↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Graph Neural Networks (GNNs) often struggle with limited labeled data and generalization across different tasks and datasets. Self-supervised learning and graph prompt learning have been explored, but they often require fine-tuning, limiting zero-shot capabilities. Large Language Models (LLMs) offer potential solutions due to their zero-shot capabilities, but integrating them effectively with GNNs is challenging.
The paper introduces TEA-GLM, a novel framework that addresses these challenges. TEA-GLM pre-trains a GNN, aligning its representations with LLM token embeddings. A linear projector then transforms GNN representations into graph token embeddings used by the LLM predictor without fine-tuning the LLM itself. Experiments show TEA-GLM achieves superior zero-shot performance across diverse datasets and tasks, outperforming existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents TEA-GLM, a novel framework that significantly improves zero-shot learning in graph machine learning. It tackles the major challenge of limited labeled data by aligning graph neural network (GNN) representations with large language model (LLM) token embeddings. This approach opens up exciting avenues for applying LLMs to various graph tasks without extensive dataset-specific training, thereby accelerating the development and application of graph machine learning models.
Visual Insights#
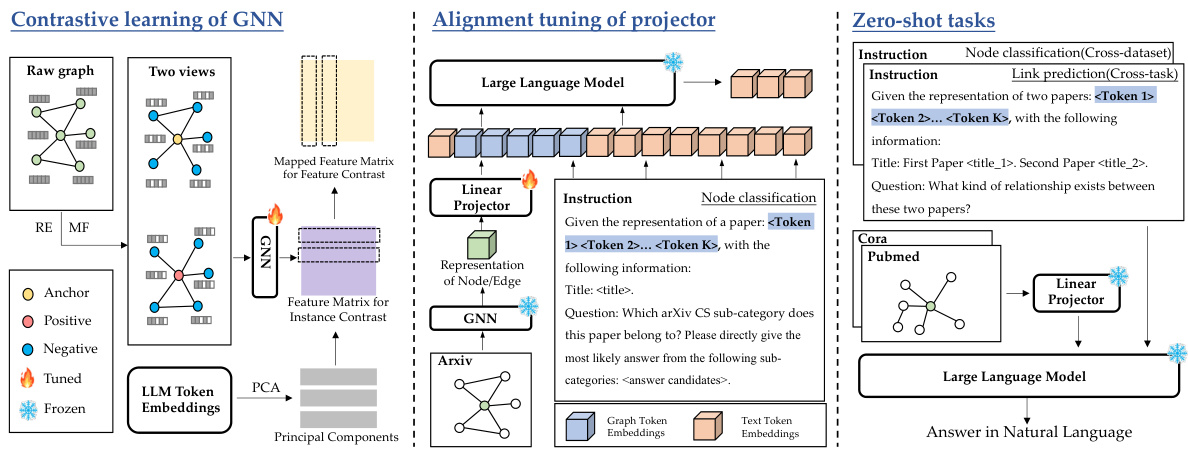
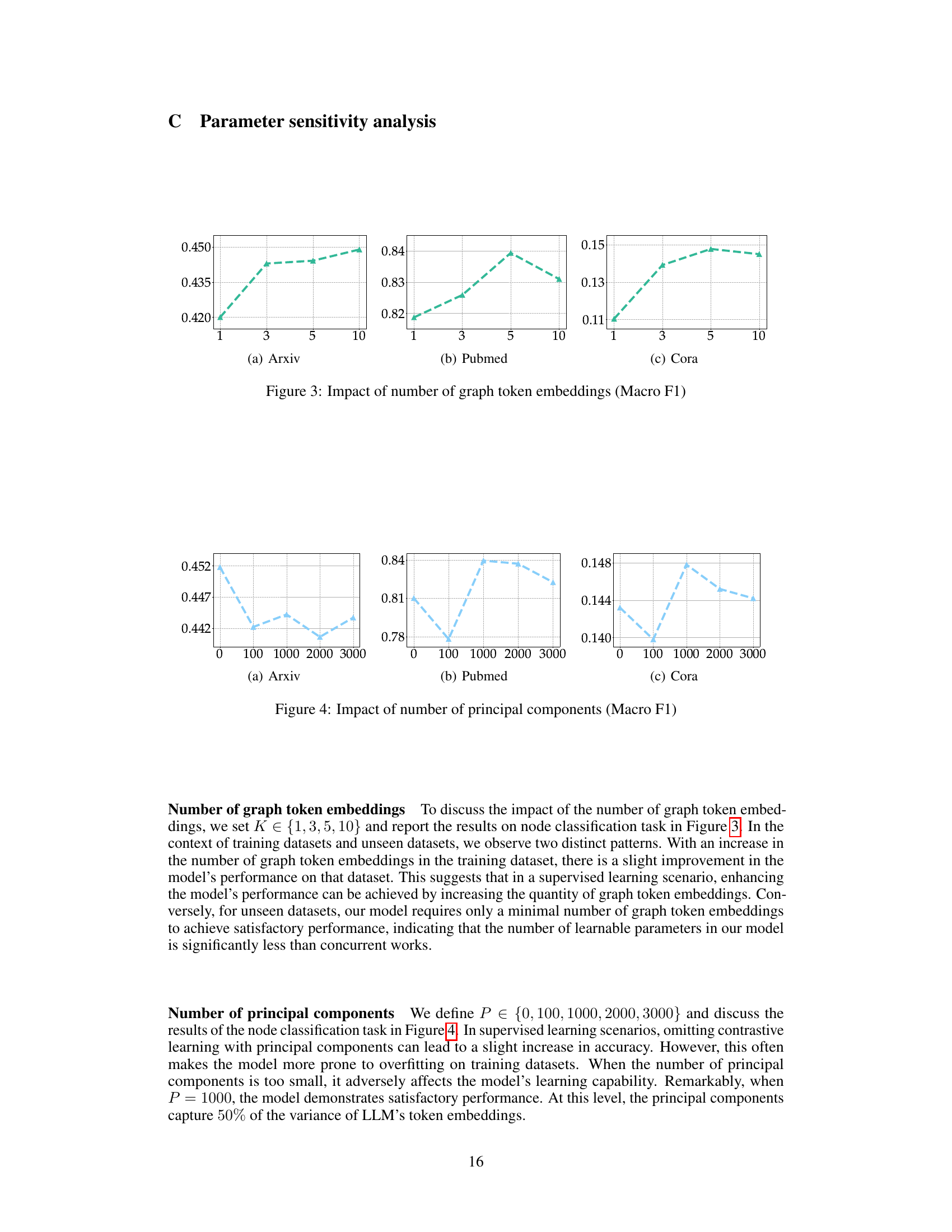
The figure illustrates the TEA-GLM framework, which consists of three main stages: contrastive learning of GNN, alignment tuning of projector, and zero-shot tasks. The contrastive learning stage uses two views of a raw graph (generated by RE and MF methods) to train a GNN, enhancing self-supervised learning using LLM token embeddings. A linear projector then aligns the GNN’s representations with the LLM’s token embeddings, creating graph token embeddings. Finally, these embeddings are used in a unified instruction for various zero-shot tasks (node classification and link prediction) on different datasets (Arxiv, Cora, Pubmed).
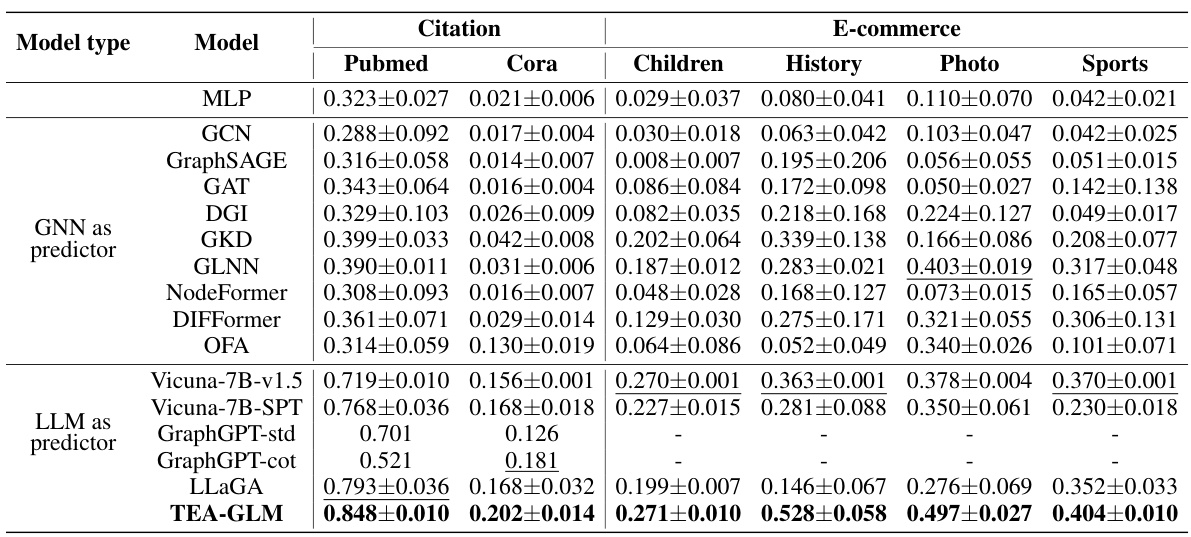
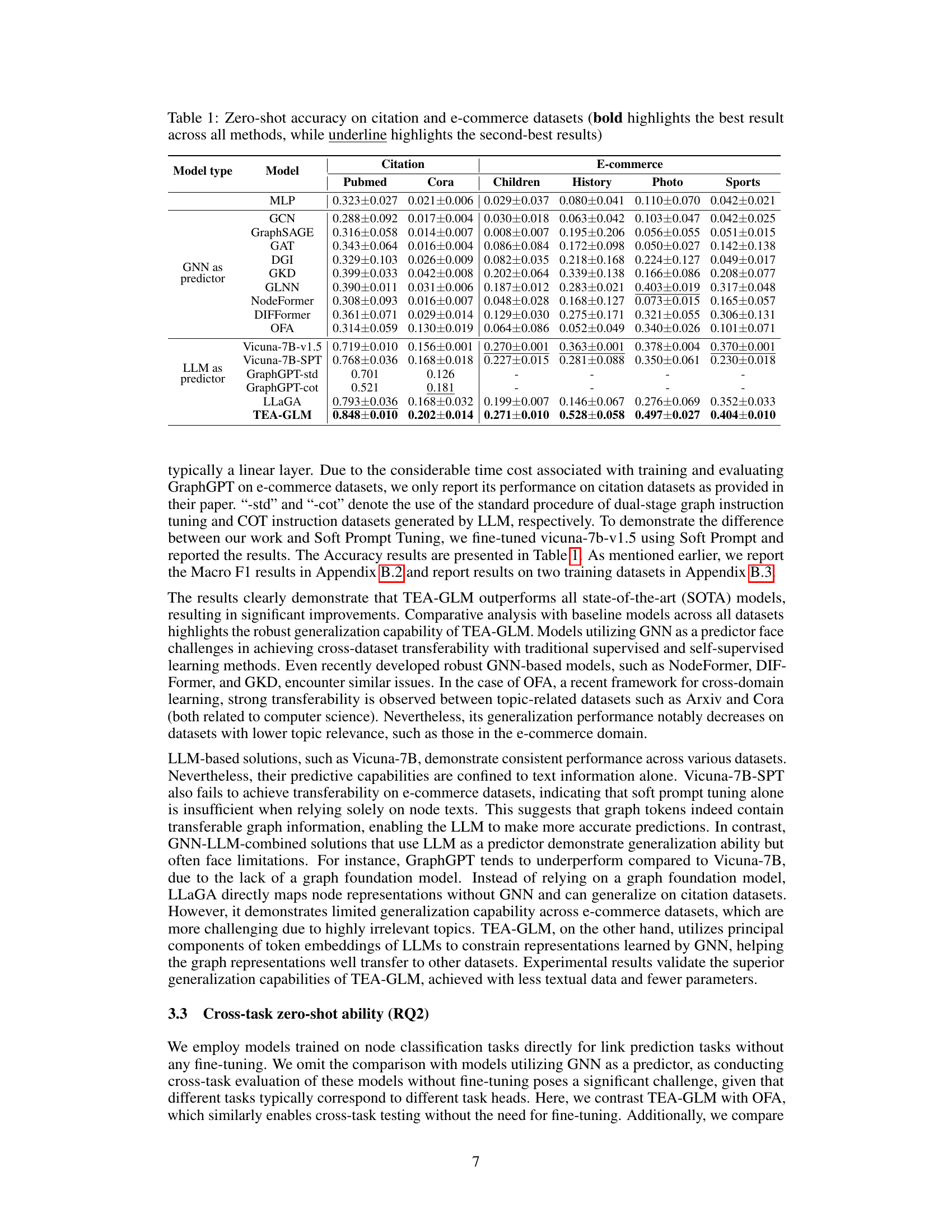
This table presents the zero-shot accuracy results on citation and e-commerce datasets for various models. It compares the performance of TEA-GLM against several baseline methods, including traditional GNNs, self-supervised methods, and LLMs. The results are shown for different datasets (Arxiv, Pubmed, Cora, Children, History, Computer, Photo, Sports) and highlight TEA-GLM’s superior zero-shot learning capabilities across diverse datasets and tasks.
In-depth insights#
TEA-GLM Framework#
The TEA-GLM framework innovatively leverages Large Language Models (LLMs) to achieve zero-shot learning in graph machine learning. It addresses the limitations of traditional GNNs, which struggle with generalization across datasets and tasks. TEA-GLM pre-trains a GNN, aligning its representations with LLM token embeddings through a contrastive learning process. This alignment is crucial for enabling the LLM to effectively interpret graph information. A linear projector maps GNN representations to a fixed number of graph token embeddings, which are seamlessly integrated into a unified instruction for various graph tasks. This approach promotes transferability and efficient learning. The unified instruction design and embedding strategy collectively enhance TEA-GLM’s ability to tackle diverse tasks across various datasets without further fine-tuning. The framework’s ability to achieve this demonstrates its strength in handling the challenges of zero-shot learning in graph machine learning.
