↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current autonomous driving motion generation models struggle with limited data and difficulty generalizing to new environments. These models often rely on encoder-decoder architectures and continuous trajectory prediction, leading to issues with multi-modal motion representation and inconsistent scene forecasting. Existing autoregressive models, while showing promise, also lack scalability and generalization capabilities.
To overcome these issues, the researchers developed SMART. SMART uses a decoder-only transformer architecture and a novel next-token prediction approach on tokenized map and trajectory data. This approach allows the model to learn the motion distribution in real driving scenarios, achieving improved performance across various metrics. The model demonstrates zero-shot generalization and impressive scalability, meeting the demands of large-scale real-time simulation. The project code and data are publicly available, enabling further model exploration.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in autonomous driving and AI due to its novel approach to motion generation. SMART’s scalability and zero-shot generalization capabilities directly address major limitations of existing methods, opening new avenues for large-scale, real-time simulations. The released codebase fosters further research and development in the field.
Visual Insights#
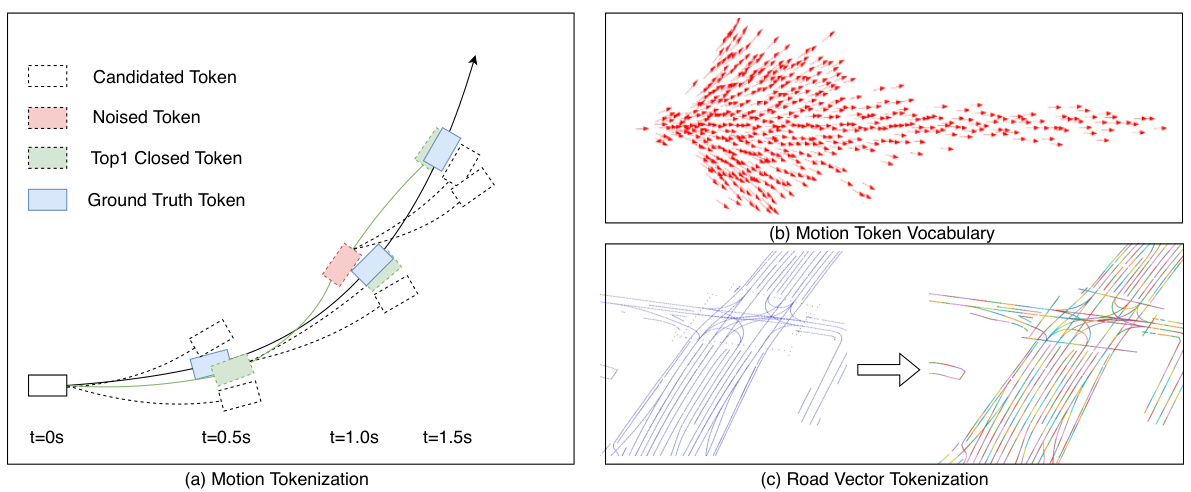
This figure illustrates the tokenization process for agent motion and road vectors. (a) shows the iterative token selection process for agent motion, using the previous token and adding noise for robustness. (b) displays the resulting motion token vocabulary. (c) demonstrates how continuous road vector features are segmented and matched to discrete road tokens.
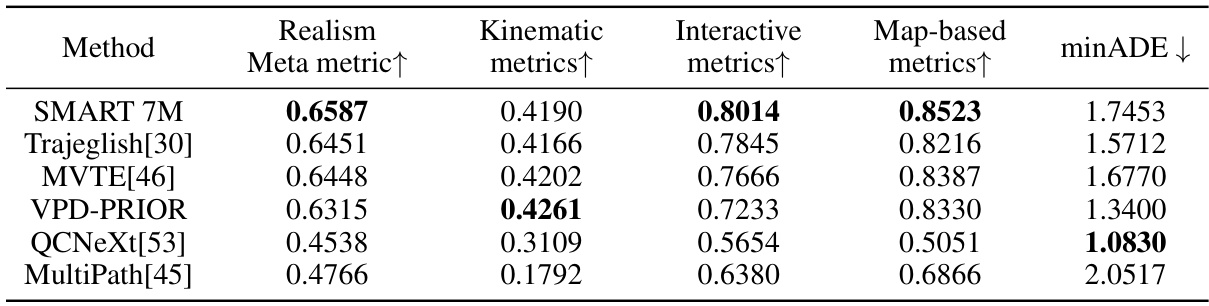
This table compares the performance of the SMART 7M model against other state-of-the-art models on the Waymo Open Motion Dataset (WOMD) 2023 Sim Agents benchmark. It shows the results across multiple metrics, including Realism (a meta-metric combining various aspects of realism), Kinematic metrics (measuring the accuracy of predicted kinematic properties), Interactive metrics (evaluating the quality of interactions between agents), and Map-based metrics (assessing how well the generated trajectories align with the map). The lower the minADE (minimum average displacement error), the better the performance.
