↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) often struggle with complex reasoning tasks. Zero-shot Chain-of-Thought (CoT) prompting, while effective, suffers from the limitation that a single prompt cannot optimally serve all instances. Existing methods focus on finding the best task-level prompt, neglecting instance-specific nuances.
This research introduces Instance-Adaptive Prompting (IAP), a novel zero-shot CoT approach. IAP analyzes the information flow within the LLM during reasoning using saliency scores to identify effective and ineffective prompts. By adaptively choosing prompts based on these analyses, IAP achieves consistent performance improvements over existing methods across various tasks, showcasing the importance of instance-specific considerations in improving LLM reasoning.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the limitations of existing zero-shot Chain-of-Thought (CoT) prompting methods by introducing an instance-adaptive approach. This is important because it leads to significant improvements in LLM reasoning performance across various tasks, opening new avenues for research in adaptive prompting strategies and enhancing the capabilities of large language models. The findings are relevant to ongoing research efforts to improve LLM reasoning and provide valuable insights into the underlying mechanisms of CoT prompting.
Visual Insights#

This figure shows an example of how different prompts can affect the LLM’s reasoning process. The same question is given to the LLM with two different prompts: ‘Let’s think step by step.’ and ‘Don’t think. Just feel.’. The first prompt leads the LLM through a step-by-step reasoning process, resulting in the correct answer but with an extra, erroneous step. The second prompt leads to a concise, incorrect answer. This highlights the impact of prompt engineering on the LLM’s performance and reasoning accuracy.
