↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Sequence modeling using Mamba models offers efficiency in processing long sequences. However, their complexity poses challenges for understanding their decision-making process, hindering their reliable application, especially in high-stakes areas. Existing methods for explaining model predictions are often unreliable, failing to provide faithful interpretations. This necessitates the development of reliable and trustworthy methods for explaining Mamba model predictions.
The paper introduces MambaLRP, a novel algorithm that integrates Layer-wise Relevance Propagation (LRP) into the Mamba architecture to produce more reliable explanations. By carefully examining relevance propagation and addressing specific components causing issues, MambaLRP ensures relevance conservation. The effectiveness is demonstrated across a wide range of models and datasets, exceeding the performance of baseline approaches. MambaLRP enhances transparency and helps in identifying model biases, contributing significantly to the reliable and responsible use of Mamba models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with sequence models, especially those using Mamba architectures. It introduces MambaLRP, a novel algorithm for explaining Mamba model predictions, addressing the critical need for transparency and explainability in these powerful models. This significantly improves the reliability of explanations and opens up new avenues for uncovering biases, improving model design, and analyzing the long-range capabilities of this widely adopted model architecture.
Visual Insights#

This figure illustrates the three main steps in the development of MambaLRP. Panel (a) shows a basic LRP (Layer-wise Relevance Propagation) approach, which is analogous to multiplying the gradient by the input. Panel (b) demonstrates how the basic LRP method fails in some layers of the Mamba architecture, leading to a violation of the relevance conservation principle and ultimately, noisy explanations (shown via an example image). Panel (c) presents the improved MambaLRP method. This method corrects the issues identified in (b), ensuring that the relevance is conserved across all layers, leading to more accurate and faithful explanations.
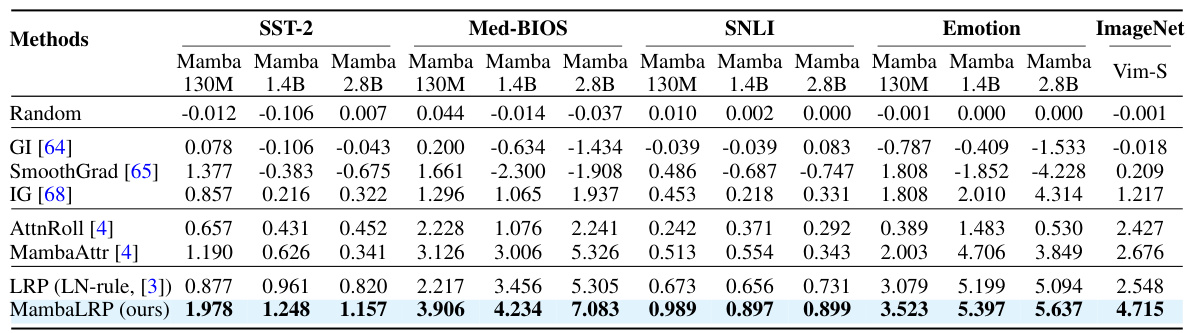
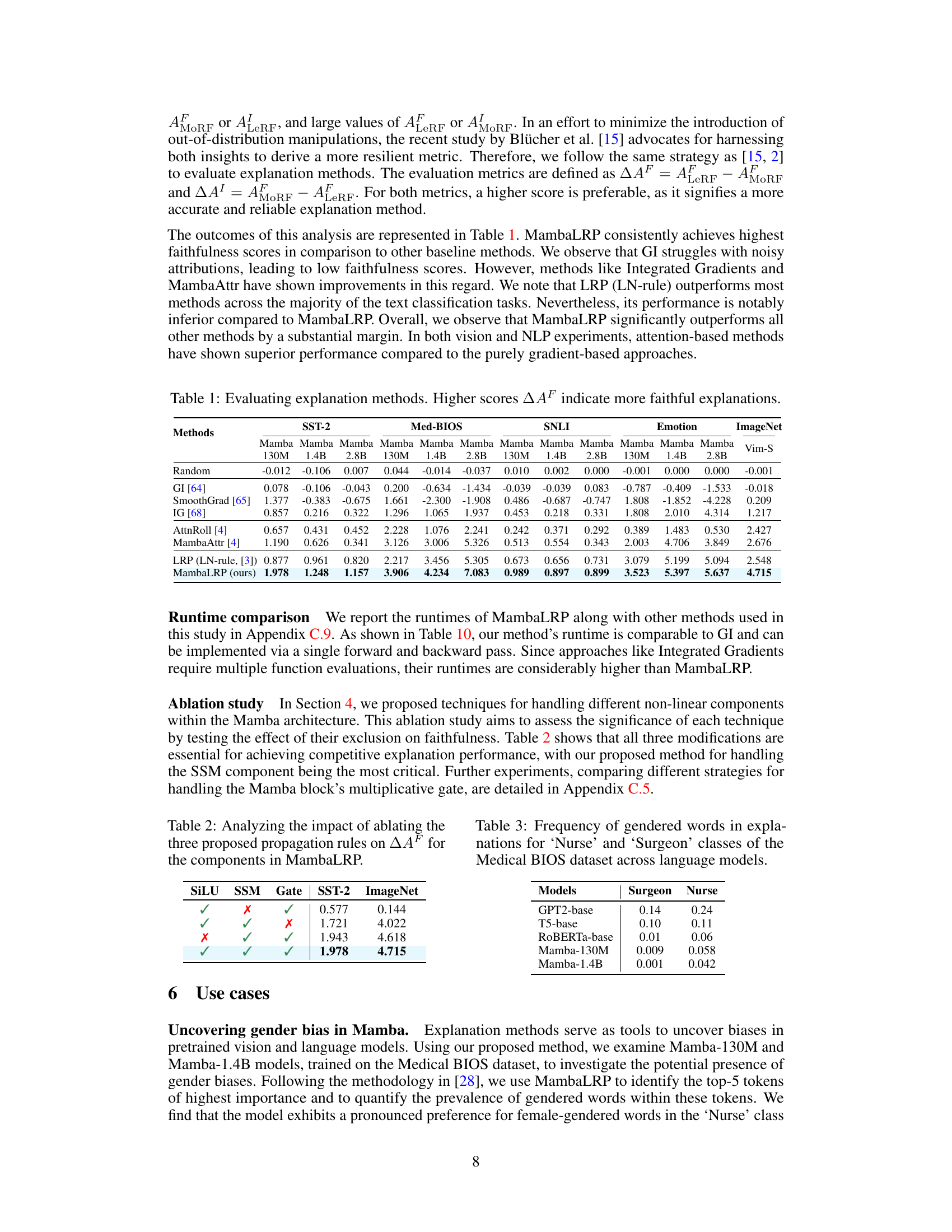
This table compares the performance of MambaLRP against several baseline explanation methods across various datasets (SST-2, Med-BIOS, SNLI, Emotion, and ImageNet). The metrics used (∆AF) measure the faithfulness of the explanations, with higher scores indicating more faithful explanations. The table shows that MambaLRP consistently outperforms other methods, including gradient-based and attention-based approaches.
In-depth insights#
MambaLRP: Intro#
