↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Training large language models (LLMs) is computationally expensive, especially with long sequences. Existing methods struggle to handle the memory demands of long sequences, limiting model size and performance. This often necessitates compromises like reducing sequence length, batch size or using gradient accumulation which are suboptimal solutions.
The proposed MINI-SEQUENCE TRANSFORMER (MST) addresses this by partitioning long input sequences into smaller mini-sequences and processing them iteratively. Combined with activation recomputation, MST achieves significant memory savings during both forward and backward passes without sacrificing training throughput. Extensive experiments demonstrate that MST successfully extends the maximum context length of various LLMs by 12-24x, highlighting its effectiveness and wide applicability.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) because it introduces a novel training method that significantly improves memory efficiency without sacrificing speed or accuracy. This breakthrough enables the training of LLMs with extremely long sequences, opening up new avenues for research in various applications that require extensive contextual understanding. The approach is general and easily adaptable, making it highly relevant for the broader LLM research community.
Visual Insights#

This figure illustrates the MINI-SEQUENCE TRANSFORMER (MST) architecture and its impact on maximum sequence length during training. (a) Shows a standard Transformer architecture highlighting the activation sequence length (S) in MLP and LM-Head blocks. (b) Shows the MST architecture, where the input sequence (S) is divided into smaller mini-sequences (S/M) processed iteratively, reducing memory usage. (c) Compares the maximum sequence length achievable for Llama2 and Llama3 models using standard, activation recomputation, and MST methods. MST demonstrates significant improvement in maximum sequence length without affecting throughput or convergence.

