↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current zero-shot monocular depth estimation (MDE) methods struggle to balance global geometric accuracy and fine-grained detail. While diffusion-based methods excel at details, they lack robust geometric priors. This limitation hinders performance in complex scenes, which are common in real-world applications.
To address this, BetterDepth uses a conditional diffusion model as a refiner. It takes predictions from a pre-trained MDE model as input and iteratively refines the details. Global pre-alignment and local patch masking are employed during training, ensuring the refiner remains faithful to the initial depth layout while learning fine details. The results demonstrate that BetterDepth achieves state-of-the-art performance on standard benchmarks, significantly improving existing models in a plug-and-play manner, showcasing its practicality and efficiency.
Key Takeaways#
Why does it matter?#
This paper is important because it presents BetterDepth, a novel plug-and-play diffusion model that significantly improves the performance of existing monocular depth estimation (MDE) models. This addresses a key challenge in computer vision by enhancing detail in depth maps, which is crucial for many applications like autonomous driving and 3D scene reconstruction. It opens new avenues for research in combining feed-forward and diffusion-based methods for improved depth estimation accuracy and efficiency. The plug-and-play nature of BetterDepth makes it easily adaptable to various MDE models, expanding its practical impact.
Visual Insights#
This figure compares the performance of different monocular depth estimation methods. It shows that feed-forward methods (like Depth Anything) excel at capturing overall 3D shape, but lack detail. Diffusion-based methods (like Marigold) produce detailed results but struggle with accurate global shape. BetterDepth, the authors’ proposed method, aims to combine the strengths of both approaches, achieving both accurate global shape and fine details.

