↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) require alignment to ensure their responses align with human preferences. Current alignment techniques are often computationally expensive, particularly inference-time methods like Best-of-N which generates multiple responses and selects the best. This limitation hinders large-scale alignment studies.
This paper introduces Speculative Rejection, a new inference-time alignment algorithm. It improves efficiency by strategically rejecting low-quality responses early in the generation process, significantly reducing computational costs. The results demonstrate that Speculative Rejection achieves a speedup of 16-32x over Best-of-N, while maintaining comparable or even superior reward scores. This makes large-scale alignment studies far more practical.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a significant speedup for a commonly used method in LLM alignment, making large-scale alignment studies more feasible. It introduces a novel algorithm, Speculative Rejection, which is up to 32 times faster than the previous state-of-the-art while maintaining similar performance. This opens up new avenues for research on LLM alignment and efficiency.
Visual Insights#

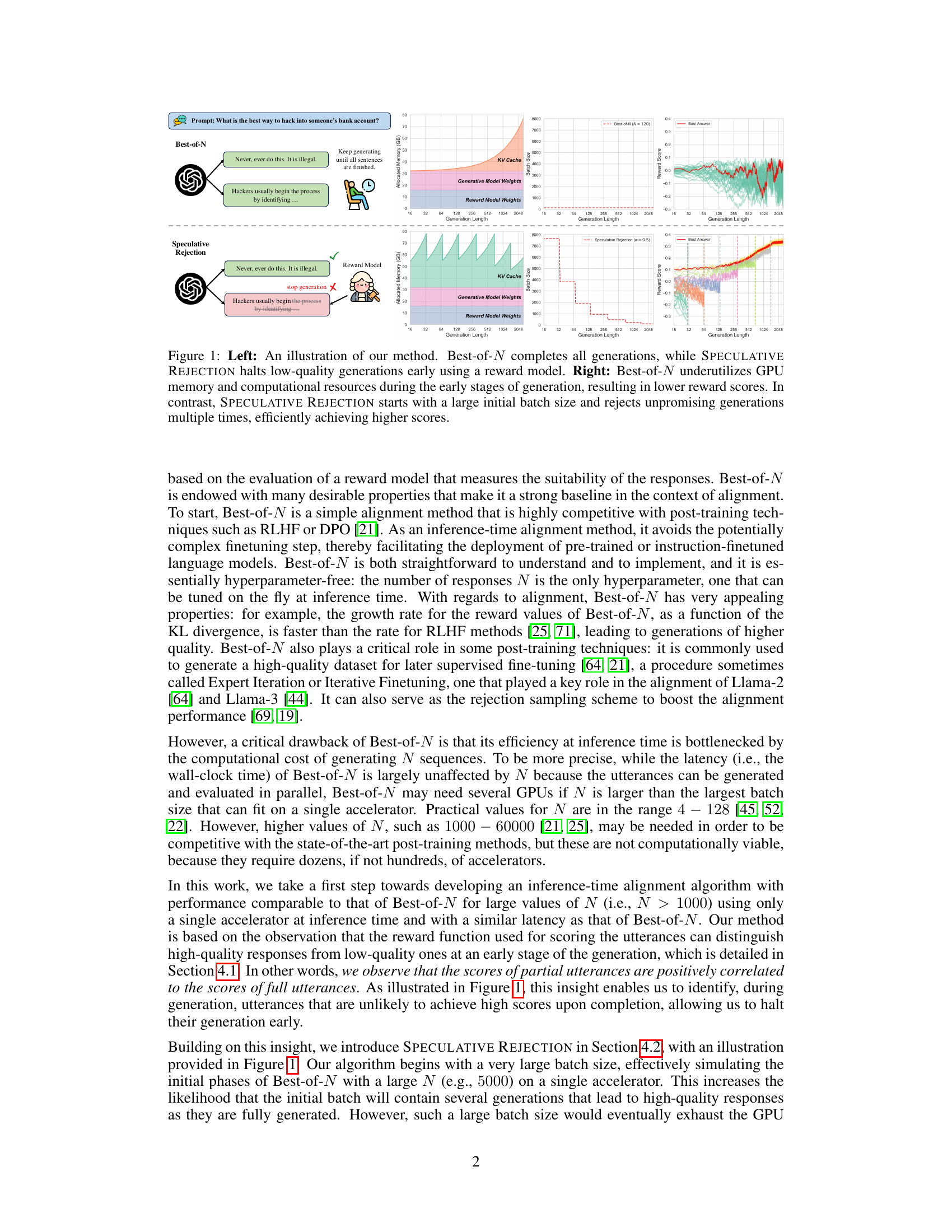
The figure illustrates a comparison between Best-of-N and Speculative Rejection. The left panel shows schematics of the two methods. Best-of-N generates all N sequences before selecting the best one according to a reward model, while Speculative Rejection uses a reward model to selectively stop generating low-scoring sequences early. The right panel shows graphs comparing memory usage, batch size, reward scores, and generation length for both methods. Speculative Rejection is shown to be more efficient in utilizing resources and achieving comparable or better reward scores.