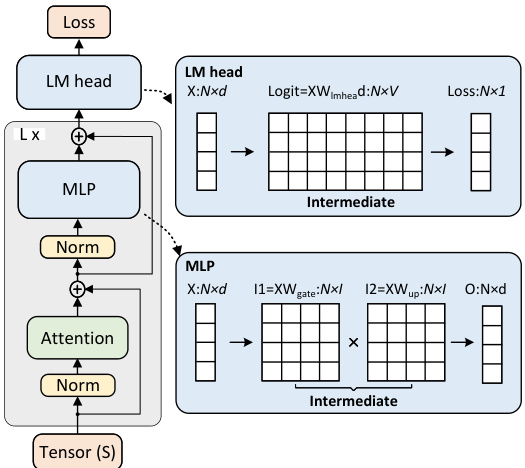
This table analyzes the peak intermediate value sizes for different transformer blocks (Attention, MLP, LM-Head) relative to their input/output sizes. It shows how much larger the intermediate values are compared to the inputs and outputs, highlighting the memory challenges associated with these blocks. The ratios are calculated specifically for the Llama3 model settings, which helps to put the memory usage in context for training large language models.
In-depth insights#
Long Seq. Training#
The research paper section on “Long Seq. Training” delves into the challenges and advancements in training large language models (LLMs) with extremely long input sequences. It highlights the memory constraints imposed by the quadratic complexity of self-attention, a critical bottleneck in processing lengthy sequences. The paper introduces and analyzes MINI-SEQUENCE TRANSFORMER (MST), a novel methodology that partitions sequences into smaller mini-sequences, reducing intermediate memory usage. MST, in combination with activation recomputation, demonstrates significant improvements in training efficiency for LLMs without compromising accuracy or convergence. Experimental results showcase impressive scaling of sequence length (12-24x longer sequences), even on single GPUs. The paper further explores the integration of MST with distributed training frameworks, enabling efficient scaling to even greater sequence lengths through enhanced memory management. Overall, the “Long Seq. Training” section presents a compelling solution to a major challenge in LLM training, paving the way for models capable of handling substantially longer contexts.
MST Algorithm#
The MINI-SEQUENCE TRANSFORMER (MST) algorithm is a memory-efficient method for training large language models (LLMs) on extremely long sequences. It addresses the challenge of high intermediate memory usage in standard transformer architectures by partitioning the input sequence into smaller mini-sequences. This partitioning significantly reduces the intermediate memory footprint of both forward and backward passes, enabling the training of LLMs with much longer sequences than previously possible. The algorithm integrates seamlessly with existing LLM training frameworks and requires minimal code changes. Furthermore, MST leverages activation recomputation to further reduce memory overhead without significant performance degradation. This combination of techniques makes MST a powerful approach to scaling LLM training to much longer context windows, thus improving the performance on tasks involving long sequences.
Memory Efficiency#
The research paper significantly emphasizes memory efficiency in training large language models (LLMs). It introduces MINI-SEQUENCE TRANSFORMER (MST), a novel technique to reduce memory consumption by partitioning input sequences and iteratively processing mini-sequences. MST’s effectiveness is demonstrated through experimental results, showing no degradation in throughput or convergence even with significantly longer sequences. The approach integrates seamlessly with activation recomputation, further enhancing memory savings. Key to MST’s success is its layer-agnostic nature, enabling adaptability to various LLM architectures and minimizing code changes for integration. The analysis provides both theoretical and empirical evidence to highlight the benefits of MST in terms of memory optimization compared to standard LLMs and other optimized methods. The authors showcase the scalability and generalizability of MST across various platforms and distributed settings. Limitations are acknowledged, specifically regarding potential performance tradeoffs for shorter sequences and the dependency on existing deep learning frameworks, prompting avenues for future research.
Distrib. Extension#
The heading ‘Distrib. Extension’ likely refers to the section in the research paper that discusses how the proposed method, MINI-SEQUENCE TRANSFORMER (MST), can be effectively scaled for distributed training across multiple GPUs. This is a crucial aspect of training large language models (LLMs) as it allows the handling of models and datasets that exceed the memory capacity of a single device. The authors probably detail strategies for efficient parallelization and communication between GPUs, potentially leveraging techniques like sequence parallelism to split the input sequence among multiple devices and minimize communication overhead. DeepSpeed-Ulysses is possibly mentioned as a key framework to enable large-scale distributed training with MST. A detailed analysis of the scalability and performance of the distributed implementation across varying numbers of GPUs would likely be included. Strong emphasis is placed on achieving linear scaling of sequence length with the number of GPUs used, demonstrating high efficiency. The section may also include experimental results comparing MST’s performance in a distributed setting against other established approaches.
Future Works#
Future work for mini-sequence transformers (MST) could involve several key areas. Extending MST to other transformer architectures beyond the MLP and LM-Head blocks would broaden its applicability. This includes integrating MST with various attention mechanisms (sparse, linear, etc.) to further optimize memory usage for diverse models. Investigating the optimal mini-sequence size (M) for different model sizes and sequence lengths is crucial for maximizing efficiency and throughput. Currently, while the paper provides some guidance, a more in-depth study using a wider range of models would be beneficial. Exploration of hardware-specific optimizations leveraging features like tensor cores could significantly enhance performance. Additionally, combining MST with other memory-saving techniques such as quantization and activation recomputation warrants investigation. Finally, a comprehensive empirical evaluation across a broader array of LLMs and benchmark datasets would solidify the claims and assess MST’s generalizability.
More visual insights#
More on figures
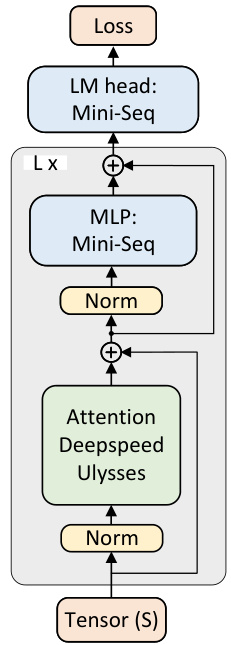
This figure shows the architecture of the distributed MINI-SEQUENCE TRANSFORMER (MST). It illustrates how MST integrates with DeepSpeed-Ulysses for sequence parallelism. The input sequence (S) is partitioned across multiple devices, and each device processes mini-sequences. The attention block uses DeepSpeed-Ulysses for efficient communication, while the MLP and LM-Head blocks utilize the mini-sequence technique. The figure highlights the parallel processing and distributed computation of the various components of the model.

This figure compares the memory usage of training Llama3-8B and Gemma2-9B models with different optimization techniques. It shows the memory breakdown for weights, optimizer, gradients, and activations for vanilla training (BF16), activation recomputation, and MST, demonstrating how MST reduces memory consumption significantly, enabling longer sequence training.
This figure illustrates the standard transformer architecture and the proposed Mini-Sequence Transformer (MST). Panel (a) shows a conventional transformer with its components: attention, normalization, MLP, and LM head. Panel (b) displays the MST architecture, highlighting how it partitions the input sequence into smaller mini-sequences to reduce memory usage. Panel (c) presents a graph showing maximum sequence lengths achieved with different model configurations (Llama2, Llama3) on A100-80GB GPUs, emphasizing that MST allows for significantly longer sequences without sacrificing performance.

