↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current few-shot fine-tuning methods for text-to-image models suffer from content leakage, where unwanted elements from the style reference image appear in generated images. This limits precise style control. Additionally, existing methods often require extensive prompt engineering or iterative fine-tuning, increasing costs and complexity.
FineStyle tackles these issues with a novel two-pronged approach. First, it uses concept-oriented data scaling, decomposing a single style reference image into multiple concept-focused sub-images to expand training data. Second, it utilizes parameter-efficient adapter tuning to directly modify key and value kernels within cross-attention layers, enhancing style control while maintaining efficiency. Experimental results demonstrate FineStyle’s superior performance in both fine-grained control and visual quality compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on text-to-image generation and style transfer. It presents FineStyle, a novel approach that significantly enhances the controllability and quality of style personalization in text-to-image models. This addresses the significant challenge of content leakage in few-shot fine-tuning. The method’s efficiency and effectiveness make it particularly relevant in the context of limited data and computational resources, opening new avenues for personalized image generation.
Visual Insights#
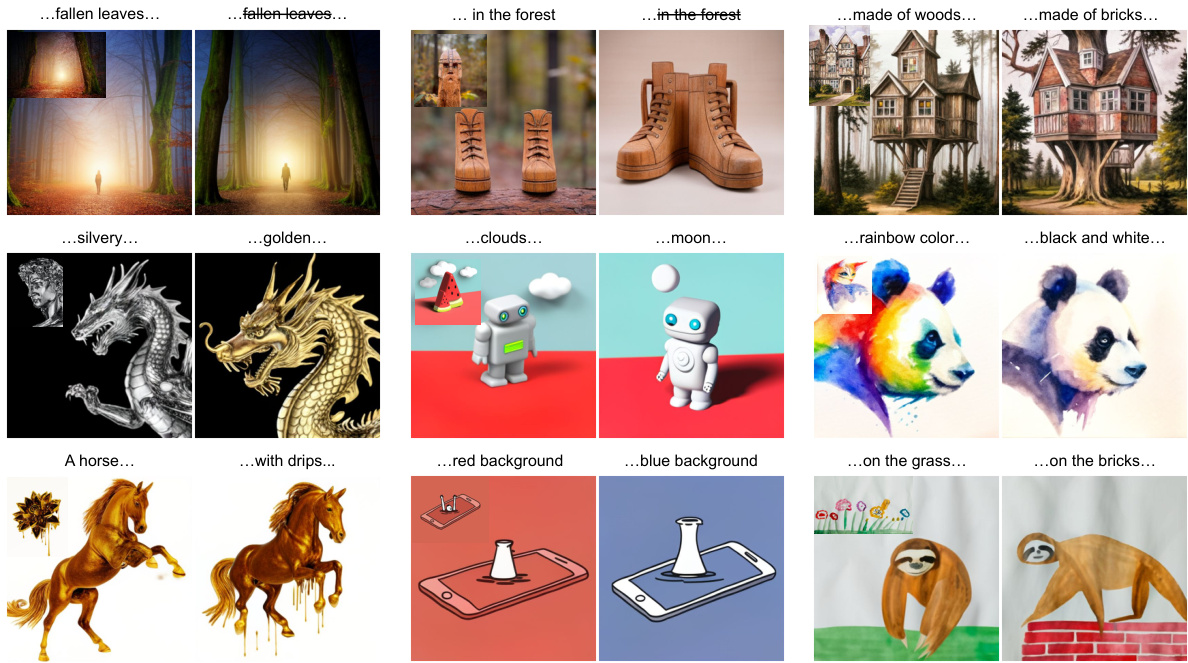
This figure shows nine pairs of images generated by FineStyle, a personalized text-to-image model. Each pair demonstrates the model’s ability to control various fine-grained style aspects, such as color, object placement, background, and texture. The left image in each pair shows the style reference image that the model was fine-tuned on.
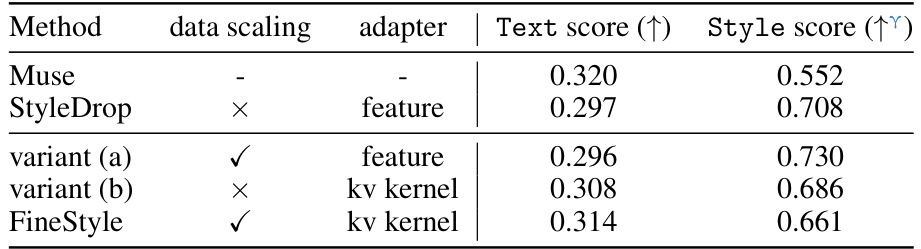
This table presents the CLIP scores (a metric evaluating the quality of image generation) for four different models: Muse (baseline), StyleDrop (a state-of-the-art method), two variants of FineStyle (with and without data scaling), and FineStyle itself. The scores are separated into Text score (measuring how well the generated image matches the given text prompt) and Style score (measuring how well the generated image matches the style of a reference image). The table aims to showcase FineStyle’s superior performance by achieving a better balance between text and style fidelity.
In-depth insights#
FineStyle: Intro#
FineStyle: Intro would ideally delve into the core motivation and problem statement. It should clearly articulate the limitations of existing text-to-image models regarding fine-grained style control, emphasizing the content leakage issue where unwanted visual elements from a reference image seep into generated outputs. The introduction would then position FineStyle as a solution, highlighting its novel approach to achieve fine-grained style control using a few-shot fine-tuning method, thereby overcoming the shortcomings of previous methods. It would also briefly introduce the core concepts: concept-oriented data scaling and parameter-efficient adapter tuning, positioning them as key components enabling enhanced style control and efficiency. Finally, the introduction should offer a concise overview of the paper’s structure, guiding the reader through the key sections and their contributions.
Concept-Oriented Scaling#
Concept-oriented scaling is a data augmentation technique in the context of few-shot learning for text-to-image models. It cleverly addresses the scarcity of training data by decomposing a single reference image into multiple concept-focused sub-images, each paired with a corresponding concise textual description. This decomposition amplifies the training data, effectively providing more examples for the model to learn fine-grained style attributes. Rather than relying solely on one image-text pair, this approach leverages the inherent compositionality of style within the reference image, creating synthetic data that captures distinct