↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Creating realistic digital humans from video is challenging due to the difficulty in capturing and animating fine details, especially in hands and faces. Current methods often struggle with accurately capturing subtle movements and expressions from single-view video data, leading to less realistic avatars.
This paper introduces EVA, a novel method that tackles this challenge by representing the human body using 3D Gaussians and an expressive parametric human model (SMPL-X). EVA introduces a reconstruction module to improve the image-model alignment, a context-aware adaptive density control strategy to better manage the granularity across different body parts, and a feedback mechanism to guide the 3D Gaussian optimization. The results demonstrate significant improvement over existing state-of-the-art methods, especially for fine-grained details.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer graphics, computer vision, and machine learning. It addresses the challenge of creating highly expressive and realistic digital human avatars from simple monocular RGB videos, a problem with broad applications in AR/VR, film, and beyond. The techniques introduced, especially the context-aware adaptive density control and the novel alignment method, are valuable contributions to the field and open doors for numerous future research directions.
Visual Insights#
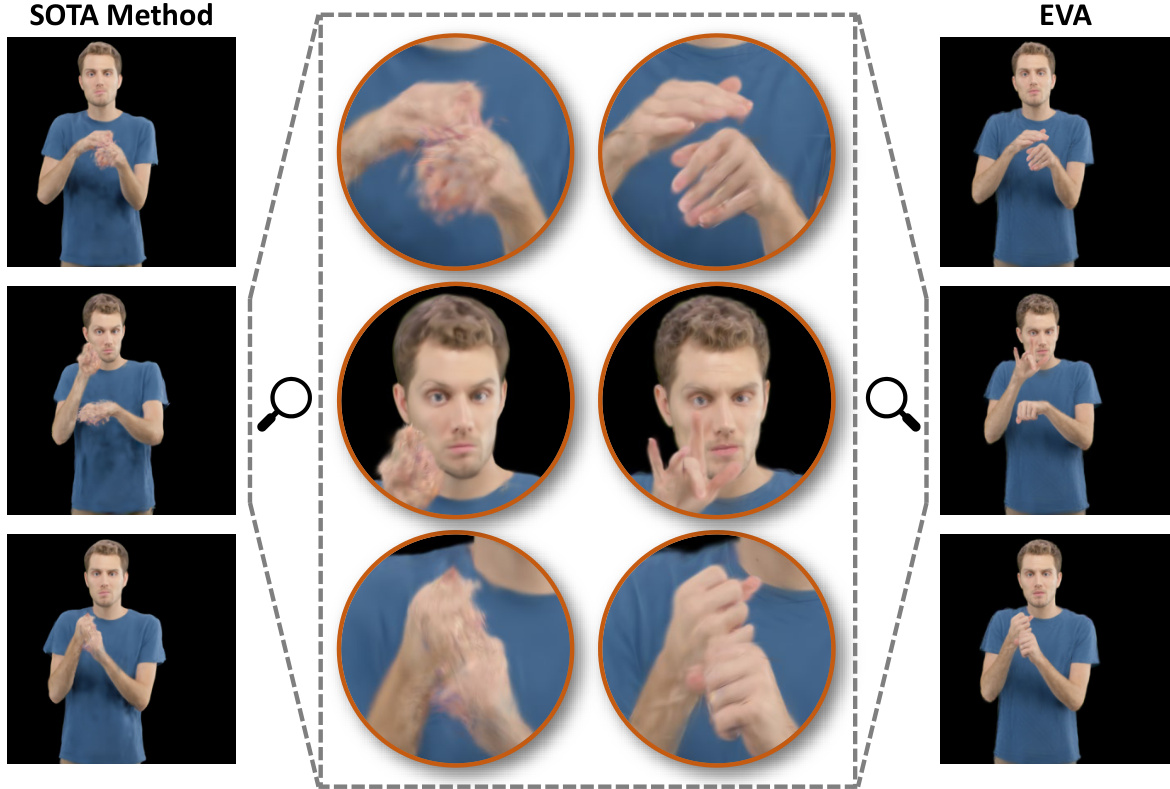
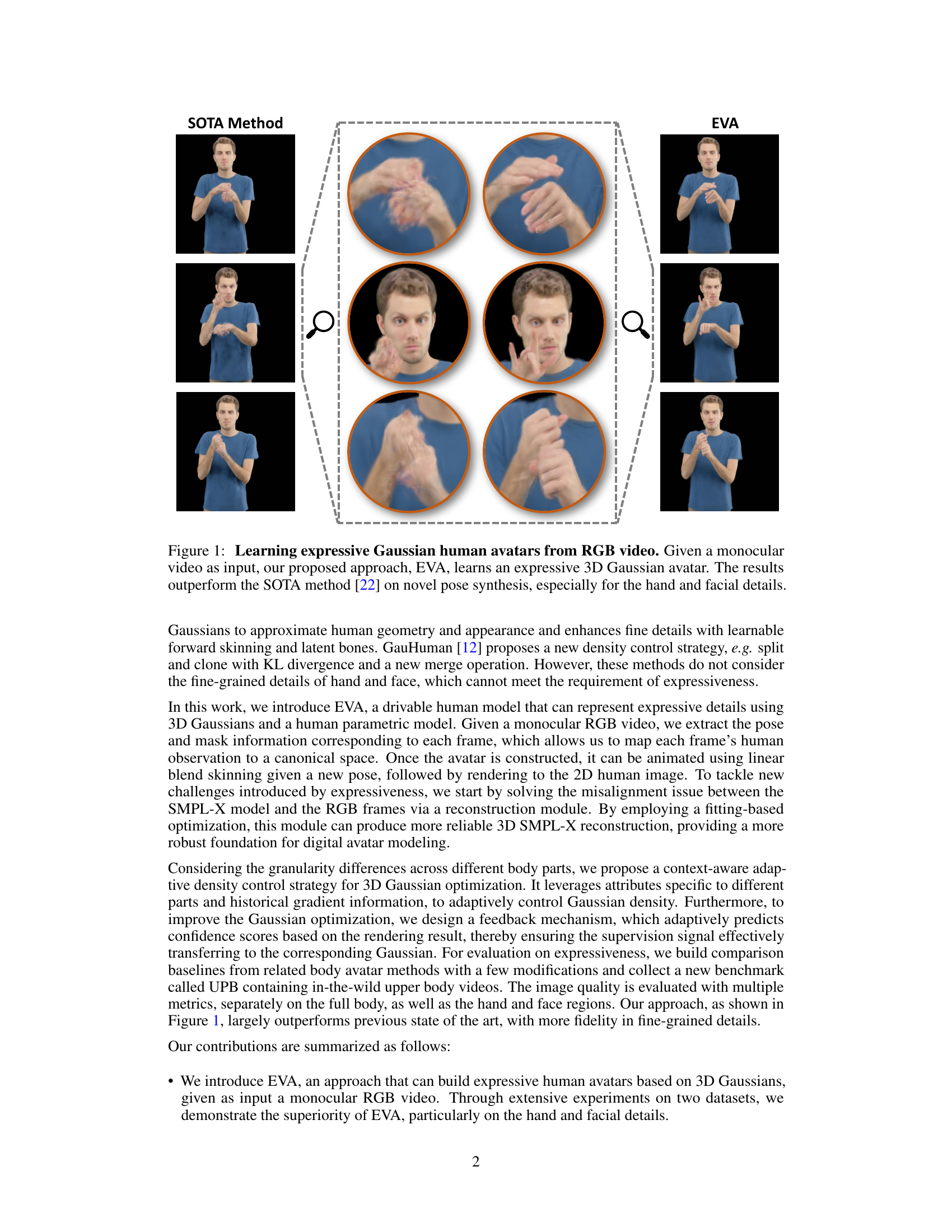
This figure compares the results of a state-of-the-art (SOTA) method and the proposed EVA method for generating expressive 3D Gaussian human avatars from a monocular RGB video. The top row shows frames from a sample video. The middle rows show close-ups of hand and facial details generated by the SOTA method, highlighting limitations in detail and expressiveness. The bottom row displays the corresponding results from the EVA method, illustrating improved expressiveness and detailed reconstruction, particularly in the hands and face.