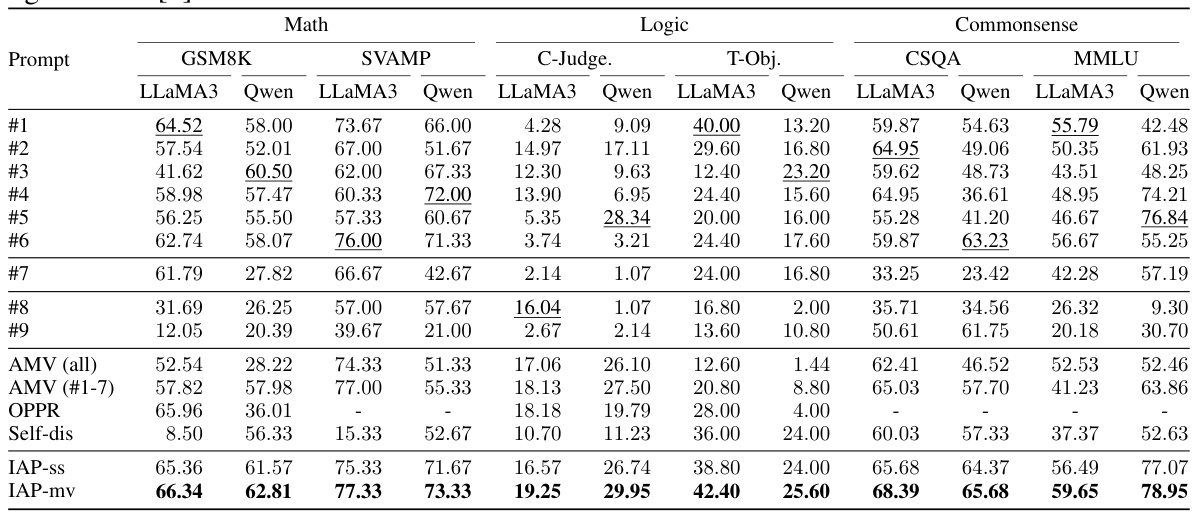
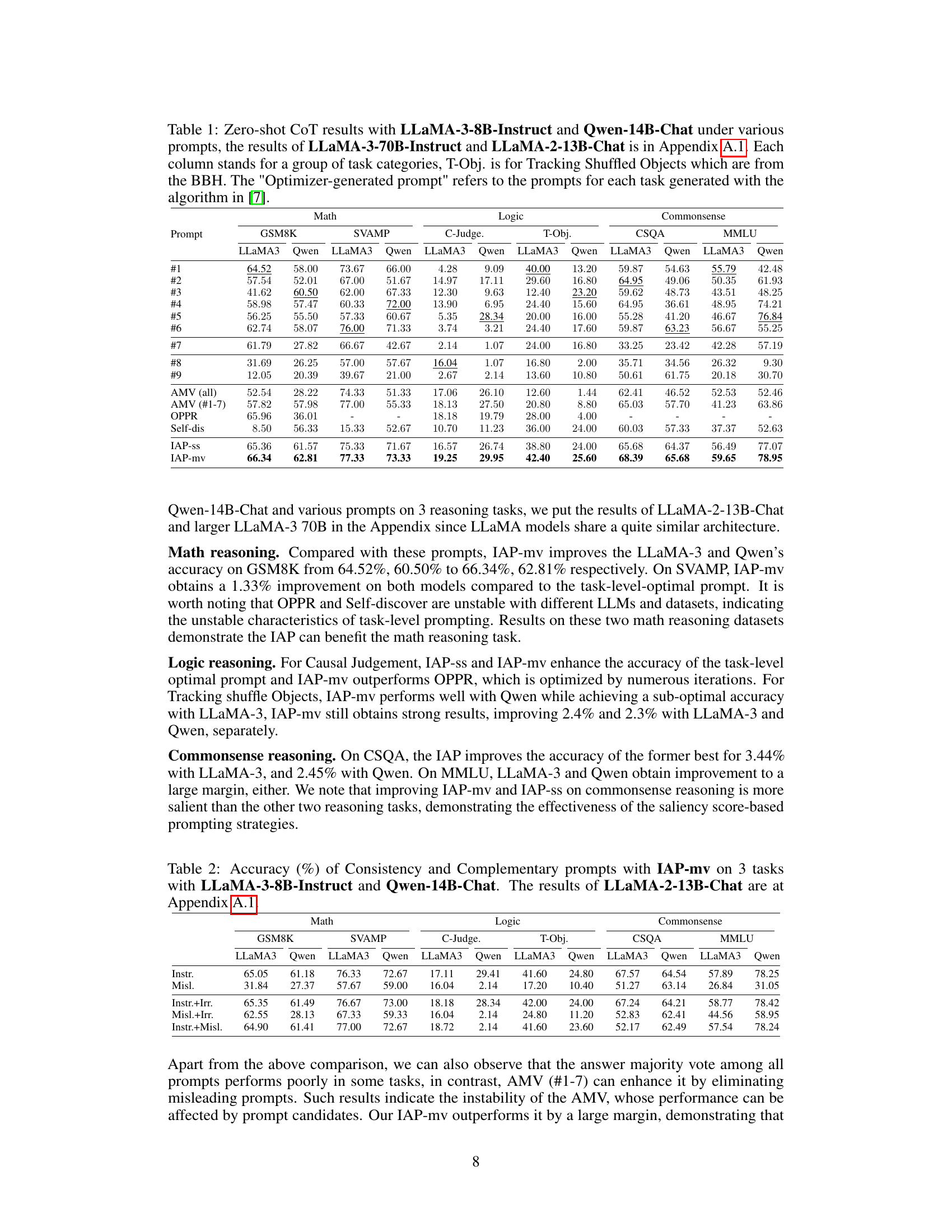
This table presents the zero-shot chain-of-thought (CoT) reasoning results for different prompts on several LLMs (LLaMA-3-8B-Instruct, Qwen-14B-Chat) across various tasks categorized as Math, Logic, and Commonsense reasoning. It compares the performance of different prompts (#1 through #9) against several baseline methods (AMV, OPPR, Self-dis, IAP-ss, and IAP-mv). The results show the accuracy achieved by each prompt and method on GSM8K, SVAMP, C-Judge, T-Obj, CSQA, and MMLU datasets.
In-depth insights#
Adaptive prompting#
Adaptive prompting techniques in large language models (LLMs) aim to dynamically adjust prompts based on the specific input and model’s performance. Unlike static prompting, which uses a fixed prompt for all inputs, adaptive methods enhance performance by tailoring prompts to the nuances of each input. This could involve techniques like iteratively refining prompts based on intermediate model outputs or selecting prompts from a pool of candidates using criteria such as model confidence scores or information flow analysis. Successful adaptive prompting strategies often leverage feedback mechanisms, allowing the model to learn and adapt over time, thus improving its reasoning and overall accuracy. A key challenge lies in efficiently and effectively determining the optimal prompt adaptation strategy. This often necessitates a tradeoff between computational cost and performance gains.
