↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision Transformers (ViTs), while successful, struggle with out-of-distribution (OoD) generalization—a critical issue for real-world applications. Existing research primarily focuses on maximizing in-distribution (ID) accuracy, neglecting OoD performance. This leads to a critical research gap in understanding how to design ViTs that generalize well under OoD shifts.
This paper introduces OoD-ViT-NAS, the first comprehensive benchmark for ViT Neural Architecture Search (NAS) focused on OoD generalization. It evaluates 3,000 ViT architectures on 8 common large-scale OoD datasets, revealing that ViT architecture significantly impacts OoD accuracy. The study also challenges the assumption that high ID accuracy translates to good OoD performance and explores training-free NAS for ViT OoD robustness, discovering that simple metrics like parameter count outperform complex methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on Vision Transformers (ViTs) and out-of-distribution (OoD) generalization. It introduces a novel benchmark and provides valuable insights into designing ViT architectures robust to real-world data shifts, opening avenues for improved model robustness and reliability. The training-free NAS study is also a significant contribution.
Visual Insights#

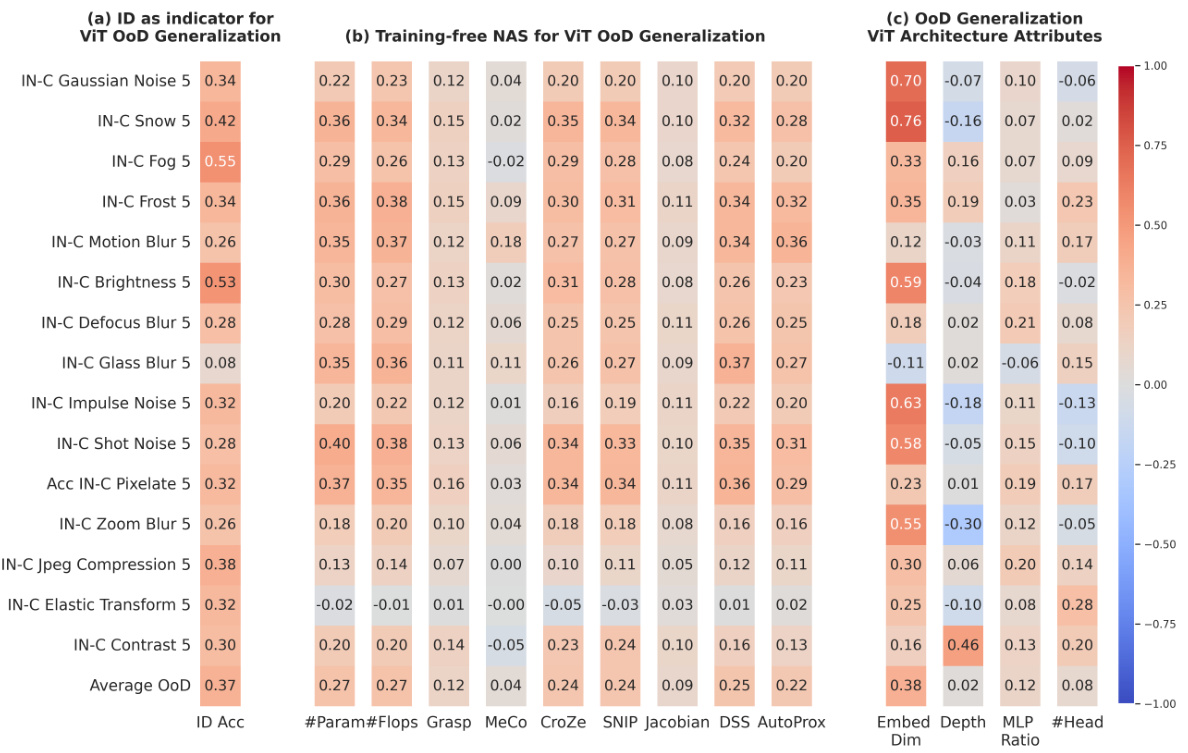
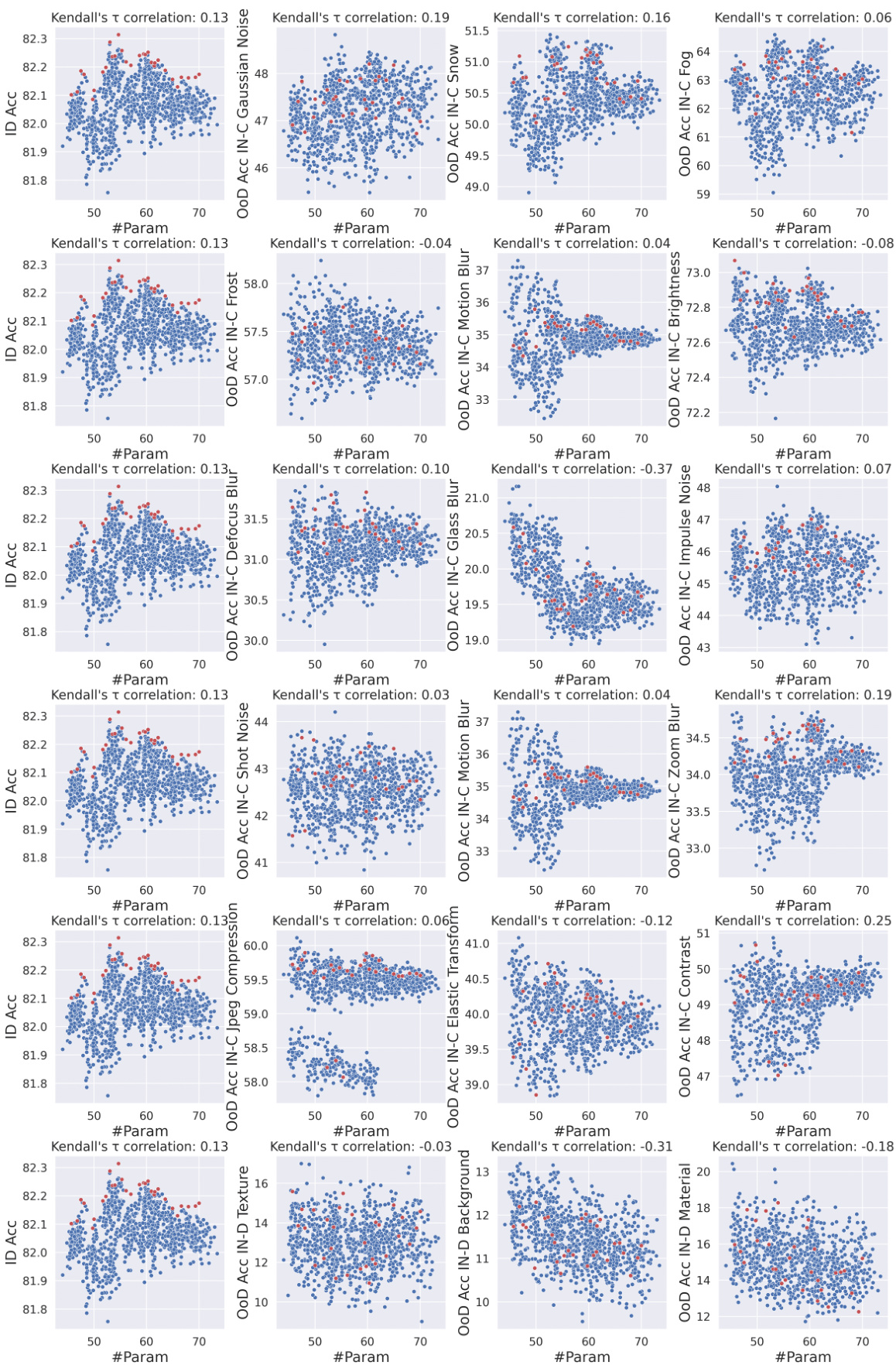
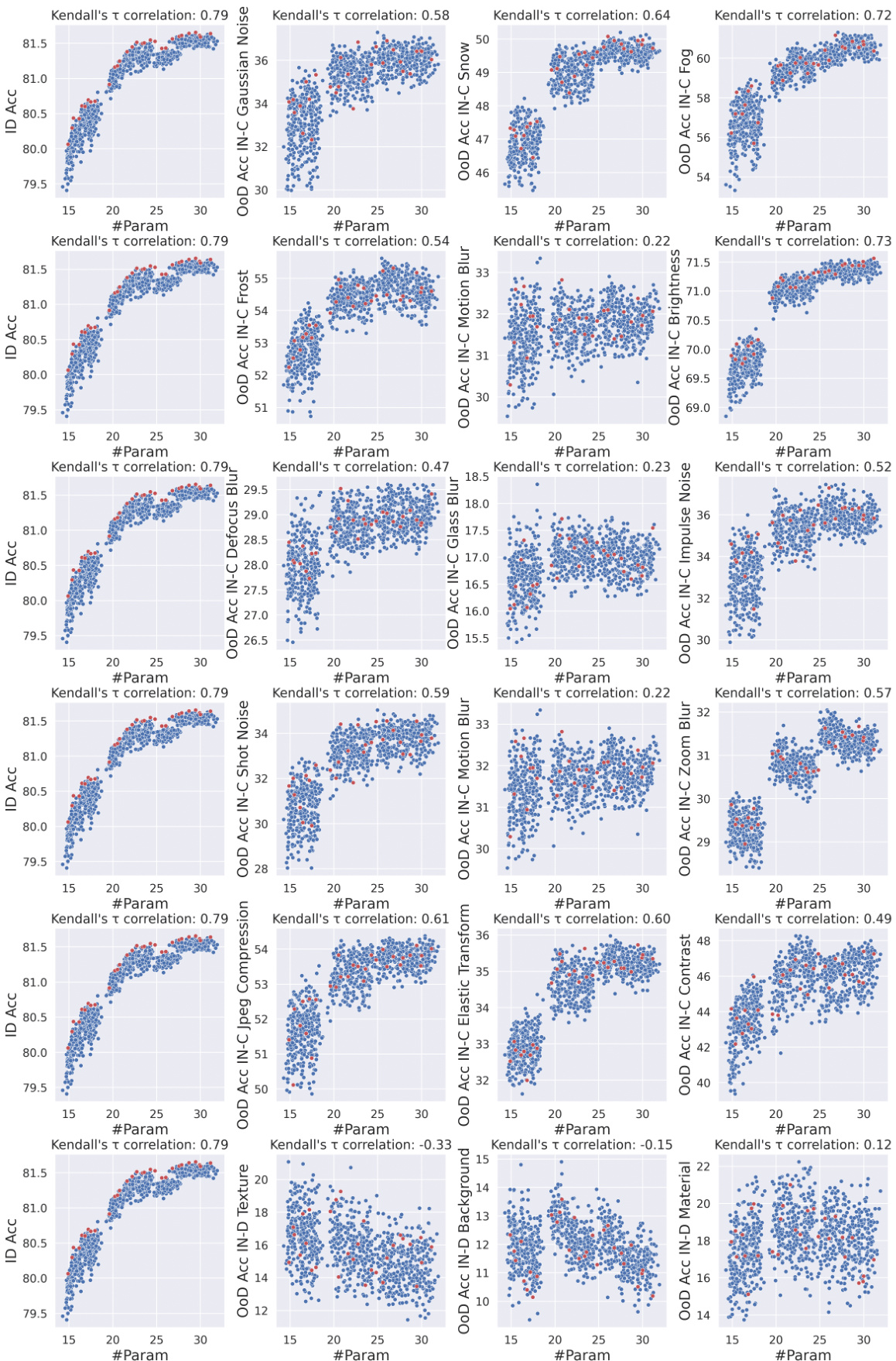
This figure summarizes the key findings of the OoD-ViT-NAS benchmark. Panel (a) shows the low correlation between in-distribution (ID) accuracy and out-of-distribution (OoD) accuracy, highlighting that ID performance is not a reliable indicator of OoD generalization. Panel (b) demonstrates the ineffectiveness of existing training-free Neural Architecture Search (NAS) methods in predicting OoD accuracy, even though they effectively predict ID accuracy. Panel (c) reveals the significant influence of ViT architectural attributes on OoD generalization, with embedding dimension showing the strongest correlation with OoD performance.
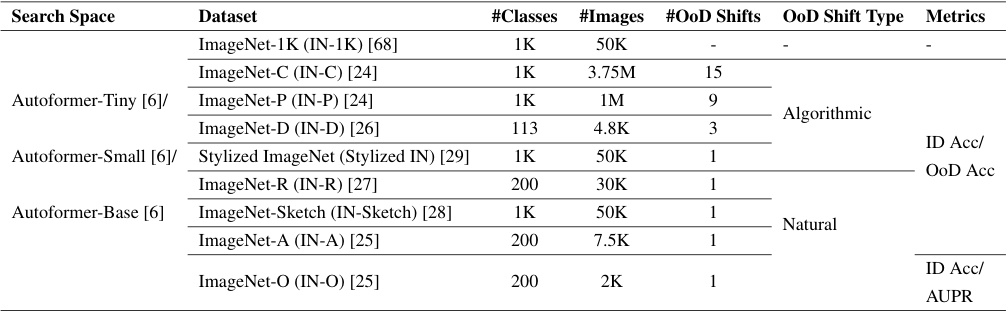
This table summarizes the experimental setup used to create the OoD-ViT-NAS benchmark. It details the search space (Autoformer with three variations: Tiny, Small, and Base), the eight out-of-distribution (OoD) datasets used for evaluation, the number of classes and images in each dataset, and the metrics used (ID accuracy, OoD accuracy, and AUPR). The table provides a comprehensive overview of the benchmark’s design and scope.
In-depth insights#
OoD-ViT-NAS Bench#
An OoD-ViT-NAS benchmark is a crucial initiative for advancing Vision Transformer (ViT) research. It systematically evaluates a large number of ViT architectures, assessing their performance under various out-of-distribution (OoD) scenarios. This comprehensive evaluation is essential because real-world deployments of ViTs often encounter data shifts not present in the training data. The benchmark’s design allows researchers to identify architectural factors that contribute to robust OoD