In-depth insights#
SMART: MotionGen#
SMART: MotionGen represents a significant advancement in autonomous driving simulation. Its core innovation lies in modeling vectorized map and agent trajectory data as discrete sequence tokens, processed via a decoder-only transformer architecture for next-token prediction. This approach cleverly leverages the strengths of large language models for sequential data processing, enabling the model to learn intricate spatial-temporal relationships within driving scenarios. The use of tokens allows for scalable training by processing vast amounts of data, significantly improving the model’s generalization capabilities. The decoder-only architecture leads to faster inference times, crucial for real-time applications. SMART: MotionGen’s demonstrated success in zero-shot generalization across diverse datasets is particularly promising, suggesting its potential for broader application and improved safety in autonomous driving simulation. However, future work should explore the limitations of the tokenization scheme and further investigate the scalability of the model with even larger datasets to fully realize its potential.
Tokenization Schemes#
Effective tokenization is crucial for the success of any model processing sequential data, and this is especially true for the complex spatiotemporal data found in autonomous driving scenarios. A well-designed tokenization scheme will directly impact the model’s ability to capture relevant relationships between agents, their trajectories, and the surrounding environment. The choice between discretizing continuous data into discrete tokens or using a continuous representation needs careful consideration. Discretization simplifies processing but may lead to information loss, while continuous representations maintain detail but increase computational complexity. Furthermore, the method chosen significantly influences generalization and scalability, as different tokenization approaches will highlight or obscure specific patterns in the data. The optimal scheme would balance information preservation, computational efficiency, and generalizability across different datasets and scenarios, ultimately driving the model’s ability to learn the underlying dynamics of autonomous driving motion.
Zero-Shot Learning#
Zero-shot learning, a captivating area of machine learning, aims to enable models to recognize or classify objects or concepts they have never encountered during training. This is achieved by leveraging auxiliary information, such as semantic word embeddings or visual attributes, to bridge the gap between seen and unseen classes. The core challenge lies in effectively representing the relationships between seen and unseen data. Successful strategies often involve learning a shared representation space where both seen and unseen categories are meaningfully embedded, allowing for generalization to novel concepts based on their similarity to the training data. This is particularly crucial in scenarios with limited data for each class, and presents a compelling alternative to traditional approaches that require extensive data for every class. SMART, for instance, demonstrates this potential by achieving competitive performance on unseen datasets, showcasing the promise of zero-shot generalization for autonomous driving motion generation. The ability to extrapolate knowledge to new domains is a key advantage, particularly in data-scarce contexts like autonomous driving. Future research will focus on improving the reliability and robustness of these methods by addressing issues such as knowledge representation, handling noisy data, and mitigating the impact of domain shifts.
Model Scalability#
The concept of ‘Model Scalability’ in the context of AI, particularly within the autonomous driving domain, is crucial. It examines how well a model’s performance and efficiency scale with increasing data volume and model complexity. The research highlights the importance of scalability for real-world applications, where massive datasets and real-time processing are essential. A scalable model can effectively leverage larger datasets to improve accuracy and handle the complexity of real-world scenarios. The study demonstrates SMART’s scalability by showcasing its ability to maintain performance as the amount of training data increases. The authors emphasize that scalability is not solely about increasing model size, but also about designing efficient model architectures that can effectively manage and process large volumes of data. Zero-shot generalization further validates the model’s ability to scale across different datasets, showcasing robustness and reducing the reliance on extensive retraining. This underscores that achieving model scalability involves careful consideration of data efficiency and architecture design to ensure the model’s suitability for large-scale deployment and real-time performance. The demonstration of scalability provides strong evidence supporting SMART’s potential for real-world applications in autonomous driving simulation.
Future of SMART#
The future of SMART hinges on addressing its current limitations and capitalizing on its strengths. Scalability remains a key challenge; while SMART demonstrates promising scaling laws, access to larger, more diverse datasets is crucial for further improvements. Generalizability is another area for growth; although SMART exhibits zero-shot capabilities, enhancing its performance across diverse unseen scenarios is important. Future development should explore advanced tokenization techniques that capture finer-grained spatial and temporal information, potentially leveraging LLMs or incorporating more sophisticated map representations. Real-time performance is vital; ongoing optimization efforts should focus on reducing inference latency for practical deployment in autonomous driving simulation. Finally, research into integration with other autonomous driving modules (planning, prediction, control) will be essential to fully realize SMART’s potential as a comprehensive simulation tool.
