↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing diffusion planning methods suffer from low decision-making frequencies due to high computational costs. This significantly limits their applicability in real-time systems like robotics. The core problem is the expensive iterative sampling in generating long-horizon trajectories, where much of the detailed information is often redundant.
To tackle this, the authors propose DiffuserLite, a lightweight framework that leverages a plan refinement process (PRP). PRP generates coarse-to-fine trajectories, thus drastically reducing redundant information and improving efficiency. Experiments show DiffuserLite achieves a remarkable 122.2Hz decision-making frequency (112.7x faster than existing methods) while maintaining state-of-the-art performance across various benchmarks. DiffuserLite is presented as a flexible plugin that can be integrated with other diffusion planning methods, offering a valuable structural design for future work.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers in reinforcement learning and robotics because it addresses the critical challenge of real-time decision-making in diffusion planning. By introducing DiffuserLite and PRP, the research opens new avenues for developing more efficient and faster planning algorithms, which is crucial for deploying autonomous robots and AI systems in real-world settings. The proposed methods and findings could also inspire further research on improving the efficiency and scalability of diffusion models for various decision-making tasks. Moreover, the structural design of DiffuserLite provides valuable insights for future algorithm designs.
Visual Insights#

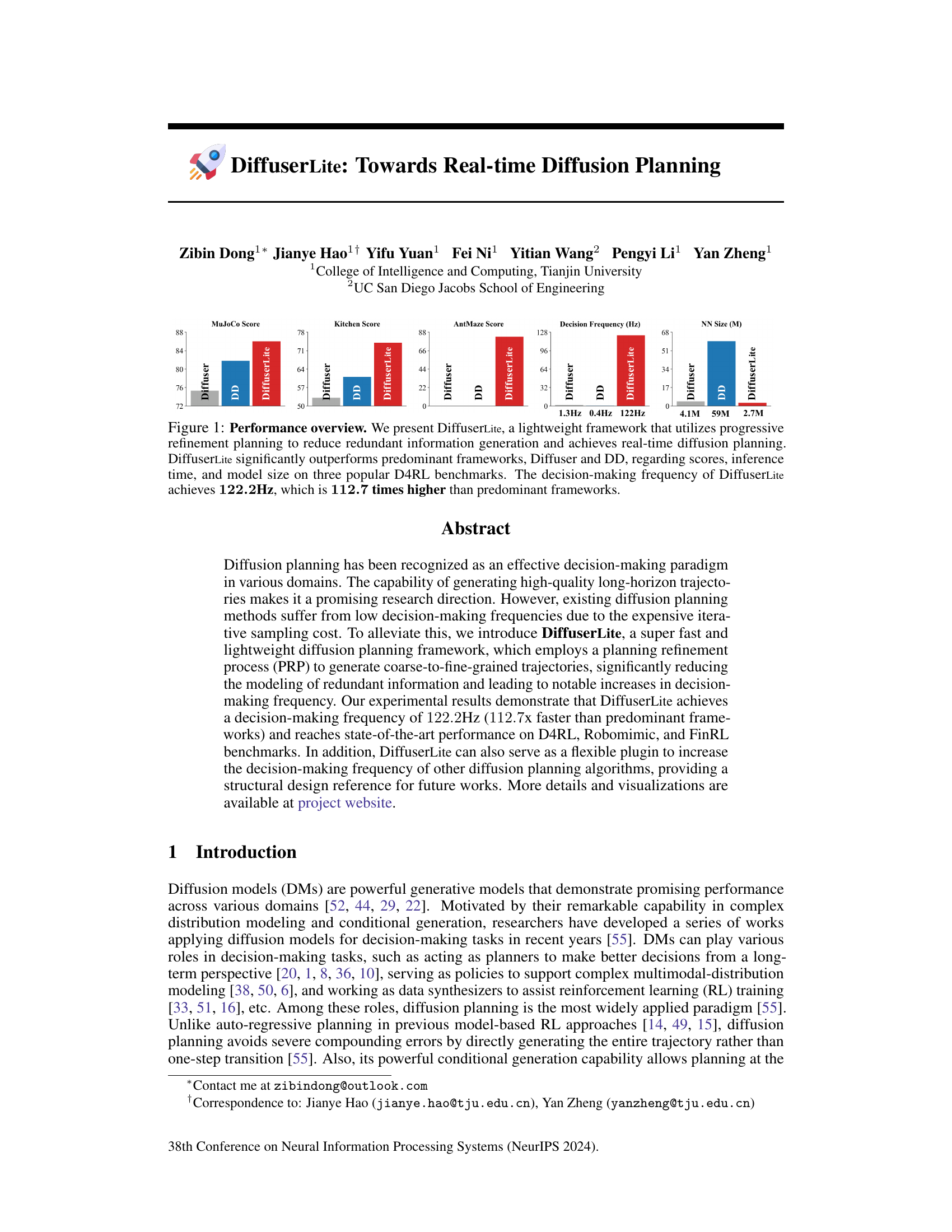