generalization, which is a significant challenge in current ViT models. The availability of such a benchmark would facilitate the development of more resilient and generalizable ViT architectures, leading to improved performance in real-world applications. Access to the benchmark, including the underlying data and code, would foster collaborative research, accelerating progress in the field. This approach highlights the importance of moving beyond simply maximizing in-distribution accuracy to building models that are truly robust and reliable in unpredictable real-world situations.
ViT Arch. Impact#
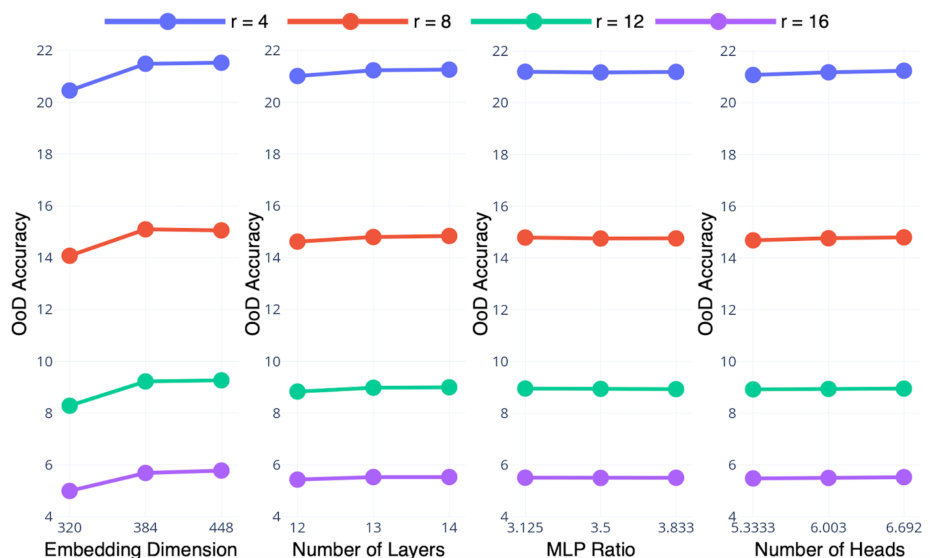
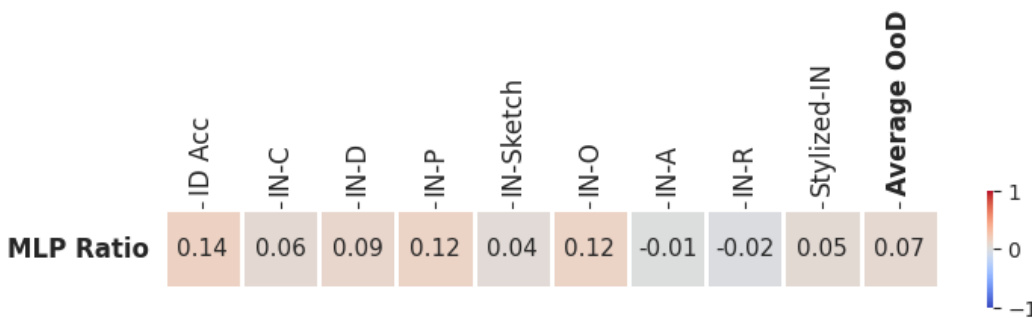
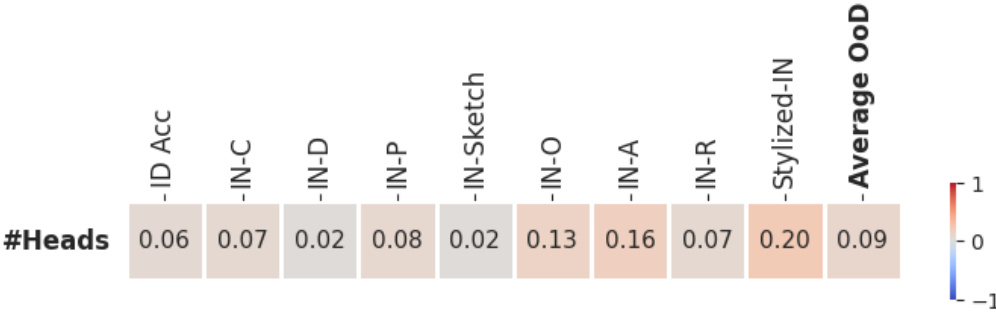
The section ‘ViT Arch. Impact’, if it were part of a research paper, would delve into the significant influence of Vision Transformer (ViT) architecture on its out-of-distribution (OOD) generalization capabilities. It would likely present empirical evidence showing that architectural choices directly affect a model’s robustness to unseen data distributions. The analysis would likely explore various architectural elements such as the number of layers, embedding dimensions, attention mechanisms, and the use of MLP layers, assessing their individual and combined effects on OOD performance. The findings would demonstrate that simply optimizing for in-distribution accuracy is insufficient for achieving strong OOD generalization. Furthermore, the section would potentially suggest architectural design principles for enhancing OOD robustness. This may involve highlighting specific architectural configurations that consistently exhibit superior OOD performance across various benchmark datasets. The insights would be crucial for the development of ViT models that reliably function in real-world scenarios where data distributions deviate from those seen during training. Overall, this section would solidify the importance of careful architectural design in achieving reliable and robust ViT performance across diverse data distributions.
Training-Free NAS#
The concept of “Training-Free NAS” explores the exciting possibility of neural architecture search without the computationally expensive training process typically involved. This approach aims to predict the performance of various architectures using zero-cost proxies, thus significantly speeding up the search process. The paper investigates nine different training-free NAS methods, evaluating their effectiveness at predicting out-of-distribution (OoD) accuracy. A surprising finding is that simple proxies, such as the number of parameters or floating-point operations, surprisingly outperformed more complex training-free NAS methods in predicting ViT’s OoD accuracy. This challenges the current understanding of training-free NAS and highlights the need for further research into more accurate and effective proxies specifically tailored for OoD generalization. Existing training-free NAS methods were largely ineffective at predicting OoD performance, demonstrating a critical gap in the current approaches. This necessitates the development of novel training-free NAS techniques that can reliably predict the OoD robustness of ViT architectures, leading to more efficient and effective neural architecture search for real-world deployment where OoD generalization is crucial.
