↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
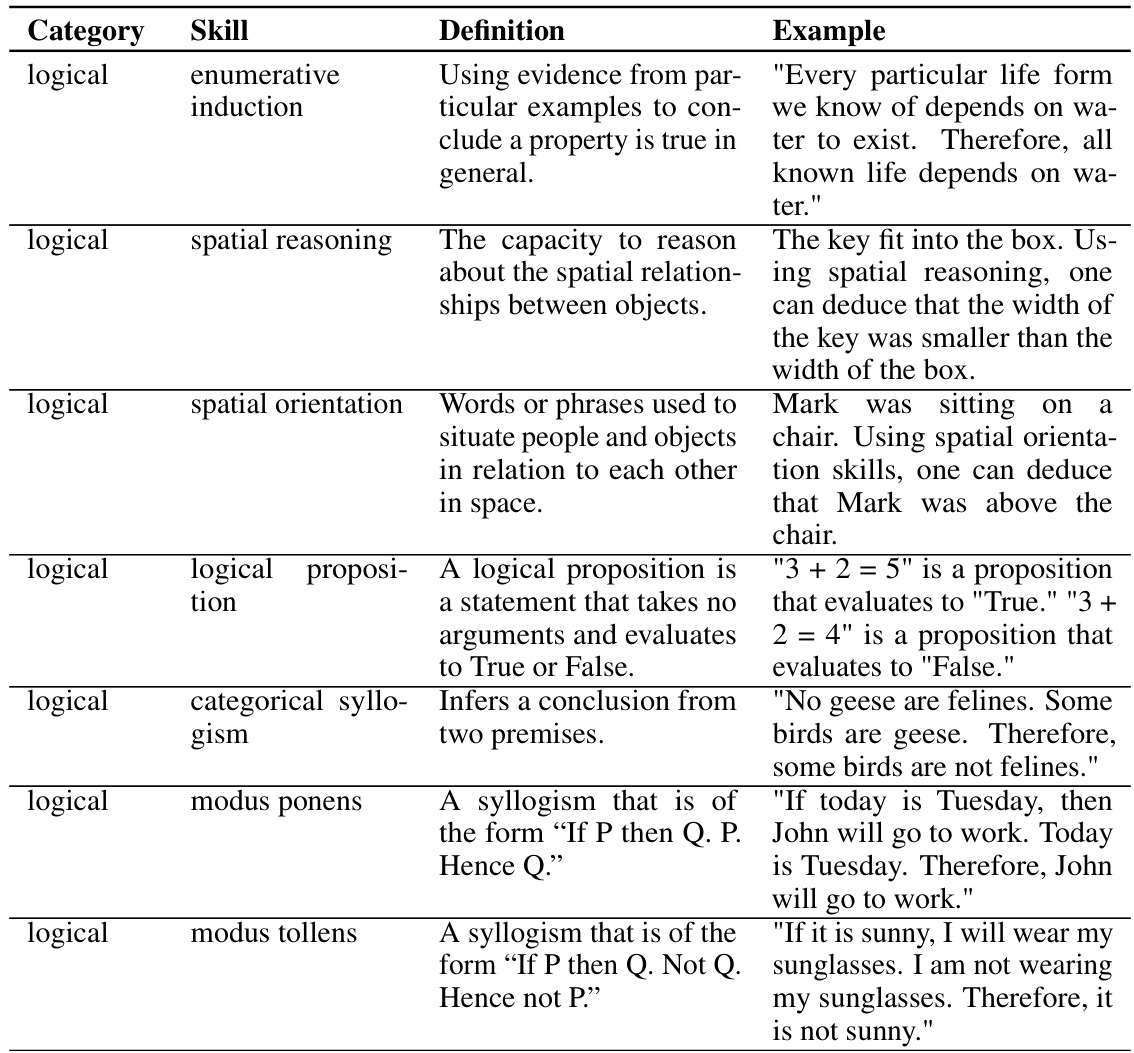
Large language models (LLMs) struggle with compositional generalization—combining learned skills in novel ways. A recent study, SKILL-MIX, showed that while larger models performed well, smaller models struggled. This creates a significant challenge in advancing AI capabilities. This limitation poses a major obstacle for research, limiting the ability to create more versatile and intelligent AI systems that can handle complex real-world tasks effectively.
This work tackles this challenge by investigating whether fine-tuning smaller LLMs on examples of combined skills can improve their composition abilities. The researchers fine-tuned smaller models on data generated by a larger model (GPT-4) exhibiting combinations of 1, 2, or 3 skills. Their results demonstrated noticeable improvements in composing texts with up to 5 skills—even those not seen during training, showing enhanced generalization. This suggests that training on skill combinations is more effective than training on individual skills alone. This finding offers a potentially more efficient approach to improve the compositional skills of LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the common assumption that large language models’ compositional abilities are solely determined by their size and pretraining. By demonstrating that fine-tuning smaller models on specific examples significantly improves their compositional generalization, it opens new avenues for enhancing model capabilities and understanding the dynamics of compositional generalization.
Visual Insights#
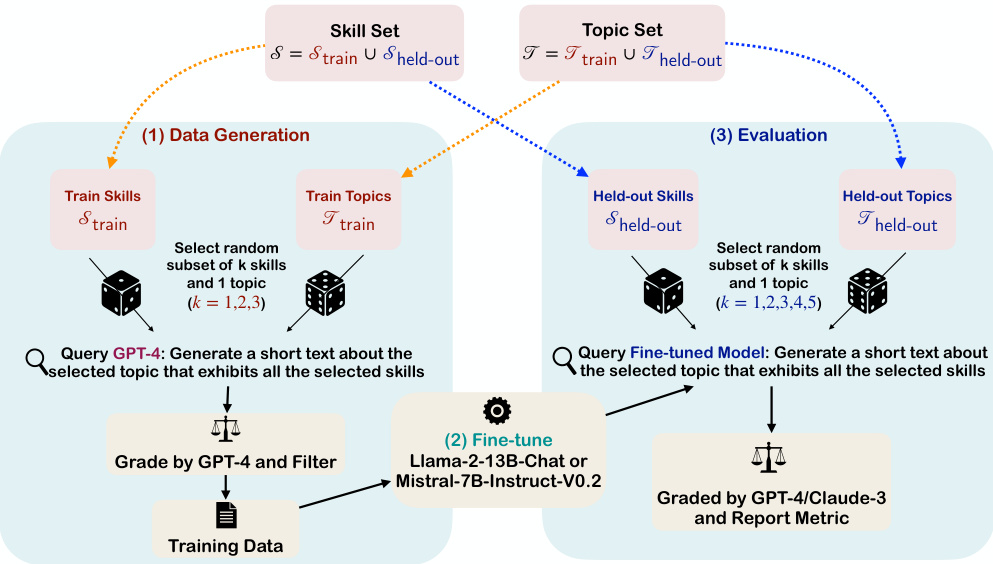
This figure illustrates the three-stage pipeline used to evaluate the models’ ability to generalize skill combinations. First, a dataset is generated using GPT-4, where the generated texts exhibit combinations of up to three training skills on training topics. Then, smaller language models (LLaMA-2-13B-Chat and Mistral-7B-Instruct-v0.2) are fine-tuned using this dataset. Finally, the fine-tuned models are evaluated on their ability to combine up to five skills (including held-out skills unseen during training) on held-out topics. The evaluation measures the models’ compositional generalization capabilities.