This figure provides a comparison of the performance of DiffuserLite against two existing diffusion planning methods (Diffuser and DD) across three different benchmark tasks (MuJoCo, Kitchen, and AntMaze). Key metrics compared include task scores, decision frequency (Hz), and model size (in millions of parameters). The results demonstrate that DiffuserLite achieves significantly higher scores, a much faster decision frequency, and a smaller model size compared to the other methods, highlighting its efficiency and improved performance.
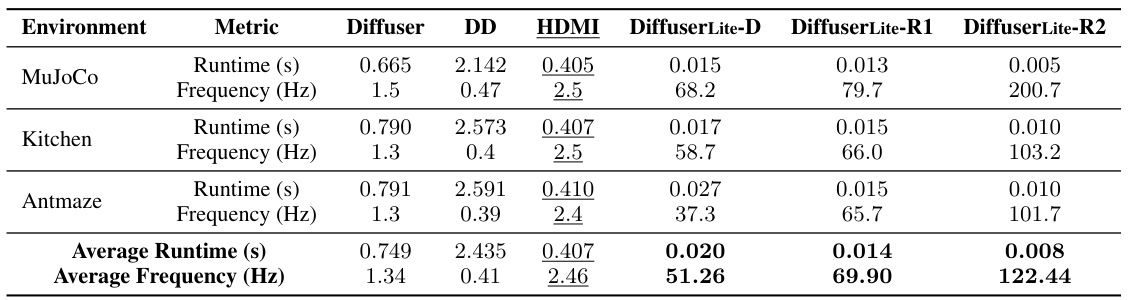
This table presents a performance comparison of Diffuser, DD, HDMI, and three variations of DiffuserLite (D, R1, R2) across three D4RL benchmarks: MuJoCo, Kitchen, and AntMaze. For each benchmark, it shows the runtime per step (in seconds) and the decision-making frequency (in Hz) for each method. DiffuserLite demonstrates significantly faster decision-making compared to the baselines.
In-depth insights#
Real-time Diffusion#
Real-time diffusion models present a significant advancement in the field of AI, particularly for applications demanding immediate responses. The core challenge lies in optimizing the diffusion process to drastically reduce computational cost without sacrificing the quality of generated results. Progressive refinement planning, as demonstrated in the paper, is a key strategy, generating coarse-to-fine trajectories which helps minimize redundant information processing. This technique, coupled with lightweight architectures like DiffuserLite, enables high-frequency decision-making previously unattainable with traditional diffusion models. The trade-off between speed and accuracy is carefully managed, with the authors highlighting the effectiveness of the method across diverse benchmarks. Rectified flow further enhances speed by simplifying trajectory generation, demonstrating the potential for achieving truly real-time performance, crucial for applications like robotics and autonomous systems. Achieving real-time capability opens many new opportunities while presenting new challenges related to robustness, adaptability, and ensuring fairness and safety in critical decision-making scenarios.
