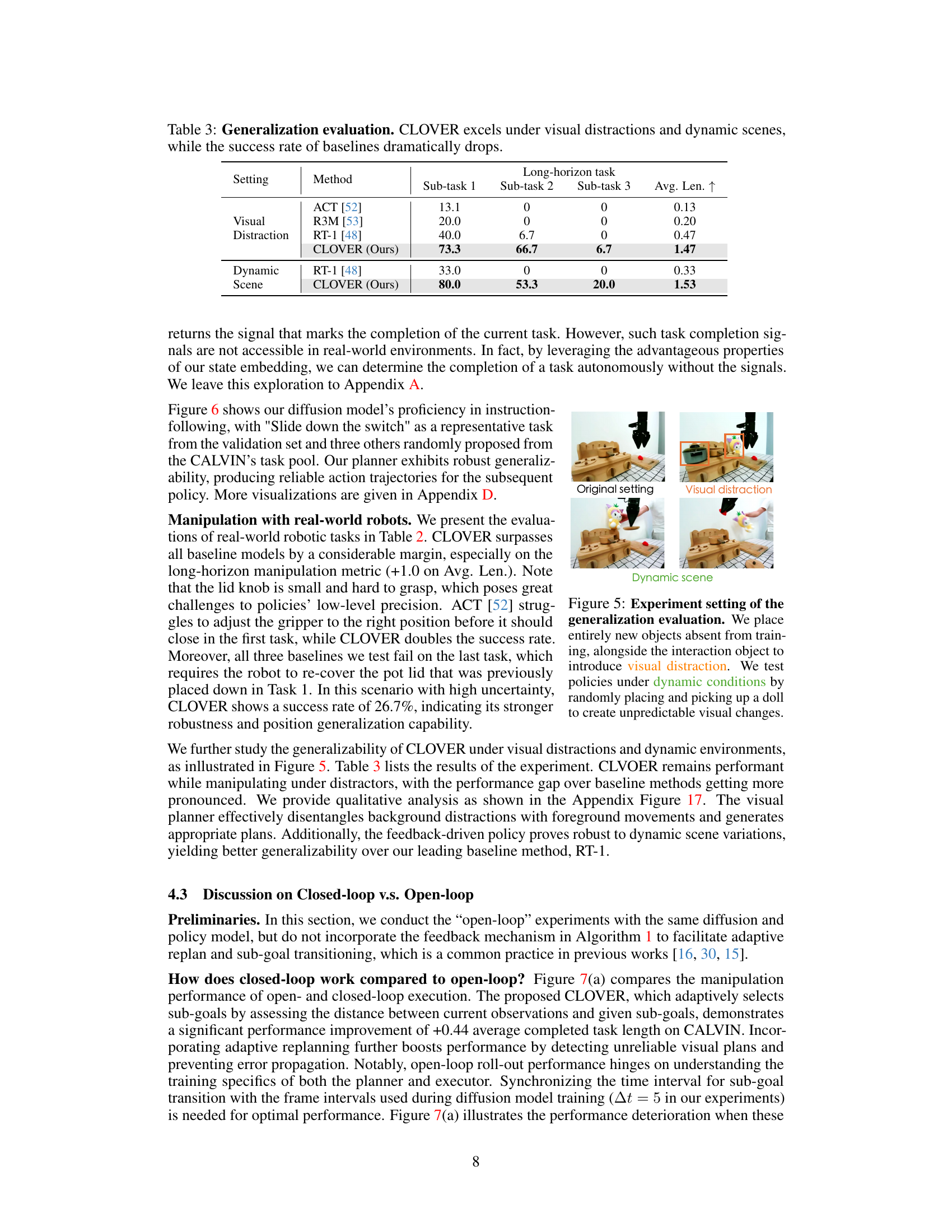
This figure shows the experimental setup for evaluating the generalization capabilities of the proposed CLOVER framework. Three different settings are shown: the original setting, a setting with visual distractions (additional objects), and a dynamic scene setting (additional objects and a moving doll). The purpose is to assess how well the robot performs under conditions that differ from those seen during training.