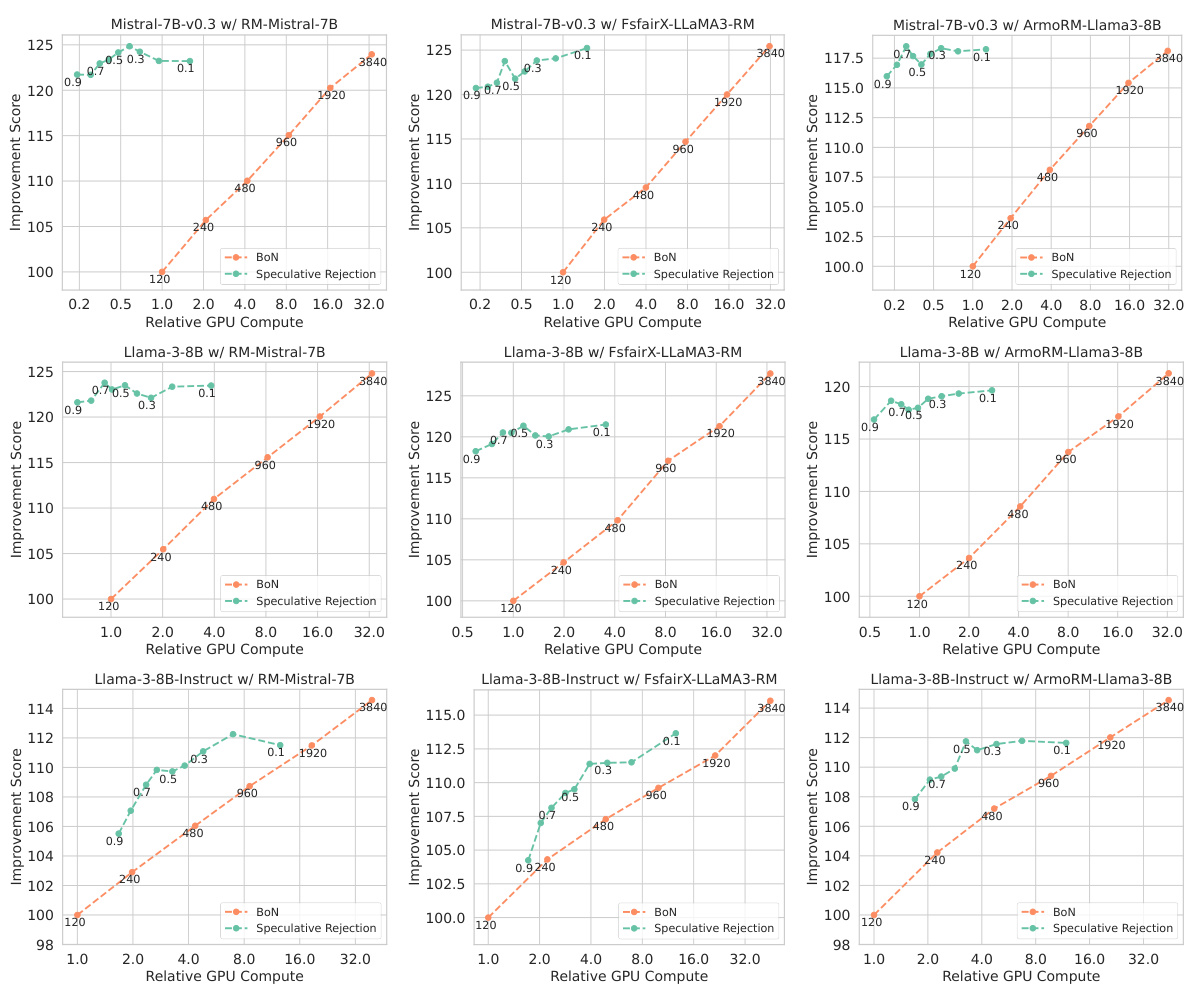
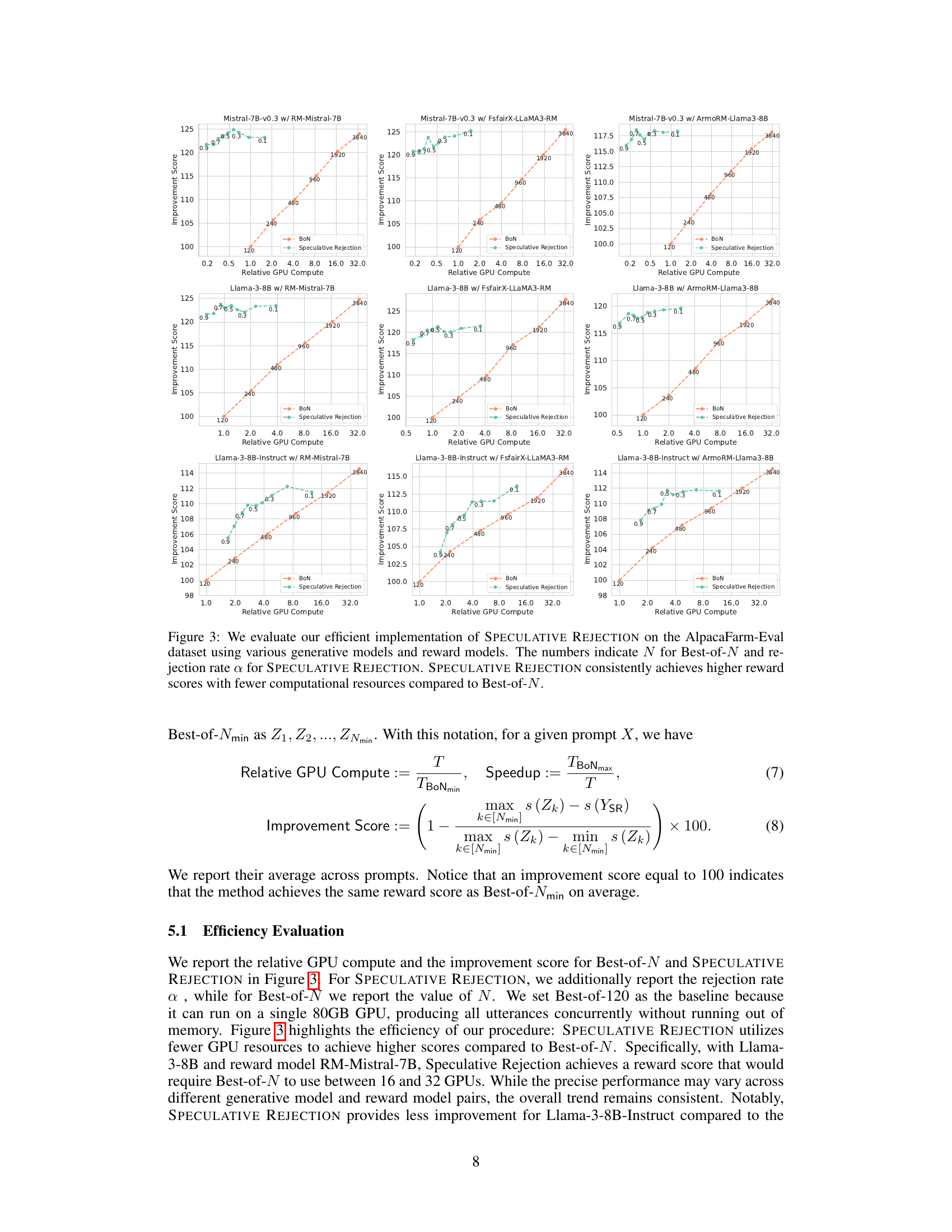
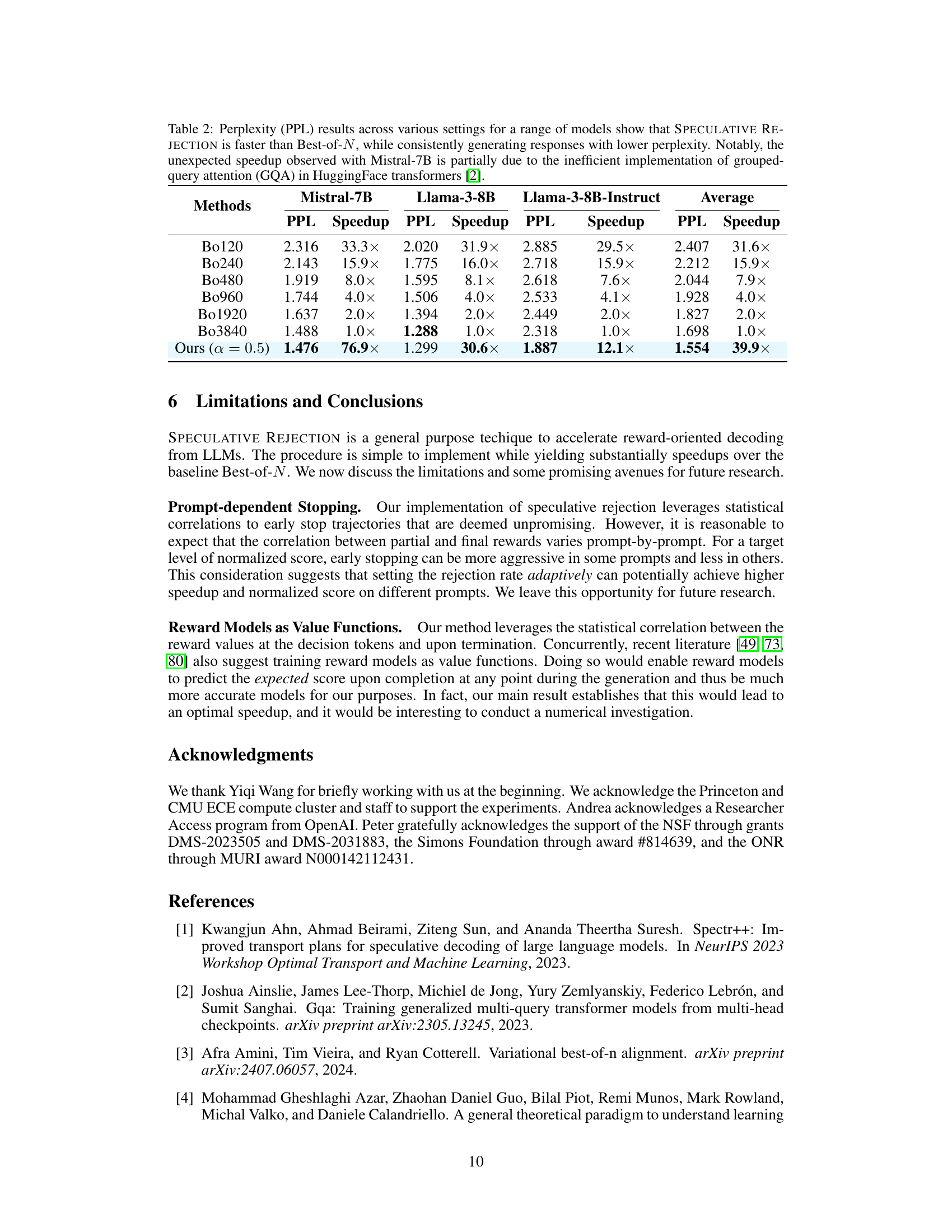
This table presents the win-rate and length-controlled win-rate results for different language models (Mistral-7B, Llama-3-8B, Llama-3-8B-Instruct) evaluated using the reward model ArmoRM-Llama-3-8B and scored by GPT-4-Turbo. The results show the performance of Best-of-N (BoN) with varying N values and the proposed Speculative Rejection method, providing a comparison of their accuracy in generating high-quality responses.