visual elements. The key advantage is enhanced controllability in generating images that are faithful to specific style characteristics mentioned in prompts. This is particularly relevant to text-to-image models which often struggle with fine-grained style control due to the limited amount of available data during personalized training. The method tackles the issue of content leakage, a common problem with simple few-shot fine-tuning methods, by directing the model’s attention to specific concepts rather than the entire image, improving the model’s ability to focus on desired attributes and minimizing the influence of unintended visual cues.
PEFT Adapters#
Parameter-Efficient Fine-Tuning (PEFT) adapters are crucial for adapting large language models (LLMs) like those used in text-to-image synthesis. They offer a compromise between full fine-tuning and simpler methods like prompt engineering. Instead of retraining the entire model, PEFT strategically modifies specific layers, often focusing on attention mechanisms, with a smaller set of trainable parameters. This approach significantly reduces computational costs and memory requirements, making it feasible to personalize models without extensive resources. The effectiveness of PEFT adapters, especially when applied to cross-attention layers, is highlighted in the context of style transfer. By fine-tuning these layers, the model learns to better associate text descriptions with specific visual styles, resulting in improved control over image generation. Careful placement of these adapters within the network architecture is key to optimizing performance; placing them in cross-attention layers enables precise style control while mitigating unwanted content leakage. However, challenges remain, including the potential for overfitting with limited data and the need for careful hyperparameter tuning to balance style fidelity and semantic consistency.
Style Control#
The concept of ‘Style Control’ in the context of text-to-image models is crucial, signifying the ability to manipulate the generated image’s aesthetic qualities according to user specifications. Fine-grained style control is particularly important, allowing for nuanced adjustments beyond broad style categories. The paper likely explores methods to achieve this, potentially through techniques like fine-tuning models on specific style reference images or incorporating style-specific parameters into the generation process. Challenges in this area likely involve disentangling style from content, preventing unwanted style leakage, and ensuring consistent style application across diverse prompts. Effective strategies might include employing parameter-efficient fine-tuning methods to avoid overfitting, leveraging concept-oriented data scaling for improved alignment of visual concepts and textual descriptions, or using attention mechanisms to carefully regulate style features within the generated output. The ultimate goal is to enable precise, user-defined control, translating natural language descriptions into highly tailored visual aesthetics with minimal human intervention.
Future Work#
Future research directions stemming from this work could involve exploring alternative data augmentation strategies beyond the concept-oriented approach, potentially enhancing performance with more diverse and robust training data. Investigating different adapter architectures and placement within the transformer network might reveal further improvements in style control and efficiency. A key area for expansion is improving the scalability of FineStyle to handle significantly larger datasets and more complex styles, enabling broader application. Furthermore, exploring applications beyond image generation, such as video or 3D model generation, leveraging the method’s fine-grained style control, warrants exploration. Finally, a thorough investigation into mitigating potential biases present in style reference images and the impact on generated output is crucial for responsible development.
More visual insights#
More on figures