This figure compares the memory usage of training Llama3-8B and Gemma2-9B models with different optimization techniques. It shows a significant reduction in memory usage when using MINI-SEQUENCE TRANSFORMER (MST), especially for Gemma2-9B, demonstrating the effectiveness of MST in enabling longer sequence training.
This figure visualizes the memory usage during the pre-training of Llama3-8B and Gemma2-9B language models. It compares memory consumption across three scenarios: a standard approach (vanilla), an approach using activation recomputation, and an approach using both activation recomputation and the proposed MINI-SEQUENCE TRANSFORMER (MST) method. The models were trained with a batch size of 1 on a single A100 GPU. The bars represent the peak memory used during the training process. It highlights that MST significantly reduces memory usage, particularly when combined with activation recomputation, enabling the training of much longer sequences.

This figure compares the memory usage during the pre-training of Llama3-8B and Gemma2-9B models. The models are trained with a batch size of 1 on a single A100 GPU. Three different scenarios are shown: vanilla training (no optimizations), training with activation recomputation, and training with both activation recomputation and the proposed MINI-SEQUENCE TRANSFORMER (MST) method. The bars illustrate the relative contribution of parameters, optimizer states, gradients, and activations to the total memory usage. Notably, gradients are not shown as they overlap with the activation memory in long-sequence training. The visualization highlights how MST significantly reduces memory consumption compared to vanilla and activation recomputation only methods.
This figure compares the memory usage of training Llama3-8B and Gemma2-9B models under different memory optimization strategies. It shows that the MINI-SEQUENCE TRANSFORMER (MST) significantly reduces the memory consumption compared to using activation recomputation alone or standard training. The results highlight MST’s effectiveness in enabling the training of very long sequences on a single GPU.