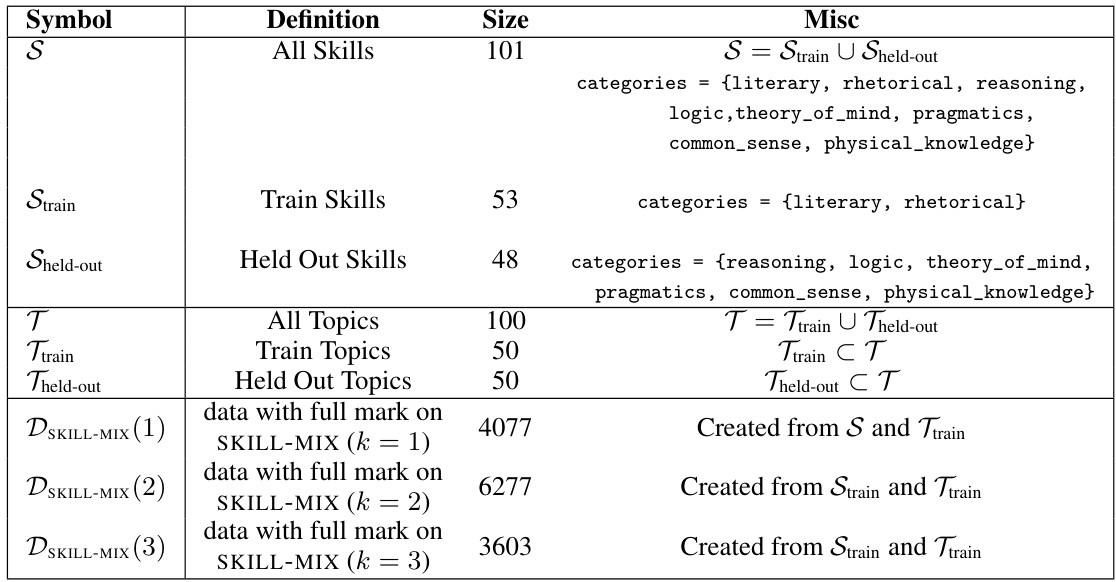
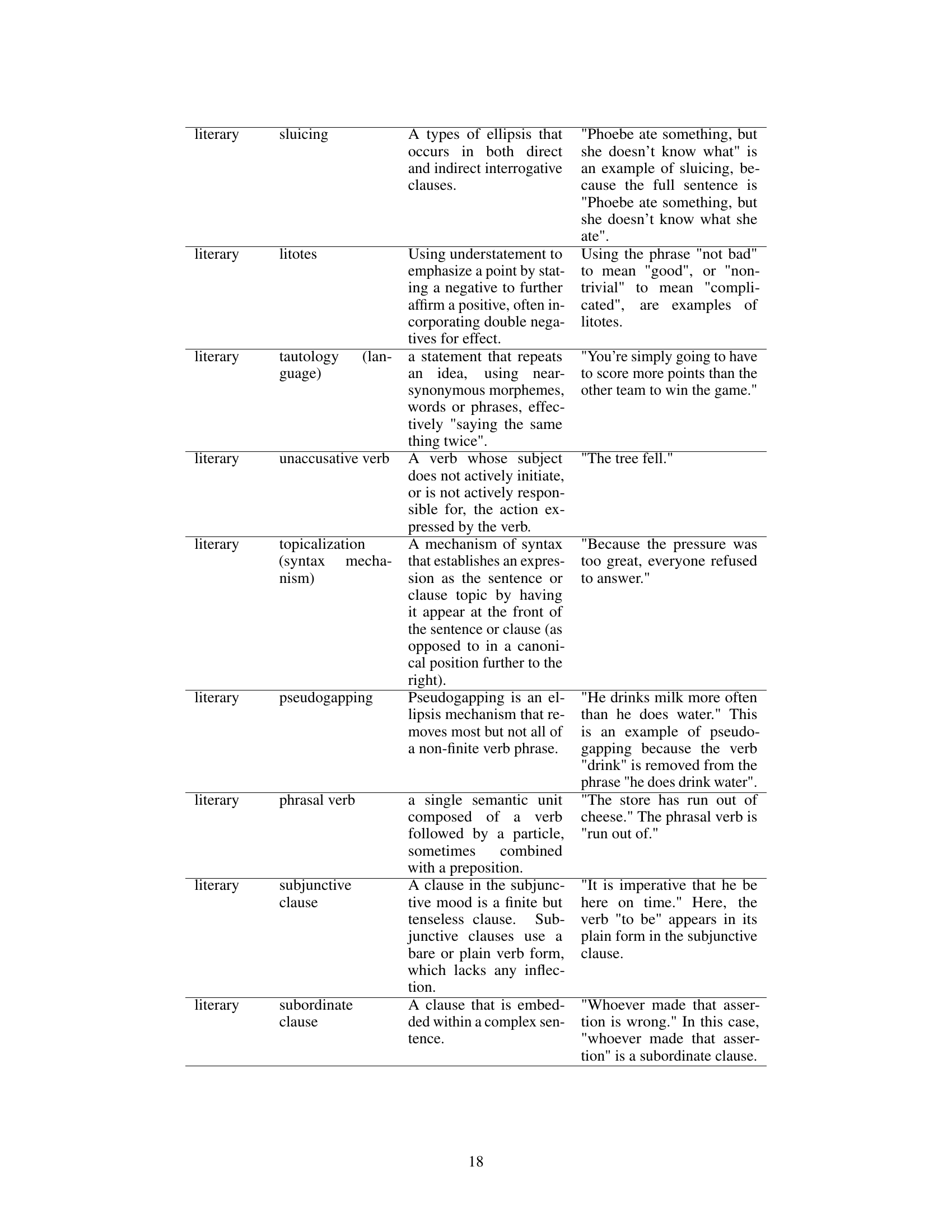
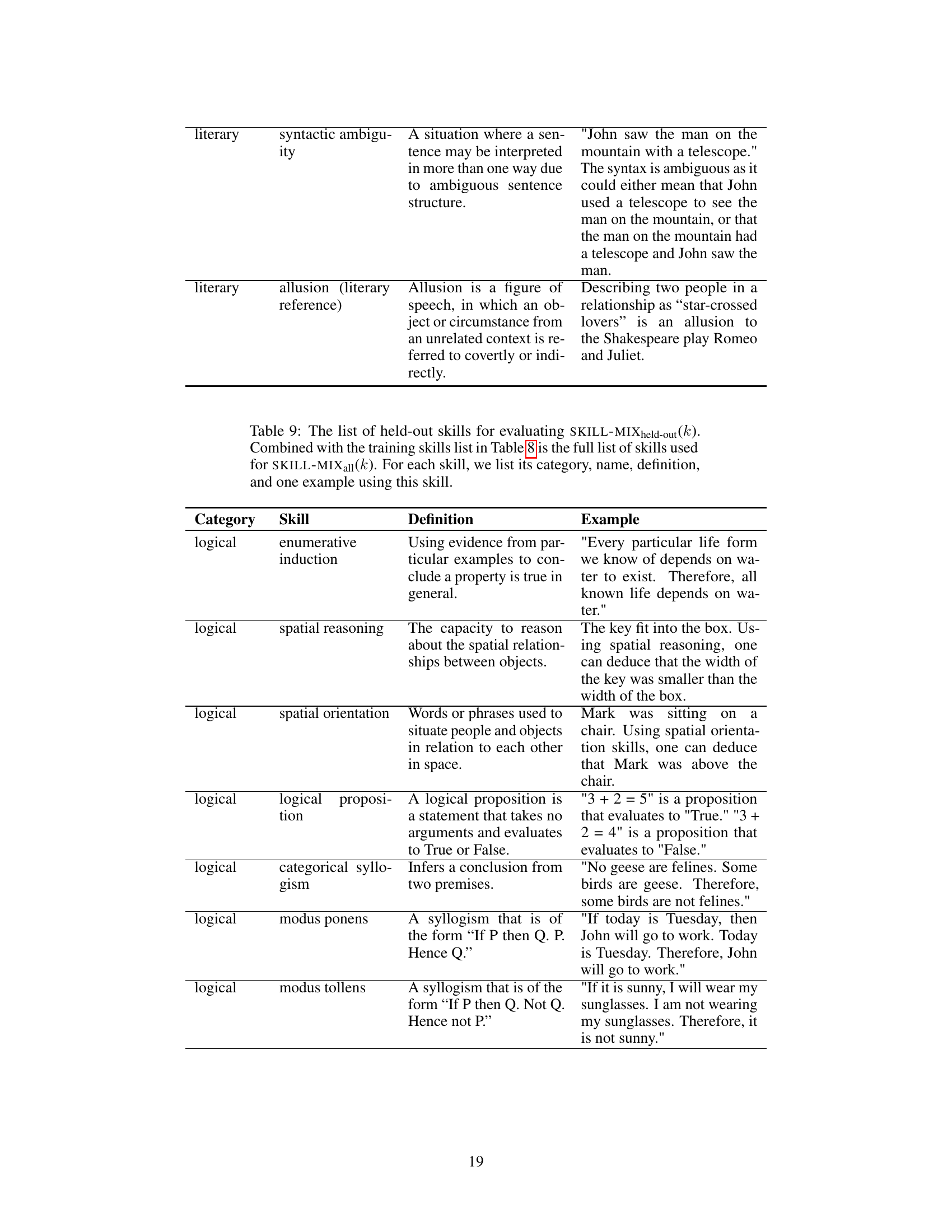
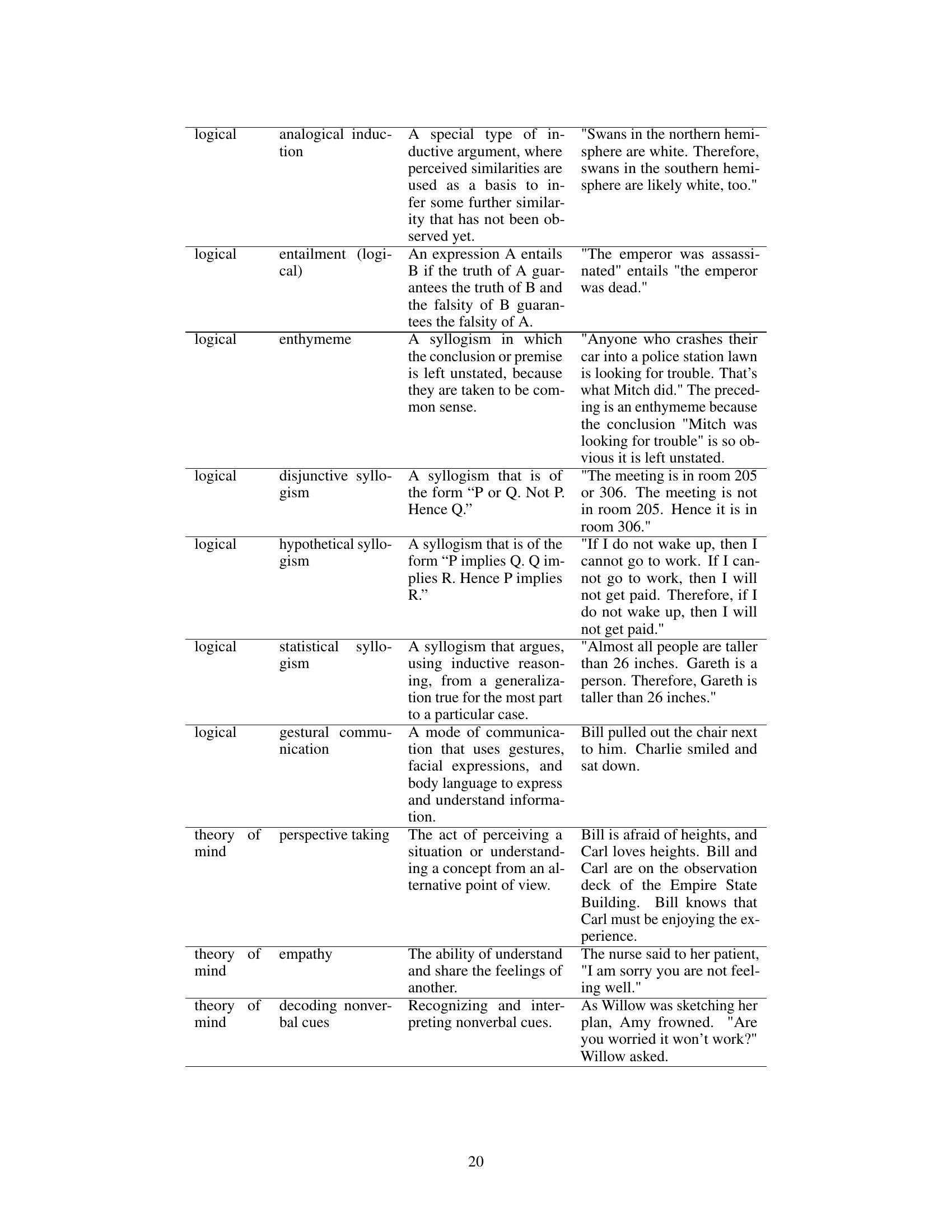
This table summarizes the notations used in the data generation section (Section 3.1) of the paper. It defines various symbols representing the skill sets (all skills, training skills, held-out skills), topic sets (all topics, training topics, held-out topics), and the datasets generated for different numbers of skills (k=1,2,3). The table also specifies the size of each set and provides additional context about how the datasets were created.