Contrastive Learning#
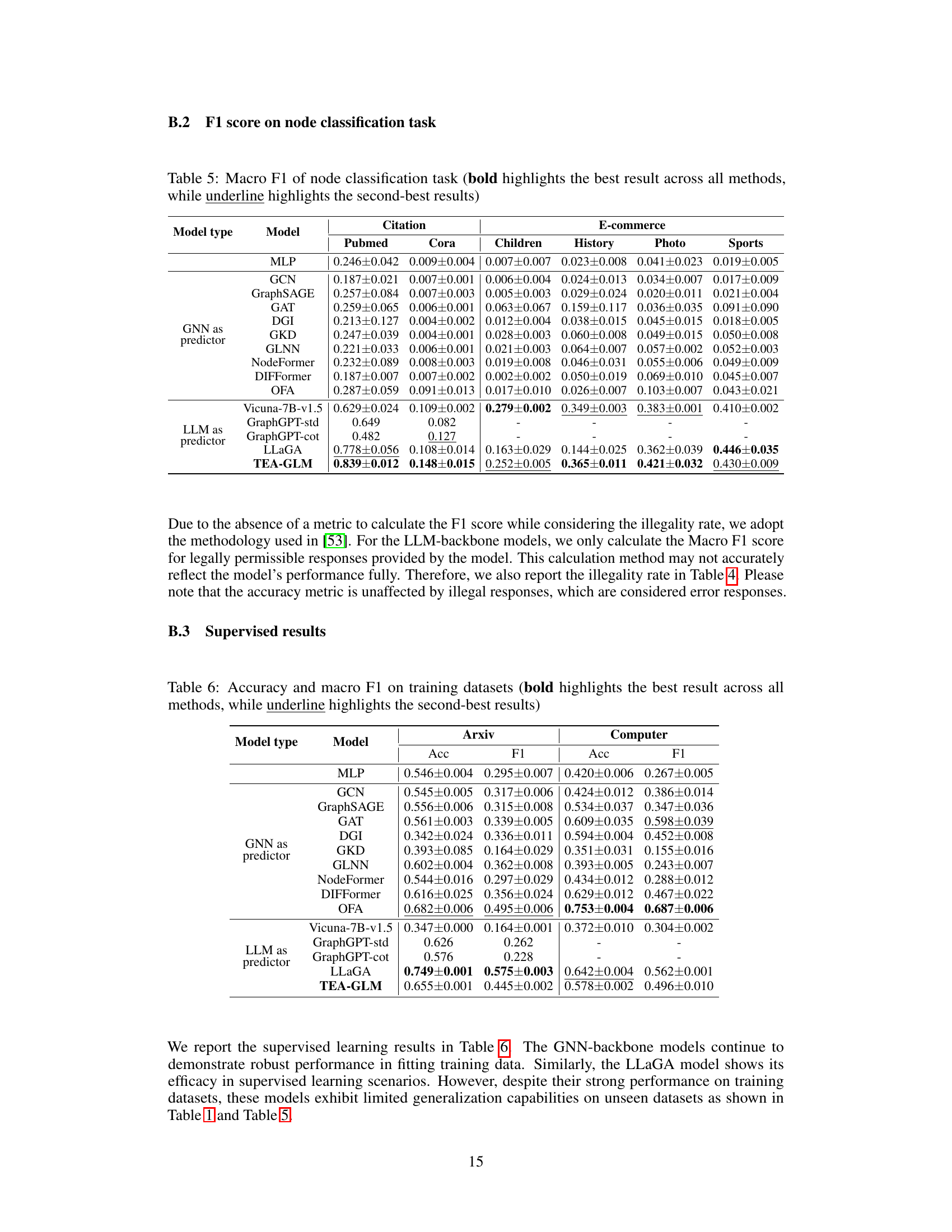
Contrastive learning, a self-supervised learning approach, is crucial in training effective graph neural networks (GNNs) especially when labeled data is scarce. It leverages the inherent structure of the data to learn robust representations by comparing similar and dissimilar instances. The paper details two contrastive learning strategies: instance-wise and feature-wise. Instance-wise contrastive learning focuses on distinguishing between different nodes within the same graph, using augmented views of the graph to create positive and negative pairs. In contrast, feature-wise contrastive learning enhances transferability and aligns GNN representations with the semantic space of Large Language Models (LLMs) by contrasting feature vectors in different views. This alignment is achieved by aligning the GNN’s representations with the principal components of LLM token embeddings, making the model more suitable for cross-dataset and cross-task zero-shot learning. The efficacy of this approach is demonstrated through experiments, showcasing state-of-the-art performance. The combination of both instance and feature-wise contrastive learning makes TEA-GLM a particularly strong model.
Zero-Shot Learning#
Zero-shot learning (ZSL) aims to enable models to recognize or classify objects or concepts they haven’t encountered during training. This is particularly valuable in scenarios with limited labeled data or where obtaining labels is expensive or time-consuming. The core challenge in ZSL is bridging the gap between seen and unseen classes. Approaches often involve leveraging auxiliary information such as semantic attributes, word embeddings, or generative models. One promising direction is aligning the representations learned by a model for seen classes with those of unseen classes using shared semantic spaces or knowledge graphs. This allows the model to generalize its knowledge to previously unseen data. However, a major limitation of ZSL is the inherent ambiguity in transferring knowledge from seen to unseen classes, often leading to performance degradation. Recent work has explored utilizing the zero-shot capabilities of large language models (LLMs) to improve ZSL, showcasing their effectiveness in cross-domain and cross-task generalization. The development of robust ZSL methods remains an active area of research, with a focus on improving generalization and handling domain shift effectively.
