↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Human language is a complex system encompassing both semantics (meaning of words) and pragmatics (how meaning is used in context). Current research often treats these aspects separately, limiting understanding of language’s evolution and development. This study aimed to bridge this gap by creating a computational model of emergent communication in artificial agents that incorporates both aspects.
The researchers developed a new information-theoretic framework for training AI agents to communicate effectively. This framework integrates utility maximization (a key aspect of pragmatics) with information-theoretic constraints (believed to shape semantic systems). They tested their approach using a visual domain, finding that agents trained this way developed a shared lexicon exhibiting key properties of human language. This suggests that both semantic and pragmatic principles are necessary for the emergence of human-like communication systems. This work provides a significant advance in understanding how language might evolve and offers a novel computational framework for building more human-like AI systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in linguistics, cognitive science, and AI because it bridges the gap between semantics and pragmatics in emergent communication. It proposes a novel information-theoretic framework that combines utility maximization with information bottleneck principles, offering a new computational model for studying language evolution and human-like communication in artificial agents. This opens avenues for developing more human-like AI systems and improves our understanding of the complex interplay between semantics and pragmatics in human language.
Visual Insights#
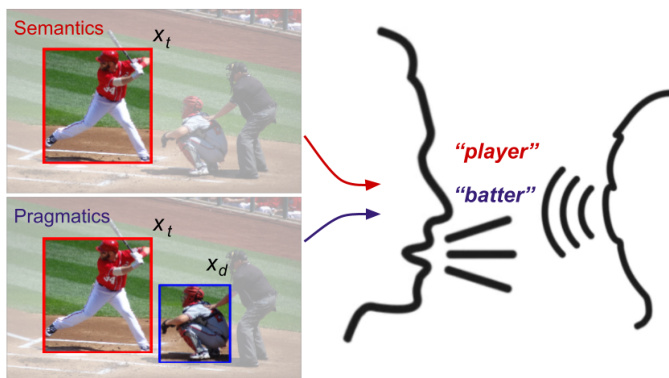
This figure shows an example from the ManyNames dataset to illustrate the difference between semantic and pragmatic communication. In the semantic setting (top), a speaker names a target object without considering context. The image shows a baseball player batting, and several names are given that people provided, such as ‘man’, ‘batter’, etc. showing the variability. In the pragmatic setting (bottom), the speaker and listener share the context of seeing two objects. Only the speaker knows which is the target; the goal is for the speaker to communicate the target object to the listener.