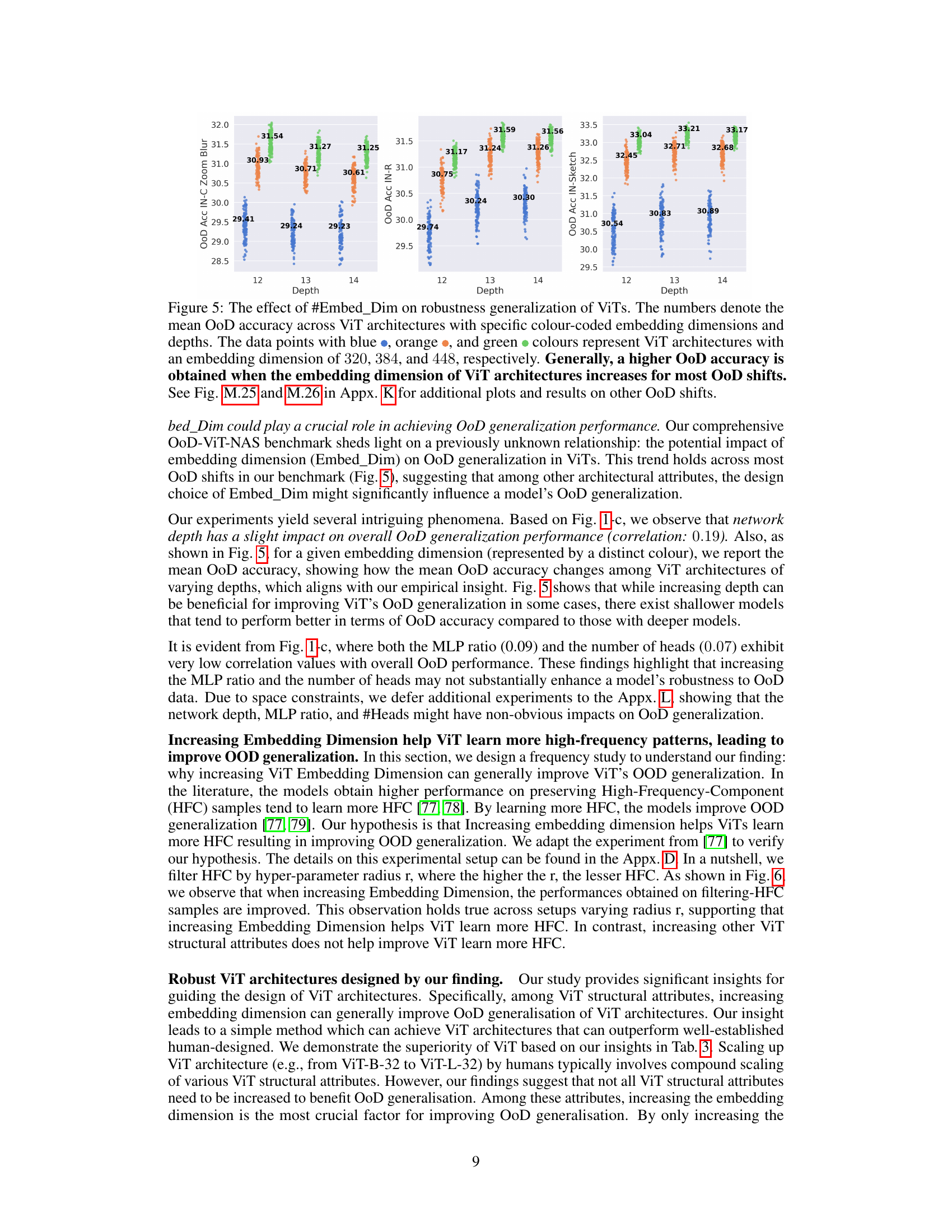
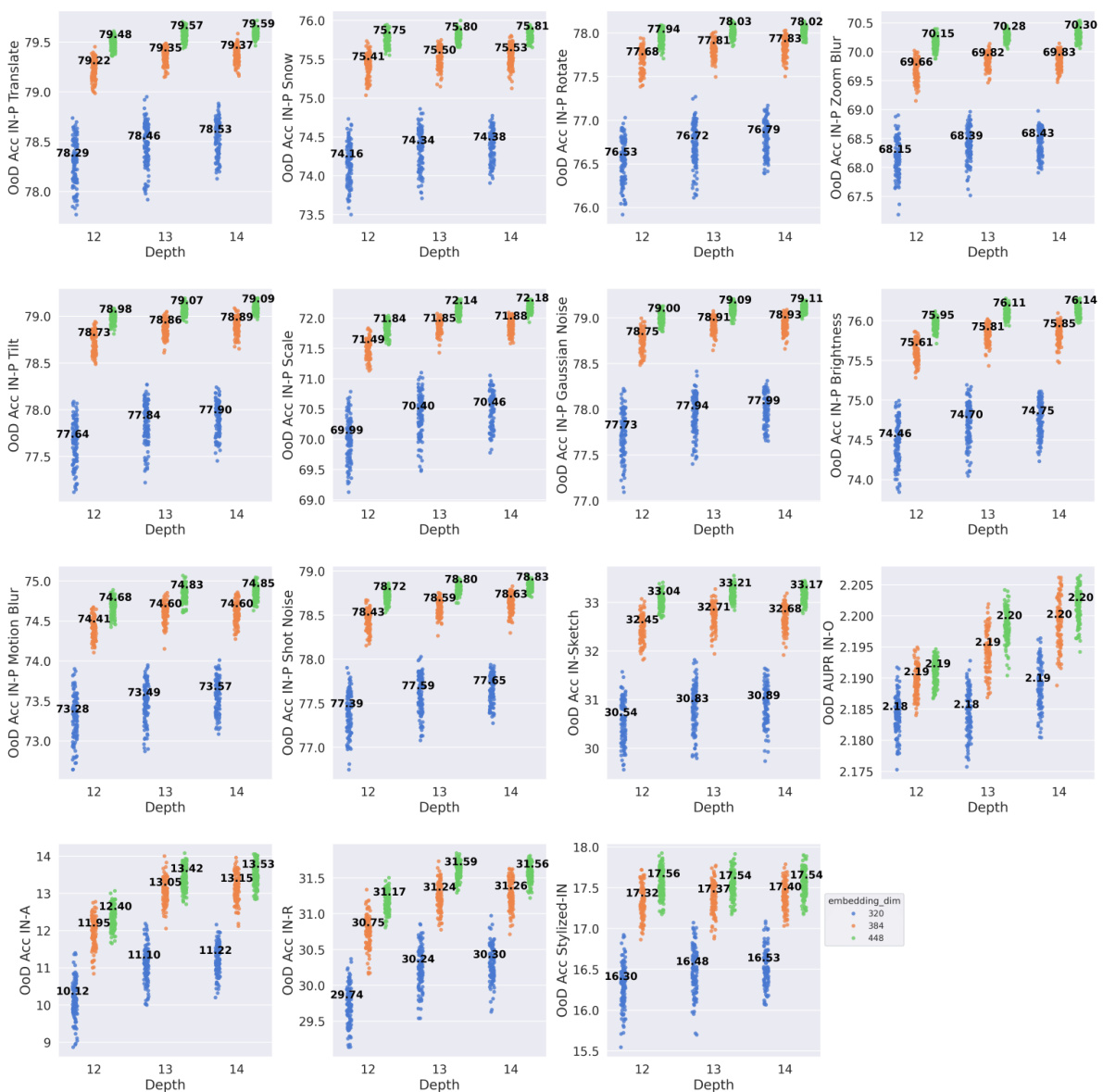
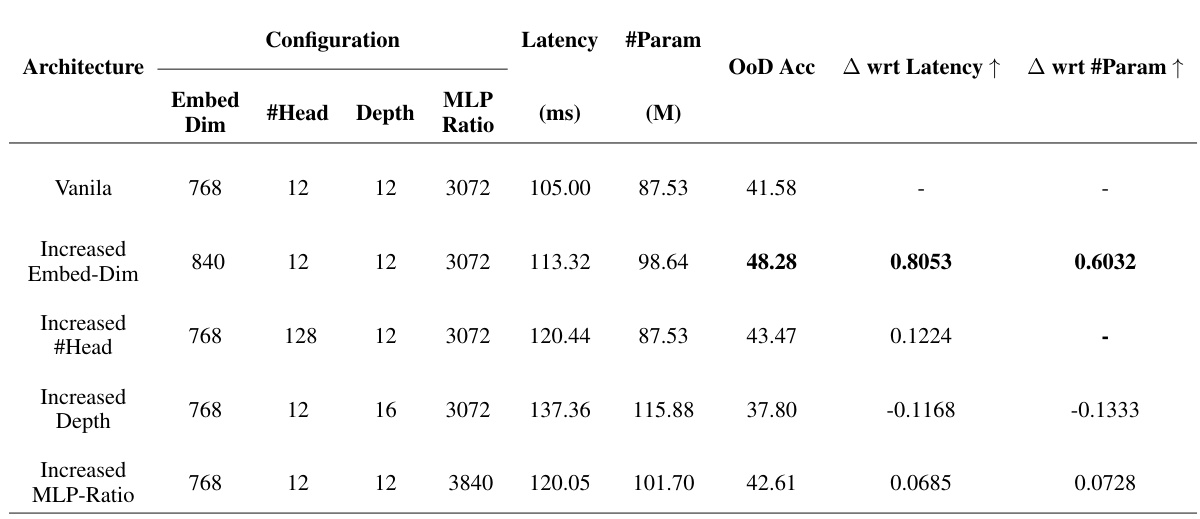
Embed Dim. Boost#
The concept of ‘Embed Dim. Boost,’ while not an explicit heading, likely refers to findings within the paper regarding the impact of embedding dimensions on a vision transformer’s (ViT) performance. The research likely demonstrates that increasing embedding dimensions generally improves out-of-distribution (OOD) generalization for ViTs. This suggests that a larger embedding space allows the model to better capture nuanced features and handle unseen data more effectively. The analysis probably involved comparing ViT architectures with varying embedding dimensions on multiple OOD datasets, observing a positive correlation between embedding dimension size and OOD accuracy. This correlation may not be linear, however, and there might be a point of diminishing returns beyond an optimal embedding dimension size. The paper might further explore the computational cost implications of increasing embedding dimensions, acknowledging the trade-off between enhanced OOD robustness and increased computational burden. The findings have significant implications for designing robust and effective ViT models, suggesting that focusing solely on in-distribution accuracy during architecture design may not guarantee good OOD performance. The optimal embedding dimension likely depends on factors such as dataset characteristics and computational constraints.
Future Research#
Future research should prioritize a deeper investigation into the interplay between ViT architecture and out-of-distribution (OoD) generalization. While increasing embedding dimensions shows promise, a more nuanced understanding of how other architectural choices (depth, MLP ratio, number of heads) individually and collectively affect OoD robustness is crucial. This necessitates exploring more sophisticated training-free NAS methods that effectively predict OoD accuracy, surpassing the performance of simple proxies like #Param and #Flops. Further research could explore novel training techniques or architectural modifications specifically designed to enhance ViT’s robustness to various OoD shifts, thereby bridging the gap between strong in-distribution performance and desired real-world generalization capabilities. Investigating the effectiveness of existing OoD generalization techniques when applied to ViTs warrants attention, as current architectural insights based on in-distribution accuracy may not translate effectively to OoD settings. Finally, benchmarking should expand beyond the currently utilized datasets, ensuring a more comprehensive evaluation across diverse OoD scenarios. This will ultimately lead to more effective and robust ViT designs for real-world applications.
More visual insights#
More on figures