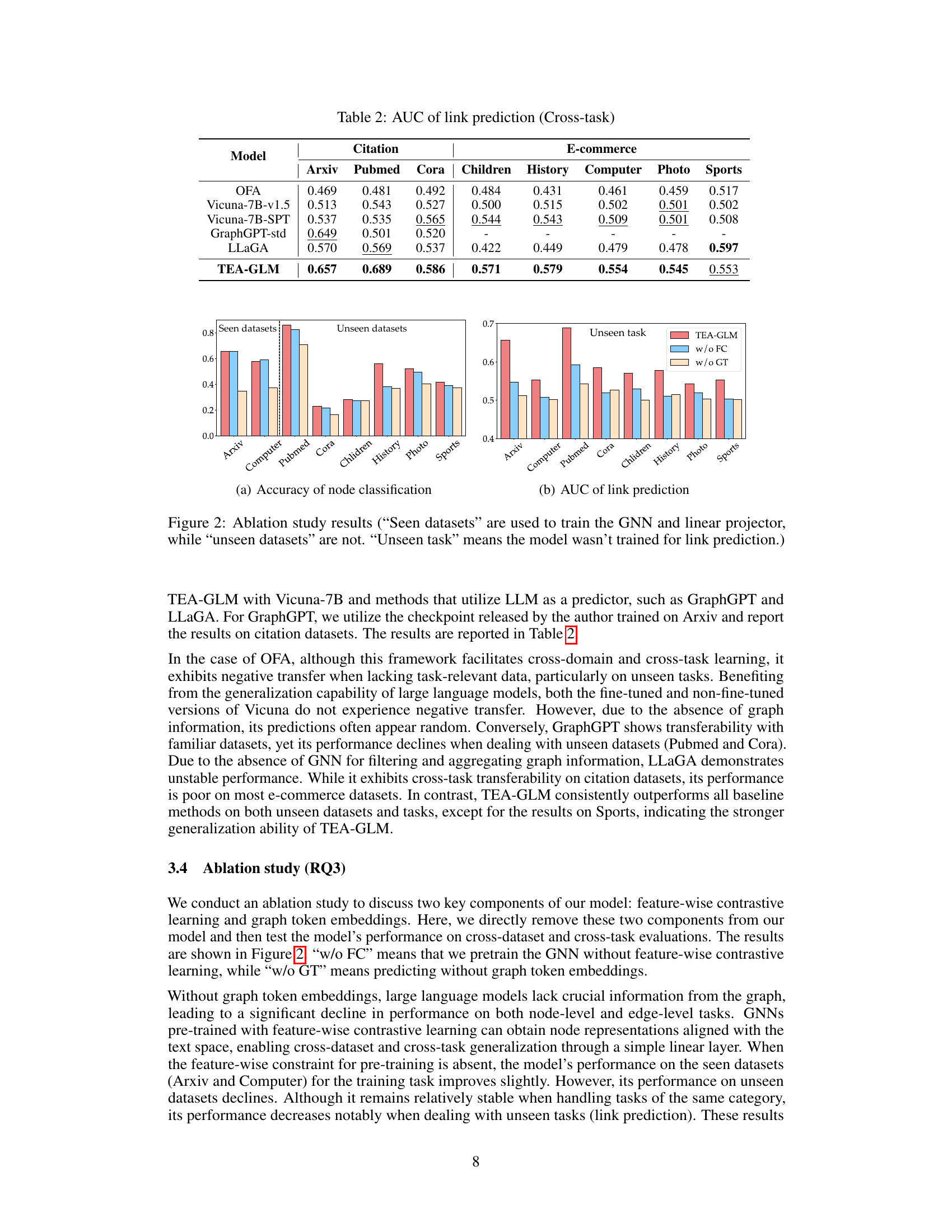
Cross-Dataset Results#
A dedicated ‘Cross-Dataset Results’ section would be crucial for evaluating the model’s generalization capabilities. It should showcase how well the model performs on unseen datasets after training on a source dataset, demonstrating its ability to transfer knowledge effectively. Key metrics would include accuracy, precision, recall, and F1-score for various tasks such as node classification or link prediction. The analysis should compare the model’s performance against established baselines, providing a quantitative measure of its advantage. A visual representation, such as a bar chart or table, could effectively highlight the differences in performance across various datasets. A detailed explanation of the datasets used, including their characteristics and sizes, would ensure reproducibility and allow readers to contextualize the results. Discussion of any challenges encountered during cross-dataset evaluation, such as dataset biases or differing data distributions, would add further depth and credibility. Finally, insights into the model’s ability to adapt to varied graph structures and tasks across different domains would strengthen the analysis and demonstrate its true zero-shot learning potential.
Future Work#
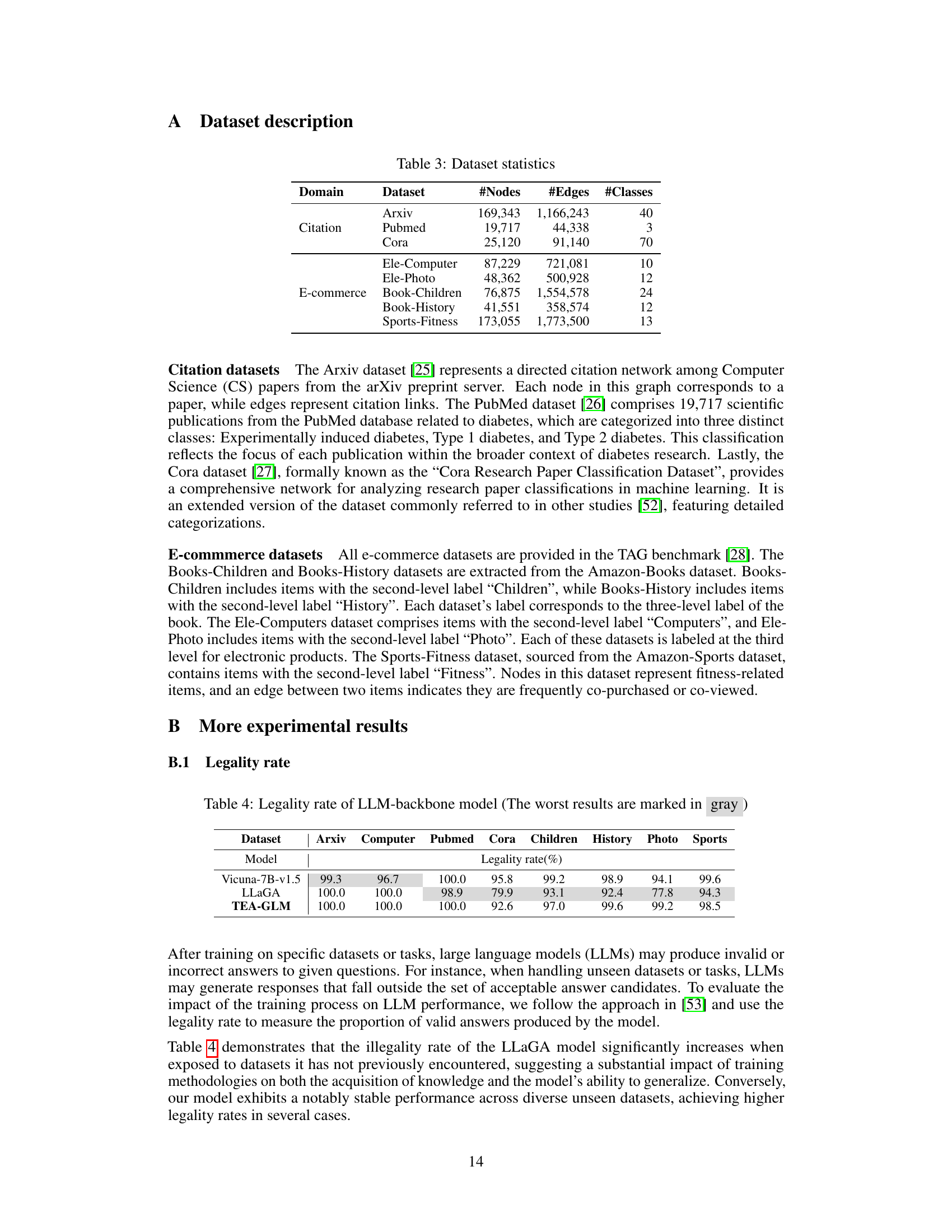
Future work could explore several promising avenues. Extending TEA-GLM to handle graph-level tasks is crucial, as the current framework primarily focuses on node and edge levels. Investigating different LLM architectures and their impact on performance, especially considering more parameter-efficient models, warrants attention. A detailed analysis of the sensitivity of the model to various hyperparameters is needed for optimization. Further research should examine the generalization capabilities of TEA-GLM across more diverse graph datasets and tasks, particularly focusing on those with unique structural properties. Finally, developing techniques to effectively incorporate additional information beyond node titles (such as abstracts or full text) could significantly enhance the model’s understanding and predictive accuracy. Addressing these areas would strengthen TEA-GLM and expand its applicability in various zero-shot graph learning scenarios.
