↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current LLM alignment techniques primarily use pairwise human preference comparisons, neglecting distributional aspects. This leads to suboptimal alignment and a lack of robustness. The reliance on paired data also limits applicability. Furthermore, existing methods often lack theoretical guarantees on their convergence and sample complexity.
This paper proposes Alignment via Optimal Transport (AOT), a novel method for distributional preference alignment of LLMs. AOT cleverly uses optimal transport to align models on unpaired preference data, by making the reward distribution of positive samples stochastically dominant over the negative samples. This approach, surprisingly, has a closed-form solution and demonstrates superior empirical performance compared to existing methods, especially for models of size 7B. The sample complexity analysis provides theoretical guarantees on the method’s convergence rate.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on LLM alignment because it introduces a novel method, Alignment via Optimal Transport (AOT), that achieves state-of-the-art results, especially in the 7B family of models. AOT addresses the limitations of existing methods by focusing on distributional preference alignment, which is more robust than pairwise comparisons. This opens up new avenues for research into more efficient and effective LLM alignment techniques. The analysis of sample complexity further enhances the method’s applicability and reliability.
Visual Insights#
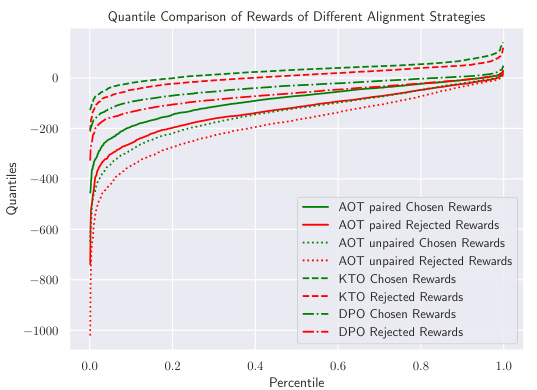
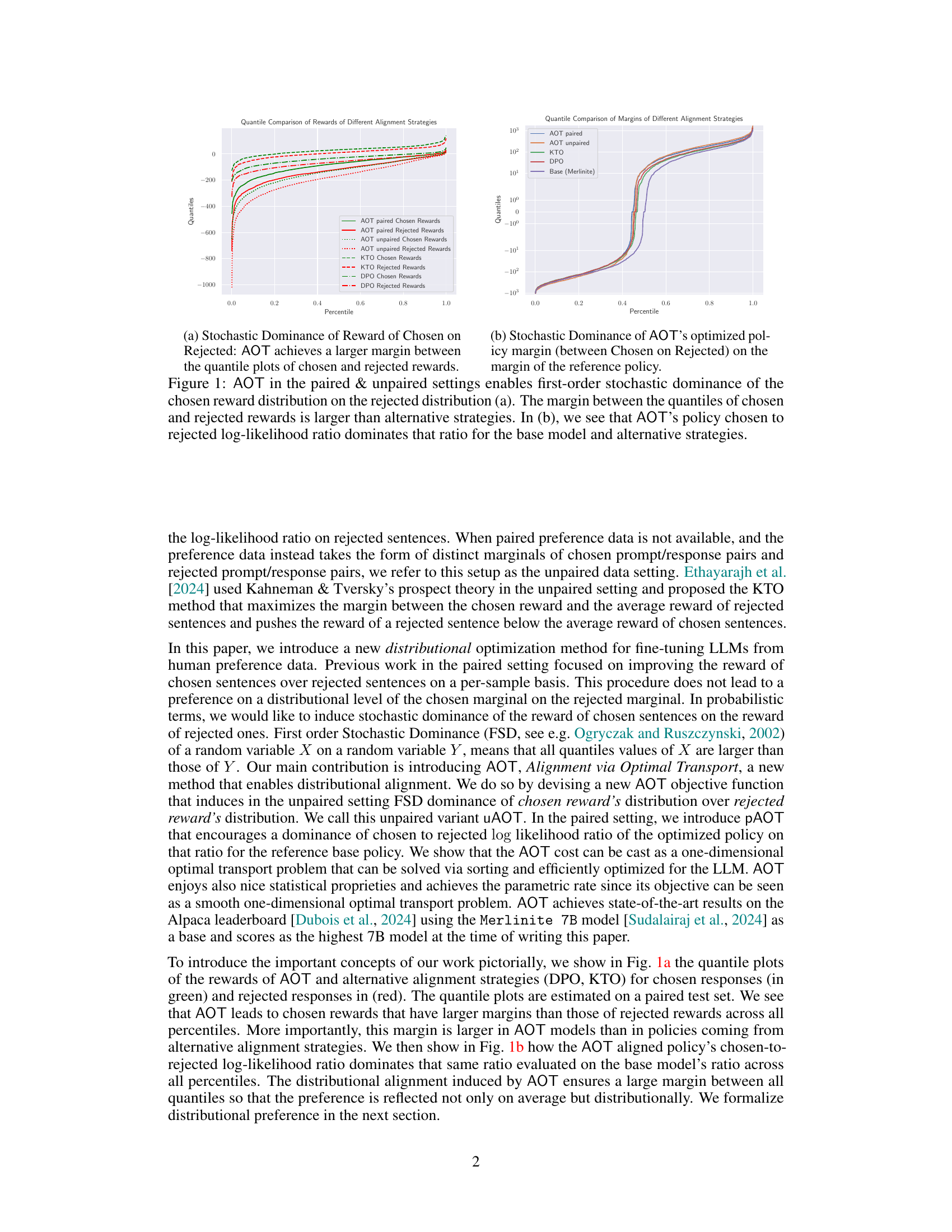
This figure shows two plots that illustrate the effectiveness of the proposed Alignment via Optimal Transport (AOT) method. Plot (a) compares the quantile plots of chosen and rejected rewards for AOT (both paired and unpaired versions), KTO, and DPO. It demonstrates that AOT achieves a larger margin between the quantiles of chosen and rejected rewards, indicating a stronger stochastic dominance of chosen rewards over rejected rewards. Plot (b) further compares the chosen-to-rejected log-likelihood ratio of AOT’s policy against the base model and other strategies. It shows that AOT’s policy ratio dominates the ratios of the others across all quantiles.