In-depth insights#
Skill Composition#
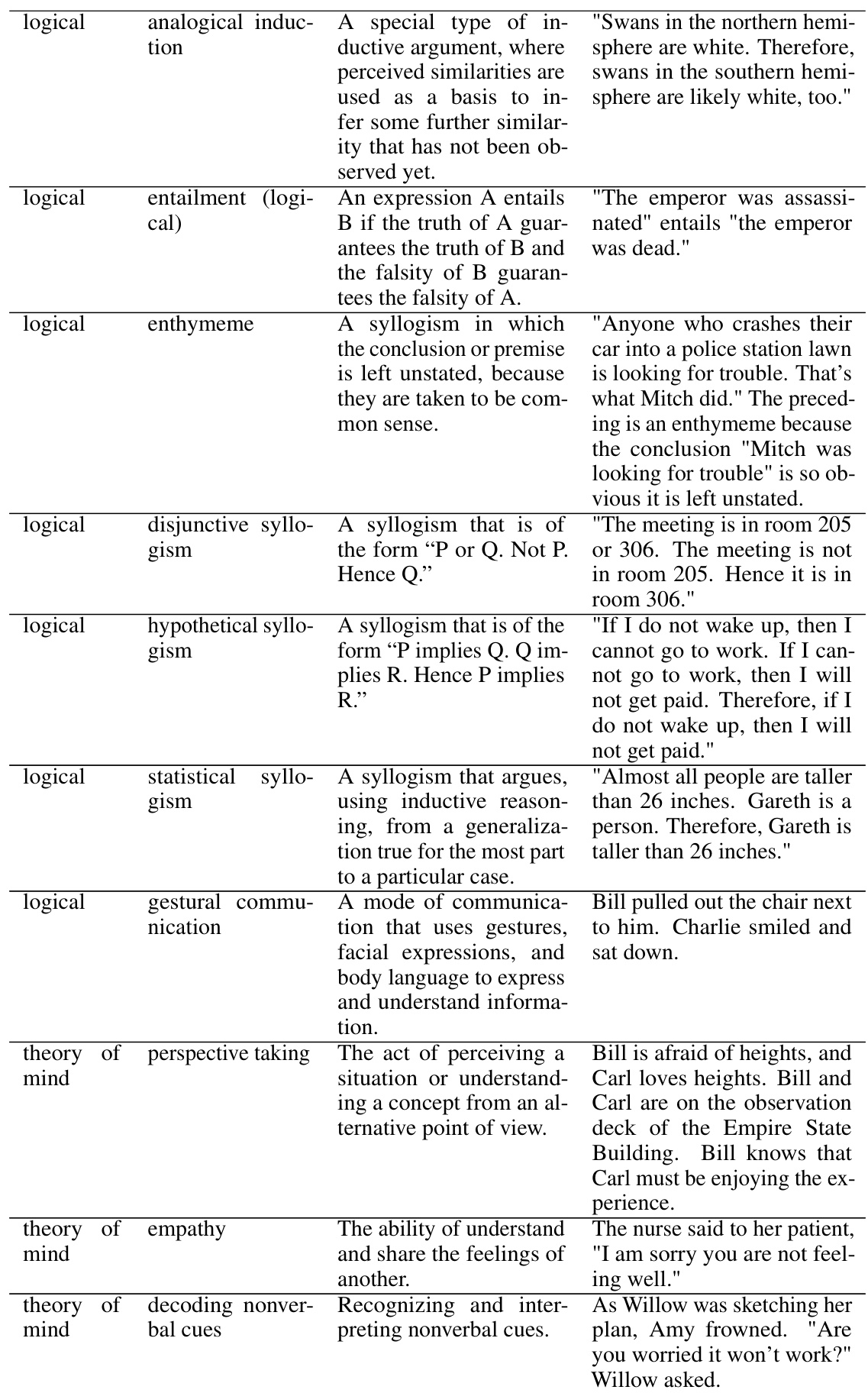
The concept of ‘Skill Composition’ in large language models (LLMs) explores the ability of these models to combine multiple learned skills in novel ways, going beyond simple memorization or retrieval. Effective skill composition is crucial for demonstrating genuine intelligence and compositional generalization, enabling LLMs to solve complex problems that require combining diverse capabilities. The research delves into how LLMs learn this skill, often investigating the impact of training data and model architecture. Fine-tuning LLMs on data explicitly showcasing combinations of skills seems to improve their compositional abilities significantly, even when tested on unseen combinations. This suggests that LLMs learn a higher-order skill, a meta-skill, enabling them to generalize beyond the training examples. However, limitations remain, as the ability to compose many skills concurrently is still challenging, highlighting the need for further research in enhancing the compositional capabilities of LLMs.
Fine-tuning Effects#
Fine-tuning’s effects on language models are multifaceted and significant. Improved performance on downstream tasks is frequently observed, showcasing the model’s enhanced ability to adapt to specific requirements. However, the extent of improvement is heavily dependent on the quality and relevance of the fine-tuning data. Overfitting can be a considerable concern, especially with smaller datasets or insufficient regularization, leading to decreased generalization to unseen data. Catastrophic forgetting, where the model loses proficiency in previously learned skills, is another potential risk. Therefore, careful consideration of data selection, model architecture, and regularization techniques are crucial for successful fine-tuning and achieving the desired balance between enhanced performance and robust generalization.
Generalization Limits#
The heading ‘Generalization Limits’ prompts a deep dive into the boundaries of a model’s ability to extrapolate learned skills to unseen situations. A key consideration is compositional generalization, where the model’s capacity to combine previously learned skills in novel ways is examined. This section would likely explore the scenarios where this ability breaks down, perhaps focusing on the complexity of skill combinations or the presence of unseen skill interactions. It may also delve into the data requirements, analyzing how much training data is needed to achieve robust generalization and how the characteristics of the dataset (diversity of skills, distribution of skill combinations) affect the limits. Furthermore, a discussion of the model’s architecture and its inherent inductive biases will likely be included, as these factors significantly influence generalization capabilities. Ultimately, this section would pinpoint the critical factors that constrain a model’s generalization ability, offering insights into the future research directions needed to overcome these limitations and enable more versatile AI systems. The impact of model size and pretraining on generalization would be a major theme, as well as the challenges of evaluating generalization performance effectively.
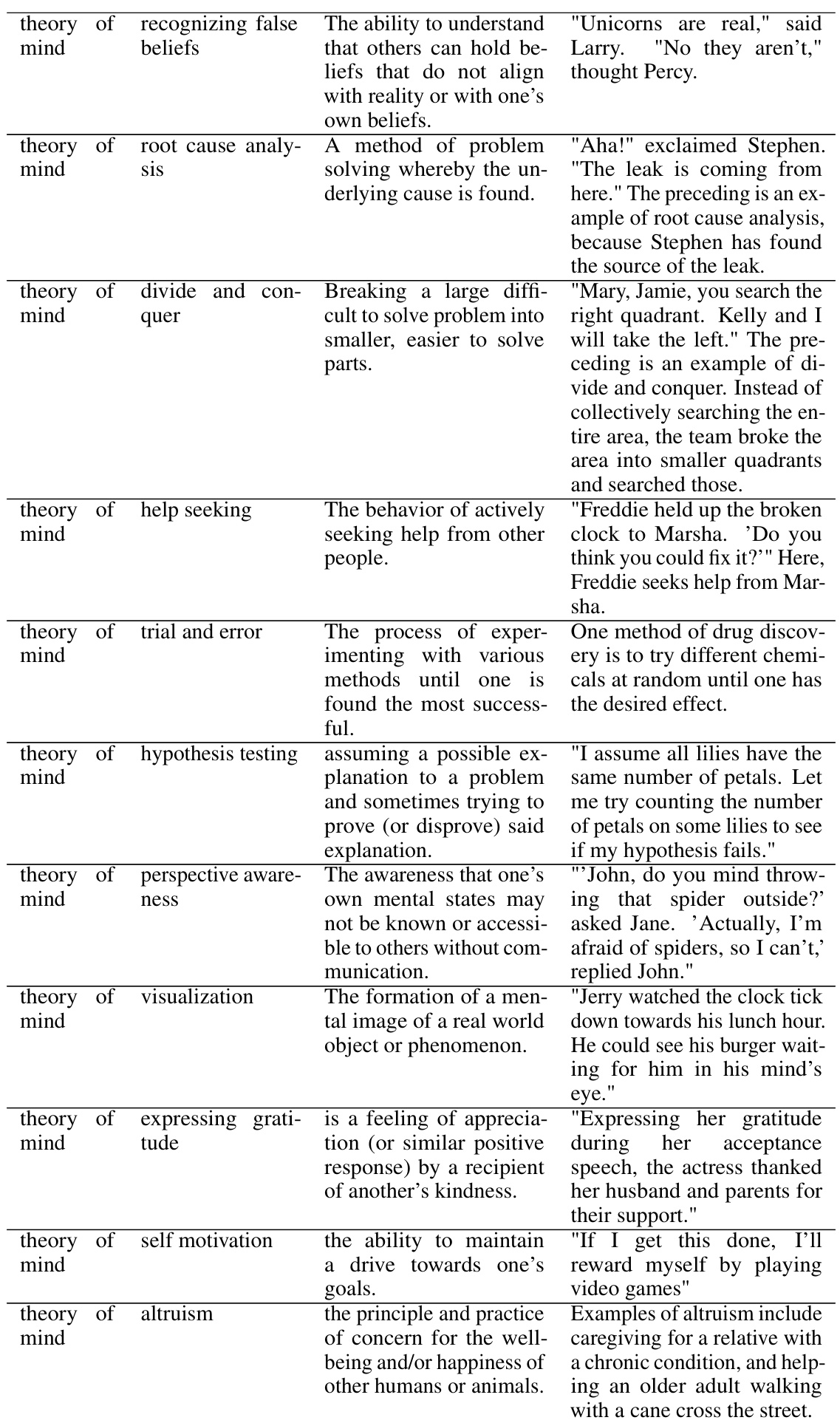
Data Efficiency#
The study reveals crucial insights into data efficiency in achieving compositional generalization. Fine-tuning on a smaller dataset comprising texts with fewer skill combinations (k=1,2,3) demonstrably improves the model’s ability to compose texts with a higher number of skills (k=4,5), even those unseen during training. This suggests that the models are not merely memorizing specific skill combinations but are learning a higher-order, generalizable skill of composition. The inclusion of texts with a larger ‘k’ during fine-tuning proves significantly more data-efficient than using only simpler combinations, highlighting the importance of training data diversity and complexity. These findings challenge existing assumptions about the scaling requirements for compositional generalization and pave the way for more efficient training strategies. The results strongly suggest that carefully curated, skill-rich datasets, even if small, can be exceptionally effective in enhancing model capabilities.
