↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Text-to-image diffusion models struggle with generating consistent images of the same subject due to their stochastic nature. Existing methods often rely on external data or require extensive model tuning, which is computationally expensive. This paper introduces OneActor, a novel one-shot tuning paradigm that addresses these limitations by leveraging a learned semantic guidance. Instead of tuning the entire model, OneActor efficiently guides the generation process towards a consistent subject appearance using only prompts.
OneActor formalizes consistent subject generation from a clustering perspective, creating a cluster-conditioned model. To mitigate overfitting, it augments tuning with auxiliary samples and employs semantic interpolation and cluster guidance techniques. Experimental results demonstrate that OneActor outperforms existing methods in terms of subject consistency, prompt conformity, and image quality while achieving a 4x faster tuning speed and minimal inference time increase. Furthermore, OneActor’s flexibility makes it adaptable to multi-subject generation and various diffusion model extensions.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents OneActor, a novel one-shot tuning paradigm that efficiently generates consistent subject images using only prompts. This addresses a critical limitation of existing text-to-image models and offers a faster, more cost-effective solution. It opens up new avenues for research in consistent image generation and integration with various diffusion-based extensions, potentially impacting several creative and design applications. The method’s efficiency and flexibility make it highly relevant to current research trends focusing on improving the speed and quality of image generation.
Visual Insights#
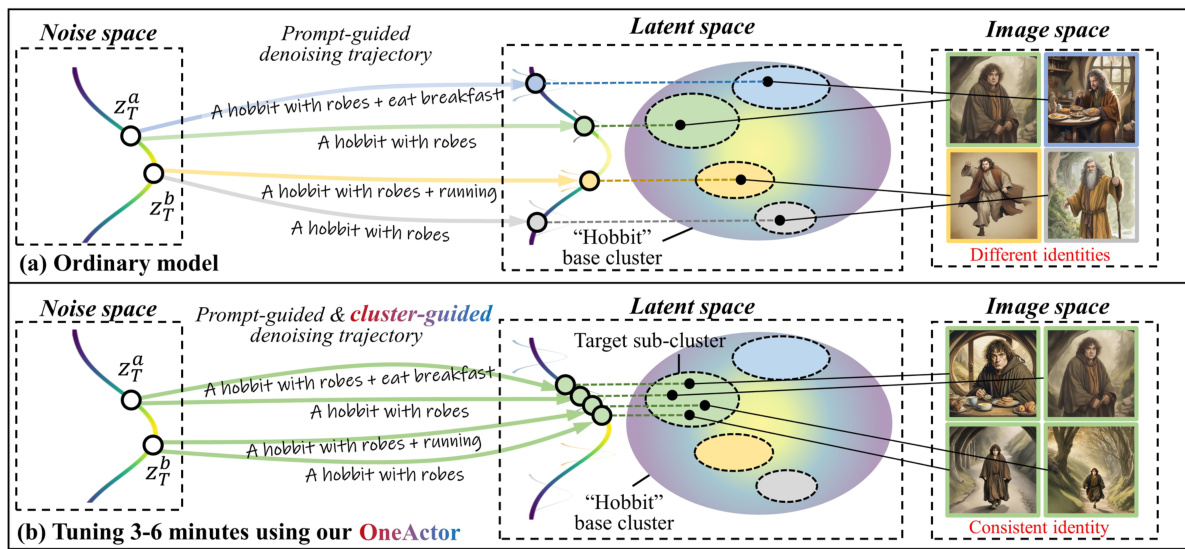
This figure illustrates the core concept of the OneActor model. Panel (a) shows how standard diffusion models generate inconsistent images of the same subject (a hobbit) due to the stochastic nature of the process and different initial noise conditions. The resulting images belong to different sub-clusters within the main ‘hobbit’ cluster in the latent space. Panel (b) demonstrates OneActor’s ability to generate consistent images by providing additional cluster-conditioned guidance during the denoising process. This guidance directs the generation towards a specific target sub-cluster, resulting in consistent images of the same subject.