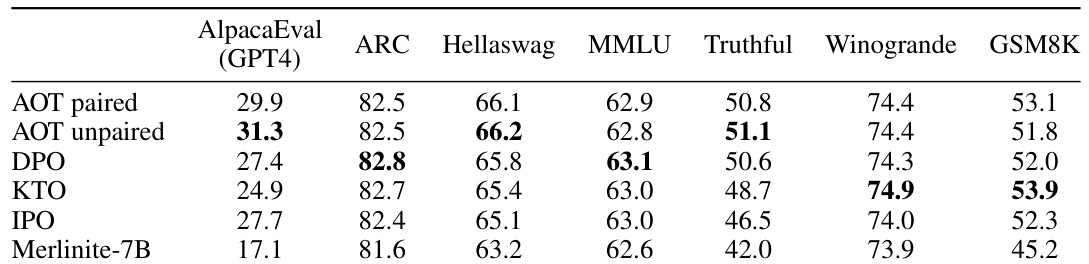
This table presents the results of evaluating the performance of different Large Language Model (LLM) alignment algorithms on various benchmark datasets. The algorithms compared include Alignment via Optimal Transport (AOT), Direct Preference Optimization (DPO), Kahneman-Tversky Optimization (KTO), and Identity Policy Optimization (IPO). The base LLM used in this experiment is Merlinite-7B, and the dataset used is the UltraFeedback Binarized dataset. The table shows the performance scores for each algorithm on several metrics, including AlpacaEval, ARC, Hellaswag, MMLU, TruthfulQA, Winogrande, and GSM8K. The results highlight that AOT achieves state-of-the-art performance on AlpacaEval compared to other methods.
In-depth insights#
Optimal Transport#
The concept of Optimal Transport (OT) is a powerful mathematical framework for measuring the distance between probability distributions. In the context of aligning Large Language Models (LLMs), OT offers a unique approach to distributional preference alignment. Unlike traditional methods that focus on pairwise comparisons, OT enables the direct comparison of reward distributions obtained from positive and negative samples. By formulating the alignment problem as an OT problem, the authors leverage the inherent structure of OT to penalize the violation of first-order stochastic dominance. This framework offers a smooth and convex cost function leading to closed-form solutions and efficient fine-tuning. The use of OT in this context provides a strong theoretical grounding for distributional alignment, enabling the development of novel and effective LLM alignment strategies. Sample complexity analysis is also performed, highlighting the efficiency and convergence properties of the proposed method. This innovative application of OT showcases its potential as a powerful tool for achieving robust and principled LLM alignment.