The introduction to MambaLRP would likely set the stage by highlighting the recent surge in popularity of selective state space sequence models, specifically mentioning “Mamba” models and their efficiency in processing long sequences. It would then emphasize the critical need for explainability in these models, especially given their increasing use in real-world applications where transparency and trustworthiness are paramount. The introduction would position LRP (Layer-wise Relevance Propagation) as a key technique for bringing explainability to Mamba models, but acknowledge the challenges posed by the model’s unique architecture. The core problem that MambaLRP solves is identified as the violation of relevance conservation within the Mamba model when using standard LRP, leading to unfaithful explanations. Finally, the introduction would briefly introduce MambaLRP as a novel algorithm designed to address these shortcomings, promising more stable and reliable relevance propagation and ultimately, state-of-the-art explanation performance.
LRP for Mamba#
The section ‘LRP for Mamba’ would delve into applying Layer-wise Relevance Propagation (LRP), a technique for explaining neural network predictions, to the Mamba architecture. It would likely begin by establishing the need for explainability in Mamba models given their increasing use in real-world applications. The core of this section would detail a novel algorithm, perhaps called ‘MambaLRP’, meticulously designed to address challenges posed by the unique structure of Mamba models. These challenges might involve the non-linearity and recurrent nature of the architecture which could lead to unfaithful explanations using standard LRP. MambaLRP would likely involve modifications to the LRP propagation rules, specifically tailored for the SSM components and gating mechanisms within Mamba. The section would emphasize the theoretical soundness of the proposed algorithm, highlighting its adherence to the relevance conservation principle. Empirical evaluations would then showcase MambaLRP’s superior performance over baseline methods, demonstrating its robustness and ability to provide faithful and efficient explanations. Finally, the discussion would likely include insightful case studies illustrating MambaLRP’s capacity to unveil biases and decision-making strategies in the Mamba model.
MambaLRP: Experiments#
The heading ‘MambaLRP: Experiments’ suggests a section dedicated to evaluating the proposed MambaLRP method. A thoughtful analysis would expect this section to present a rigorous evaluation methodology, comparing MambaLRP against various baseline methods using multiple datasets. Key aspects to look for would include a clear description of the datasets used, metrics employed (such as accuracy, faithfulness, conservation property), and the statistical significance of the results. The discussion should go beyond simply reporting numbers; it should delve into the insights gained about MambaLRP’s strengths and weaknesses, perhaps revealing its superior performance in specific scenarios, or exposing its limitations when dealing with noisy data or complex architectures. A comprehensive experiment section would also likely cover ablation studies to assess the contribution of individual components of the MambaLRP algorithm, further strengthening the overall findings. Furthermore, attention should be given to the computational efficiency of MambaLRP relative to existing approaches. The experiments section should provide strong evidence supporting the claims made about MambaLRP’s efficacy and reliability in explaining selective state-space sequence models. Finally, a high-quality experiments section is not only about quantitative results but also includes qualitative examples illustrating how MambaLRP aids in interpretation.