More visual insights#
More on figures

The figure illustrates the TEA-GLM framework, showing its two main components: a Graph Neural Network (GNN) and a Large Language Model (LLM). The GNN processes the raw graph data to generate node or edge representations. These representations are then passed through a linear projector that maps them into graph token embeddings. Finally, these embeddings, along with a unified instruction, are fed into the LLM to perform zero-shot tasks such as node classification and link prediction. The figure also highlights the contrastive learning methods used to enhance the self-supervised learning of the GNN and the alignment tuning of the projector to enhance LLM’s graph comprehension. Different tasks (node classification, link prediction) using data from different datasets (Cora, Pubmed, Arxiv) are also illustrated.

This figure illustrates the framework of the proposed method TEA-GLM, which consists of two main components: a Graph Neural Network (GNN) and a Large Language Model (LLM). The GNN is used to derive node representations from the graph, while the LLM is used to perform zero-shot tasks. The framework involves two key stages: enhanced self-supervised learning of the GNN and training a linear projector to map graph representations into a fixed number of graph token embeddings. The figure shows the contrastive learning of the GNN, the alignment tuning of the projector, and the zero-shot tasks performed using the LLM.

The figure illustrates the TEA-GLM framework, showing its three main stages: contrastive learning of GNN, alignment tuning of the projector, and zero-shot tasks. The contrastive learning stage uses two views of the graph (RE and MF) and LLM token embeddings to generate enhanced node representations. These are then mapped to graph token embeddings using a linear projector, which is trained to align the GNN representations with the LLM’s embedding space. Finally, these graph token embeddings are used within unified instructions for zero-shot node classification and link prediction tasks across various datasets.