PRP Speed Boost#
The concept of ‘PRP Speed Boost’ suggests a significant acceleration in planning achieved through a Plan Refinement Process (PRP). PRP likely involves a hierarchical planning approach, starting with a coarse overview of the task and progressively refining the plan in subsequent iterations. This avoids redundant computations by focusing computational resources on the most critical aspects of the plan at each stage. The core speed improvement comes from reducing the computational burden of generating detailed trajectories; instead of calculating the full trajectory at once, PRP generates initial plans with fewer keypoints and then iteratively refines those keypoints, efficiently allocating computational resources. This method is particularly beneficial for long-horizon tasks where the computational cost of generating high-quality long-horizon plans is extremely high. This trade-off between computational cost and planning quality is a crucial aspect of PRP’s effectiveness. The ‘Speed Boost’ thus highlights PRP as a computationally efficient technique for real-time decision-making in complex scenarios, enabling planning algorithms to keep pace with dynamic environments. Further investigation is required to fully understand the robustness and limits of this planning technique under various conditions and task complexities.
D4RL Benchmarks#
The D4RL (Datasets for Deep Data-driven Reinforcement Learning) benchmarks are crucial for evaluating offline reinforcement learning algorithms. They provide diverse datasets from real-world robotics and simulation environments, allowing researchers to assess the generalization capabilities and robustness of their methods beyond simple simulated scenarios. D4RL’s focus on offline learning is particularly important as it addresses the challenges of data scarcity and safety inherent in real-world applications. The benchmarks include tasks with varying levels of complexity and reward sparsity, enabling a comprehensive comparison of different approaches. Performance on D4RL tasks often serves as a key indicator of an algorithm’s practical applicability, showcasing its ability to learn effectively from limited and potentially noisy data. However, it’s also important to acknowledge that D4RL benchmarks are not without limitations. The datasets might not fully represent the complexities of real-world deployments, and the evaluation metrics may not capture all aspects of performance. Nevertheless, D4RL has significantly contributed to the advancement of offline RL by providing a standardized and challenging evaluation framework.
Plugin Flexibility#
The concept of “Plugin Flexibility” in the context of a research paper likely refers to the design of a module or component that can be easily integrated into different systems or frameworks. This modularity enhances the algorithm’s versatility and adaptability. A flexible plugin architecture is valuable because it allows researchers to leverage existing tools and algorithms and facilitates easy customization and extension. Successful implementation is dependent on well-defined interfaces and minimal dependencies. This approach accelerates the development process and promotes code reusability, which is crucial in a research context. A key benefit is the potential to extend the capabilities of a core algorithm by incorporating additional features or functionalities offered by other plugins. Furthermore, it promotes collaboration and knowledge sharing, as other researchers can develop and contribute to the plugin ecosystem.
Future Enhancements#
Future enhancements for DiffuserLite could focus on addressing its limitations. Improving the classifier-free guidance (CFG) mechanism is crucial, as it currently requires careful adjustment of target conditions, especially in the multi-level structure. Exploring alternative guidance methods, such as classifier guidance, or designing a more unified architecture with a single diffusion model instead of multiple levels, could simplify the framework and potentially enhance performance. Investigating optimal temporal jump adjustments and exploring more advanced ODE solvers to further speed up the generation process are also promising avenues. Furthermore, expanding DiffuserLite’s applicability to a broader range of tasks and environments, including continuous control tasks, remains an important future direction. Finally, a thorough investigation into the robustness and generalizability of the approach, as well as an exploration of its potential for deployment in real-world robotic systems, are essential steps towards practical implementation. Addressing potential concerns regarding computational cost and memory usage, especially for complex scenarios, would also strengthen its appeal for broader applications.
More visual insights#
More on figures
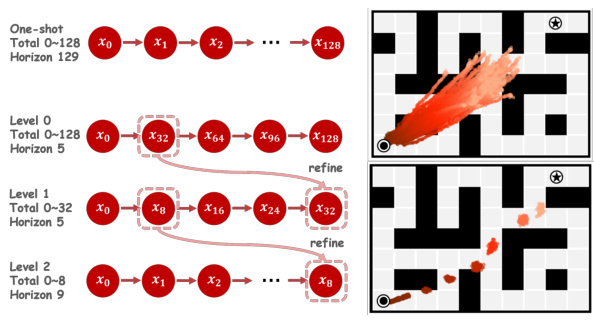
This figure compares one-shot planning and the proposed plan refinement process (PRP) in the AntMaze environment. It visually demonstrates how PRP reduces redundant information and the search space, leading to more consistent plans compared to the one-shot approach.