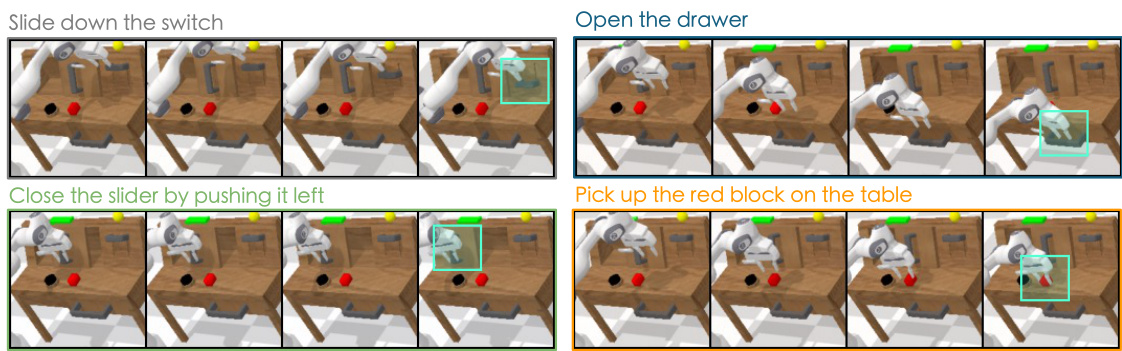
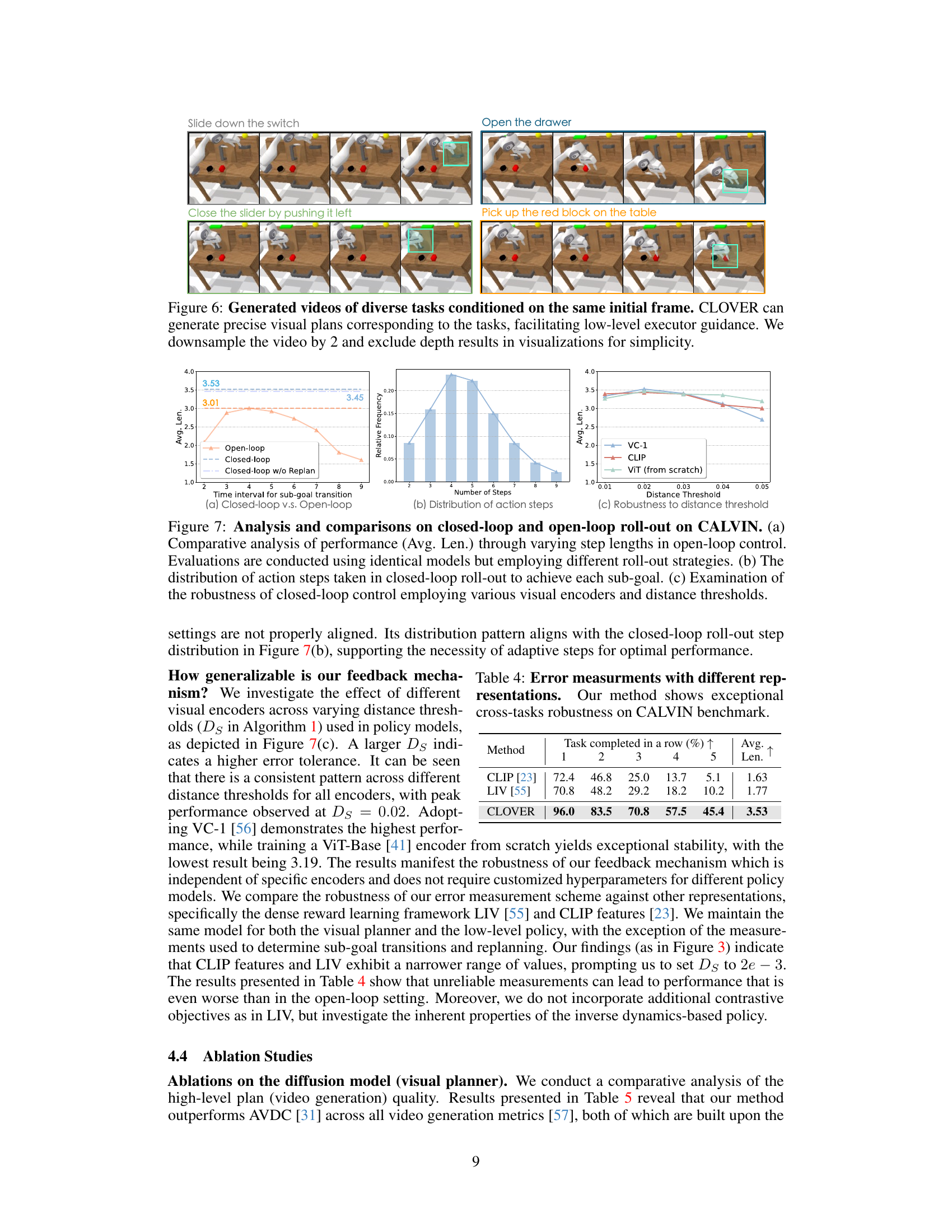
This figure shows examples of videos generated by CLOVER for four different tasks, all starting from the same initial frame. The model generates a sequence of images (a visual plan) for each task that accurately reflects the task’s goal. The visual plans are detailed enough to guide a low-level robotic control system in performing the task successfully. The videos are downsampled (2x) and only RGB images are shown to simplify visualization; depth information is omitted.
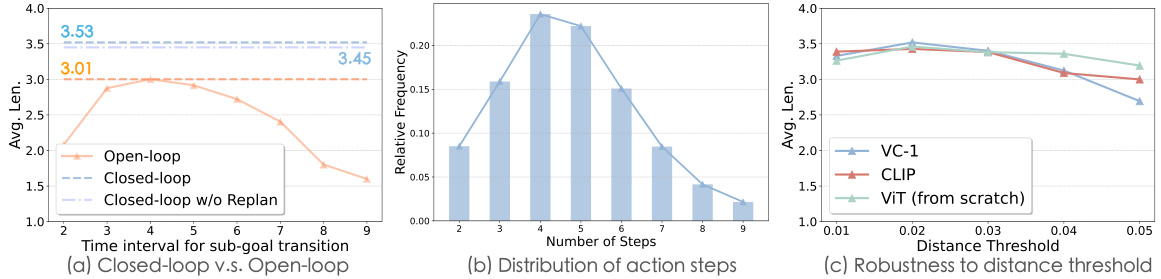
This figure compares the performance of closed-loop and open-loop control strategies on the CALVIN benchmark. It shows the impact of varying the time interval for sub-goal transitions in open-loop control, the distribution of action steps in closed-loop control, and the robustness of closed-loop control to different visual encoders and distance thresholds.