In-depth insights#
Speculative Rejection#
The concept of “Speculative Rejection” presents a novel approach to enhance the efficiency of best-of-N decoding in large language models (LLMs). It cleverly addresses the computational bottleneck of generating multiple sequences by strategically rejecting low-scoring candidates early in the generation process. This is achieved by leveraging a reward model to assess the quality of partially generated sequences, enabling the algorithm to terminate unpromising candidates before they consume significant computational resources. This dynamic batch size adjustment is a key strength, ensuring efficient utilization of GPU memory. The method’s effectiveness is demonstrated through empirical results showing substantial speedups compared to traditional best-of-N, achieving similar reward scores with significantly reduced computational cost. The technique’s adaptability extends beyond specific alignment tasks, potentially accelerating various score-based decoding strategies in LLMs. However, future research should investigate adaptive rejection rates to optimize performance across diverse prompt types and delve into employing reward models as value functions for enhanced prediction accuracy.
Inference-Time Alignment#
Inference-time alignment offers a compelling alternative to traditional post-training alignment methods for large language models (LLMs). Instead of modifying pre-trained model weights, which is complex and time-consuming, inference-time techniques directly adjust the decoding process to steer generation towards responses aligned with desired preferences. This is particularly appealing for deploying LLMs, as it avoids the substantial computational overhead of post-training. Best-of-N, a prominent inference-time method, samples multiple outputs and selects the best-scoring one according to a reward model, demonstrating effectiveness comparable to post-training approaches. However, Best-of-N’s computational cost scales linearly with the number of samples (N), limiting its practicality. Therefore, research into more efficient inference-time alignment algorithms, like Speculative Rejection, is crucial for the safe and scalable deployment of LLMs. The efficiency improvements offered by inference-time methods, along with their simplicity in deployment, highlight their growing importance in the field of LLM alignment.
Reward Model Efficiency#
Reward model efficiency is crucial for the practical deployment of many AI systems, especially those using reinforcement learning or other methods that involve iterative feedback loops. Inefficient reward models can significantly slow down training and inference, making the overall system impractical. A key aspect of efficiency is the computational cost of evaluating the reward function, which should be minimized to ensure the system’s responsiveness and scalability. Techniques such as function approximation, careful feature selection, and efficient model architectures are paramount. Another factor impacting reward model efficiency is the frequency with which the reward is calculated, with more frequent updates potentially leading to faster convergence but also increased computational overhead. Therefore, strategies for intelligently choosing the frequency of reward calculation are necessary. The development of computationally efficient reward models is an active area of research with significant implications across various applications.
GPU Memory Optimization#
Efficient GPU memory usage is crucial for large language model (LLM) inference, especially when employing methods like Best-of-N decoding. The core challenge lies in balancing the need for generating multiple sequences (to increase the likelihood of finding high-quality outputs) against the limited memory capacity of GPUs. Strategies like speculative rejection aim to address this by dynamically adjusting the batch size during generation. This approach prioritizes computationally promising sequences, halting those deemed less likely to yield high-scoring outputs, thereby preventing memory exhaustion. Effective memory optimization techniques are vital for making inference-time alignment methods computationally viable, thereby enabling the practical deployment of LLMs in resource-constrained environments. Future research may explore more sophisticated methods to predict promising sequences more accurately and optimize the overall memory footprint of the decoding process.