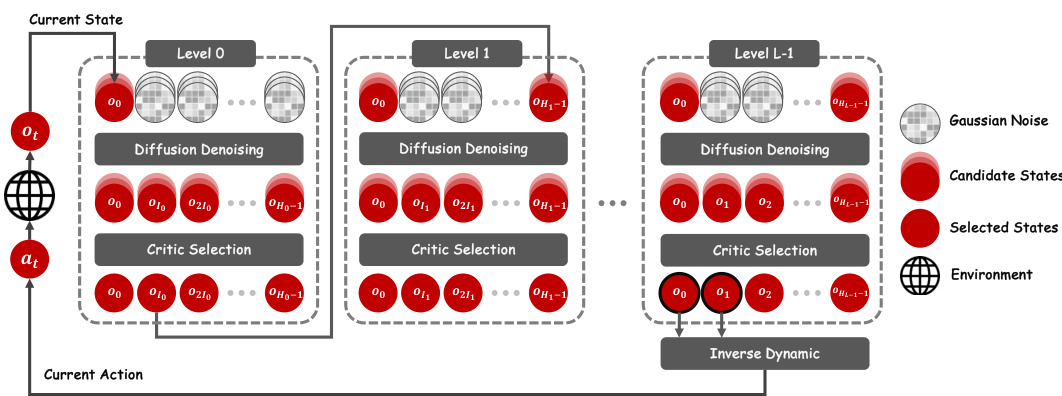
This figure provides a visual overview of the DiffuserLite architecture. It shows how the model generates trajectories level by level, refining the plan at each stage using a critic to select the optimal trajectory and an inverse dynamic model to extract the action. The process starts with the current state and iteratively refines the plan until the final action is determined.
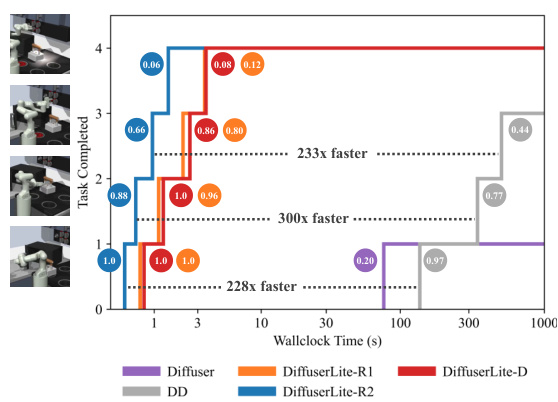
This figure compares the runtime and performance of DiffuserLite against Diffuser and DD on the FrankaKitchen benchmark. The y-axis shows the number of tasks completed (out of a maximum of 4), while the x-axis represents the time taken. Each point represents the average of 250 rollouts. The colored circles indicate task success rates, and the lines illustrate how the number of tasks completed changes with time for each method. The figure highlights that DiffuserLite achieves a significantly higher number of completed tasks in a much shorter time than the baselines.

This figure shows six different benchmark environments used in the paper to evaluate the performance of the proposed DiffuserLite model and compare it with other baseline methods. The environments represent diverse robotic control tasks, including locomotion (HalfCheetah, Hopper, Walker2d), manipulation (FrankaKitchen, Robomimic), and navigation (Antmaze). These diverse tasks provide a comprehensive evaluation of the model’s generalization and adaptability across different domains.
