↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Worldwide image geolocalization is challenging due to difficulties in capturing location-specific visual semantics and handling the uneven global distribution of image data. Existing methods struggle to accurately pinpoint locations, often confusing visually similar but geographically distant images or failing to adapt to diverse regions with limited data. This creates significant limitations when scaling these methods globally.
The researchers introduce G3, a new framework that tackles these challenges head-on. G3 uses Retrieval-Augmented Generation (RAG), incorporating a novel Geo-alignment step to jointly learn multi-modal representations of images, GPS coordinates, and textual descriptions, enabling more precise location-aware semantic understanding. Additionally, G3 employs Geo-diversification and Geo-verification to improve robustness and accuracy. The superior performance of G3 on benchmark datasets, along with the release of a new, improved dataset (MP16-Pro), marks a substantial contribution to the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and geographic information retrieval due to its novel approach to worldwide image geolocalization. It introduces G3, a robust framework that surpasses existing methods by effectively combining retrieval and generation techniques, addressing the challenges of visual semantic capture and heterogeneous geographical data distribution. The proposed multi-modality model and dataset advance the field significantly, offering promising avenues for future research and real-world applications.
Visual Insights#

This figure illustrates the challenges in worldwide image geolocalization. (a) shows the overall task: given a query image, pinpoint its location on the globe. (b) highlights the difficulty of extracting location-aware visual semantics, as visually similar images can be geographically distant. (c) emphasizes the challenge of image heterogeneity, where the geographical distribution of training data is uneven, impacting the performance of existing methods.
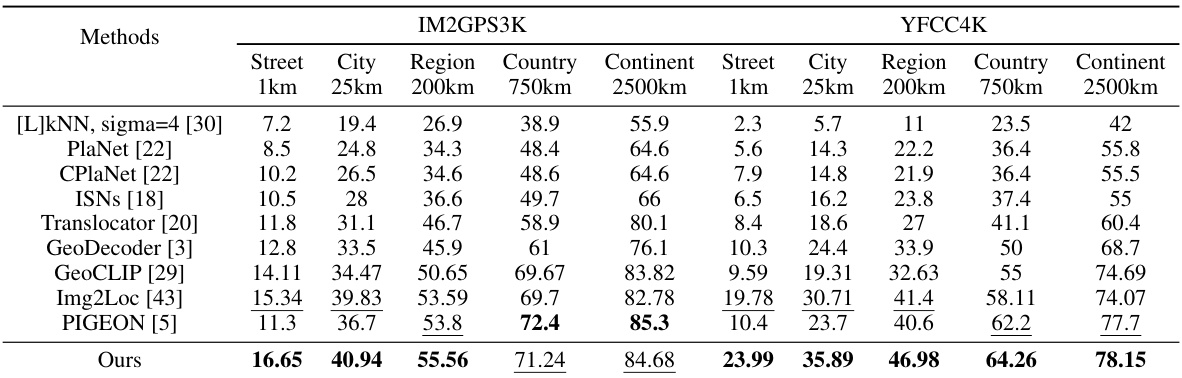
This table presents a comparison of the proposed G3 model’s performance against several state-of-the-art image geolocalization methods on two benchmark datasets, IM2GPS3K and YFCC4K. The results are shown for various geographic granularities (street, city, region, country, continent), with the performance measured as the percentage of predictions within a certain distance threshold (1km, 25km, 200km, 750km, 2500km) of the ground truth location. This provides a comprehensive evaluation of G3’s accuracy and robustness across different scales and geographic regions.
In-depth insights#
Multimodal Geolocation#
Multimodal geolocation represents a significant advancement in location identification by integrating diverse data sources. Combining visual information from images with other modalities, such as GPS data, textual descriptions, and even sensor data, enhances accuracy and robustness, especially in challenging environments. This approach addresses limitations of unimodal methods that rely solely on visual features, which can be ambiguous or easily confused across various locations. The fusion of modalities improves the model’s understanding of context and location-specific characteristics, leading to more precise and reliable geolocation. While the challenges of data heterogeneity and the need for large, diverse datasets remain, the potential for multimodal geolocation to revolutionize location-based services and applications is vast. Further research should focus on developing more sophisticated fusion techniques and exploring novel modalities to further boost performance and handle increasingly complex scenarios.
RAG Framework#
The core of this research paper centers on a novel Retrieval-Augmented Generation (RAG) framework for worldwide image geolocalization. This framework, unlike previous methods, directly addresses the challenges of diverse visual semantics and heterogeneous geographic data distribution. Geo-alignment is a crucial component, jointly learning multi-modal representations for images, GPS coordinates, and textual descriptions to capture location-aware semantics for more effective image retrieval. Geo-diversification enhances robustness by employing prompt ensembling to handle inconsistent retrieval performance across different queries. This method generates diverse prediction candidates using varying numbers of retrieved GPS coordinates as input prompts. Finally, Geo-verification combines these generated candidates with retrieved candidates to make the final location prediction. The integration of these three steps is what makes this RAG framework effective, robust, and adaptive for worldwide geolocalization tasks.