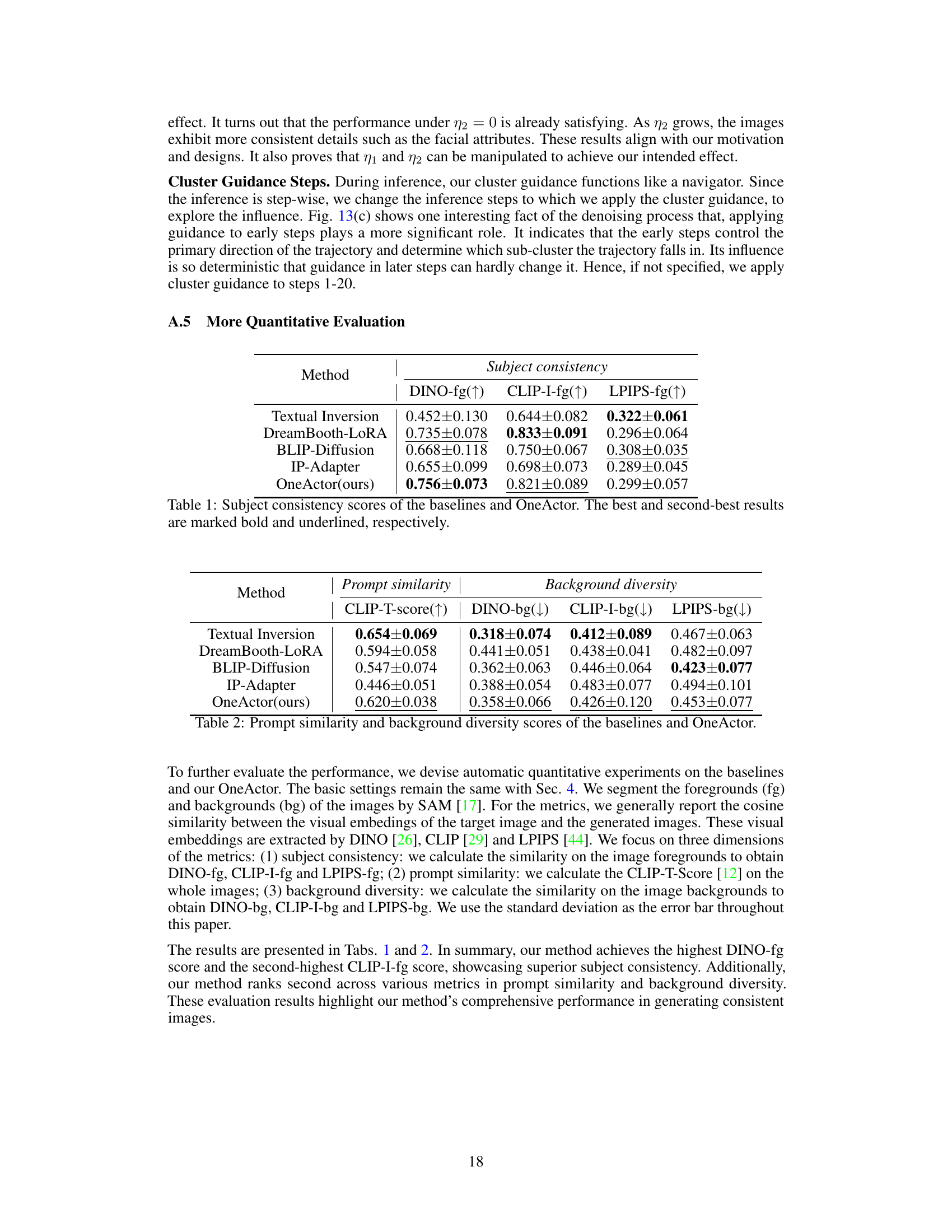
This table presents a quantitative comparison of different methods for generating consistent images of a single subject, focusing on the metric of ‘subject consistency.’ The methods compared include several personalization techniques (Textual Inversion, DreamBooth-LoRA, BLIP-Diffusion, IP-Adapter) and the proposed OneActor method. Subject consistency is evaluated using three different metrics: DINO-fg (foreground), CLIP-I-fg (foreground), and LPIPS-fg (foreground). Higher scores indicate better consistency. The table highlights OneActor’s performance relative to the baselines.
In-depth insights#
OneActor’s Tuning#
OneActor’s tuning represents a novel, efficient approach to consistent subject generation in text-to-image diffusion models. Instead of the computationally expensive method of directly tuning the backbone diffusion model, OneActor employs a learned semantic guidance module. This module acts as a ‘projector’, mapping latent representations of generated images to a semantic space, enabling a fast and targeted tuning process. The use of auxiliary samples alongside the target sample during training helps prevent overfitting, a common problem in one-shot tuning methods. Furthermore, OneActor incorporates semantic interpolation and cluster guidance strategies, enhancing both the controllability and diversity of image generation. This efficient tuning paradigm allows OneActor to achieve comparable or superior results to existing methods while significantly reducing training time, making it a more practical and scalable solution for consistent subject generation.
Cluster Guidance#
The concept of ‘Cluster Guidance’ in the context of a research paper likely refers to a method for improving the consistency and quality of generated outputs, such as images, by leveraging the underlying structure of a dataset. It suggests a technique where generated data points are steered toward specific clusters in a latent space, enhancing the coherence of the results. This likely involves learning a mapping from input features (like text descriptions) to a latent space representation, where clusters correspond to semantically similar outputs. The ‘guidance’ aspect suggests a mechanism for directing the generation process towards desired clusters, perhaps by incorporating cluster-level information into a generative model. This could be achieved through various techniques, such