Future Directions#
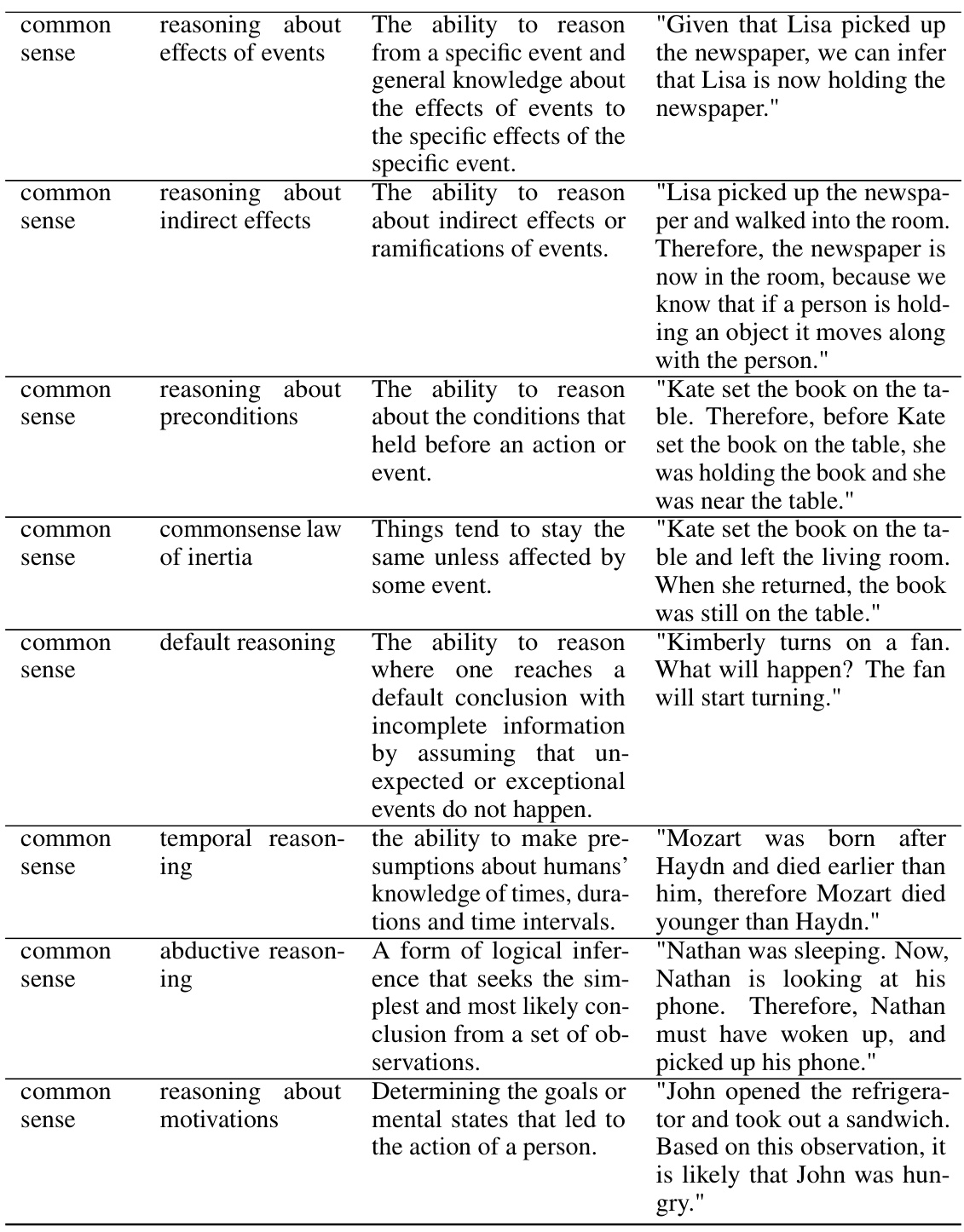
Future research could explore several promising avenues. Expanding the scope of skills beyond those used in the SKILL-MIX evaluation is crucial to assess generalization more broadly. Investigating the impact of training data size and composition on the compositional abilities of smaller models would also refine our understanding. A deeper dive into the interplay between model size and compositional generalization is warranted, especially given the current findings. Exploring alternative training paradigms beyond fine-tuning, perhaps focusing on meta-learning or transfer learning techniques, may lead to significant improvements. Finally, robust evaluation methods are needed to accurately measure compositional generalization across various skill sets and model architectures. This multifaceted approach would solidify our understanding of skill composition and its implications for enhancing LLM capabilities.
More visual insights#
More on figures
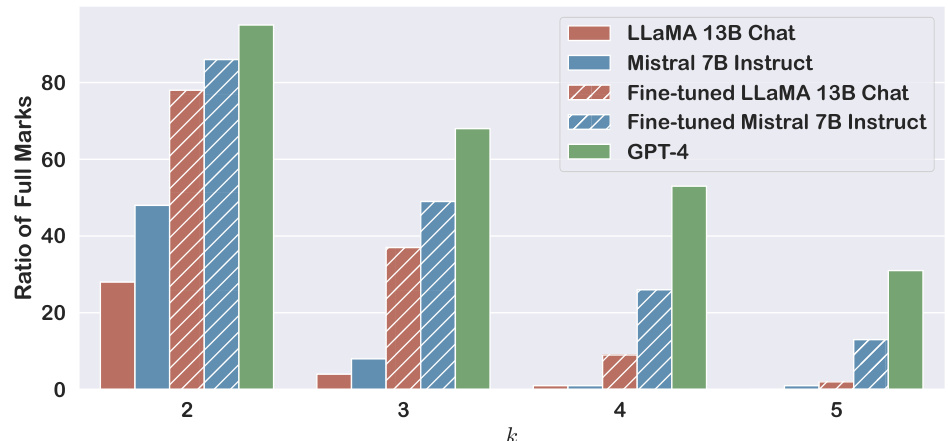
This figure shows the success rate of different language models in composing a short paragraph that demonstrates a given number (k) of skills. The models tested include LLaMA-2-13B-Chat, Mistral-7B-Instruct, and GPT-4. Both the fine-tuned and original versions of LLaMA-2-13B-Chat and Mistral-7B-Instruct are included. The x-axis represents the number of skills (k) to be composed, and the y-axis shows the success rate. The results demonstrate that fine-tuning on examples of composing fewer skills (k=2,3) significantly improves the ability of smaller models to compose a larger number of held-out skills (k=4,5), indicating the models are not simply memorizing specific combinations of skills, but rather have learned a more general ability to compose skills.

This figure illustrates the three-stage pipeline used to evaluate the compositional generalization capability of language models. The pipeline starts by generating training data using GPT-4, ensuring each text contains a combination of up to 3 skills from a training set. Next, smaller language models (LLaMA-2-13B-Chat and Mistral-7B-Instruct-v0.2) are fine-tuned using this data. Finally, the fine-tuned models are evaluated on their ability to compose larger combinations of skills (up to 5) from a held-out set, assessing their capacity for compositional generalization beyond what was seen during training.

This figure illustrates the three-stage pipeline used to evaluate the models’ ability to generalize skill combinations. The process begins by using GPT-4 to generate training data consisting of short texts that demonstrate combinations of up to three skills from a training set. These texts are then used to fine-tune smaller language models (LLaMA-2-13B-Chat and Mistral-7B-Instruct-v0.2). Finally, the fine-tuned models are evaluated on their ability to generate texts demonstrating combinations of up to five skills, including skills not seen during training, thereby assessing compositional generalization.