Saliency analysis#
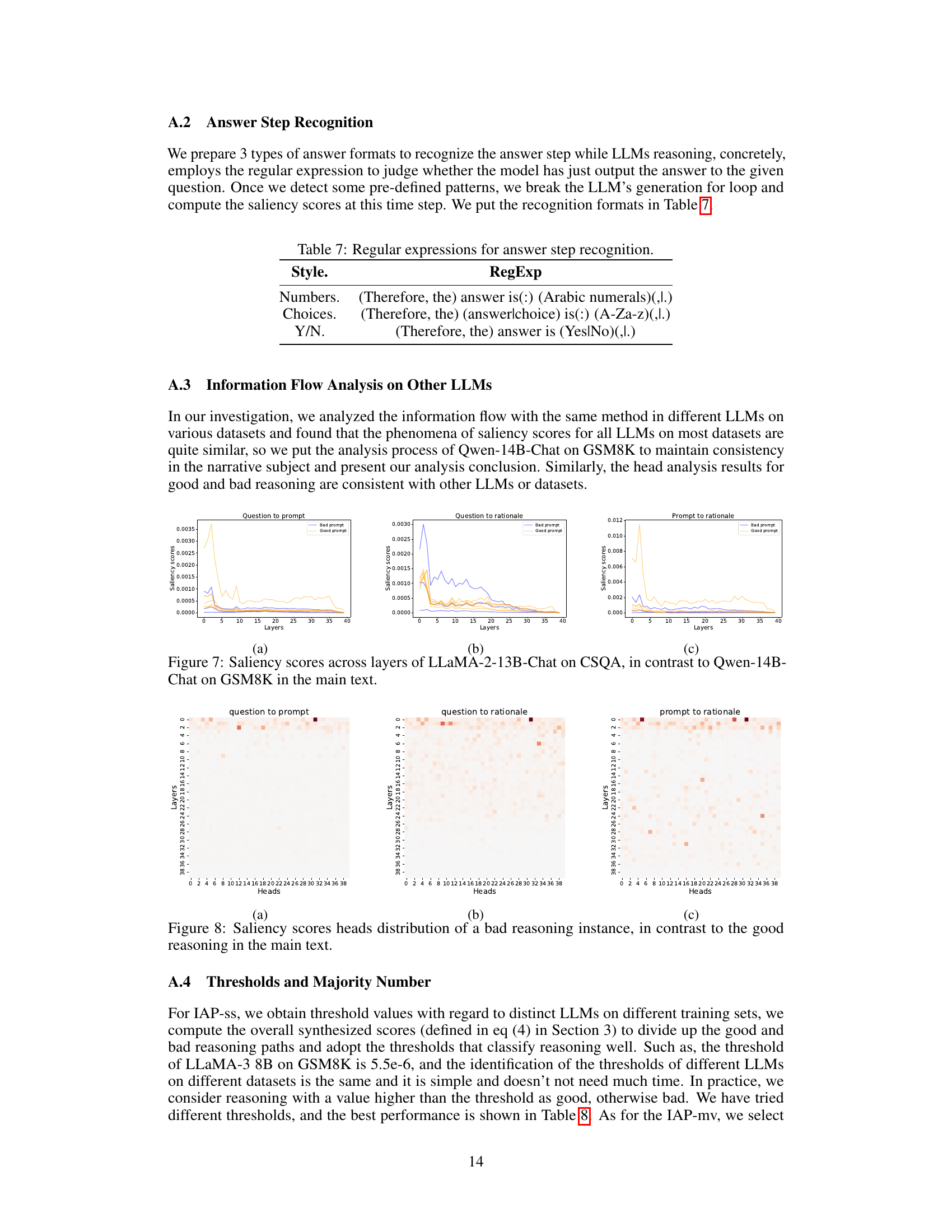
The saliency analysis section of this research paper is crucial for understanding the inner workings of the model. By analyzing attention weights, it reveals how information flows between different parts of the model’s reasoning process. This includes how information flows from the question to the prompt, from the question to the rationale, and from the prompt to the rationale. The study finds that successful reasoning requires semantic information from the question to be aggregated to the prompt first, and then the rationale to aggregate information from both the question and the prompt. This highlights the importance of a well-crafted prompt in guiding the LLM’s reasoning. The visualization of saliency scores, especially across layers and heads, provides valuable insights into the hierarchical and systematic progression of semantics within the model, strengthening the understanding of the model’s internal mechanisms during reasoning. This approach offers a more fine-grained way of analyzing zero-shot chain of thought prompting, moving beyond task-level analysis to an instance-level analysis. This instance-level adaptive approach to prompt selection is a key contribution of the paper.