This figure compares the effectiveness of different embedding methods for measuring errors in a closed-loop visuomotor control system. It shows that using the proposed state embeddings, trained with an explicit error measuring mechanism, leads to a clearer and more measurable representation of the error between the observed and planned states compared to using CLIP features or state embeddings trained without such a mechanism. This improved measurement ability is crucial for the effectiveness of the feedback control system.
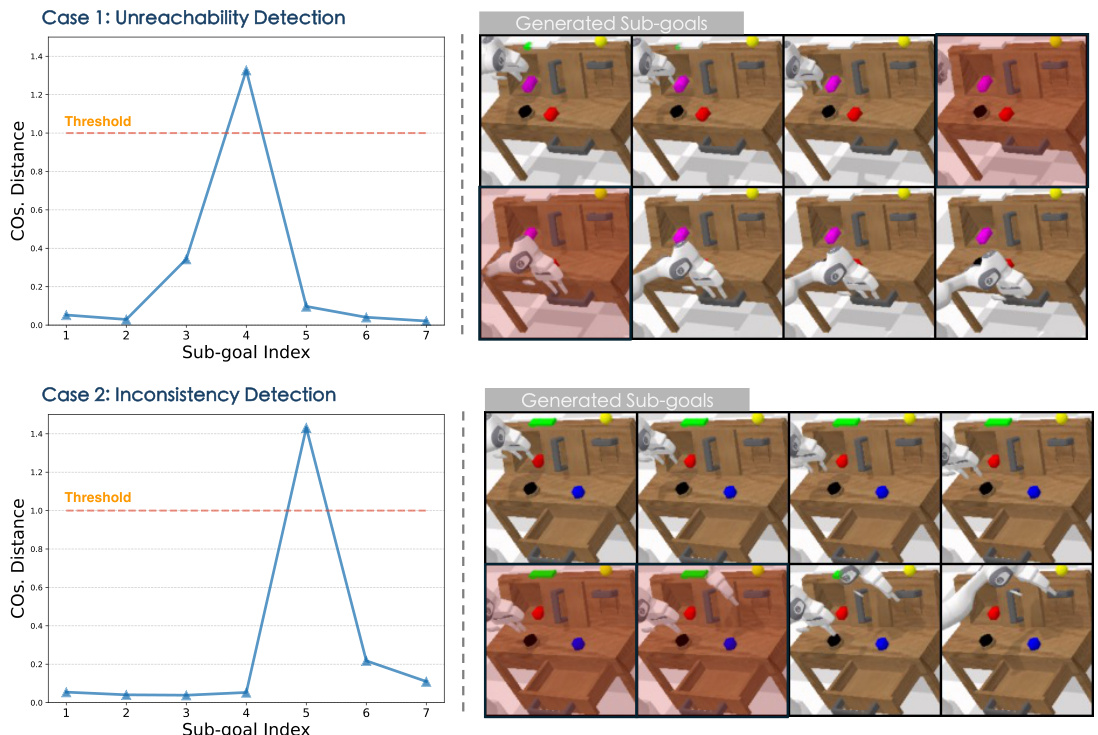
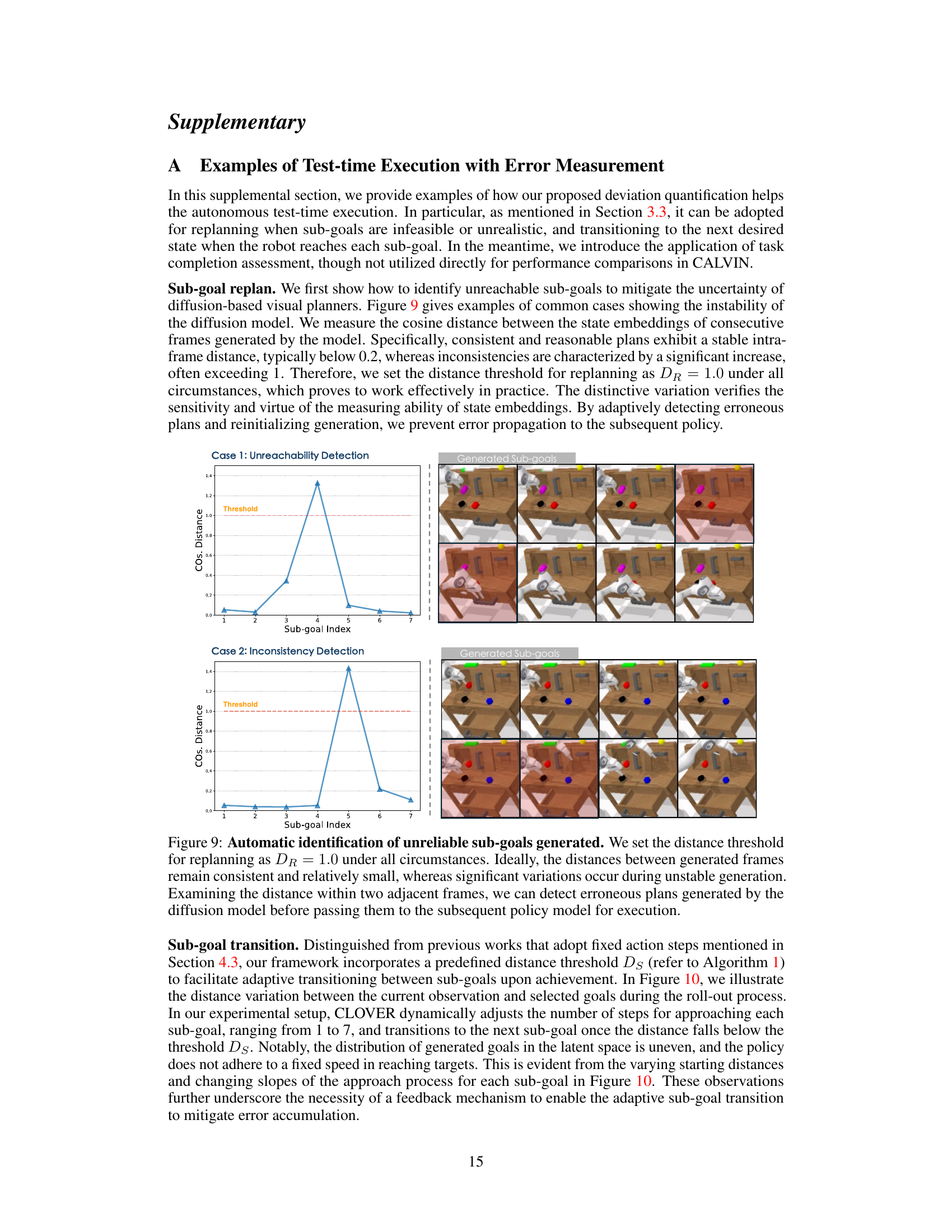
