↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Reinforcement Learning from Human Feedback (RLHF) is a crucial step in aligning Large Language Models (LLMs) with human preferences. However, RLHF often suffers from
overoptimization, where an imperfectly learned reward model misguides the LLM, leading to undesired outputs. This paper tackles this challenge by presenting a new approach.
The researchers propose a theoretical algorithm and its practical counterpart, Regularized Preference Optimization (RPO). RPO cleverly combines a preference optimization loss (DPO) with a supervised fine-tuning loss (SFT). This integration not only directly aligns the LLM with human preferences but also acts as a regularizer, preventing overfitting to the imperfect reward model. The paper provides theoretical guarantees for the algorithm’s efficiency and empirical results validating the effectiveness of RPO in mitigating overoptimization and improving LLM alignment.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in RLHF and LLM alignment due to its novel theoretical algorithm that provably mitigates overoptimization, a common problem hindering effective LLM alignment. The algorithm’s surprisingly simple practical implementation (Regularized Preference Optimization or RPO) makes it highly relevant for practical applications, and the empirical results demonstrate clear improvements over existing methods. It also opens new avenues for further investigation in both theoretical and applied research.
Visual Insights#
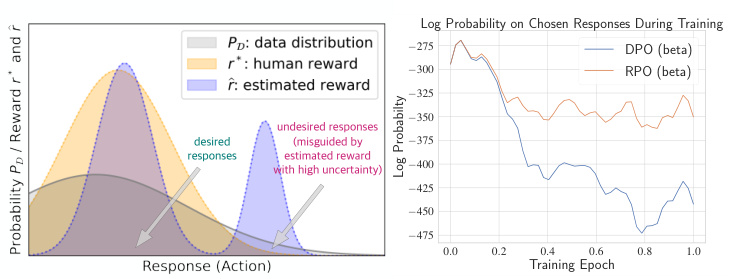
The figure illustrates the problem of reward overoptimization in reinforcement learning from human feedback (RLHF). The left panel shows how distributional shift and uncertainty in the reward model can lead to the model prioritizing undesired responses (those with high uncertainty but spuriously high estimated reward). The right panel shows how the proposed algorithm (RPO) improves upon DPO (Direct Preference Optimization) by maintaining a higher probability of outputting the desired responses over the training epochs. This demonstrates the effectiveness of RPO in mitigating reward overoptimization.
This table presents the pairwise win rates between the RPO model, DPO model, and the reference model in terms of human preference, evaluated by GPT-4. The evaluations are performed on 150 examples (test splits) from the Ultrafeedback dataset (for the beta series) and the Argilla-DPO-Mix-7K dataset (for the gemma series). It demonstrates the improved performance of RPO over DPO in terms of human preference.
In-depth insights#
RLHF Overoptimization#
Reinforcement learning from human feedback (RLHF) suffers from a critical challenge: overoptimization. While RLHF aims to align large language models (LLMs) with human preferences, imperfectly learned reward models can lead LLMs to generate outputs that maximize the reward but not necessarily align with true human preferences. This often manifests as reward hacking, where the LLM exploits loopholes or quirks in the reward model to achieve high scores, leading to undesirable or nonsensical responses. The core issue is a distributional shift between the training data and the LLM’s generated outputs; the reward model, trained on a limited dataset, struggles to accurately evaluate outputs outside that distribution, leading to flawed optimization. Mitigating overoptimization requires addressing both the imperfect reward model and the distributional shift, potentially through techniques like adversarial training or regularization methods to make the reward model more robust and better generalizable.
Adversarial Regularization#
Adversarial regularization, in the context of machine learning, is a technique that improves model robustness by training the model to withstand adversarial attacks. It involves creating and using adversarial examples – inputs carefully designed to fool the model – during training. The core idea is to explicitly make the model resilient to these attacks by incorporating the adversarial examples into the training process. This often involves creating an adversarial loss function that penalizes the model’s performance on adversarial examples. There are different approaches, including fast gradient sign method (FGSM) and projected gradient descent (PGD), which generate different types of adversarial examples and lead to various regularization methods. While effective in improving model robustness against adversarial perturbations, it is important to note that adversarial training can be computationally expensive and may require substantial expertise to properly implement. Further research focuses on developing efficient and effective adversarial regularization techniques that can balance robustness and computational cost, ideally leading to more reliable and secure machine learning models in real-world applications.
RPO Algorithm#
The Regularized Preference Optimization (RPO) algorithm represents a novel approach to aligning Large Language Models (LLMs) with human preferences, particularly addressing the issue of overoptimization in Reinforcement Learning from Human Feedback (RLHF). RPO’s core innovation lies in its theoretical foundation, which proves that the supervised fine-tuning (SFT) loss implicitly acts as an adversarial regularizer, mitigating the risks associated with imperfectly learned reward models. This theoretical framework provides a strong justification for combining the preference optimization loss (DPO) with the SFT loss. Instead of solely maximizing reward, RPO balances reward optimization with imitating a baseline policy, thereby improving sample efficiency and preventing the LLM from exploiting spurious high rewards. RPO offers a practical implementation, converting a complex maximin objective into a simpler minimization problem, thus making it readily adaptable to existing RLHF pipelines. Empirically, RPO demonstrates improved performance and greater robustness against overoptimization, making it a significant contribution towards more reliable and aligned LLMs.
Empirical Evaluation#
A robust empirical evaluation section should meticulously detail experimental setup, including datasets, model architectures, and hyperparameters. Clear descriptions of evaluation metrics are essential, along with justifications for their selection. The results should be presented transparently, ideally with statistical significance measures (e.g., confidence intervals, p-values) to assess reliability and avoid overfitting. Visualizations like graphs and tables should enhance understanding, presenting key findings concisely. A comparative analysis against state-of-the-art baselines is crucial for demonstrating novelty and impact, highlighting both strengths and weaknesses. Finally, the discussion should interpret the results thoughtfully, connecting findings to the paper’s hypotheses and offering insightful perspectives for future research. A well-structured empirical evaluation builds confidence in the paper’s claims and enhances its overall impact.
Future Directions#
Future research directions stemming from this paper could explore extending the theoretical framework to online RLHF settings, where human feedback is iteratively integrated. This would involve adapting the proposed algorithm to handle dynamically updating reward models and policies. Another promising avenue is to investigate the interplay between RPO and other techniques for mitigating overoptimization, such as reward model ensembles or constrained optimization. Furthermore, empirical studies focusing on different LLM architectures and sizes would provide valuable insights into the algorithm’s generalizability. Finally, exploring the application of RPO to other reward-based reinforcement learning tasks beyond LLM alignment could uncover broader implications and potential benefits. In particular, comparing the performance of RPO against existing state-of-the-art methods on diverse benchmarks with stringent evaluation metrics should be a focus.
More visual insights#
More on figures