LLM reasoning#
The paper delves into the intricacies of Large Language Model (LLM) reasoning, particularly focusing on the zero-shot chain-of-thought (CoT) prompting technique. A core argument is that the effectiveness of a single, task-level prompt is limited because it lacks adaptability across diverse instances. The authors introduce instance-adaptive prompting (IAP) as an alternative approach, which dynamically differentiates between good and bad prompts for individual instances. This adaptive strategy is grounded in an information flow analysis of LLMs, using saliency scores to investigate information movement between the question, prompt, and rationale. The analysis reveals crucial relationships in successful reasoning: semantic information effectively flows from the question to the prompt, and subsequently, the rationale aggregates information directly from the question and indirectly via the prompt. The IAP algorithm utilizes these insights to enhance zero-shot CoT performance, significantly outperforming task-level methods in experiments across various LLMs and reasoning tasks. IAP’s success underscores the importance of instance-specific prompt engineering for improved LLM reasoning capabilities.
IAP effectiveness#
The paper demonstrates the effectiveness of the Instance-Adaptive Prompting (IAP) strategy for enhancing zero-shot Chain-of-Thought (CoT) reasoning in large language models (LLMs). IAP consistently outperforms task-level methods across various reasoning tasks (math, logic, commonsense) and LLMs (LLaMA, Qwen). This improvement is attributed to IAP’s ability to adaptively select prompts based on the specific instance, rather than relying on a single, universally applied prompt. The key to IAP’s success lies in its analysis of information flow within the LLM, using saliency scores to identify prompts that effectively guide the reasoning process. Good prompts facilitate information flow from question to prompt and then from both to the rationale, while poor prompts fail to establish this crucial connection. This insight provides a novel perspective on zero-shot CoT prompting, moving beyond the search for optimal task-level prompts to an instance-specific approach. Furthermore, the study highlights the effectiveness of both sequential and majority vote variations of IAP. The research contributes a significant advance in improving the efficiency and accuracy of zero-shot CoT reasoning in LLMs.
Future work#
Future research directions stemming from this instance-adaptive zero-shot chain-of-thought prompting work could explore several promising avenues. Extending the approach to more complex reasoning tasks and larger language models is crucial for validating its broader applicability and effectiveness. A key area would be investigating the interaction between different prompt styles and model architectures, seeking to identify optimal pairings for specific reasoning domains. Developing more sophisticated methods for prompt selection and adaptation that go beyond simple saliency analysis would be highly beneficial, perhaps incorporating techniques from reinforcement learning or meta-learning. Furthermore, research could focus on developing more robust metrics for evaluating zero-shot CoT reasoning, considering factors beyond simple accuracy, such as reasoning efficiency and the interpretability of the generated rationales. Finally, understanding the potential biases inherent in instance-adaptive prompting and developing mitigation strategies is critical for ensuring fair and equitable outcomes. The work’s insights on the dynamics of information flow within LLMs hold significant potential for advancements in model explainability and interpretability.
More visual insights#
More on figures

This figure visualizes the saliency matrices for good and bad reasoning examples using two different prompts: ‘Let’s think step by step’ and ‘Don’t think, just feel.’ The color intensity represents the strength of information flow between the question, prompt, and rationale. The red, blue, and green boxes highlight the question-to-prompt, question-to-rationale, and prompt-to-rationale information flow, respectively. The figure demonstrates how the information flow differs between successful and unsuccessful reasoning instances.

This bar chart compares the average saliency scores for three different information flows (question-to-prompt, question-to-rationale, prompt-to-rationale) between good and bad reasoning instances from the GSM8K dataset. The higher saliency scores for good reasoning instances across all three flows suggest that successful reasoning involves a strong interplay between the question, prompt, and rationale, where the prompt effectively captures the question’s semantics and the rationale aggregates information from both the question and the prompt.