as using cluster centroids as targets, conditioning the generation process on cluster assignments, or incorporating cluster-based similarity measures into the loss function during training. The effectiveness hinges on the quality of the clustering itself and the ability of the guidance mechanism to effectively steer the generation process without compromising diversity or introducing artifacts.
Multi-Subject Gen#
Generating images with multiple subjects presents a significant challenge in text-to-image models. A naive approach might involve simply combining prompts, but this often leads to inconsistent or incomplete results. Effective multi-subject generation requires careful consideration of subject relationships and spatial arrangement. Methods addressing this might involve techniques like generating individual subjects and then intelligently compositing them, or leveraging advanced prompting techniques to explicitly guide the model to produce a well-integrated scene with distinct subjects. Another key factor is the balance between consistency and diversity. Maintaining consistent visual characteristics across multiple subjects while avoiding repetitive or monotonous imagery is crucial. Furthermore, the computational cost of generating multi-subject images can be substantially higher than single-subject generation, requiring efficient algorithms and architectures. Successfully navigating these challenges will involve a combination of sophisticated prompt engineering, model improvements that can handle complex scenes, and potentially novel architectures specifically designed for multi-subject image generation.
Ablation Studies#
Ablation studies systematically investigate the contribution of individual components within a model by removing or altering them. In the context of a research paper, a well-designed ablation study is crucial for understanding the model’s architecture and justifying design choices. By progressively removing parts, researchers determine the impact of each component on the overall performance. This approach helps isolate and identify critical features, separating the effects of individual elements from any synergistic interactions. A comprehensive ablation study will explore multiple variations and analyze the results to robustly support the claims made in the paper, providing evidence that the proposed method’s effectiveness is due to specific architectural choices. A thorough ablation study strengthens the conclusions by showing which elements are essential and which are less important. The results of this analysis often inform future research directions, guiding the refinement or modification of the model based on the key insights revealed through the ablation process.