This figure compares the memory consumption during the pre-training of Llama3-8B and Gemma2-9B language models. It illustrates the memory usage breakdown for different components: weights, optimizer, gradients and activations. The comparison is shown for three scenarios: vanilla (standard) training, training with activation recomputation, and training with the proposed Mini-Sequence Transformer (MST) along with activation recomputation. The figure highlights how MST significantly reduces memory usage, especially for Gemma2-9B, enabling the training of much longer sequences.
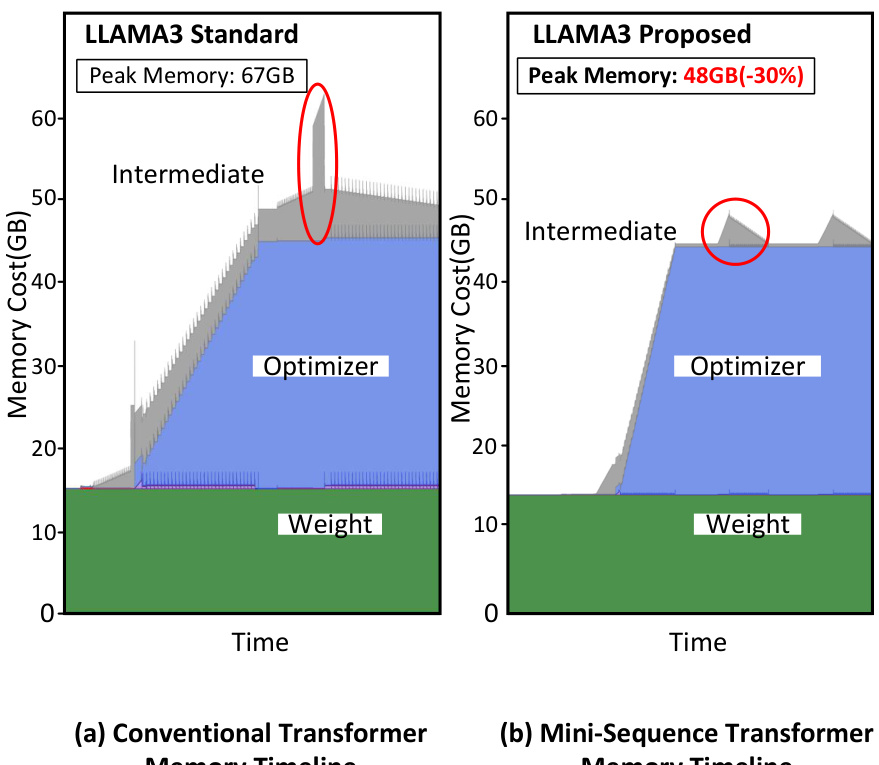
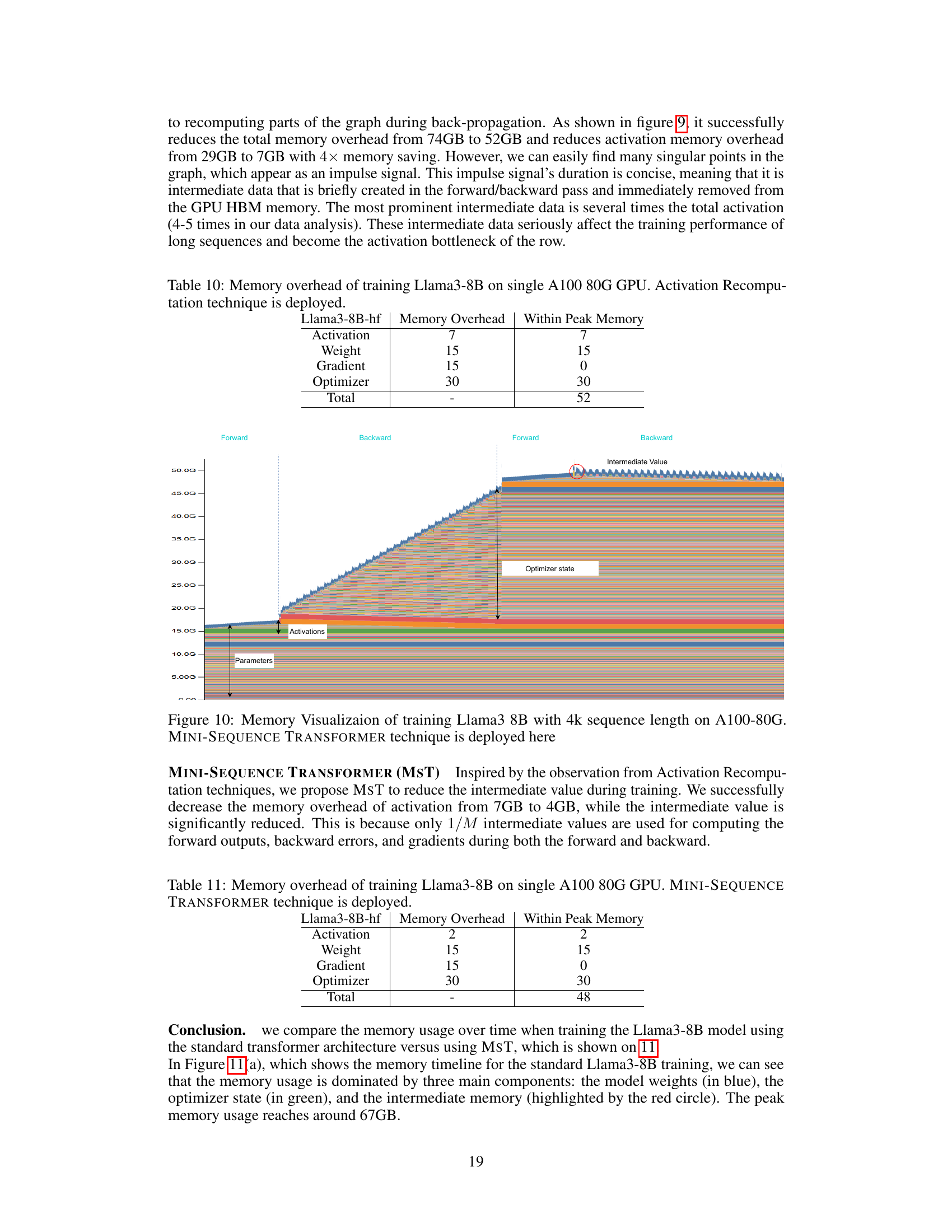
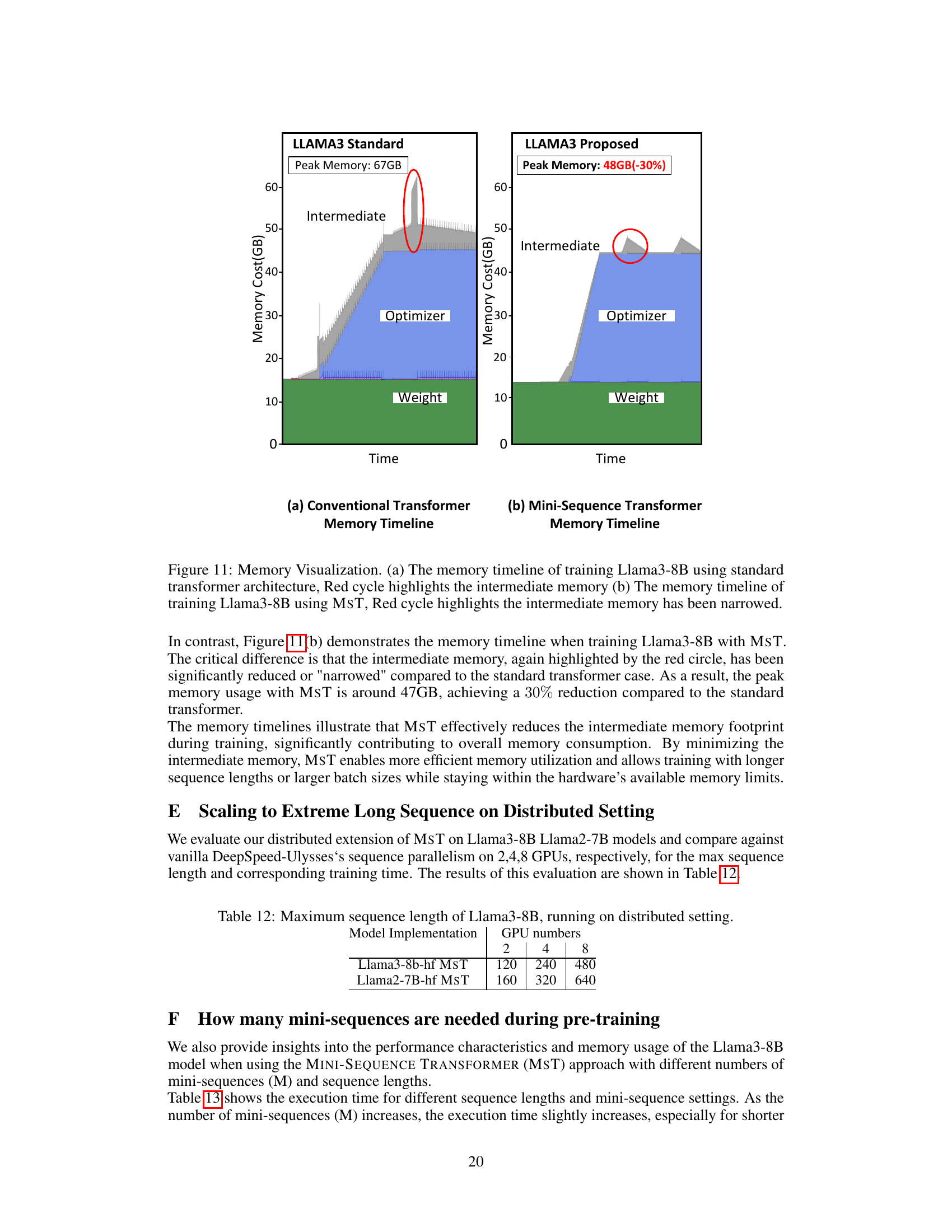
