↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Open-set classification, a critical task in deploying machine learning models in real-world scenarios, faces challenges due to the overconfidence of traditional softmax-based classifiers and the immense diversity of out-of-distribution (OOD) samples. Existing methods often struggle to accurately classify samples from known classes and effectively reject OOD samples. Many approaches try to estimate the uncertainty of predictions or the density of in-distribution features, which are shown to be fragile to various OOD examples.
To address these issues, EGonc, a novel energy-based generative open-set node classification method, is proposed. EGonc generates substitute unknowns to mimic the distribution of real open-set samples, employs energy-based models as density estimators, and uses an additional energy logit to serve as an OOD indicator. The method offers strong theoretical properties guaranteeing a margin between IND and OOD detection scores and exhibits significant performance gains on benchmark datasets compared to state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on open-set node classification in graph neural networks. It introduces a novel approach that significantly improves accuracy and addresses the limitations of existing methods. This work will likely inspire further research into energy-based models, substitute data generation techniques, and their application to other open-world learning problems.
Visual Insights#
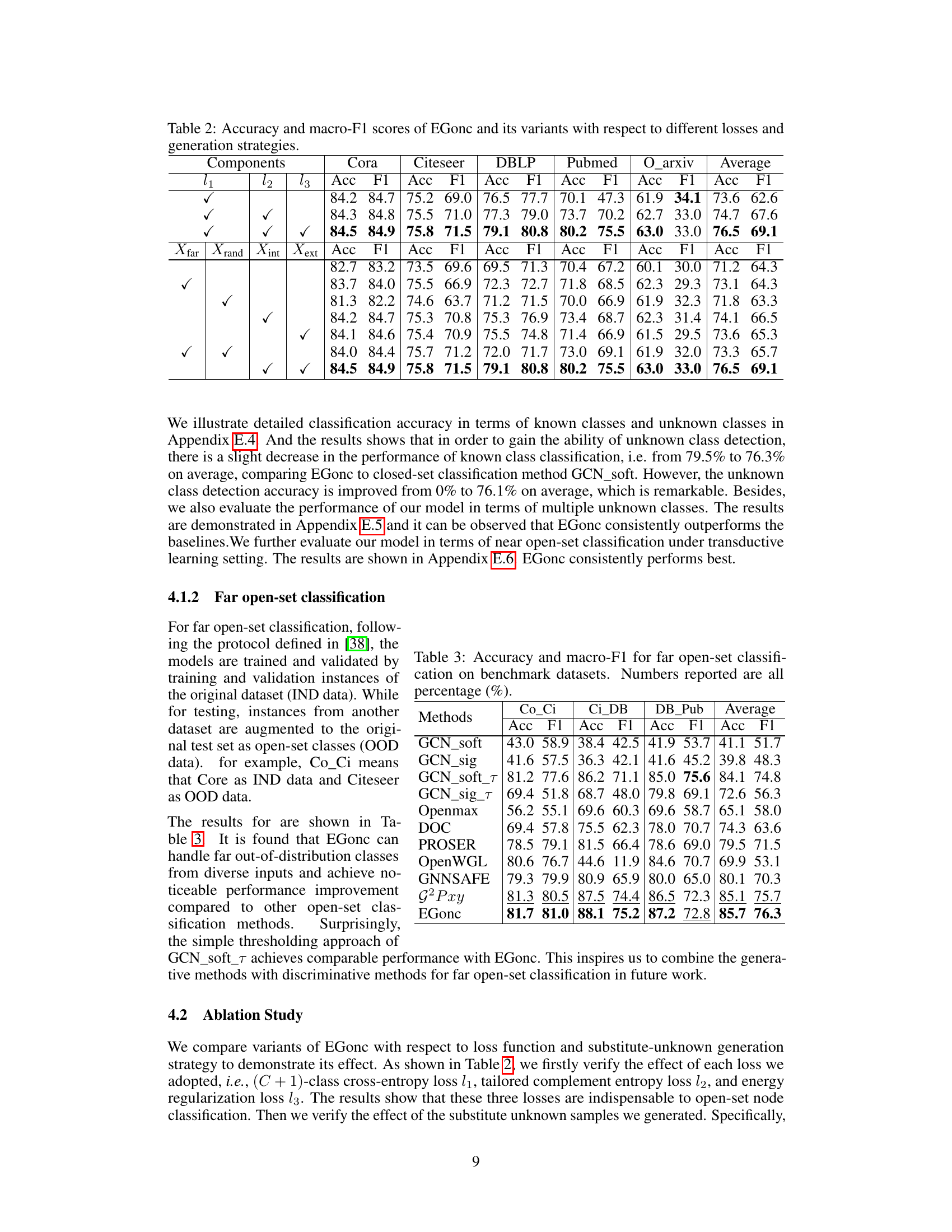
This figure shows the performance of the EGonc model on five different citation network datasets (Cora, Citeseer, DBLP, Pubmed, and Ogbn-arxiv) with varying numbers of generated substitute nodes. The x-axis represents the quantity of generated substitutes, which is expressed as a multiple of the average number of nodes in each known class. The y-axis shows the model’s performance, measured by both accuracy and F1-score. The figure demonstrates that the performance of the EGonc model is stable across a wide range of substitute node quantities, indicating its robustness and efficiency.