Distributional Alignment#
Distributional alignment in LLMs seeks to move beyond pairwise comparisons of model outputs and instead focuses on aligning the entire probability distributions of model responses. This is a crucial step because pairwise methods only address point estimates and ignore the broader uncertainty inherent in LLM generation. Aligning distributions ensures that the model’s outputs not only satisfy individual preferences but also maintain a consistent level of quality and safety across diverse situations. Methods like optimal transport provide a powerful framework for achieving distributional alignment by minimizing the discrepancy between the distributions of positive and negative samples. The success of distributional alignment hinges on having adequate and representative datasets that capture the nuances of desired behaviors and avoiding undesirable ones. This approach promises more robust and generalizable alignment than pointwise methods, leading to LLMs that are less prone to unexpected or harmful outputs.
LLM Fine-tuning#
LLM fine-tuning, as discussed in the research paper, is a crucial technique for aligning large language models (LLMs) with human preferences. The paper explores various methods, particularly focusing on distributional preference alignment, contrasting it with traditional pairwise approaches. Optimal Transport (OT) is presented as a novel and efficient method to address the challenge of aligning reward distributions, allowing for stochastic dominance of positive samples over negative ones. This approach offers a significant advancement by moving beyond sample-level alignment to a distributional level, leading to more robust and generalizable results. The implementation details, including the choice of loss functions and the use of sorting or soft-sorting algorithms for computational efficiency, highlight the practicality and scalability of the proposed method. Empirical results demonstrate state-of-the-art performance, surpassing other alignment strategies on benchmark datasets, validating the effectiveness of the distributional approach. The analysis of sample complexity further solidifies the theoretical foundation of the proposed method, offering insights into the generalization capabilities of the fine-tuning process. The study also investigates the impact of various hyperparameters, such as batch size and loss function, providing valuable guidance for practitioners. Overall, the research significantly advances LLM fine-tuning techniques by introducing a novel, efficient, and theoretically well-founded distributional alignment approach, setting a new standard for aligning LLMs with human preferences.
Stochastic Dominance#
The concept of stochastic dominance is crucial to the paper’s methodology. It provides a distributional comparison of reward distributions between positive and negative samples generated by an LLM. Instead of merely comparing average rewards (as in many previous methods), the authors use stochastic dominance to ensure the positive samples’ rewards are consistently higher across all quantiles. This is a more robust measure of preference alignment, as it considers the entire distribution and not just the mean. First-order stochastic dominance is specifically employed, guaranteeing that the cumulative distribution function of positive rewards is always above that of negative rewards. This is computationally efficient to implement using a sorting-based method because the optimal transport problem simplifies due to the one-dimensional nature of the reward space. The use of stochastic dominance is innovative in the context of LLM alignment, ensuring that the alignment is distributional and not merely a consequence of achieving high average reward. The strength of the proposed approach is directly linked to the strength and robustness of this distributional criterion.
AOT: Unpaired Setting#
The unpaired setting in Alignment via Optimal Transport (AOT) presents a significant advancement in large language model (LLM) alignment. Unlike paired approaches that rely on comparing chosen and rejected responses for a given prompt, AOT’s unpaired setting leverages separate distributions of positive and negative samples. This is crucial because real-world preference data is rarely neatly paired. The method elegantly addresses this limitation by focusing on the distributional dominance of positive reward samples over negative ones. Using optimal transport, AOT ensures that the quantiles of reward distribution in positive samples are stochastically dominant over those in negative samples. This distributional perspective provides a more robust and generalizable alignment than pointwise comparisons. The technique’s computational efficiency is enhanced by the one-dimensional optimal transport problem’s closed-form solution via sorting, making it scalable for practical LLM alignment. The theoretical analysis of the AOT unpaired setting demonstrates its convergence properties, offering a strong foundation for its practical applications. The overall approach promises more robust and efficient LLM alignment in scenarios with unpaired or limited preference data.