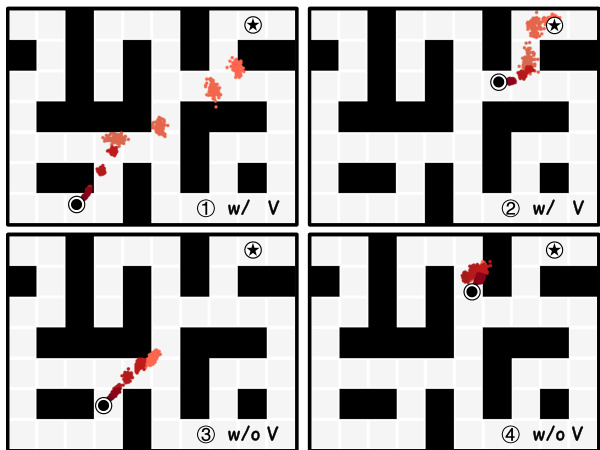
This figure compares the plans generated by DiffuserLite with and without value conditions in the AntMaze environment. The darker the color of a plan, the closer it is to the current state. Using only rewards, plans tend to cluster prematurely, away from the goal. Adding value conditions results in plans that more directly reach the goal.
More on tables
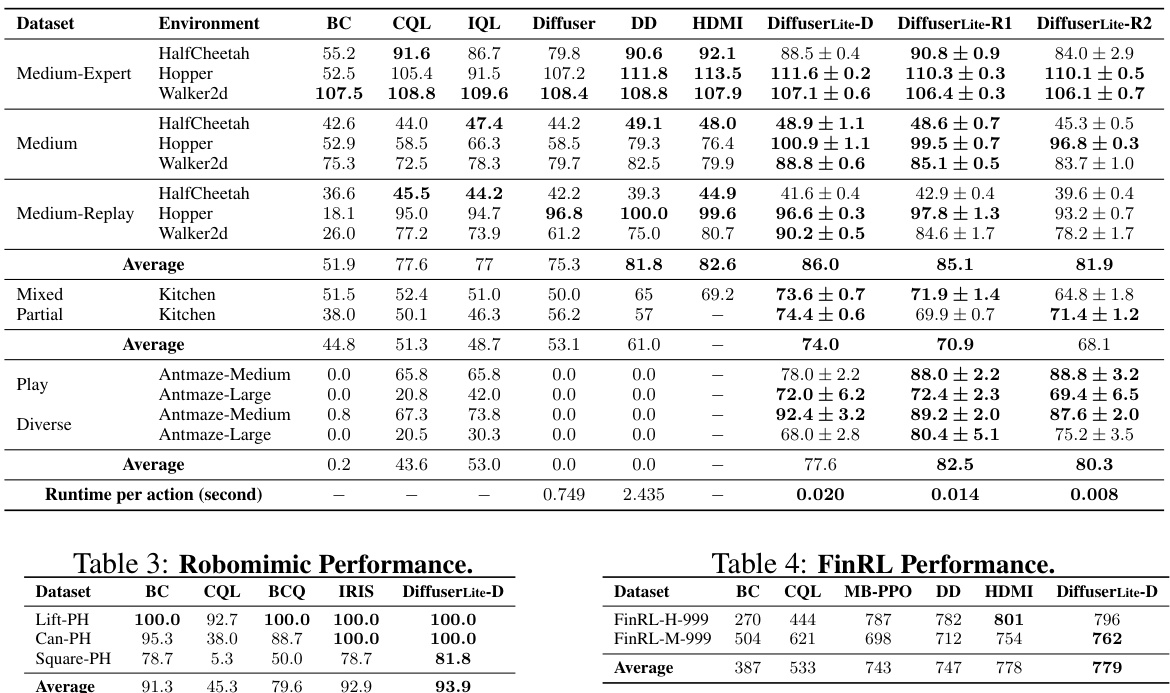
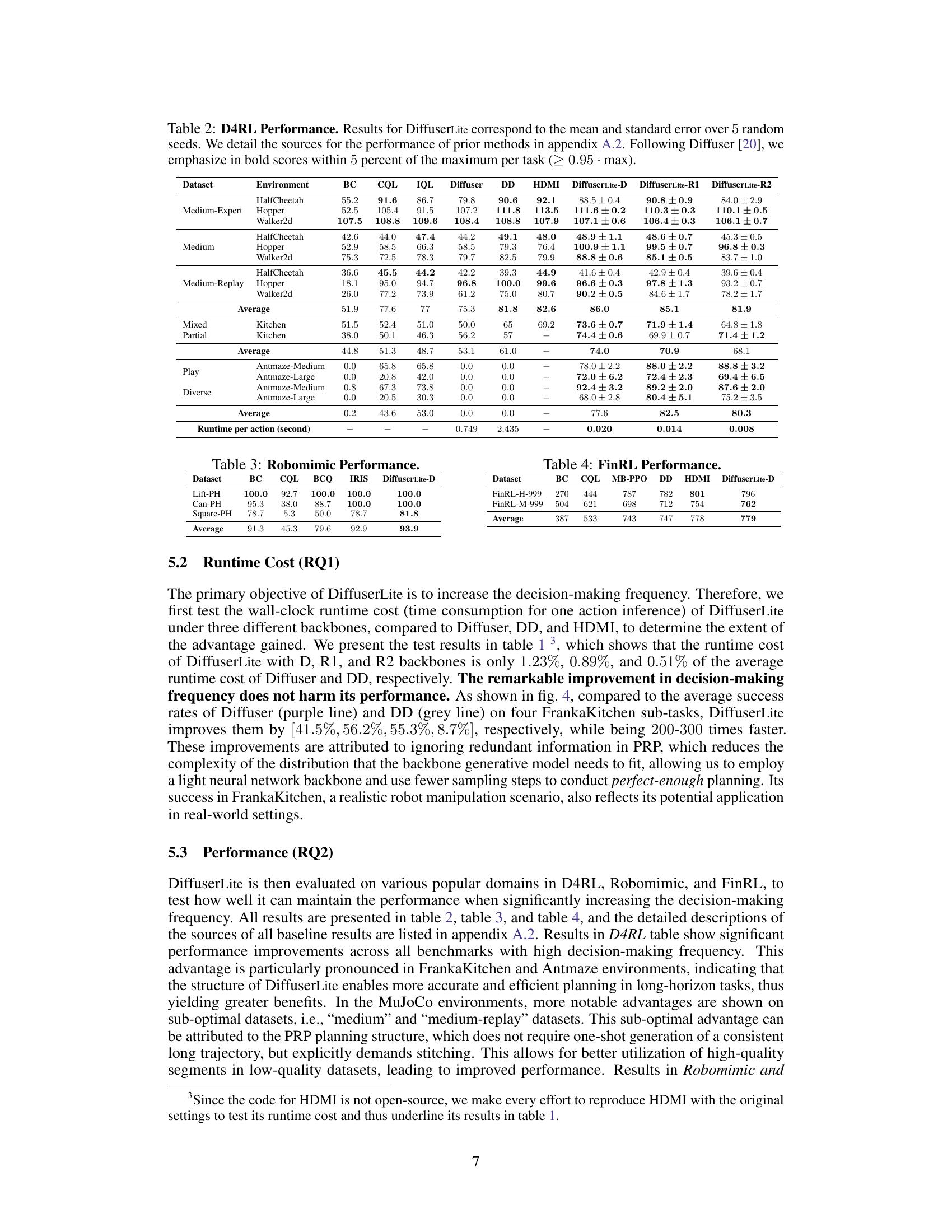
This table presents the performance comparison of DiffuserLite against several baselines (BC, CQL, IQL, Diffuser, DD, HDMI) across various D4RL tasks (HalfCheetah, Hopper, Walker2d, Kitchen, Antmaze). The results show the mean and standard deviation over 5 random trials for each algorithm and task, highlighting DiffuserLite’s performance. Bold scores indicate performance within 5% of the best result for each task.

This table compares the performance of three different methods: Goal-Conditioned behavior clone (GC), AlignDiff, and AlignDiff-Lite (AlignDiff with DiffuserLite as a plugin) in terms of MAE Area and decision-making frequency. It demonstrates that incorporating DiffuserLite significantly improves the decision-making frequency of AlignDiff with only a small decrease in MAE Area, highlighting its effectiveness as a flexible plugin to improve performance.