More visual insights#
More on figures

This figure illustrates the architecture of the SMART model. Panel (a) shows the decoder-only transformer used for predicting the next motion token for multiple agents. It takes as input previous motion tokens, interactive agent motion tokens (showing inter-agent interactions), and encoded road tokens. Panel (b) details a separate training task focusing on spatial understanding of road vectors, using a separate neural network (RoadNet) to predict the next road token in the sequence.

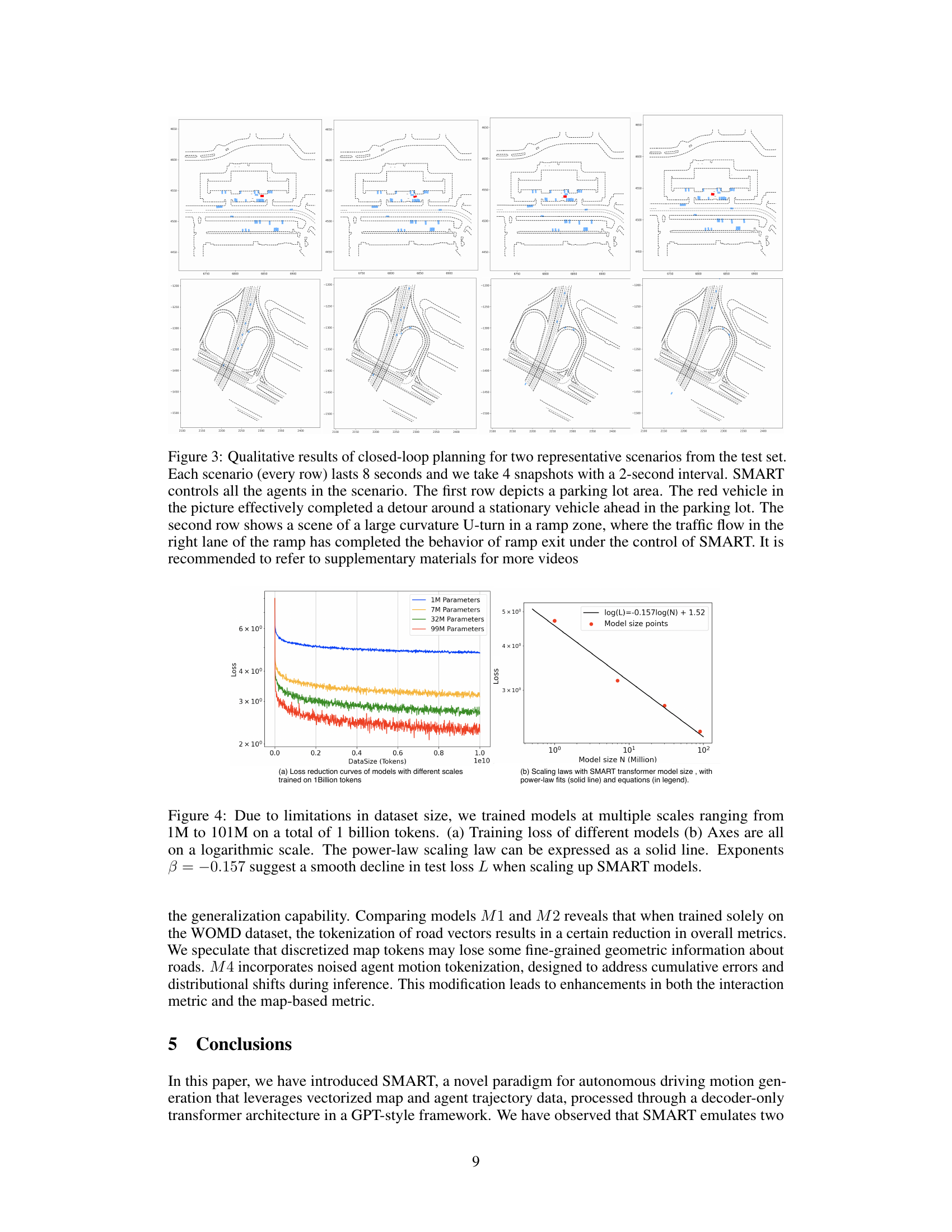
This figure shows two example scenarios of the SMART model performing closed-loop planning. The top row demonstrates successful navigation in a parking lot, avoiding a stationary vehicle. The bottom row showcases successful negotiation of a sharp U-turn on a ramp.