This figure compares memory usage over time for training Llama3-8B using the standard transformer versus using MST. The standard transformer shows a peak memory usage of 67GB, dominated by intermediate memory, optimizer state, and weights. In contrast, MST significantly reduces the intermediate memory, resulting in a peak memory usage of only 48GB (a 30% reduction).
More on tables
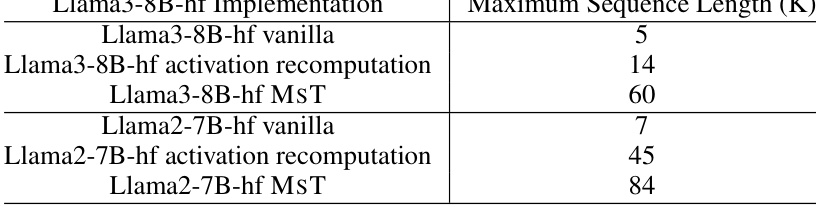
This table compares the maximum sequence lengths achieved for Llama3-8B and Llama2-7B models using three different training methods: vanilla PyTorch, activation recomputation, and the proposed MINI-SEQUENCE TRANSFORMER (MST). It demonstrates the significant increase in maximum sequence length enabled by MST compared to the standard implementation and activation recomputation alone, highlighting the effectiveness of MST in handling extremely long sequences during training.