This figure compares the results of StyleDrop and FineStyle models when generating images of sneakers. StyleDrop, a state-of-the-art model, suffers from content leakage, generating images that include elements from the style reference image (spindle leaves) that are not specified in the text prompt. FineStyle, in contrast, mitigates this leakage by focusing on the desired style attributes, resulting in images that are more faithful to the prompt while maintaining the style.

This figure illustrates the FineStyle framework. It shows how a single style image and its corresponding text prompt are decomposed into multiple concept-oriented sub-image-text pairs. This concept-oriented data scaling increases the amount of training data for fine-tuning. The figure also highlights the use of parameter-efficient adapter tuning applied to the key and value kernels of cross-attention layers within the transformer blocks. The overall process enhances controllability for style-personalized text-to-image generation.

This figure showcases FineStyle’s ability to control style in text-to-image generation. Nine pairs of images demonstrate how fine-tuning on a single style image allows for precise control over various aspects like color, objects, background, and texture. Each pair highlights a specific style attribute.
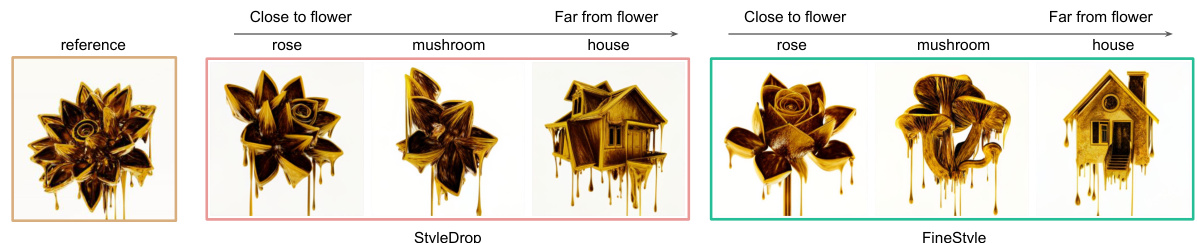
This figure compares the performance of StyleDrop and FineStyle models in generating images with a specific style (‘melting golden 3d rendering’) when the subject’s semantic similarity to the reference image (a flower) varies. The x-axis represents the semantic distance from the reference image (flower), ranging from close (rose, mushroom) to far (house). The results show that StyleDrop struggles to maintain style consistency when the subject is semantically close to the reference, whereas FineStyle better preserves the style across different subjects with varying semantic distances.

This figure shows nine pairs of images generated by FineStyle, a personalized text-to-image model. Each pair demonstrates the model’s ability to control various fine-grained style aspects, such as color, background, and texture, based on a single reference image. The fine-grained control is showcased through textual descriptions overlaid on the images, highlighting the model’s nuanced compositionality.