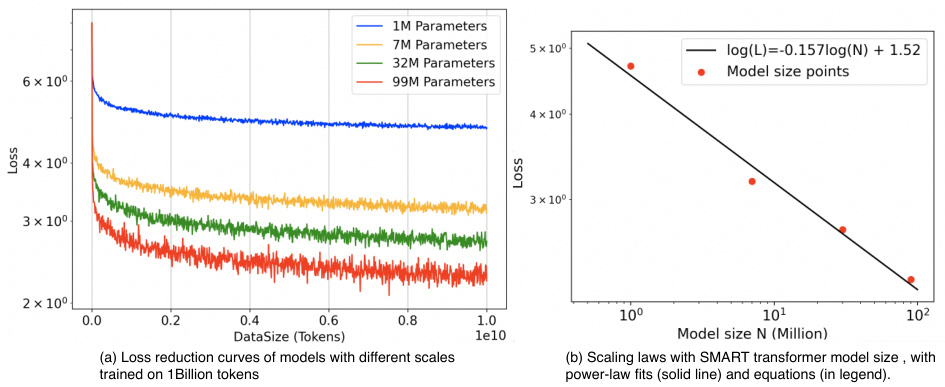
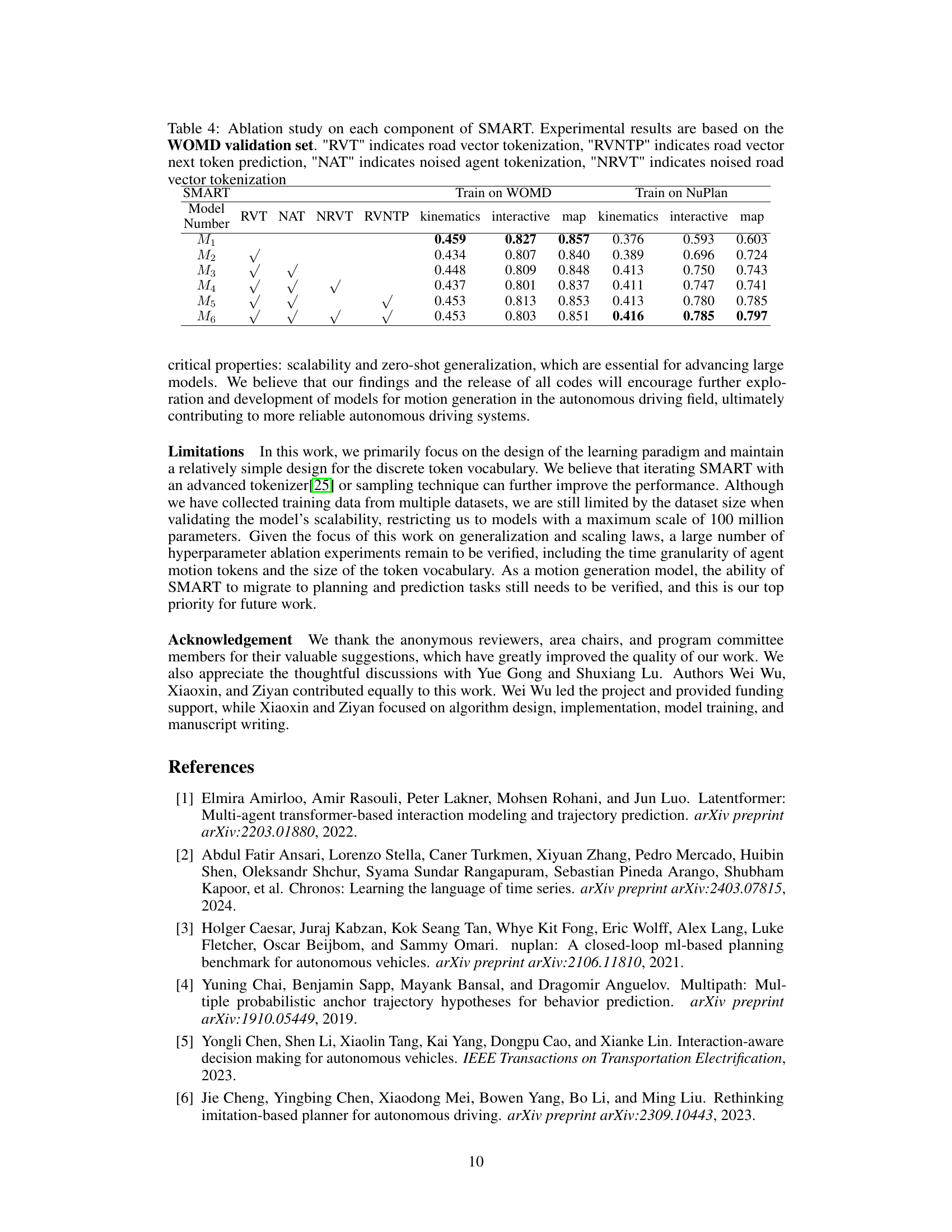
This figure shows the results of experiments on the scalability of the SMART model. The left panel (a) presents training loss curves for models with different numbers of parameters (1M, 7M, 32M, and 99M) trained on 1 billion tokens. The right panel (b) displays a log-log plot illustrating the power-law scaling relationship between model size and test loss, demonstrating that the SMART model exhibits consistent performance improvements as its size increases. The equation of the fitted power law is also provided.