This table presents the maximum sequence length achieved by three different models (Mistral-7B, Qwen2-7B, and gemma-2-9b) using three different training methods: vanilla, activation recomputation, and MST (MINI-SEQUENCE TRANSFORMER). The results show a significant increase in maximum sequence length when using MST compared to the other two methods.

This table compares the maximum sequence length achieved by different training methods (vanilla, activation recomputation, and MST) for Llama3-8B and Llama2-7B models. It shows a significant increase in maximum sequence length when using MST, demonstrating its effectiveness in handling longer sequences.

This table compares the maximum sequence length achieved by different Llama3 implementations on a single A100 GPU. The implementations include standard 8-bit and 4-bit quantization, as well as the proposed MINI-SEQUENCE TRANSFORMER (MST) alone and in combination with 8-bit and 4-bit quantization. The results demonstrate that MST significantly improves the maximum sequence length achievable, particularly when combined with quantization techniques.
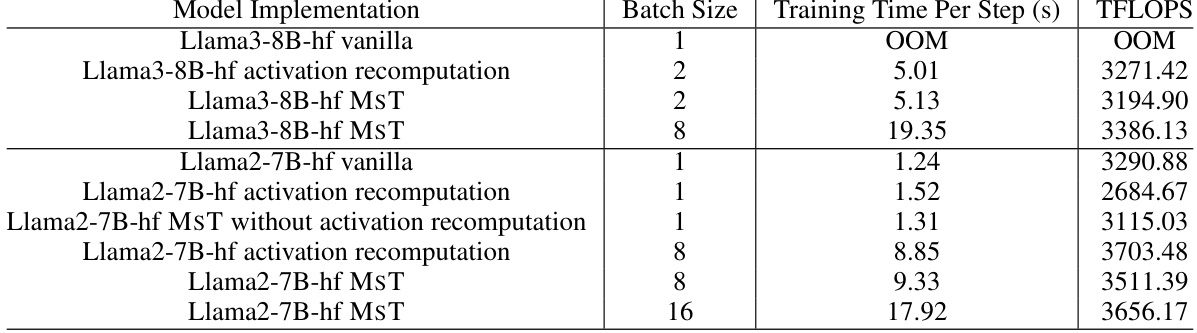
This table compares the training performance of MST against the vanilla PyTorch implementation and activation recomputation for Llama3-8B and Llama2-7B models. The metrics compared are training time per step and TFLOPS achieved using different batch sizes. It highlights MST’s ability to maintain comparable performance while enabling the use of larger batch sizes due to its memory efficiency.

This table presents the results of training Llama3-8B with different context lengths and methods. It compares the performance of training with activation recomputation and MST (Mini-Sequence Transformer) on the LongAlpaca dataset. The metrics evaluated are perplexity (ppl) and loss, along with the training time required for each configuration. The table demonstrates MST’s capability of handling much longer context lengths (up to 30k) while maintaining or improving performance compared to activation recomputation (8k).