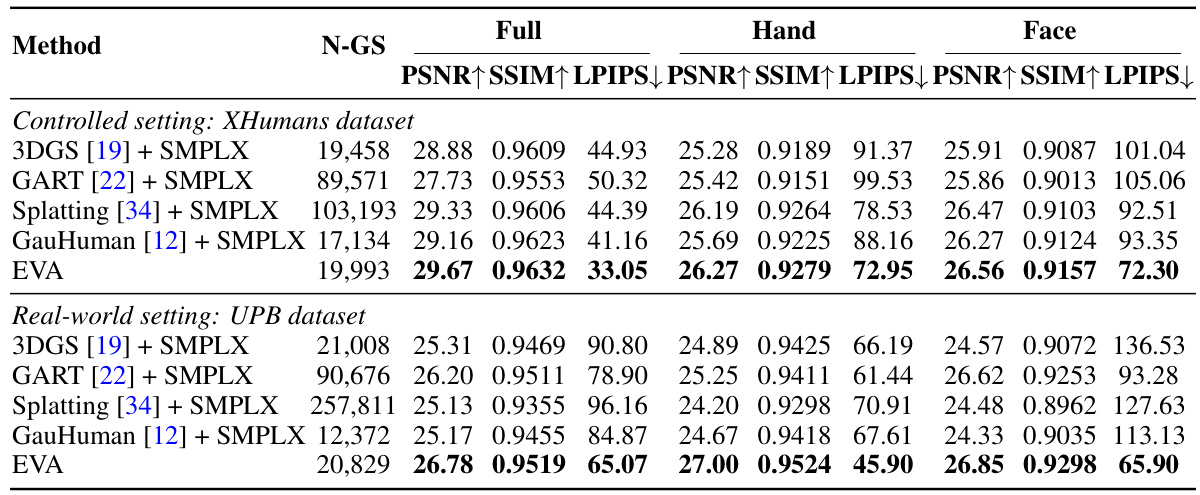
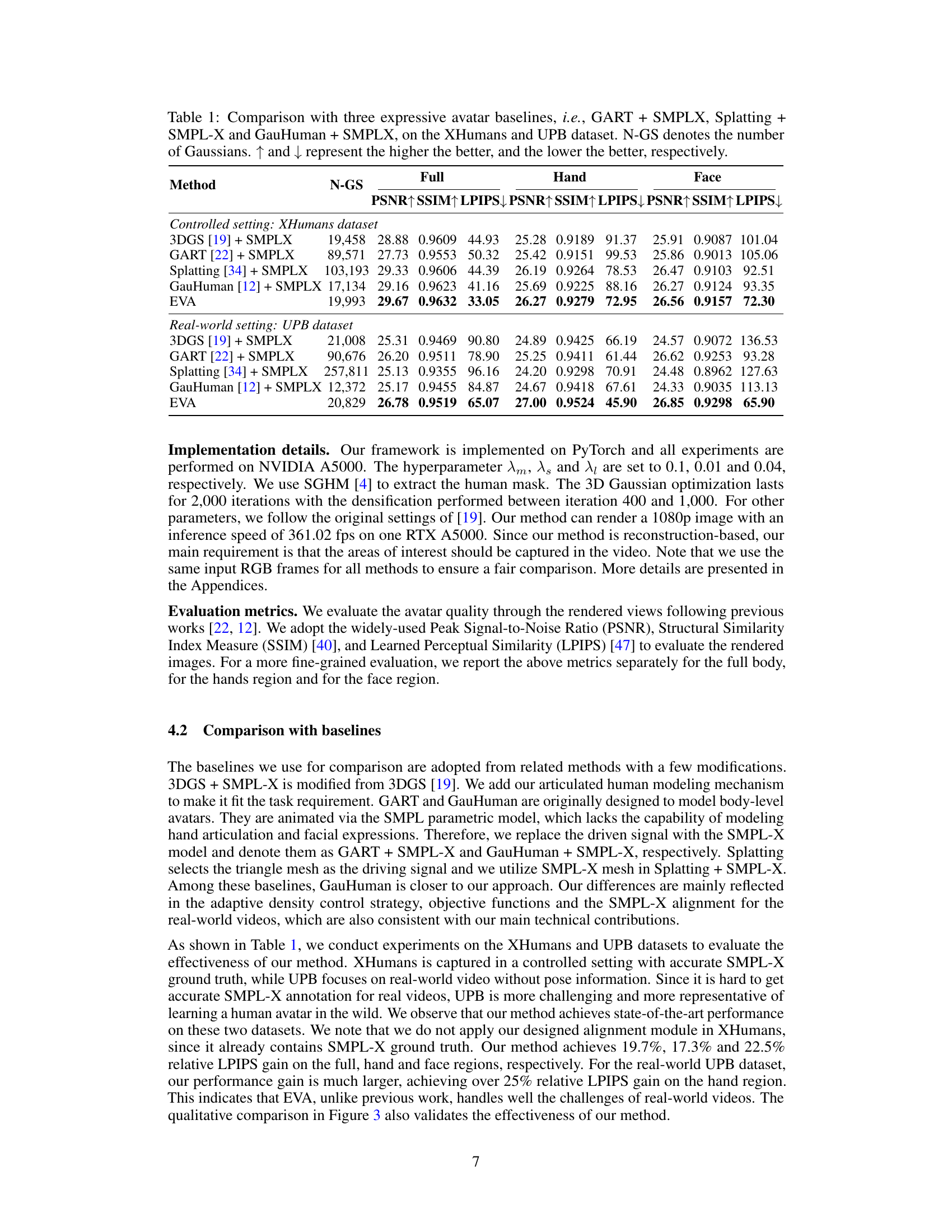
This table compares the performance of the proposed EVA method against three other state-of-the-art expressive avatar baselines on two datasets: XHumans (controlled setting) and UPB (real-world setting). The metrics used are PSNR, SSIM, and LPIPS, calculated for the full body, hands, and face separately. N-GS represents the number of 3D Gaussians used in the model. The arrows indicate whether higher or lower values are better for each metric.
In-depth insights#
Expressive Avatar#
The concept of “Expressive Avatar” in this research paper centers around creating highly realistic and emotionally engaging digital humans. The paper emphasizes the need to move beyond simple body representations to capture fine-grained details, such as nuanced facial expressions and hand gestures, to enhance realism. This is achieved by leveraging sophisticated techniques, which combine 3D Gaussian splatting for efficient rendering with a parametric human body model like SMPL-X. Context-aware adaptive density control is crucial for handling the variable detail across different body parts, optimizing detail in areas like hands and face. A key innovation is the introduction of a feedback mechanism using predicted pixel confidence to improve 3D Gaussian optimization. The ultimate goal is to generate avatars that are not only visually accurate but also convey complex emotions and intentions, pushing the boundaries of human-computer interaction and digital human representation. The paper achieves significant improvements in the realism and expressiveness of the avatars over current state-of-the-art methods, particularly in the often-challenging fine details of hands and faces.
3D Gaussian#
The concept of “3D Gaussian” in the context of a research paper likely refers to the utilization of three-dimensional Gaussian functions as fundamental building blocks for representing complex shapes or objects. This approach leverages the inherent properties of Gaussian distributions, specifically their ability to smoothly approximate various forms. The use of 3D Gaussians allows for efficient shape representation, as each Gaussian represents a localized blob of density, making it ideal for capturing fine details and intricate geometries. Combining numerous such Gaussians through summation or other sophisticated techniques enables the construction of arbitrarily complex 3D models. The choice of 3D Gaussians often stems from their mathematical tractability, facilitating efficient optimization procedures crucial for learning and rendering. Furthermore, the parameters of each 3D Gaussian (mean, covariance matrix) provide intuitive handles for manipulating the model’s shape and appearance, allowing for fine-grained control and the possibility of incorporating learned parameters to achieve high realism.