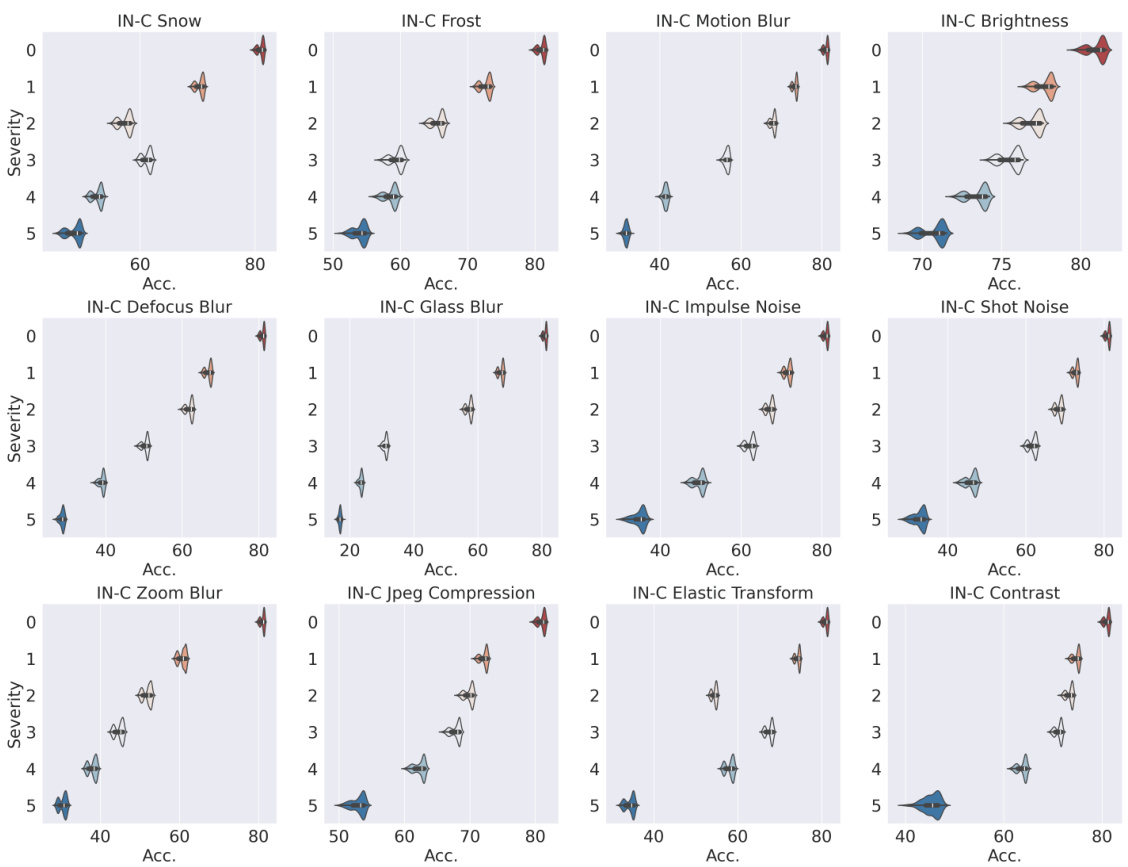
This figure shows the impact of ViT architecture design on out-of-distribution (OoD) generalization performance. Violin plots illustrate the range of OoD accuracy across different datasets for three ViT search spaces (Tiny, Small, Base) from the Autoformer search space. The numbers within each plot show the OoD and In-Distribution (ID) accuracy ranges for each search space. The results demonstrate that ViT architecture significantly impacts OoD generalization performance, highlighting the need for focused architecture research on robustness to OoD shifts.
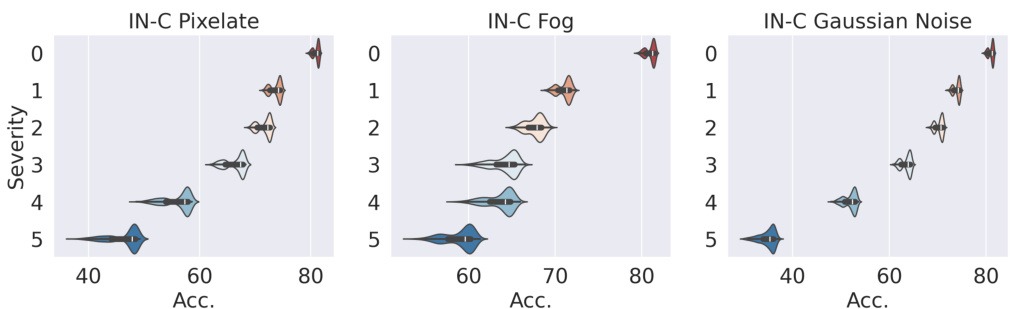
This figure shows the impact of ViT architectural designs on out-of-distribution (OoD) generalization performance. Violin plots illustrate the range of OoD accuracies for different ViT architectures (sampled from three search spaces: Tiny, Small, and Base) across eight OoD datasets. The numbers in each plot represent the average OoD accuracy and the range of OoD accuracy for architectures sampled from different search spaces. The figure demonstrates that ViT architectures have a significant influence on OoD generalization and highlights the surprising finding that the OoD accuracy can be substantially improved through careful design.
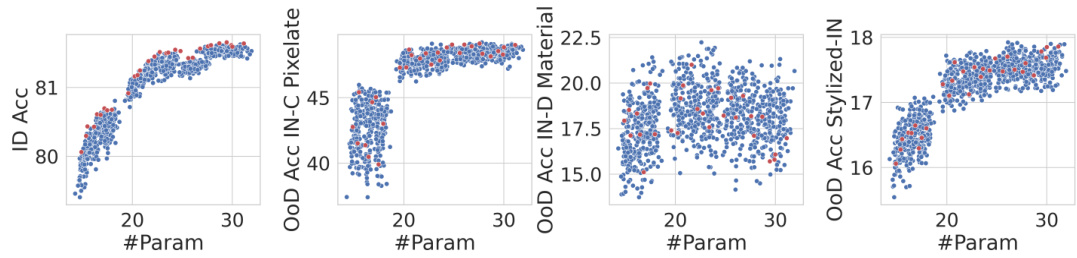
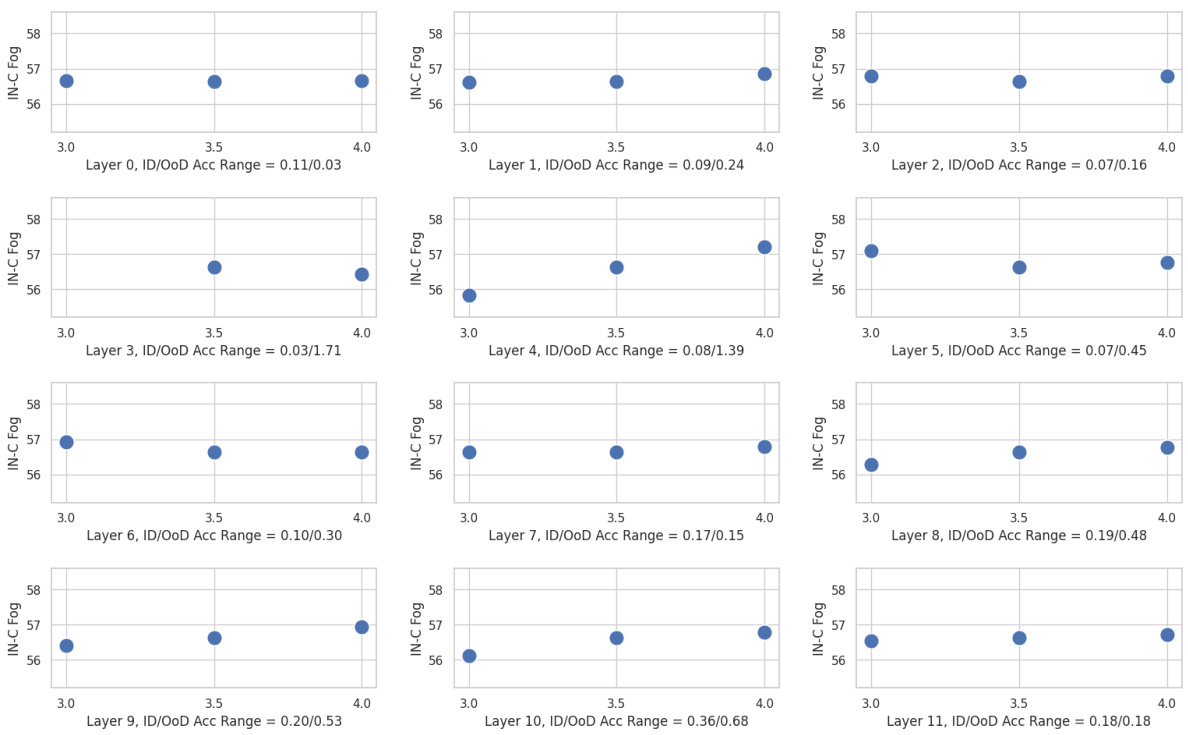
This figure visualizes the relationship between ID accuracy and OoD accuracy for Pareto architectures (top-performing architectures for a given model size) using the Autoformer-Small search space. The blue dots represent all architectures within the search space, while the red dots highlight the Pareto architectures optimized for ID accuracy. The plot reveals that Pareto architectures, although excellent in ID scenarios, perform suboptimally when facing OoD shifts, suggesting ID accuracy alone isn’t a reliable indicator of OoD robustness for ViT architectures.