This figure shows two examples of how the system identifies unreliable sub-goals generated by the diffusion model. In Case 1 (Unreachability Detection), a large spike in the cosine distance between consecutive frames indicates an unreachable sub-goal. In Case 2 (Inconsistency Detection), inconsistent distances between frames signal an unreliable plan. The threshold for identifying these issues is set at a cosine distance of 1.0. The generated sub-goals are visualized alongside each graph, showing the visual inconsistencies associated with the high cosine distances.
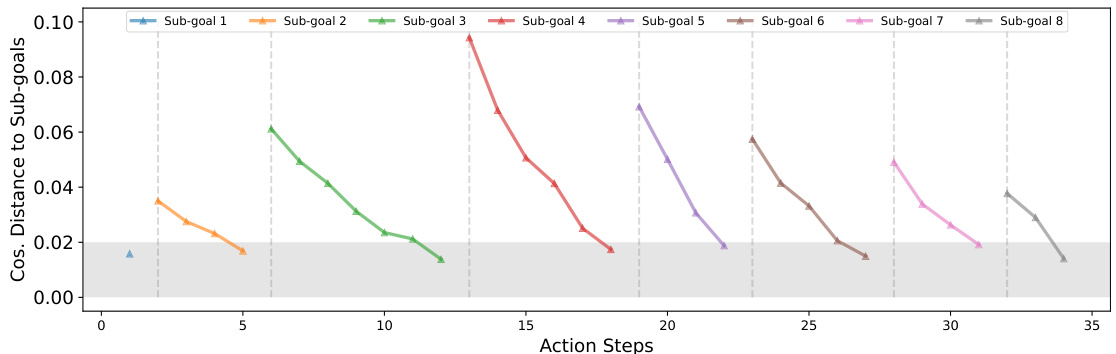
This figure compares the ability of different embedding methods to measure the error between observed and planned states for robotic manipulation. It shows that using CLIP features or state embeddings trained