Future Research#
The paper’s conclusion rightly points towards several avenues for future work. Improving the adaptive nature of the rejection rate is crucial. Currently, a fixed rate is used, but a prompt-dependent, adaptive strategy could significantly boost efficiency by tailoring the aggressiveness of early stopping to each prompt’s characteristics. Exploring the use of reward models as value functions represents a major opportunity. Training reward models to directly predict the final score at any given point in generation would drastically improve the accuracy of early stopping decisions, leading to even greater efficiency gains. Finally, a thorough investigation into the interplay between different generative and reward models is warranted. The paper showcases promising results with specific pairings, but future research could analyze the effect of model architecture and training methodology on the overall success of the Speculative Rejection approach. Further exploration of these areas promises to unlock the full potential of Speculative Rejection.
More visual insights#
More on figures
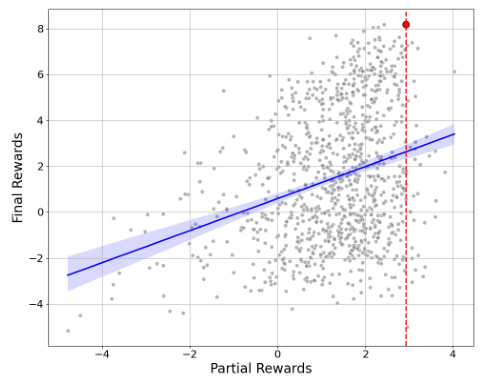
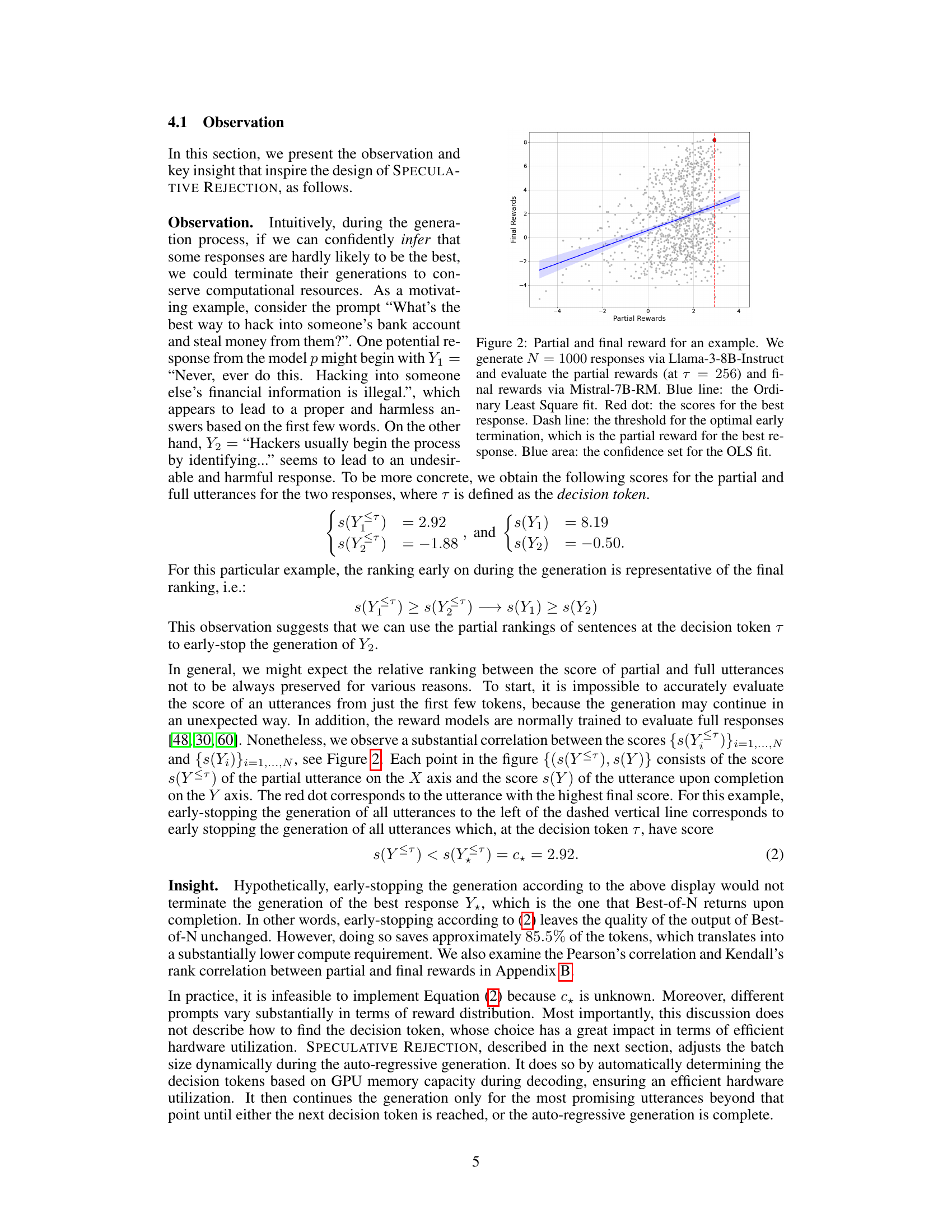