This figure presents a violin plot analysis showing the impact of ViT architecture design on out-of-distribution (OoD) accuracy across various datasets. The violin plots illustrate the distribution of OoD accuracies for different ViT architectures (sampled from three different search spaces: Tiny, Small, and Base) under various OoD scenarios. The numbers within each violin plot indicate the OoD accuracy (and the ID accuracy in parenthesis). The analysis reveals that ViT architectures significantly influence OoD accuracy, with a wide range observed across different datasets and search spaces, even exceeding the state-of-the-art. The figure highlights that the OoD accuracy varies widely depending on the type of OoD shift and the ViT architecture used. Appendix G contains additional plots.
Violin plots showing the distribution of out-of-distribution (OoD) accuracy for different ViT architectures on 8 different OoD datasets. The figure demonstrates that ViT architecture design significantly impacts OoD accuracy. The accuracy ranges shown are for three different model sizes (Tiny, Small, Base) from the Autoformer search space. The OoD accuracy ranges are compared to in-distribution (ID) accuracy and state-of-the-art (SOTA) methods, showcasing the effectiveness of ViT architecture design on OoD generalization.

This figure summarizes the key findings of the OoD-ViT-NAS benchmark. It shows the correlation between in-distribution (ID) accuracy and out-of-distribution (OoD) accuracy for different datasets and architectural attributes, highlighting the limited predictive power of ID accuracy for OoD generalization and the importance of embedding dimensions in ViT architectures for OoD robustness. It also shows the results of the training-free NAS methods.

This figure presents violin plots showing the distribution of out-of-distribution (OoD) accuracy for different ViT architectures across 8 datasets. The data is separated by model size (Tiny, Small, Base) from the Autoformer search space. The numbers in each plot show the average OoD accuracy and (in parentheses) the average in-distribution (ID) accuracy for that model size. The figure demonstrates the significant impact of ViT architecture on OoD generalization, showing a wide range of performance across the architectures.

This figure summarizes the main findings of the OoD-ViT-NAS benchmark, showing the correlation between in-distribution (ID) accuracy and out-of-distribution (OoD) accuracy for various ViT architectures. It highlights that ID accuracy is not a strong indicator of OoD accuracy, that training-free NAS methods are ineffective in predicting OoD accuracy, and that embedding dimension is a key factor influencing OoD generalization. The figure is divided into three parts: (a) shows the correlation between ID and OoD accuracy; (b) illustrates the performance of training-free NAS methods for predicting OoD accuracy; and (c) shows the relationship between ViT architectural attributes and OoD accuracy.

This figure summarizes the key findings of the OoD-ViT-NAS benchmark. It shows the Kendall rank correlation between OoD accuracy across different datasets and various factors such as ID accuracy, training-free NAS methods, and ViT architectural attributes. Panel (a) highlights the weak correlation between ID and OoD accuracy, suggesting that focusing solely on ID accuracy may not be sufficient for OoD generalization. Panel (b) demonstrates the ineffectiveness of existing training-free NAS methods in predicting OoD accuracy for ViTs. Panel (c) illustrates the significant impact of ViT architectural attributes (especially embedding dimension) on OoD performance. The figure supports the paper’s claims about the importance of considering OoD generalization when designing and searching ViT architectures.

This figure from the paper shows three key analysis results of the OoD-ViT-NAS benchmark: (a) The correlation between In-Distribution (ID) accuracy and Out-of-Distribution (OoD) accuracy is not high, indicating that optimizing for ID accuracy alone may not improve OoD performance. (b) Training-free Neural Architecture Search (NAS) methods are ineffective at predicting OoD accuracy, despite being effective at predicting ID accuracy. (c) The embedding dimension of the ViT architecture has the strongest correlation with OoD accuracy.
This figure summarizes the key findings of the OoD-ViT-NAS benchmark. It shows three main parts: (a) The correlation between in-distribution (ID) accuracy and out-of-distribution (OoD) accuracy is low, indicating that ID accuracy is a poor predictor of OoD performance. (b) Training-free Neural Architecture Search (NAS) methods are ineffective at predicting OoD accuracy, despite their effectiveness in predicting ID accuracy. (c) ViT architectural attributes, specifically embedding dimensions, have a significant impact on OoD generalization performance.
This figure summarizes the key findings of the OoD-ViT-NAS benchmark. It shows the Kendall Tau correlation between out-of-distribution (OoD) accuracy across different datasets and various factors, including ID accuracy, training-free NAS methods, and ViT architectural attributes. The analysis reveals that ID accuracy is not a strong predictor of OoD accuracy and that existing training-free NAS methods are ineffective in predicting OoD performance for ViTs. Finally, it highlights the significant influence of embedding dimension on OoD generalization.

This figure presents a comprehensive overview of the OoD-ViT-NAS benchmark and its key findings. It’s divided into three parts: (a) assesses the correlation between in-distribution (ID) accuracy and out-of-distribution (OoD) accuracy across different datasets, revealing that ID accuracy is not a strong predictor of OoD performance; (b) evaluates the effectiveness of nine training-free Neural Architecture Search (NAS) methods in predicting OoD accuracy, showing that simpler metrics like parameter count are surprisingly better predictors than complex NAS methods; and (c) explores the impact of ViT architectural attributes (embedding dimension, depth, MLP ratio, number of heads) on OoD generalization, highlighting the significant influence of embedding dimension. The figure uses Kendall’s Tau correlation to quantify the relationships between variables.