More visual insights#
More on figures
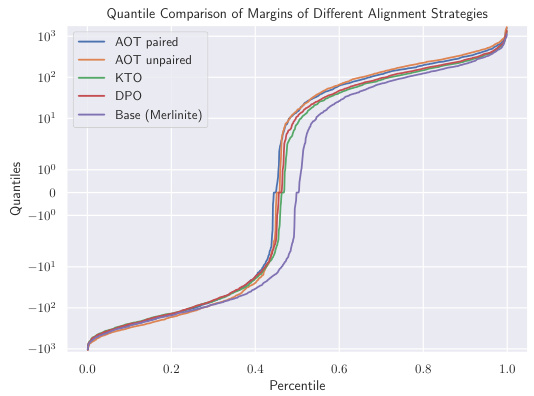
This figure shows the results of AOT (Alignment via Optimal Transport) compared to other alignment strategies (DPO, KTO) in both paired and unpaired settings. Subfigure (a) demonstrates that AOT achieves a larger margin between chosen and rejected rewards across all percentiles, indicating a stronger distributional preference. Subfigure (b) shows that AOT’s optimized policy results in a higher log-likelihood ratio for chosen versus rejected sentences compared to the baseline model and other strategies.

This figure presents a comparison of AOT’s performance against other alignment strategies in both paired and unpaired settings. Subfigure (a) shows quantile plots of chosen and rejected rewards, demonstrating AOT’s superior ability to create a larger margin between the two distributions. Subfigure (b) displays the log-likelihood ratios of chosen versus rejected responses, highlighting that AOT’s policy consistently outperforms the base model and other strategies.

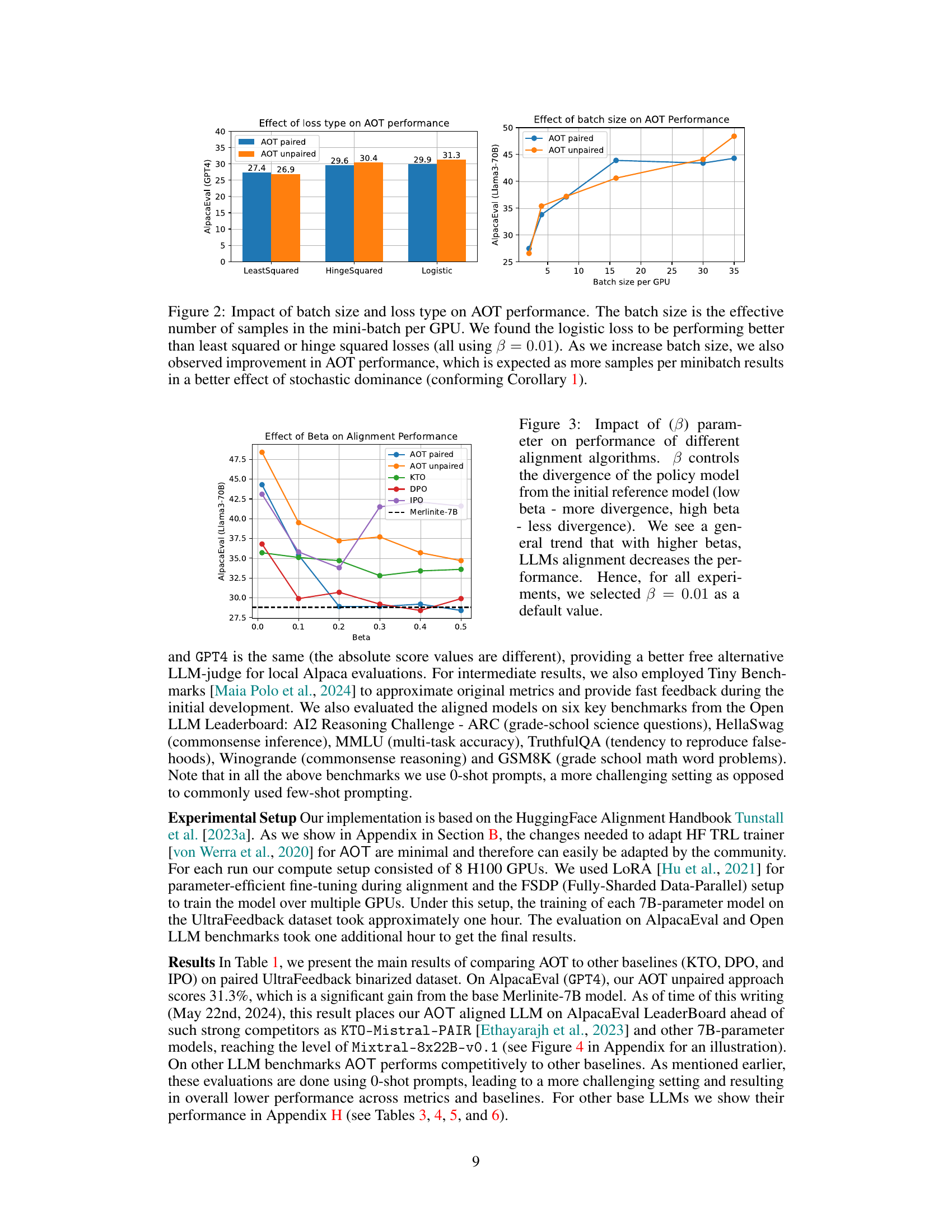
This figure shows the effect of the hyperparameter beta (β) on the performance of different LLM alignment algorithms, including AOT (paired and unpaired), KTO, DPO, and IPO. Beta controls the divergence of the optimized LLM policy from the initial reference policy; a lower beta allows for greater divergence, while a higher beta enforces closer adherence to the reference policy. The results indicate a general trend of decreasing alignment performance as beta increases. Therefore, a default value of β = 0.01 was selected for subsequent experiments. The plot displays the AlpacaEval (Llama3-70B) scores for each algorithm across different beta values.