without an explicit error-measuring component results in inconsistent and less informative distance metrics between sub-goals. In contrast, the proposed state embeddings show a clear, monotonic relationship reflecting progress towards the sub-goals, making them suitable for closed-loop control.
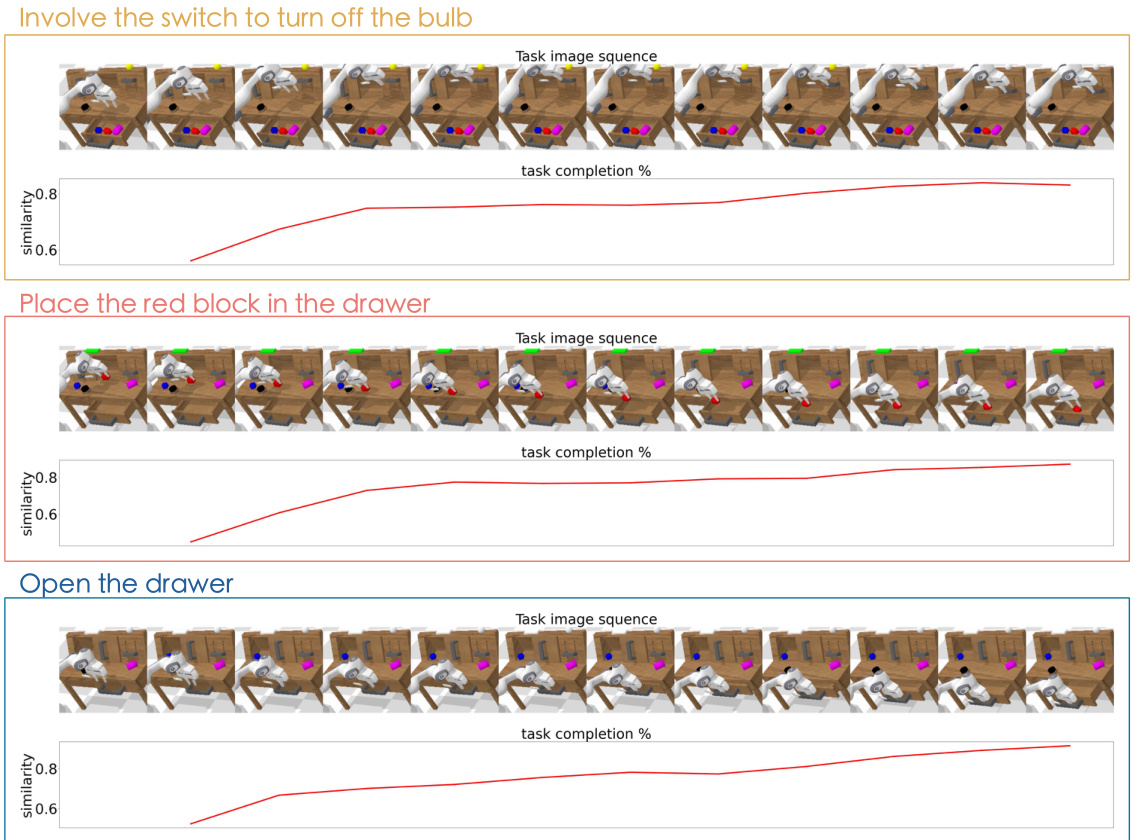
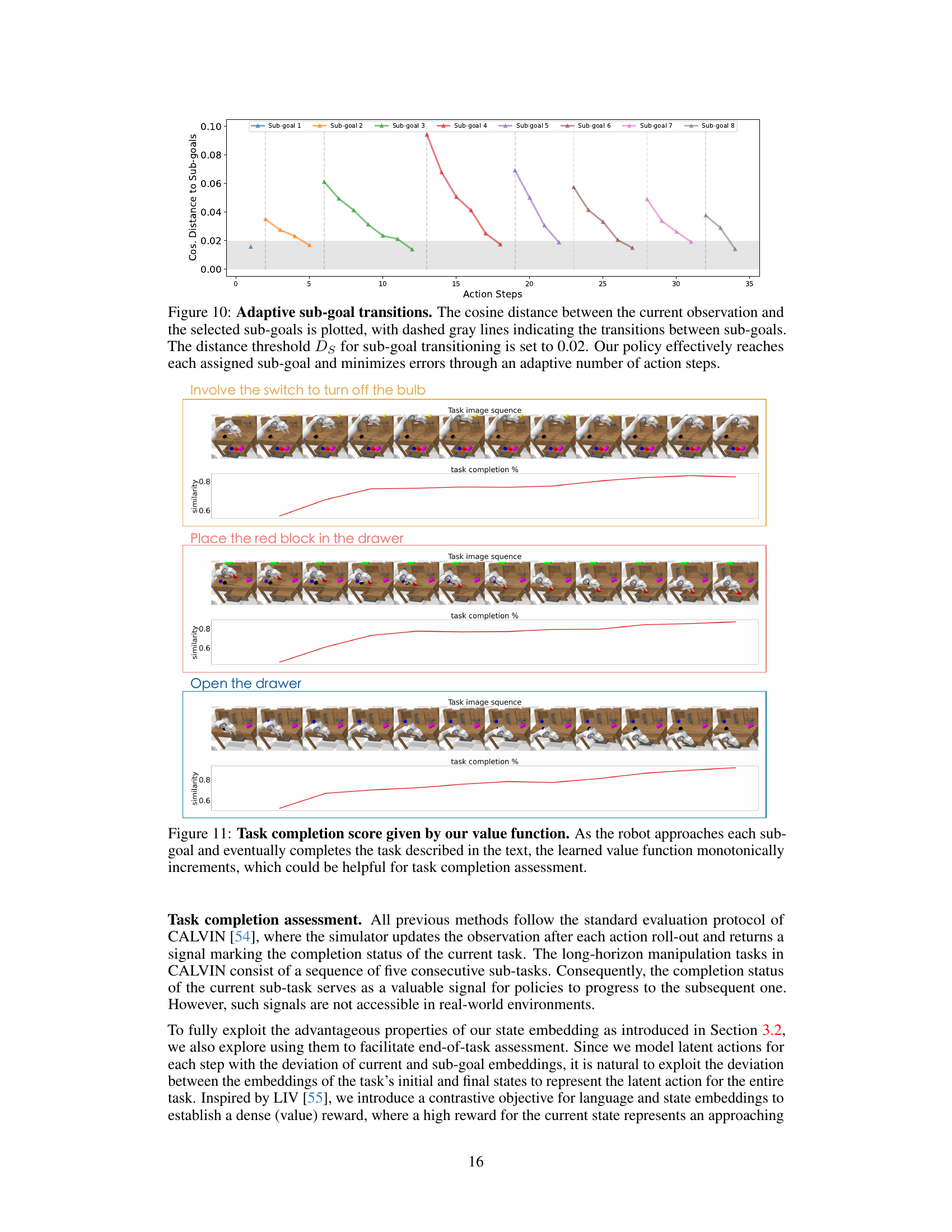
This figure shows how a learned value function can be used to assess task completion. As the robot successfully completes sub-goals in a task, the value function increases monotonically. This provides a way to automatically determine task completion without relying on external signals, which is especially useful in real-world scenarios.