Geo-Diversification#
The proposed Geo-Diversification method is a crucial component of the G3 framework, designed to enhance the robustness of worldwide image geolocalization. The core idea is to mitigate the inconsistent retrieval performance across diverse image queries by generating a diverse set of predictions using multiple retrieval-augmented prompts. This approach acknowledges that the effectiveness of retrieval-based methods may vary significantly across different image queries, influenced by factors such as image content and geographical location. Instead of relying on a fixed number of references, as typically done in other RAG-based methods, Geo-Diversification dynamically adapts to each query’s characteristics. This adaptability is achieved by employing prompt ensembling, where several prompts are constructed and subsequently processed by the language model to produce a broader range of GPS candidates. By combining these diverse predictions from multiple prompts, Geo-Diversification strengthens the overall prediction accuracy. This is particularly valuable in a worldwide context where retrieval may be unreliable for certain areas with limited or inconsistent image data. The method implicitly handles heterogeneity in the image data, a major challenge in worldwide geolocalization, by ensuring the model can work effectively even when a query image’s retrieval fails to produce sufficiently similar references.
MP16-Pro Dataset#
The creation of the MP16-Pro dataset represents a significant contribution to the field of image geolocalization. By augmenting the existing MP16 dataset with rich textual geographical descriptions obtained from Nominatim, MP16-Pro enhances the multi-modality aspect of the data, allowing for more robust and accurate model training. This addition of textual context, encompassing various geographical scales from neighborhood to continent, addresses the limitations of previous methods that relied primarily on visual and GPS data. This move directly tackles the challenge of representing geographical proximity in a world with diverse and heterogeneous visual features. The inclusion of MP16-Pro therefore improves the ability to learn expressive location-aware semantics and significantly boosts the performance of geolocalization models, especially in the context of worldwide geolocalization where variations in geography and visual appearance are significant. The availability of MP16-Pro for future research thus greatly accelerates advancements in this challenging area.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Improving the robustness and efficiency of the Geo-diversification module is crucial; current methods, while effective, are computationally expensive. Investigating more efficient prompt generation strategies or alternative methods for integrating diverse information sources could significantly enhance scalability and speed. Another key area involves exploring the limits of the multi-modality approach, particularly concerning the impact of different multimodal model architectures and training data on worldwide geolocalization accuracy. The dataset MP16-Pro, while an improvement, could benefit from further expansion and annotation, potentially incorporating diverse visual and textual features. This would allow for more comprehensive evaluation and the development of more robust, generalized models. Finally, applying the proposed framework to other related tasks such as video geolocalization or large-scale scene understanding offers exciting possibilities.
More visual insights#
More on figures
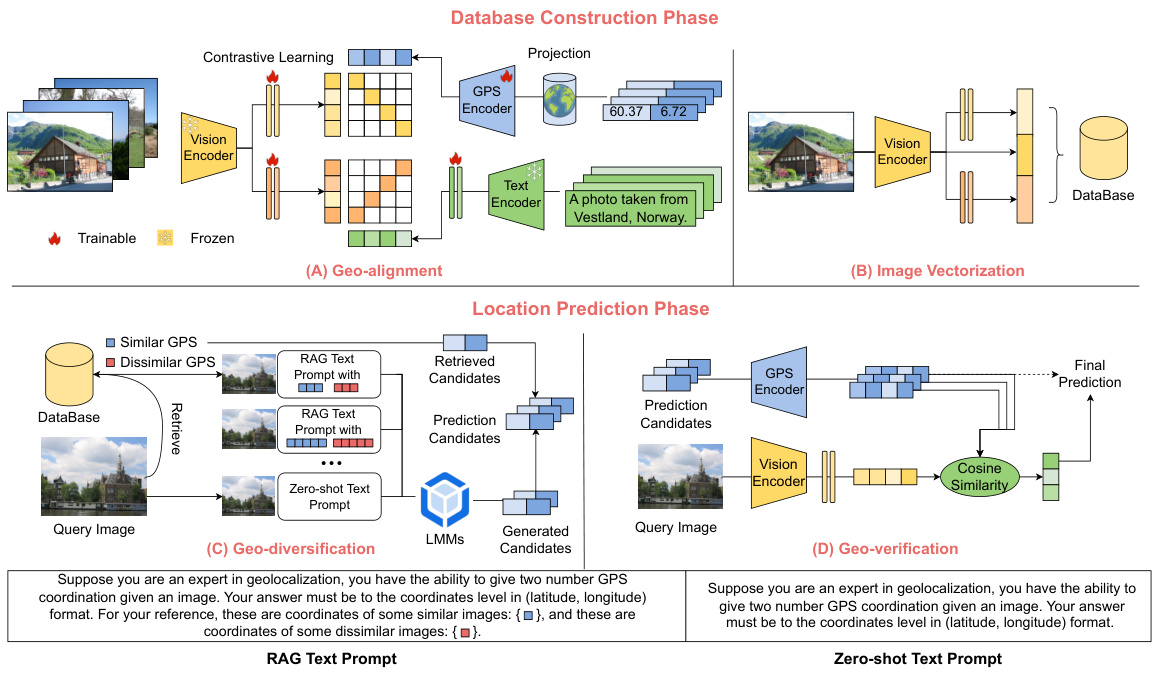
This figure illustrates the overall framework of G3, a novel RAG-based solution for worldwide image geolocalization. It is divided into two main phases: Database Construction and Location Prediction. The Database Construction phase involves Geo-alignment, a process of aligning image representations with textual geographical descriptions and GPS coordinates to capture fine-grained location-aware semantics. The resulting image representations are then stored in a database. The Location Prediction phase consists of three steps: Image Vectorization, Geo-diversification, and Geo-verification. Image Vectorization creates vector representations of the query image. Geo-diversification enhances the robustness of prediction by using multiple prompts with varying numbers of reference GPS coordinates. Geo-verification combines both retrieved and generated GPS candidates to select the best prediction. The figure also shows the text prompts used within the RAG process.