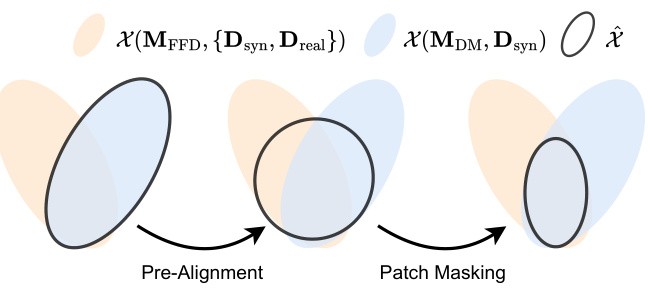
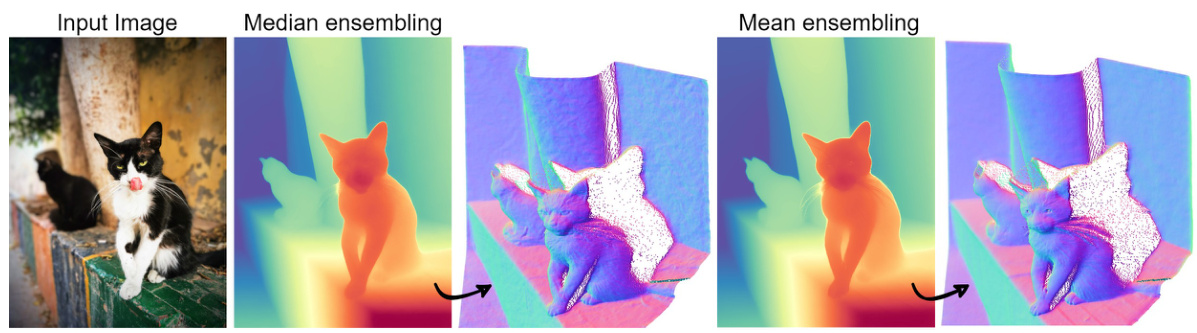
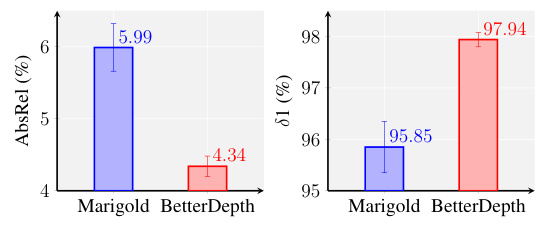
This table compares the performance of feed-forward and diffusion-based monocular depth estimation (MDE) models. It highlights the trade-offs between detail extraction and zero-shot generalizability. Feed-forward models (MFFD) trained on both synthetic (Dsyn) and real (Dreal) data achieve robust zero-shot performance but lack fine details. Diffusion-based models (MDM) trained on synthetic data (Dsyn) excel at extracting fine details but struggle with zero-shot generalization. The ideal model (Mideal) would combine the strengths of both, achieving both high detail and robust zero-shot performance with diverse data (Dideal). The table uses X(M,D) to represent the output distribution as a function of the model (M) and training data (D).
In-depth insights#
Diffusion Refinement#
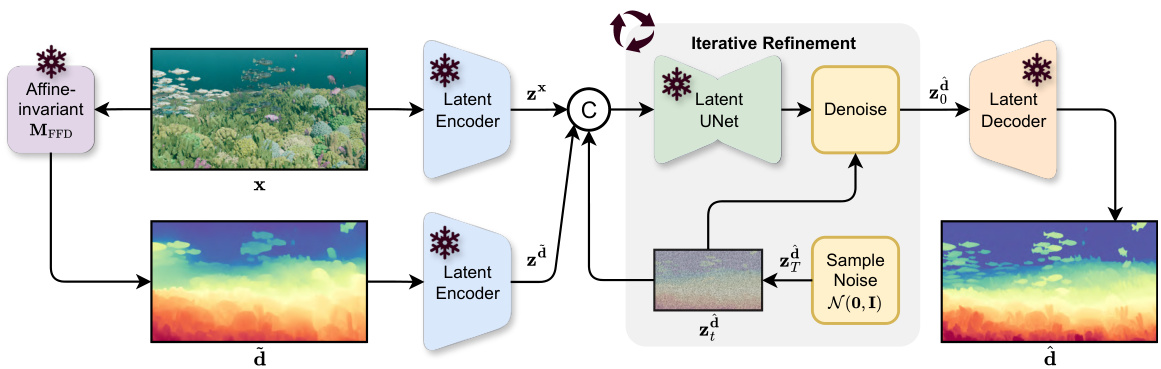
Diffusion refinement, in the context of zero-shot monocular depth estimation, is a crucial technique for enhancing the quality of initial depth predictions. It leverages the power of diffusion models to iteratively refine coarse depth maps, adding fine-grained details that are often missing in traditional feed-forward methods. The process starts with a pre-trained depth estimation model providing a global depth layout. Then, a conditional diffusion model takes this as input and refines the depth map pixel-by-pixel. Key challenges include balancing the fidelity to the initial prediction (avoiding hallucinations) while simultaneously capturing fine details. This necessitates careful training strategies, potentially using techniques like global pre-alignment to establish a robust correspondence between initial and refined depths and local patch masking to selectively refine details while preserving the fidelity of the global structure. The ultimate aim is to improve both visual quality and quantitative metrics related to accuracy and completeness of the depth map.
Zero-Shot Transfer#
Zero-shot transfer in the context of monocular depth estimation signifies a model’s ability to generalize to unseen data without any fine-tuning or retraining. This is a highly desirable characteristic, as acquiring and annotating large-scale real-world datasets for depth estimation is expensive and time-consuming. Success in zero-shot transfer hinges on the model learning robust and generalizable representations of depth cues from the training data. This might involve utilizing synthetic data for training, carefully designed loss functions to handle scale and shift ambiguities in depth measurements, and training on diverse datasets to improve robustness. However, a key challenge lies in balancing the trade-off between generalization capability and the quality of the depth estimates. While zero-shot methods may achieve impressive results on previously unseen data, they often lack the fine-grained details extracted by models trained with high-quality real-world labels. Recent techniques using diffusion models are making progress, but challenges remain in effectively leveraging the power of diffusion models while ensuring the zero-shot transfer capability. Furthermore, research continues to explore innovative strategies like data augmentation and advanced loss functions to improve zero-shot transfer performance in monocular depth estimation.
Synthetic Data Use#
The utilization of synthetic data in the paper is a crucial methodological choice impacting the reliability and generalizability of the results. The authors justify the use of synthetic data due to the difficulty and cost of acquiring large-scale, high-quality real-world depth labels. This is a common limitation in depth estimation research, and the decision to utilize synthetic data is a pragmatic one. However, it is important to acknowledge the potential limitations of this approach. Domain adaptation techniques may be necessary to mitigate discrepancies between the simulated environment and real-world scenarios. The paper should thoroughly address this potential limitation, either by demonstrating the robustness of the model to real-world data or by employing explicit techniques to bridge the simulation-reality gap. A discussion of the synthetic data generation process, including the level of realism and diversity of the simulated scenes, is also crucial for evaluating the reliability of the findings.