This table compares the maximum sequence length achieved by different implementations of Llama3-8B and Llama2-7B models using Hugging Face. The implementations include the vanilla PyTorch implementation, the implementation with activation recomputation, and the implementation with MINI-SEQUENCE TRANSFORMER (MST). The results show that MST significantly increases the maximum sequence length compared to the other implementations, indicating its effectiveness in handling long sequences.
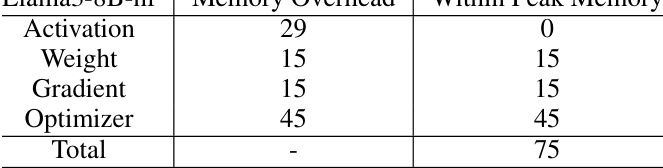
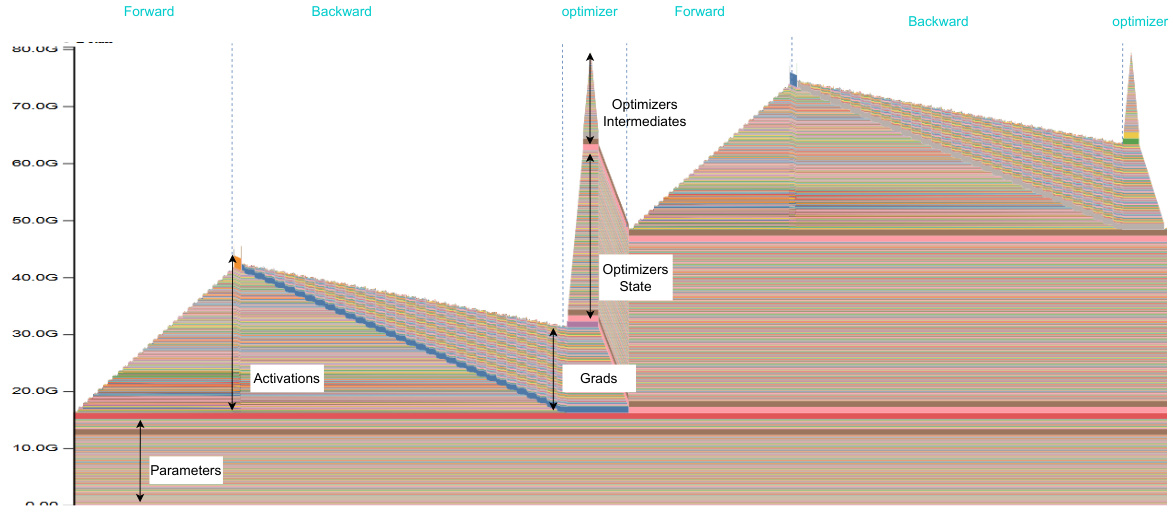
This table shows a breakdown of memory usage during the training of the Llama3-8B model on a single A100 80G GPU using the vanilla PyTorch implementation. It lists the memory overhead for different components such as weights, activations, gradients, and optimizer, both separately and as the total peak memory usage. It provides context for understanding the memory optimization strategies introduced later in the paper.

This table shows a breakdown of memory usage during the training of the Llama3-8B model on a single A100 80G GPU when using the ‘optimizer-in-backward’ technique. It lists the memory overhead for activations, weights, gradients, and the optimizer, and shows the total peak memory usage. The optimizer-in-backward technique combines the optimizer update with the backward pass. Note that gradients are not shown because they overlap with activations.