More on tables

This table presents the results of evaluating the performance of different large language model (LLM) alignment algorithms. The algorithms were evaluated on the Merlinite-7B LLM after training on the UltraFeedback Binarized dataset. The table compares AOT (Alignment via Optimal Transport) to several other algorithms (DPO, KTO, IPO) across multiple benchmarks (AlpacaEval, ARC, Hellaswag, MMLU, TruthfulQA, Winogrande, GSM8K). AOT shows the best performance on AlpacaEval and competitive results on other benchmarks, indicating its effectiveness in aligning LLMs.

This table presents the performance of different LLM alignment approaches on the OpenHermes-2.5-Mistral-7B model, which was fine-tuned using the UltraFeedback Binarized dataset. The results are benchmarked across multiple metrics including AlpacaEval, ARC, HellaSwag, MMLU, TruthfulQA, Winogrande, and GSM8K. AOT demonstrates a significant improvement over the baseline model and other alignment techniques.
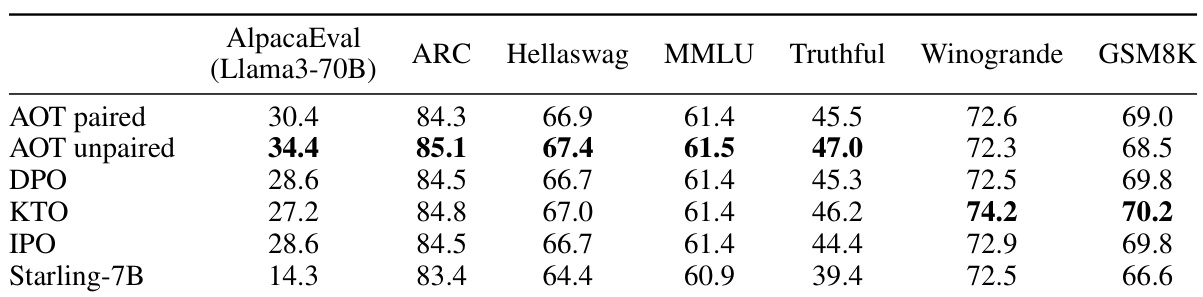
This table presents the performance comparison of different Large Language Model (LLM) alignment algorithms using the Merlinite-7B model trained on the UltraFeedback Binarized dataset. The algorithms compared are AOT (paired and unpaired), DPO, KTO, and IPO. The evaluation is performed across several benchmarks including AlpacaEval, ARC, Hellaswag, MMLU, TruthfulQA, Winogrande, and GSM8K. The results demonstrate that AOT achieves the best overall performance, particularly excelling in AlpacaEval.