Adaptive Density#
Adaptive density in 3D Gaussian splatting for human avatar generation is a crucial technique for balancing detail and efficiency. A fixed density approach is computationally expensive and may not capture nuanced details, while a lower density results in a less realistic representation. Adaptive density control dynamically adjusts the number of Gaussians based on the complexity of the region. This approach is particularly important in areas like hands and faces which require fine-grained detail, while maintaining a lower density in simpler regions like the torso to optimize performance. The success of adaptive density hinges on effectively determining a context-aware threshold to trigger density adjustments. This threshold should account for factors such as per-pixel confidence, gradient information, and inherent characteristics of body regions. Incorporating a feedback mechanism that predicts per-pixel confidence enhances this process, leading to more refined density adjustments. The adaptive nature of the density also presents challenges; over-densification may lead to computational bottlenecks and unnecessary memory usage, while under-densification results in insufficient detail. Therefore, a careful balance is required to make this approach practical and effective.
SMPL-X Alignment#
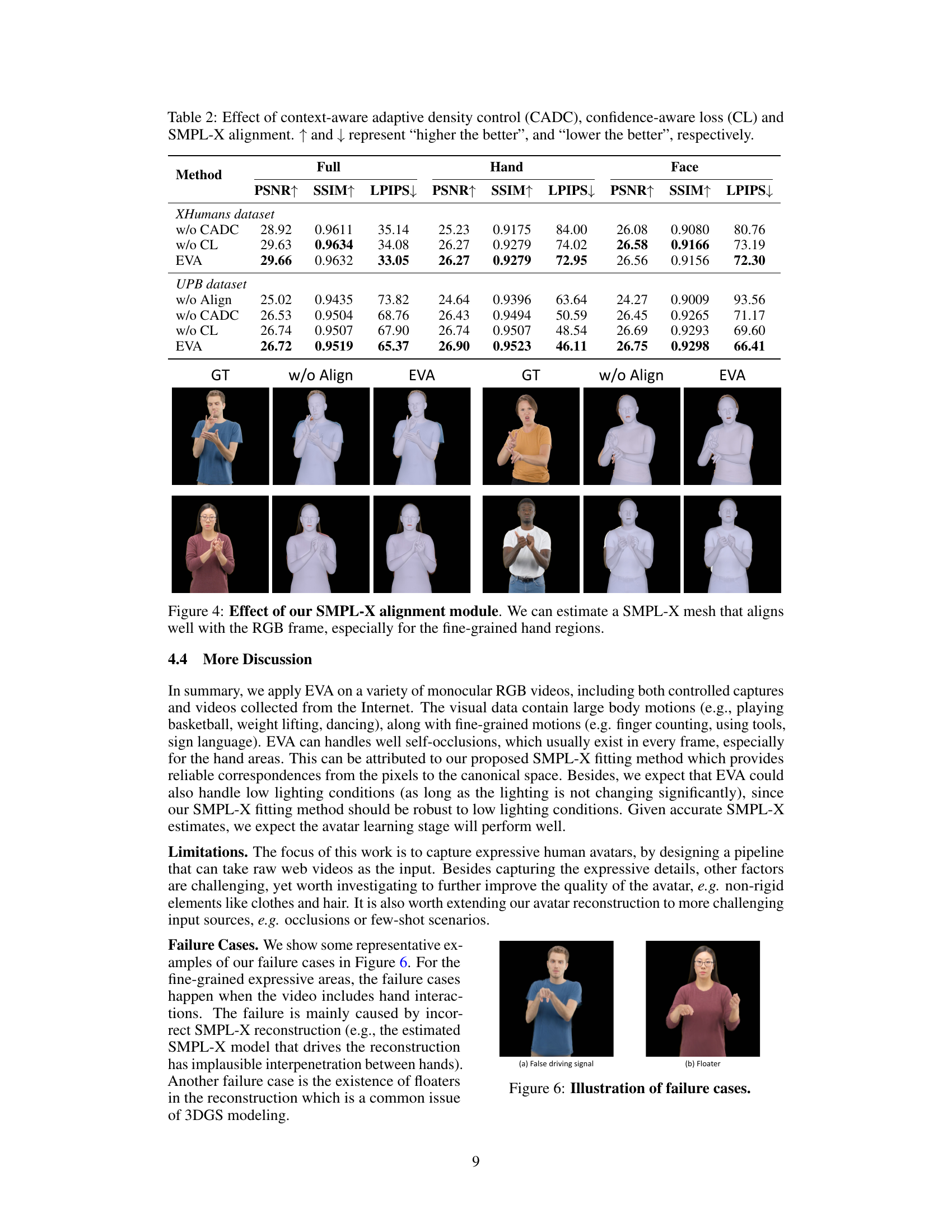
Accurate SMPL-X alignment is crucial for high-fidelity avatar creation from video. The challenge lies in robustly estimating SMPL-X parameters (pose, shape, expression) that accurately reflect the 3D human pose within the often noisy and partially-observed 2D video frames. The paper addresses this by proposing a reconstruction module that leverages multiple data sources, including initial camera parameters, predicted 2D keypoints, and potentially 3D hand data, to improve the initial SMPL-X estimate. This