More on tables
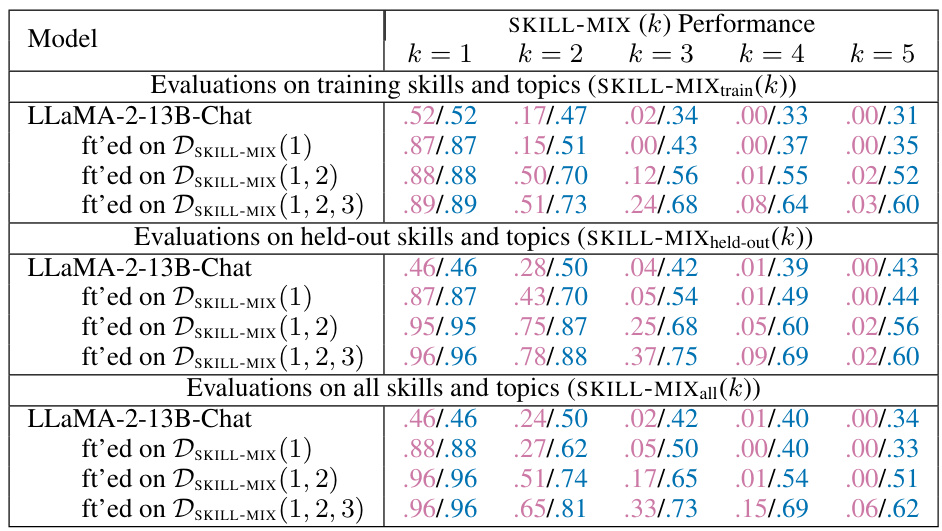
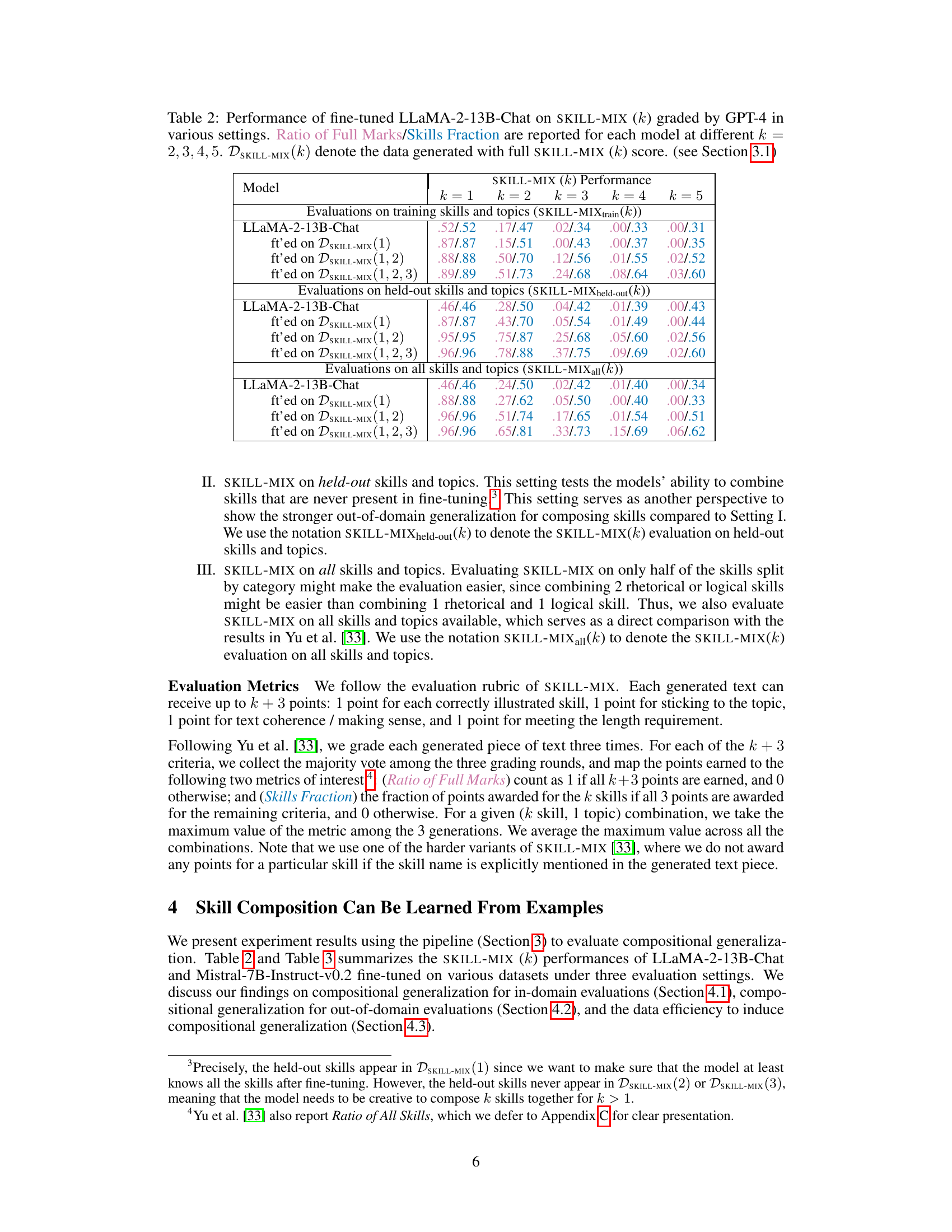
This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. It shows the ‘Ratio of Full Marks’ and ‘Skills Fraction’ for different values of k (number of skills combined), across three evaluation settings: training skills and topics, held-out skills and topics, and all skills and topics. Each setting evaluates the model’s ability to generalize and compose skills under different conditions, highlighting the impact of fine-tuning on held-out skills.
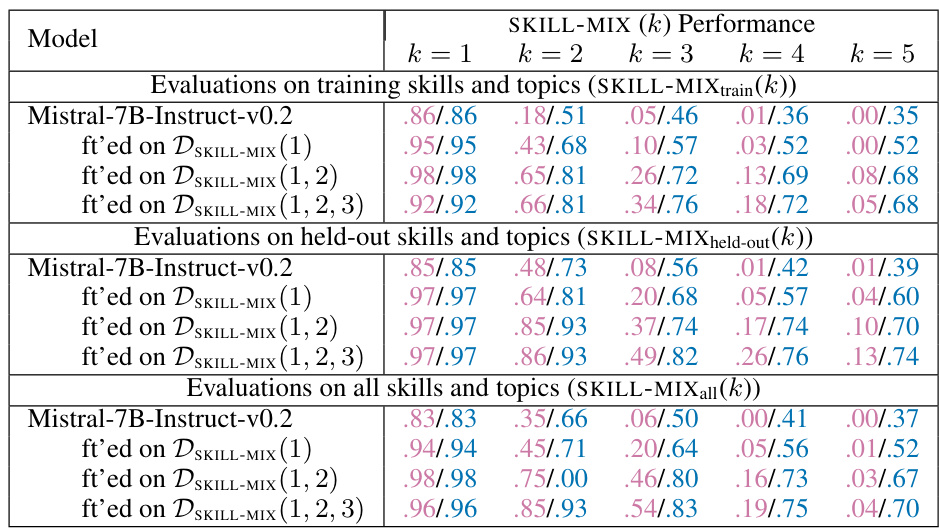
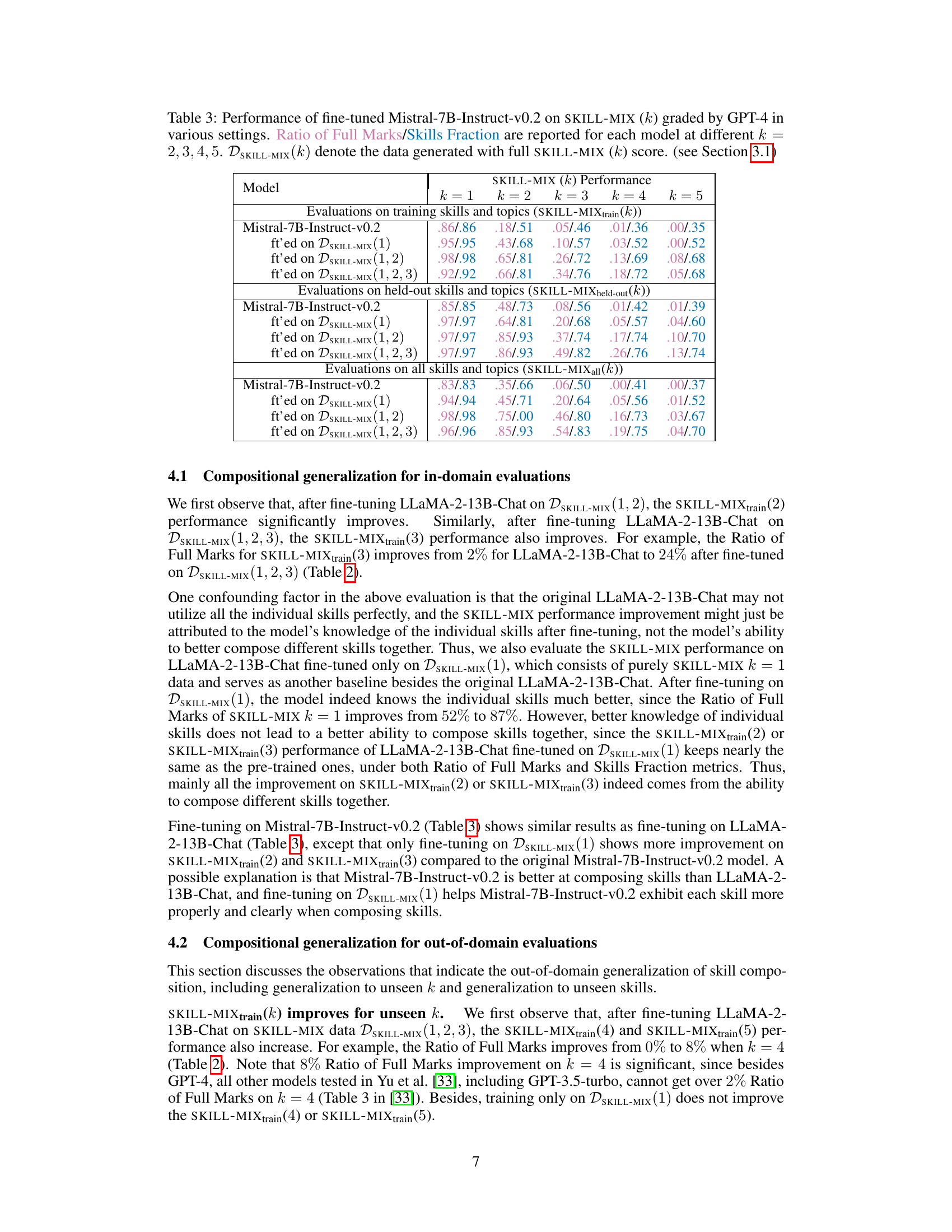
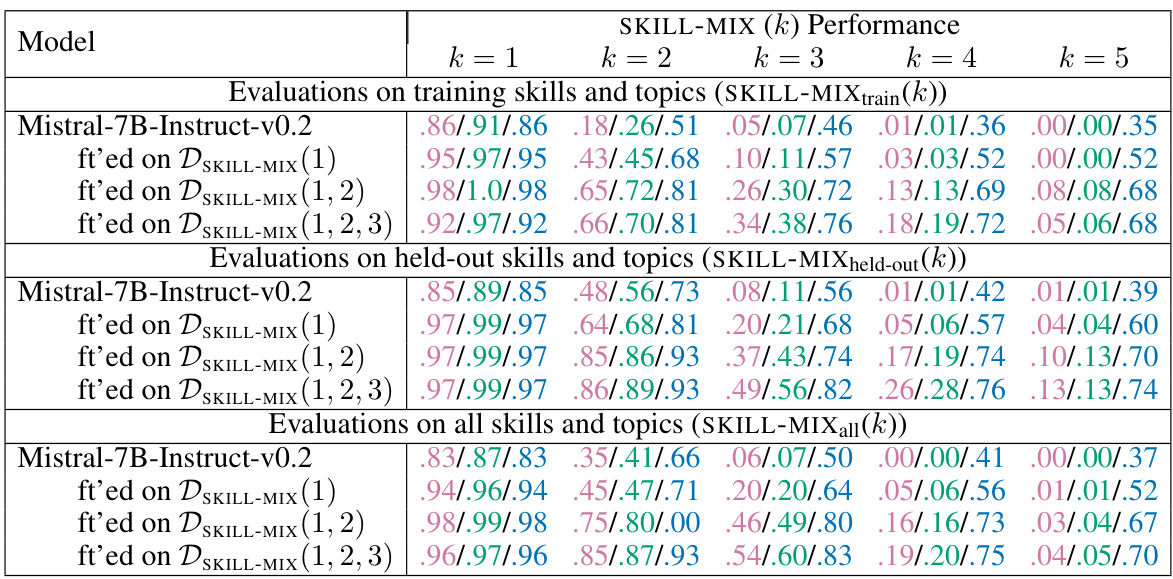
This table presents the results of the Mistral-7B-Instruct-v0.2 model after fine-tuning on different datasets (DSKILL-MIX(1), DSKILL-MIX(1,2), DSKILL-MIX(1,2,3)) evaluated using the SKILL-MIX metric. The performance is measured by the Ratio of Full Marks and Skills Fraction for different numbers of skills (k=2,3,4,5) combined in short paragraphs. The evaluation is conducted across three settings: training skills and topics, held-out skills and topics, and all skills and topics.