This figure presents a comprehensive benchmark for Vision Transformer (ViT) Neural Architecture Search (NAS) focused on out-of-distribution (OoD) generalization. It shows Kendall’s tau correlation ranking between OoD accuracy across different datasets and several factors including ID accuracy, training-free NAS methods, and ViT architectural attributes like embedding dimensions. The analysis reveals that ViT architecture design significantly impacts OoD accuracy, ID accuracy is not a good predictor of OoD accuracy, and existing training-free NAS methods are ineffective at predicting OoD accuracy. Increasing embedding dimensions generally improves OoD generalization.
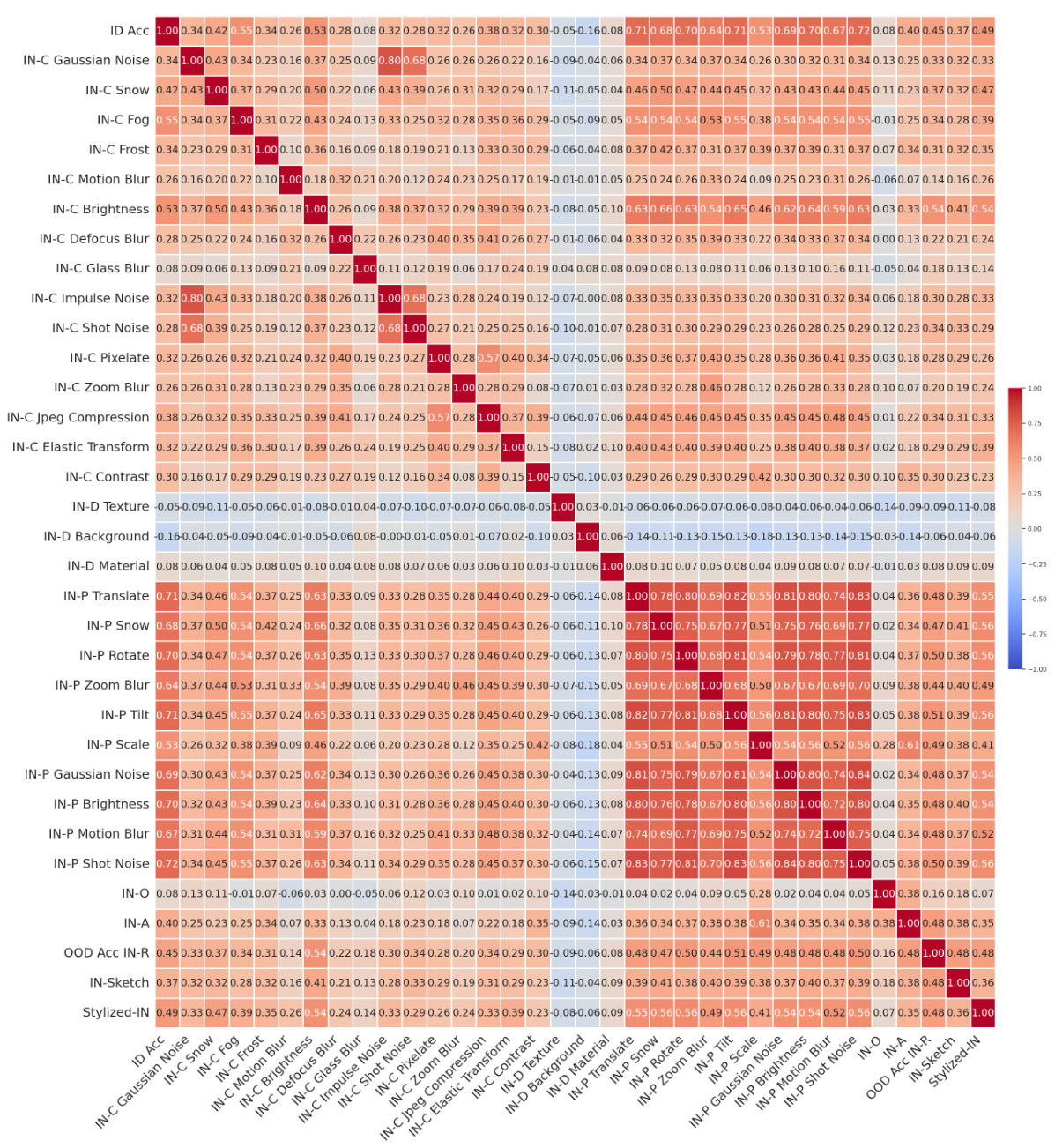
This figure shows the Kendall rank correlation between the out-of-distribution (OOD) accuracy of various datasets and different quantities (ID accuracy, training-free NAS methods, and ViT architectural attributes). It highlights three key findings: 1) In-distribution (ID) accuracy is not a good predictor of OOD accuracy; 2) existing training-free NAS methods are ineffective at predicting OOD accuracy despite their effectiveness at predicting ID accuracy; and 3) increasing the embedding dimension of a ViT architecture generally improves OOD generalization.

This figure presents a comprehensive overview of the OoD-ViT-NAS benchmark, highlighting key findings on Vision Transformer (ViT) neural architecture search for out-of-distribution (OoD) generalization. It shows Kendall’s τ correlation analysis, comparing in-distribution (ID) accuracy to OoD accuracy across 8 datasets and various architectural attributes. The three subfigures focus on: (a) ID accuracy as an indicator for OoD generalization, demonstrating a weak correlation; (b) the ineffectiveness of training-free NAS in predicting OoD accuracy; and (c) the impact of ViT architectural attributes (like embedding dimension) on OoD generalization.

This figure presents a comprehensive benchmark for Vision Transformer Neural Architecture Search (ViT-NAS) focused on out-of-distribution (OoD) generalization. It shows the Kendall Tau ranking correlation between OoD accuracy across various datasets and different quantities (like model parameters and FLOPs). Three key insights are illustrated: (a) In-distribution (ID) accuracy is not a good predictor of OoD accuracy. (b) Existing training-free NAS methods are ineffective at predicting OoD accuracy despite their effectiveness at predicting ID accuracy. (c) The embedding dimension of a ViT architecture significantly impacts OoD generalization.
This figure summarizes the key findings of the OoD-ViT-NAS benchmark. It shows the Kendall Tau correlation between out-of-distribution (OoD) accuracy across different datasets and various factors including in-distribution (ID) accuracy, training-free Neural Architecture Search (NAS) methods, and ViT architectural attributes. Panel (a) demonstrates the weak correlation between ID and OoD accuracy, suggesting that ID accuracy alone is not a sufficient indicator of OoD generalization. Panel (b) shows that existing training-free NAS methods are not very effective at predicting OoD accuracy despite their efficacy in predicting ID accuracy. Finally, panel (c) reveals that the embedding dimension in ViT architectures is a strong predictor of OoD generalization performance.
This figure from the paper shows the Kendall τ ranking correlation between OoD accuracy of different datasets and different quantities. The left panel shows the correlation between ID accuracy and OoD accuracy. The middle panel shows the performance of training-free NAS for predicting OoD accuracy. The right panel shows the correlation between OoD accuracy and different ViT architectural attributes.
This figure presents a comprehensive overview of the OoD-ViT-NAS benchmark and its key findings. It shows the Kendall Tau correlation between OoD accuracy across different datasets and various factors like ID accuracy, training-free NAS methods, and ViT architectural attributes. The three subfigures highlight the relatively weak correlation between ID and OoD accuracy, the ineffectiveness of training-free NAS for predicting OoD performance, and the strong positive correlation between embedding dimension and OoD generalization, respectively. This visually summarizes the paper’s main contributions and insights.

This figure shows the distribution of out-of-distribution (OoD) accuracy across different ViT architectures and various OoD datasets. Each violin plot represents the range and distribution of OoD accuracy for architectures of a specific size (tiny, small, base) on a specific OoD dataset. The numbers in parentheses indicate the corresponding in-distribution (ID) accuracy range. The key finding is that ViT architecture design significantly affects OoD accuracy, with a wide range of performance observed even within the same ID accuracy range. This surpasses the state-of-the-art results.
This figure visualizes the significant impact of ViT architecture design on out-of-distribution (OoD) generalization performance. It shows the range of OoD accuracy across eight different OoD datasets for ViT architectures sampled from three different search spaces (Autoformer-Tiny, Small, and Base). The numbers within each violin plot indicate the OoD accuracy (and ID accuracy in parentheses) for each search space. The figure highlights that even with comparable in-distribution (ID) accuracy, the OoD accuracy can vary significantly across different architectures, emphasizing the importance of architecture design for OoD robustness.

This figure visualizes the impact of ViT architectural designs on out-of-distribution (OoD) accuracy. Violin plots show the distribution of OoD accuracy across various ViT architectures, categorized by model size (Tiny, Small, Base). The numbers in parentheses indicate the corresponding in-distribution (ID) accuracy. The figure demonstrates that different architectures exhibit a wide range of OoD performance, even when achieving similar ID accuracy. The OoD accuracy ranges are significantly better than the current state-of-the-art (SOTA) methods, highlighting the potential for improving OoD generalization through careful architectural design.