This table compares the performance of four different models in terms of complexity, lexicon size, normalized information distance (NID), utility, and mean squared error (MSE). The models differ in the weighting of utility, informativeness, and complexity in their objective functions. The model with the best alignment to English is highlighted, showing a good balance between these three factors. Baseline models show the effects of prioritizing only one of the three factors.
In-depth insights#
Pragmatics & Semantics#
The interplay between pragmatics and semantics is a crucial aspect of human language, and this paper delves into their co-evolution within an information-theoretic framework. Pragmatics, focusing on context-dependent meaning, is shown to influence the emergence of a shared lexicon. Semantics, encompassing word meanings independent of context, is shaped by the communicative pressures and general constraints believed to influence human linguistic systems. The study cleverly integrates utility maximization (tied to pragmatics) with information-bottleneck principles (linked to semantics) to model how these two forces interact in shaping the lexicon. The authors propose and test a novel framework where artificial agents learn to communicate through pragmatic interactions, evaluating the resulting lexicon against human-like properties. This approach offers valuable insights into how both pragmatic reasoning and semantic pressures contribute to the development and structure of human language, offering a new lens through which to explore the complexity of linguistic systems.
IB Framework Ext.#
Extending the Information Bottleneck (IB) framework for emergent communication presents a significant opportunity to model the interplay between semantics and pragmatics in language evolution. The core idea is to integrate task-specific utility maximization (reflecting pragmatic pressures) with the IB objective (capturing semantic constraints). This extension allows for a richer understanding of how lexicons emerge from communicative interactions, moving beyond traditional frameworks that assume a pre-existing shared lexicon. By incorporating both utility and informational constraints, the model can potentially explain the emergence of human-like lexical properties and efficient communication strategies. This approach highlights the crucial trade-off between communicative efficiency (minimizing complexity and maximizing informativeness) and achieving task-specific goals (maximizing utility). The success of this extended framework depends on appropriately balancing these competing objectives, as extreme emphasis on any single factor could lead to unrealistic or inefficient language systems. Further research should investigate the parameter space to identify optimal trade-offs and explore the effects of different learning dynamics and training regimes on lexicon development.
ManyNames Dataset#
The ManyNames dataset serves as a crucial foundation for this research, providing a rich visual domain of naturalistic images annotated with multiple names for each target object. This multi-label nature is key, directly addressing the study’s focus on how pragmatic context influences lexical selection. The dataset’s naturalistic image content avoids biases associated with simpler, artificial stimuli, making the emergent communication system more ecologically valid. The existence of human-annotated names offers a valuable benchmark to assess the ‘human-likeness’ of the emergent lexicon developed by the artificial agents. The explicit consideration of both semantic and pragmatic communication in the annotation scheme enhances the assessment process. The use of this dataset allows for the testing and validation of the proposed information-theoretic framework in a challenging and complex visual environment, making it a rigorous test for the model’s ability to learn realistic communicative behavior.
Human-like Lexicon#
The concept of a “Human-like Lexicon” in the context of artificial intelligence and emergent communication is multifaceted. It probes the ability of AI agents to develop lexicons that mirror the properties of human language. This involves not just the creation of a vocabulary, but also the implicit understanding of semantic relationships between words, the ability to utilize words appropriately within various contexts, and the capacity for efficient communication. The key challenge is to design systems that leverage both pragmatic and semantic aspects of language. Pragmatics involves using context to understand meaning, while semantics is the study of meaning independent of context. The human-like lexicon would emerge from a balance between optimizing for task utility (pragmatics) and minimizing communication complexity (semantics), thereby revealing an efficient and context-aware lexical system. Successful models would exhibit a lexicon that is both informative and concise, matching human characteristics in terms of word selection and usage. Furthermore, a human-like lexicon will depend heavily on the training data and parameters used in the experiment, showcasing the importance of appropriate datasets and the interplay between different algorithmic choices in achieving human-like capabilities. Therefore, a comprehensive understanding necessitates examining the trade-off between semantic informativeness, pragmatic utility, and lexical complexity during the system’s learning process. The evaluation of such systems requires careful comparison with human linguistic data, to judge the extent to which they mirror the properties of natural language.
Future Work#
The paper’s core contribution lies in demonstrating the co-evolution of semantics and pragmatics in emergent communication systems, using an information-theoretic framework. Future work should focus on extending this model to incorporate more complex linguistic features, such as syntax and morphology, moving beyond the lexical level explored here. This would involve developing a more sophisticated communication model that can handle compositional meaning and more nuanced contextual information. Furthermore, testing the model on a wider variety of languages and cultural contexts is crucial for establishing its generalizability and understanding cross-linguistic variations in lexical semantic systems. The current model uses a pre-trained object classification model; therefore, future research should investigate the impact of different visual feature extraction methods on the emergent lexicon. Investigating whether the same principles apply to other communication modalities, like auditory or multimodal communication, could provide valuable insights into the universality of the proposed framework. Finally, exploring real-world applications of this framework could have a significant impact on fields like human-computer interaction and artificial intelligence, enabling more natural and intuitive communication between humans and machines.
More visual insights#
More on figures

This figure shows the architecture of the communication model used in the paper. The model is trained in a pragmatic setting, where both speaker and listener share contextual information (x0, x1), but only the speaker knows the target object (xt). The speaker uses a Variational Autoencoder (VAE) to generate a representation of both the target (mt) and a distractor (md), then encodes the target representation into a communication signal (w). The listener also uses a VAE to decode the signal into a representation (mt) and uses this representation to identify the target. The model is then evaluated in a semantic setting, where only the target is shown to the speaker. This evaluates the emergent lexicon (the communication signals) by testing the capacity of the communication signals to convey the meaning of the object to the listener without context.

This figure displays the results of the experiment using a simplex to show the tradeoff between utility, informativeness, and complexity, and their effects on the emergent lexicon. It shows how different weighting of these factors leads to different properties in the resulting communication system, with a combination of all three factors being required to create a system that best aligns with human language properties. The figure shows that human-like properties emerge from an optimal trade-off between these three factors.

This figure visualizes the performance of the model across a range of hyperparameter settings, showing how different balances of utility, informativeness, and complexity lead to different outcomes. The plots illustrate the trade-offs between these factors, and how a balance near the top of the simplex leads to the most human-like results.
Full paper#



