This figure shows the saliency scores for the interaction between the question, prompt, and rationale across different layers of the LLM. The saliency score represents the strength of the semantic information flow between these components. The results indicate that effective prompts show a high saliency score in the initial layers (shallow layers), transferring information from the question to the prompt and then to the rationale. Ineffective prompts show much lower saliency scores, especially in the shallow layers.

This figure visualizes the saliency scores for three different information flows within the LLM: question to prompt, question to rationale, and prompt to rationale. The heatmaps show the distribution of saliency scores across different layers and heads of the transformer model. Darker colors indicate stronger information flow. The figure helps to illustrate the different information aggregation patterns between successful and unsuccessful reasoning paths.
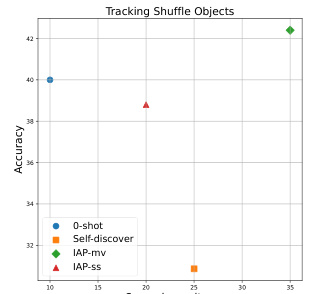
This figure shows a comparison of the efficiency and accuracy of different prompting strategies for the ‘Tracking Shuffle Objects’ task, using the LLaMA-3-8B-Instruct language model. The strategies compared are 0-shot (using the best single prompt found for the task), Self-discover, IAP-mv (Instance-Adaptive Prompting - majority vote), and IAP-ss (Instance-Adaptive Prompting - sequential substitution). The x-axis represents the time taken per iteration in seconds, and the y-axis represents the accuracy achieved. The figure demonstrates the trade-off between efficiency and accuracy offered by the different approaches; IAP-mv achieves high accuracy but at the cost of longer processing time.

This figure visualizes the saliency scores (representing the flow of semantic information) between different components (question, prompt, rationale) across multiple layers of an LLM during zero-shot chain-of-thought reasoning. It compares the information flow for both ‘good’ prompts (leading to correct answers) and ‘bad’ prompts (leading to incorrect answers). The different lines show the saliency at each layer for each of the three relationships. The graph shows that effective prompts have a strong information flow from the question to the prompt in the earlier layers and a sustained flow from both the question and the prompt to the rationale across most layers, while ineffective prompts show a weaker flow of information.
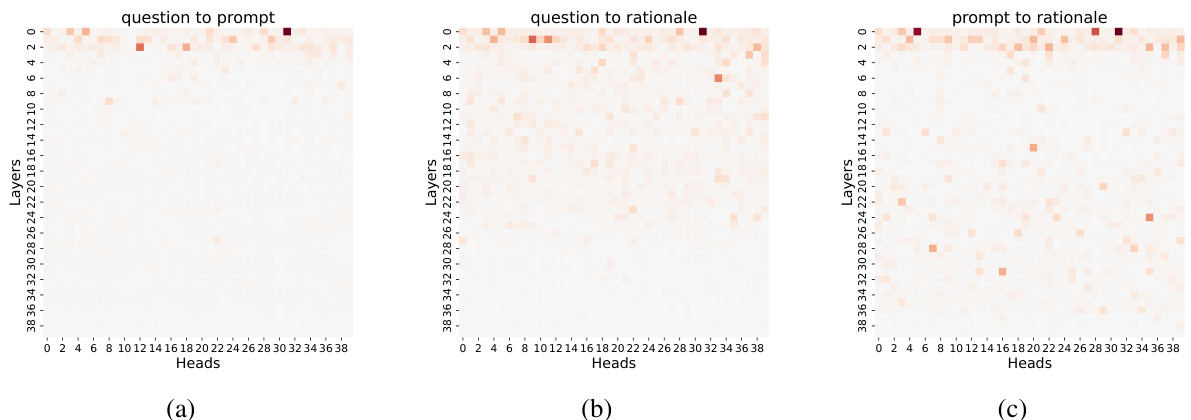
This figure visualizes the saliency scores across different heads and layers of a transformer model for three different semantic relationships: question-to-prompt, question-to-rationale, and prompt-to-rationale. The intensity of the color represents the strength of the interaction, with darker colors indicating stronger interactions. The figure allows for a detailed analysis of how information flows between these components during the zero-shot chain of thought (CoT) reasoning process.