This table presents the performance of LLaMA-2-13B-Chat models, fine-tuned on different datasets (combinations of SKILL-MIX data with k=1,2,3), evaluated on the SKILL-MIXall(k) metric (k=2,3,4,5). The performance is measured using the Ratio of Full Marks and Skills Fraction. The table shows the impact of the size and composition of the fine-tuning dataset on the model’s ability to combine k skills. It includes results for a smaller dataset (8000 samples) for comparison.
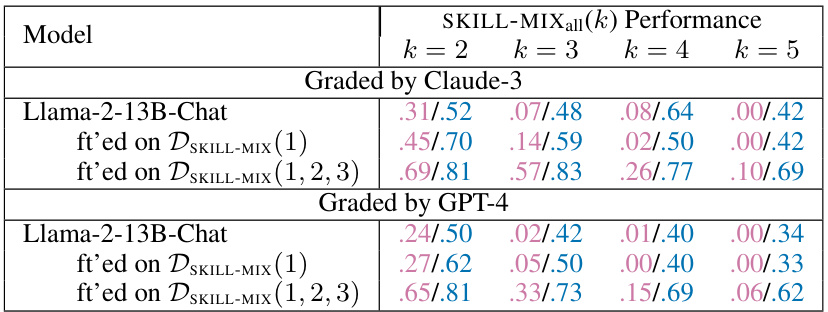
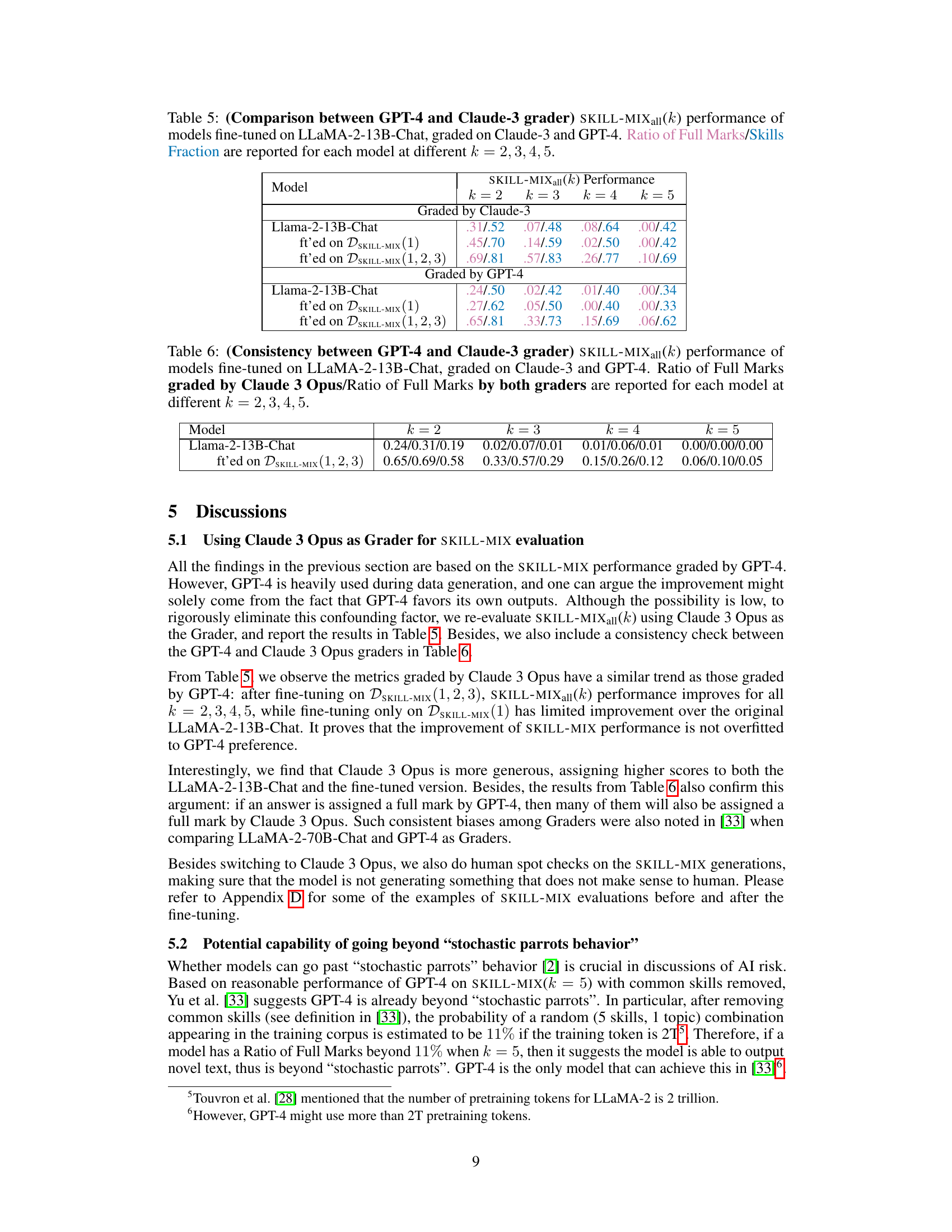
This table presents a comparison of the performance of the fine-tuned Llama-2-13B-Chat model on the SKILL-MIXall(k) evaluation metric (k = 2, 3, 4, 5). The key difference is that the evaluation was performed using two different graders: GPT-4 and Claude-3. This allows for an assessment of the consistency and potential biases introduced by different grading approaches. The table shows the Ratio of Full Marks and Skills Fraction for each model and grader combination.

This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. It shows the ‘Ratio of Full Marks’ and ‘Skills Fraction’ for different values of k (number of skills to combine), across three evaluation settings: training skills and topics, held-out skills and topics, and all skills and topics. Each setting reflects different levels of generalization: in-domain, out-of-domain, and overall generalization. The table helps in understanding how well the model generalizes to unseen skill combinations after fine-tuning on different datasets. The DSKILL-MIX(k) notation refers to the data used for fine-tuning, indicating the level of skill complexity (k) in the training data.
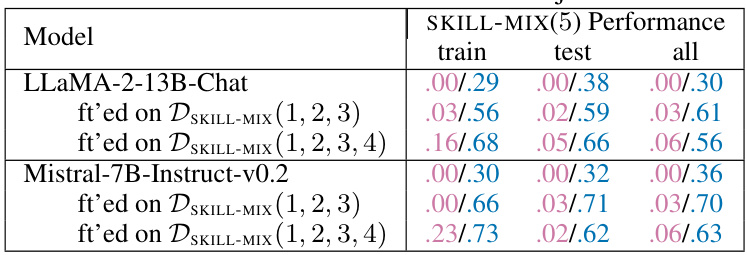
This table presents the results of evaluating the performance of fine-tuned LLaMA-2-13B-Chat and Mistral-7B-Instruct-v0.2 models on the SKILL-MIX(5) task. The evaluation focuses on combinations of uncommon skills (skills with an occurrence rate in the RedPajama dataset of less than 5%). The table displays the Ratio of Full Marks and Skills Fraction for each model under three different evaluation settings: training skills, held-out skills, and all skills. This helps to analyze the models’ ability to generalize skill composition to unseen skills.
This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation metric, graded by GPT-4. It shows the ‘Ratio of Full Marks’ and ‘Skills Fraction’ for different values of k (number of skills combined), across three evaluation settings: training skills and topics, held-out skills and topics, and all skills and topics. Each setting represents a different level of generalization and provides insights into the model’s ability to compose skills, both seen and unseen during training. The table also includes the dataset used for fine-tuning (DSKILL-MIX(k)) which is also defined in Section 3.1 of the paper.
This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. It shows the ‘Ratio of Full Marks’ and ‘Skills Fraction’ for different values of k (number of skills combined), across three evaluation settings: training skills and topics, held-out skills and topics, and all skills and topics. The table also indicates the fine-tuning dataset used for each model (DSKILL-MIX(1), DSKILL-MIX(1,2), DSKILL-MIX(1,2,3)) which varies in the number of skills (k) included in the training data.