More on tables
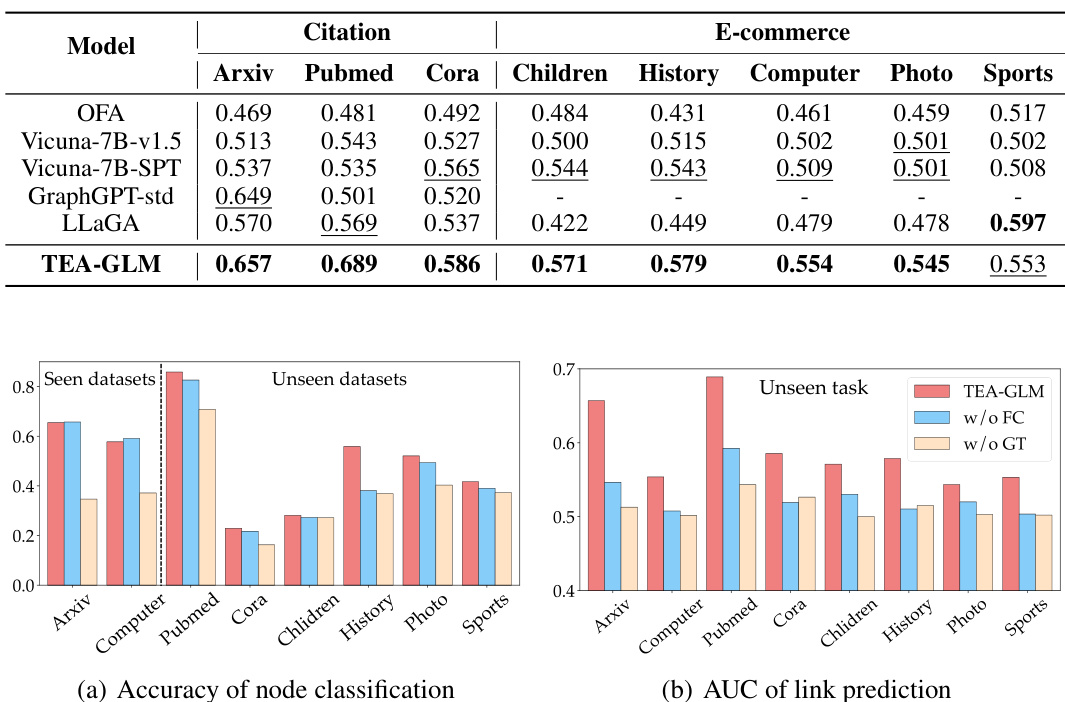
This table presents the zero-shot accuracy results of various models on citation and e-commerce datasets. The models are categorized by type (MLP, GNN, LLM, and TEA-GLM). For each dataset, the accuracy is shown, with the best result in bold and the second-best underlined. This illustrates the cross-dataset generalization capabilities of the different approaches, highlighting the superior performance of TEA-GLM.
This table presents the zero-shot accuracy results on eight datasets (three citation and five e-commerce datasets) using various methods. It compares the performance of TEA-GLM against several baselines, including MLP, GCN, GraphSAGE, GAT, DGI, GKD, GLNN, NodeFormer, DIFFormer, OFA, Vicuna-7B-v1.5, Vicuna-7B-SPT, GraphGPT, and LLaGA. The results show TEA-GLM’s superior performance in zero-shot settings across diverse datasets and tasks. Bold highlights the best result across all models for each dataset; underline highlights the second best.

This table presents the zero-shot accuracy results on eight datasets across three different domains: citation and e-commerce. It compares the performance of TEA-GLM against various baselines, including non-GNN methods, supervised GNN methods, self-supervised GNN methods, graph knowledge distillation methods, graph transformer networks, and LLMs. The results are shown for each dataset separately, with bold highlighting the best performance and underlined values indicating the second-best performance for each dataset. The table highlights TEA-GLM’s superiority across diverse datasets and tasks.
This table presents the zero-shot accuracy results on citation and e-commerce datasets for various models, including MLP, GCN, GraphSAGE, GAT, DGI, GKD, GLNN, NodeFormer, DIFFormer, OFA, Vicuna-7B-v1.5, Vicuna-7B-SPT, GraphGPT-std, GraphGPT-cot, LLaGA, and TEA-GLM. The best result for each dataset is shown in bold, while the second-best is underlined. It compares the performance of TEA-GLM against multiple baselines across different model types (GNNs, LLMs) and learning strategies (supervised, self-supervised, zero-shot). This allows for a comprehensive evaluation of TEA-GLM’s performance in zero-shot cross-dataset settings.

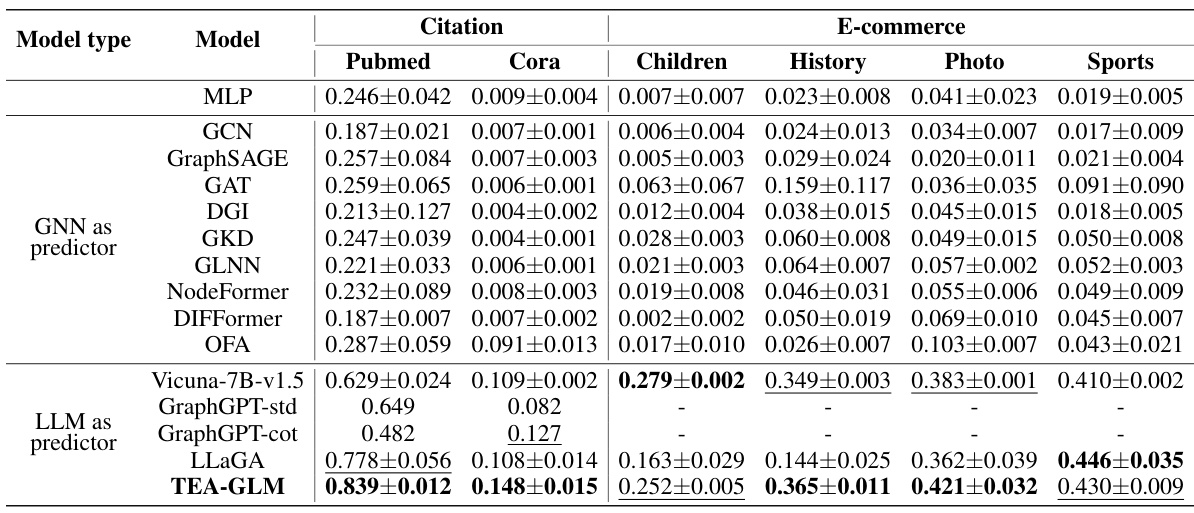
This table presents the zero-shot accuracy results of various models on citation and e-commerce datasets. The models are categorized into GNNs as predictors, LLMs as predictors, and a combined approach using both. The best result for each dataset is shown in bold, and the second-best is underlined. This allows for a direct comparison of different model types and their performance in zero-shot settings across diverse datasets. The datasets represent various citation networks (Arxiv, Pubmed, Cora) and e-commerce product co-purchasing/co-viewing networks.