multi-modal approach enhances robustness, particularly important when dealing with real-world videos. The fitting process minimizes a loss function combining 2D-3D correspondence errors, body pose priors, and hand pose priors. This integrated approach addresses the inherent ambiguities in monocular video data, leading to significantly improved SMPL-X alignment and a stronger foundation for subsequent avatar generation steps.
Future Works#
The ‘Future Works’ section of this research paper hints at several promising avenues for extending the current research. Improving the handling of non-rigid elements like clothing and hair is a significant challenge, as is extending the approach to handle more challenging input scenarios, such as those with significant occlusions or limited data. Robustness against low lighting conditions is another area for potential improvement, and also enhancing the handling of self-occlusions in the video. Finally, making the method more generalizable, removing the need for per-subject training and achieving successful avatar creation from very limited input (a single image, for instance) are ambitious but potentially transformative goals that would significantly broaden the impact of this research.
More visual insights#
More on figures
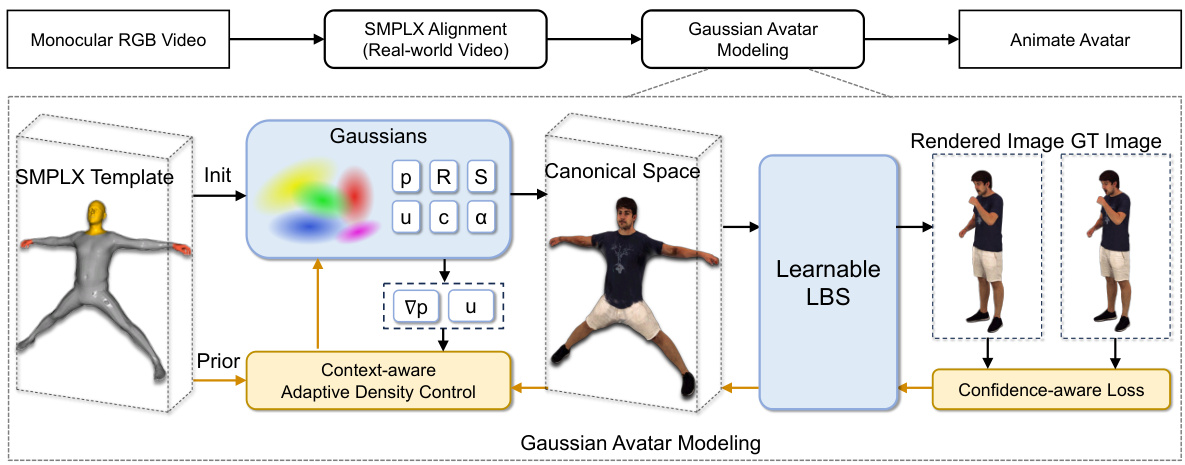
This figure illustrates the overall pipeline of the EVA method. It starts with a monocular RGB video as input. The first stage is SMPL-X alignment, where a reconstruction module aligns a SMPL-X mesh to the video frames. The second stage is Gaussian Avatar Modeling, which uses 3D Gaussian Splatting and incorporates the SMPL-X model as prior for better human shape representation. To enhance quality, context-aware adaptive density control and confidence-aware loss are applied during optimization. Finally, an animated avatar is generated.