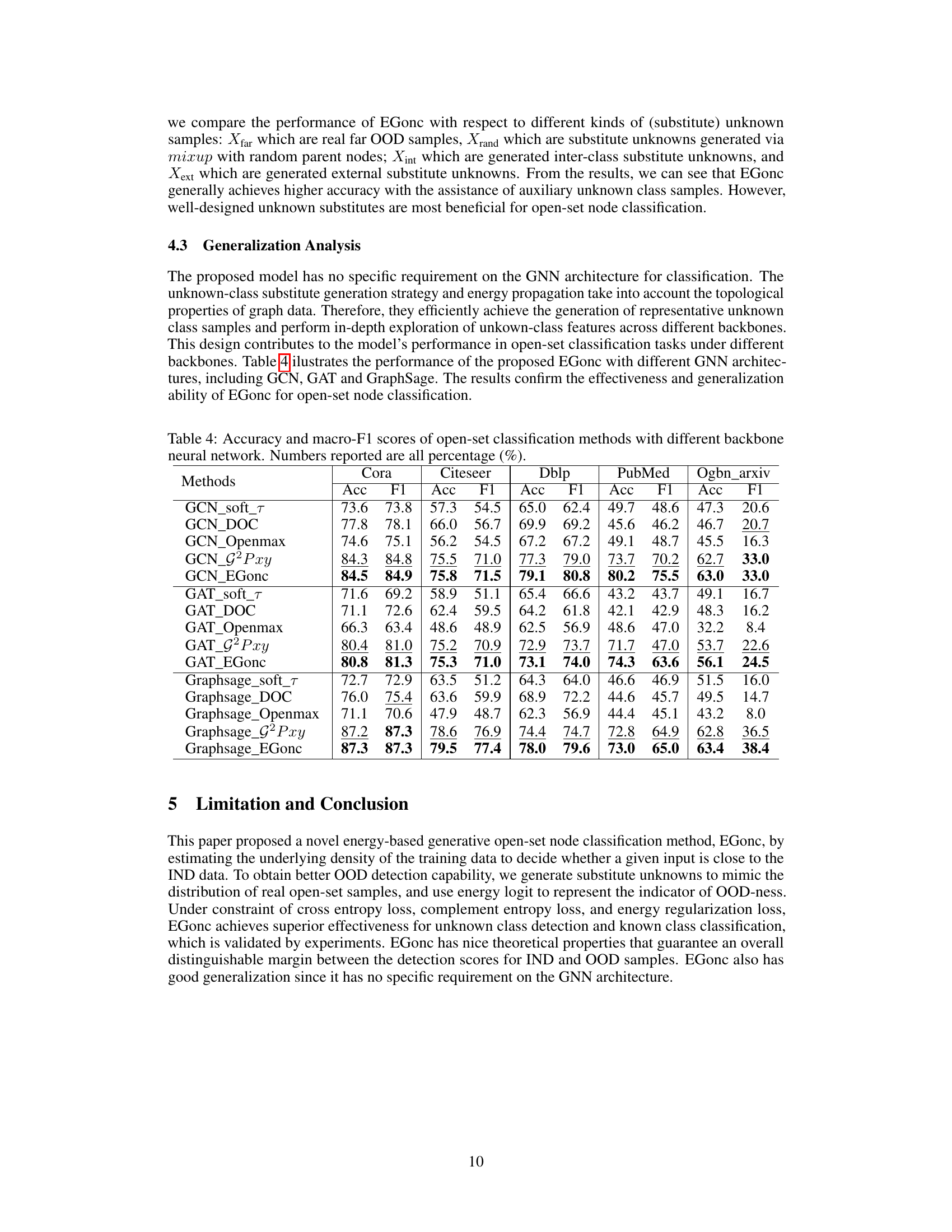
This table presents the results of near open-set node classification experiments conducted on five benchmark citation network datasets. Each dataset has one class designated as unknown, and the remaining classes are used for training. The inductive learning setting means that no information about the unknown class is provided during training. The table compares the performance of EGonc against several baseline methods in terms of accuracy and F1-score. The results show EGonc’s superiority over all baselines.