MambaLRP: Discussion#
The discussion section of a research paper on MambaLRP, a novel method for integrating Layer-wise Relevance Propagation (LRP) into Mamba sequence models, would likely cover several key aspects. First, it would summarize the achievements of MambaLRP, emphasizing its superior performance in achieving state-of-the-art explanation accuracy compared to existing methods across diverse model architectures and datasets. The discussion should also delve into the theoretical soundness of the proposed method, highlighting how it addresses limitations of conventional LRP approaches within the unique structure of Mamba models by ensuring relevance conservation and thus generating faithful explanations. A critical analysis of the results, including the qualitative evaluations and detailed explanation examples, would be crucial to support the claims and uncover hidden insights into model behavior. Limitations and potential future directions of research should also be addressed, focusing on challenges in applying MambaLRP to very large models and datasets due to computational demands, and outlining how its scope could expand to other explainability methods and more diverse applications. Finally, the broad impact of the work on promoting transparency and trust in Mamba models for real-world use-cases, especially those with high-stakes decisions, needs a thorough discussion.
Future Work#
Future research directions stemming from this work on MambaLRP could explore several promising avenues. Extending MambaLRP’s applicability to a wider range of SSM architectures and model types beyond the specific Mamba models used in this study would be valuable. This would involve adapting the relevance propagation strategies to handle variations in model design and specific components. Investigating the impact of different hyperparameter choices on the quality and faithfulness of explanations generated by MambaLRP is essential. A comprehensive study could systematically analyze the effects of various hyperparameters to optimize performance and ensure robustness. Another area to investigate is MambaLRP’s performance with extremely long sequences and its ability to capture long-range dependencies. The current study could be extended to examine how MambaLRP scales with sequence length and the potential challenges in maintaining accuracy and computational efficiency. Finally, developing techniques to improve the computational efficiency of MambaLRP is crucial for practical applications involving large models and datasets. Exploring algorithmic optimizations or approximations could significantly reduce the computational cost of generating explanations.
More visual insights#
More on figures