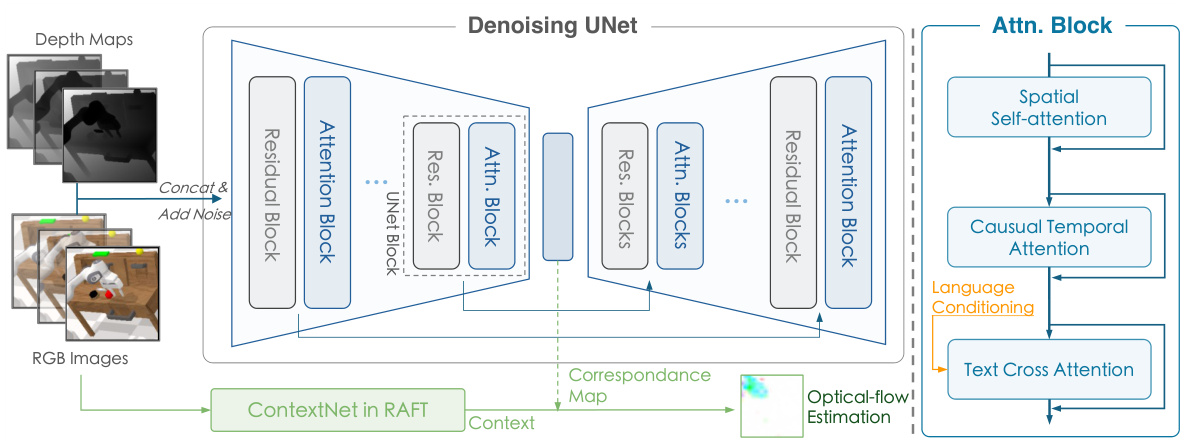
This figure illustrates the architecture of the visual planner used in the CLOVER framework. It shows how a UNet architecture is augmented with components for handling temporal consistency (casual temporal attention), incorporating language information (language conditioning and text cross-attention), and leveraging optical flow estimation for improved accuracy (ContextNet in RAFT). The visual planner takes RGB images and depth maps as input and generates a sequence of future visual plans.
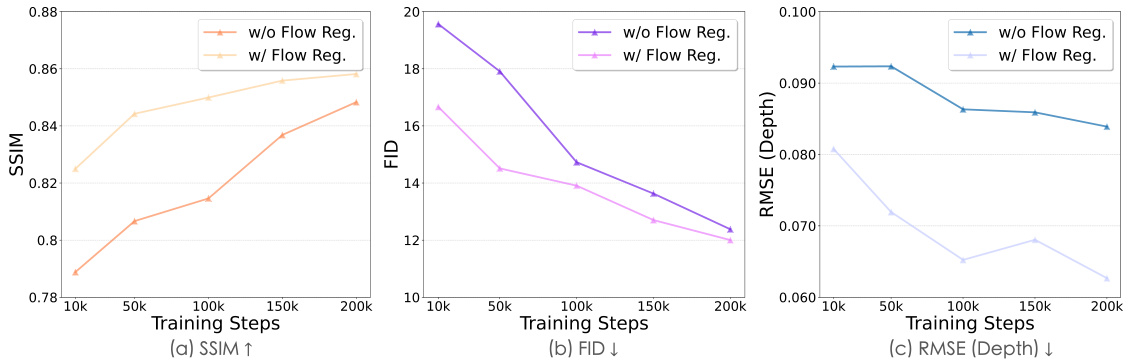
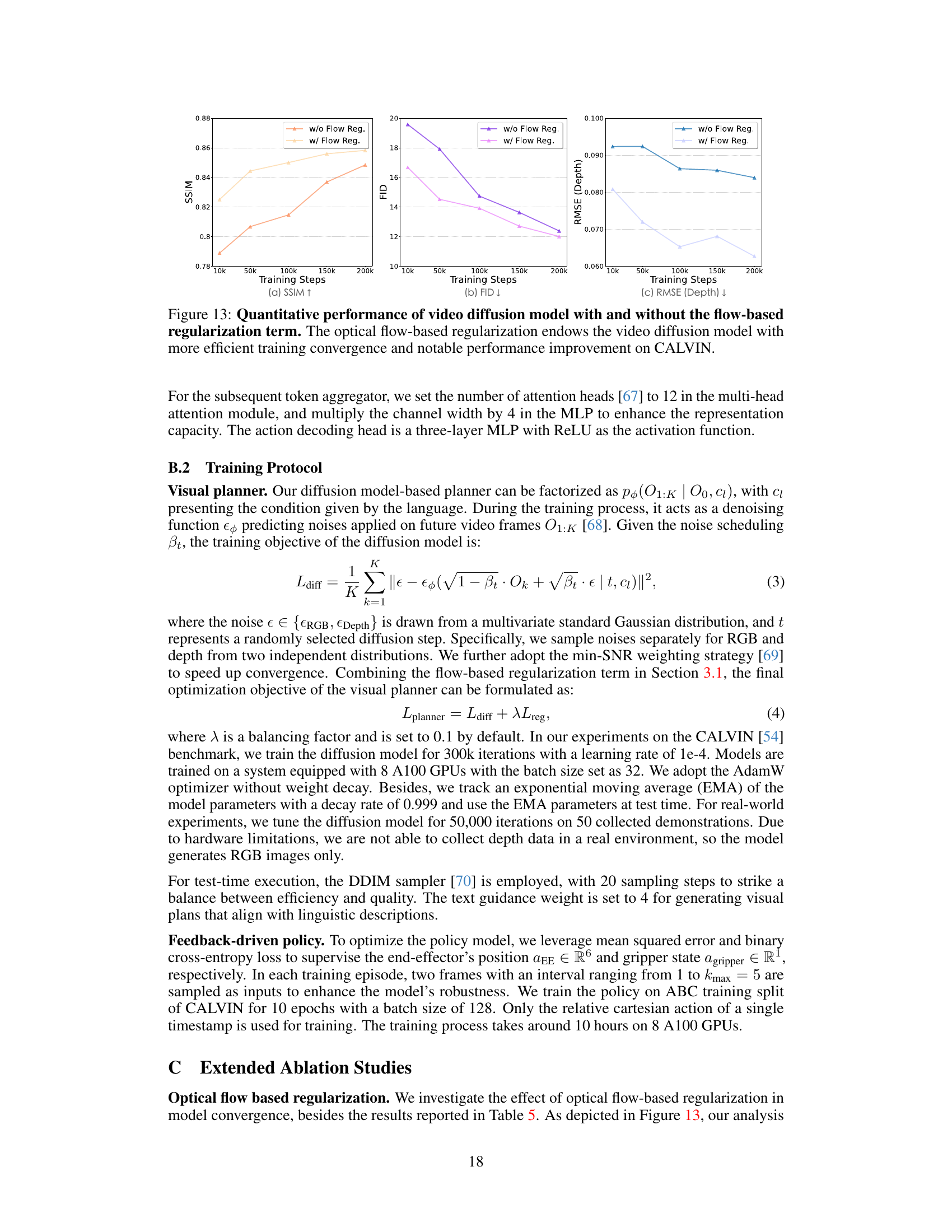
This figure shows the quantitative performance comparison of the video diffusion model with and without optical flow-based regularization. Three metrics are plotted against training steps: Structural Similarity Index (SSIM), Fréchet Inception Distance (FID), and Root Mean Square Error (RMSE) for depth. The results indicate that optical flow regularization leads to significantly better performance in all three metrics, demonstrating improved training convergence and quality of the generated videos.

The figure shows attention maps generated by the policy model during execution. The maps highlight the areas of the input image that the model focuses on when making decisions. The fact that the model focuses on the end-effector and the object it is interacting with demonstrates the model’s ability to implicitly learn relevant visual features.
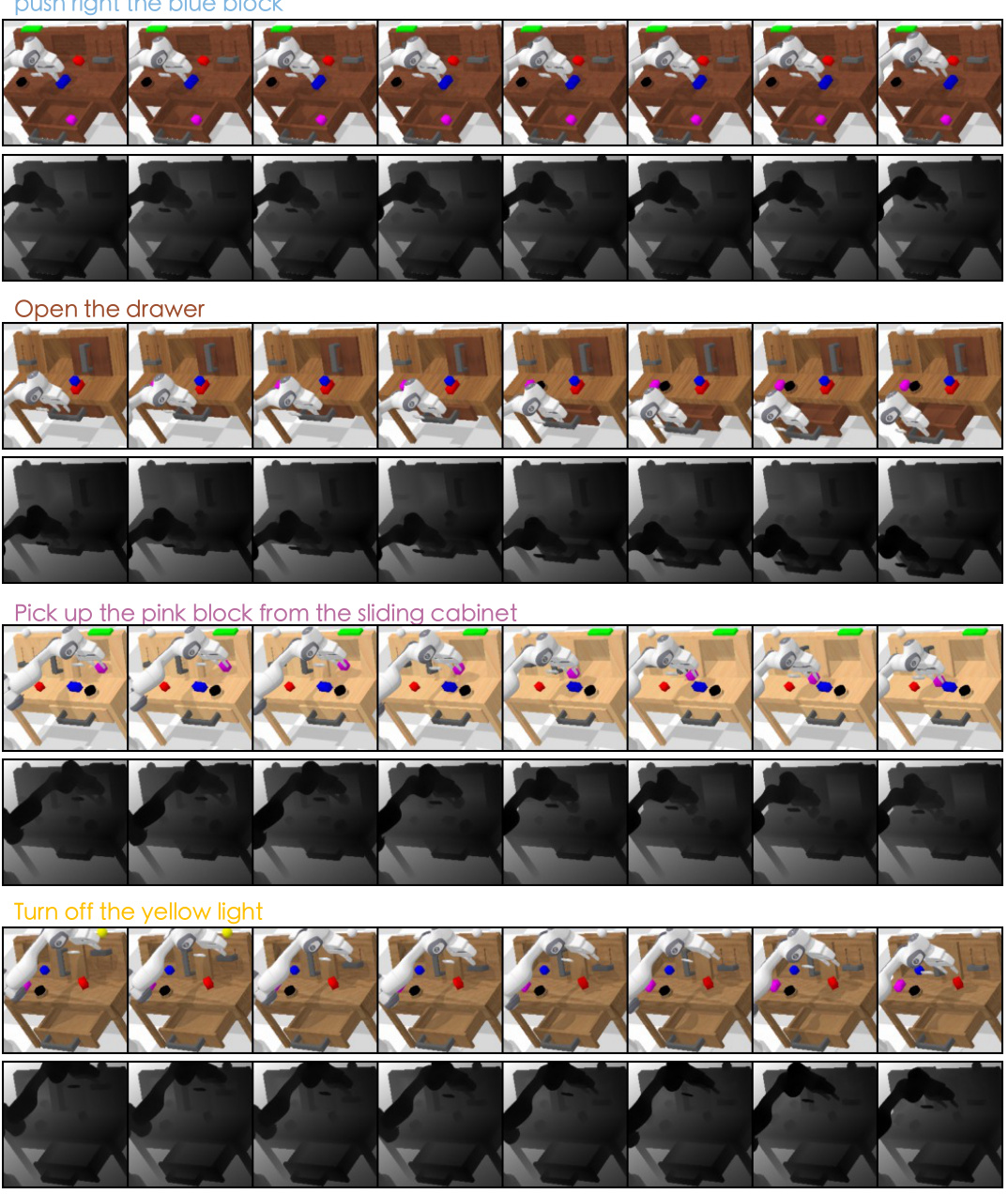
This figure shows examples of RGB-D visual plans generated by the model for various tasks. The high consistency between the RGB and depth information in the generated plans demonstrates the model’s ability to produce reliable and coherent visual plans that can effectively guide the robot’s actions.