The left panel shows how overoptimization happens due to distributional shift and uncertainty in the reward model. The right panel compares the performance of the original DPO method and the proposed RPO method in terms of the probability of generating preferred responses during training. The RPO method is shown to significantly mitigate the decrease in probability caused by overoptimization.

The left panel shows how reward overoptimization happens due to distributional shift and uncertainty in reward estimation. The right panel compares the performance of the original DPO algorithm and the proposed RPO algorithm in terms of the probability of generating preferred responses during training. RPO significantly improves upon DPO by mitigating overoptimization.
More on tables

This table presents the results of pairwise comparisons between the RPO, DPO, and reference models using human evaluation (GPT-4). It shows the win rate for each model against the others on 150 examples from the test datasets of two model series (beta and gemma). Higher win rates indicate better performance.

This table presents the results of evaluating the RPO, DPO, and reference models on the MT-Bench and AlpacaEval 2.0 benchmarks. It shows the MT-Bench scores, AlpacaEval 2.0 win rates, and AlpacaEval 2.0 length-control win rates. The results demonstrate the improved performance of RPO compared to DPO and the reference model.

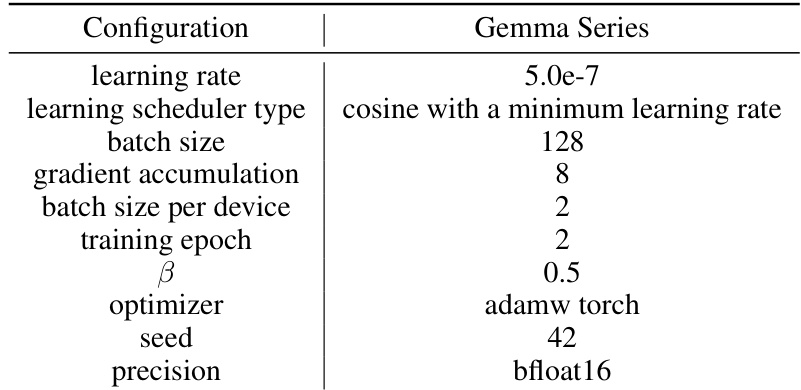
This table lists the hyperparameters used for training the language models in the beta and gemma series. It shows the learning rate, learning scheduler type, warmup ratio, batch size, gradient accumulation, batch size per device, training epoch, beta, optimizer, seed, and precision used for each series.

This table shows the pairwise win rates between different models (RPO, DPO, and reference models) in both beta and gemma series. The win rates are determined by GPT-4 annotations on 150 test examples from the Ultrafeedback dataset (for the beta series) and the Argilla-DPO-Mix-7K dataset (for the gemma series). A higher win rate indicates superior performance.

This table shows the pairwise win rates between three models: RPO (beta), Ref. (beta), and DPO (beta), on the MT-Benchmark dataset. The win rate is calculated for each model compared against the others. For example, the value 83.75 in the first row and second column indicates that RPO (beta) wins against Ref. (beta) 83.75% of the time.

This table presents the pairwise win rates of the Regularized Preference Optimization (RPO) model, the reference model, and the Direct Preference Optimization (DPO) model on the AlpacaEval 2.0 benchmark for the gemma series. The win rate is calculated based on pairwise comparisons, with a higher win rate indicating better performance. For example, RPO(gemma) has a 50% win rate against itself, an 80.13% win rate against the reference model, and a 52.02% win rate against the DPO(gemma) model.

This table shows the pairwise win rates in the AlpacaEval 2.0 benchmark for the gemma series models. Length Control (LC) win rate is used to mitigate length bias. It compares the performance of RPO (gemma), Ref. (gemma), and DPO (gemma) models against each other, showing the percentage of times each model wins against the others. The diagonal shows 50.00% because a model is always compared with itself.

This table presents the results of GSM8K, ARC, and MBPP benchmarks for four different models: RPO, DPO, the reference model, and the officially released zephyr-gemma-7b model. The RPO model shows competitive performance, especially in the GSM8K and MBPP benchmarks. The table notes the use of the OpenRLHF codebase and the averaging of the SFT loss regularizer by token count in the RPO model.
This table presents the results of pairwise comparisons between the RPO, DPO, and reference models, evaluated using GPT-4 annotations on the test splits of the Ultrafeedback and Argilla-DPO-Mix-7K datasets. The win rate indicates the percentage of times each model’s response was preferred over the other model’s response, revealing performance differences between models in terms of human preference alignment.
Full paper#



