Plug-and-Play Use#
The concept of “Plug-and-Play Use” in the context of a research paper, likely concerning a novel model or algorithm, signifies its ease of integration and application. It suggests the method is designed for seamless incorporation into existing workflows without extensive retraining or modification. This characteristic is highly desirable, offering several advantages: reduced development time and effort, wider accessibility due to lower technical barriers for users, and potential for greater impact by facilitating broader adoption and collaboration. A successful plug-and-play system requires careful design, considering compatibility issues and potential performance trade-offs. The paper likely details the methodology used to achieve plug-and-play functionality and evaluates its efficacy in diverse settings. Robustness and reliability of the plug-and-play implementation would be key performance indicators, as would the degree of performance improvement when integrated into various pre-existing systems.
Future Enhancements#
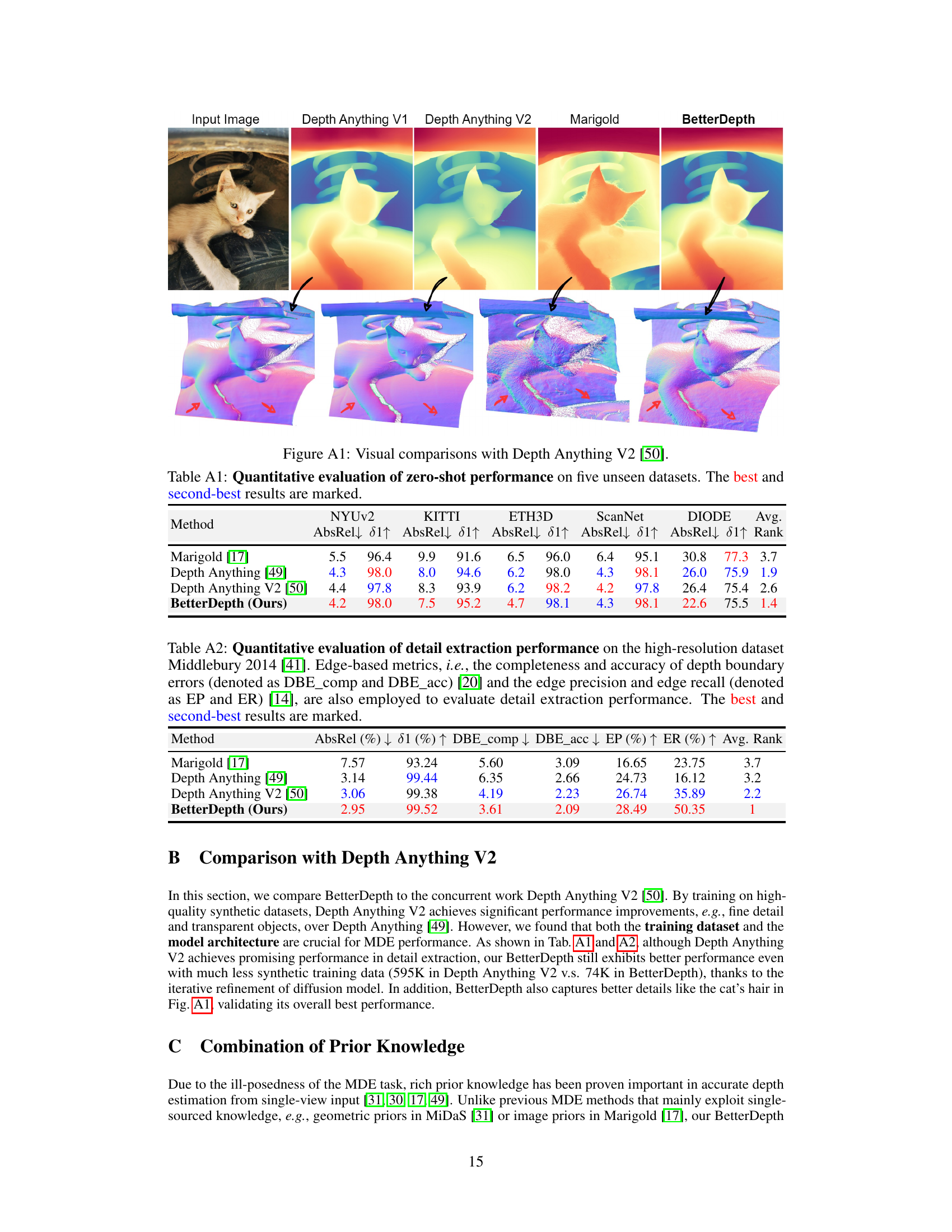
Future enhancements for BetterDepth could involve exploring more sophisticated diffusion models, potentially incorporating advancements in score-based generative modeling or other generative architectures beyond diffusion. Improving the efficiency of the training process is crucial, possibly through exploring alternative loss functions or more efficient sampling techniques. Addressing the limitations of synthetic data by incorporating techniques such as domain adaptation or self-supervised learning with real-world data would significantly improve the model’s generalization capabilities. Incorporating multi-modal information, such as color, texture, or even semantic segmentation, into the model to refine the depth estimation could also enhance its performance. Finally, further research could focus on developing more robust and efficient methods for inference, possibly through model compression or the exploration of quantization techniques. These enhancements would create a more powerful and practical zero-shot monocular depth estimation system.
More visual insights#
More on figures
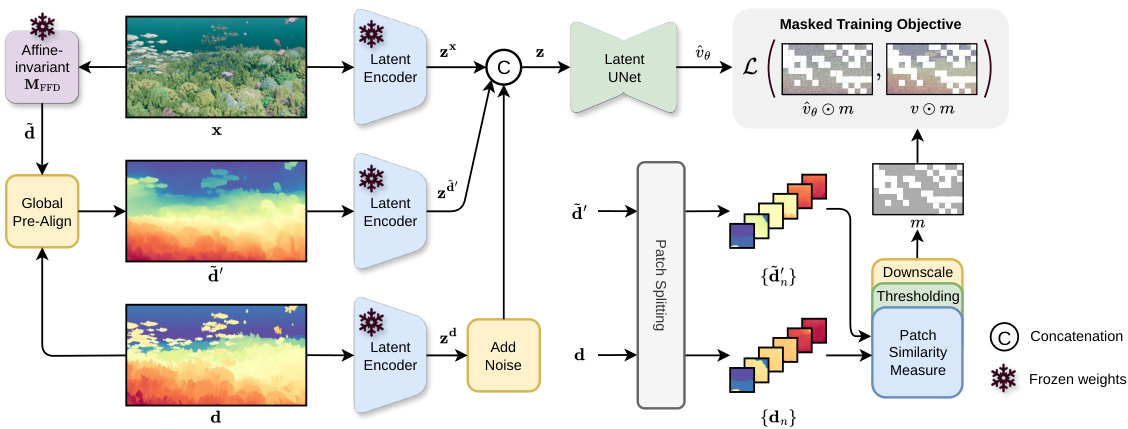
This figure illustrates the BetterDepth training pipeline. It starts by using a pre-trained feed-forward model (MFFD) to generate an initial depth map (d). This depth map is then globally aligned to the ground truth depth labels (d) to create an aligned conditioning depth map (d’). Both d and d’ are then encoded into latent space using a latent encoder. Next, d and d’ are split into patches. A similarity measure is used to identify dissimilar patches, which are masked to prevent overfitting. This masked training objective is used in combination with the latent space representations of the image (x) and the noisy depth (zd) to train a diffusion model (MDM) to refine the details of the initial depth map.
The figure illustrates the training pipeline of BetterDepth, a two-stage framework that refines depth maps from a pre-trained model (MFFD). The first stage uses global pre-alignment to align the initial coarse depth map with the ground truth. Then, both the coarse map and ground truth are divided into patches. Dissimilar patches are masked out, and the remaining patches are used to train a conditional diffusion model (MDM) to refine details in the latent space. This approach helps maintain the global structure while focusing on local detail improvements.
The figure illustrates the training pipeline of the BetterDepth model. It starts with a pre-trained feed-forward model (MFFD) that provides a coarse depth map (d) from an input image (x). This coarse map is then pre-aligned with the ground truth depth labels (d) to improve accuracy, generating an aligned depth map (d’). Both the input image and aligned depth map are encoded into a latent space using a latent encoder. To refine the depth details and prevent overfitting, the aligned depth map and the ground truth are divided into patches, and patches with low similarity are masked out. The masked patches are then used to train the diffusion model (MDM). This training scheme ensures that the refined depth remains faithful to the original prediction while adding fine-grained details.