More on tables
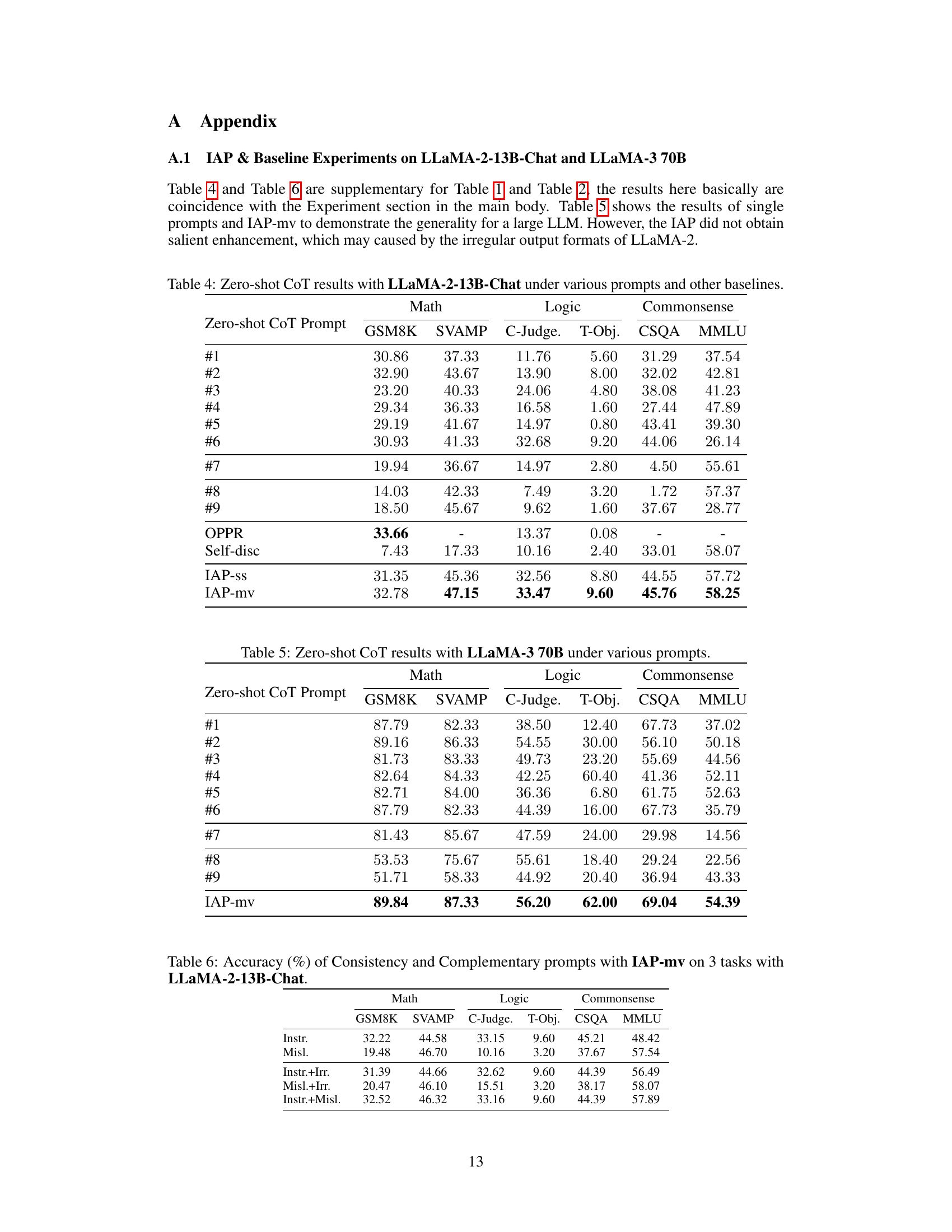
This table presents the results of zero-shot chain-of-thought (CoT) prompting experiments using different prompts on several large language models (LLMs) across various reasoning tasks. The tasks are categorized into math, logic, and commonsense reasoning. Results show the accuracy of each LLM with different prompts, including the performance of some baseline methods (AMV, OPPR, Self-dis). The table highlights that no single prompt performs best across all tasks and models.