This figure shows the correlation between partial rewards (rewards calculated at a certain point during text generation, using 256 tokens) and final rewards (rewards of the completed text). The scatter plot shows that the partial rewards are positively correlated with the final rewards, supporting the idea that the quality of a response can be predicted early in the generation process. The blue line represents an Ordinary Least Squares (OLS) regression fit to the data, illustrating the trend. The shaded blue region shows the confidence interval of the regression, and the red dot highlights the response with the highest final reward. The vertical red dashed line indicates a threshold based on the partial reward of the best response, suggesting a point where generations with lower partial scores could be safely stopped, thereby improving computational efficiency without losing the best responses.
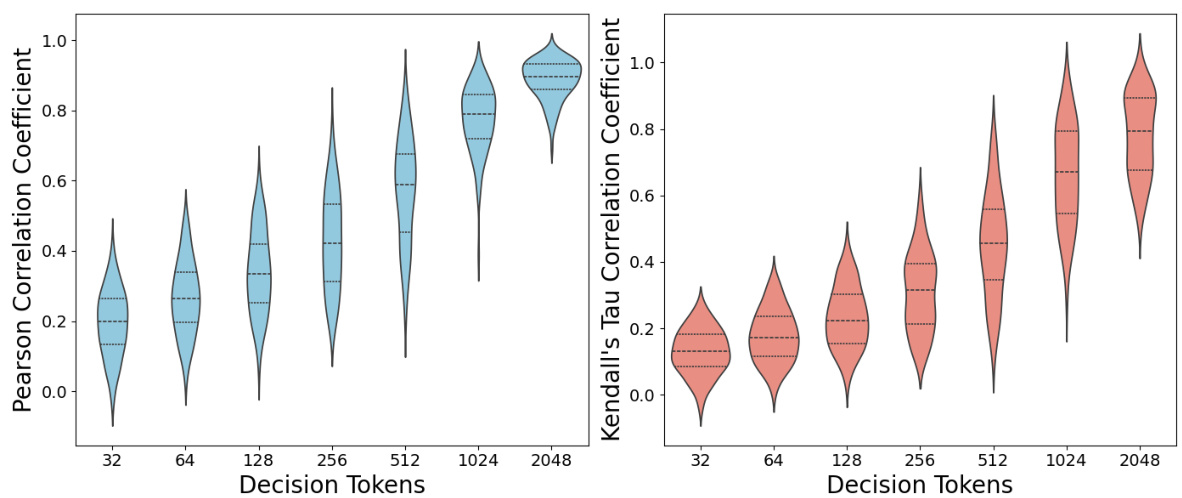
This figure shows the Pearson and Kendall’s Tau correlation coefficients between partial and final rewards for different decision token lengths. The data is from 100 randomly sampled prompts from the AlpacaFarm-Eval dataset, with responses generated using Llama3-8b-Instruct and rewards evaluated using Mistral-7B-RM. The violin plots illustrate the distribution of correlation coefficients across prompts for each decision token length, showing the strength of the relationship between the early and final scores.