This figure compares the performance of SMART model with and without road vector tokenization and noise tricks across different datasets. It demonstrates the impact of these techniques on the model’s generalization ability. The results show that SMART model with these enhancements generalizes better across datasets than the version without them, achieving higher scores on the overall evaluation metric, even when trained on a smaller dataset like NuPlan.
More on tables
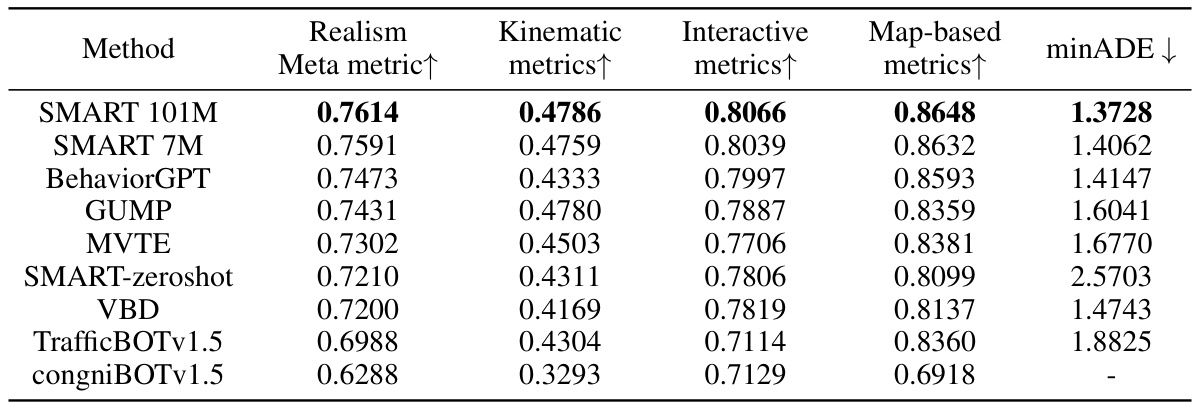
This table compares the performance of the SMART model (with 101M and 7M parameters) against other state-of-the-art models on the WOMD 2024 Sim Agents benchmark. The comparison includes metrics for Realism (Meta metric), Kinematic, Interactive, and Map-based performance, as well as the minimum Average Displacement Error (minADE). It also shows the performance of a SMART model trained only on the NuPlan dataset (‘SMART-zeroshot’), demonstrating its zero-shot generalization capabilities.
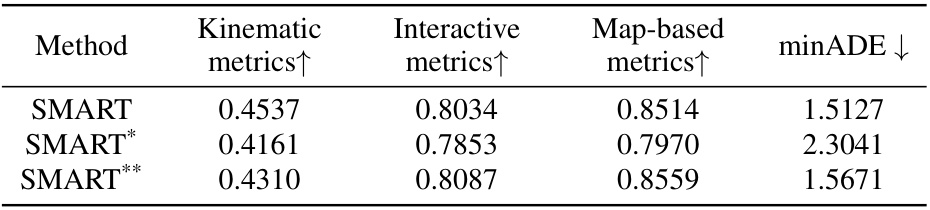
This table presents the results of a zero-shot generalization experiment. Three SMART models are evaluated: one trained solely on the Waymo Open Motion Dataset (WOMD), one trained only on the NuPlan dataset, and a third model that fine-tuned the NuPlan-trained model on WOMD. The table shows the performance of each model across three metrics: kinematic, interactive, and map-based, along with the minimum average displacement error (minADE). The results highlight the generalization capabilities of SMART, especially when a small amount of fine-tuning is applied.