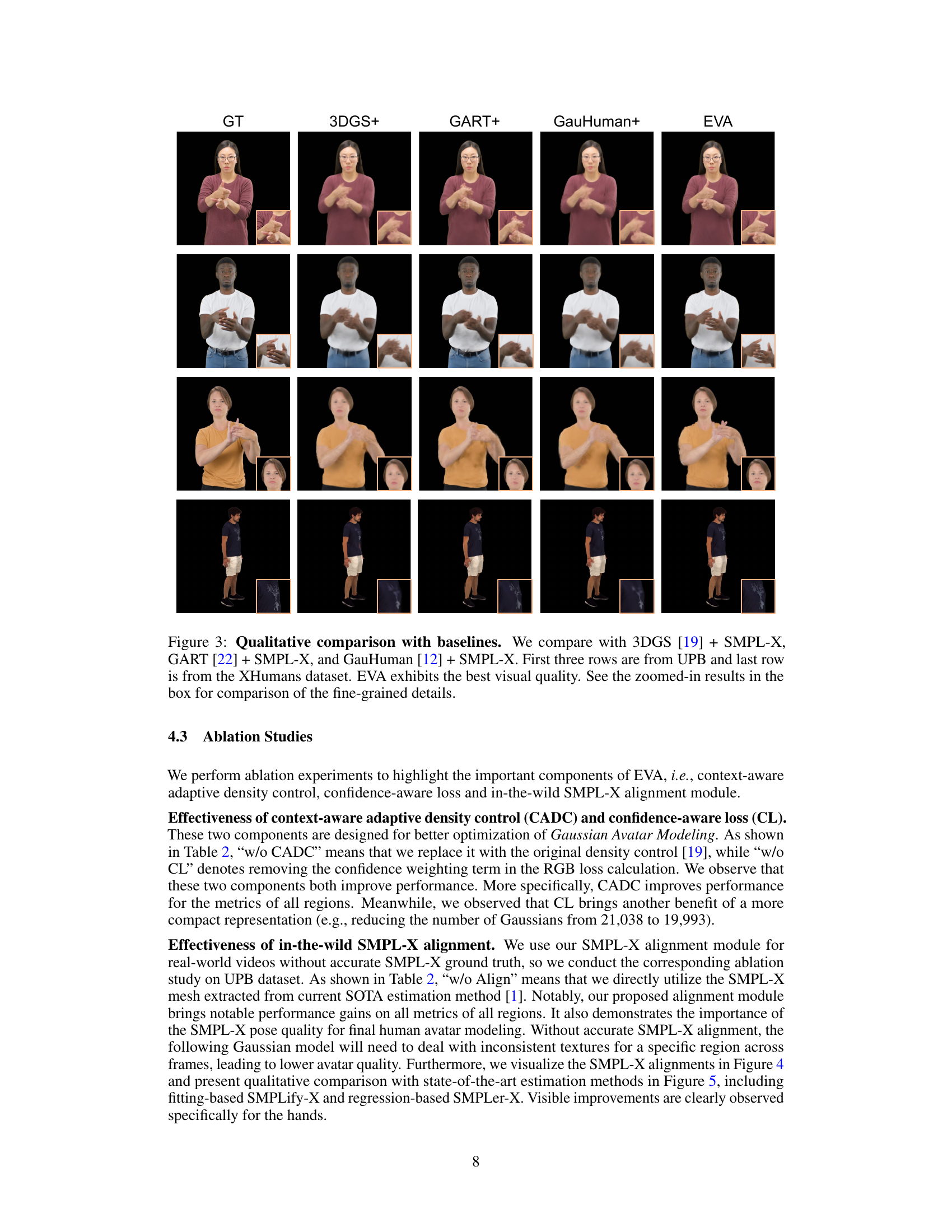
This figure presents a qualitative comparison of the proposed EVA method against three state-of-the-art baselines (3DGS+SMPL-X, GART+SMPL-X, and GauHuman+SMPL-X) on the task of generating expressive human avatars from monocular RGB video. The comparison highlights the superior quality of EVA, particularly in capturing fine-grained details such as hand and facial expressions. The results are shown on both the XHumans (controlled setting) and UPB (in-the-wild) datasets, demonstrating the robustness of the EVA method.