This table presents the performance of DiffuserLite under different configurations of the plan refinement process (PRP). The left side shows how the number of planning levels (2, 3, or 4) affects performance on three different tasks. The right side explores the impact of different temporal horizon choices within the PRP on these tasks. The highest scores are highlighted in bold, and the default settings are underlined.
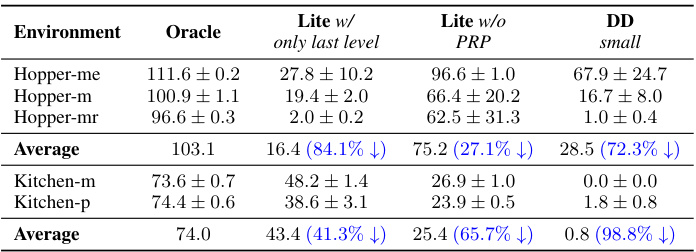
This table presents the ablation study results, comparing the performance of DiffuserLite against three variations: Lite w/ only last level (removing all but the final level of PRP), Lite w/o PRP (removing PRP entirely), and DD-small (a downscaled version of DD). It highlights the significant performance drop when removing or simplifying the PRP, demonstrating its importance in improving performance.
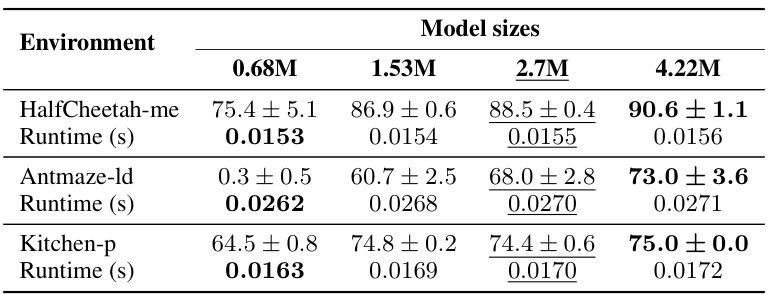
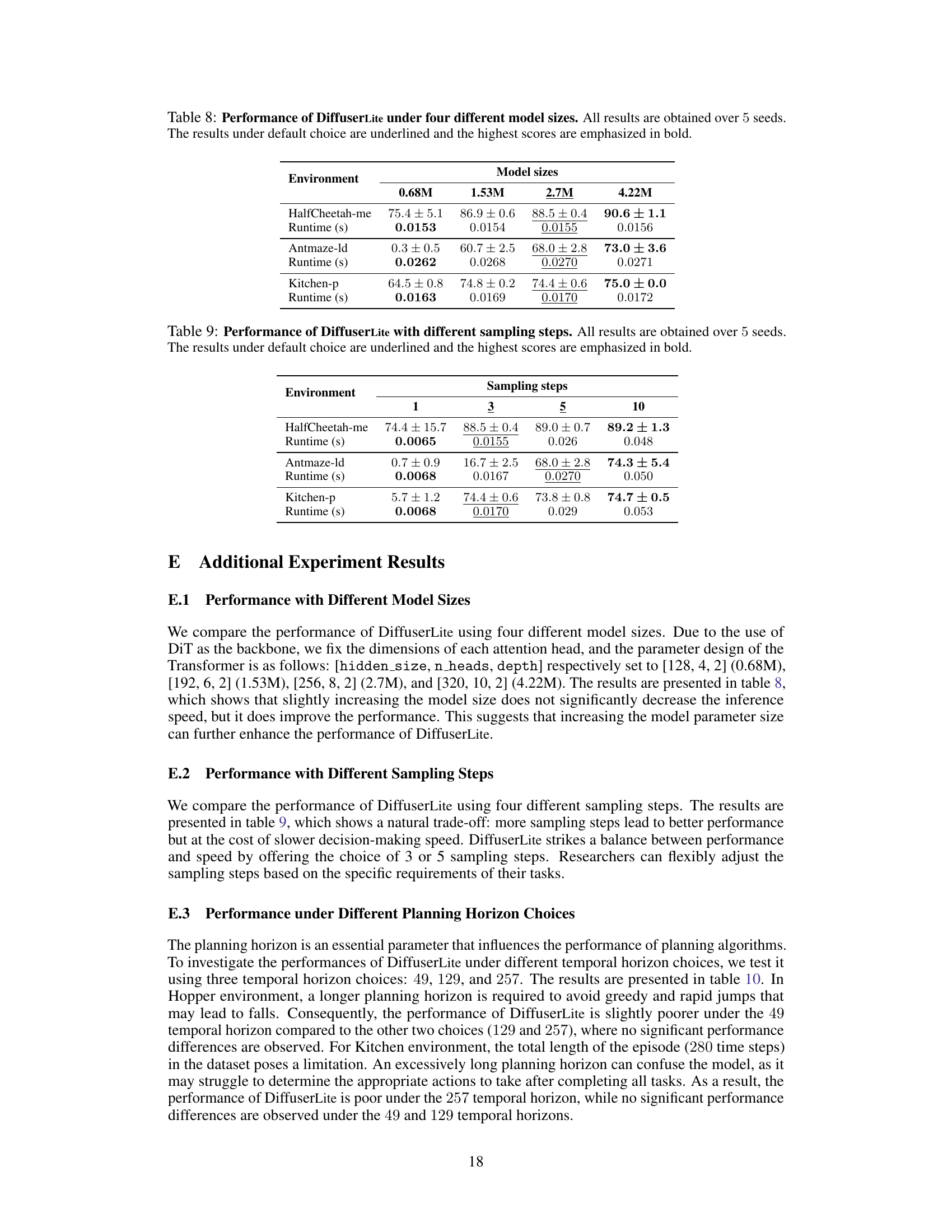