In-depth insights#
Open-Set Node Class#
Open-set node classification tackles the challenge of handling unseen node classes during the testing phase of a graph neural network. Unlike closed-set classification, which assumes all classes are known during training, open-set node classification requires the model to not only classify known classes but also reliably reject samples belonging to unknown classes. This necessitates designing methods to distinguish between in-distribution (IND) and out-of-distribution (OOD) data. The core difficulty lies in the inherent overconfidence of neural networks, which often assign high probabilities even to unfamiliar inputs. Therefore, novel approaches are necessary for accurately identifying OOD samples. Energy-based models and generative methods are explored to improve performance in this setting. Careful consideration of the underlying graph structure and the generation of substitute unknowns play a crucial role. The goal is to achieve a clear margin between classification scores for known and unknown classes, ensuring robust and reliable open-set node classification.
Energy-Based Model#
Energy-based models (EBMs) offer a powerful approach to open-set node classification by directly modeling the probability density of the data. Unlike discriminative models that rely on confidence scores, EBMs estimate the likelihood of an input belonging to the known data distribution. A key advantage is their ability to naturally handle out-of-distribution (OOD) samples, as OOD samples will tend to have lower probability density, leading to easier rejection. EBMs also avoid the issue of overconfidence that plagues softmax-based classifiers. However, the normalizing constant in EBMs is often intractable, requiring approximations. The paper addresses this by using energy scores as the basis of the classification, cleverly side-stepping the need for explicit density estimation. This allows the model to focus on distinguishing between in-distribution and out-of-distribution data, improving the overall performance and robustness of the open-set node classifier.
Substitute Unknowns#
The concept of “Substitute Unknowns” in open-set node classification addresses the challenge of handling unseen data during testing. The core idea is to generate synthetic data points that mimic the characteristics of real, unknown data. This avoids the need for collecting and labeling potentially scarce and costly real-world open-set samples. The generation process itself is crucial, often leveraging graph structure information. For example, the method may identify nodes near class boundaries or outlier nodes and create synthetic examples by perturbing features or graph connections to create a representative distribution of unknowns. By training the classifier with a mix of real known-class data and these synthetic substitutes, the model learns to distinguish between the seen and unseen classes, accurately classifying known data and rejecting inputs that resemble the generated unknown samples. The effectiveness heavily relies on the quality and representativeness of the generated substitute unknowns. Careful design of the generation process is paramount to achieve good generalization performance and avoid biasing the classifier towards the specific characteristics of the synthetic data.
Ablation & Analysis#
An ablation study, crucial for evaluating the impact of individual components within a machine learning model, would systematically remove or alter parts of the EGonc framework to isolate their effects. For example, removing the substitute unknown generation module would assess its contribution to open-set classification accuracy. Similarly, excluding the energy propagation module or varying the energy regularization loss would reveal their relative importance. Analyzing the results across these ablation experiments provides insights into the model’s strengths and weaknesses. Observing substantial performance drops when specific components are removed highlights their essential roles, such as substitute generation in improving OOD sample detection. Conversely, minor effects suggest potentially replaceable elements, potentially simplifying the model or improving its efficiency. A comprehensive analysis should not just focus on accuracy but also consider the trade-offs between performance, computational complexity, and model interpretability. For instance, if a simplified model with slightly reduced accuracy shows comparable performance, it might be preferred. This holistic perspective offers valuable insights into optimizing the EGonc model and developing improved, more efficient open-set node classification solutions.
Future Directions#
Future research could explore more sophisticated methods for generating substitute unknowns, potentially leveraging techniques from generative adversarial networks or variational autoencoders to better capture the distribution of unseen classes. Investigating the impact of different graph neural network architectures and their inherent biases on EGonc’s performance is another promising area. Theoretical analysis could focus on providing tighter bounds for the distinguishable margin between in-distribution and out-of-distribution samples, potentially leading to more robust open-set classification. Furthermore, extending the framework to handle dynamic graphs where nodes or edges are added or removed over time would be a significant advance. Finally, applying EGonc to real-world open-set problems in domains like social networks or recommendation systems and evaluating its performance against state-of-the-art methods would offer valuable insights into its practical applicability and limitations.