This figure shows the impact of varying the number of RAG prompts on the accuracy of geolocalization at different geographical granularities (street, city, region, country, continent). Each point represents the accuracy achieved using a specific number of RAG prompts. The results indicate that increasing the number of prompts generally improves accuracy up to a certain point, beyond which the gains diminish, suggesting that a balance must be struck between the benefits of multiple perspectives and the potential for noise or redundancy.

This figure shows the impact of varying the number of candidate GPS coordinates generated by each RAG prompt on the accuracy of geolocalization at different geographical levels (street, city, region, country, continent). The x-axis represents the number of candidates, and the y-axis represents the accuracy. The results show an initial increase in accuracy as the number of candidates increases, indicating the benefit of exploring a wider range of possibilities. However, beyond a certain point, increasing the number of candidates leads to diminishing returns and even a decrease in accuracy, suggesting that the additional candidates introduce noise that outweighs the potential benefits. The optimal number of candidates varies across geographical levels, with the optimal point shifting to higher values as the scale increases from street to continent.

This figure illustrates the overall framework of the G3 model, which is proposed for worldwide image geolocalization. The framework is composed of two main phases: database construction and location prediction. The database construction phase involves a multi-modality alignment process (Geo-alignment) that incorporates geographical information into image representations. The location prediction phase involves retrieving images from the database, generating diverse GPS coordinate candidates using a prompt ensembling method (Geo-diversification), and finally selecting the best coordinates through a verification process (Geo-verification) that combines retrieved and generated candidates. The figure visually represents these steps with diagrams, showing the flow of data and processing within the G3 system.

This figure shows three example images from the MP16-Pro dataset. These images represent the diversity of scenes and geographical locations found within the dataset, highlighting the challenge of worldwide geolocalization. The images are labeled with their filenames.

This figure shows example images from the IM2GPS3K dataset, categorized by the localization error of the G3 model. Each row represents a different error threshold (1km, 25km, 200km, 750km, 2500km). The images within each row illustrate the types of images that resulted in localization errors within that range. The figure visually demonstrates that images with lower errors tend to contain more easily identifiable landmarks or distinctive regional features, while images with higher errors are more ambiguous and lack easily recognizable characteristics.

This figure shows a man holding an American flag in France. The text on the left says ‘United States of America’ in French. G3 can accurately give the prediction coordinate latitude: 48.8529 and longitude: 2.3632 located in Paris, France. This demonstrates that G3 can effectively avoid the influence of text in images, thereby focusing on the location where the image was taken, showing strong stability.