This figure illustrates the unfolded selective state space sequence model (SSM) which is a crucial component of the Mamba architecture. The figure highlights two groups of nodes (red and orange) to simplify the analysis of relevance propagation. The connections within these groups and between them highlight how the conservation property of relevance scores can be violated during the backpropagation process. The key idea is that within each group there are no connections between nodes, making the relevance calculation simpler. The figure serves as a visual aid to understand how the selective SSM works and how it can be addressed to achieve the conservation of relevance during the backward propagation used by the LRP method.

This figure compares the conservation property (i.e., whether the sum of relevance scores attributed to the input features equals the network’s output score) between the Gradient × Input (GI) baseline and the proposed MambaLRP method. The plots show the sum of relevance scores (Σ_i R(x_i)) versus the output score (f) for Mamba-130M on SST-2 and Vim-S on ImageNet. MambaLRP demonstrates significantly improved conservation compared to GI, indicating more faithful explanations.

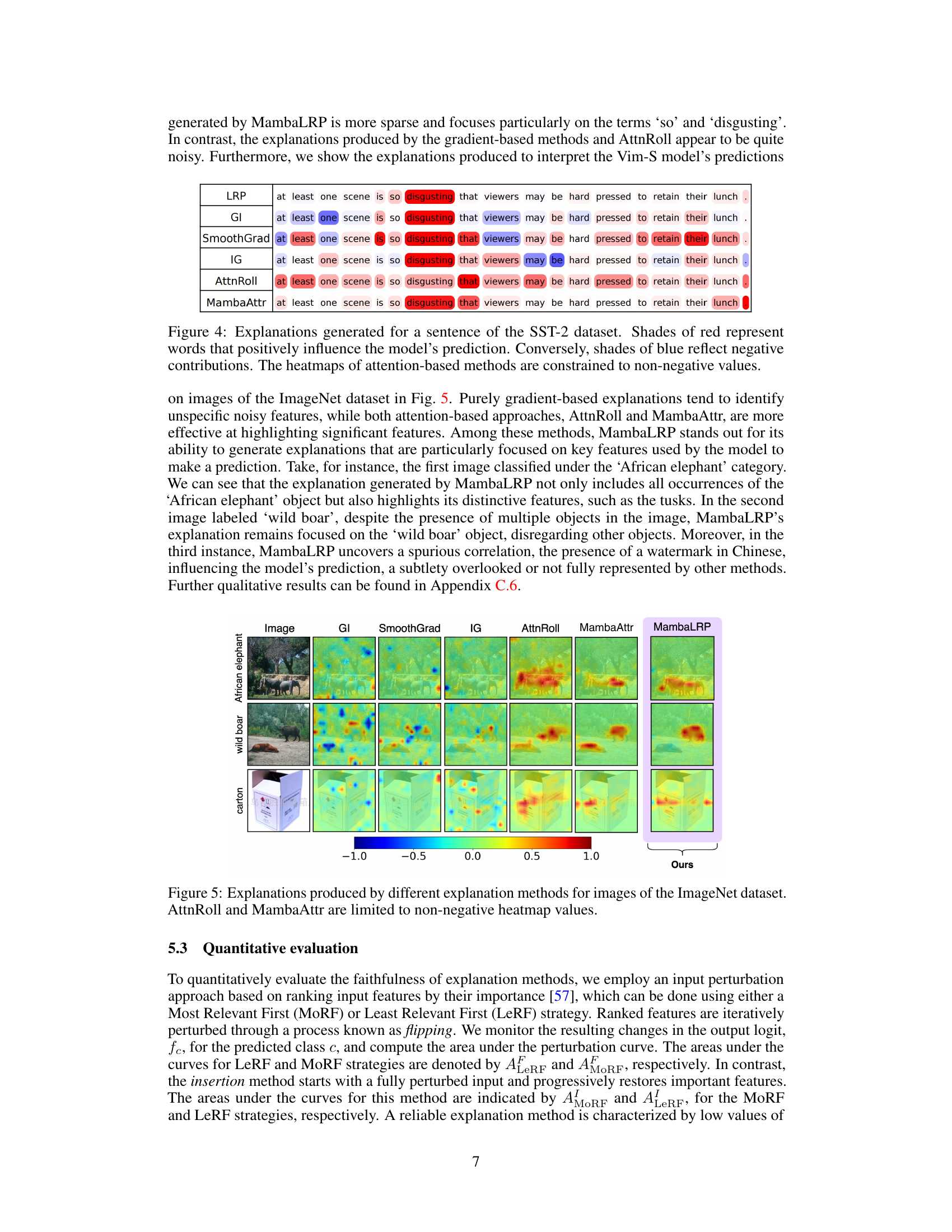
This figure compares the explanations generated by different methods for a single sentence from the SST-2 dataset. The sentence expresses a negative sentiment. The heatmaps show which words contribute positively (red) or negatively (blue) to the model’s prediction. Notice that MambaLRP’s explanation is more sparse than the other methods, focusing on the most relevant words. Attention-based methods (AttnRoll and MambaAttr) only show positive contributions (no blue).

This figure compares the explanations generated by various methods (Gradient × Input, SmoothGrad, Integrated Gradients, Attention Rollout, MambaAttr, and MambaLRP) for three example images from the ImageNet dataset. Each row shows a different image and its corresponding explanations produced by each method, visually represented as heatmaps. The heatmaps show which parts of the image the model focused on when making a prediction. MambaAttr and Attention Rollout are constrained to positive values only, whereas the others allow for both positive and negative contributions, indicating whether a feature increased or decreased the model’s confidence in its prediction. The color bar at the bottom indicates the scale of relevance scores. MambaLRP produces more focused explanations by highlighting key features.