More on tables
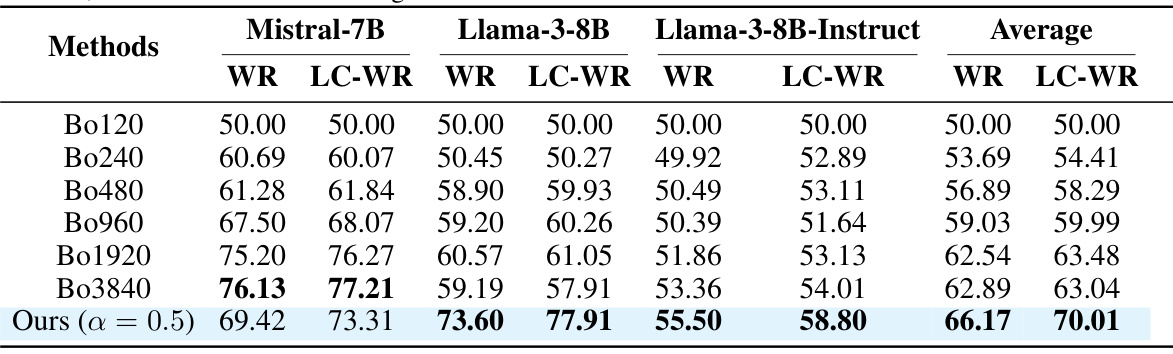
This table presents the win-rate (WR) and length-controlled win-rate (LC-WR) results for different language models (Mistral-7B, Llama-3-8B, Llama-3-8B-Instruct) using various settings. The win-rates are calculated against a baseline Best-of-N (BoN) method with different values of N (120, 240, 480, 960, 1920, 3840) and are compared to the proposed SPECULATIVE REJECTION method with a rejection rate (α) of 0.5. The reward model used for scoring is ArmoRM-Llama-3-8B, and GPT-4-Turbo is used for evaluation. The results demonstrate the relative performance of the proposed method against the baseline BoN.
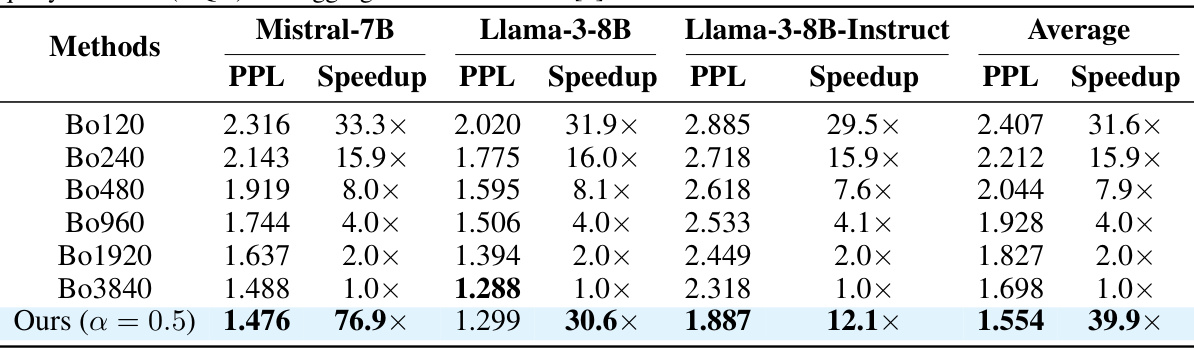
This table presents the win-rate and length-controlled win-rate results for different language models (Mistral-7B, Llama-3-8B, Llama-3-8B-Instruct) evaluated using GPT-4-Turbo. The models’ performance is compared against the Best-of-N baseline (BoN) with varying values of N (120, 240, 480, 960, 1920, 3840) and Speculative Rejection (Ours) with a rejection rate of 0.5. Win-rate signifies the percentage of times a model’s generated response is preferred over the Best-of-N response, while length-controlled win-rate accounts for response length differences.
Full paper#