Future Work#
Future research directions stemming from this work could explore several key areas. Extending the model to handle significantly more subjects simultaneously within a single image generation is crucial. Currently, the model struggles with scenes involving more than a few subjects, suggesting limitations in the capacity of the cluster-conditioned guidance mechanism or potential entanglement of latent representations for multiple subjects. Investigating different clustering strategies and potentially incorporating attention mechanisms that better isolate individual subjects could alleviate these issues. Furthermore, the model’s reliance on pre-trained diffusion models introduces potential biases and limitations related to the underlying latent space structure. Research into alternative training methodologies or integrating techniques for latent space manipulation could address this limitation, potentially leading to greater control over subject identity and style. Finally, the model’s performance on out-of-distribution subjects could be improved. Developing more robust methods for handling unseen subjects, perhaps using few-shot learning or more advanced representation learning techniques, would enhance the model’s overall versatility and robustness. Addressing these challenges is key to unlocking the full potential of this method and enabling consistent subject generation in complex scenarios.
More visual insights#
More on figures
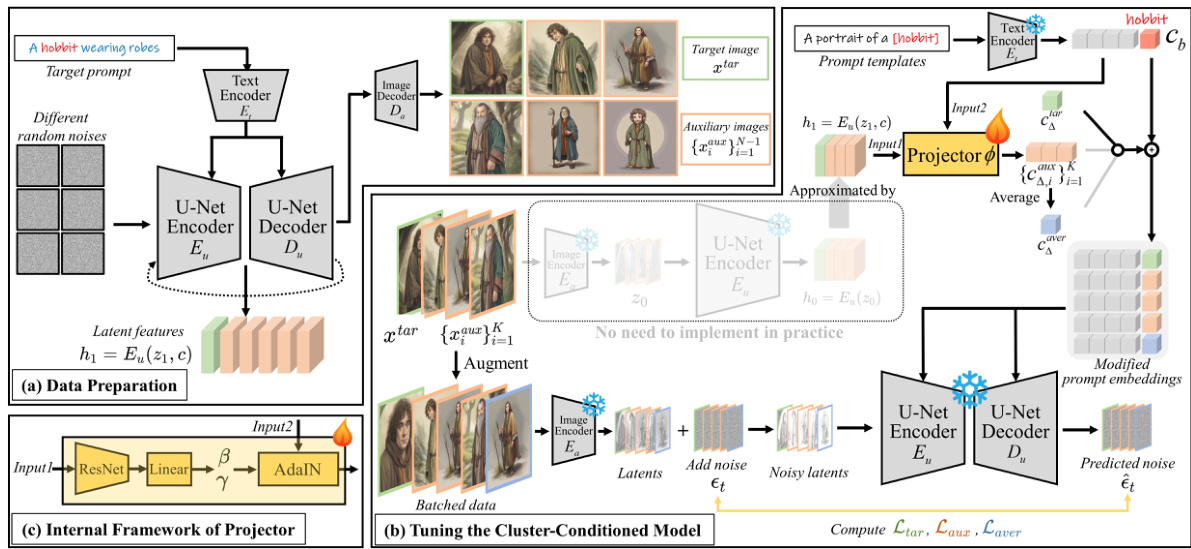
This figure illustrates the architecture of OneActor, a cluster-conditioned model for consistent subject generation. It shows the data preparation stage (a) involving the generation of base and auxiliary images from a target prompt. The tuning process (b) is detailed, showing how a cluster-conditioned model is trained using batched data. Finally, (c) presents the internal structure of the projector, a key component that processes latent codes and semantic embeddings to produce subject-specific guidance. The use of different colors highlights the data used for training various loss functions (target, auxiliary, average).