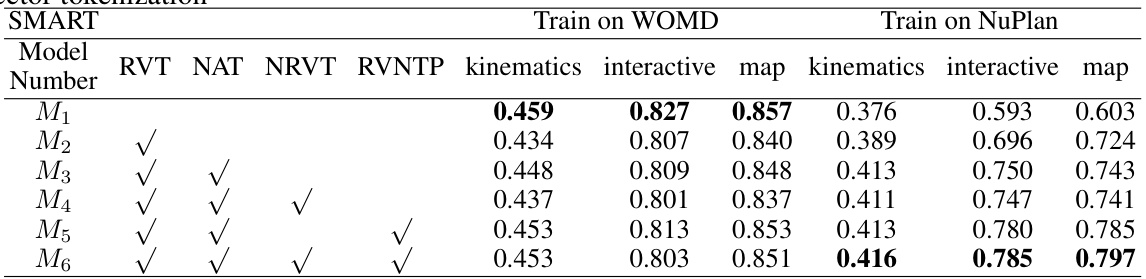
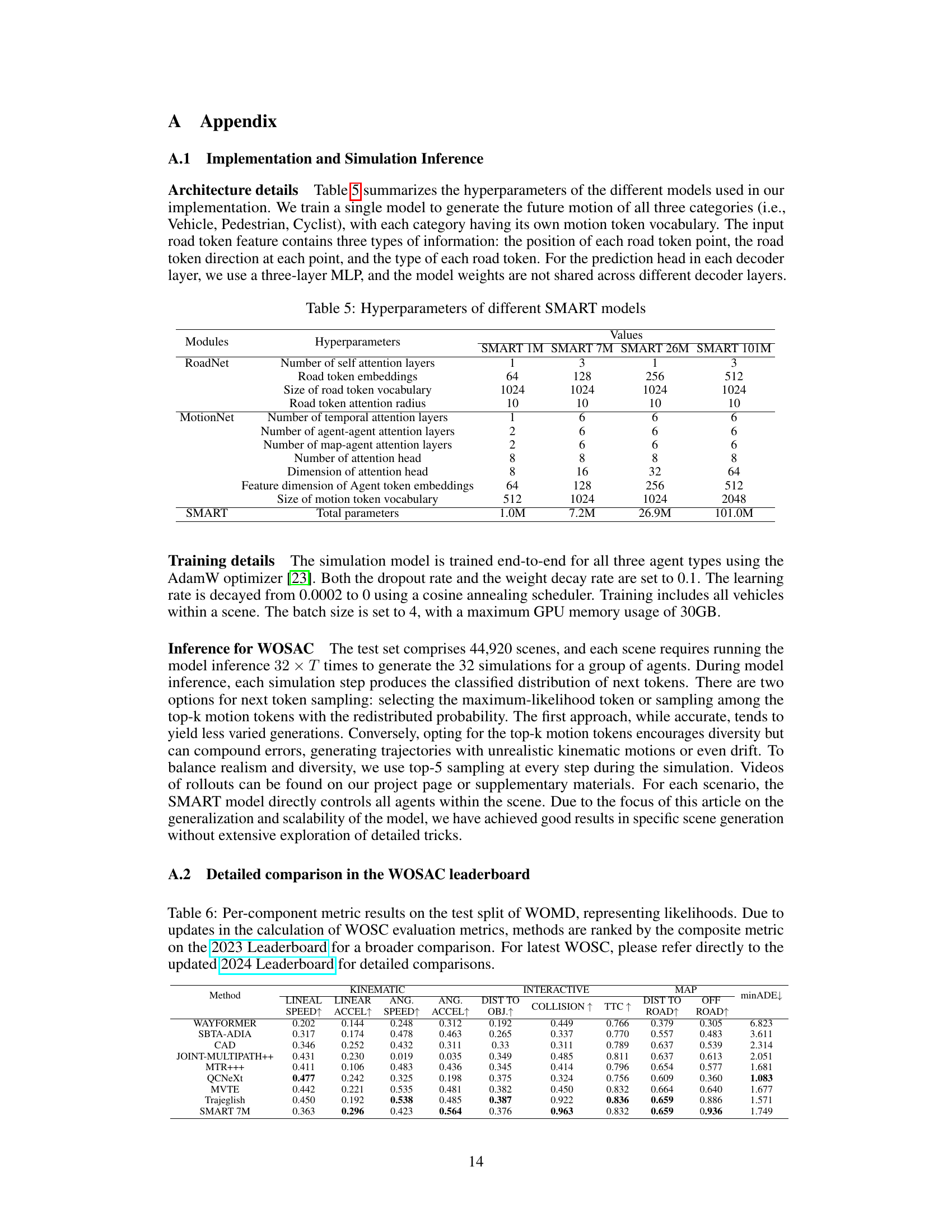
This table presents the ablation study results for different components of the SMART model. It shows the impact of road vector tokenization (RVT), road vector next token prediction (RVNTP), noised agent tokenization (NAT), and noised road vector tokenization (NRVT) on the model’s performance across various metrics (kinematics, interactive, map) when trained on both WOMD and NuPlan datasets. Each row represents a model configuration, indicating which components were included (√) and the corresponding performance metrics.