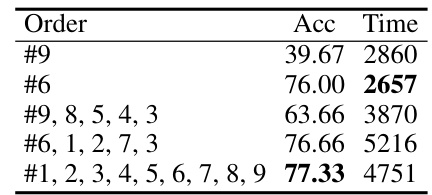
This table presents the accuracy and inference time taken by the LLaMA-3-8B-Instruct model on the SVAMP dataset using different orders and numbers of prompts in the Instance-Adaptive Prompting (IAP) strategy. It showcases how the order and quantity of prompts impact the model’s performance and computational cost. The results highlight the trade-off between efficiency and accuracy when employing the IAP-ss approach.

This table presents the results of zero-shot Chain-of-Thought (CoT) prompting experiments using different prompts on various tasks and LLMs. It compares the performance of different prompts, including those generated by optimization algorithms, and shows the accuracy achieved on math, logic, and commonsense reasoning tasks.

This table presents the results of zero-shot chain-of-thought (CoT) prompting experiments using different prompts on various tasks and two large language models (LLMs): LLaMA-3-8B-Instruct and Qwen-14B-Chat. It shows accuracy scores for math, logic, and commonsense reasoning tasks. Results for other LLMs are included in the appendix. The table also includes a comparison with other state-of-the-art methods for finding optimal prompts.
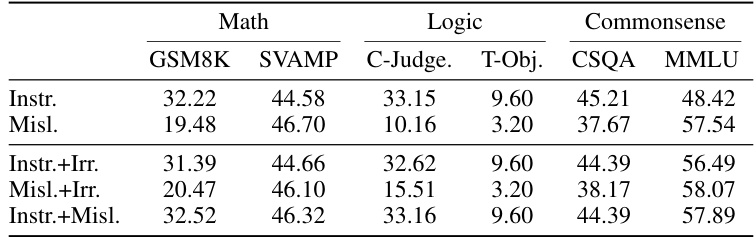
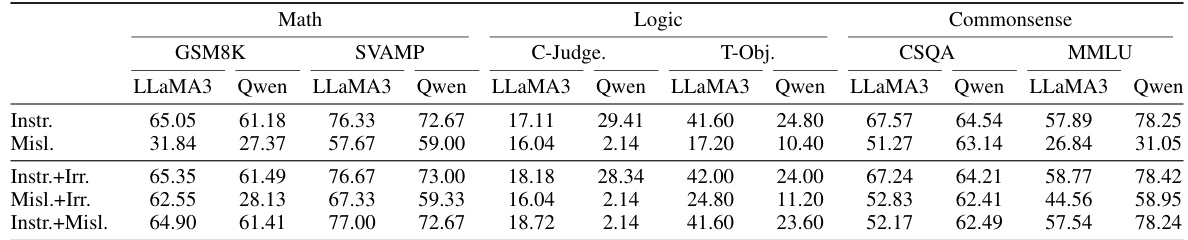
This table presents the accuracy results of the Instance-Adaptive Prompting (IAP-mv) method on three categories of reasoning tasks (Math, Logic, and Commonsense) using the LLaMA-2-13B-Chat language model. It compares the performance of different prompt combinations, categorized as ‘Instructive’, ‘Misleading’, and ‘Irrelevant’, and combinations thereof, to assess the effect of prompt consistency and complementarity on reasoning accuracy. The results showcase how combining different types of prompts affects the overall performance of the model on various reasoning challenges.

This table presents the results of zero-shot chain-of-thought (CoT) prompting experiments using various prompts on several language models (LLMs): LLaMA-3-8B-Instruct and Qwen-14B-Chat. It compares the performance across different prompts (’#1’ to ‘#9’) and baselines (AMV, OPPR, Self-discover, IAP-ss, IAP-mv) on a range of tasks categorized as math, logic, and commonsense reasoning. The results are shown as accuracy percentages for each task and LLM.

This table presents the accuracy achieved by the LLaMA-3-8B-Instruct model on the GSM8K dataset using different threshold values for the instance-adaptive prompting strategy (IAP-ss). The threshold determines whether a prompt is considered ‘good’ or ‘bad’ based on its saliency score. The table shows how accuracy changes with different thresholds, helping to find the optimal value for separating good and bad prompts.

This table presents the accuracy results obtained using different thresholds with the LLaMA-3-8B-Instruct model on the GSM8K dataset. It shows how the accuracy varies as the threshold changes, indicating the impact of the threshold on the model’s performance for this specific task and model.
Full paper#