This figure demonstrates the equivalence between manipulating the latent space and the semantic space of a diffusion model for image generation. By varying the latent guidance scale (left panel) and the semantic interpolation scale (right panel), the generated images show a consistent trend, indicating that both latent and semantic manipulations have the same effect on controlling the generation process. This result supports the authors’ argument that they can precisely control the generation through semantic guidance.

This figure compares the results of different text-to-image generation methods on three different subjects (a hobbit, a cat, and an old man). The goal is to demonstrate that the proposed OneActor method generates images with better consistency and diversity than other baselines such as Textual Inversion (TI), DreamBooth (DB), IP-Adapter (IP), and BLIP-Diffusion (BL). The comparison highlights how OneActor achieves a better balance between maintaining a consistent subject appearance and generating diverse results with different prompts.

This figure compares the image generation results of different consistent subject generation methods, including OneActor and several baselines. It visually demonstrates that while all methods produce consistent images for the same subject given different prompts, OneActor generates images with superior details and finer qualities compared to the other methods, particularly in terms of clothing and other features.

This figure compares the image generation results of several baselines (Textual Inversion, DreamBooth, IP-Adapter, BLIP-Diffusion) against OneActor, all using the same prompts. The goal is to illustrate that OneActor achieves superior consistency and diversity while maintaining high image quality.
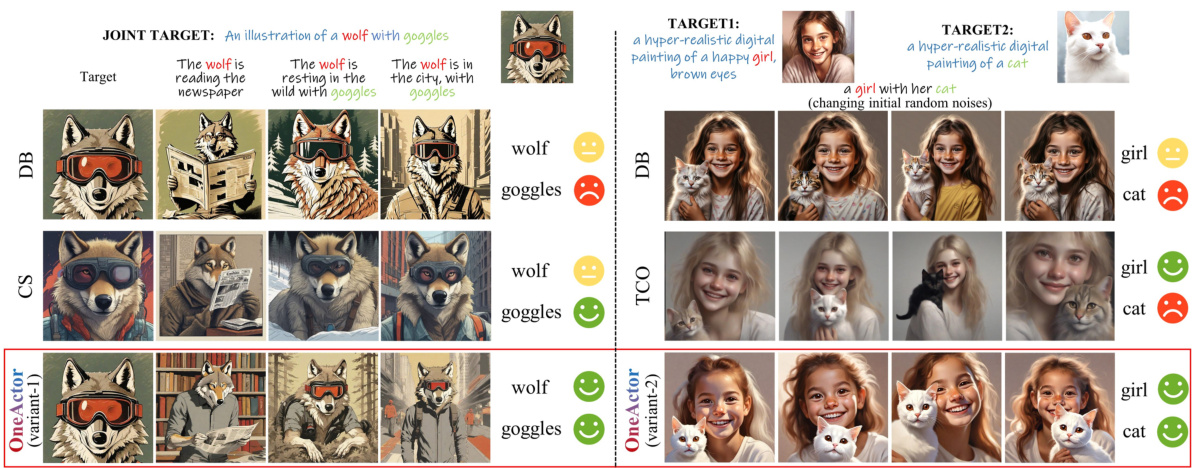
This figure compares the performance of different methods for generating images with multiple subjects. The baselines shown (CS, DB, TCO) struggle to maintain subject consistency across different generated images. OneActor’s two variants significantly improve consistency, allowing for the generation of multiple subjects that maintain consistent appearances, even when the initial random noise changes. The figure showcases examples of generating images with a wolf wearing goggles and a girl with her cat.

This figure presents a quantitative comparison of the proposed OneActor method against various baselines in terms of subject consistency and prompt similarity, using two different evaluation settings: TheChosenOne and ConsiStory. The results are visualized as scatter plots showing the trade-off between these two metrics, with OneActor demonstrating a superior performance by achieving higher prompt similarity while maintaining satisfactory subject consistency. This superior performance is highlighted by the establishment of a new Pareto front, indicating that OneActor outperforms existing methods in this multi-objective optimization problem.
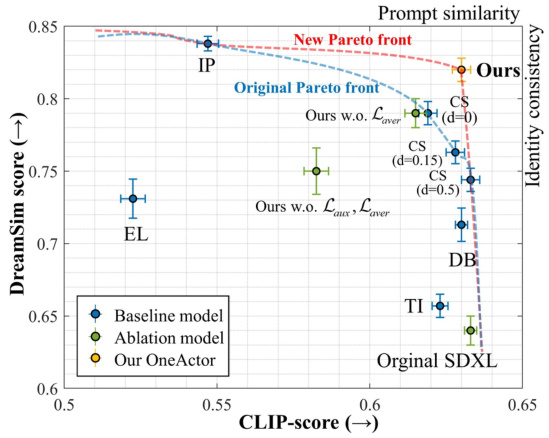
This figure shows a quantitative comparison of different methods for consistent subject generation. The plots compare identity consistency (how well the generated images match the target subject) against prompt similarity (how well the generated images reflect the given prompts). (a) shows the comparison using metrics from the TheChosenOne paper, while (b) uses metrics from the ConsiStory paper. The results indicate that OneActor achieves a new Pareto front, meaning it outperforms existing baselines across both identity consistency and prompt similarity.