This figure presents the key findings of the OoD-ViT-NAS benchmark, highlighting the impact of different factors on the out-of-distribution (OoD) generalization ability of Vision Transformers (ViTs). Panel (a) shows the weak correlation between in-distribution (ID) accuracy and OoD accuracy, implying that ID-optimized architectures may not generalize well to OoD scenarios. Panel (b) reveals the ineffectiveness of training-free neural architecture search (NAS) methods in predicting OoD accuracy, while panel (c) demonstrates the strong positive correlation between embedding dimension and OoD accuracy, suggesting this as a crucial factor for improving OoD generalization.
This figure presents a comprehensive overview of the OoD-ViT-NAS benchmark, highlighting key findings regarding the impact of ViT architecture on out-of-distribution (OoD) generalization. It shows Kendall’s tau ranking correlation between OoD accuracies across different datasets and various factors such as ID accuracy, training-free NAS methods, and ViT architectural attributes. The figure is divided into three sections: (a) shows the correlation between In-distribution (ID) and OoD accuracy; (b) shows the effectiveness of training-free NAS for predicting OoD accuracy; and (c) demonstrates the correlation between specific ViT architectural attributes and their OoD performance. This provides a holistic view of how ViT architecture design impacts OoD generalization capabilities.

This figure presents a comprehensive overview of the OoD-ViT-NAS benchmark, which is the first benchmark for Vision Transformer Neural Architecture Search focused on out-of-distribution (OoD) generalization. It shows the Kendall Tau correlation, a measure of rank correlation, between OoD accuracy across different datasets and various factors, such as ID accuracy, training-free NAS methods, and ViT architectural attributes. This helps to understand how different aspects contribute to the OoD generalization capability of ViT architectures and provides insights into the limitations of current approaches.

This figure presents a comprehensive benchmark for Vision Transformer Neural Architecture Search (ViT-NAS) focused on out-of-distribution (OoD) generalization. It shows Kendall’s tau ranking correlation between OoD accuracy across different datasets and various architectural attributes. Three key insights are highlighted: 1. In-distribution (ID) accuracy is a poor indicator of OoD accuracy. 2. Existing training-free NAS methods are ineffective at predicting OoD accuracy for ViTs. 3. Embedding dimension is the most important architectural attribute impacting OoD generalization.

This figure shows the range of out-of-distribution (OoD) accuracy for different ViT architectures across eight datasets. The violin plots illustrate the distribution of OoD accuracy for each dataset, categorized by three model sizes (Tiny, Small, Base). The numbers in parentheses represent the corresponding in-distribution (ID) accuracy. The figure demonstrates that ViT architecture design significantly influences OoD generalization; different architectures show considerable variation in OoD accuracy, even those with similar ID accuracy. Notably, the OoD accuracy range of the benchmarked architectures is comparable to or exceeds the state-of-the-art (SOTA) in domain-invariant representation learning.
This figure presents a comprehensive analysis of the OoD-ViT-NAS benchmark, focusing on three key aspects: the relationship between in-distribution (ID) and out-of-distribution (OoD) accuracy, the effectiveness of training-free Neural Architecture Search (NAS) methods for predicting OoD accuracy, and the impact of various ViT architectural attributes on OoD generalization. It reveals that ID accuracy is not a strong predictor of OoD accuracy, existing training-free NAS methods are ineffective at predicting OoD performance, and embedding dimension is the most significant architectural factor influencing OoD performance.

This figure shows the violin plots of OoD accuracy for different ViT architectures from three search spaces (Tiny, Small, Base) across various OoD datasets. Each plot represents a specific OoD dataset and shows the distribution of OoD accuracy for ViT architectures with different sizes. The numbers in parentheses are the corresponding ID accuracy. It highlights that ViT architectures have a considerable impact on OoD generalization performance, even surpassing state-of-the-art methods in some cases.
This figure shows the distribution of out-of-distribution (OoD) accuracy across different ViT architectures from three different search spaces (Tiny, Small, Base). The violin plots visually represent the range and density of OoD accuracy for eight different OoD datasets under various corruption levels. The figure emphasizes that ViT architecture significantly impacts OoD generalization performance and that higher ID accuracy does not guarantee better OoD accuracy. The results show a wide range of OoD accuracy across architectures, highlighting the importance of architecture design for OoD robustness.
More on tables
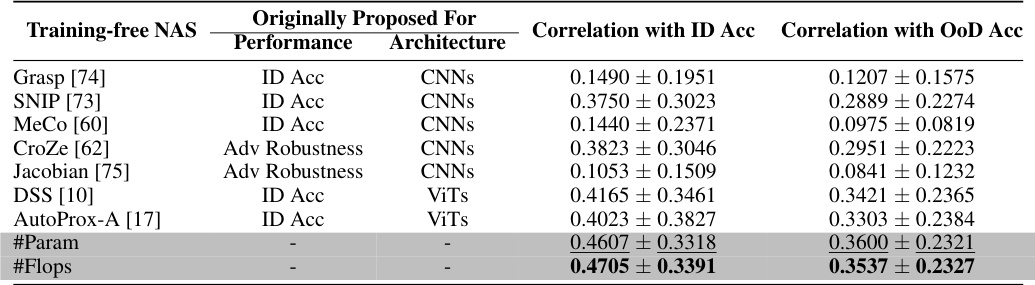
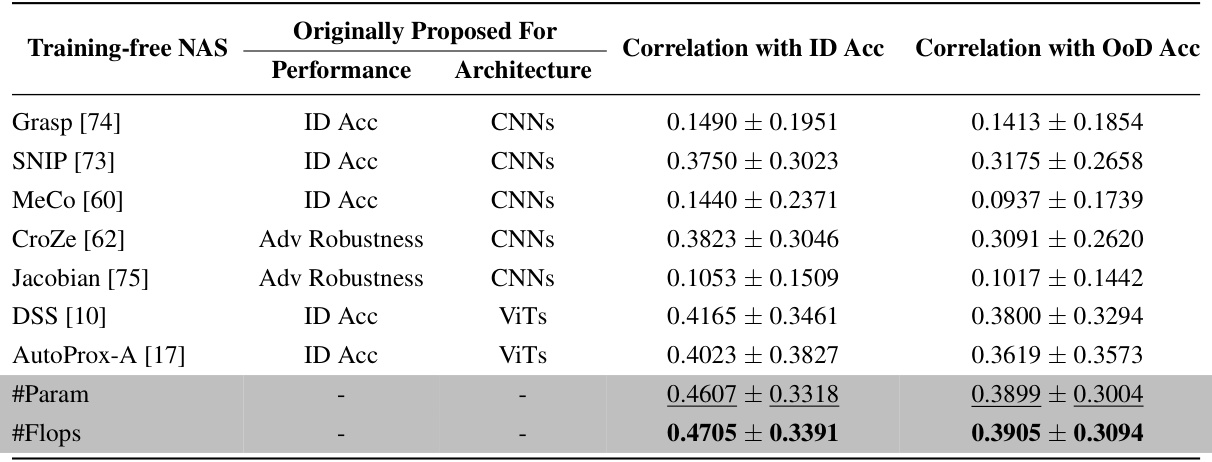
This table presents the Kendall τ correlation coefficients between the OoD accuracy and the predictions from nine different training-free neural architecture search (NAS) methods and two simple proxies (#Param and #Flops). The results show that existing training-free NAS methods are not very effective at predicting OoD accuracy, even those specifically designed for Vision Transformers (ViTs). Surprisingly, simple proxies like #Param and #Flops show better correlation with OoD accuracy than the more sophisticated training-free NAS methods. This indicates a need for improved training-free NAS methods for predicting the out-of-distribution (OoD) generalization performance of ViTs.

This table details the experimental setup of the OoD-ViT-NAS benchmark. It shows the search space used (Autoformer-Tiny, Small, Base), the number of architectures sampled (3000), the eight out-of-distribution (OOD) datasets used for evaluation, and the three metrics used to measure performance: In-Distribution (ID) accuracy, OoD accuracy, and Area Under the Precision-Recall Curve (AUPR).
This table details the experimental setup used to create the OoD-ViT-NAS benchmark. It outlines the search space (Autoformer-Tiny/Small/Base), the number of architectures sampled (3000), the eight out-of-distribution (OOD) datasets used for evaluation (ImageNet-C, ImageNet-P, ImageNet-D, Stylized ImageNet, ImageNet-R, ImageNet-Sketch, ImageNet-A, ImageNet-O), and the three metrics employed to assess the model’s performance: ID Accuracy, OoD Accuracy, and AUPR.

This table summarizes the experimental setup used in the OoD-ViT-NAS benchmark. It specifies the search space (Autoformer-Tiny, -Small, -Base) used to generate 3,000 ViT architectures, the eight standard Out-of-Distribution (OoD) datasets employed for evaluation, and the three metrics (ID Accuracy, OoD Accuracy, AUPR) used for assessing performance.

This table presents the Kendall’s τ correlation coefficients between the OoD accuracies and different training-free NAS proxy values on eight common large-scale out-of-distribution (OoD) datasets. The results demonstrate that existing training-free NAS methods are largely ineffective at predicting OoD accuracy for Vision Transformers (ViTs). Surprisingly, simple proxies such as the number of parameters (’#Param’) or floating-point operations (’#Flops’) significantly outperform more complex training-free NAS methods in predicting both OoD and in-distribution (ID) accuracy for ViTs.