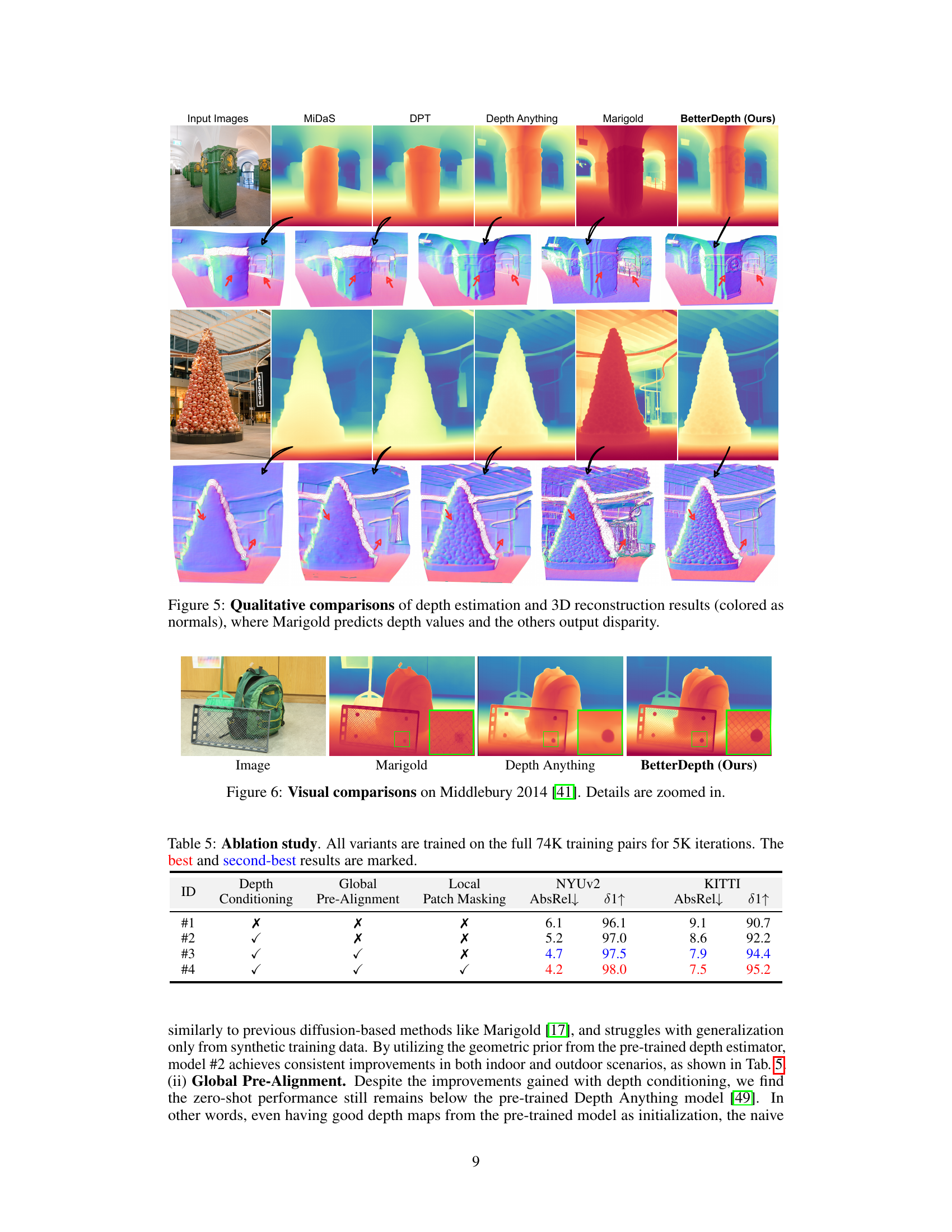
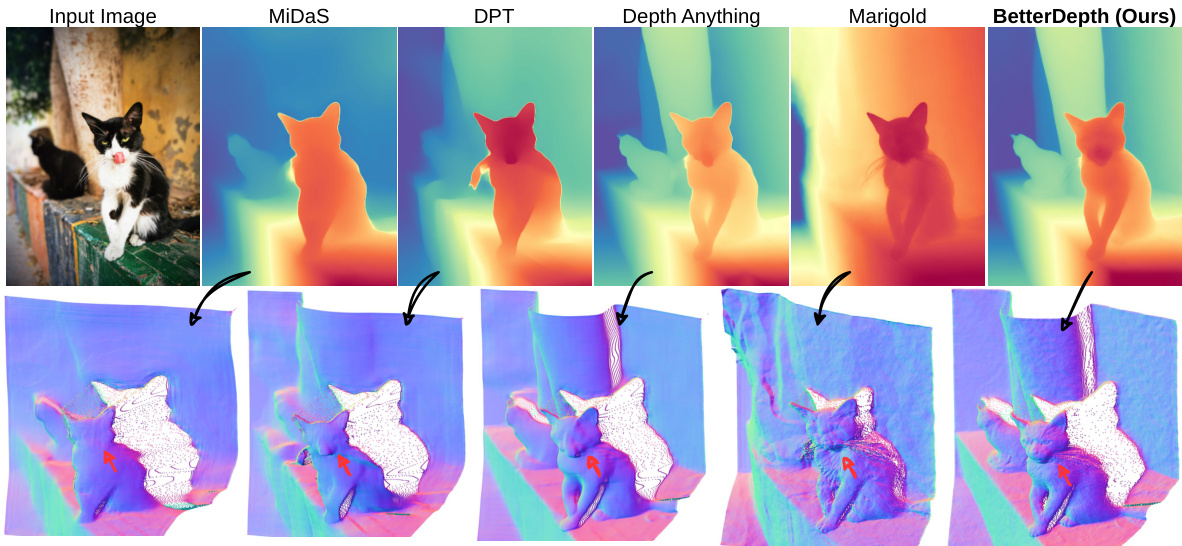
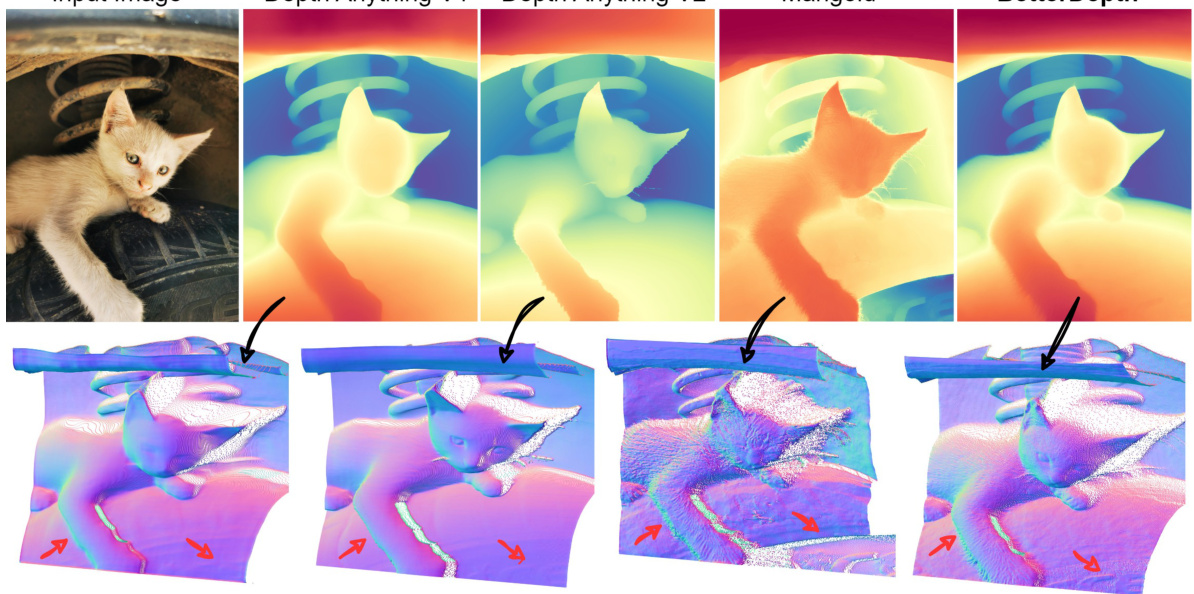
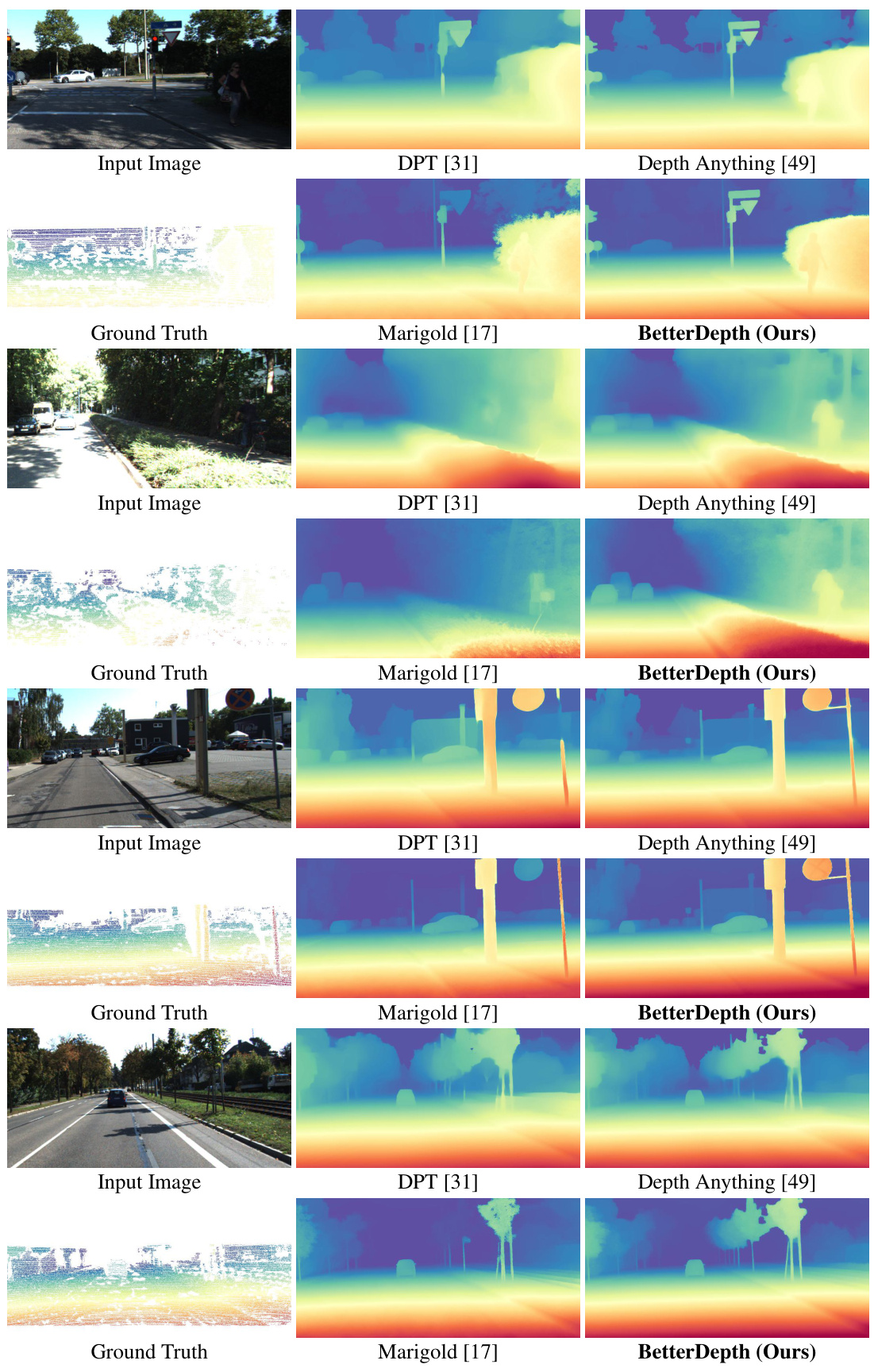
This figure shows a comparison of monocular depth estimation results from different methods. The input image is a photo of a cat. The first row shows depth maps generated by MiDaS, DPT, Depth Anything, Marigold, and BetterDepth. The second row shows 3D reconstructions of the scene using the corresponding depth maps, color-coded by surface normals. The figure highlights the trade-off between global shape accuracy and fine detail preservation in existing methods. BetterDepth aims to achieve both. Feed-forward methods (like Depth Anything) are good at global structure but lack detail, while diffusion-based methods (like Marigold) capture fine details but may struggle with global geometry. BetterDepth is presented as a solution that successfully integrates the strengths of both approaches.

