↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current advanced text-to-image models are often trained on proprietary datasets, limiting accessibility. This restricts researchers and developers, and the high cost of generating data from existing APIs is a major barrier. This paper tackles these issues head-on.
The proposed solution, EvolveDirector, addresses the challenges by using publicly available APIs of advanced models to gather training data, and employs VLMs to intelligently curate this data, thereby minimizing redundancy and maximizing efficiency. Experiments show that EvolveDirector successfully trains a model, Edgen, which surpasses the performance of existing advanced models, demonstrating the effectiveness of the proposed approach and opening new avenues for future research.
Key Takeaways#
Why does it matter?#
This paper is crucial because it demonstrates a novel approach to train high-quality text-to-image models using publicly available resources, significantly reducing the high costs associated with training data. It also introduces EvolveDirector, a novel framework that enhances the training process, paving the way for more accessible and cost-effective AI model development and accelerating advancements in the field.
Visual Insights#

This figure showcases examples of images generated by the model Edgen, highlighting its ability to produce high-quality images at various resolutions and aspect ratios. The model demonstrates strong performance in generating text within images and accurately depicting multiple objects without confusion, features typically associated with leading text-to-image models.
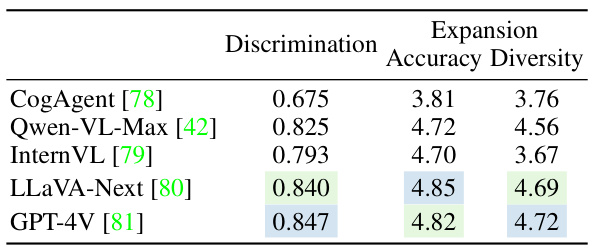
This table presents the results of evaluating various Vision-Language Models (VLMs) based on their alignment with human preferences. Two key aspects were assessed: Discrimination (ability to correctly identify which image best aligns with a given text prompt) and Expansion (ability to generate diverse variations of a text prompt). The table shows the accuracy and diversity scores for each VLM’s expansion capabilities, as well as the accuracy scores for discrimination. LLaVA-Next and GPT-4V show the best overall performance, achieving high accuracy in discrimination and high scores for both accuracy and diversity in expansion.
In-depth insights#
EvolveDirector Framework#
The EvolveDirector framework is a novel approach to training advanced text-to-image models using publicly available resources. Its core innovation lies in leveraging large vision-language models (VLMs) to dynamically curate and refine a training dataset generated from the APIs of existing advanced models. This addresses the limitations of solely relying on vast, static datasets. Instead, EvolveDirector uses the VLM to discriminate, expand, delete and mutate training samples, resulting in a more efficient and higher-quality dataset, significantly reducing the expense and time associated with API calls. The framework’s iterative and adaptive nature allows it to continuously evaluate and adjust the training process, potentially leading to models that surpass the capabilities of those models initially used for data generation. The dynamic dataset strategy ensures only high-value samples are retained. This results in a more powerful and balanced final model, exemplified by Edgen, which outperforms the advanced models it learned from.
VLM-Guided Evolution#
The concept of “VLM-Guided Evolution” presents a powerful paradigm shift in training generative models. Instead of relying on static, pre-defined datasets, it leverages the capabilities of a Vision-Language Model (VLM) to dynamically curate and refine the training data. The VLM acts as an intelligent curator, continuously evaluating the model’s performance and making adjustments to the dataset. This iterative process, involving discrimination, expansion, deletion, and mutation operations, ensures that the model is exposed to high-quality, relevant data, leading to faster convergence and better performance. This dynamic approach addresses the limitations of traditional methods, which often struggle with data redundancy and bias, ultimately leading to more efficient and effective model training. This intelligent feedback loop allows for a more efficient use of resources and facilitates the generation of significantly more robust and capable models, overcoming the challenges of using limited training data and high API costs often associated with external data sources.
Multi-Model Approach#
A multi-model approach in text-to-image generation involves leveraging the strengths of several pre-trained models to improve the overall quality and diversity of generated images. Instead of relying on a single model, this strategy combines the outputs or intermediate representations from multiple sources. This can lead to enhanced image quality because each model may excel in different aspects (e.g., detail, style, composition), and their combined capabilities surpass those of any individual model. Furthermore, it can address limitations of individual models; reducing bias and increasing robustness. By selectively incorporating the best features from each model, a multi-model system can generate images that are both visually appealing and less prone to artifacts or inconsistencies. However, challenges include the computational cost, data management, and algorithmic complexity of integrating multiple models. Careful model selection and data integration strategies are crucial for optimizing performance and avoiding negative effects. Efficient methods for combining and evaluating diverse model outputs are key areas of ongoing research.
Data Efficiency Gains#
The concept of ‘Data Efficiency Gains’ in the context of a research paper likely refers to methods and techniques employed to reduce the amount of training data required to achieve a desired level of performance in a machine learning model. This is crucial because obtaining large, high-quality datasets can be very expensive and time-consuming. The paper likely details strategies that enhance the quality and utility of the available data, rather than simply increasing its quantity. This might involve techniques like data augmentation, active learning to selectively sample informative data points, or transfer learning from pre-trained models. A successful demonstration of data efficiency gains would show that the model performs comparably to state-of-the-art models trained on much larger datasets, while using significantly fewer samples. Quantifiable metrics such as reduced training time, computational costs, and improved generalization performance would support the claim of data efficiency. The discussion would analyze the trade-offs between data efficiency and model performance, acknowledging any limitations or compromises made to achieve data efficiency. The overall impact emphasizes the potential for broader accessibility and applicability of the model because less data means more researchers and developers can utilize and adapt the technology.
Limitations and Future#
The ‘Limitations and Future’ section of a research paper is critical for demonstrating intellectual honesty and guiding future research. A thoughtful discussion acknowledges the study’s shortcomings, such as limited sample size, specific data biases, or methodological constraints. It also proposes avenues for future work by suggesting improvements to address identified limitations, exploring alternative approaches, or broadening the scope of the investigation. For example, the authors might discuss the need for larger-scale datasets to enhance generalizability, investigate confounding variables not considered in the initial study, or explore how their findings may be applied to different contexts or populations. A strong ‘Limitations and Future’ section significantly enhances the paper’s credibility and impact by clearly outlining the study’s boundaries and highlighting the potential for future research.
More visual insights#
More on figures