More visual insights#
More on tables
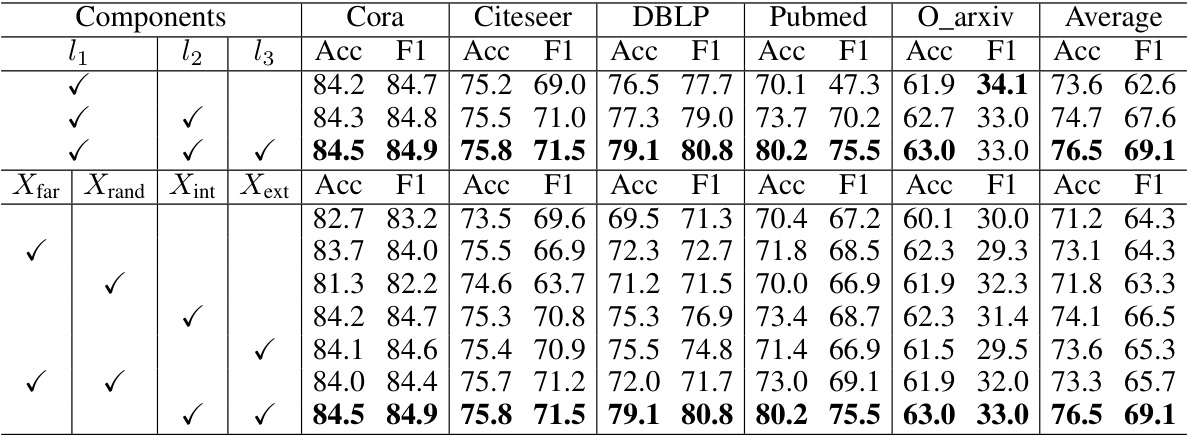
This table presents the results of near open-set node classification experiments on five benchmark citation network datasets. The inductive learning setting means that no information about the unknown classes (other than the fact that they are unknown) was used during training. Each dataset had one of its classes designated as the unknown class for testing. The table compares the performance of the proposed EGonc method against several baselines in terms of accuracy and F1-score.
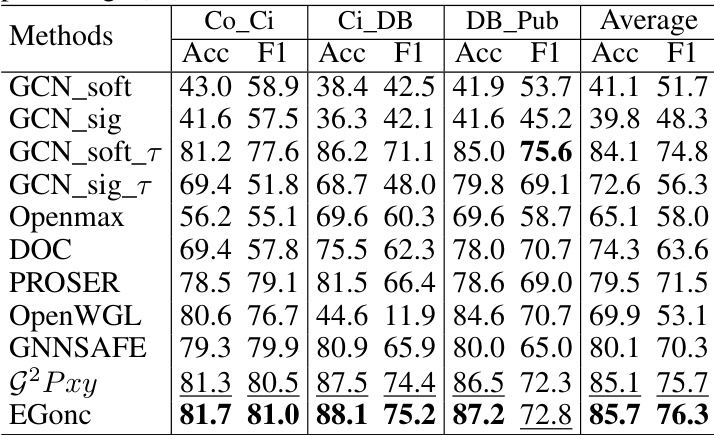
This table presents the results of far open-set node classification experiments. The experiments evaluate the performance of various methods when the test set includes nodes from a different dataset than the training set (out-of-distribution data). The table shows the accuracy and macro-F1 scores for each method across five benchmark graph datasets, using different combinations of in-distribution and out-of-distribution datasets for training and testing.