This figure compares the performance of different monocular depth estimation methods. It shows that while feed-forward methods (like Depth Anything) are good at capturing the overall shape, they lack detail. Diffusion-based methods (like Marigold) excel at detail but struggle with accurate global shape, especially in complex scenes. The authors’ proposed method, BetterDepth, aims to combine the strengths of both approaches, resulting in accurate depth maps with fine details.
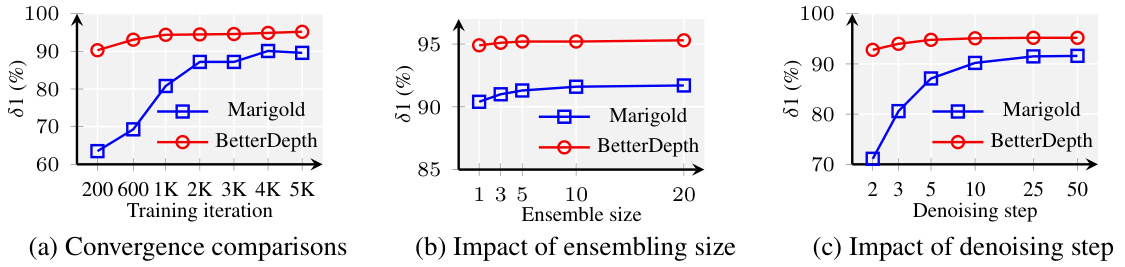
This figure compares BetterDepth and Marigold across three aspects: training iterations, ensemble size, and denoising steps. The (a) Convergence comparisons subplot shows that BetterDepth converges faster than Marigold, achieving comparable performance with fewer iterations. The (b) Impact of ensembling size subplot shows BetterDepth maintains higher performance with a smaller ensemble size, indicating better stability. The (c) Impact of denoising step subplot demonstrates that BetterDepth requires fewer denoising steps than Marigold to achieve similar performance.
This figure compares the performance of different monocular depth estimation methods. It shows that feed-forward methods (like Depth Anything) excel at capturing the overall 3D shape, but lack fine details. Diffusion-based methods (like Marigold) are better at capturing details, but struggle with accurate global shape representation. The authors’ proposed method, BetterDepth, aims to combine the strengths of both approaches, achieving both accurate global shape and fine details.
This figure shows a comparison of monocular depth estimation results from several different methods. The input image is a photograph of a cat. The results show that feed-forward methods (like Depth Anything) produce good overall depth but lack fine details. Diffusion-based methods (like Marigold) produce fine details but struggle with the overall depth layout. BetterDepth aims to combine the strengths of both approaches, providing both accurate depth and fine detail.
This figure compares the performance of several monocular depth estimation methods. It shows input images and their corresponding depth maps and 3D reconstructions. The figure highlights the strengths and weaknesses of different approaches: feed-forward methods (like Depth Anything) excel at capturing the overall 3D shape but lack fine details, while diffusion-based methods (like Marigold) are better at detail extraction but struggle with accurate global shape representation, particularly in complex scenes. BetterDepth, the proposed method, aims to combine the advantages of both approaches, achieving both accurate global shape and fine details in zero-shot settings.
This figure compares the performance of different monocular depth estimation methods. It shows that feed-forward methods (like Depth Anything) excel at capturing the overall 3D shape but lack fine details. Conversely, diffusion-based methods (like Marigold) are good at detail extraction but struggle with the global shape, particularly in complex scenes. BetterDepth, the authors’ proposed method, aims to combine the strengths of both approaches, achieving both accurate geometry and fine details.
This figure compares the depth estimation and 3D reconstruction results of several methods, including input image, MiDaS, DPT, Depth Anything, Marigold and BetterDepth. It highlights the strengths and weaknesses of different approaches. Feed-forward methods (like Depth Anything) excel at capturing the overall shape but lack fine details; diffusion-based methods (like Marigold) are better at capturing details but struggle with the global shape. BetterDepth aims to combine the advantages of both.