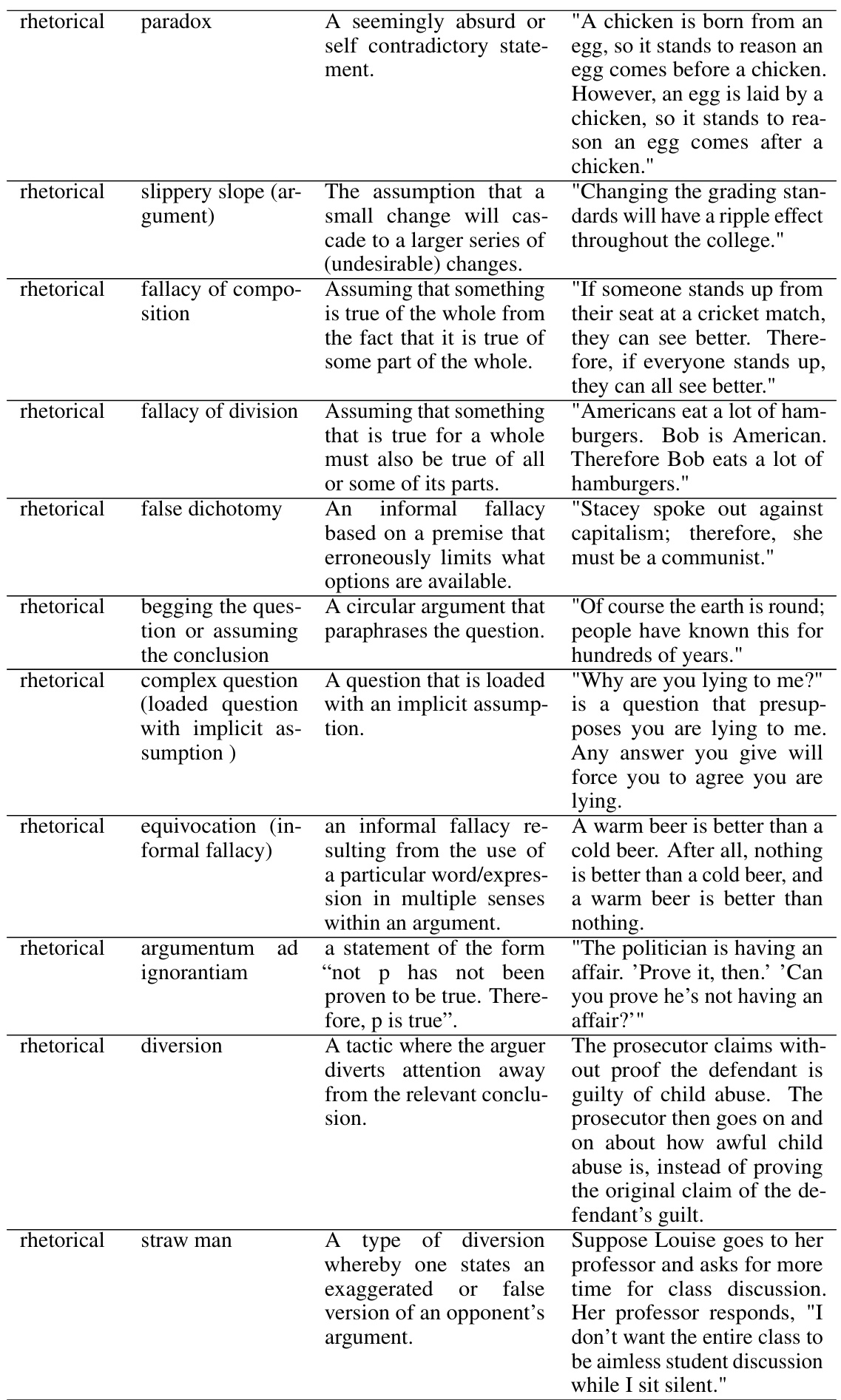
This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. It shows the ‘Ratio of Full Marks’ and ‘Skills Fraction’ for different values of k (number of skills combined), across various settings. The settings include evaluations on training skills and topics, held-out skills and topics, and all skills and topics. The table helps analyze the model’s ability to generalize and compose skills both within and outside of its training data.
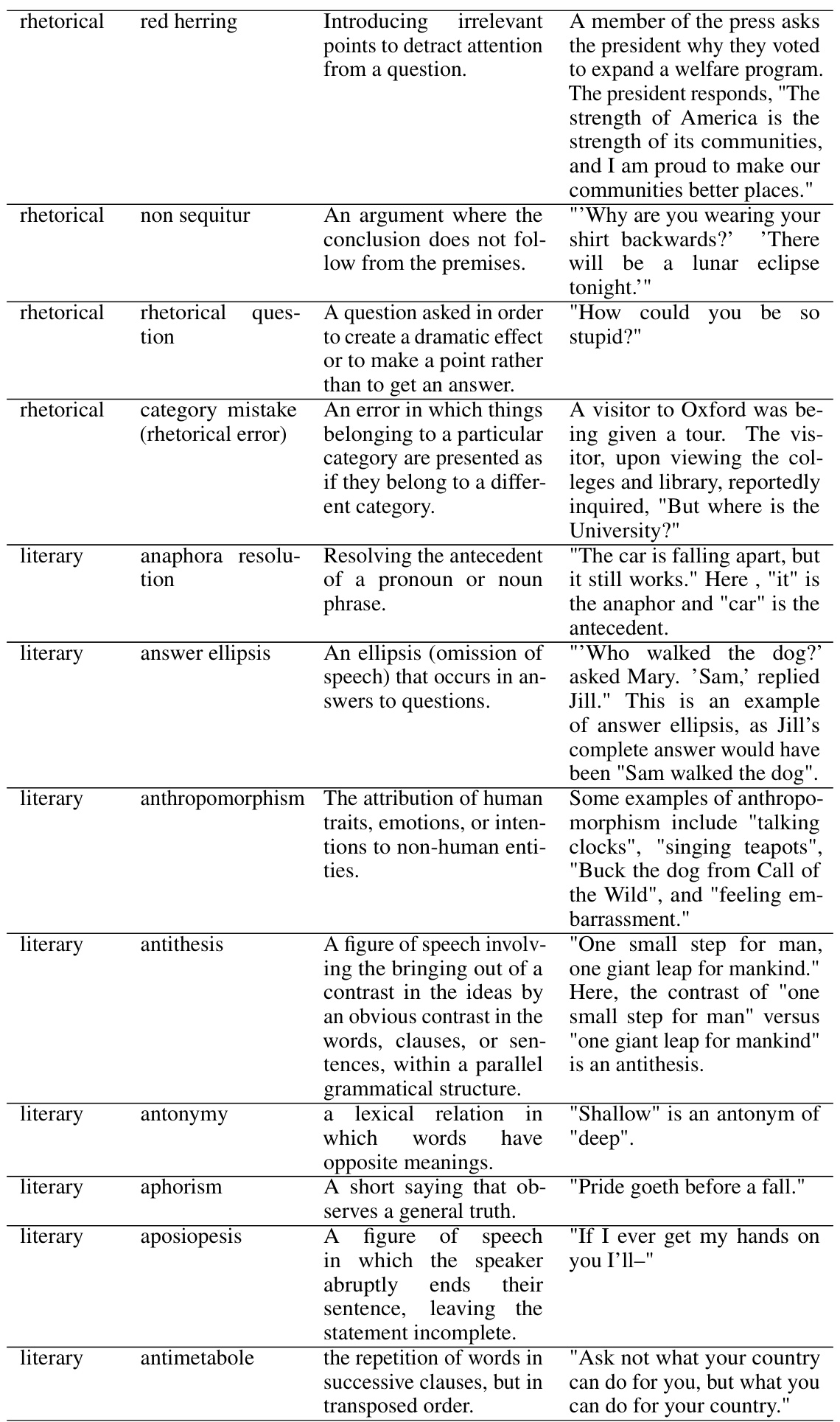
This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. The evaluation assesses the model’s ability to combine k skills (k=2,3,4,5) in various settings. The settings include evaluating the model on the same training skills and topics it was fine-tuned on (in-domain), on held-out skills and topics (out-of-domain), and on all skills and topics. The results are presented as the Ratio of Full Marks and Skills Fraction, which are metrics reflecting the model’s success rate in composing skills. Different datasets (DSKILL-MIX(k)) used for fine-tuning are also indicated.
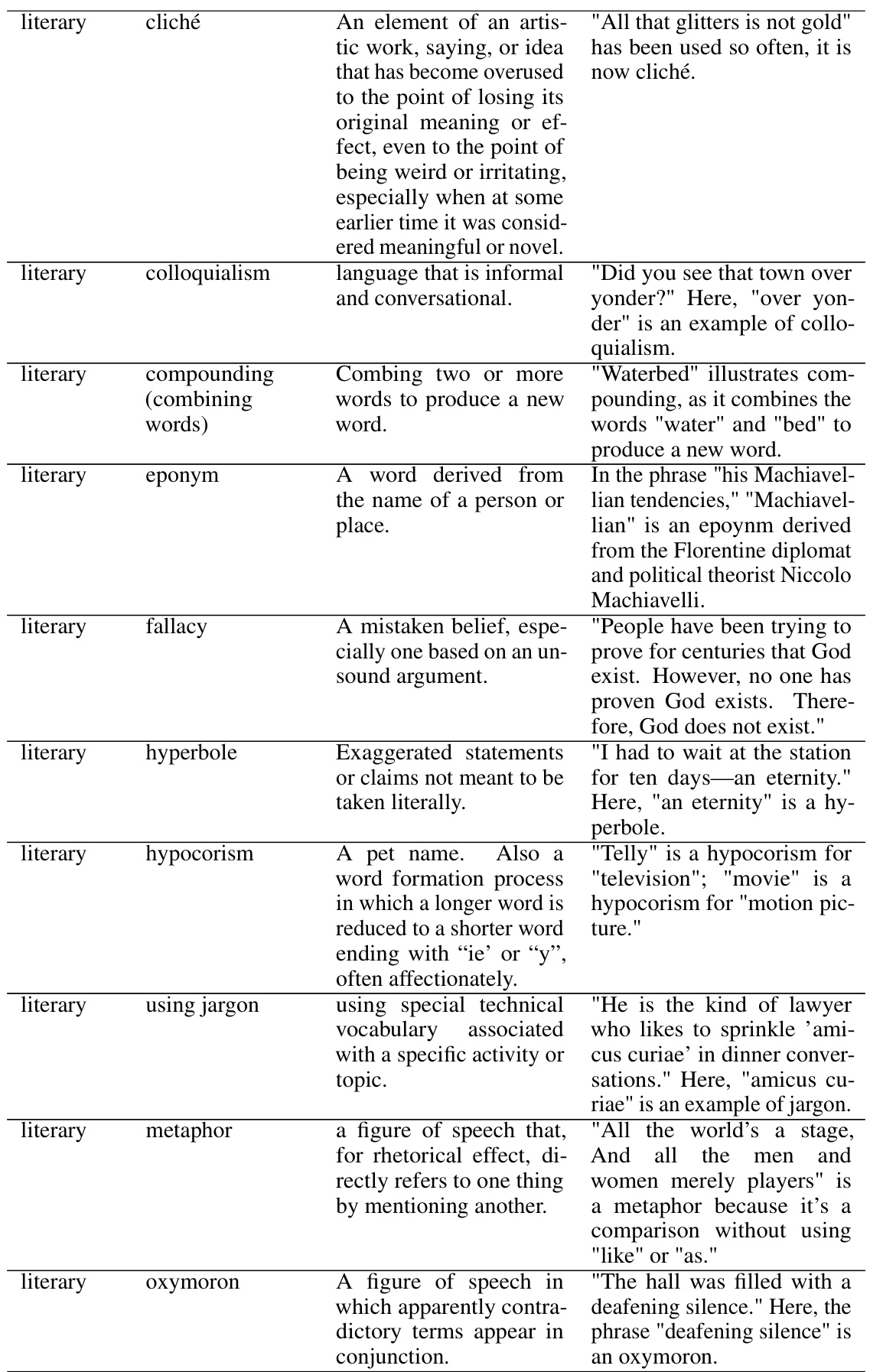
This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. It shows the ‘Ratio of Full Marks’ and ‘Skills Fraction’ for different values of k (number of skills to combine), across three evaluation settings: training skills and topics, held-out skills and topics, and all skills and topics. The data used for fine-tuning is indicated (DSKILL-MIX(1), DSKILL-MIX(1,2), DSKILL-MIX(1,2,3)), allowing for comparison of performance based on different training data. This helps analyze the model’s ability to generalize to unseen skills (held-out) and to combine larger numbers of skills (higher k).