This figure showcases various images generated by the model Edgen, highlighting its ability to produce high-quality images at different aspect ratios and resolutions. The examples demonstrate Edgen’s strength in accurately rendering text and managing multiple objects within a scene, capabilities usually associated with top-tier text-to-image models. Each image is accompanied by its corresponding text prompt.

This figure shows examples of images generated by the model Edgen, highlighting its ability to generate high-quality images with various aspect ratios and resolutions. The model demonstrates its proficiency in accurately rendering text and avoiding ambiguity when depicting multiple objects within a single scene, characteristics that align with state-of-the-art text-to-image models. Each image is accompanied by the text prompt used to generate it.

This figure showcases examples of images generated by the model Edgen, highlighting its ability to produce high-quality images at various resolutions and aspect ratios. The model demonstrates a strong ability to incorporate text prompts accurately and handle scenes with multiple objects, showcasing its capabilities that are comparable to the most advanced text-to-image generation models.

This figure shows a schematic of the EvolveDirector framework. Panel (a) illustrates how users interact with advanced text-to-image (T2I) models through their APIs, obtaining generated images from text prompts. Panel (b) details the training process of the base T2I model using a dynamic dataset. This dataset is updated iteratively by a vision-language model (VLM), which evaluates the base model’s performance and refines the dataset using operations like discrimination, expansion, deletion, and mutation. The VLM acts as a director, guiding the dataset’s evolution to improve the base model’s ability to generate high-quality images.

This figure showcases several images generated by the model Edgen, highlighting its ability to produce high-quality images with diverse aspect ratios and resolutions. The model demonstrates strong performance in generating text within images and in correctly representing multiple objects within a single image, capabilities typically associated with state-of-the-art text-to-image models. Each image is accompanied by the text prompt used to generate it.

This figure shows several example images generated by the model Edgen, highlighting its ability to produce high-quality images with various aspect ratios and resolutions. The examples demonstrate the model’s strength in accurately rendering text and avoiding confusion when depicting multiple objects within a scene, capabilities typically found only in state-of-the-art text-to-image models.