This figure compares the depth estimation and 3D reconstruction results of several monocular depth estimation methods, including Depth Anything, Marigold, and the proposed BetterDepth. It showcases that feed-forward methods excel at producing accurate global 3D shapes, while diffusion-based methods are better at capturing fine details. BetterDepth aims to combine the strengths of both approaches, resulting in depth maps that are both geometrically accurate and rich in detail.

This figure compares the performance of different monocular depth estimation methods. It shows that feed-forward methods like Depth Anything are good at capturing overall shape but lack detail. Diffusion-based methods such as Marigold excel at detail but struggle with overall shape. The authors’ proposed method, BetterDepth, aims to combine the best of both approaches, resulting in accurate depth maps with fine details.

This figure compares the performance of several monocular depth estimation methods. The input image is processed by different methods: MiDaS, DPT, Depth Anything, Marigold, and BetterDepth. The results show that feed-forward methods (like Depth Anything) produce good overall shape but lack detail, while diffusion-based methods (like Marigold) capture fine details but struggle with accurate global shape. BetterDepth aims to combine the strengths of both approaches, providing both accurate overall shape and fine details. The 3D reconstructions with color-coded normals further illustrate the differences in depth map quality.

This figure compares the performance of several monocular depth estimation methods. The input image is shown, followed by depth maps and 3D renderings generated by MiDaS, DPT, Depth Anything, Marigold, and the proposed BetterDepth method. The figure highlights that feed-forward methods (e.g., Depth Anything) produce good overall depth but lack fine details, while diffusion-based methods (e.g., Marigold) excel at detail but sometimes struggle with global shape accuracy. BetterDepth aims to improve upon both approaches, achieving both robust global depth and fine detail. The color-coded normals in the 3D reconstructions provide additional visual information about surface orientation.
This figure compares the performance of different monocular depth estimation methods. It shows that while feed-forward methods (like Depth Anything) excel at predicting the overall 3D shape, they lack fine details. Conversely, diffusion-based methods (like Marigold) are better at capturing details but struggle with global shape accuracy. BetterDepth, the proposed method, aims to combine the strengths of both approaches by refining the output of a pre-trained feed-forward model using a diffusion model to improve both global shape and fine details.

This figure showcases the performance comparison of different monocular depth estimation methods. It compares the depth maps and 3D reconstructions generated by several state-of-the-art techniques including feed-forward methods (like Depth Anything) and diffusion-based methods (like Marigold), highlighting their respective strengths and weaknesses. Depth Anything excels at providing robust global shapes but lacks detail. Marigold produces highly detailed depth maps but struggles with global shape. The authors’ method, BetterDepth, is shown to combine the strengths of both, achieving both accurate global geometry and fine details.
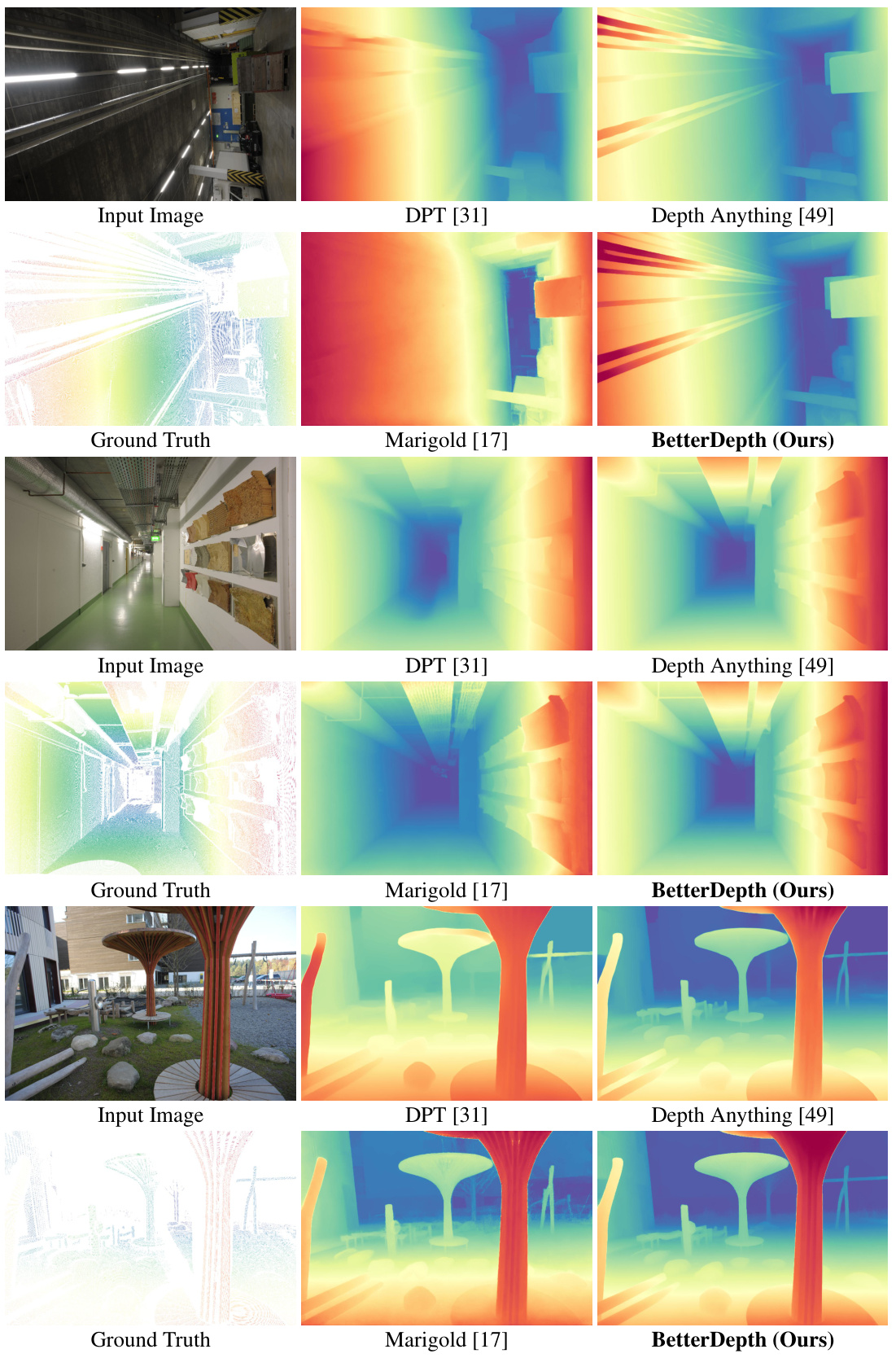
This figure compares the performance of different monocular depth estimation methods, including feed-forward methods (Depth Anything) and diffusion-based methods (Marigold). It shows that feed-forward methods are good at capturing the overall shape but lack detail, while diffusion-based methods excel at detail but struggle with global shape. The authors’ method, BetterDepth, aims to combine the strengths of both approaches, resulting in accurate depth estimation with fine details.

This figure compares the performance of several monocular depth estimation methods, including feed-forward methods (Depth Anything) and diffusion-based methods (Marigold). It highlights the strengths and weaknesses of each approach, demonstrating that feed-forward methods excel at capturing global 3D shapes but lack fine details, while diffusion-based methods produce more detailed depth maps but struggle with the overall shape in more complex scenes. The authors propose their method, BetterDepth, as a solution that combines the strengths of both approaches and delivers more accurate and detailed zero-shot depth estimation.

This figure shows a comparison of different monocular depth estimation methods applied to the same input image. The methods include MiDaS, DPT, Depth Anything, Marigold, and the authors’ proposed method, BetterDepth. Each method’s output is visualized as a depth map and a 3D reconstruction with color-coded normals. The figure highlights the strengths and weaknesses of each approach: feed-forward methods (like Depth Anything) produce good overall shape but lack detail, diffusion-based methods (like Marigold) capture fine details but struggle with global shape, while BetterDepth aims to combine the best of both.