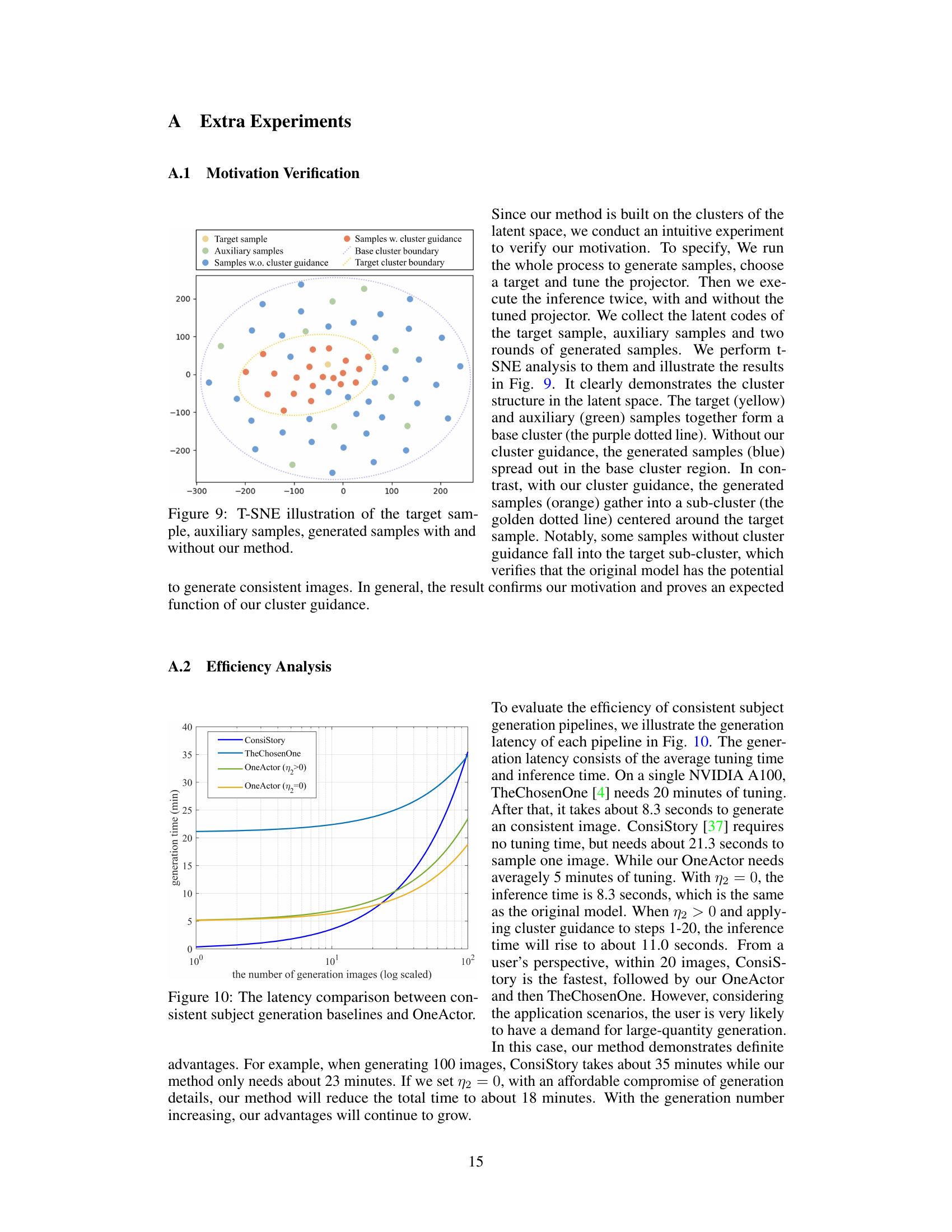
This figure uses t-distributed stochastic neighbor embedding (t-SNE) to visualize the latent space of a diffusion model. It shows the distribution of latent representations for different sets of samples: * Target sample: A single sample representing the desired subject. * Auxiliary samples: Additional samples related to the target subject, used to guide the model and prevent overfitting. * Samples w/o cluster guidance: Samples generated by the diffusion model without the proposed cluster-conditioned guidance. * Samples w/ cluster guidance: Samples generated with the proposed method, demonstrating how the guidance affects sample distribution. The plot illustrates that without guidance, samples are spread across the base cluster, while with cluster guidance, the samples are concentrated near the target sample. This demonstrates the effectiveness of the proposed method in achieving consistent subject generation.
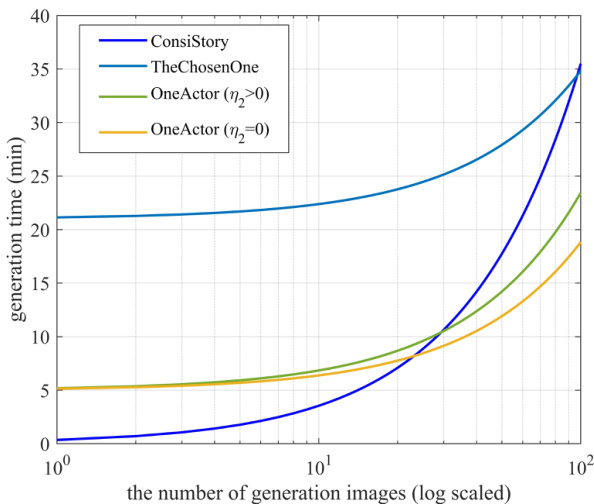
The figure shows a comparison of the generation time (in minutes) taken by different methods (ConsiStory, TheChosenOne, OneActor with η2>0, and OneActor with η2=0) as the number of generated images increases. It illustrates the efficiency gains of OneActor, particularly when generating a large number of images. The plot is on a log scale for the x-axis (number of generation images).