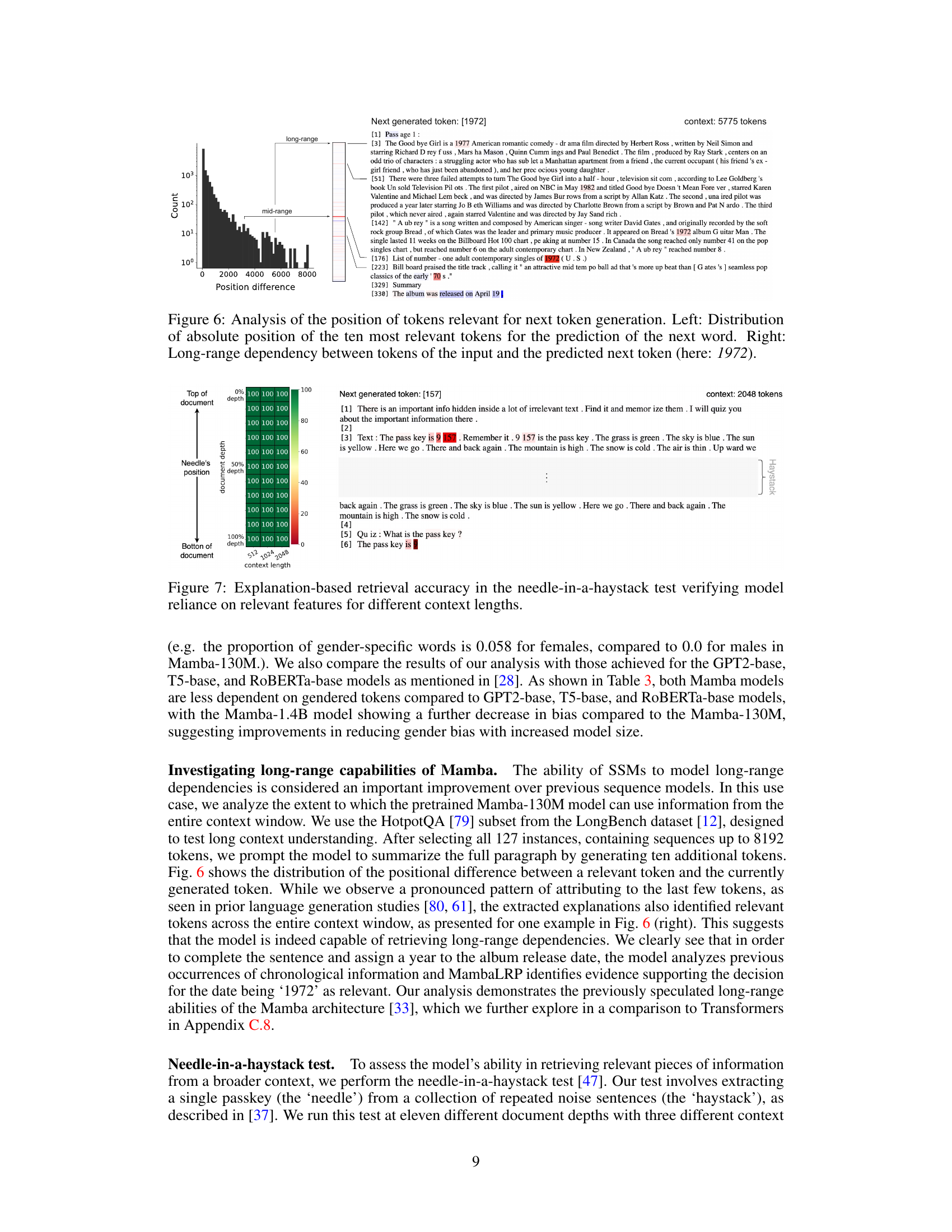
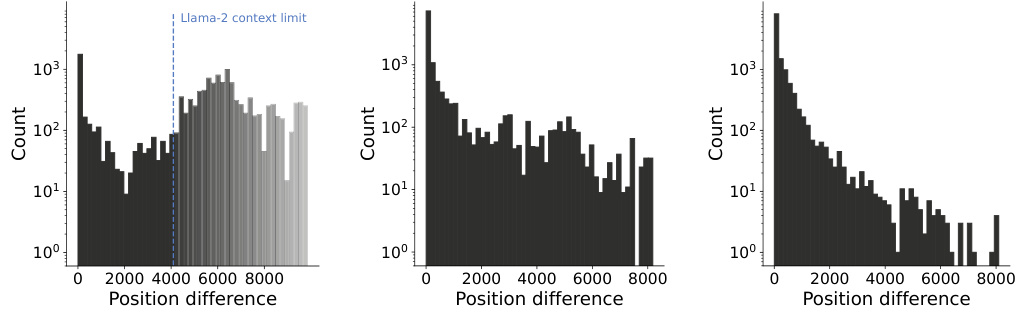
This figure analyzes the positional relationship between tokens in the input sequence and the predicted next token, specifically focusing on long-range dependencies. The left panel shows the distribution of the positions of the ten most relevant tokens for predicting the next word, revealing that the most relevant tokens are not always those nearest in the sequence. The right panel demonstrates a long-range dependency example, illustrating how the model uses information from a token far from the point of generation to generate the next token (the year 1972, in this case).