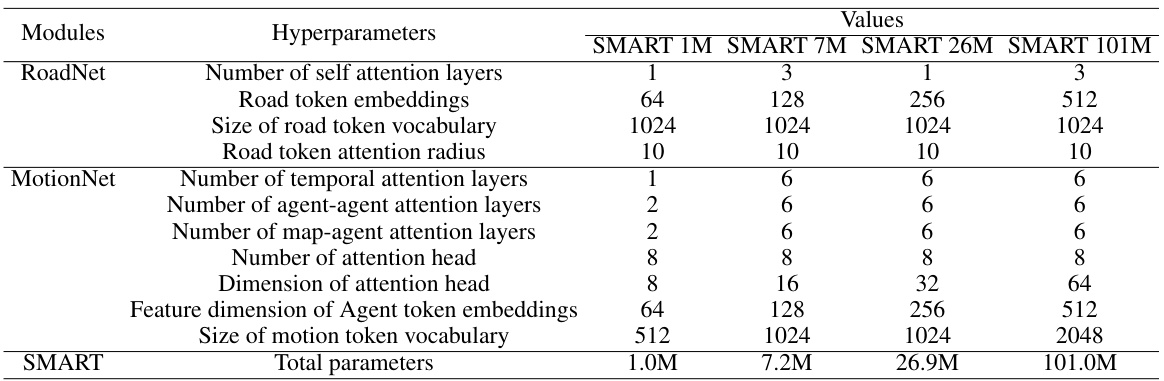
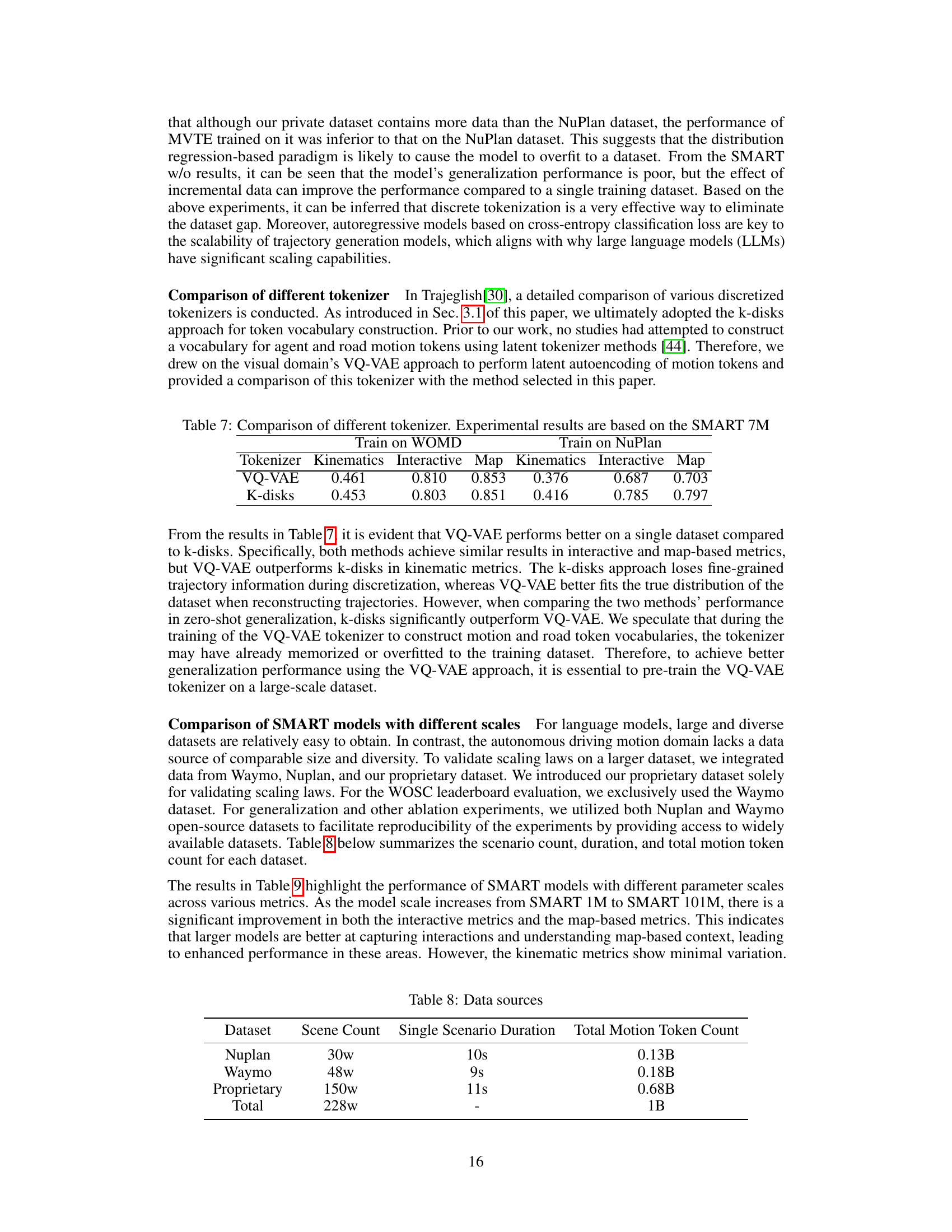
This table lists the hyperparameters used for training four different SMART models with varying model sizes (1M, 7M, 26M, and 101M parameters). The hyperparameters are categorized into those for the RoadNet (road token encoder), MotionNet (agent motion decoder), and overall SMART model architecture. Specific hyperparameters listed include the number of self-attention layers, embedding dimensions, vocabulary sizes, attention radius, and the total number of parameters in each model. The table provides a detailed specification of the architectural choices made for each model variant.
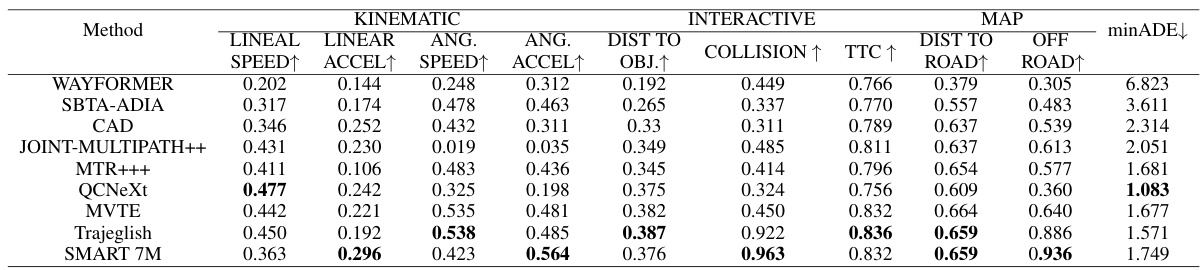
This table compares the performance of SMART 7M with other state-of-the-art models on the Waymo Open Motion Dataset (WOMD) 2023 Sim Agents benchmark. It shows a comparison across multiple metrics, including realism (meta-metric), kinematic metrics (minADE), interactive metrics, and map-based metrics. The results highlight SMART 7M’s performance relative to other leading models in autonomous driving simulation.

This table compares the performance of two different tokenizers, VQ-VAE and k-disks, used in the SMART model. The comparison is done for both models trained on the WOMD and NuPlan datasets. The metrics used for comparison are Kinematics, Interactive, and Map-based metrics, reflecting different aspects of driving motion generation.

This table presents a summary of the data sources used in the paper, including the number of scenes, single scenario duration, and the total number of motion tokens for each dataset (NuPlan, Waymo, Proprietary). The total dataset combines these sources to create a large-scale dataset for training and validating the SMART model.

This table presents the results of experiments conducted to evaluate the scalability of the SMART model. Different model sizes (1M, 7M, 26M, and 101M parameters) were trained on a large dataset. The table shows the performance (Kinematic, Interactive, and Map-based metrics) achieved by each model, along with the corresponding training time and average inference time. This allows for analysis of how performance, training time, and inference speed change as the model scale increases.
Full paper#