This ablation study evaluates the impact of each objective function component (Ltar, Laux, Laver) on the overall performance of the OneActor model. By comparing the results of the full model against versions missing one or more components, the figure demonstrates that all three objective functions are crucial for achieving high character consistency and diverse image generation. Removing even one component leads to a significant degradation in the quality and variety of generated images.

This figure shows the result of an ablation study on the semantic scale parameter (v) in the OneActor model. Different values of v were used to generate images, showing that a value of v = 0.8 provides the best balance between consistent character generation and diverse image content. Values of v lower than 0.8 result in less consistent character appearance while values higher than 0.8 generate more diverse images but reduce consistency.

This figure illustrates the core idea of OneActor. Panel (a) shows how standard diffusion models generate inconsistent images of the same subject (a hobbit) due to random noise and different prompts. The resulting images belong to different sub-clusters in the latent space, representing different variations of the subject. Panel (b) demonstrates OneActor’s ability to generate consistent images of the same subject by using a learned semantic guidance to steer the generation process towards a specific target sub-cluster in the latent space, resulting in consistent image outputs.

This figure demonstrates the style transfer application of the OneActor model. A target image is generated using a prompt that includes a style keyword. The model is then fine-tuned using this image, and then new images are generated using prompts that also include the style keyword. This showcases the model’s ability to generate consistent images across multiple prompts, maintaining the same style.

This figure illustrates the core idea of OneActor. Panel (a) shows how standard diffusion models generate inconsistent images of the same subject (a hobbit) because of their stochastic nature and the existence of multiple sub-clusters in the latent space representing different variations of the subject. Panel (b) demonstrates OneActor’s approach, where a short tuning process based on the user’s selection of a preferred image guides the model to consistently generate similar images of the same subject from the same target sub-cluster, thus improving consistency.

This figure illustrates the core concept of OneActor. Panel (a) shows how standard diffusion models generate inconsistent images of the same subject (a hobbit) due to the stochastic nature of the process and the presence of multiple sub-clusters in latent space representing different variations of the subject. Panel (b) demonstrates OneActor’s approach. After a brief tuning process, OneActor leverages cluster-conditioned guidance to consistently generate images from a single target sub-cluster, resulting in consistent depictions of the subject.

This figure shows examples of single-subject image generation using the OneActor method. Each row represents a different subject (e.g., an alien, a gentleman, a cat, a hippie, an adventurer, a teenager), with variations in the background and added elements (such as eating a burger or wearing sunglasses). The consistency of the generated images demonstrates OneActor’s ability to produce multiple images of the same subject, despite differences in added details, maintaining a consistent visual identity.

This figure illustrates the core idea of OneActor. (a) shows that ordinary diffusion models generate inconsistent images of the same subject (‘hobbit’) due to the stochastic nature of the sampling process. Different prompts and random noise lead to different sub-clusters in the latent space, resulting in different identities of the same subject. (b) shows that OneActor, after a quick tuning process, guides the denoising trajectory toward a specific sub-cluster, resulting in consistent images of the subject.

