↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Few-shot semantic segmentation, a crucial task in image understanding, typically relies on complex, resource-intensive models. Existing methods often struggle with open-set generalization and high-quality segmentations. This research addresses these challenges by adapting diffusion models, known for their strong generative capabilities, to few-shot semantic segmentation tasks. The goal is to create a model that can accurately segment objects even with limited training data.
The researchers propose DiffewS, a novel framework designed to address the interaction between query and support images, incorporate information from support masks, and provide appropriate supervision. DiffewS maintains the original generative framework of the diffusion model and effectively utilizes its pre-trained prior. The results show that this simple and effective approach significantly outperforms other state-of-the-art methods in various experimental settings, particularly in the in-context learning setting. This suggests a promising direction for developing generalist, powerful segmentation models.
Key Takeaways#
Why does it matter?#
This paper is crucial because it bridges the gap between generative models and the field of semantic segmentation. By demonstrating the effectiveness of diffusion models for few-shot learning, it opens up new avenues for research in generalist segmentation models and paves the way for more efficient and adaptable segmentation techniques. The proposed framework, DiffewS, provides a solid foundation for future developments in the field, enabling researchers to create more powerful tools for image analysis and object recognition. This work will likely influence the development of novel in-context learning approaches and lead to improvements in various downstream vision tasks.
Visual Insights#

This figure provides a comprehensive overview of the DiffewS framework, illustrating the encoding process of query and support images and masks using a Variational Autoencoder (VAE). It also shows the fine-tuning protocol used in DiffewS, where encoded query and support image features are concatenated before being fed to the UNet. Finally, it details the KV Fusion Self-Attention (FSA) mechanism, highlighting how information from support images is incorporated by concatenating query and key features.
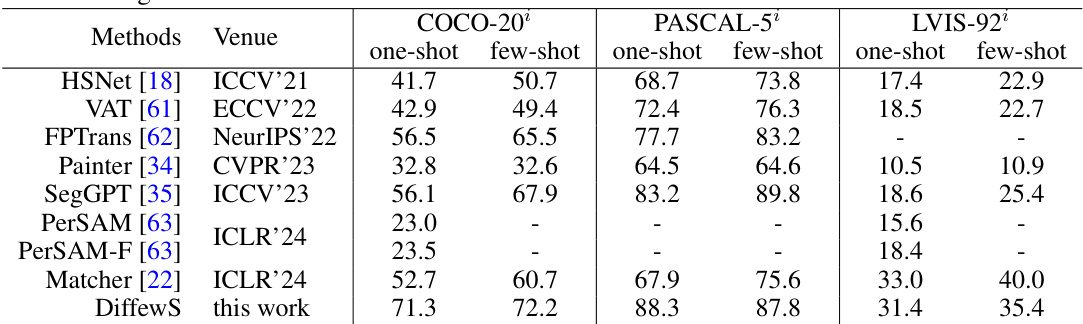
This table presents the results of few-shot semantic segmentation experiments conducted on three benchmark datasets (COCO-20, PASCAL-5, and LVIS-92) using different methods, in an in-context learning setting. The results show the performance of each method in terms of mean Intersection over Union (mIoU) for both one-shot and few-shot scenarios. This allows for a comparison of various methods’ ability to generalize to unseen categories with limited labeled data. The table provides a quantitative evaluation and comparison of different approaches to Few-Shot Semantic Segmentation.
In-depth insights#
DiffuSion in FSS#
Applying diffusion models to Few-Shot Segmentation (FSS) presents a unique opportunity to leverage the generative capabilities of diffusion models for improved segmentation accuracy and generalization. The inherent ability of diffusion models to learn rich representations from unlabeled data is particularly beneficial in the low-data regime typical of FSS. However, effectively integrating diffusion models with FSS tasks requires careful consideration. Challenges include efficiently encoding support information and query images into a format suitable for diffusion model processing, as well as designing effective loss functions to guide the diffusion process towards accurate segmentation masks. Furthermore, the computational cost of diffusion models needs to be balanced with FSS’s demand for speed and efficiency. Successful approaches will likely involve innovative methods for feature fusion, attention mechanisms, and potentially novel training paradigms that capitalize on the strengths of both diffusion models and FSS methodologies. Addressing these challenges will unlock a new paradigm in FSS that significantly surpasses current performance limits.
KV Fusion Self-Attn#
The proposed “KV Fusion Self-Attn” mechanism cleverly integrates information from support images into the self-attention layers of a diffusion model for few-shot semantic segmentation. Instead of treating query and support features separately, it fuses support image key (K) and value (V) features with the query features (Q) before the attention calculation. This approach allows the model to directly leverage contextual information from the support images, enabling more effective few-shot learning. The method is particularly insightful because it maximizes reuse of the original model architecture, avoiding the need for additional decoder heads or significant modifications to the pre-trained diffusion model. This simplicity and efficiency are key advantages, making it computationally efficient and easier to implement compared to methods requiring extensive retraining or architectural changes. The effectiveness hinges on the ability of the fused K and V to effectively guide the attention mechanism towards relevant parts of the query image, which improves accuracy and generalizability in the few-shot setting. However, further investigation is needed to determine the optimal strategies for effective fusion of the feature spaces and the limitations of the method when support image features are not aligned well with query image needs.
Mask Info Injection#
Incorporating mask information effectively is crucial for few-shot semantic segmentation. Several methods exist, each with trade-offs. Direct concatenation of the mask with image features is simple but may hinder performance due to representational differences. Multiplication of mask and image features offers a more nuanced approach, allowing the mask to modulate the feature values. However, attention mechanisms provide potentially superior control, selectively focusing network attention based on mask guidance. Additive integration, combining image and mask features, could offer benefits by providing complementary information. The optimal method likely depends on the specific network architecture and training data, with attention-based methods showing promise for sophisticated feature interaction and superior performance in few-shot settings. The choice necessitates careful consideration of computational cost and the network’s ability to learn effective representations from the combined information. Further investigation into the interplay of these strategies and their influence on generalization is warranted.
Gen. Process Expl.#
The heading ‘Gen. Process Expl.’ suggests an exploration of generative processes within a research paper. This likely involves a detailed investigation into how the model generates outputs, focusing on the underlying mechanisms and algorithms. The exploration could encompass several key aspects: the model architecture, which dictates how data flows and transformations occur; the training procedure, including the optimization algorithms, loss functions, and data used; the sampling strategies employed for generating diverse and realistic outputs; and analysis of the generative process, possibly using techniques like visualization or theoretical analysis to better understand model behavior. A thoughtful exploration should examine both the strengths and weaknesses of the generative process, perhaps by comparing its performance against established baselines or exploring different model variations. The results might reveal insights into the model’s capability, limitations, and areas for future improvement, providing valuable contributions to the broader field of generative models.
1-shot to N-shot#
The section ‘1-shot to N-shot’ explores extending a model trained on single-support-image scenarios to handle multiple support images (N-shot). The core challenge is that the 1-shot training doesn’t directly translate to effective N-shot inference. The paper investigates two solutions: modifying the inference process by sampling support image features to maintain consistency with training, and modifying the training process by incorporating multiple support images during training. The results highlight that training with multiple support images yields significantly better N-shot performance than simply adapting the inference process. This emphasizes that the model’s learning needs to explicitly handle multiple support contexts rather than simply adapting to them during inference. The findings underscore the importance of training data diversity in creating robust few-shot models and demonstrate a thoughtful approach to scaling from the 1-shot setting to a more generalized N-shot capability.
More visual insights#
More on figures