This figure shows a qualitative comparison of the proposed EVA method against three baselines (3DGS + SMPL-X, GART + SMPL-X, and GauHuman + SMPL-X) for generating expressive human avatars from video. The comparison highlights the superior visual quality of EVA, particularly in capturing fine-grained details such as hand and facial expressions. The figure presents results from both the UPB (in-the-wild) and XHumans (controlled) datasets.
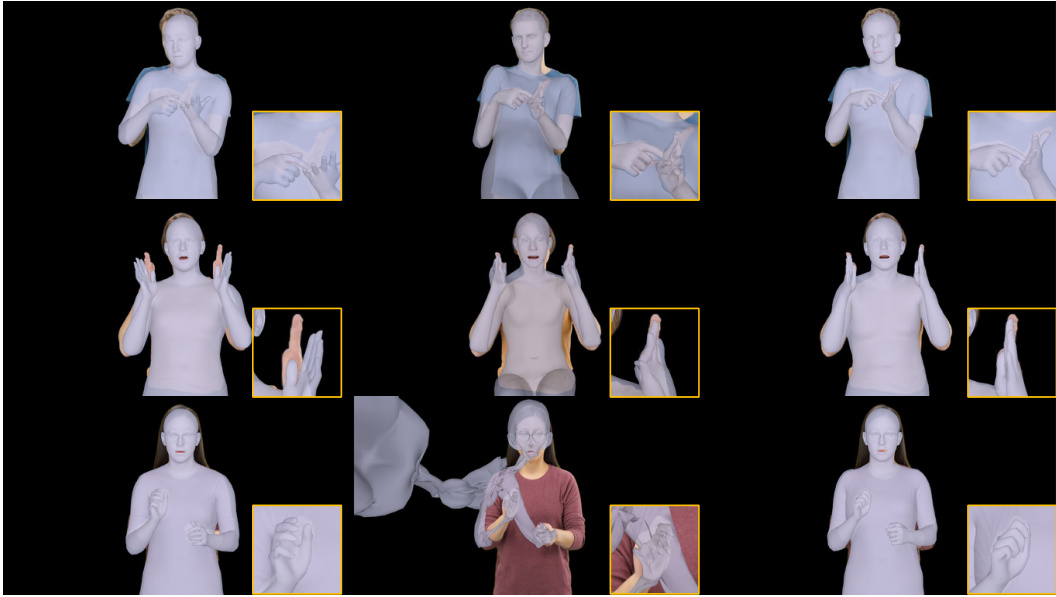
This figure shows a qualitative comparison of the proposed EVA method against three state-of-the-art baselines (3DGS, GART, and GauHuman) for generating expressive human avatars from monocular RGB video. The comparison includes results from both the UPB (in-the-wild) and XHumans (controlled) datasets, highlighting EVA’s superior performance in capturing fine details, particularly in hand and facial expressions. Zoomed-in sections provide a close-up view of the fine-grained details for better comparison.
Full paper#