This table presents the results of evaluating different LLM alignment techniques on a set of benchmarks. The techniques compared include AOT (paired and unpaired), DPO, KTO, and IPO. The base model used is Merlinite-7B, and it’s fine-tuned using the UltraFeedback Binarized dataset. The benchmarks include AlpacaEval (using GPT-4), ARC, Hellaswag, MMLU, TruthfulQA, Winogrande, and GSM8K. The results demonstrate that AOT outperforms the other alignment methods in AlpacaEval, and shows competitive performance on other benchmarks in zero-shot evaluation.
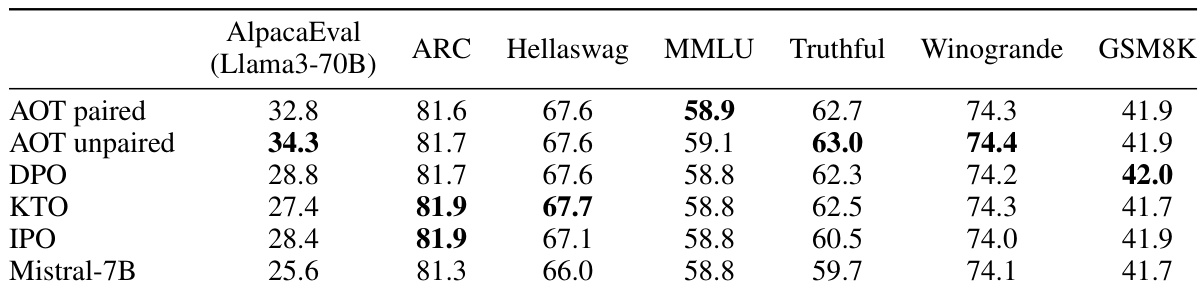
This table presents the results of comparing AOT with other state-of-the-art alignment approaches (DPO, KTO, and IPO) on the Merlinite-7B model trained on the UltraFeedback Binarized dataset. The performance is measured across various benchmarks including AlpacaEval, ARC, HellaSwag, MMLU, TruthfulQA, Winogrande, and GSM8K. AOT shows the best performance on AlpacaEval and competitive performance on other benchmarks.

This table presents the results of the evaluation of the proposed AOT method and other alignment methods on a diverse set of benchmarks. The results show that AOT achieves state-of-the-art performance on AlpacaEval and competitive results on other benchmarks. This table belongs to the ‘Experiments’ section, demonstrating the performance of AOT compared to other alignment algorithms.

This table presents the results of evaluating the performance of the AOT model against several other models (DPO, KTO, IPO, and a baseline Merlinite-7B model) on various benchmarks. The benchmarks include AlpacaEval, ARC, HellaSwag, MMLU, TruthfulQA, Winogrande, and GSM8K. The results show that AOT outperforms the other models on AlpacaEval and is competitive on the other benchmarks.

This table presents the performance of different LLM alignment methods (AOT paired, AOT unpaired, DPO, KTO, IPO) on the OpenHermes-2.5-Mistral-7B model, which was fine-tuned using the UltraFeedback Binarized dataset. The results are evaluated across several benchmarks: AlpacaEval (using Llama3-70B as a judge), ARC, Hellaswag, MMLU, TruthfulQA, Winogrande, and GSM8K. Each benchmark assesses different aspects of LLM capabilities, such as reasoning, commonsense understanding, knowledge, truthfulness, and grammaticality. The table allows for comparison of AOT’s performance against other state-of-the-art alignment techniques.

This table presents the results of several Large Language Model (LLM) alignment techniques on a variety of benchmark datasets. The models were fine-tuned using the UltraFeedback Binarized dataset. The table compares the performance of Alignment via Optimal Transport (AOT) against other methods (DPO, KTO, IPO) across metrics like AlpacaEval, ARC, Hellaswag, MMLU, TruthfulQA, Winogrande, and GSM8K. AOT consistently shows superior performance on AlpacaEval, demonstrating its effectiveness in aligning LLMs with human preferences.

This table presents the performance of different LLM alignment algorithms on various benchmarks. It includes the results obtained using both Llama3-70B and GPT4 for AlpacaEval, highlighting the consistency of relative performance despite Llama3’s tendency to inflate scores. The table focuses on the Merlinite-7B model trained on the UltraFeedback Binarized dataset.
Full paper#