This figure demonstrates the controllable reference image variation of FineStyle. It shows a series of images generated using different prompts, all based on a reference image similar to Van Gogh’s ‘The Starry Night’. The variations highlight FineStyle’s ability to control the presence or absence of specific elements (trees, mountains, a village) within the generated image while maintaining the overall style.
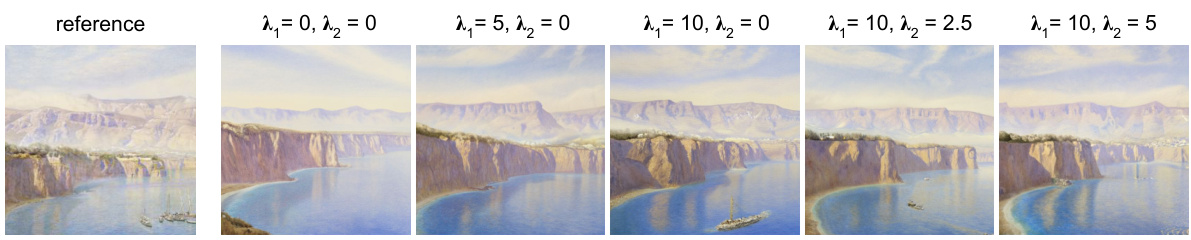
This figure demonstrates the impact of hyperparameters λ₁ and λ₂ on the generated image’s fidelity to both style and semantic content. λ₁ controls the strength of the style, while λ₂ controls the strength of the semantic content from the prompt. As λ₁ increases, the image increasingly reflects details from the style reference image, potentially leading to unwanted style leakage (like the boats). Increasing λ₂ counteracts this leakage by better aligning the generated image with the specified semantic content of the prompt, resulting in a more balanced image.

This figure shows nine pairs of images generated by FineStyle, a personalized text-to-image model. Each pair demonstrates the model’s ability to control various fine-grained aspects of image style, such as color, background, and texture, based on a single reference image. The differences between the image pairs highlight the level of style control offered by FineStyle.

This figure shows nine pairs of images generated by FineStyle, a personalized text-to-image model. Each pair demonstrates the model’s ability to control various fine-grained style aspects, such as color, object placement, background, and texture. The left image in each pair shows the generated image, and the right image is a comparison, highlighting the controlled aspects of the generated image. The style of each generated image is determined by a single reference image, which is shown in the corner of the left image in each pair.

This figure showcases the fine-grained control over style offered by the FineStyle model. Nine pairs of images demonstrate how the model, personalized with a single reference image, generates images with various controlled stylistic elements (color, objects, background, texture). Each pair highlights a specific stylistic concept.

This figure shows nine pairs of images generated by FineStyle, a personalized text-to-image model. Each pair demonstrates the model’s ability to control fine-grained style aspects, such as color, objects, background, and texture, based on a single reference image. The reference image is shown in the corner of the left image in each pair. The fine-grained style concepts are overlaid on the generated images for comparison.

This figure shows nine pairs of images generated by FineStyle, a personalized text-to-image model. Each pair demonstrates the model’s ability to control various fine-grained style aspects, such as color, background, object features and texture, based on a single reference image. The differences between the image pairs highlight the level of control offered by FineStyle.

This figure showcases the fine-grained control offered by FineStyle over the style of images generated by personalized text-to-image models. Nine pairs of images are shown; each pair demonstrates how a single style image influences the generated image, highlighting control over color, foreground object, background, and texture.

This figure shows nine pairs of images generated by FineStyle, a personalized text-to-image model. Each pair demonstrates the model’s ability to control various fine-grained style aspects such as color, object placement, background, and texture. The left image of each pair shows the generated image, and the right image shows a similar image without the fine-grained style controls applied.
This figure showcases the fine-grained style control offered by FineStyle. Nine pairs of images demonstrate how the model, fine-tuned on a single style image, generates images according to specific, nuanced prompts. Each pair highlights the impact of factors such as color, foreground object, background, and texture.

This figure showcases FineStyle’s ability to control image generation styles with high granularity. Nine pairs of images demonstrate how fine-tuning on a single style reference image enables control over various aspects, including color, foreground objects, background, and texture. Each pair highlights a specific stylistic element, allowing for a nuanced comparison of FineStyle’s capabilities.