This figure compares the performance of different monocular depth estimation methods. It shows input images and their corresponding depth maps and 3D reconstructions generated by several methods, including MiDaS, DPT, Depth Anything, Marigold, and the authors’ proposed method, BetterDepth. The comparison highlights BetterDepth’s ability to achieve both accurate global geometry and fine-grained details, outperforming other methods that either excel at one aspect but struggle with the other.

This figure shows a comparison of monocular depth estimation results from different methods: MiDaS, DPT, Depth Anything, Marigold, and the proposed BetterDepth. It highlights the trade-off between capturing accurate global shape and fine details. Feed-forward methods (MiDaS, DPT, Depth Anything) excel at global shape but lack fine detail, while diffusion-based methods (Marigold) are better at details but struggle with global accuracy. BetterDepth aims to combine the best of both worlds, showing accurate global shape with sharp details.

This figure shows a comparison of monocular depth estimation results from different methods. The input is a single image of a cat. The first method, MiDaS, provides a coarse depth map. DPT improves on this, while Depth Anything produces a more accurate global shape but lacks detail. Marigold, a diffusion-based method, produces a very detailed depth map but the global shape is less accurate. BetterDepth, the proposed method, aims to combine the strengths of these approaches, offering both accurate global shape and fine details.
More on tables
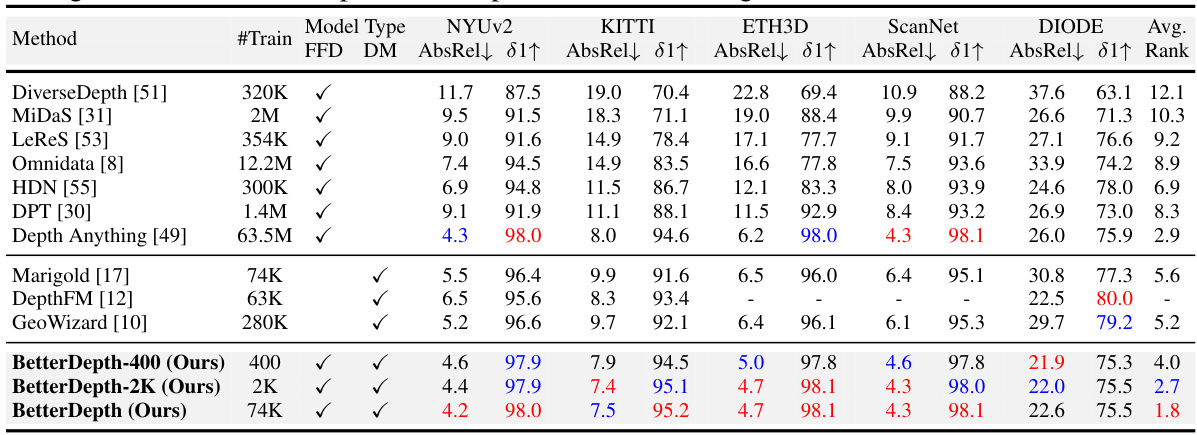
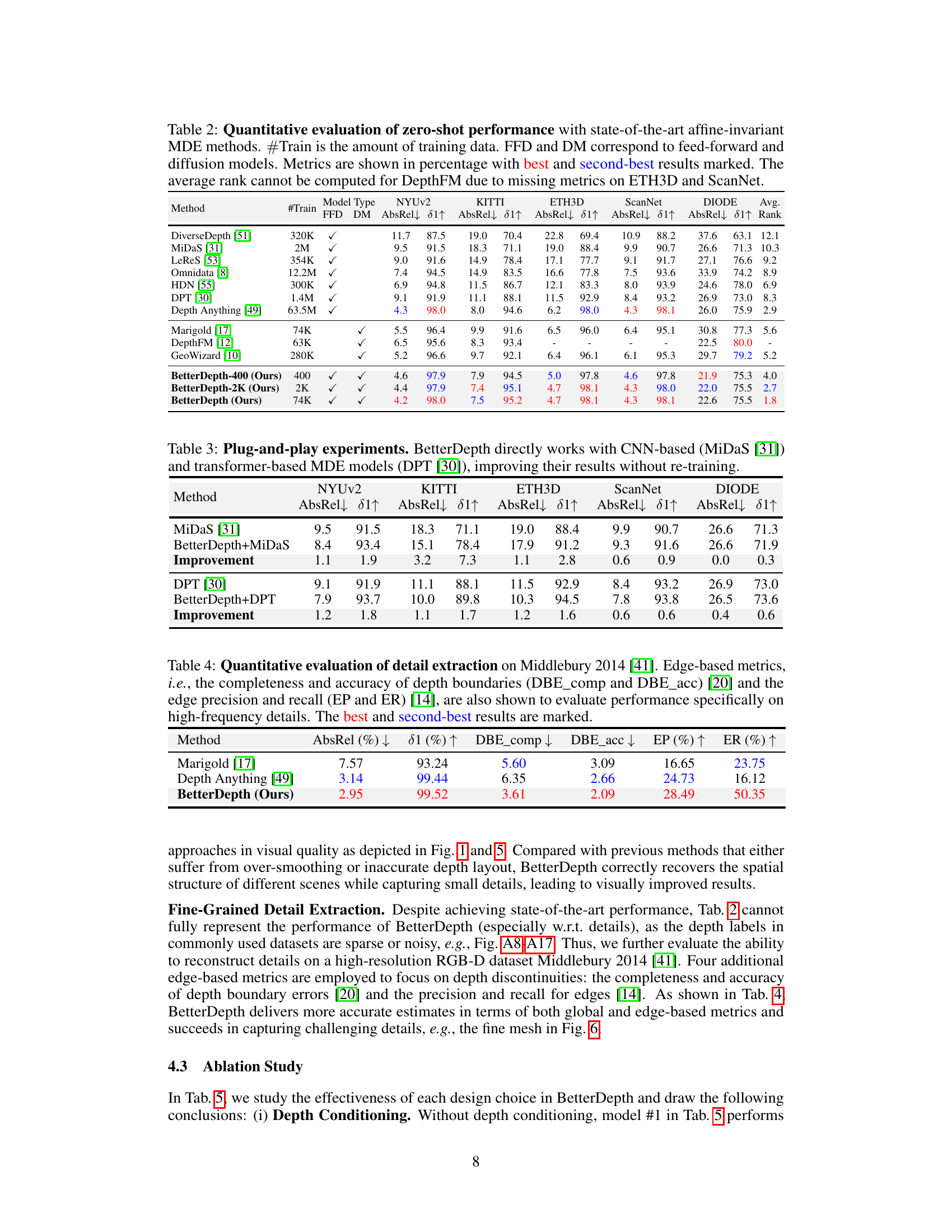
This table compares the zero-shot performance of BetterDepth against other state-of-the-art methods across five datasets (NYUv2, KITTI, ETH3D, ScanNet, DIODE). It evaluates performance using AbsRel and 81 metrics, showing the relative error and percentage of accurate depth predictions. The table highlights BetterDepth’s superior performance, especially when trained on a smaller dataset.
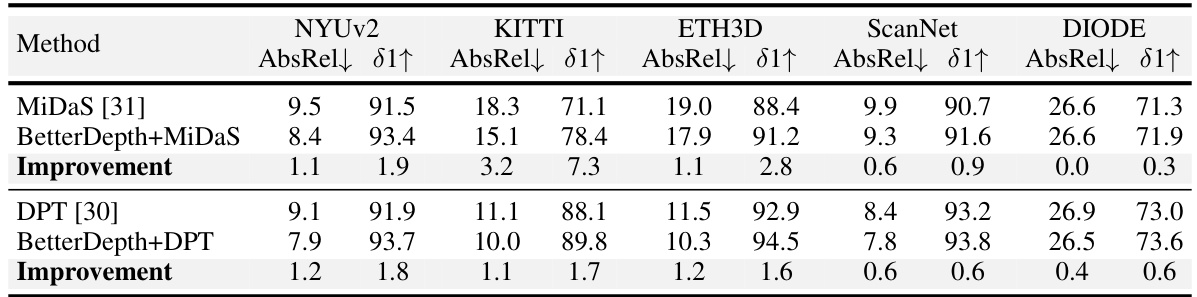
This table presents the results of plug-and-play experiments using BetterDepth with two different pre-trained models: MiDaS (CNN-based) and DPT (transformer-based). It demonstrates that BetterDepth can improve the performance of these existing models without requiring further re-training, showcasing its plug-and-play functionality and versatility.