This table shows the performance of DiffuserLite with four different model sizes (0.68M, 1.53M, 2.7M, and 4.22M parameters). The results are reported for three benchmark environments (HalfCheetah-me, Antmaze-ld, and Kitchen-p) and include both performance scores and runtime in seconds. The default model size parameters are underlined, and the highest scores for each metric are shown in bold.
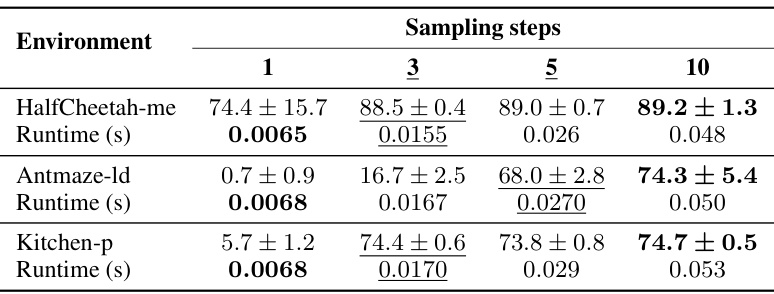
This table presents the performance of DiffuserLite using different numbers of sampling steps (1, 3, 5, and 10). The results are averaged over 5 random seeds. The best performance for each environment is highlighted in bold. Runtime (in seconds) is also provided for each condition.
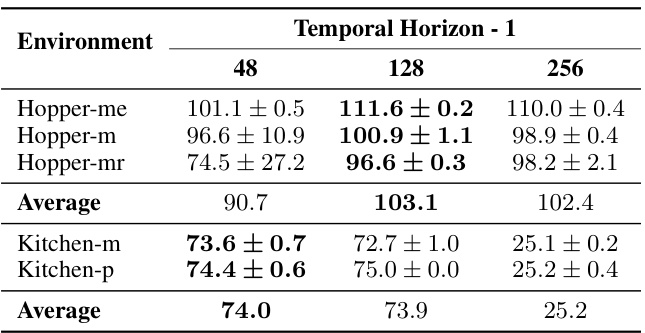
This table shows the performance of DiffuserLite under three different temporal horizon choices (48, 128, and 256). The results are presented for two environments, Hopper and Kitchen, each with three different datasets (medium, medium-replay, and expert for Hopper; mixed and partial for Kitchen). The average performance across all datasets is also shown for each environment and temporal horizon. The best results for each environment are highlighted in bold.
Full paper#