The figure showcases several images generated by the model Edgen, highlighting its ability to produce high-quality images with various aspect ratios and resolutions. The examples demonstrate Edgen’s strength in accurately rendering text and avoiding confusion when depicting multiple objects within a single image, features typically associated with state-of-the-art text-to-image models.

This figure illustrates the EvolveDirector framework, showing how it interacts with advanced text-to-image (T2I) models. Panel (a) depicts users interacting with the advanced T2I models via APIs to generate images from text prompts. Panel (b) details the training process of the base T2I model within EvolveDirector, emphasizing the dynamic dataset created by using the advanced T2I model APIs. The Vision-Language Model (VLM) continuously monitors and adjusts the training dataset (text prompts and images) using discrimination, expansion, deletion and mutation operations to optimize the training process.

This figure illustrates the EvolveDirector framework. Panel (a) shows how the framework interacts with advanced text-to-image (T2I) models through their APIs, using text prompts to obtain generated images. Panel (b) details the core training loop: the base T2I model is trained on a dynamic dataset of text-image pairs generated by the advanced models. A Vision-Language Model (VLM) continuously assesses the base model’s performance and dynamically adjusts the training dataset using four operations (discrimination, expansion, deletion, and mutation) to improve training efficiency and quality.
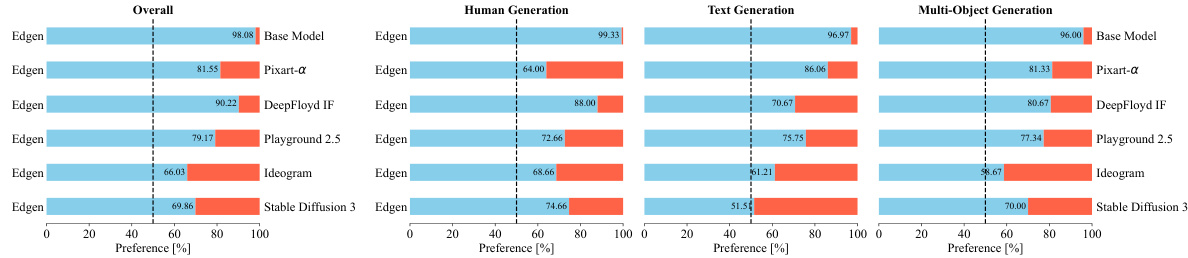
This figure presents the results of a human evaluation comparing images generated by four different models: a base model, Edgen (the model trained using EvolveDirector), and two state-of-the-art models (Pixart-a and DeepFloyd IF). The evaluation focuses on four aspects: overall image quality, human generation, text generation, and multi-object generation. For each model and aspect, a bar chart shows the percentage of times human evaluators preferred the model’s output over the comparison model’s output. This figure demonstrates Edgen’s ability to outperform even state-of-the-art models in several categories, highlighting the effectiveness of the EvolveDirector training framework.

This figure showcases examples of images generated by the model Edgen, highlighting its ability to generate high-quality images at various resolutions and aspect ratios. The model demonstrates its strength in accurately rendering text within images and managing scenes with multiple objects, a hallmark of advanced text-to-image models.

The figure shows the effect of adding layer normalization after the query (Q) and key (K) projections in the multi-head cross-attention mechanism of a diffusion model. The leftmost image (a) shows an image generated after only 0.5k training steps without layer normalization, resulting in artifacts and distortion. The middle image (b) shows the model trained for 2k steps without layer normalization, showing further degradation in image quality. The rightmost image (c) demonstrates the benefit of layer normalization applied after the QK projections, resulting in a clearer image even after 2k training steps. This highlights the importance of layer normalization for stabilizing the training process and improving the quality of generated images.

This figure illustrates the EvolveDirector framework. Panel (a) shows how the framework interacts with advanced text-to-image (T2I) models via APIs, obtaining generated images from text prompts. Panel (b) details the training process of the base T2I model using a dynamic dataset. This dataset is constantly refined by a Vision-Language Model (VLM) that assesses the base model’s performance and adjusts the dataset accordingly using operations like discrimination, expansion, deletion, and mutation to improve the training data’s diversity and quality.