This table compares the performance of different depth estimation methods on the Middlebury 2014 dataset, focusing on detail extraction capabilities. It uses standard metrics (AbsRel, δ1) along with edge-based metrics (DBE_comp, DBE_acc, EP, ER) to evaluate the accuracy and completeness of depth boundaries and fine details. The results highlight the ability of BetterDepth to accurately reconstruct fine-grained details compared to other methods.

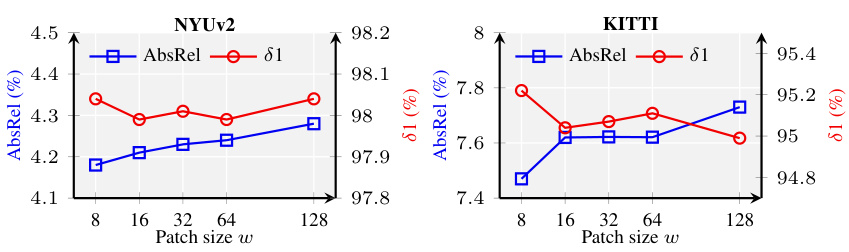
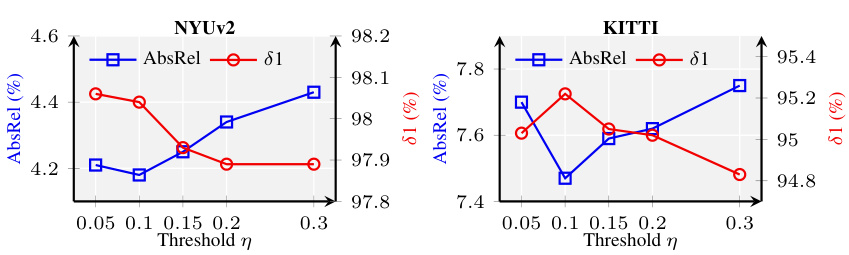
This table presents the ablation study results for the BetterDepth model. It shows the impact of each component of the model: depth conditioning, global pre-alignment, and local patch masking. The table compares the performance (AbsRel and 81) on the NYUv2 and KITTI datasets for four different model variants, each excluding one of the components. Variant #4 includes all three components and achieves the best performance, showcasing the contribution of each element to the overall results.

This table compares the zero-shot performance of BetterDepth against other state-of-the-art monocular depth estimation (MDE) methods across five datasets (NYUv2, KITTI, ETH3D, ScanNet, DIODE). It shows metrics (AbsRel and 81) for each method and dataset, indicating the amount of training data used for each method. The best and second-best results are highlighted for each metric. It helps to understand the relative performance of BetterDepth in comparison to other MDE models in zero-shot settings. Note that DepthFM is excluded from average rank calculations due to missing data.

This table presents a quantitative comparison of detail extraction performance on the Middlebury 2014 dataset. It compares several methods, including BetterDepth, using metrics such as absolute relative error (AbsRel), percentage of values within 1.25x of ground truth (δ1), and edge-based metrics (DBE_comp, DBE_acc, EP, ER) to evaluate accuracy of details. The best and second-best results are highlighted.

This table shows the ablation study results on the contribution of geometric and image priors in BetterDepth. It compares the performance of BetterDepth with and without each prior, demonstrating their individual and combined impact on depth estimation accuracy across several metrics. The results highlight the importance of incorporating both types of prior knowledge for optimal performance.
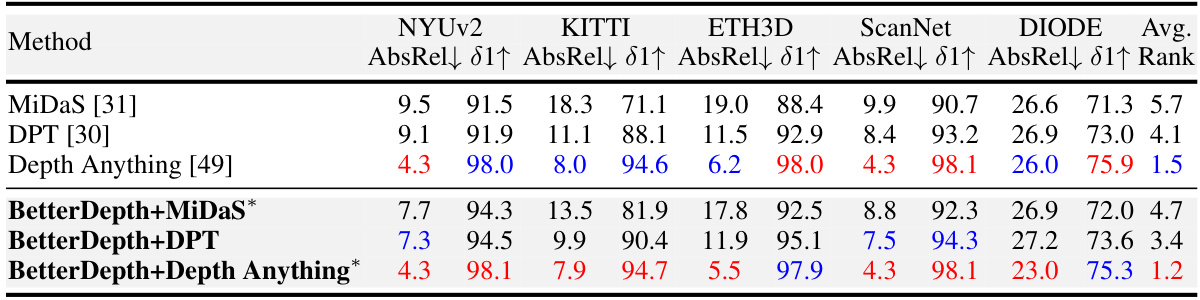
This table compares the zero-shot performance of BetterDepth against other state-of-the-art methods on five datasets (NYUv2, KITTI, ETH3D, ScanNet, DIODE). It shows quantitative metrics (AbsRel↓ and 81↑) for different models, categorized as feed-forward (FFD) or diffusion (DM) models. The table highlights BetterDepth’s superior performance, especially with limited training data, by showing its rank compared to other methods.

This table compares the zero-shot performance of BetterDepth with other state-of-the-art monocular depth estimation methods on five benchmark datasets (NYUv2, KITTI, ETH3D, ScanNet, DIODE). It evaluates both feed-forward (FFD) and diffusion (DM) models, considering the amount of training data used. Metrics such as AbsRel and δ1 are presented, with the best and second-best results highlighted. The table indicates BetterDepth’s superior performance across various datasets, even with less training data.
Full paper#