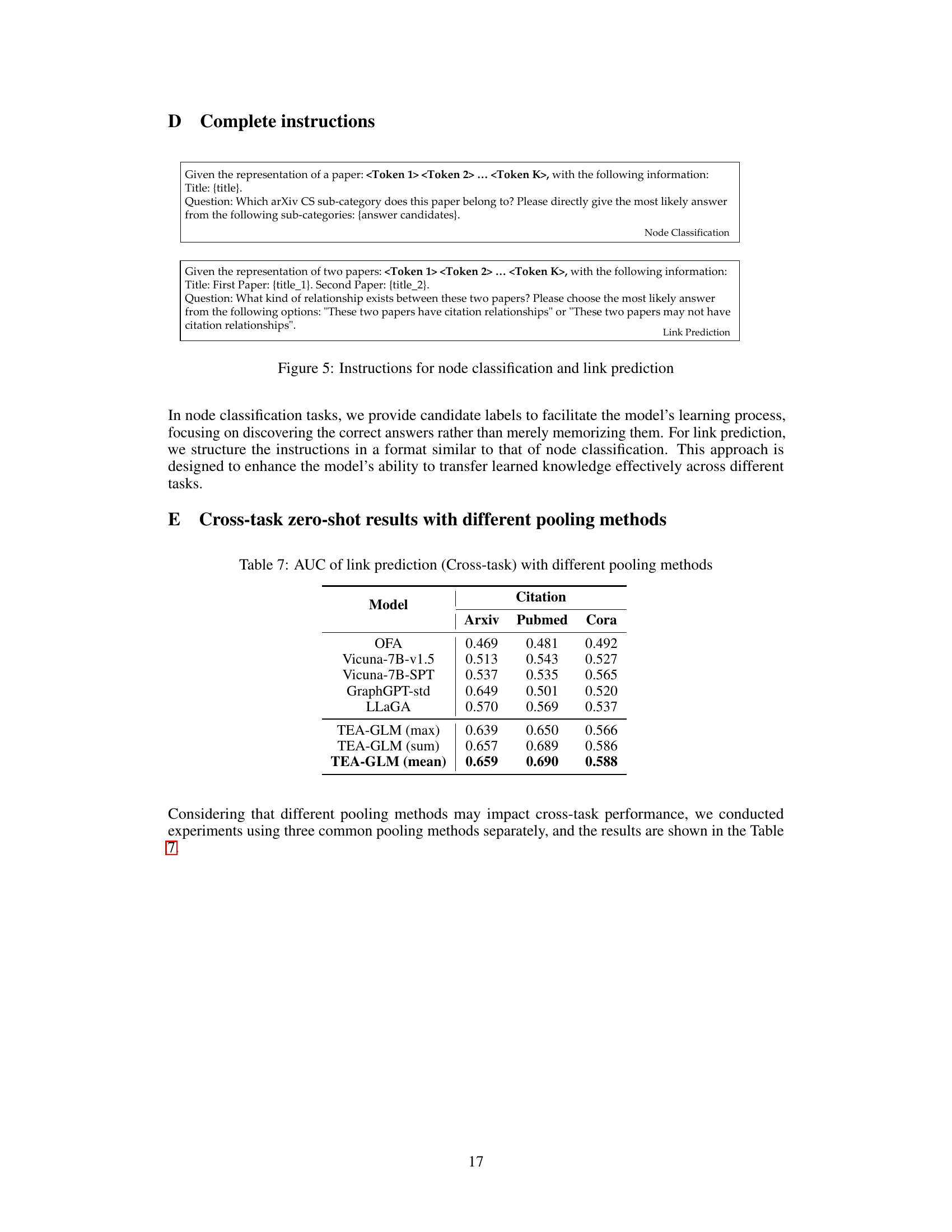
This table presents the Area Under the Curve (AUC) scores for link prediction task in a cross-task zero-shot learning setting. The results are shown for different models on various citation and e-commerce datasets. The models include OFA, Vicuna-7B-v1.5, Vicuna-7B-SPT, GraphGPT-std, LLaGA and TEA-GLM (using max, sum, and mean pooling methods). The table allows for a comparison of the performance of various models in a cross-task setting, highlighting the effectiveness of TEA-GLM in this challenging scenario.
Full paper#