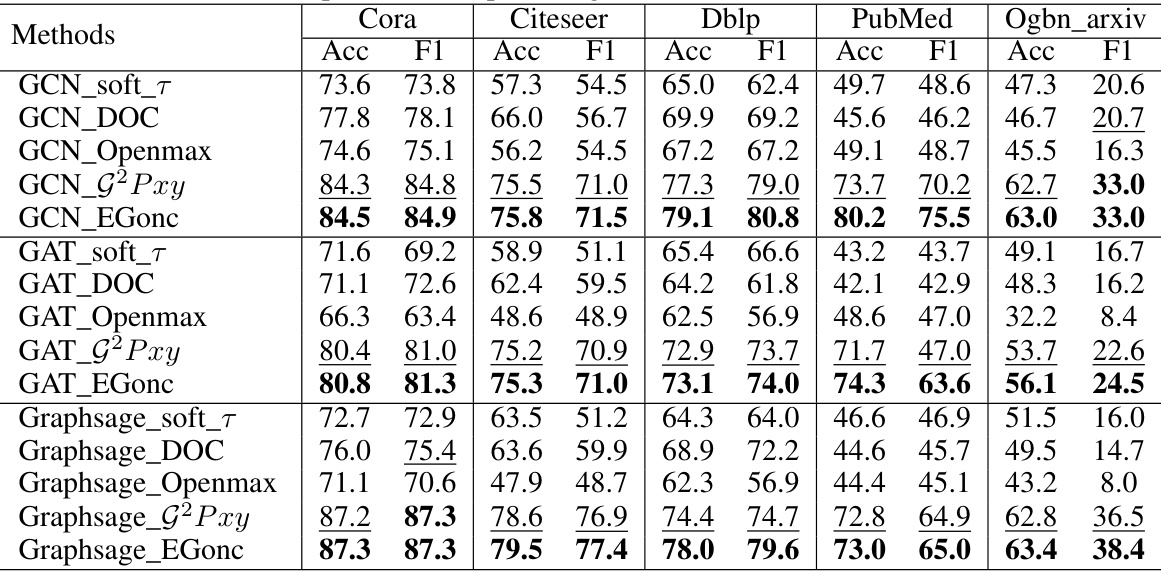
This table presents the results of a near open-set node classification experiment. Five citation network datasets were used, each with one unknown class (u=1). The experiment was conducted under an inductive learning setting, meaning that no information about the unknown classes was used during training or validation. The table compares the performance of EGonc against several baseline methods in terms of accuracy and F1 score.
This table presents the results of near open-set node classification experiments on five citation network datasets. For each dataset, one class was designated as the unknown class, and the remaining classes were used for training. The inductive learning setting means that no information about the unknown class was provided during training. The table shows the accuracy and F1-score for several open-set classification methods. The results highlight the performance of the proposed method (EGonc) compared to several baselines.

This table presents the results of a near open-set node classification experiment. Five citation network datasets were used, each with one class designated as unknown. The inductive learning setting means that no information about the unknown class was used during training. The table compares the performance of EGonc against several baseline methods in terms of accuracy and F1-score.

This table presents the results of a near open-set classification experiment conducted under the inductive learning setting. Multiple unknown classes were used (u=2, 3 for Cora and Citeseer; u=5, 10, 15, 20 for Ogbn-arxiv). The table shows the accuracy and F1 scores for various methods, demonstrating the performance under different numbers of unknown classes. This helps to illustrate the robustness and generalizability of EGonc in the face of varying levels of uncertainty or unseen data.
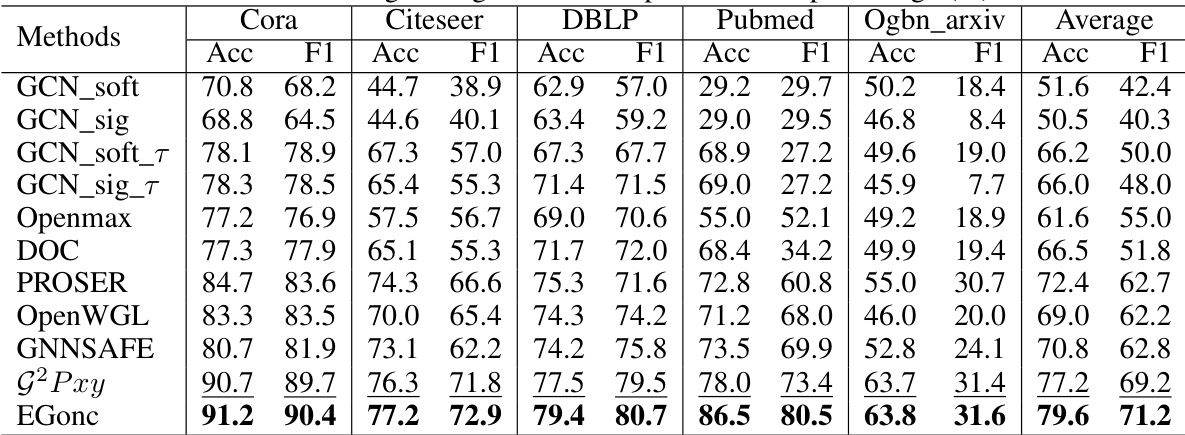
This table presents the results of near open-set node classification experiments on five citation network datasets. The experiments were conducted using an inductive learning setting, meaning no information about the unknown class was used during training or validation. For each dataset, one class was designated as the unknown class, and the remaining classes were used for training and testing. The table reports the accuracy and F1-score for several methods, including the proposed EGonc method and various baselines. The results show EGonc’s superior performance compared to existing approaches.
Full paper#