This figure compares two different interaction methods (KV Fusion Self-Attention and Tokenized Interaction Cross-Attention) combined with four different injection methods (concatenation, multiplication, attention mask, and addition) for incorporating support mask information into the model. The bar chart shows the mean Intersection over Union (mIoU) results for each combination, demonstrating the effectiveness of each approach. The results reveal that KV Fusion Self-Attention generally outperforms Tokenized Interaction Cross-Attention, and within KV Fusion Self-Attention, the concatenation method achieves the highest mIoU.

This figure shows four different ways to convert a query mask (Mq) into an RGB image for input to the VAE. The four methods are: (a) White foreground + black background; (b) Real foreground + black background; (c) Black foreground + real background; and (d) Adding mask on real image. A bar chart illustrates the mIoU (mean Intersection over Union) results for each method, demonstrating the superior performance of method (a). Method (a) is found to be the most effective because it is easier for the UNet to learn from, and it is also easier to obtain the final segmentation result through post-processing.

This figure shows three different mask generation processes and their results. (a) shows a pipeline of diffusion for mask generation. (b1), (b2), and (b3) illustrate the multi-step noise-to-mask generation (MN2M), multi-step image-to-mask generation (MI2M), and one-step image-to-mask generation (OI2M) methods, respectively. (c) compares the performance of these three methods in terms of mean Intersection over Union (mIoU). OI2M outperforms MN2M and MI2M, indicating that a direct one-step generation process is more effective for mask prediction.

This figure showcases qualitative results of the DiffewS model performing one-shot semantic segmentation on the LVIS-92 dataset. Each set of three images shows a reference image, ground truth mask, and the model’s prediction. The blue color highlights the support mask, while red highlights the query mask, demonstrating the model’s ability to segment objects based on limited visual input.

This figure shows the architecture of the proposed DiffewS framework. It consists of four parts: (a) Support Image Encoding, (b) Query Image Encoding, (c) DiffewS Fine-tuning protocol, and (d) KV Fusion Self-Attention (FSA). Part (a) and (b) illustrate how the support image, support mask, query image, and query mask are encoded into latent space representations. Part (c) details the training process where the concatenated query and query mask features are fed into UNet, with the latent representation of the query mask serving as supervision. Finally, part (d) illustrates how the key and value features are fused from support and query images within the self-attention mechanism.