This figure shows the conservation property of the proposed MambaLRP method against a baseline method (GI) on two different datasets (SST-2 and ImageNet). The x-axis represents the sum of relevance scores for all input features, while the y-axis shows the model’s output prediction score. Ideally, the points should fall on the blue identity line (perfect conservation), indicating that the relevance scores perfectly match the output. The figure demonstrates that MambaLRP achieves significantly better conservation than the baseline method.
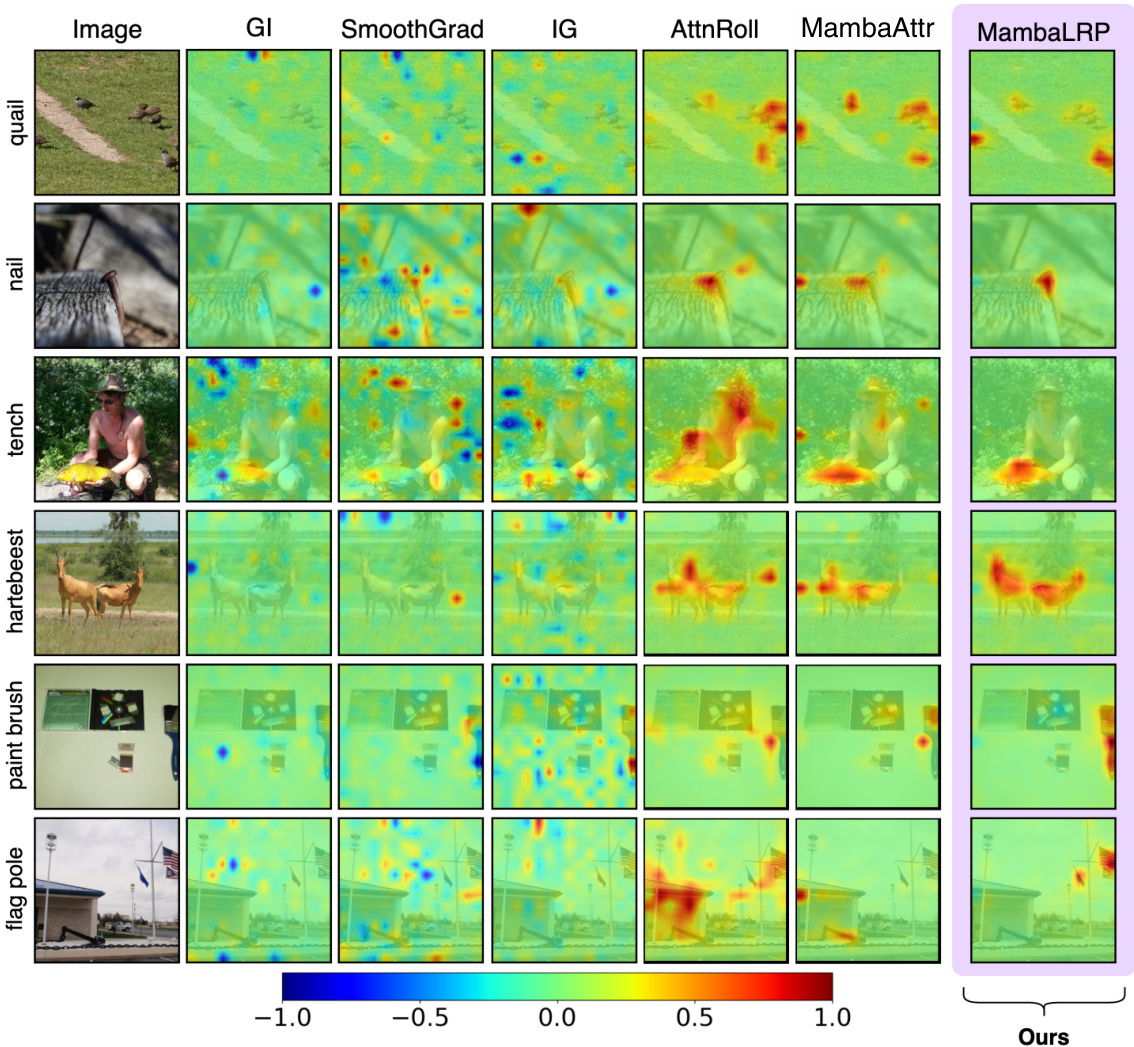
This figure compares the visualizations generated by different explanation methods (Gradient × Input, SmoothGrad, Integrated Gradients, Attention Rollout, MambaAttr, and MambaLRP) for several images from the ImageNet dataset. Each row represents a different image, and each column shows the heatmap generated by a specific method, highlighting the regions of the image that were deemed most relevant to the model’s prediction. Note that AttnRoll and MambaAttr are constrained to produce non-negative heatmaps, unlike the other methods which show both positive and negative contributions.