This table presents the Kendall τ correlation coefficients between the OoD accuracies and the predictions from nine different training-free Neural Architecture Search (NAS) methods. The methods are evaluated across eight common out-of-distribution (OoD) datasets and three different ViT architecture search spaces. The results show that existing training-free NAS methods are not very effective at predicting OoD accuracy, even those recently proposed and specifically designed for Vision Transformers (ViTs). Surprisingly, simple metrics like the number of parameters (#Param) and floating-point operations (#Flops) outperform the more complex training-free NAS methods in predicting both OoD and in-distribution (ID) accuracy for ViTs.
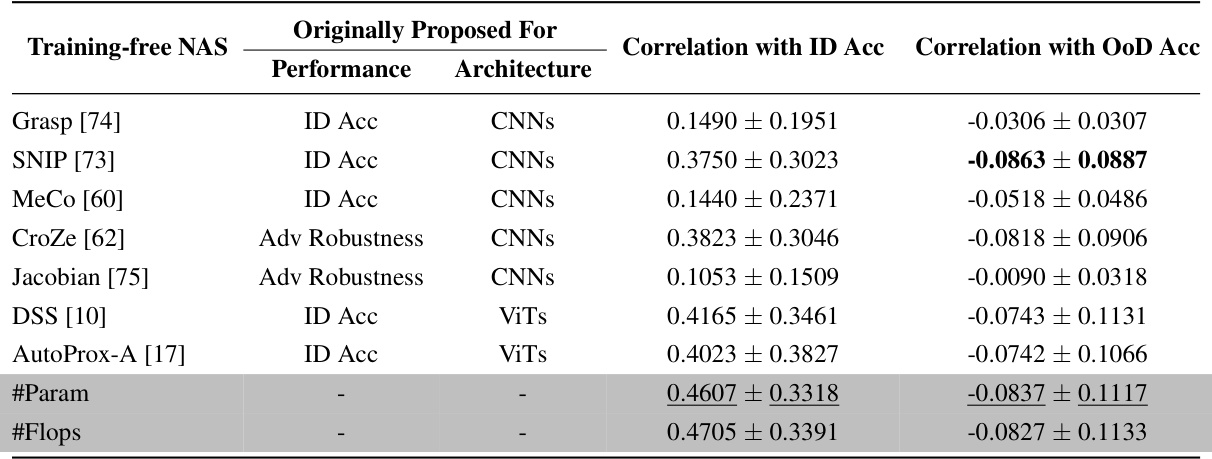
This table presents the Kendall τ ranking correlation coefficients between the out-of-distribution (OoD) accuracies and the predictions of nine training-free neural architecture search (NAS) methods on eight common large-scale OoD datasets. The results show that existing training-free NAS methods are not very effective at predicting OoD accuracy for Vision Transformers (ViTs), even recently proposed ones. Surprisingly, simple proxies like the number of parameters (#Param) and the number of floating-point operations (#Flops) surprisingly outperform more complex training-free NAS methods in predicting both OoD and in-distribution (ID) accuracy.
This table presents the Kendall τ ranking correlation coefficients between the out-of-distribution (OoD) accuracies and various training-free Neural Architecture Search (NAS) proxies across eight common large-scale OoD datasets. It shows that existing training-free NAS methods are not very effective at predicting OoD accuracy for Vision Transformers (ViTs), even recent ones. Surprisingly, simple proxies like the number of parameters (#Param) or floating point operations (#Flops) surprisingly outperform more complex training-free NAS methods.

This table presents the results of a study comparing the effectiveness of various training-free Neural Architecture Search (NAS) methods in predicting out-of-distribution (OoD) accuracy for Vision Transformers (ViTs). It compares the Kendall τ correlation between the OoD accuracy and the prediction from each NAS method, using 8 common OoD datasets. The table notably shows that simple proxies like parameter count (’#Param’) and floating-point operations (’#Flops’) surprisingly outperform more sophisticated training-free NAS methods in accurately predicting OoD accuracy. This finding challenges the current state-of-the-art in training-free NAS for ViTs and suggests that simpler measures might be more effective for predicting OoD robustness.
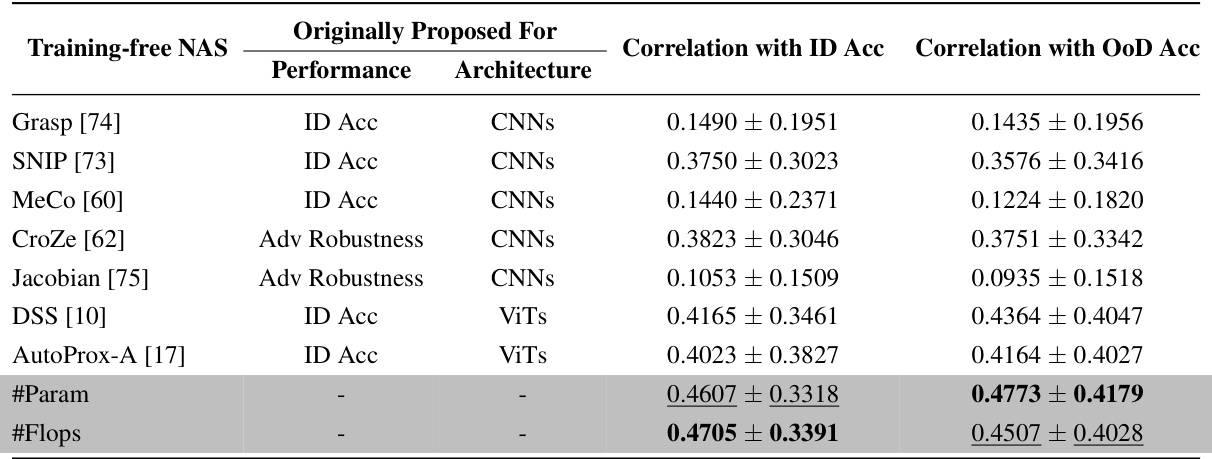
This table presents the Kendall’s τ ranking correlation between the out-of-distribution (OoD) accuracy and predictions from nine different zero-cost training-free neural architecture search (NAS) methods across eight common OoD datasets. The results show that existing training-free NAS methods are not very effective at predicting OoD accuracy, even for methods specifically designed for Vision Transformers (ViTs). Surprisingly, simple proxies such as the number of parameters (#Param) or floating point operations (#Flops) surprisingly outperform the more complex NAS methods in predicting both OoD and in-distribution (ID) accuracy for ViTs.

This table presents a comparison of the Kendall τ rank correlation between the out-of-distribution (OoD) accuracies and the predictions from nine different training-free neural architecture search (NAS) methods. The methods are evaluated on eight common large-scale OoD datasets using the OoD-ViT-NAS benchmark. The table highlights that existing training-free NAS methods are not very effective at predicting OoD accuracy, even those recently proposed and specifically designed for Vision Transformers (ViTs). Surprisingly, simple proxies like the number of parameters (#Param) or floating point operations (#Flops) significantly outperform the more complex training-free NAS methods in predicting both OoD and in-distribution (ID) accuracy for ViTs.
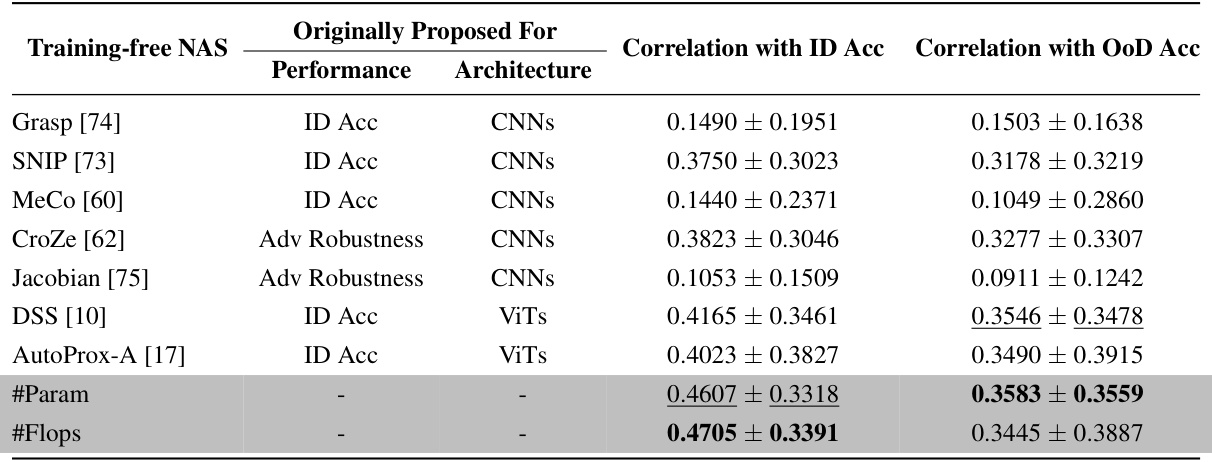
This table presents the Kendall τ correlation coefficients between the out-of-distribution (OoD) accuracies and the predictions from nine different training-free neural architecture search (NAS) methods, along with two simple proxies (#Param and #Flops), across eight common OoD datasets. The results show that existing training-free NAS methods are largely ineffective at predicting OoD accuracy. Surprisingly, the simple proxies of #Param and #Flops outperform more sophisticated training-free NAS methods in this task.

This table details the experimental setup for the OoD-ViT-NAS benchmark. It lists the search space used (Autoformer-Tiny/Small/Base), the number of architectures sampled (3000), the eight out-of-distribution (OoD) datasets used for evaluation, and the three metrics employed to assess performance: In-Distribution (ID) Accuracy, OoD Accuracy, and Area Under the Precision-Recall Curve (AUPR).

This table details the experimental setup for the OoD-ViT-NAS benchmark. It specifies the search space used (Autoformer with Tiny, Small, and Base variations), the number of architectures sampled (3000), the eight out-of-distribution (OOD) datasets used for evaluation, and the three metrics employed to assess performance: In-Distribution (ID) accuracy, OOD accuracy, and Area Under the Precision-Recall Curve (AUPR).
Full paper#