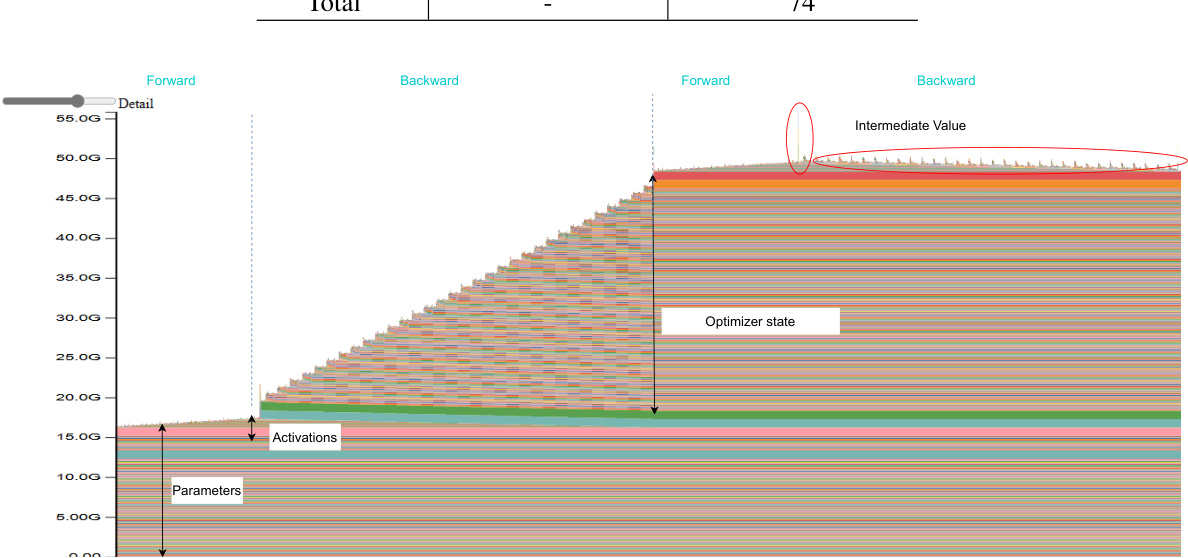
This table presents the memory usage breakdown during Llama3-8B training on a single A100 80G GPU, using the Activation Recomputation technique. It shows the memory overhead for different components: Activation, Weight, Gradient, and Optimizer. The ‘Total’ column indicates the peak memory usage. Activation recomputation is employed, resulting in a significant reduction of activation memory overhead, and the gradient is computed and released immediately after use, hence no memory overhead.
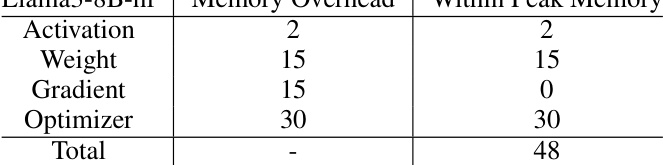
This table shows a breakdown of memory usage during the training of the Llama3-8B model using the MINI-SEQUENCE TRANSFORMER (MST) technique on a single A100 80G GPU. It lists the memory overhead for activations, weights, gradients, and the optimizer, as well as the total peak memory usage. The MST technique is designed to reduce memory overhead, particularly for activations and intermediate values.
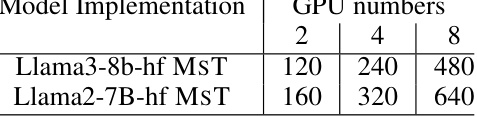
This table shows the maximum sequence length achieved by Llama3-8B and Llama2-7B using MST with different numbers of GPUs. The results demonstrate the scalability of MST for training with extremely long sequences on distributed hardware.

This table presents the execution time of the LM-head component for various sequence lengths (1024, 2048, 4096, 8192, 20000, 40000, 80000) under different mini-sequence settings (M=2, 4, 8, 16, 32). It demonstrates the effect of the mini-sequence technique on the computational time, comparing it to the standard implementation (standard). The results show that while increasing the number of mini-sequences may slightly increase the execution time for shorter sequences, the difference becomes negligible for longer sequences.
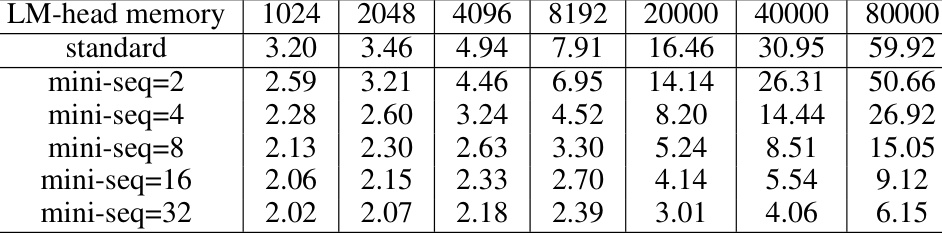
This table presents the memory usage in gigabytes (GB) for the LM-Head component of the model, considering different sequence lengths and various mini-sequence settings. It demonstrates how the memory usage decreases as the number of mini-sequences increases, showcasing the memory efficiency gains achieved by using mini-sequences in processing long sequences.

This table presents the execution time of the MLP component in the MINI-SEQUENCE TRANSFORMER (MST) model for various sequence lengths (1024, 2048, 4096, 8192, 20000, 40000, 80000) and different numbers of mini-sequences (M). It demonstrates the impact of the number of mini-sequences on the MLP’s execution time. The results show that increasing the number of mini-sequences generally leads to slightly longer execution times, particularly for shorter sequences, but the effect is less pronounced for longer sequences.

This table presents the memory usage in gigabytes (GB) for the MLP component of the model when using different sequence lengths and numbers of mini-sequences. The ‘standard’ row shows the memory usage without employing the mini-sequence technique. Subsequent rows demonstrate the memory usage when using 2, 4, 8 mini-sequences respectively. It helps to visualize the memory efficiency improvement achieved by using mini-sequences, especially for longer sequences.
Full paper#