This figure shows the experimental setup for real-world robot experiments. A long-horizon task consisting of three consecutive sub-tasks is presented, demonstrating the robot’s ability to perform multiple actions in sequence, with failure in one step affecting subsequent steps. Additional single tasks further demonstrate CLOVER’s generalizability to various scenarios.

This figure shows the experimental setup for evaluating the model’s generalization capabilities. Two scenarios are presented: visual distraction and dynamic scenes. The visual distraction scenario includes adding new objects to the scene that were not present during training. In the dynamic scene experiment, an additional object (a doll) is introduced and manipulated to simulate a more dynamic environment. The images depict the setup for each scenario.
More on tables
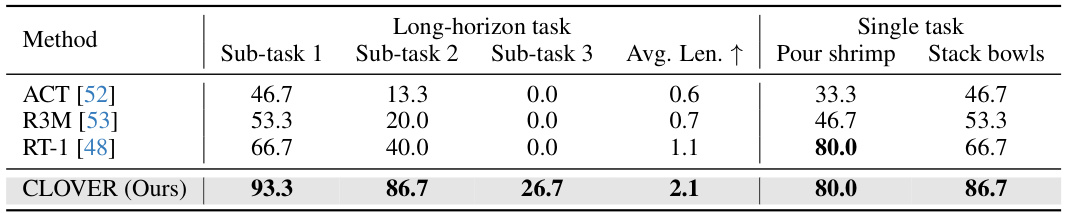
This table presents the results of real-world robotic experiments comparing CLOVER’s performance against other methods on three sub-tasks of a long-horizon task (lifting a pot lid, putting a fish into the pot, and putting the lid back on), as well as two additional single tasks (pouring shrimp into a plate and stacking bowls). The results show CLOVER achieving the highest success rate and average task completion length, demonstrating superior generalization ability across different tasks.
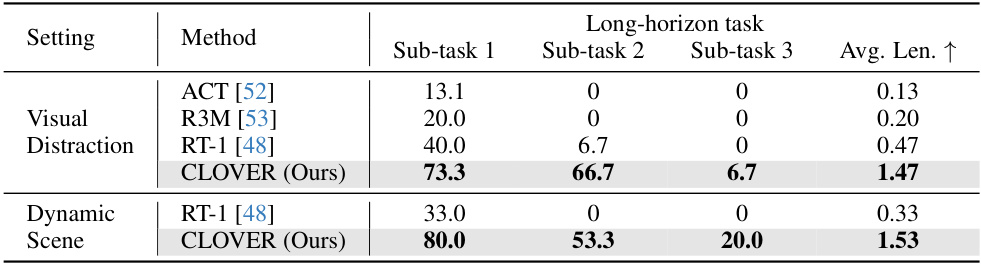
This table presents the results of generalization experiments conducted under visual distraction and dynamic scene conditions. It compares the performance of CLOVER against existing methods (ACT, R3M, RT-1) across three sub-tasks within a long-horizon manipulation task. The results demonstrate CLOVER’s superior robustness and ability to maintain high success rates even when presented with challenging environmental variations, unlike the baseline models which exhibit significant performance degradation.
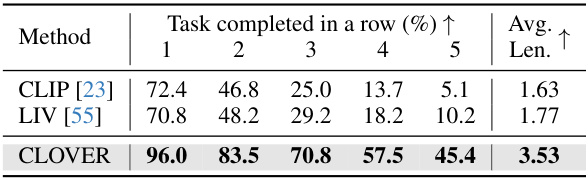
This table compares the performance of different state representation methods (CLIP, LIV, and CLOVER) on the CALVIN benchmark, showing the success rate for each subtask of a long-horizon task and the average length of completed tasks. CLOVER significantly outperforms the baselines, demonstrating its superior robustness and ability to effectively measure errors in feedback loops.

This table compares the performance of video prediction using different methods. The metrics used are SSIM, PSNR, LPIPS, FID, RMSE (Depth), and Average Length (CALVIN). It shows that CLOVER, especially with optical flow regularization, achieves better results than AVDC in terms of various metrics, including visual quality and temporal coherence, suggesting that the added regularization improves the model’s ability to generate videos consistent with realistic movements.

This table presents the results of experiments conducted to evaluate the performance of the CLOVER model when using different visual encoders of varying sizes. The experiment uses the CALVIN benchmark. The table shows the success rate (percentage of tasks completed successfully) across five subtasks for each encoder, as well as the average task length. The results demonstrate the robustness of CLOVER across different visual encoders.
Full paper#