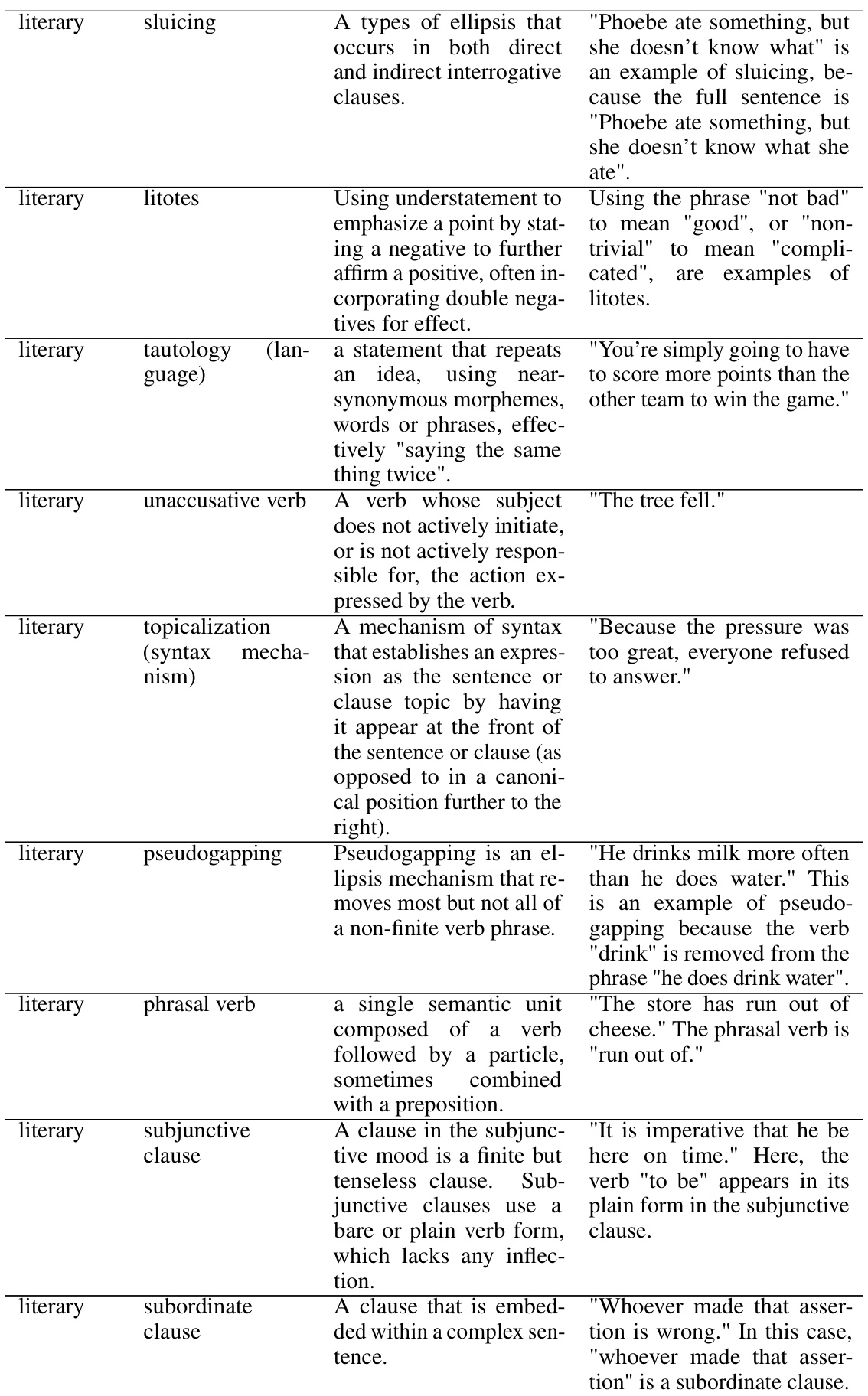
This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. It shows the ‘Ratio of Full Marks’ and ‘Skills Fraction’ for different values of k (number of skills combined), across three evaluation settings: training skills and topics, held-out skills and topics, and all skills and topics. The data used for fine-tuning is indicated (DSKILL-MIX(1), DSKILL-MIX(1,2), DSKILL-MIX(1,2,3)) and allows for comparison of the model’s performance before and after fine-tuning with different datasets. The table helps assess the model’s ability to generalize and compose skills in various contexts.

This table shows the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation for different numbers of skills (k=2, 3, 4, 5) under three different evaluation settings: training skills and topics, held-out skills and topics, and all skills and topics. The performance is measured using two metrics: Ratio of Full Marks and Skills Fraction. The table also shows the model’s performance before and after fine-tuning on different datasets (DSKILL-MIX(1), DSKILL-MIX(1,2), DSKILL-MIX(1,2,3)).
This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. It shows the ‘Ratio of Full Marks’ and ‘Skills Fraction’ for different values of k (number of skills combined), across three evaluation settings: training skills and topics, held-out skills and topics, and all skills and topics. Each setting reflects different levels of generalization, with held-out skills representing a more challenging out-of-distribution test.
This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. It shows the ‘Ratio of Full Marks’ and ‘Skills Fraction’ for different values of k (number of skills to be combined), across three evaluation settings: using training skills and topics, held-out skills and topics, and all skills and topics. Each setting assesses the model’s ability to compose skills under different conditions, revealing its generalization capabilities.
This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. It shows the ‘Ratio of Full Marks’ and ‘Skills Fraction’ for different values of k (number of skills to compose), across three evaluation settings: training skills and topics, held-out skills and topics, and all skills and topics. Each setting evaluates the model’s ability to compose skills in different scenarios, allowing for a comprehensive analysis of its compositional generalization capabilities. The table also references Section 3.1 for details on data generation.

This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. It shows the ‘Ratio of Full Marks’ and ‘Skills Fraction’ for different values of k (number of skills), across three evaluation settings: training skills and topics, held-out skills and topics, and all skills and topics. Each setting further breaks down the results based on which dataset the model was fine-tuned on (DSKILL-MIX(1), DSKILL-MIX(1,2), or DSKILL-MIX(1,2,3)). This allows for a comparison of model performance under different training conditions and shows the impact of fine-tuning on compositional generalization.
This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. It shows the ‘Ratio of Full Marks’ and ‘Skills Fraction’ for different values of k (number of skills), across three evaluation settings: training skills and topics, held-out skills and topics, and all skills and topics. The data used for fine-tuning (DSKILL-MIX(k)) is also specified. The table helps illustrate the impact of fine-tuning on the model’s ability to compose varying numbers of skills, both those seen and unseen during training.

This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. It shows the ‘Ratio of Full Marks’ and ‘Skills Fraction’ for different values of k (number of skills to be composed), across various settings. The settings include evaluations on training skills and topics, held-out skills and topics, and all skills and topics. The table helps to analyze the model’s ability to generalize compositional skills learned during training to unseen skill combinations. Different fine-tuning datasets (DSKILL-MIX(1), DSKILL-MIX(1,2), DSKILL-MIX(1,2,3)) are compared to understand the impact of training data richness on compositional generalization.

This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. The evaluation was performed across different settings (training, held-out, and all skills/topics) and varying numbers of skills (k=2,3,4,5). The results are shown as the ‘Ratio of Full Marks’ and ‘Skills Fraction’, reflecting the model’s success in composing the specified skills. DSKILL-MIX(k) refers to the dataset generated with full scores on the SKILL-MIX(k) evaluation. Section 3.1 provides more details about the data generation process.
This table presents the performance of the fine-tuned LLaMA-2-13B-Chat model on the SKILL-MIX evaluation, graded by GPT-4. It shows the ‘Ratio of Full Marks’ and ‘Skills Fraction’ for different values of k (number of skills to combine), across three evaluation settings: training skills and topics, held-out skills and topics, and all skills and topics. The table allows comparison of the model’s performance before and after fine-tuning on different datasets (DSKILL-MIX(1), DSKILL-MIX(1,2), DSKILL-MIX(1,2,3)). It helps to analyze the model’s ability to generalize to unseen skills and the impact of training data on its compositional generalization capabilities.
Full paper#