This figure displays the results of a conservation property analysis for the GI baseline and the proposed MambaLRP. The x-axis shows the sum of relevance scores across all input features, and the y-axis represents the network’s output score. Each data point represents a single example. Points near the blue identity line (y=x) indicate that the conservation property is well preserved, meaning that the relevance scores accurately reflect the model’s prediction. Deviations from the identity line signify a violation of this property. The plot visually demonstrates how MambaLRP substantially improves the conservation property compared to the GI baseline. This is an important property for faithful explanations, as violations can lead to unreliable attributions.
This figure compares the conservation property of two different methods: GI baseline and the proposed MambaLRP, for two models trained on different datasets. The x-axis represents the sum of relevance scores across input features, while the y-axis represents the network’s output score. Each point represents a single data point. Points closer to the blue identity line (perfect conservation) indicate better conservation of relevance scores. MambaLRP shows significantly better adherence to the conservation property than GI.
More on tables
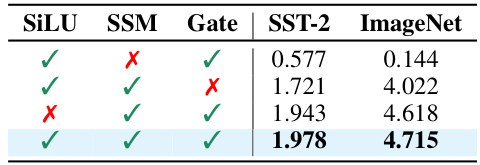
This table presents the results of an ablation study evaluating the impact of removing each of the three novel relevance propagation strategies introduced in MambaLRP. The strategies are for the SiLU activation function, the selective SSM, and the multiplicative gate. The table shows the ∆AF (a faithfulness metric, higher is better) achieved on the SST-2 and ImageNet datasets when each component is excluded, one at a time, demonstrating the importance of each component for achieving high explanation faithfulness. The results clearly show that all three modifications are essential for achieving competitive explanation performance, with the SSM modification having the largest impact.
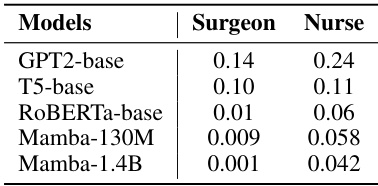
This table presents a quantitative comparison of different explanation methods’ faithfulness. Faithfulness is measured using the delta-AF metric (AeRF - AMORF), where higher scores indicate more accurate and reliable explanations. The table compares MambaLRP against several gradient-based methods (Gradient × Input, SmoothGrad, Integrated Gradients), a naive LRP implementation (LRP (LN-rule)), and two attention-based methods (Attention Rollout, MambaAttr) across various datasets (SST-2, Medical BIOS, SNLI, Emotion, ImageNet). The results show MambaLRP consistently outperforms other methods in faithfulness.
This table compares the faithfulness of different explanation methods across various datasets (SST-2, Med-BIOS, SNLI, Emotion, and ImageNet) using two metrics: ΔAF and ΔAI. Higher scores indicate better faithfulness, meaning the explanations more accurately reflect the model’s decision-making process. The methods compared are: Random, GI, SmoothGrad, IG, AttnRoll, MambaAttr, LRP (LN-rule), and MambaLRP (the proposed method). MambaLRP consistently achieves the highest faithfulness scores, significantly outperforming all other methods.

This table presents a comparison of different explanation methods’ performance across various datasets (SST-2, Med-BIOS, SNLI, Emotion, and ImageNet). The methods are evaluated using two faithfulness metrics (∆AF and ∆AI) calculated using input perturbation with a Most Relevant First (MoRF) and Least Relevant First (LeRF) strategy. Higher scores in ∆AF indicate more faithful explanations. The table shows that MambaLRP consistently outperforms the other methods.

This table presents an ablation study on the Vision Mamba model to determine the optimal LRP composite. Different combinations of applying the generalized LRP-γ rule and basic LRP-0 rule across various layers (input projection, output projection, and convolutional layers) within each block of the model are tested. The performance metric used is ΔAF, which measures the faithfulness of the explanations. The table shows the ΔAF score for each configuration, helping to identify the best combination of LRP rules for achieving the most faithful explanations.

This table compares the faithfulness of different explanation methods (MambaLRP, Gradient × Input, SmoothGrad, Integrated Gradients, Attention Rollout, MambaAttr, and a naive LRP implementation) across four text classification datasets (SST-2, Medical BIOS, SNLI, Emotion) and one image classification dataset (ImageNet). Faithfulness is measured using two metrics: ∆AF (AeRF - AMORF) and ∆AI (AMORF - ALeRF), where higher scores indicate better faithfulness. The results demonstrate that MambaLRP consistently achieves the highest faithfulness scores, significantly outperforming the other methods.