This figure showcases three categories of failure cases encountered by the DiffewS model during one-shot semantic segmentation tasks on the LVIS-92 and COCO-20 datasets. These categories highlight the model’s limitations in handling specific image characteristics. The categories are: 1. Appearance disparity: Situations where there is a substantial visual difference between the support and query images, hindering accurate segmentation. 2. Look-alike interference: Scenarios with similar-looking objects in the query image that confuse the model’s segmentation process. 3. Occlusion interference: Instances where significant parts of the target object in the query image are hidden or obstructed, leading to inaccurate or incomplete segmentation. Each category includes three example pairs: the reference image, ground truth, and model prediction. The figure illustrates the challenges in achieving accurate segmentation under these complex image conditions.

This figure provides a comprehensive overview of the DiffewS framework, illustrating the encoding of query and support images and masks using a Variational Autoencoder (VAE), the fine-tuning protocol, and the key-value fusion self-attention (FSA) mechanism. Panel (a) shows support image encoding, (b) shows query image encoding, (c) demonstrates the DiffewS fine-tuning, and (d) details the FSA, emphasizing the fusion of information from support images via query-key concatenation.
More on tables
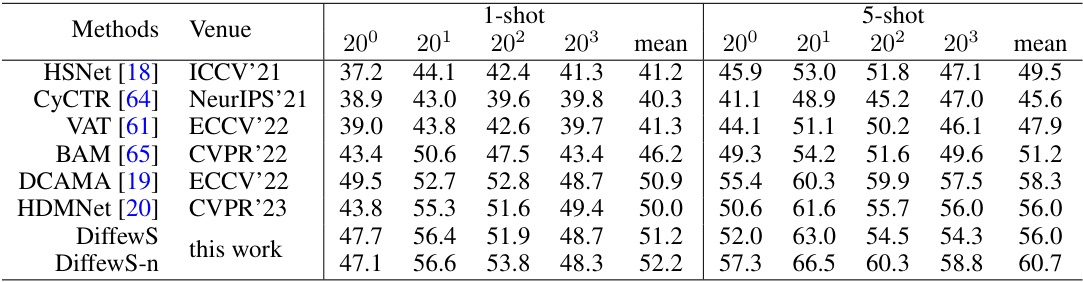
This table presents the results of the strict few-shot semantic segmentation experiment conducted on the COCO-20 dataset. It compares the performance of the proposed DiffewS method (both the original version and a version with training time improvements denoted by DiffewS-n) against several state-of-the-art (SOTA) methods. The results are shown for both 1-shot and 5-shot settings across four different folds (20’. Each fold consists of 60 classes for training and 20 for testing, and for each fold 1000 reference-target pairs are randomly sampled. The table shows the mean Intersection over Union (mIoU) scores for each method across all folds, offering a comprehensive evaluation of few-shot segmentation performance.

This table presents the results of an experiment comparing different thresholding methods (absolute and relative) used in post-processing the model’s output mask. The goal was to determine which thresholding method yielded the best segmentation performance (measured by mIoU). The table shows that a relative threshold of 0.25 produced the best results in this instance (47.69 mIoU).

This table presents a comparison of two different methods for applying the multiplication operation within the DiffewS framework. One method applies the multiplication in the latent space, while the other applies it directly to the RGB images. The table shows that applying the multiplication directly to the RGB images achieves slightly better results (33.12 mIoU) compared to applying it in the latent space (32.14 mIoU).

This table presents a comparison of two different self-attention fusion strategies: KV fusion and QKV fusion. The results show that the KV fusion strategy achieves slightly better performance (46.64 mIoU) compared to the QKV fusion strategy (46.61 mIoU).

This table presents the results of the DiffewS model on COCO and PASCAL datasets, comparing the performance with and without the inference time improvement. The original DiffewS model (‘ori’) is compared against a version that employs random sampling of keys and values from support samples during inference (‘sample’). Results are shown for 1-shot, 5-shot, and 10-shot scenarios, demonstrating the impact of the inference optimization on performance.
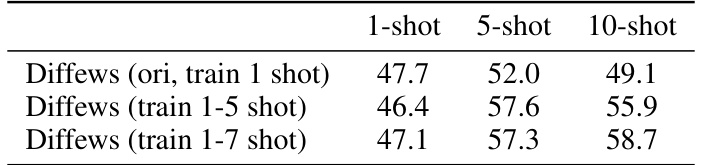
This table shows the performance (mIoU) of the DiffewS model in a few-shot semantic segmentation task under different training scenarios. The ‘Diffews (ori, train 1 shot)’ row represents the original model trained only for the 1-shot setting. The other rows demonstrate the improvement achieved by training the model with multiple shots (1-5 shots and 1-7 shots) before evaluating it on 1, 5, and 10 shot scenarios. The results indicate how training with multiple shots impacts the performance in different few-shot settings.
Full paper#