This figure illustrates the difference between ordinary diffusion models and the proposed OneActor model in generating images of a consistent subject (a hobbit). (a) shows that ordinary models, given different prompts and random noise, produce hobbits with inconsistent appearances (different identities), as indicated by the different colored sub-clusters. (b) demonstrates OneActor’s capability to generate consistent images of a hobbit (same identity sub-cluster) after a short tuning period, highlighted by the consistent color of the generated images within the same sub-cluster. The additional cluster guidance in OneActor ensures consistent subject generation.

This figure shows how the OneActor model can be used to generate consistent images for a storybook. Three different characters are initially generated using separate prompts. The model then uses a multi-subject generation approach to create images containing combinations of these characters. The consistent appearance of each character across different scenes is a key feature highlighted in this image.

This figure shows example images generated by the OneActor model for two subjects. The top row demonstrates images in a neonpunk style, showing a boy and his dog in various settings. The second row shows a realistic photo of a dog with a hat in different scenes. The third row features a digital painting of a wizard and a warrior boy. The bottom row displays a watercolor illustration of an explorer interacting with a lion.

This figure illustrates the core idea of the OneActor method. Panel (a) shows how a standard diffusion model generates inconsistent images of the same subject (a hobbit) because it samples from different sub-clusters within the latent space, which represent different variations of the subject. Panel (b) shows how OneActor, through a quick tuning process, guides the generation to a specific sub-cluster, resulting in consistent images. Different colors in the latent space represent different sub-clusters of the same subject.

This figure compares the results of different image generation methods, focusing on the consistency and diversity of the generated images. It shows that while existing personalization methods (TI, DB, IP, BL) struggle to produce consistent and diverse results, the OneActor method achieves superior performance in both areas. The images in the figure illustrate this difference, highlighting the strengths of the OneActor method.

This figure shows example images generated by the OneActor model with three subjects in each image. The model successfully generates consistent and coherent images featuring multiple subjects, demonstrating its ability to handle complex scenes and diverse subject combinations.

This figure illustrates the core concept of the OneActor model. Panel (a) shows how standard diffusion models, given different prompts about the same subject (a hobbit), produce images with inconsistent appearances due to sampling from different identity sub-clusters within the subject’s main cluster in the latent space. Panel (b) demonstrates OneActor’s improvement: after a brief tuning process, OneActor uses cluster-conditioned guidance to consistently generate images from the same target sub-cluster, resulting in consistent subject appearances across different prompts.
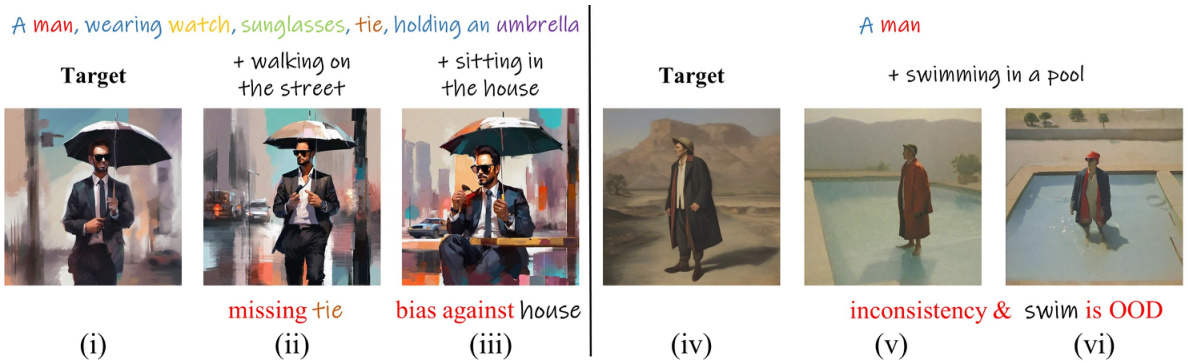
This figure demonstrates some limitations of the OneActor model. The left side shows that while the model can generate images with multiple subjects, it sometimes fails to maintain consistency in details (e.g., missing tie). The right side shows how the latent space properties of the diffusion model can introduce bias against certain contextual details (e.g., preference for outdoor settings) and out-of-distribution (OOD) issues (e.g., inability to generate a man swimming, despite having generated images of a man in other situations).
Full paper#