This table compares the faithfulness of different explanation methods (Random, GI, SmoothGrad, IG, AttnRoll, MambaAttr, LRP (LN-rule), and MambaLRP) across multiple datasets (SST-2, Med-BIOS, SNLI, Emotion, and ImageNet). Faithfulness is measured using the delta-AF metric (AeRF - AMORF), where higher scores indicate more reliable explanations. The results show that MambaLRP consistently outperforms other methods across all datasets.

This table presents a comparison of different explanation methods’ performance in terms of faithfulness, evaluated using the delta-F metric (∆AF). Higher ∆AF scores indicate more faithful explanations. The methods compared include random baseline, Gradient × Input (GI), SmoothGrad, Integrated Gradients (IG), Attention Rollout (AttnRoll), MambaAttr, LRP (LN-rule), and the proposed MambaLRP method. The comparison is performed across multiple datasets including SST-2, Med-BIOS, SNLI, Emotion and ImageNet, for various sizes of Mamba models.

This table compares the performance of different explanation methods (Random, Gradient × Input (GI), SmoothGrad, Integrated Gradients (IG), Attention Rollout (AttnRoll), MambaAttr, LRP (LN-rule), and MambaLRP) across four datasets (SST-2, Med-BIOS, SNLI, and Emotion) and ImageNet. The methods are evaluated using the ∆AF metric, where a higher score indicates better faithfulness of the explanation. The results demonstrate that MambaLRP consistently achieves the highest faithfulness scores, significantly outperforming other methods.

This table presents a comparison of different explanation methods’ faithfulness scores across multiple datasets (SST-2, Medical BIOS, SNLI, Emotion, and ImageNet). Faithfulness is measured using the delta-AF metric (∆AF = AeRF - AMORF), where higher scores indicate more faithful explanations. The methods compared include several gradient-based, model-agnostic techniques (GI, SmoothGrad, Integrated Gradients) and two attention-based methods (AttnRoll, MambaAttr), along with a naive implementation of LRP (LRP (LN-rule)) and the proposed MambaLRP. The results show that MambaLRP consistently achieves the highest faithfulness scores across all datasets.

This table presents a comparison of different explanation methods’ performance on several datasets (SST-2, Medical BIOS, SNLI, Emotion, and ImageNet). The methods compared include several gradient-based techniques, two attention-based approaches, and the proposed MambaLRP. The evaluation metric used is ∆AF, which reflects the faithfulness of the explanation. Higher ∆AF scores indicate more faithful explanations, meaning the explanation better aligns with the model’s actual decision-making process. The table highlights MambaLRP’s superior performance compared to the baseline methods.

This table presents a comparison of different explanation methods’ performance on several datasets. The metrics used are ∆AF and ∆AI, which measure the faithfulness of explanations. Higher scores indicate more faithful explanations. The methods compared include baseline methods like Gradient × Input, SmoothGrad, Integrated Gradients, and attention-based methods like Attention Rollout and MambaAttr. The proposed method, MambaLRP, is also included and shows superior performance across all datasets. This table provides quantitative evidence supporting the claim that MambaLRP generates more faithful and robust explanations.
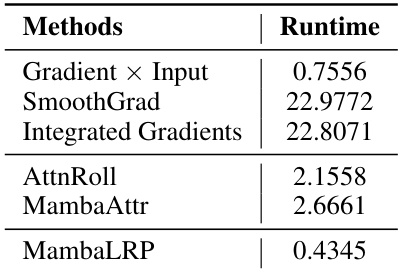
This table compares the faithfulness of different explanation methods, including Gradient × Input (GI), SmoothGrad, Integrated Gradients (IG), Attention Rollout (AttnRoll), MambaAttr, a naive implementation of LRP (LRP (LN-rule)), and the proposed MambaLRP. Faithfulness is measured using the delta AF metric (∆AF = AeRF - AMORF), where AeRF is the area under the curve for the Least Relevant First (LeRF) strategy and AMORF is for the Most Relevant First (MoRF) strategy. Higher ∆AF scores indicate better faithfulness. The table shows that MambaLRP consistently achieves the highest faithfulness scores across various datasets, significantly outperforming other methods.

This table presents a comparison of different explanation methods’ faithfulness scores on several datasets. The ∆AF score, a metric of faithfulness, is higher for methods producing more reliable explanations. The results show that MambaLRP consistently outperforms other methods across multiple datasets, demonstrating superior explanation accuracy.
Full paper#