This figure shows the results of using the G3 model to predict the coordinates of the Eiffel Tower and its replicas in different locations. The model successfully predicts the coordinates of the Eiffel Tower in Paris, France and its replica in Las Vegas, USA. However, it fails to correctly identify the replica in Hangzhou, China, instead predicting the coordinates of Paris, France. This demonstrates that the model’s performance can be affected by the presence or absence of surrounding reference objects that provide context to the scene.
More on tables
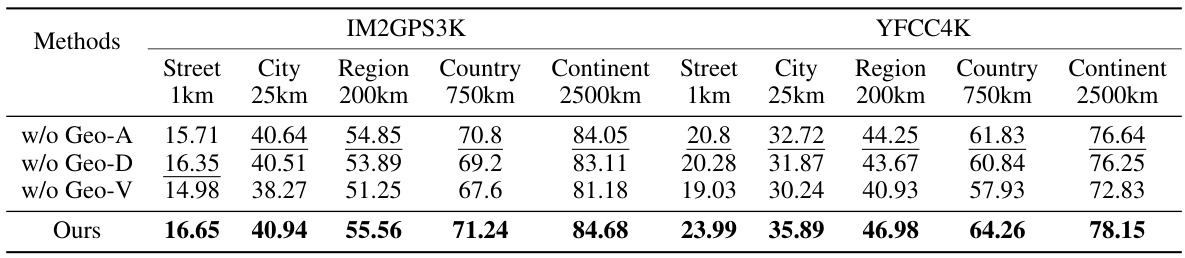
This ablation study shows the impact of each module (Geo-alignment, Geo-diversification, and Geo-verification) of the G3 framework on the performance of worldwide image geolocalization. It compares the performance of G3 with variants where one or more of these modules are removed, using metrics like accuracy at different distance thresholds (1km, 25km, 200km, 750km, 2500km) on the IM2GPS3K and YFCC4K datasets. This allows for a quantitative assessment of each module’s contribution to the overall performance.

This table presents a comparison of the average, median, maximum, and minimum geodesic distances of retrieved images using three different embedding methods: CLIP ViT, G3+EEP, and G3+Mercator. The comparison is shown for the top 5, top 10, and top 15 retrieved images, illustrating how the choice of embedding method affects the geographical proximity of retrieved images to the query image. Smaller distances indicate more geographically relevant retrieval results.

This table presents the experimental results comparing the performance of the proposed G3 model using two different Large Multi-modal Models (LMMs): LLaVA and GPT4V. The results are shown for different geographical granularities (street, city, region, country, continent) using a threshold metric (1km, 25km, 200km, 750km, 2500km). This allows for an assessment of the impact of the choice of LMM on the overall accuracy of the G3 geolocalization approach.

This table presents the results of an ablation study that investigates the necessity of aligning the three representations (image, GPS, and text) in the Geo-alignment module of the G3 model. It compares the performance of the G3 model under different conditions: using only image features (IMG), using image and GPS features (IMG+GPS), and using image, GPS, and text features (IMG+GPS+TEXT, which is the complete G3 model). The results are evaluated across five different geographical levels (Street 1km, City 25km, Region 200km, Country 750km, Continent 2500km) and show the contribution of each component to the final performance.

This table presents a comparison of the proposed G3 method with other state-of-the-art techniques on two benchmark datasets for worldwide image geolocalization: IM2GPS3K and YFCC4K. For each method and dataset, the table shows the accuracy of geolocalization predictions at various distance thresholds (1km, 25km, 200km, 750km, and 2500km). The thresholds represent the acceptable error margin between the predicted location and the ground truth location. Higher percentages at each threshold indicate more accurate geolocalization.
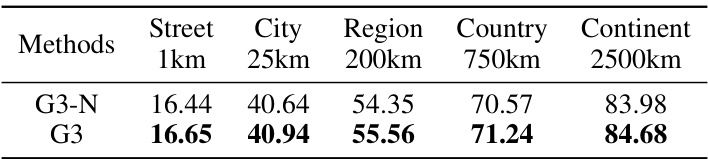
This table presents the performance comparison between G3 and G3-N on the IM2GPS3K dataset. G3-N is a variant of G3 that uses less granular textual descriptions for GPS coordinates (neighborhood, city, county, state, region, country, country code, and continent). The table shows the accuracy in terms of percentage of correct predictions (within 1km, 25km, 200km, 750km, and 2500km) for different levels of geographical granularity (street, city, region, country, continent). This helps assess the impact of the level of detail in geographical description on the geolocalization accuracy.
Full paper#