The figure shows several images generated by the model Edgen, highlighting its ability to produce high-quality images with various aspect ratios and resolutions. The examples showcase the model’s proficiency in rendering text accurately and managing multiple objects without confusion, features typically found in state-of-the-art text-to-image models.

The figure showcases various images generated by the model Edgen, highlighting its ability to produce high-quality images with different aspect ratios and resolutions. The examples demonstrate its proficiency in accurately rendering text and avoiding confusion when depicting multiple objects, key capabilities of state-of-the-art text-to-image models. Each image is accompanied by the text prompt used to generate it.
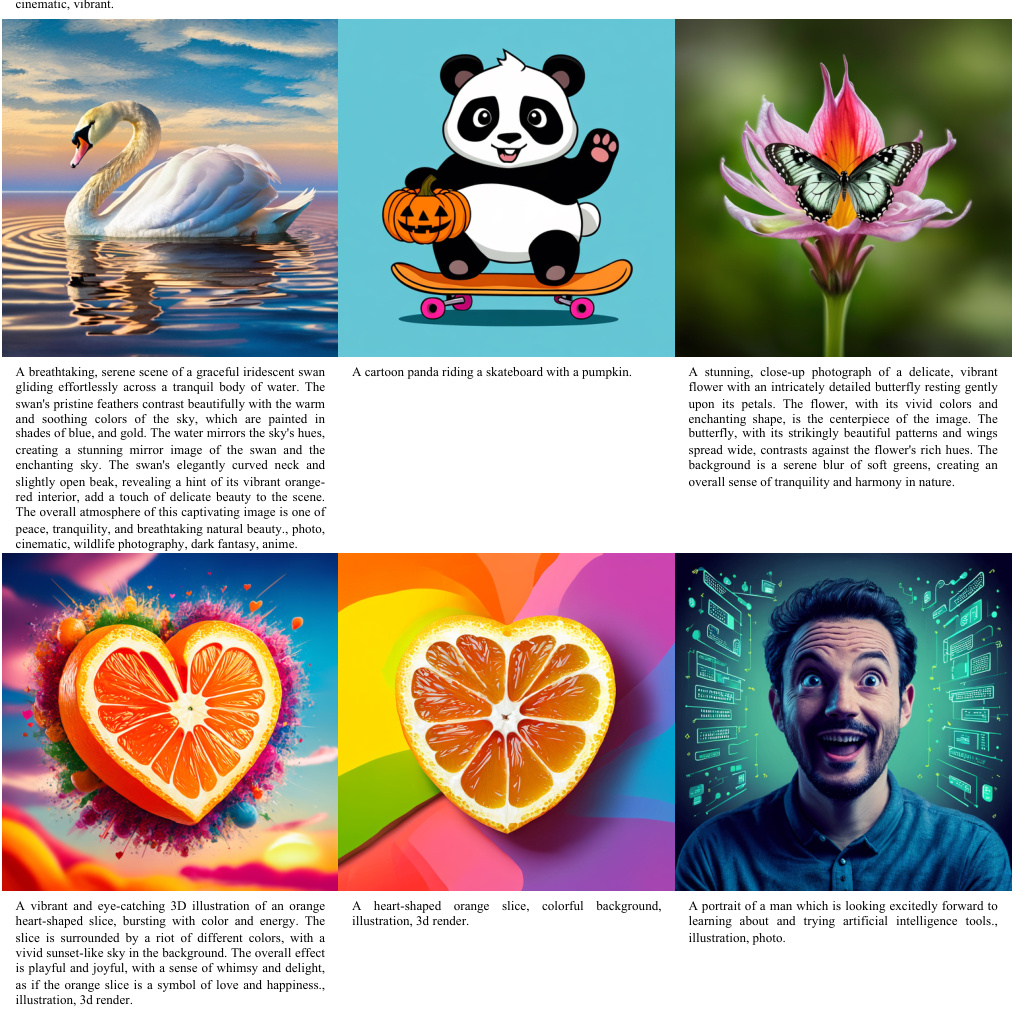
This figure showcases the capabilities of the model Edgen, developed using the EvolveDirector framework. It demonstrates Edgen’s ability to generate high-quality images across various aspect ratios and resolutions. Notably, the images highlight Edgen’s strength in accurately rendering text and avoiding errors when depicting multiple objects in a scene, showcasing its proficiency on par with leading advanced text-to-image models. Each image is accompanied by the corresponding text prompt used for its generation.