This figure showcases the fine-grained style control offered by FineStyle. Nine pairs of images are presented; each pair shows an image generated by a model fine-tuned on a specific style image (shown in the corner). The image pairs highlight the model’s ability to control various stylistic elements, such as color, the main object, background, and texture, demonstrating the nuanced control over style.

This figure showcases the fine-grained controllability of FineStyle in generating images. Nine pairs of images are shown, each pair demonstrating the influence of fine-tuning on a single style reference image. The fine-tuning allows for control over aspects like color, foreground objects, background, and texture, highlighting the model’s ability to capture nuanced stylistic details.

This figure compares the image generation results of FineStyle against several baseline methods (StyleDrop, StyleAligned, and IP-Adapter) across five different styles. Each row shows a prompt, the style reference image, and the outputs from each model. The goal is to demonstrate FineStyle’s superior performance in preventing ‘content leakage.’ Content leakage refers to undesired elements from the style image appearing in generated images, even when those elements are not mentioned in the prompt. The ‘Unwanted concepts’ column lists elements present in the style image’s training data but not included in the image generation prompt—highlighting FineStyle’s success in producing cleaner, more faithful results to the prompt alone.

This figure shows nine pairs of images generated by FineStyle, a personalized text-to-image model. Each pair demonstrates the model’s ability to control fine-grained style aspects like color, background, and texture. The left image of each pair shows the style reference image that was used for fine-tuning the model.

This figure demonstrates FineStyle’s ability to precisely control style attributes. Panel (a) shows how omitting or adding words related to a specific style element (drips) leads to changes in the generated image’s drips. The changes are subtle but noticeable, showcasing the fine-grained control. Panel (b) shows that FineStyle can control multiple style elements simultaneously, unlike other methods that struggle with such compositionality. The images highlight FineStyle’s ability to handle complex style combinations with accuracy.

This figure shows nine pairs of images generated using FineStyle, a personalized text-to-image model. Each pair demonstrates the model’s ability to control fine-grained style aspects like color, background, and texture. The left image in each pair shows the style reference image used for fine-tuning.

This figure illustrates the FineStyle framework’s workflow. It starts with a single style image and its text description, decomposes it into multiple concept-oriented sub-image-text pairs, and uses a parameter-efficient adapter to fine-tune the key and value kernels of the transformer blocks. The concept-oriented data scaling method amplifies training data by creating multiple sub-prompts focusing on individual concepts within the style reference image. Cross-attention maps help identify the spatial locations of these concepts.

This figure demonstrates FineStyle’s ability to control specific style attributes. In (a), the model modifies the style of melting drips by omitting or adding decorative elements. The results show that FineStyle can precisely control the style of these fine-grained elements, even with limited visual representation. (b) shows the model’s capability to control multiple fine-grained styles simultaneously. This further highlights the model’s enhanced control over styles due to its fine-grained concept alignment.

This figure showcases FineStyle’s ability to control image generation styles with precision. Nine pairs of images are shown, each pair generated from the same text prompt but with different styles. The left image in each pair shows the style reference image used in training, highlighting FineStyle’s fine-grained control over color, objects, background, and texture.
More on tables

This table presents the CLIP scores for image-text similarity (Text) and image-image similarity (Style) for different methods: Muse, StyleDrop, and two variants of FineStyle (with and without data scaling and different adapter locations). It shows the performance of FineStyle and its variants in balancing the trade-off between text and style scores in image generation, indicating that FineStyle provides the best overall performance.

This table presents the hyperparameters used for the optimizer (Adam), adapter architecture, and image synthesis process in both FineStyle and StyleDrop. It details the learning rate, batch size, number of training steps, projection dimension (d_prj), whether adapter parameters are shared, the total number of adapter parameters, the number of decoding steps, temperature, and the lambda values (λ1, λ2, λmuse) used for classifier-free guidance. These settings are crucial in controlling the model’s training and image generation behavior, highlighting the differences in approach between FineStyle and StyleDrop.
Full paper#