This figure shows several example images generated by the model Edgen, highlighting its ability to create high-quality images at various resolutions and aspect ratios. The model demonstrates strong performance in generating text within images and accurately depicting multiple objects without confusion, features characteristic of advanced text-to-image models.

This figure showcases example images generated by the model Edgen, highlighting its ability to produce high-quality images at various aspect ratios and resolutions. The model demonstrates strong performance in text generation and accurately depicting multiple objects without confusion, features that are typically found in advanced text-to-image models. Each image is accompanied by the text prompt that generated it.

This figure showcases various images generated by the model Edgen, highlighting its ability to produce high-quality images with different aspect ratios and resolutions. The examples demonstrate Edgen’s proficiency in accurately rendering text within images and managing multiple objects without confusion, a key feature of advanced text-to-image models. Each image is accompanied by the corresponding text prompt used to generate it.

This figure showcases example images generated by the model Edgen, highlighting its ability to produce high-quality images with various aspect ratios and resolutions. The examples demonstrate the model’s capability to accurately generate text within images and to handle scenes with multiple objects without causing confusion between attributes, features commonly associated with the most advanced text-to-image models.

This figure shows several images generated by the model Edgen, highlighting its ability to produce high-quality images with various aspect ratios and resolutions. The model demonstrates strong performance in generating text within the images and accurately representing multiple objects without confusion. These are key capabilities of advanced text-to-image models.

This figure showcases various images generated by the model Edgen, highlighting its ability to produce high-quality images with diverse aspect ratios and resolutions. The model demonstrates strength in accurately rendering text and avoiding confusion when depicting multiple objects within a single image, features commonly associated with top-tier text-to-image models. Each image is accompanied by its corresponding text prompt.

The figure shows several images generated by the model Edgen, highlighting its ability to produce high-quality images with various aspect ratios and resolutions. The examples demonstrate Edgen’s skill in accurately rendering text and avoiding confusion when depicting multiple objects within a single scene—key strengths of advanced text-to-image models.
More on tables
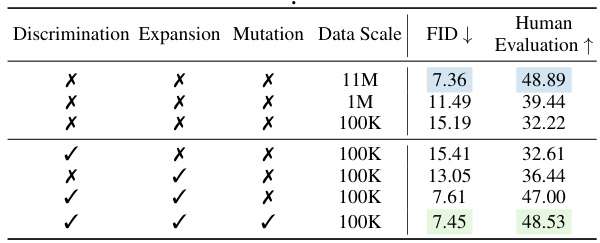
This table presents the results of ablation studies conducted to evaluate the impact of different components of the EvolveDirector framework on the performance of the base model. The studies examine the effects of discrimination, expansion, and mutation operations on the model’s FID score and human evaluation results across various data scales. It compares the performance of models trained with different combinations of these operations, highlighting the effectiveness of the proposed framework in improving data efficiency and model performance.
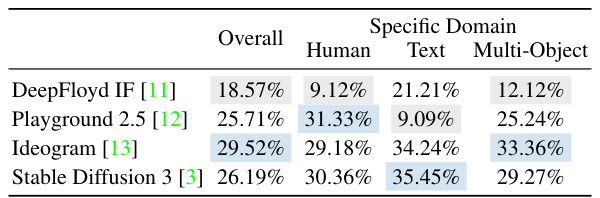
This table presents the percentages of images generated by four different advanced text-to-image models (DeepFloyd IF, Playground 2.5, Ideogram, and Stable Diffusion 3) that were selected by the Vision-Language Model (VLM) in the training process of EvolveDirector. The selection indicates that the VLM considered these images to be superior in quality compared to those generated by the base model. The table breaks down these selection rates into overall percentages and also provides a more granular view of the selection percentages for specific image domains: images containing humans, text, and multiple objects. Highlighting shows the best-performing model in each category.
Full paper#